About Clustering on the Firepower 4100/9300 Chassis
The cluster consists of multiple devices acting as a single logical unit. When you deploy a cluster on the Firepower 4100/9300 chassis, it does the following:
-
Creates a cluster-control link (by default, port-channel 48) for unit-to-unit communication.
For intra-chassis clustering (Firepower 9300 only), this link utilizes the Firepower 9300 backplane for cluster communications.
For inter-chassis clustering, you need to manually assign physical interface(s) to this EtherChannel for communications between chassis.
-
Creates the cluster bootstrap configuration within the application.
When you deploy the cluster, the chassis supervisor pushes a minimal bootstrap configuration to each unit that includes the cluster name, cluster control link interface, and other cluster settings. Some parts of the bootstrap configuration may be user-configurable within the application if you want to customize your clustering environment.
-
Assigns data interfaces to the cluster as Spanned interfaces.
For intra-chassis clustering, spanned interfaces are not limited to EtherChannels, like it is for inter-chassis clustering.The Firepower 9300 supervisor uses EtherChannel technology internally to load-balance traffic to multiple modules on a shared interface, so any data interface type works for Spanned mode. For inter-chassis clustering, you must use Spanned EtherChannels for all data interfaces.

Note
Individual interfaces are not supported, with the exception of a management interface.
-
Assigns a management interface to all units in the cluster.
The following sections provide more detail about clustering concepts and implementation. See also Reference for Clustering.
Bootstrap Configuration
When you deploy the cluster, the Firepower 4100/9300 chassis supervisor pushes a minimal bootstrap configuration to each unit that includes the cluster name, cluster control link interface, and other cluster settings. Some parts of the bootstrap configuration are user-configurable if you want to customize your clustering environment.
Cluster Members
Cluster members work together to accomplish the sharing of the security policy and traffic flows.
One member of the cluster is the control unit. The control unit is determined automatically. All other members are data units.
You must perform all configuration on the control unit only; the configuration is then replicated to the data units.
Some features do not scale in a cluster, and the control unit handles all traffic for those features. See Centralized Features for Clustering.
Master and Slave Unit Roles
One member of the cluster is the master unit. The master unit is determined automatically. All other members are slave units.
You must perform all configuration on the master unit only; the configuration is then replicated to the slave units.
Some features do not scale in a cluster, and the master unit handles all traffic for those features. See Centralized Features for Clustering.
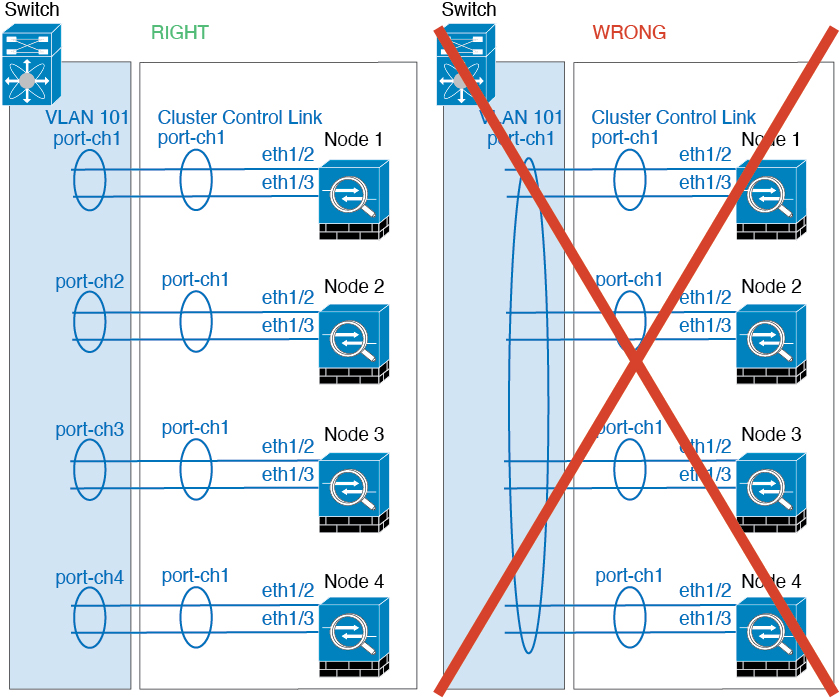
Cluster Control Link
The cluster-control link is an EtherChannel (port-channel 48) for unit-to-unit communication. For intra-chassis clustering, this link utilizes the Firepower 9300 backplane for cluster communications. For inter-chassis clustering, you need to manually assign physical interface(s) to this EtherChannel on the Firepower 4100/9300 chassis for communications between chassis.
For a 2-chassis inter-chassis cluster, do not directly-connect the cluster control link from one chassis to the other chassis. If you directly connect the interfaces, then when one unit fails, the cluster control link fails, and thus the remaining healthy unit fails. If you connect the cluster control link through a switch, then the cluster control link remains up for the healthy unit.
Cluster control link traffic includes both control and data traffic.
Control traffic includes:
-
Control unit election.
-
Configuration replication.
-
Health monitoring.
Data traffic includes:
-
State replication.
-
Connection ownership queries and data packet forwarding.
Size the Cluster Control Link
If possible, you should size the cluster control link to match the expected throughput of each chassis so the cluster-control link can handle the worst-case scenarios. For example, if you have the ASA 5585-X with SSP-60, which can pass 14 Gbps per unit maximum in a cluster, then you should also assign interfaces to the cluster control link that can pass at least 14 Gbps. In this case, you could use 2 Ten Gigabit Ethernet interfaces in an EtherChannel for the cluster control link, and use the rest of the interfaces as desired for data links.
Cluster control link traffic is comprised mainly of state update and forwarded packets. The amount of traffic at any given time on the cluster control link varies. The amount of forwarded traffic depends on the load-balancing efficacy or whether there is a lot of traffic for centralized features. For example:
-
NAT results in poor load balancing of connections, and the need to rebalance all returning traffic to the correct units.
-
AAA for network access is a centralized feature, so all traffic is forwarded to the control unit.
-
When membership changes, the cluster needs to rebalance a large number of connections, thus temporarily using a large amount of cluster control link bandwidth.
A higher-bandwidth cluster control link helps the cluster to converge faster when there are membership changes and prevents throughput bottlenecks.
Note |
If your cluster has large amounts of asymmetric (rebalanced) traffic, then you should increase the cluster control link size. |
Cluster Control Link Redundancy
We recommend using an EtherChannel for the cluster control link, so that you can pass traffic on multiple links in the EtherChannel while still achieving redundancy.
The following diagram shows how to use an EtherChannel as a cluster control link in a Virtual Switching System (VSS) or Virtual Port Channel (vPC) environment. All links in the EtherChannel are active. When the switch is part of a VSS or vPC, then you can connect ASA interfaces within the same EtherChannel to separate switches in the VSS or vPC. The switch interfaces are members of the same EtherChannel port-channel interface, because the separate switches act like a single switch. Note that this EtherChannel is device-local, not a Spanned EtherChannel.
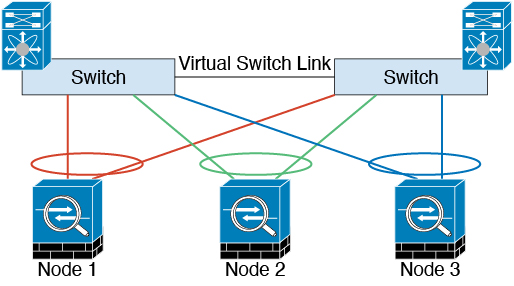
Cluster Control Link Reliability
To ensure cluster control link functionality, be sure the round-trip time (RTT) between units is less than 20 ms. This maximum latency enhances compatibility with cluster members installed at different geographical sites. To check your latency, perform a ping on the cluster control link between units.
The cluster control link must be reliable, with no out-of-order or dropped packets; for example, for inter-site deployment, you should use a dedicated link.
Cluster Control Link Network
The Firepower 4100/9300 chassis auto-generates the cluster control link interface IP address for each unit based on the chassis ID and slot ID: 127.2.chassis_id.slot_id. You cannot set this IP address manually, either in FXOS or within the application. The cluster control link network cannot include any routers between units; only Layer 2 switching is allowed. For inter-site traffic, Cisco recommends using Overlay Transport Virtualization (OTV).
Cluster Interfaces
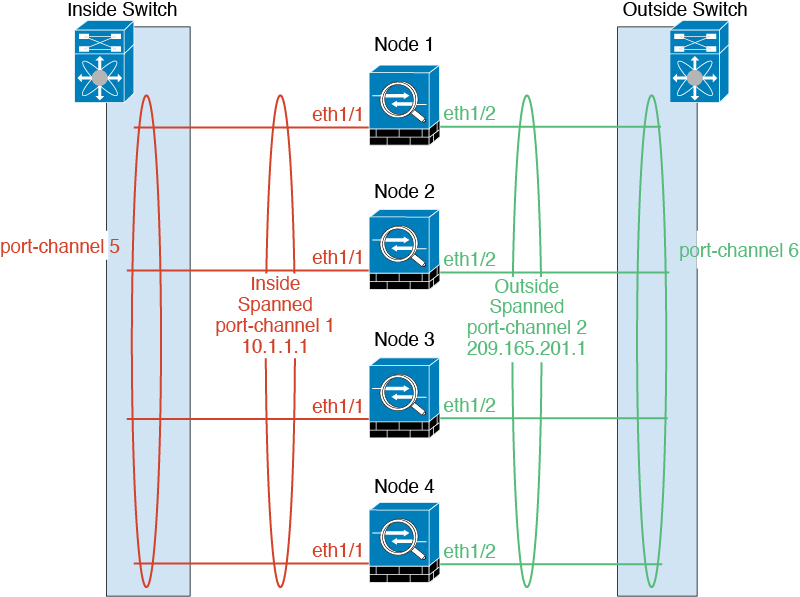
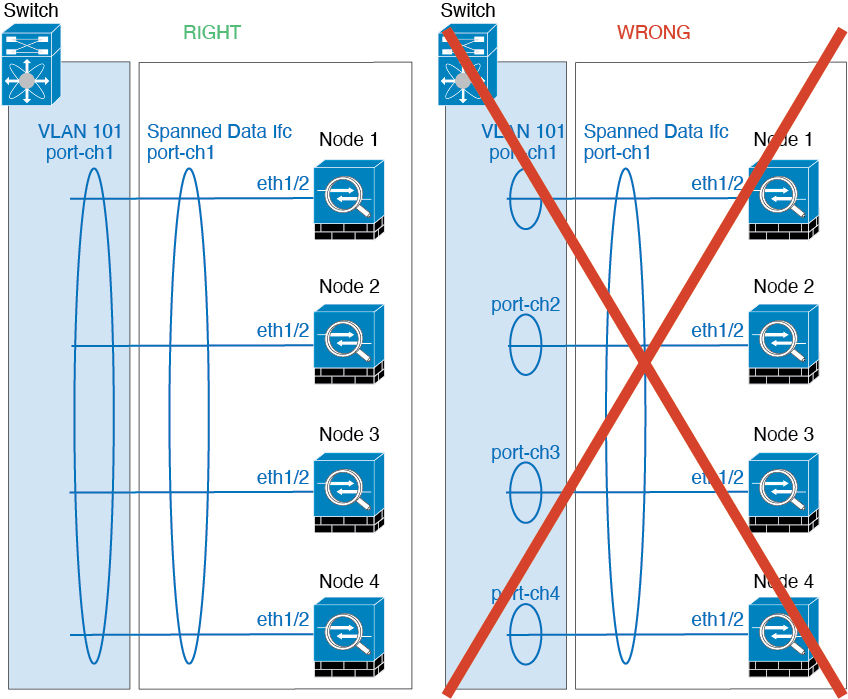
For intra-chassis clustering, you can assign both physical interfaces or EtherChannels (also known as port channels) to the cluster. Interfaces assigned to the cluster are Spanned interfaces that load-balance traffic across all members of the cluster.
For inter-chassis clustering, you can only assign data EtherChannels to the cluster. These Spanned EtherChannels include the same member interfaces on each chassis; on the upstream switch, all of these interfaces are included in a single EtherChannel, so the switch does not know that it is connected to multiple devices.
Individual interfaces are not supported, with the exception of a management interface.
Connecting to a VSS or vPC
We recommend connecting EtherChannels to a VSS or vPC to provide redundancy for your interfaces.
Configuration Replication
All units in the cluster share a single configuration. You can only make configuration changes on the control unit, and changes are automatically synced to all other units in the cluster.
ASA Cluster Management
One of the benefits of using ASA clustering is the ease of management. This section describes how to manage the cluster.
Management Network
We recommend connecting all units to a single management network. This network is separate from the cluster control link.
Management Interface
You must assign a Management type interface to the cluster. This interface is a special individual interface as opposed to a Spanned interface. The management interface lets you connect directly to each unit.
The Main cluster IP address is a fixed address for the cluster that always belongs to the current control unit. You also configure a range of addresses so that each unit, including the current control unit, can use a Local address from the range. The Main cluster IP address provides consistent management access to an address; when a control unit changes, the Main cluster IP address moves to the new control unit, so management of the cluster continues seamlessly.
For example, you can manage the cluster by connecting to the Main cluster IP address, which is always attached to the current control unit. To manage an individual member, you can connect to the Local IP address.
For outbound management traffic such as TFTP or syslog, each unit, including the control unit, uses the Local IP address to connect to the server.
Control Unit Management Vs. Data Unit Management
All management and monitoring can take place on the control unit. From the control unit, you can check runtime statistics, resource usage, or other monitoring information of all units. You can also issue a command to all units in the cluster, and replicate the console messages from data units to the control unit.
You can monitor data units directly if desired. Although also available from the control unit, you can perform file management on data units (including backing up the configuration and updating images). The following functions are not available from the control unit:
-
Monitoring per-unit cluster-specific statistics.
-
Syslog monitoring per unit (except for syslogs sent to the console when console replication is enabled).
-
SNMP
-
NetFlow
RSA Key Replication
When you create an RSA key on the control unit, the key is replicated to all data units. If you have an SSH session to the Main cluster IP address, you will be disconnected if the control unit fails. The new control unit uses the same key for SSH connections, so that you do not need to update the cached SSH host key when you reconnect to the new control unit.
ASDM Connection Certificate IP Address Mismatch
By default, a self-signed certificate is used for the ASDM connection based on the Local IP address. If you connect to the Main cluster IP address using ASDM, then a warning message about a mismatched IP address might appear because the certificate uses the Local IP address, and not the Main cluster IP address. You can ignore the message and establish the ASDM connection. However, to avoid this type of warning, you can enroll a certificate that contains the Main cluster IP address and all the Local IP addresses from the IP address pool. You can then use this certificate for each cluster member. See https://www.cisco.com/c/en/us/td/docs/security/asdm/identity-cert/cert-install.html for more information.
Spanned EtherChannels (Recommended)
You can group one or more interfaces per chassis into an EtherChannel that spans all chassis in the cluster. The EtherChannel aggregates the traffic across all the available active interfaces in the channel. A Spanned EtherChannel can be configured in both routed and transparent firewall modes. In routed mode, the EtherChannel is configured as a routed interface with a single IP address. In transparent mode, the IP address is assigned to the BVI, not to the bridge group member interface. The EtherChannel inherently provides load balancing as part of basic operation.
Inter-Site Clustering
For inter-site installations, you can take advantage of ASA clustering as long as you follow the recommended guidelines.
You can configure each cluster chassis to belong to a separate site ID.
Site IDs work with site-specific MAC addresses and IP addresses. Packets egressing the cluster use a site-specific MAC address and IP address, while packets received by the cluster use a global MAC address and IP address. This feature prevents the switches from learning the same global MAC address from both sites on two different ports, which causes MAC flapping; instead, they only learn the site MAC address. Site-specific MAC addresses and IP address are supported for routed mode using Spanned EtherChannels only.
Site IDs are also used to enable flow mobility using LISP inspection, director localization to improve performance and reduce round-trip time latency for inter-site clustering for data centers.
See the following sections for more information about inter-site clustering:
-
Sizing the Data Center Interconnect—Requirements and Prerequisites for Clustering on the Firepower 4100/9300 Chassis
-
Inter-Site Guidelines—Clustering Guidelines and Limitations
-
Configure Cluster Flow Mobility—Configure Cluster Flow Mobility
-
Enable Director Localization—Configure Basic ASA Cluster Parameters

 )
)
 )
) )
) )
)


 Feedback
Feedback