Introduzione
In questo documento vengono descritti i diversi tipi di errori del disco, le relative modalità di classificazione e gli strumenti che è possibile utilizzare per identificarli.
Prerequisiti
Requisiti
Nessun requisito specifico previsto per questo documento.
Componenti usati
Le informazioni fornite in questo documento si basano sui dischi rigidi di Unified Computing System (UCS).
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Il documento descrive inoltre il ruolo del controller del disco rigido (HDD) e del controller RAID (Redundant Array of Independent Disks) quando vengono identificati gli errori medi presenti sulle unità.
Nota: gli errori medi vengono anche definiti errori dei supporti
Gestione degli errori dei supporti HDD
Cosa causa gli errori del supporto HDD?
La causa più comune degli errori medi è la scarsa ampiezza del segnale, che determina
- Percorso di lettura LBA (Logical Bus Address) non affidabile. A volte recuperabili con più tentativi.
- Condizioni transitorie, scritture ad alta velocità causate da particelle morbide.
- Condizioni transitorie causate da urti temporanei, vibrazioni o eventi acustici che determinano scritture fuori traccia.
- Funzione di mappatura degli errori insufficiente nella produzione del disco rigido che determina l'imbottitura delle posizioni dei difetti principali correnti.
In che modo il disco rigido rileva l'errore medio?
Passaggio 1. Il disco rigido esegue periodicamente scansioni dei supporti in background per rilevare gli errori.
Passaggio 2. Il disco rigido tenta di leggere dal supporto e per qualche motivo non è in grado di recuperare i dati scritti.
Passaggio 3. Quando il disco rigido non è in grado di recuperare i dati che sono stati scritti, richiama il codice di recupero del disco rigido che proverà vari passaggi di recupero dell'errore per leggere correttamente i dati dal supporto.
Passaggio 4. Se tutte le operazioni di ripristino hanno esito negativo, l'unità genererà un errore 03/11/0x all'host e gli LBA verranno inseriti nell'elenco dei difetti in sospeso.
In che modo il controller Raid rileva gli errori medi?
- Il controller RAID incontra errori medi durante le operazioni di lettura di controllo, verifica della coerenza, lettura normale, ricostruzione e lettura/modifica/scrittura.
- In base alla configurazione RAID, il controller potrebbe essere in grado di gestire l'errore medio riportato dall'HDD e non sarà necessario eseguire altre operazioni.
- In alcuni casi, il controller non sarà in grado di gestire l'errore del supporto e passerà l'errore all'host per gestirlo.
Quando il sistema operativo visualizza gli errori medi?
- Se il disco rigido segnala un errore medio e il controller RAID non è in grado di gestire il ripristino, l'host verrà informato dell'errore.
- Questa notifica non è più solo un messaggio informativo che informa il sistema che l'evento si è verificato, ma è una richiesta per il sistema operativo di agire perché l'HDD e il controller RAID non è stato in grado di recuperare dall'errore del supporto.
- Se il sistema operativo dispone del contesto richiesto per risolvere correttamente l'errore del supporto, deve gestirlo
- Se i dischi si trovano in un solo gruppo di dischi (JBOD), il sistema operativo visualizzerà gli errori in quanto non vengono corretti dal controller. Ciò è comune negli ambienti HyperFlex (HX)/ Virtual Storage Area Network (VSAN).
Ruolo HDD
Livello dischi rigidi difetti (G-list)
Durante il funzionamento di un'unità, la testa potrebbe trovarsi in un settore con un livello di lettura magnetica ridotto. I dati sono ancora leggibili, ma potrebbero scendere al di sotto della soglia preferita per i livelli di lettura qualificati del settore. Questa unità disco considererebbe questo un settore che potrebbe e vorrebbe risparmiare questi dati in una nuova posizione disponibile nell'elenco di riserve valide note. Una volta spostati i dati, l'indirizzo del settore precedente viene aggiunto all'elenco Difetti estesi, per non essere più utilizzato. Questo processo è un errore del supporto recuperabile. L'unità darà un impulso SMART una volta che la maggior parte dei suoi settori di riserva noti-validi saranno esauriti.
Ruolo controller RAID
Patrol Read
- Patrol Read è un'opzione definibile dall'utente che esegue letture delle unità in background e mappa le aree danneggiate dell'unità.
- Patrol Read verifica la presenza di errori fisici del disco che potrebbero causare guasti all'unità. Tali controlli comprendono in genere un tentativo di azione correttiva. La lettura di controllo può essere attivata o disattivata con l'attivazione automatica o manuale.
- Una lettura di controllo verifica periodicamente tutti i settori dei dischi fisici collegati a un controller, che includono l'area riservata del sistema nelle unità configurate RAID. Patrol Read funziona per tutti i livelli RAID e tutte le unità hot spare.
- Questo processo viene avviato solo quando il controller RAID rimane inattivo per un determinato periodo di tempo e non sono attive altre attività in background, sebbene possa continuare a essere eseguito contemporaneamente ai processi di input/output (I/O) pesanti.
- Non è possibile eseguire letture di controllo sulle unità configurate in JBOD.
Nota:l'LSI (Latent Semantic Indexing) consiglia di lasciare la frequenza di lettura di pattuglia e le altre impostazioni di lettura di pattuglia sui valori predefiniti per ottenere le migliori prestazioni del sistema. Se si decide di modificare i valori, registrare qui il valore predefinito originale in modo da poterlo ripristinare in seguito.
Nota: durante l'esecuzione di Patrol Read non viene segnalato lo stato di avanzamento. Lo stato di lettura della pattuglia è riportato solo nel registro eventi.
Le opzioni di lettura della pattuglia sono come mostrato nell'immagine:
 Esempi di MegaCli
Esempi di MegaCli
Per visualizzare le informazioni sullo stato di lettura della pattuglia e il ritardo tra le esecuzioni di lettura della pattuglia:
# MegaCli64 -AdpPR -Info -aALL
Per conoscere la frequenza di lettura corrente delle pattuglie, eseguire:
# MegaCli64 -AdpGetProp FrequenzaLetturaControllo -aALL
Per disabilitare la lettura automatica della pattuglia:
# MegaCli64 -AdpPR -Dsbl -aALL
Per abilitare la lettura automatica delle pattuglie:
#MegaCli64 -AdpPR -EnblAuto -All
Per avviare un'analisi di lettura di pattuglia manuale:
# MegaCli64 -AdpPR -Start -All
Per interrompere una scansione di lettura di pattuglia:
# MegaCli64 -AdpPR -Stop -aALL
Verifica coerenza
- In RAID, il Consistency Check verifica la correttezza dei dati ridondanti in un array. Ad esempio, in un sistema con parità, verificare la coerenza significa calcolare la parità delle unità dati e confrontare i risultati con il contenuto dell'unità di parità.
- JBOD non supporta la verifica di coerenza.
- RAID 0 non supporta la verifica di coerenza.
- RAID 1 utilizza un confronto dei dati e non la parità.
- RAID 6 calcola la parità per 2 unità di parità e verifica entrambe.
Nota: si consiglia di eseguire una verifica coerenza almeno una volta al mese.
Le opzioni di gestione del controllo di coerenza sono indicate nell'immagine:
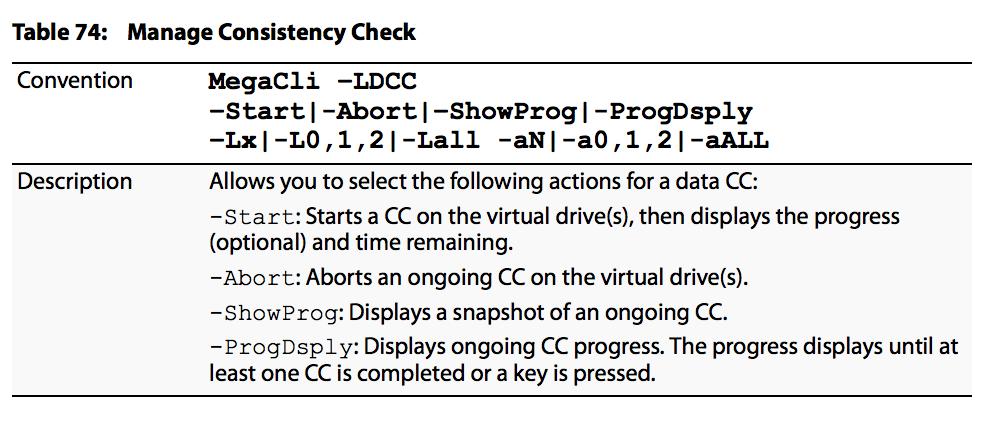
Le opzioni di pianificazione del controllo di coerenza sono indicate nell'immagine:

Esempi di MegaCli
Per visualizzare il successivo tempo di verifica coerenza pianificato:
#MegaCli64 -AdpCcSched -Info -aALL
Per modificare l'ora pianificata per il controllo di coerenza:
#MegaCli64 -AdpCCSched -SetSTartTime 20171028 02 -All
Per disabilitare la verifica di coerenza:
#MegaCli64 -AdpCcSched -Dsbl -aALL
Condizioni in cui un controller RAID non è in grado di correggere un errore medio
- In JBOD
- Il sistema operativo host è responsabile degli errori medi.
- In RAID 0
- Poiché non è presente alcuna ridondanza, il controller non è in grado di fornire all'HDD i dati da scrivere sull'LBA.
- In RAID 1
- Quando il controller non è in grado di determinare quale copia mirror contiene i dati corretti. Ciò si verifica solo se è possibile leggere entrambi gli LBA, ma i dati non corrispondono.
- RAID 5
- Se sono presenti 2 o più errori nello stesso stripe. È molto probabile che si verifichi dopo l'avvio della ricostruzione di una matrice. L'unità ricostruita è un errore, mentre un errore medio su qualsiasi altra unità ricostruita sarebbe il secondo errore. Il controller non è in grado di ricostruire i dati necessari per ricostruire l'LBA sull'unità sostitutiva.
- RAID 6
- Se nella stessa stripe sono presenti 3 o più errori. È molto probabile che si verifichi durante la ricostruzione di un array. L'unità ricostruita presenta un errore e un errore medio su due altre unità durante la ricostruzione indica un secondo e un terzo errore oppure un errore medio e un secondo errore dell'unità. Il controller non sarebbe in grado di ricostruire i dati necessari per ricostruire gli LBA sulle unità con gli errori.
Informazioni correlate
 Feedback
Feedback