Servidores UCS B-Series: Substituir um controlador RAID por um firmware mais antigo pode causar falha na montagem do armazenamento de dados em hosts ESXi
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Instrução do problema:
Após a substituição da controladora RAID, a id NAA do VD foi alterada durante a importação de configuração externa e isso causou falha na montagem do datastore.
Hardware afetado:
UCSB-MRAID12G
UCSC-MRAID12G
Servidores com controladoras UCSB-MRAID12G RAID:
UCS B200 M4
UCS B200 M5
UCS B480 M5
UCS B420 M4
UCS C220 M4
UCS C240 M4
Firmware afetado:
Firmware da controladora RAID : 24.5.x.x e 24.6.x.x
Exemplo nº
***mrsasctlr.24.5.0-0043_6.19.05.0_NA.bin
O firmware da controladora 24.5.x.x é visto em todas as versões do UCSM anteriores à 3.2.*
Notas de versão do nº 3.1
https://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/release/notes/CiscoUCSManager-RB-3-1.htmlhttps://www.cisco.com/c/en/us/td/docs/unified_computing/ucs/release/notes/CiscoUCSManager-RB-3-1.html
SO afetado:
VMware ESXi
Causa:
Com versões de firmware mais antigas, se houver uma incompatibilidade de versão do espaço de trabalho DDF (Device Data Format) encontrada, o firmware do controlador não poderá restaurar o ID NAA do DDF durante a importação externa.
O MR 6.4 tem DDF_WORK_SPACE versão 1, enquanto o MR 6.10 tem DDF_WORK_SPACE versão 3. Versões posteriores do FW pós-MR 6.4, foram feitas correções que permitem que o FW da controladora restaure a IDD da NAA do DDF mesmo que uma incompatibilidade de espaço de trabalho do DDF seja encontrada. A ID NAA não pode ser analisada corretamente quando o firmware do controlador de substituição é antigo (Exemplo: 24.5.x e 24.6.x). No entanto, a versão 24.12.x pode analisar corretamente o ID da NAA.
| Antes da substituição: Servidor 2/2: Nome do produto equipado: Servidor blade de 2 soquetes Cisco UCS B200 M5 PID equipado: UCSB-B200-M5 VID equipada: V06 Série equipada (SN): FCH222973K5 Status do slot: Equipado Nome do produto reconhecido: Servidor blade de 2 soquetes Cisco UCS B200 M5 PID reconhecido: UCSB-B200-M5 VID reconhecido: V06 Serial reconhecida (SN): FCH222973K5 Memória reconhecida (MB): 524288 Memória efetiva reconhecida (MB): 524288 Núcleos reconhecidos: 28 Adaptadores reconhecidos: 1 Unidade virtual 0: Digite: RAID 1 espelhado Tamanho do bloco: 512 Blocos: 1560545280 Operabilidade: Operável Presença: Equipado Tamanho: 761985 Ciclo de vida: Alocado Estado da unidade: Ideal Tamanho da faixa (KB): 64 Política de acesso: Leitura e gravação Política de leitura: Normal Política de Cache de Gravação Configurada: Gravar Através Política real de cache de gravação: Gravar Através Política de E/S: DIRECT Cache da unidade: Nenhuma alteração Inicializável: Verdadeiro Identificador exclusivo: bcc0dd21-2006-4189-86c1-132017ad0958 Identificador exclusivo do fornecedor: 618e7283-72eb-6460-240f-d02c0bbd9310 <<<<<<<<<<<<<<< Após a substituição: Servidor 2/2: Unidade virtual 0:
Nesse caso, a ID do servidor 2/2 [Identificador exclusivo do fornecedor] foi alterada de [618e7283-72eb-6460-240f-d02c0bd9310] para [618e7283-72ea-3f 20-ff00-005a0574b04b] |
Como evitar que o problema seja atingido?
Esse problema pode ser evitado atualizando o firmware do controlador de substituição antes de inserir o VD / disco.
Etapas detalhadas:
- Desligar o servidor
- Remova todos os discos um por um e deixe os discos no mesmo slot não totalmente inserido para que a ordem de posicionamento não seja perturbada(Se remover completamente do slot, mantenha uma nota do slot pois as unidades precisam ser colocadas de volta no mesmo slot)
- Instale um novo controlador RAID para substituição sem inserir um disco.
- O servidor reconhecerá o novo controlador RAID
- Atualize o firmware do controlador Raid.
- Após a atualização bem-sucedida do firmware, desligue o servidor e insira o disco no servidor.
- Agora ligue o servidor
Como recuperar se o servidor é atingido por esse problema?
Etapas detalhadas:
===================
Procedimento para restaurar o armazenamento de dados
===================
1 Faça login no vSphere Client e selecione o servidor no painel de inventário.
2 Clique na guia Configuração e em Armazenamento no painel Hardware.
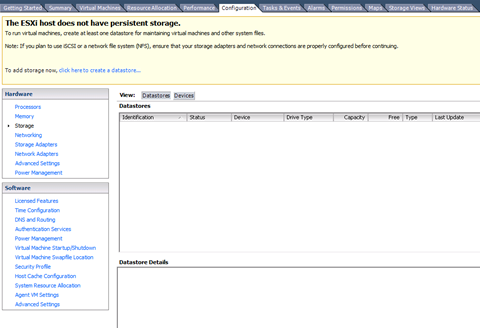
3 Clique em Add Storage (Adicionar armazenamento).
4 Selecione o tipo de armazenamento Disco/LUN e clique em Avançar.
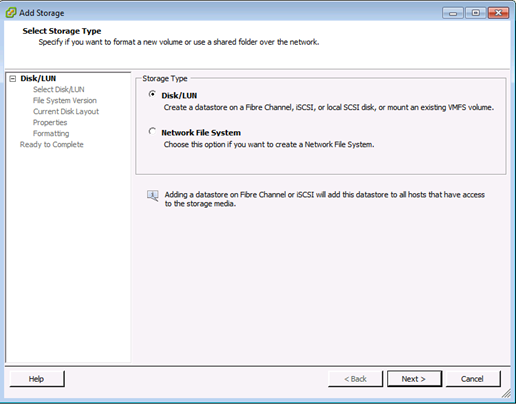
5 Na lista de LUNs, selecione o LUN que tem um nome de armazenamento de dados exibido na coluna VMFS Label e clique em Next.
Nota: O nome presente na coluna Rótulo VMFS indica que o LUN é uma cópia que contém uma cópia de um armazenamento de dados VMFS existente.

6 Em Opções De Montagem, estas opções são exibidas:
Manter assinatura existente: Monte o LUN de forma persistente (por exemplo, monte o LUN em reinicializações)
Atribuir uma nova assinatura: Renigalize o LUN
Formatar o disco: Reformate o LUN
Notas: Formatar o discoexclui todos os dados existentes no LUN. Antes de tentar assinar novamente, certifique-se de que não há máquinas virtuais em execução no volume VMFS em qualquer outro host, pois essas máquinas virtuais se tornam inválidas no inventário do vCenter Server e devem ser registradas novamente em seus respectivos hosts.
selecione Atribuir uma nova assinatura e clique em Avançar.

7 Selecione a opção desejada para o seu volume
8 Na página Ready to Complete (Pronto para concluir), revise as informações de configuração do armazenamento de dados e clique em Finish (Concluir).

===================
O que fazer a seguir
===================
Após a demissão, talvez seja necessário fazer o seguinte:
1 Faça login no vSphere Client ,Uem Lista de inventário > Clique em Armazenamento de dados
2 Clique com o botão direito do mouse no datastore e clique em "Procurar datastore"

3 No painel esquerdo, clique em uma pasta VM para exibir o conteúdo no painel direito

4 No painel direito, clique com o botão direito do mouse no arquivo .vmx e selecione "Adicionar ao inventário"

5 Consulte o assistente "Adicionar ao inventário" para concluir a adição da VM ao host ESXi
6 Repita as etapas para todas as VMs restantes
7 Depois que todas as VMs tiverem sido registradas novamente, remova todas as VMs inacessíveis do inventário clicando com o botão direito em cada uma e selecionando "Remover do inventário"
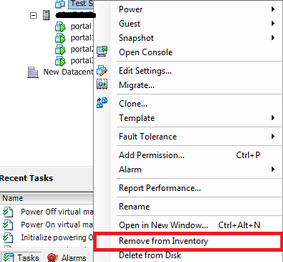
8 Ligue cada VM e verifique se está operacional e acessível
Note: Antes de ligar a VM, reinicialize o host ESXi e depois que ele voltar a ficar on-line e acessível via cliente vSphere, confirme se as VMs ainda estão visíveis e não estão no estado "Inacessível"
BUG relacionado: CSCvr11972
CSCvr11972  Identificador exclusivo do fornecedor alterado após a substituição de MRAID12G
Identificador exclusivo do fornecedor alterado após a substituição de MRAID12G
Colaborado por engenheiros da Cisco
- Afroj AhmadTechnical Consulting Engineer - CX
- Yogesha MGTechnical Leader - CX
- Yogindar Das YasodharTechnical Leader - Storage Engineering
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)