Introduzione
In questo documento vengono descritti importanti comandi per verificare la replica del database di Cisco Unified Communications Manager (CUCM) e gli output previsti.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
- Cisco Unified Communications Manager
Componenti usati
Le informazioni fornite in questo documento si basano sulle seguenti versioni software:
- Cisco Unified Communications Manager versione 10.5.2.1590-8
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Il database in CUCM è una topologia a maglia completa, il che significa che l'autore e ogni sottoscrittore si connettono in modo logico a ogni server del cluster e tutti hanno la capacità di aggiornare i dati tra loro.
Per verificare lo stato del database in CUCM, è necessario concedere l'accesso dall'interfaccia della riga di comando (CLI) in ognuno dei nodi del cluster. Se è disponibile un'interfaccia utente grafica (GUI), è necessario generare un report sullo stato del database.
Per generare un report sullo stato del database di Unified CM, selezionare Cisco Unified Reporting > System Reports > Unified CM Database Status (Report di sistema > Stato database di Unified CM). Selezionare Genera un nuovo report.
Verifica connettività
Per la replica del database, è necessario stabilire correttamente la connettività tra i server in ognuno dei nodi coinvolti nel cluster. Questi comandi consentono di conoscere lo stato di ciascuno di essi.
mostra cluster di rete
Utilizzare il comando show network cluster per verificare che i nodi siano autenticati tra loro. L'output del server di pubblicazione contiene voci della tabella processnode. Tuttavia, è necessario autenticare tutti i nodi (assicurarsi che la password di protezione sia la stessa su tutti i nodi).
Autore:
admin:show network cluster
10.1.89.30 CUCMv10SUB.alegarc2.lab CUCMv10SUB Subscriber callmanager DBSub authenticated using TCP since Mon Jul 1 13:44:09 2019
10.1.89.20 CUCM10.alegarc2.lab CUCM10 Publisher callmanager DBPub authenticated
Server Table (processnode) Entries
----------------------------------
10.1.89.20
10.1.89.30
Iscritto:
admin:show network cluster
10.1.89.30 CUCMv10SUB.alegarc2.lab CUCMv10SUB Subscriber callmanager DBSub authenticated
10.1.89.20 CUCM10.alegarc2.lab CUCM10 Publisher callmanager DBPub authenticated using TCP since Mon Jul 1 13:44:19 2019
esegui sql select * da processnode
La tabella Processnode deve elencare tutti i nodi nel cluster.
admin:run sql select * from processnode
pkid name mac systemnode description isactive nodeid tknodeusage ipv6name fklbmhubgroup tkprocessnoderole tkssomode
==================================== ================== === ========== =========== ======== ====== =========== ======== ============= ================= =========
00000000-1111-0000-0000-000000000000 EnterpriseWideData t t 1 1 NULL 1 0
68b56caa-d320-4c94-9c5a-43c3ba6cb4b8 10.1.89.20 f 10.1.89.20 t 2 0 NULL 1 0
a6a92a62-8e66-cdfc-80fa-56a688d3dd58 10.1.89.30 f t 3 1 NULL 1 0
utilizza la connettività di rete <IP/hostname>
Il server di pubblicazione deve essere in grado di raggiungere tutti i sottoscrittori e il risultato della connettività di rete deve essere completato correttamente.
admin:utils network connectivity 10.1.89.30
This command can take up to 3 minutes to complete.
Continue (y/n)?y
Running test, please wait ...
......
Network connectivity test with 10.1.89.30 completed successfully.
Ogni sottoscrittore deve raggiungere il server di pubblicazione e gli altri sottoscrittori inclusi nel risultato della connettività di rete del cluster devono essere completati correttamente.
admin:utils network connectivity 10.1.89.20
This command can take up to 3 minutes to complete.
Continue (y/n)?y
Running test, please wait ...
.
Network connectivity test with 10.1.89.20 completed successfully.
Dal report stato database di Unified CM, la connettività deve essere visualizzata come 1=riuscita per ogni nodo, come mostrato nell'immagine.

utils diagnose test
Controlla tutti i componenti e restituisce il valore passato/non riuscito. I componenti più importanti per la funzionalità di replica del database sono validate_network, ntp_reachability e ntp_stratum.
admin:utils diagnose test
Log file: platform/log/diag1.log
Starting diagnostic test(s)
===========================
test - disk_space : Passed (available: 1753 MB, used: 12413 MB)
skip - disk_files : This module must be run directly and off hours
test - service_manager : Passed
test - tomcat : Passed
test - tomcat_deadlocks : Passed
test - tomcat_keystore : Passed
test - tomcat_connectors : Passed
test - tomcat_threads : Passed
test - tomcat_memory : Passed
test - tomcat_sessions : Passed
skip - tomcat_heapdump : This module must be run directly and off hours
test - validate_network : Passed
test - raid : Passed
test - system_info : Passed (Collected system information in diagnostic log)
test - ntp_reachability : Passed
test - ntp_clock_drift : Passed
test - ntp_stratum : Passed
skip - sdl_fragmentation : This module must be run directly and off hours
skip - sdi_fragmentation : This module must be run directly and off hours
Diagnostics Completed
The final output will be in Log file: platform/log/diag1.log
Please use 'file view activelog platform/log/diag1.log' command to see the output
stato ntp utils
Cisco consiglia di configurare un server Network Time Protocol (NTP) con Stratum-1, Stratum-2 o Stratum-3 nell'editore CUCM in modo da assicurare che l'ora del cluster sia sincronizzata con un'origine dell'ora esterna.
admin:utils ntp status
ntpd (pid 8609) is running...
remote refid st t when poll reach delay offset jitter
==============================================================================
*10.1.89.1 LOCAL(1) 2 u 935 1024 377 0.262 2.591 3.260
synchronised to NTP server (10.1.89.1) at stratum 3
time correct to within 32 ms
polling server every 1024 s
Current time in UTC is : Wed Jul 3 12:40:36 UTC 2019
Current time in America/Mexico_City is : Wed Jul 3 07:40:36 CDT 2019
Il protocollo NTP per i sottoscrittori è un server di pubblicazione e deve essere visibile come sincronizzato.
admin:utils ntp status
ntpd (pid 30854) is running...
remote refid st t when poll reach delay offset jitter
==============================================================================
*10.1.89.20 10.1.89.1 3 u 179 1024 377 0.524 -1.793 1.739
synchronized to NTP server (10.1.89.20) at stratum 4
time correct to within 50 ms
polling server every 1024 s
Current time in UTC is : Wed Jul 3 12:41:46 UTC 2019
Current time in America/Mexico_City is : Wed Jul 3 07:41:46 CDT 2019
Verifica dei servizi
I servizi CUCM coinvolti per la replica del database sono Cluster Manager, A Cisco DB e Cisco Database Layer Monitor.
utils service list
Il comando utilizza l'elenco dei servizi visualizza i servizi e il relativo stato nel nodo CUCM. Questi servizi devono essere visualizzati come STARTED.
- Gestione cluster [AVVIATO]
- UN DATABASE Cisco [AVVIATO]
- A Cisco DB Replicator [AVVIATO]
- Cisco Database Layer Monitor [AVVIATO]
Comandi del database
I comandi di replica del database devono essere eseguiti dal server di pubblicazione.
utilizza lo stato di duplicazione
Questo comando attiva solo il controllo dello stato del database. Per verificarne lo stato di avanzamento, utilizzare il comando utils duplication runtimestate.
admin:utils dbreplication status
Replication status check is now running in background.
Use command 'utils dbreplication runtimestate' to check its progress
The final output will be in file cm/trace/dbl/sdi/ReplicationStatus.2019_07_03_07_54_21.out
Please use "file view activelog cm/trace/dbl/sdi/ReplicationStatus.2019_07_03_07_54_21.out " command to see the output
utilizza proprietà runtime di replica
Il comando Runtimestate mostra lo stato del database in modo da poter visualizzare diverse impostazioni di replica per i nodi mentre è in corso. Dopo aver completato il comando, è possibile verificare gli output e verificare lo stato corrente del database.
admin:utils dbreplication runtimestate
Server Time: Wed Jul 3 09:11:03 CDT 2019
Cluster Replication State: Replication status command started at: 2019-07-03-07-54
Replication status command COMPLETED 681 tables checked out of 681
Last Completed Table: devicenumplanmapremdestmap
No Errors or Mismatches found.
Use 'file view activelog cm/trace/dbl/sdi/ReplicationStatus.2019_07_03_07_54_21.out' to see the details
DB Version: ccm10_5_2_15900_8
Repltimeout set to: 300s
PROCESS option set to: 1
Cluster Detailed View from CUCM10 (2 Servers):
PING DB/RPC/ REPL. Replication REPLICATION SETUP
SERVER-NAME IP ADDRESS (msec) DbMon? QUEUE Group ID (RTMT) & Details
----------- ---------- ------ ------- ----- ----------- ------------------
CUCM10 10.1.89.20 0.013 Y/Y/Y 0 (g_2) (2) Setup Completed
CUCMv10SUB 10.1.89.30 0.230 Y/Y/Y 0 (g_3) (2) Setup Completed
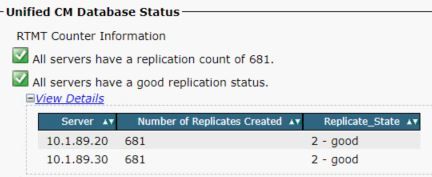
Lo stato del database è visibile dal report stato database di Gestione certificati unificata, come mostrato nell'immagine.
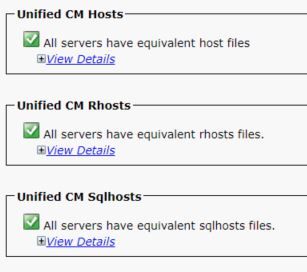
File Hosts/Rhosts/Sqlhosts
Al database sono associati tre file importanti che devono essere gli stessi in ognuno dei nodi interessati. Per verificarle dalla CLI, è necessario l'accesso alla directory principale. Tuttavia, anche il report sullo stato del database di Unified CM visualizza queste informazioni, come mostrato nell'immagine.
File di registro di Cronologia sistema
La replica del database può essere danneggiata a causa di arresti anomali e può essere visualizzata nel registro System-history.
Esempio di arresto anomalo:
09/13/2019 15:29:01 | root: Boot 10.5.2.15900-8 Start
09/13/2019 16:55:24 | root: Boot 10.5.2.15900-8 Start
Esempio di spegnimento regolare:
09/03/2019 14:51:51 | root: Restart 10.5.2.15900-8 Start
09/03/2019 14:52:27 | root: Boot 10.5.2.15900-8 Start
La ricostruzione del server è consigliata quando il sistema è stato arrestato in modo anomalo ed è documentata nell'ID bug Cisco CSCth53322
Verifica
Se durante la convalida di questi parametri vengono visualizzati errori, si consiglia di contattare il Technical Assistance Center (TAC) di Cisco e fornire le informazioni raccolte da ogni nodo del cluster per ulteriore assistenza.
Informazioni correlate
 Feedback
Feedback