Prerequisites and Guidelines
 Note |
This section describes requirements and guidelines that are common for all services enabled in your Nexus Dashboard cluster. Additional service-specific requirements are listed in the following sections of this document. |
Network Time Protocol (NTP) and Domain Name System (DNS)
The Nexus Dashboard nodes require valid DNS and NTP servers for all deployments and upgrades. Lack of valid DNS connectivity (such as if using an unreachable or a placeholder IP address) can prevent the system from deploying or upgrading successfully, as well as impact regular services functionality.
Note |
Nexus Dashboard acts as both a DNS client and resolver. It uses an internal Core DNS server which acts as DNS resolver for internal services. It also acts as a DNS client to reach external hosts within the intranet or the Internet, hence it requires an external DNS server to be configured. Nexus Dashboard does not support DNS servers with wildcard records. |
Beginning with release 3.0(1), Nexus Dashboard also supports NTP authentication using symmetrical keys. If you want to enable NTP authentication, you will need to provide the following information during cluster configuration:
-
NTP Key – a cryptographic key that is used to authenticate the NTP traffic between the Nexus Dashboard and the NTP server(s). You will define the NTP servers in the following step, and multiple NTP servers can use the same NTP key.
-
Key ID – each NTP key must be assigned a unique key ID, which is used to identify the appropriate key to use when verifying the NTP packet.
-
Auth Type – this release supports
MD5,SHA, andAES128CMACauthentication types.
The following guidelines apply when enabling NTP authentication:
-
For symmetrical authentication, any key you want to use must be configured the same on both your NTP server and Nexus Dashboard.
The ID, authentication type, and the key/passphrase itself must match and be trusted on both your NTP server and Nexus Dashboard.
-
Multiple servers can use the same key.
In this case the key must only be configured once on Nexus Dashboard, then assigned to multiple servers.
-
Both Nexus Dashboard and the NTP servers can have multiple keys as long as key IDs are unique.
-
This release supports SHA1, MD5, and AES128CMAC authentication/encoding types for NTP keys.
Note
We recommend using AES128CMAC due to its higher security .
-
When adding NTP keys in Nexus Dashboard, you must tag them as
trusted; untrusted keys will fail authentication.This option allows you to easily disable a specific key in Nexus Dashboard if the key becomes compromised.
-
You can choose to tag some NTP servers as
preferredin Nexus Dashboard.NTP clients can estimate the "quality" of an NTP server over time by taking into account RTT, time response variance, and other variables. Preferred servers will have higher priority when choosing a primary server.
-
If you are using an NTP server running
ntpd, we recommend version 4.2.8p12 at a minimum. -
The following restrictions apply to all NTP keys:
-
The maximum key length for SHA1 and MD5 keys is 40 characters, while the maximum length for AES128 keys is 32 characters.
-
Keys that are shorter than 20 characters can contain any ASCII character excluding '
#' and spaces. Keys that are over 20 characters in length must be in hexadecimal format. -
Keys IDs must be in the 1-65535 range.
-
If you configure keys for any one NTP server, you must also configure the keys for all other servers.
-
Enabling and configuring NTP authentication is described as part of the deployment steps in the later sections.
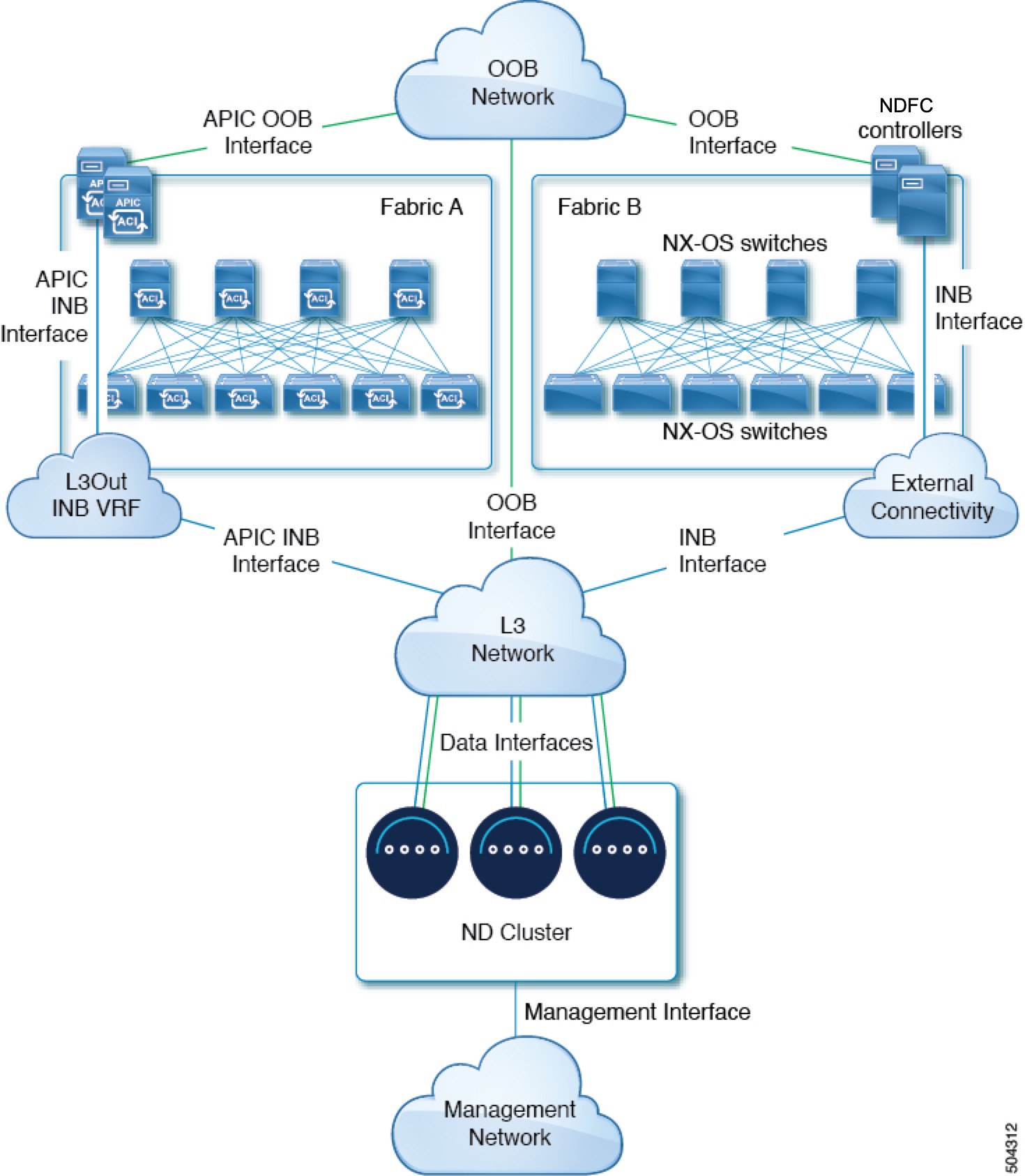
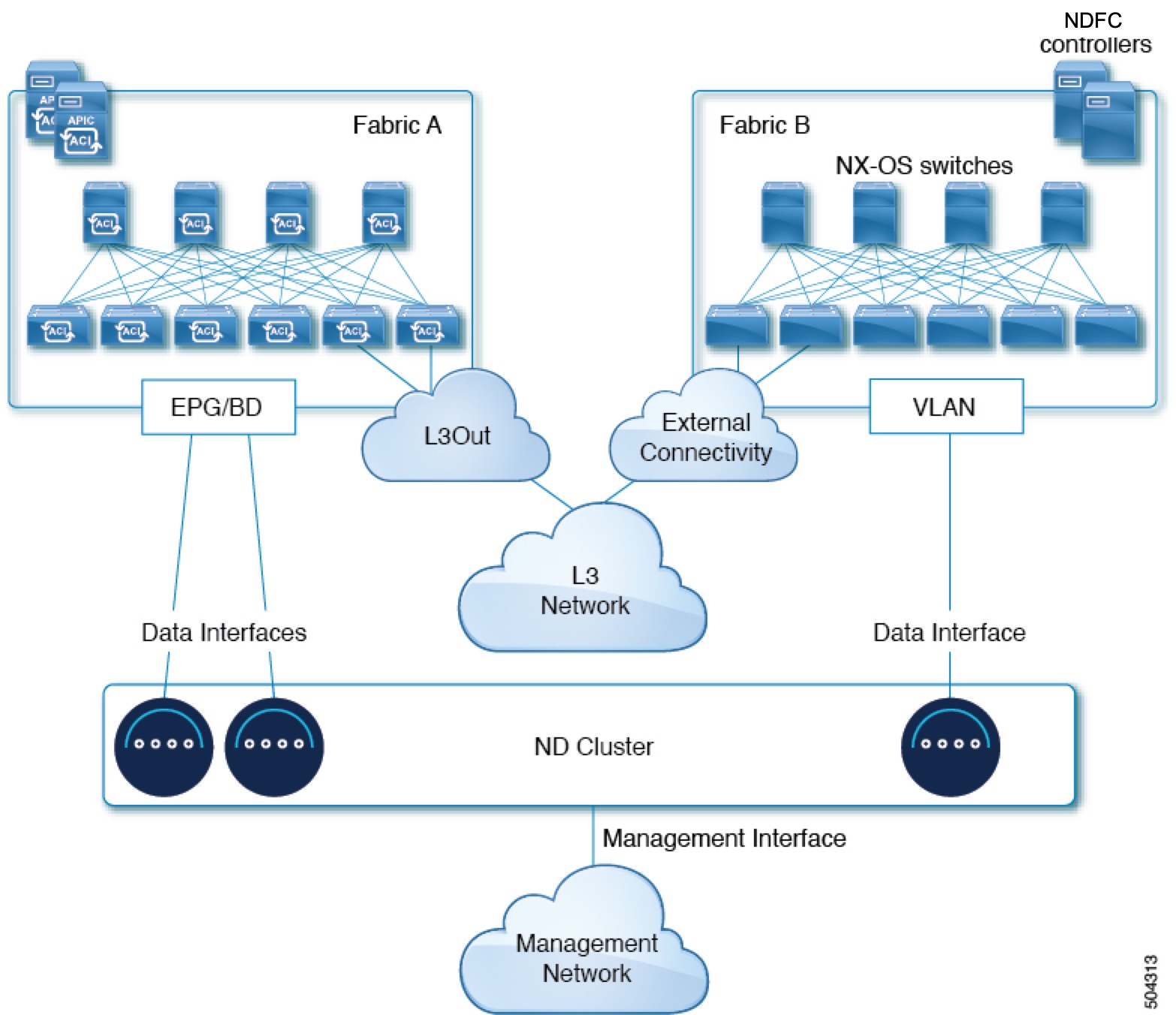
Nexus Dashboard External Networks
Nexus Dashboard is deployed as a cluster, connecting each service node to two networks. When first configuring Nexus Dashboard, you will need to provide two IP addresses for the two Nexus Dashboard interfaces—one connected to the Data network and the other to the Management network.
Individual services installed in the Nexus Dashboard may utilize the two networks for additional purposes, as described in the following sections.
| Data Network | Management Network |
|---|---|
|
|
The two networks have the following requirements:
-
For all new Nexus Dashboard deployments, the management network and data network must be in different subnets.
Note
With the exception of a Nexus Dashboard cluster running only Nexus Dashboard Fabric Controller service, which can be deployed using the same subnets for the data and management networks.
-
Changing the data subnet requires re-deploying the cluster, so we recommend using a larger subnet than the bare minimum required by the nodes and services to account for any additional services in the future.
-
For physical clusters, the management network must provide IP reachability to each node's CIMC via TCP ports 22/443.
Nexus Dashboard cluster configuration uses each node's CIMC IP address to configure the node.
-
The data network interface requires a minimum MTU of 1500 to be available for the Nexus Dashboard traffic.
Higher MTU can be configured if desired on the switches to which the nodes are connected .
Note
If external VLAN tag is configured for switch ports that are used for data network traffic, you must enable jumbo frames or configure custom MTU equal to or greater than 1504 bytes on the switch ports where the nodes are connected.
-
Connectivity between the nodes is required on both networks with the following additional round trip time (RTT) requirements:
Note
RTT requirements for connectivity from the Nexus Dashboard cluster to the site controllers or switches depends on the specific service you plan to enable, see the "Network Requirements" sections in the service-specific chapters below.
Table 2. Cluster RTT Requirements Connectivity
Maximum RTT
Between nodes within the same Nexus Dashboard cluster
50 ms
Between nodes in one cluster and nodes in a different cluster if the clusters are connected via multi-cluster connectivity
For more information about multi-cluster connectivity, see Cisco Nexus Dashboard Infrastructure Management.
500 ms
Between external DNS servers and the Nexus Dashboard cluster
5 seconds
Nexus Dashboard Internal Networks
Two additional internal networks are required for communication between the containers used by the Nexus Dashboard:
-
Application overlay is used for applications internally within Nexus Dashboard
Application overlay must be a
/16network and a default value is pre-populated during deployment. -
Service overlay is used internally by the Nexus Dashboard.
Service overlay must be a
/16network and a default value is pre-populated during deployment.
If you are planning to deploy multiple Nexus Dashboard clusters, they can use the same Application and Service subnets.
Note |
Communications between containers deployed in different Nexus Dashboard nodes is VXLAN-encapsulated and uses the data interfaces IP addresses as source and destination. This means that the Application Overlay and Service Overlay addresses are never exposed outside the data network and any traffic on these subnets is routed internally and does not leave the cluster nodes. For example, if you had another service (such as DNS) on the same subnet as one of the overlay networks, you would not be able to access it from your Nexus Dashboard as the traffic on that subnet would never be routed outside the cluster. As such, when configuring these networks, ensure that they are unique and do not overlap with any existing networks or services external to the cluster, which you may need to access from the Nexus Dashboard cluster nodes. For the same reason, we recommend not using |
IPv4 and IPv6 Support
Prior releases of Nexus Dashboard supported either pure IPv4 or dual stack IPv4/IPv6 (for management network only) configurations for the cluster nodes. Beginning with release 3.0(1), Nexus Dashboard supports pure IPv4, pure IPv6, or dual stack IPv4/IPv6 configurations for the cluster nodes and services.
When defining IP configuration, the following guidelines apply:
-
All nodes and networks in the cluster must have a uniform IP configuration – either pure IPv4, or pure IPv6, or dual stack IPv4/IPv6.
-
If you deploy the cluster in pure IPv4 mode and want to switch to dual stack IPv4/IPv6 or pure IPv6, you must redeploy the cluster.
-
For dual stack configurations:
-
Both external (data and management) and internal (app and services) networks must be in dual stack mode.
Mixed configurations, such as IPv4 data network and dual stack management network, are not supported.
-
IPv6 addresses are also required for physical servers' CIMCs.
-
You can configure either IPv4 or IPv6 addresses for the nodes' management network during initial node bring up, but you must provide both types of IPs during the cluster bootstrap workflow.
Management IPs are used to log in to the nodes for the first time to initiate cluster bootstrap process.
-
Kubernetes internal core services will start in IPv4 mode.
-
DNS will serve and forward both IPv4 and IPv6 requests.
-
VXLAN overlay for peer connectivity will use data network's IPv4 addresses.
Both IPv4 and IPv6 packets are encapsulated within the VXLAN's IPv4 packets.
-
The UI will be accessible on both IPv4 and IPv6 management network addresses.
-
-
For pure IPv6 configurations:
-
Pure IPv6 mode is supported for physical and virtual form factors only.
Clusters deployed in AWS and Azure do not support pure IPv6 mode.
-
You must provide IPv6 management network addresses when initially configuring the nodes.
After the nodes are up, these IPs are used to log in to the UI and continue cluster bootstrap process.
-
You must provide IPv6 CIDRs for the internal App and Service networks described above.
-
You must provide IPv6 addresses and gateways for the data and management networks described above.
-
All internal services will start in IPv6 mode.
-
VXLAN overlay for peer connectivity will use data network's IPv6 addresses.
IPv6 packets are encapsulated within the VXLAN's IPv6 packets.
-
All internal services will use IPv6 addresses.
-
BGP Configuration and Persistent IPs
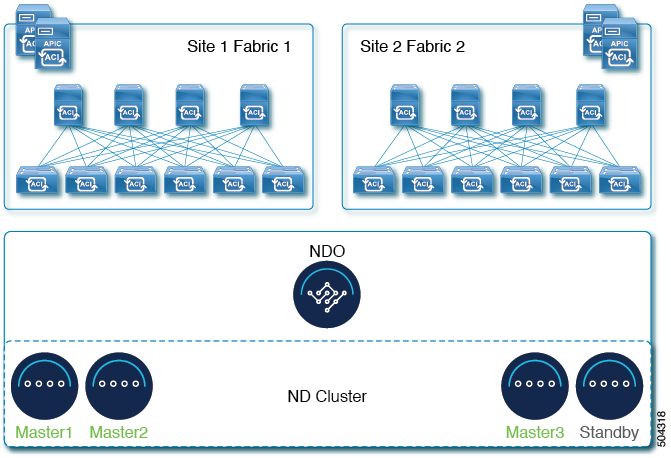
Some prior releases of Nexus Dashboard allowed you to configure one or more persistent IP addresses for services (such as Insights and Fabric Controller) that require retaining the same IP addresses even in case they are relocated to a different Nexus Dashboard node. However, in those releases, the persistent IPs had to be part of the management and data subnets and the feature could be enabled only if all nodes in the cluster were part of the same Layer 3 network. Here the services used Layer 2 mechanisms like Gratuitous ARP or Neighbor Discovery to advertise the persistent IPs within it's Layer 3 network
While that is still supported, this release also allows you to configure the Persistent IPs feature even if you deploy the cluster nodes in different Layer 3 networks. In this case, the persistent IPs are advertised out of each node's data links via BGP, which we refer to as "Layer 3 mode". The IPs must also be part of a subnet that is not overlapping with any of the nodes' management or data subnets. If the persistent IPs are outside the data and management networks, this feature will operate in Layer 3 mode by default; if the IPs are part of those networks, the feature will operate in Layer 2 mode. BGP can be enabled during cluster deployment or from the Nexus Dashboard GUI after the cluster is up and running.
If you plan to enable BGP and use the persistent IP functionality, you must:
-
Ensure that the peer routers exchange the advertised persistent IPs between the nodes' Layer 3 networks.
-
Choose to enable BGP at the time of the cluster deployment as described in the subsequent sections or enable it afterwards in the Nexus Dashboard GUI as described in the "Persistent IP Addresses" sections of the Infrastructure Management document.
-
Ensure that the persistent IP addresses you allocate do not overlap with any of the nodes' management or data subnets.
-
Ensure that you fulfill the service-specific persistent IP requirements listed in the service-specific sections that follow.
The total number of persistent IPs required for each service is listed in the service-specific requirements sections that follow.



 Feedback
Feedback