This topic provides examples of configuring high availability, specifically, of configuring affinity between vSmart controllers
and
Cisco IOS XE SD-WAN device.
Configure Affinity to vSmart Controllers in a Single Data Center
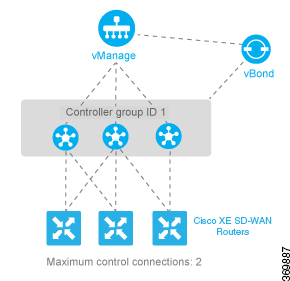
In an overlay network with a single data center that has multiple vSmart controllers, if you want the
Cisco IOS XE SD-WAN device to establish a single control connection to one of vSmart controllers, there is no need to configure affinity because this
situation is the default behavior.
However, if you want the
Cisco IOS XE SD-WAN device to establish control connections to more than one vSmart controllers, to provide redundancy in case one of the controllers
becomes unavailable, you configure affinity. You generally place the vSmart controllers in the same controller group.
Let's say that all the vSmart controllers use the same controller group identifier, 1. You configure the identifier on all
three controllers as follows:
vSmart(config)# system controller-group-id 1
To verify the configuration, use the
show running-config
command:
vSmart# show running-config system
system
description "vSmart in data center 1"
host-name vSmart
gps-location latitude 37.368140
gps-location longitude -121.913658
system-ip 172.16.255.19
site-id 100
controller-group-id 1
organization-name "Cisco"
clock timezone America/Los_Angeles
We want the three
Cisco IOS XE SD-WAN devices to establish two control connections to two of the three vSmart controllers. We do this for purposes of redundancy, in case
one of the controllers becomes available. Because all the vSmart controllers are in the same controller group, we cannot specify
or influence which of the two controllers the
Cisco IOS XE SD-WAN devices connect to. The configurations on all three routers are effectively identical. We show here the configuration for router
Cisco IOS XE SD-WAN device-1.
First, configure the available vSmart controller groups. This scenario has just one group:
ISR4331-1(config)# system controller-group-list 1
By default, a
Cisco IOS XE SD-WAN device can establish two control connections. Because we want each
Cisco IOS XE SD-WAN device and each tunnel interface to connect to two vSmart controllers, no configuration is required here. However, if you want to
explicitly configure these parameters, you configure the maximum number of OMP sessions at the system level and the maximum
number of control connections per tunnel:
ISR4331-1(config)# system max-omp-sessions 2
ISR4331-1(config)# sdwan interface GigabitEthernets0/0/1 tunnel-interface
ISR4331-1(config-tunnel-interface)# max-control-connections 2
Here are the relevant configuration snippets from Cisco IOS XE SD-WAN device-1:
ISR4331-1# show sdwan running-config | section system
system
host-name ISR4331-1
gps-location latitude 43.0
gps-location longitude -75.0
system-ip 172.16.255.11
site-id 100
max-omp-sessions 2
controller-group-list 1
admin-tech-on-failure
organization-name Cisco
...
ISR4331-1# show running-config | section sdwan
...
interface GigabitEthernets0/0/1
tunnel-interface
encapsulation ipsec
max-control-connections 1
no allow-service bgp
allow-service dhcp
allow-service dns
allow-service icmp
no allow-service sshd
no allow-service netconf
no allow-service ntp
no allow-service ospf
no allow-service stun
allow-service https
exit
exit
…
To display the control connections with the vSmart controllers, use the
show sdwan control connections
command. The last column, Controller Group ID, lists the vSmart controller group that a router is in.
ISR4331-1# show sdwan control connections
PEER
PEER CONTROLLER
PEER PEER PEER SITE DOMAIN PEER PRIV PEER
PUB GROUP
TYPE PROT SYSTEM IP ID ID PRIVATE IP PORT PUBLIC IP PORT
LOCAL COLOR PROXY STATE UPTIME ID
----------------------------------------------------------------------------------------------------------------------------------------------
------------------------------------------
vsmart dtls 10.255.2.120 1 1 10.2.1.120 12346 10.2.1.120 12346
default up 0:00:06:17 1
vmanage dtls 10.255.2.100 1 1 0 10.2.1.100 12346 10.2.1.100
12346 default up 0:00:06:13 0
To display the maximum number of control connections allowed on the router, use the
show sdwan control local-properties
command. The last line of the output lists the maximum controllers. The following is the abbreviated output for this command:
ISR4331-1# show sdwan control local-properties
personality vedge
organization-name Cisco
certificate-status Installed
root-ca-chain-status Installed
certificate-validity Valid
certificate-not-valid-before Sep 27 03:14:18 2016 GMT
certificate-not-valid-after Sep 27 03:14:18 2026 GMT
...
PUBLIC PUBLIC PRIVATE PRIVATE PRIVATE MAX RESTRICT/ LAST SPI
TIME NAT VM
INTERFACE IPv4 PORT IPv4 IPv6 PORT VS/VM COLOR STATE CNTRL CONTROL/ LR/LB CONNECTION
REMAINING TYPE CON
STUN PRF
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
-------------------
GigabitEthernet0/0/1 2.2.1.17 12406 2.2.1.17 :: 12406 2/1 default up 2 no/yes/no No/No 17:15:53:07
0:08:02:33 N 5
Two commands display information about the control connections established by the affinity configuration. To see, for each
interface, which controller groups are configured and which the interface is connected to, use the
show sdwan control affinity config
command:
ISR4331-1# show sdwan control affinity config
EFFECTIVE CONTROLLER LIST FORMAT - G(C),... - Where G is the Controller Group ID
C is the Required vSmart Count
CURRENT CONTROLLER LIST FORMAT - G(c)s,... - Where G is the Controller Group ID
c is the current vSmart count
s Status Y when matches, N when does not match
EFFECTIVE
REQUIRED LAST-RESORT
INDEX INTERFACE VS COUNT EFFECTIVE CONTROLLER LIST CURRENT CONTROLLER LIST EQUILIBRIUM INTERFACE
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
0 GigabitEthernet0/0/11 1(1) 1(1)Y Yes No
The command output above shows that affinity is configured on interface GigabitEthernet 0/0/11.
-
The Effective Required and Count column shows that the interface is configured to create two control connections, and, in fact, two control connections have
been established. You configure the number of control connections for the tunnel interface with the
max-control-connections
command.
-
The Effective Controller List column shows that affinity on the interface is configured to use Cisco vSmart Controller identifier 1 and that the router supports two OMP sessions. You configure the affinity controller identifiers with the
controller-group-list
command (at the
system
level) and, for the tunnel interface, the
exclude-controller-group-list
command.
-
The Current Controller List column lists the actual affinity configuration for the interface. The output here shows that the
interface has two control connections with Cisco vSmart Controllers in group 1. The check mark indicates that the current and effective controller lists match each other. If, for example,
the tunnel had established only one TLOC connection to a vSmart controller, this column would show "1(1)X".
-
The Equilibrium column indicates that the current controller lists matches what is expected from the affinity configuration
for that tunnel interface.
To determine the exact Cisco vSmart Controllers that the tunnel interface has established control connections with, use the
show control affinity status
command:
ISR4331-1# show sdwan control affinity status
ASSIGNED CONNECTED CONTROLLERS - System IP( G),.. - System IP of the assigned vSmart
G is the group ID to which the vSmart belongs to
UNASSIGNED CONNECTED CONTROLLERS - System IP( G),.. - System IP of the unassigned vSmart
G is the group ID to which the vSmart belongs to
INDEX INTERFACE ASSIGNED CONNECTED CONTROLLERS UNASSIGNED CONNECTED CONTROLLERS
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
0 GigabitEthernet 0/0/1 10.255.2.120( 1)
The command output above shows that interface GigabitEthernet 0/0/1 has control connections to the vSmart controller, 10.255.2.120,which is in group 1. If the interface were connected to a
vSmart controller not in the controller group list, it would be listed in the Unassigned Connected Controllers column.
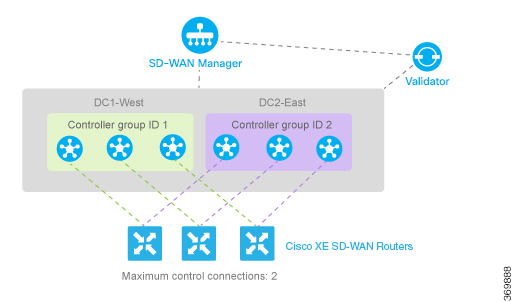
When a data center has multiple vSmart controllers, you can configure them to be in different controller groups. For example,
if you configure them to be in two different controller groups, each
Cisco IOS XE SD-WAN device can establish two control connections, one to each of the groups. While this configuration design is similar to what we discussed
in the previous section, providing redundant control connections to the vSmart controllers, on subtle difference is that it
provides fault isolation between the twoCisco vSmart Controller groups in the data center. The configuration for this scenario is almost identical to the configuration when Cisco vSmart Controllers are two data centers. The only difference is that here, two Cisco vSmart Controller groups are collocated in the same data center. See the configuration example in the next section.
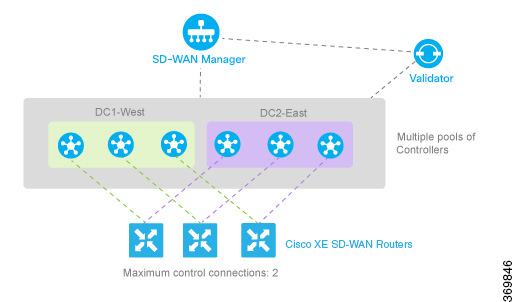
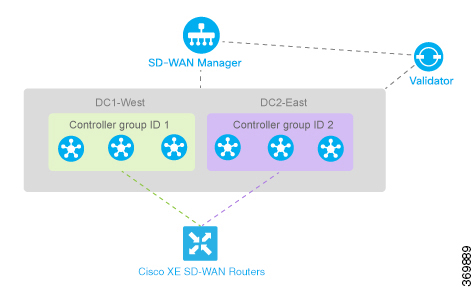
Configure Affinity to vSmart Controllers in Two Data Centers
You can use affinity to enable redundancy among data centers, for a network design in which multiple Cisco vSmart Controllers are spread across two or more data centers. Then, if the link between a
Cisco IOS XE SD-WAN device and one of the data centers goes down, the Cisco vSmart Controllers in the second data center are available to continue servicing the overlay network. The figure below illustrates this scenario,
showing three Cisco vSmart Controllers in each of two data centers. Each of the three
Cisco IOS XE SD-WAN devices establishes a TLOC connection to one controller in the West data center and one in the East data center.
You configure the three vSmart controllers in DC1-West with controller group identifier 1:
vSmart-DC1(config)# system controller-group-id 1
The three vSmart controllers in DC2-East are in controller group 2:
vSmart-DC2(config)# system controller-group-id 2
We want all the
Cisco IOS XE SD-WAN devices to have a maximum of two OMP sessions, and we want each tunnel interface to have a maximum of two control connections and
to not exclude any controller groups. So the only configuration that needs to be done on the routers is to set the controller
group list. We want
Cisco IOS XE SD-WAN devices in the west to prefer Cisco vSmart Controllers in DC1-West over DC2-East:
ISR4331-West(config)# system controller-group-list 1 2
Similarly, we want
Cisco IOS XE SD-WAN devices in the east to prefer DC2-East:
ISR4331-East(config)# system controller-group-list 2 1
The software evaluates the controller group list in order, so with this configuration, the Cisco XE SD-WAN-West routers prefer
Cisco vSmart Controller group 1 (which is the West data center), and the Cisco XE SD-WAN-East routers prefer Cisco vSmart Controller group 2.
You can fine-tune the controller group preference in other ways:
-
Set the maximum number of OMP sessions allowed on the router to 2 (system max-omp-sessions 1). To illustrate how this works, let's look at a Cisco XE SD-WAN-West router. The router has only one tunnel interface, and
that interface creates one control connection to Cisco vSmart Controller list 1. If all the Cisco vSmart Controllers in this group become unavailable, or if the connection between the router that the DC1-West data center goes down, the tunnel
interface establishes one control connection to Cisco vSmart Controller list 2, because this group is listed in the system controller-group-list command. If all Cisco vSmart Controllers in both controller groups, or the connections to them, become unavailable, and if the vBond orchestrator also indicates
that all these vSmart controllers are unreachable, the tunnel interface establishes a control connection to any other Cisco vSmart Controller in the overlay network if other controllers are present.
-
Set the maximum number of control connections that the tunnel interface can establish to 1 (
vpn 0 sdwan interface tunnel-interface max-control-connections 1
). Because the software evaluates the controller group list in order, for a Cisco XE SD-WAN-West router, this configuration
forces the tunnel interface to establish a control connection to Cisco vSmart Controller group 1. Again, if this controller group or data center becomes unreachable, the tunnel establishes a control connection
with controller group 2, because this group is configured in the
system controller-group-list
command. And if neither controller group 1 or 2 is available, and if another Cisco vSmart Controller is present in the network, the tunnel interface establishes a control connection with that controller.
-
Exclude the non-preferred Cisco vSmart Controller group for a particular tunnel. For example, for a Cisco XE SD-WAN-West router to prefer controller group 1, you configure
vpn 0 sdwan interface tunnel-interface exclude-controller-group-list 2
. As with the above configurations, if this controller group or data center becomes unreachable, the tunnel establishes a
control connection with controller group 2, because this group is configured in the
system controller-group-list
command. And if neither controller group 1 or 2 is available, and if another Cisco vSmart Controller is present in the network, the tunnel interface establishes a control connection with that controller.
Configure Redundant Control Connections on One
Cisco IOS XE SD-WAN Device
When a router has two tunnel connections and the network has two (or more) data centers, you can configure redundant control
connections from the
Cisco IOS XE SD-WAN device to Cisco vSmart Controllers in two of the data centers. It is recommended that do this using the minimum number of OMP sessions—in this case, two. To
do this, you configure one of the tunnel interfaces to go only to one of the data centers and the other to go only to the
second. This configuration provides vSmart redundancy with the minimum number of OMP sessions.
On the
Cisco IOS XE SD-WAN device router, define the controller group list and configure the maximum number of OMP sessions to be 2:
ISR4331(config)# system controller-group-list 1 2
ISR4331(config)# system max-omp-sessions 2
For one of the tunnels, you can use the default affinity configuration (that is, there is nothing to configure) to have this
tunnel prefer a Cisco vSmart Controller in group 1. You can also explicitly force this tunnel to prefer Cisco vSmart Controller group 1:
ISR4331(config-tunnel-interface-1)# max-control-connections 1
You do not need to configure
exclude-controller-group-list 2
, because the software evaluates the controller group list in order, starting with group 1. However, you could choose to explicitly
exclude vSmart controller group 2.
Then, on the second tunnel, configure it to prefer a vSmart controller in group 2. As with the other tunnel, you limit the
maximum number of control connections to 1. In addition, you have to exclude controller group 1 for this tunnel.
ISR4331(config-tunnel-interface-2)# max-control-connections 1
ISR4331(config-tunnel-interface-2)# exclude-controller-group-list 1




 Feedback
Feedback