Cisco 12000 シリーズ インターネット ルータのアーキテクチャ:スイッチ ファブリック
内容
概要
この文書では、バックプレーン、スイッチ ファブリック、Clock and Scheduler Card(CSC; クロック スケジューラ カード)、Switch Fabric Card(SFC; スイッチ ファブリック カード)、シスコ セルなど、Cisco 12000 シリーズ インターネット ルータのハードウェア コンポーネントの一部について検証します。
前提条件
要件
このドキュメントに特有の要件はありません。
使用するコンポーネント
このドキュメントの情報は、Cisco 12000シリーズインターネットルータに基づくものです。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、初期(デフォルト)設定の状態から起動しています。対象のネットワークが実稼働中である場合には、どのようなコマンドについても、その潜在的な影響について確実に理解しておく必要があります。
表記法
ドキュメント表記の詳細は、『シスコ テクニカル ティップスの表記法』を参照してください。
バックプレーン
Cisco 12000 スイッチ ファブリックについての説明の前に、バックプレーンについて説明します。
シャーシの前面には、Gigabit Route Processor(GRP; ギガビット ルート プロセッサ)および Line Card(LC; ラインカード)が取り付けられており、パッシブ バックプレーンに差し込まれています。このバックプレーンに用意されているシリアル回線によって、すべてのラインカードがスイッチ ファブリック カードに相互接続されるだけでなく、電源やメンテナンス機能のための他の接続部も相互接続されています。120xxモデルでは、各2.5 Gbpsシャーシスロットに最大4つの1.25 Gbpsシリアルライン接続があり、各スイッチファブリックカードに1つずつ接続して、スロットあたり5 Gbpsまたは2.5 Gbps全二重を提供します。124xxモデルでは、各10 Gbpsシャーシスロットは4組のシリアル回線接続を使用し、各スロットに20 Gbps全二重のスイッチング容量を提供します。
また、ラインカードのすべてのモデルには、冗長 Clock and Scheduler Card(CSC; クロック スケジューラ カード)に接続できる 5 つ目のシリアル回線が用意されています。
スイッチ ファブリック
Cisco 12000 シリーズ インターネット ルータでは、ギガビットの速度で高キャパシティのスイッチングを行うことができるように最適化されている、マルチギガビット クロスバー スイッチ ファブリックがその核心となっています。クロスバー スイッチでは、次の 2 つの理由により高キャパシティを実現できます。
-
ラインカードから中央集中型ファブリックにはポイントツーポイント リンクで接続されているため、非常に高速に動作できます。
-
複数のバス トランザクションを同時にサポートできるため、システムの集約帯域幅が広くなります。Switch Fabric Card(SFC; スイッチ ファブリック カード)は、スケジューリング情報とクロッキング基準を Clock Scheduler Card(CSC; クロック スケジューラ カード)から受信し、スイッチング機能を実行します。SFC は NxN(この場合、N はスロット数)のマトリックスと考えることができます。
このアーキテクチャでは、複数のラインカードで同時にデータの送受信を行うことができます。CSC は、特定のファブリック サイクルでデータの送信を行うラインカードおよび受信を行うラインカードを選択します。
スイッチ ファブリックは、次のトラフィックに対して物理的なパスを提供します。
-
電源投入時の Route Processor(RP; ルート プロセッサ)からラインカードへの初期ファブリック ダウンローダ
-
Cisco Express Forwardingのアップデート
-
ラインカードからの統計情報
-
トラフィック交換
次に、これらの機能の詳細を説明します。
スイッチ ファブリックは、NxN の非ブロッキング クロスバー スイッチ ファブリックです。この場合、N はシャーシ(GRP を含む)でサポートされる LC の最大数を表します。 これにより、各スロットはファブリックを通してトラフィックの送信および受信を同時に行うことができます。非ブロッキング アーキテクチャで同時に複数のラインカードが他のラインカードに送信できるようにするために、各 LC には N+1 個の Virtual Output Queuing(VOQ; 仮想出力キュー)が装備されています(ラインカードの送信先ごとに 1 つずつ、マルチキャスト用に 1 つ)。
あるインターフェイスにパケットが着信すると、ルックアップが実行されます(LC や設定されている機能によって、ハードウェアまたはソフトウェアで実行される)。 ルックアップによって、出力LC、インターフェイス、および適切なメディアアクセスコントロール(MAC)レイヤの書き換え情報が決定されます。パケットがファブリックを介して出力LCに送信される前に、パケットはCisco Cellsに分割されます。次に、シスコ セルを特定の出力 LC に送信するための権限要求がクロック スケジューラに対して送信されます。1 つのセルは、1 つのファブリック クロック サイクルごとに E0 LC によって送信され、4 つのファブリック クロック サイクルごとに E1 以上の LC によって送信されます。出力 LC によってこれらのシスコ セルがパケットに再構成され、パケットとともに送信された MAC 書き換え情報を使用して MAC レイヤの書き換えが実行され、パケットは送信のために適切なインターフェイスにキューイングされます。
LC 上のあるインターフェイスで着信され、同じ LC 上の別のインターフェイス(またはサブインターフェイスの場合は同じインターフェイス)で送信される場合でも、パケットはシスコ セルにセグメント化されてファブリックを通して送り返されます。
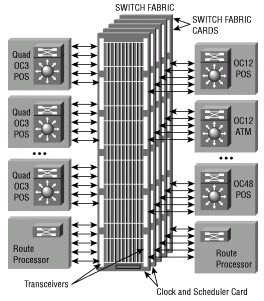
クロック スケジューラ カード(CSC)
CSC はラインカードから送信要求を受け入れ、ファブリックへのアクセス許可を発行してから、システム内のすべてのカードに基準クロックを提供してクロスバーでのデータ転送の同期を取ります。同時に複数の CSC がアクティブになることはありません。
CSC は、システムに 2 枚目の(冗長)CSC が取り付けられている場合に限り、システムの通常動作を中断せずに取りはずしたり交換できます。システムの通常動作を維持するには、常に最低 1 枚の CSC が取り付けられており、動作している必要があります。2 枚目の CSC によって、データ パス、スケジューラ、および基準クロックに冗長性が提供されます。ラインカードとスイッチ ファブリックとの間のインターフェイスは、常に監視されています。Loss of Synchronization(LoS; 同期損失)が検出されると、冗長 CSC のデータ パスが自動的にアクティブになり、冗長パスを通してデータが送信されます。冗長CSCへの切り替えは通常、秒数の順序(実際の切り替え時間は設定とその規模によって異なります)で行われます。この間、一部またはすべてのLCでデータが失われる可能性があります。
スイッチ ファブリック カード(SFC)
Cisco 12008、12012、および 12016 では、3 枚の SFC のセットをオプションでルータに取り付け、ルータのスイッチ ファブリックキャパシティを増加させることができます。この構成はフル帯域幅と呼ばれます。SFC カードによって、ルータのデータ処理キャパシティが増加します。1 枚の SFC またはすべての SFC は、システム動作を中断したりルータの電源をオフにせずに、取りはずしたり交換できます。いずれかの SFC が動作していない期間は、ルータのデータ処理およびスイッチング機能のための潜在的なデータ パスとしての、SFC のルータへのデータ伝送キャパシティが失われます。
冗長性および帯域幅
Switch Fabric Card(SFC; スイッチ ファブリック カード)および Clock Scheduler Card(CSC; クロック スケジューラ カード)によって、システムの物理スイッチ ファブリックが構成され、ラインカードとルート プロセッサの間でデータや制御パケットを伝送するシスコ セルのクロッキングが提供されます。
12008、12012、および12016では、ルータを実行するために少なくとも1つのCSCカードが必要です。1枚のCSCカードのみでSFCカードが存在しない場合は、四半期の帯域幅と呼ばれ、エンジン0のラインカードでのみ動作します。他のラインカードがシステム内にある場合、自動的にシャットダウンされます。エンジン0以外のラインカードが必要な場合は、ルータに全帯域幅(3つのSFCと1つのCSC)をインストールする必要があります。冗長性が必要な場合は、2枚目のCSCが必要です。この冗長 CSC は、CSC または SFC のいずれかに障害が発生した場合にだけ動作します。冗長 CSC は、CSC または SFC として動作可能です。
12416、12406、12410、および 12404 では、フル帯域幅が必要です。
次に、スイッチ ファブリックの冗長性および帯域幅についてのその他の重要事項を示します。
-
すべての 12000 シリーズ ルータには、最大 3 枚の SFC と 2 枚の CSC が取り付けられています。ただし、12410 シリーズには 5 枚の専用 SFC と 2 枚の専用 CSC が取り付けられており、12404 にはすべての CSC/SFC 機能を内蔵したボードが 1 枚取り付けられています。12404 の場合、冗長性がありません。
-
12008、12012、12016、12406、および 12416 では、CSC カードはスイッチ ファブリック カードとしても機能します。これは、フル帯域幅の冗長構成を実現するには 3 枚の SFC と 2 枚の CSC だけが必要となるためです。12410 には、専用クロック スケジューラ カード、スイッチ ファブリック カードがあります。フル帯域幅の冗長構成を実現するには、2 枚の CSC と 5 枚の SFC が必要となります。
-
シャーシにエンジン 0 の LC 以外何もない場合、1/4 帯域幅構成は 12008、12012、12016 でしか使用できません。12400 シリーズ シャーシで使用される CSC192 および SFC192 では、1/4 帯域幅構成はサポートされていません。
次に、各プラットフォームのためのスイッチ ファブリックに関するリンクを示します。
Cisco 12008 インターネット ルータ
CSCは上部のカードケージに取り付けられ、SFCはエアーフィルタアセンブリのすぐ後ろにある下部のカードケージに取り付けられます(図1-22を参照)。Product Overview Documentationの下のLower Card Cageのコンポーネント)。
詳細は次の文書で参照してください。
Cisco 12012 インターネット ルータ
CSC および SFC の両方とも 5 スロット下段カード ケージに取り付けられています。「前面図」および「下段カード ケージ」を参照してください。
詳細は次の文書で参照してください。
Cisco 12016/12416 インターネット ルータ
現在、Cisco 12016 では、次の 2 つのスイッチ ファブリックを選択できます。
-
2.5 Gbps スイッチ ファブリック(80 Gbps スイッチング システム帯域幅):GSR16/80-CSC と GSR16/80-SFC のファブリックの組み合せで構成されます。SFC または CSC の各カードによって、システム内の各ラインカードに 2.5 Gbps の全二重接続が可能になります。16 枚のラインカードを持つ Cisco 12016 で、各ラインカードのキャパシティを 2 x 2.5 Gbps(全二重)にした場合、システム スイッチング帯域幅は 16 x 5 Gbps = 80 Gbps となります(以前のスイッチ ファブリックを 80-Gbps スイッチ ファブリックと呼ぶこともあります)。
-
10 Gbpsスイッチファブリック(320 Gbpsスイッチングシステム帯域幅):GSR16/320-CSCとGSR16/320-SFCファブリックセットで構成されます。SFC または CSC の各カードによって、システム内の各ラインカードに 10 Gbps の全二重接続が可能になります。16枚のラインカードを搭載したCisco 12016で、それぞれが2 x 10 Gbpsのキャパシティ(全二重)を備えている場合、システムスイッチング帯域幅は16 x 20 Gbps = 320 Gbpsです。(新しいスイッチ ファブリックを 320-Gbps スイッチ ファブリックと呼ぶこともあります)。
Cisco 12016 ルータに 320 Gbps スイッチング ファブリックが使用されている場合、Cisco 12416 インターネット ルータと呼ばれます。
CSC および SFC は、5 スロット スイッチ ファブリック カード ケージに取り付けられています。
詳細は次の文書で参照してください。
Cisco 12404 インターネット ルータ
Cisco 12404 には Consolidated Switch Fabric(CSF; 統合スイッチ ファブリック)というボードが 1 枚取り付けられているため、ラインカードおよび RP の同期の取れた速度での相互接続が可能です。CSF 回路はクロック スケジューラとスイッチ ファブリック機能で構成されており、1 枚のカードに収められています。CSF カードは、Cisco 12404 インターネット ルータ シャーシ内の、FABRIC ALARM とラベル付けされた下部スロットに収容されています。
詳細は次の文書で参照してください。
Cisco 12410 インターネット ルータ
Cisco 12410 のスイッチ ファブリックは、スイッチ ファブリックおよびアラーム カード ケージに取り付けられている、2 枚の Clock and Scheduler Card(CSC; クロック スケジューラ カード)および 5 枚の Switch Fabric Card(SFC; スイッチ ファブリック カード)で構成されています。アクティブなスイッチファブリックには1つのCSCと4つのSFCが必要です。2枚目のCSCと5枚目のSFCは冗長性を提供します。スイッチ ファブリックおよびアラーム カード ケージの 2 枚のアラーム カードは、スイッチ ファブリックの一部ではありません。
Cisco 12000 シリーズの他のシステムとは異なり、Cisco 12410 では最新の 10 Gbps スイッチ ファブリックだけをサポートしています。SFC または CSC の各カードによって、システム内の各ラインカードに 10 Gbps の全二重接続が可能になります。このため、10 枚のラインカードを持つ Cisco 12410 で、各ラインカードのキャパシティを 2 x 10 Gbps(全二重)にした場合、システム スイッチング帯域幅は 10 x 20 Gbps = 200 Gbps となります。
詳細は次の文書で参照してください。
Cisco 12416 インターネット ルータ
『Cisco 12016』インターネット ルータを参照してください。
スイッチ ファブリック カードのためのトラブルシューティングのヒント
12016 および 12416 のスイッチ ファブリック カードは装着しにくいので、少し力を入れて装着しなければならない場合があります。正しく挿入されていない CSC があると、次のようなエラーメッセージが表示されます。
%MBUS-0-NOCSC: Must have at least 1 CSC card in slot 16 or 17 %MBUS-0-FABINIT: Failed to initialize switch fabric infrastructure
1/4 帯域幅構成に必要なだけの CSC および SFC しか挿入されていない場合も、このようなエラーメッセージが表示されることがあります。この場合、E1 以上の LC はブートしません。
カードが正しく取り付けられているかどうかを確認する確実な方法の1つは、CSC/SFCで4つのライトが「オン」になっていることです(図4を参照)。 そうでない場合、そのカードは正しく装着されていません。
ファブリックおよび LC がブートしない問題に対処する場合、必要な CSC および SFC がすべて正しく挿入され、電源がオンになっているかどうかを確認する必要があります。たとえば、12016 でフル帯域幅の冗長システムを構成するには、3つの SFC および2つの CSC が必要です。フル帯域幅の非冗長システムを実現するには、3 枚の SFC と 1 枚の CSC が必要です。
show version コマンドおよび show controller fia コマンドの出力から、現在ボックス内で動作しているハードウェア構成を確認できます。
Thunder#show version Cisco Internetwork Operating System Software IOS (tm) GS Software (GSR-P-M), Experimental Version 12.0(20010505:112551) [tmcclure-15S2plus-FT 118] Copyright (c) 1986-2001 by cisco Systems, Inc. Compiled Mon 14-May-01 19:25 by tmcclure Image text-base: 0x60010950, data-base: 0x61BE6000 ROM: System Bootstrap, Version 11.2(17)GS2, [htseng 180] EARLY DEPLOYMENT RELEASE SOFTWARE (fc1) BOOTFLASH: GS Software (GSR-BOOT-M), Version 12.0(15.6)S, EARLY DEPLOYMENT MAINTENANCE INTERIM SOFTWARE Thunder uptime is 17 hours, 53 minutes System returned to ROM by reload at 23:59:40 MET Mon Jul 2 2001 System restarted at 00:01:30 MET Tue Jul 3 2001 System image file is "tftp://172.17.247.195/gsr-p-mz.15S2plus-FT-14-May-2001" cisco 12012/GRP (R5000) processor (revision 0x01) with 262144K bytes of memory. R5000 CPU at 200Mhz, Implementation 35, Rev 2.1, 512KB L2 Cache Last reset from power-on 2 Route Processor Cards 1 Clock Scheduler Card 3 Switch Fabric Cards 1 8-port OC3 POS controller (8 POs). 1 OC12 POs controller (1 POs). 1 OC48 POs E.D. controller (1 POs). 7 OC48 POs controllers (7 POs). 1 Ethernet/IEEE 802.3 interface(s) 17 Packet over SONET network interface(s) 507K bytes of non-volatile configuration memory. 20480K bytes of Flash PCMCIA card at slot 0 (Sector size 128K). 8192K bytes of Flash internal SIMM (Sector size 256K). Thunder#show controller fia Fabric configuration: Full bandwidth nonredundant Master Scheduler: Slot 17
詳細は、『show controller fia コマンドの出力の読み方』を参照することをお勧めします。
スイッチ ファブリックの設計
Cisco 12000 スイッチ ファブリックの設計では革新的な方法が採用されているため、非常に効率的なシステムを構築できます。スイッチ ファブリックは、非常に効率的なキャリア クラスとスケーラブルな設計を実現するために、次の主要なコンポーネントを使用しています。
-
行頭ブロッキングをなくすためのラインカードごとの仮想出力キュー
-
ファブリック効率を高めるための、従来のラウンドロビン方式に代わる効率的なスケジューリング アルゴリズム
-
マルチキャストトラフィックのハードウェアベースのレプリケーションマルチキャスト トラフィック用に非常に効率的なプラットフォームの提供を部分的に実現する。
-
スイッチ ファブリックのパフォーマンスを改善するためのパイプライニング
仮想出力キュー
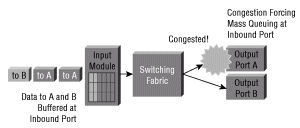
Head of Line Blocking(HoLB; 行頭ブロッキング)とは、出力ポートに輻輳が存在するシステムで発生する問題のことです(次の図を参照)。 HoLB は、複数の送信先宛ての複数のパケットがすべて 1 つのキューを共有する場合に発生します。特定の場所宛てのパケットは、その前のパケットがすべて処理されるまで待機してから、スイッチ ファブリックを通して渡される必要があります。たとえば、いくつかの複数車線の道路が 1 本の 1 車線の道路に合流する場合を考えてください。この問題を解決する最善の方法は、いくつかの複数車線の道路が合流する 1 本の道路を複数車線にすることです。
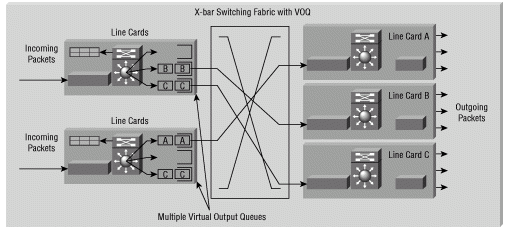
Cisco 12000 シリーズ インターネット ルータは、行頭ブロッキングをなくすために、固有のマルチキュー実装を採用しています。パケットがラインカードに着信すると、スロット、ポート、Class of Service(CoS; サービス クラス)ごとに分類された複数の出力キューのいずれかに入れられます。 これらのキューは Virtual Output Queue(VOQ; 仮想出力キュー)と呼ばれます。
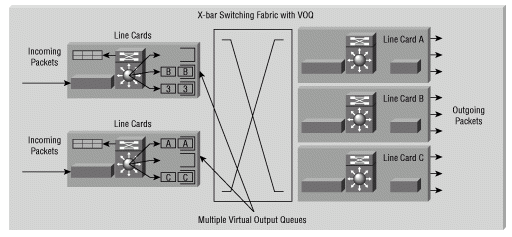
上の図では、仮想出力キュー(A)はラインカード A を表し、仮想出力キュー(VOQ)B はラインカード B を表しています。各パケットはソートされ、適切な VOQ に入れられます。パケットは、Cisco Express Forwarding(CEF)テーブルに含まれる転送情報に基づいてソートされ、VOQ に入れられます。
次の図は、VOQ が HoLB 問題を回避する方法を示します。図に示すように、パケットの配置によって HoLB 問題が最小限に抑えられます。一連のパケットが1つのラインカードに送信されている場合でも、異なるVOQ内の他のパケットはスイッチングファブリック経由で送信され、従来のHoLBの問題を回避できます。
スケジューリング
SFC/CSC には、スケジューリング アルゴリズムが組み込まれています。シスコシステムズとスタンフォード大学で共同開発されたスケジュール アルゴリズムでは、Cisco 12008 と Cisco 12012 の場合には最大 13 の入力要求(12 のスロットと 1 つのマルチキャスト)、Cisco 12016 の場合には最大 17 個の入力要求(16 のスロットと 1 つのマルチキャスト)を受信できます。 すべての要求は、特定のクロック インターバルに完了します。このアルゴリズムでは、このインターバルで使用可能な最良の入出力の組み合せを計算します。この高速アルゴリズムと VOQ の進歩によって、スイッチング ファブリックで高レベルのスイッチング効率を達成できます。つまり、スイッチング ファブリックのスループットは、ファブリックの以前の設計で達成できた理論上の最高値が 53 % であったのに対し、最大で 99 % に達することができます(スタンフォード大学での調査に基づいたデータ)。
マルチキャスト サポート
スイッチング ファブリックは、IP マルチキャストを使用する次世代のアプリケーションも視野に入れた設計になっています。スイッチング ファブリックは、次のような改良によって、IP マルチキャストに関する従来の問題点を解消しています。
-
IP パケットの分散ベースでの複製を実行(ファブリックおよびラインカード)する特別なハードウェアを使用します。
-
ユニキャスト トラフィックへの影響を回避するために、マルチキャスト トラフィック用に専用のキュー(VOQ)を用意しています。
-
部分的マルチキャスト セグメントの作成を可能にします。
インターフェイスは、スイッチ ファブリックに対してマルチキャスト要求およびユニキャスト要求の両方を送信できます。マルチキャスト要求を送信する場合、データのすべての送信先と要求の優先順位が指定されます。CSC ではマルチキャストとユニキャストが一緒に要求されますが、ユニキャストまたはマルチキャストに関係なく優先順位の最も高い要求が優先されます。
マルチキャスト要求を受信すると、要求がクロックスケジューラカードに送信されます。CSCから認可を受信すると、パケットはスイッチファブリックに転送されます。スイッチ ファブリックはパケットのコピーを作成し、(1 つのセル クロック サイクルの間)すべての送信先のラインカードに同時にコピーを送信します。 各受信ラインカードは、複数のポートへの送信が必要な場合、パケットのコピーを作成します。
ブロッキングをなくすために、スイッチング ファブリックはマルチキャスト送信のための部分割り当てをサポートしています。これにより、スイッチング ファブリックは使用可能なすべてのカードに対してマルチキャスト処理を実行できます。送信先カードが別の送信元からのパケットを受信している場合、マルチキャスト処理は、次の割り当てサイクル時に続行されます。
これらの新しい拡張機能により、第 1 世代のクロスバー スイッチング ファブリックでは避けられなかった帯域幅浪費の障害が回避され、信頼性をなくさずにスイッチング ファブリックの高レベルのスイッチング効率を達成することが可能です。
パイプライニング
スイッチング ファブリックは、全二重処理をサポートするため、高度なパイプライニング技術が導入されています。パイプライニングによって、スイッチ ファブリックは、前のサイクルのデータ送信が完了する前に、将来のサイクルのためのスイッチ リソースの割り当てを開始できます。パイプライニングでは、デッド タイム(無駄なクロック サイクル)を削減することにより、スイッチ ファブリック全体の効率を大幅に改善します。パイプライニングによってスイッチング ファブリックのパフォーマンスが改善し、理論上最高のスループットを達成できます。
Cisco セル
クロスバースイッチファブリック全体の転送の単位は、常に固定サイズのパケットです。これはシスコのセルとも呼ばれ、可変サイズのパケットよりもスケジュールが容易です。パケットはファブリックに配置される前にセルに分割され、送信LCによって送信前に再構成されます。シスコ セルのサイズは 64 バイトであり、そのうちの 8 バイトはヘッダー、48 バイトはペイロード、および 8 バイトは Cyclic Redundancy Check(CRC; 巡回冗長検査)です。
関連情報
- Cisco 12000 シリーズ インターネット ルータのアーキテクチャ - シャーシ
- Cisco 12000 シリーズ インターネット ルータのアーキテクチャ:ルート プロセッサ
- Cisco 12000 シリーズ インターネット ルータのアーキテクチャ:ライン カードの設計
- Cisco 12000 シリーズ インターネット ルータのアーキテクチャ:メモリの詳細
- Cisco 12000 シリーズ インターネット ルータのアーキテクチャ:メンテナンス バス、電源とブロアー、およびアラーム カード
- Cisco 12000 シリーズ インターネット ルータのアーキテクチャ:ソフトウェアの概要
- Cisco 12000 シリーズ インターネット ルータのアーキテクチャ - パケット スイッチング
- Cisco Express Forwarding について
- show controller fia コマンド出力の解釈方法
- テクニカルサポート - Cisco Systems
 フィードバック
フィードバック