Substituição do servidor de computação UCS C240 M4 - vEPC
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve as etapas necessárias para substituir um servidor de computação defeituoso em uma configuração Ultra-M que hospeda as VNFs (Virtual Network Functions, funções de rede virtual) do StarOS.
Informações de Apoio
O Ultra-M é uma solução de núcleo de pacotes móveis virtualizados, pré-embalada e validada, projetada para simplificar a implantação de VNFs. O OpenStack é o Virtualized Infrastructure Manager (VIM) para Ultra-M e consiste nos seguintes tipos de nó:
- Computação
- Disco de Armazenamento de Objeto - Computação (OSD - Compute)
- Controlador
- Plataforma OpenStack - Diretor (OSPD)
A arquitetura de alto nível da Ultra-M e os componentes envolvidos estão descritos nesta imagem:
 Arquitetura UltraM
Arquitetura UltraM
Este documento destina-se ao pessoal da Cisco familiarizado com a plataforma Cisco Ultra-M e detalha as etapas necessárias para serem executadas no nível de VNF do OpenStack e do StarOS no momento da substituição do servidor de computação.
Note: A versão Ultra M 5.1.x é considerada para definir os procedimentos neste documento.
Abreviaturas
| VNF | Função de rede virtual |
| CF | Função de controle |
| SF | Função de serviço |
| ESC | Controlador de serviço elástico |
| MOP | Método de Procedimento |
| OSD | Discos de Armazenamento de Objeto |
| HDD | Unidade de disco rígido |
| SSD | Unidade de estado sólido |
| VIM | Virtual Infrastructure Manager |
| VM | Máquina virtual |
| EM | Gestor de Elementos |
| UAS | Ultra Automation Services |
| UUID | Identificador de ID universal exclusivo |
Fluxo de trabalho do MoP
 Fluxo de trabalho de alto nível do procedimento de substituição
Fluxo de trabalho de alto nível do procedimento de substituição
Prerequisites
Backup
Antes de substituir um nó de computação, é importante verificar o estado atual do ambiente da plataforma Red Hat OpenStack. É recomendável verificar o estado atual para evitar complicações quando o processo de substituição de computação estiver ativado. Isso pode ser feito por meio desse fluxo de substituição.
Em caso de recuperação, a Cisco recomenda fazer um backup do banco de dados OSPD com o uso destas etapas:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Esse processo garante que um nó possa ser substituído sem afetar a disponibilidade de quaisquer instâncias. Além disso, é recomendável fazer backup da configuração do StarOS, especialmente se o nó de computação a ser substituído hospeda a Máquina Virtual (VM) da Função de Controle (CF).
Identificar as VMs hospedadas no nó de computação
Identifique as VMs hospedadas no servidor de computação. Podem existir duas possibilidades:
- O servidor de computação contém apenas a VM da função de serviço (SF):
[stack@director ~]$ nova list --field name,host | grep compute-10
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d |
pod1-compute-10.localdomain |
- O servidor de computação contém a combinação de funções de controle (CF)/controlador de serviços elásticos (ESC)/gerenciador de elementos (EM)/serviços de automação ultra (UAS) de VMs:
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
Note: Na saída mostrada aqui, a primeira coluna corresponde ao UUID (Universal Unique IDentifier), a segunda coluna é o nome da VM e a terceira coluna é o nome do host onde a VM está presente. Os parâmetros dessa saída serão usados em seções subsequentes.
Desligamento normal
Caso 1. Computador nó hospeda somente a VM SF
Migre a placa SF para o estado de espera
- Faça login no VNF do StarOS e identifique a placa que corresponde ao SF VM. Use o UID da VM SF identificada na seção "Identifique as VMs hospedadas no nó de computação" e identifique a placa que corresponde ao UUID:
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 8:
Card Type : 4-Port Service Function Virtual Card
CPU Packages : 26 [#0, #1, #2, #3, #4, #5, #6, #7, #8, #9, #10, #11, #12, #13, #14, #15, #16, #17, #18, #19, #20, #21, #22, #23, #24, #25]
CPU Nodes : 2
CPU Cores/Threads : 26
Memory : 98304M (qvpc-di-large)
UUID/Serial Number : 49AC5F22-469E-4B84-BADC-031083DB0533
<snip>
- Verifique o status da placa:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Active No
2: CFC Control Function Virtual Card Standby -
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
- Se a placa estiver no estado ativo, mova-a para o estado de espera:
[local]VNF2# card migrate from 8 to 10
Desligar a VM SF do ESC
- Faça login no nó ESC que corresponde ao VNF e verifique o status da VM SF:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name> VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
- Pare a VM SF com o uso de seu nome de VM. (Nome da VM observado na seção " Identifique as VMs hospedadas no nó de computação"):
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
- Uma vez parada, a VM deve entrar no estado SHUTOFF:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d</vm_name>
<state>VM_SHUTOFF_STATE</state>
<snip>
Remova o nó de computação da lista de agregados Nova
- Liste os agregados da nova e identifique o agregado que corresponde ao servidor de computação com base na VNF hospedada por ela. Geralmente, ele deve estar no formato <VNFNAME>-SERVICE<X>:
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
Nesse caso, o servidor de computação a ser substituído pertence ao VNF2. Portanto, a lista agregada correspondente será VNF2-SERVICE2.
- Remova o nó de computação do agregado identificado (remova por nome de host anotado na Seção "Identifique as VMs hospedadas no nó de computação"):
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-SERVICE2 pod1-compute-10.localdomain
- Verifique se o nó de computação foi removido dos agregados. Agora, o host não deve ser listado no agregado:
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-SERVICE2
Caso 2. Nó de computação hosts CF/ESC/EM/UAS
Migrar cartão CF para o estado de espera
- Faça login no VNF do StarOS e identifique a placa que corresponde à VM CF. Use o UUID da VM CF identificada na seção "Identifique as VMs hospedadas no nó de computação" e encontre a placa que corresponde ao UUID:
[local]VNF2# show card hardware
Tuesday might 08 16:49:42 UTC 2018
<snip>
Card 2:
Card Type : Control Function Virtual Card
CPU Packages : 8 [#0, #1, #2, #3, #4, #5, #6, #7]
CPU Nodes : 1
CPU Cores/Threads : 8
Memory : 16384M (qvpc-di-large)
UUID/Serial Number : F9C0763A-4A4F-4BBD-AF51-BC7545774BE2
<snip>
- Verifique o status da placa:
[local]VNF2# show card table
Tuesday might 08 16:52:53 UTC 2018
Slot Card Type Oper State SPOF Attach
----------- -------------------------------------- ------------- ---- ------
1: CFC Control Function Virtual Card Standby -
2: CFC Control Function Virtual Card Active No
3: FC 4-Port Service Function Virtual Card Active No
4: FC 4-Port Service Function Virtual Card Active No
5: FC 4-Port Service Function Virtual Card Active No
6: FC 4-Port Service Function Virtual Card Active No
7: FC 4-Port Service Function Virtual Card Active No
8: FC 4-Port Service Function Virtual Card Active No
9: FC 4-Port Service Function Virtual Card Active No
10: FC 4-Port Service Function Virtual Card Standby -
- Se a placa estiver no estado ativo, mova-a para o estado de espera:
[local]VNF2# card migrate from 2 to 1
Desligar VM CF e EM do ESC
- Faça login no nó ESC que corresponde ao VNF e verifique o status das VMs:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
- Interrompa as VMs CF e EM um por um com o uso de seu nome de VM. (Nome da VM observado na seção "Identifique as VMs hospedadas no nó de computação"):
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
- Depois de parar, as VMs devem entrar no estado SHUTOFF:
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
Migrar ESC para o modo de espera
- Faça login no ESC hospedado no nó de computação e verifique se ele está no estado mestre. Em caso afirmativo, mudar o sistema ESC para o modo de espera:
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
Remova o nó de computação da lista de agregados Nova
- Liste os agregados da nova e identifique o agregado que corresponde ao servidor de computação com base na VNF hospedada por ela. Geralmente, ele deve estar no formato <VNFNAME>-EM-MGMT<X> e <VNFNAME>-CF-MGMT<X>
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
Em nosso caso, o servidor de computação pertence ao VNF2. Portanto, os agregados que correspondem seriam VNF2-CF-MGMT2 e VNF2-EM-MGMT2.
- Remova o nó de computação do agregado identificado:
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-CF-MGMT2 pod1-compute-8.localdomain
[stack@director ~]$ nova aggregate-remove-host VNF2-EM-MGMT2 pod1-compute-8.localdomain
- Verifique se o nó de computação foi removido dos agregados. Agora, certifique-se de que o Host não esteja listado nos agregados:
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
Eliminação do nó de computação
As etapas mencionadas nesta seção são comuns independentemente das VMs hospedadas no nó de computação.
Excluir nó de computação da lista de serviços
- Exclua o serviço de computação da lista de serviços:
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep compute-8
| 404 | nova-compute | pod1-compute-8.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
Excluir Agentes Neutron
- Exclua o antigo agente de nêutrons associado e o agente de vswitch aberto para o servidor de computação:
[stack@director ~]$ openstack network agent list | grep compute-8
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-compute-8.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-compute-8.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
Excluir do banco de dados irônico
- Exclua um nó do banco de dados irônico e verifique-o:
[stack@director ~]$ source stackrc
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-compute-10 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
Excluir do Overcloud
- Crie um arquivo de script chamado delete_node.sh com o conteúdo como mostrado. Certifique-se de que os modelos mencionados sejam os mesmos usados no script Deployment.sh usado para a implantação da pilha:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
- Aguarde até que a operação da pilha do OpenStack passe para o estado COMPLETO:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
Instale o novo nó de computação
- As etapas para instalar um novo servidor UCS C240 M4 e as etapas de configuração inicial podem ser consultadas a partir de:
Guia de instalação e serviços do servidor Cisco UCS C240 M4
- Após a instalação do servidor, insira os discos rígidos nos respectivos slots como o servidor antigo
- Faça login no servidor com o uso do CIMC IP
- Execute a atualização do BIOS se o firmware não estiver de acordo com a versão recomendada usada anteriormente. As etapas para a atualização do BIOS são fornecidas aqui:
Guia de atualização do BIOS de servidor com montagem em rack Cisco UCS C-Series
- Verifique o status das unidades físicas. Ele deve ser "Não configurado bom":
Armazenamento > Controlador Raid modular SAS Cisco 12G (SLOT-HBA) > Informações da unidade física
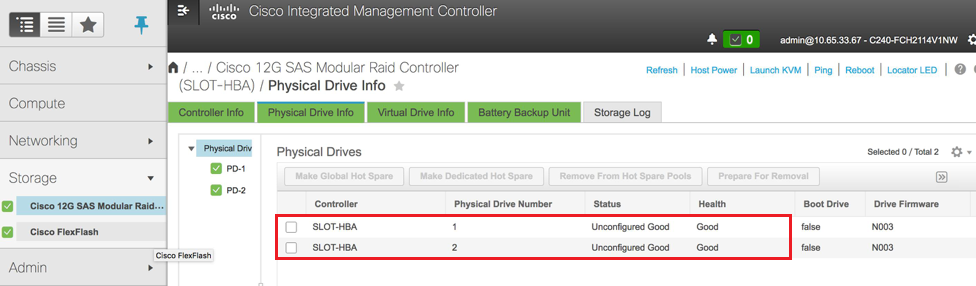
- Crie uma unidade virtual a partir das unidades físicas com RAID Nível 1:
Armazenamento > Controlador RAID modular SAS Cisco 12G (SLOT-HBA) > Informações da controladora > Criar unidade virtual a partir de unidades físicas não utilizadas

- Selecione o VD e configure "Set as Boot Drive" (Definir como unidade de inicialização):
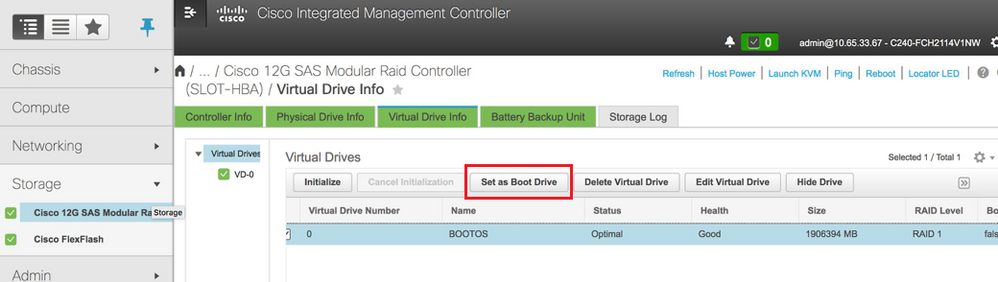
- Ativar IPMI na LAN:
Admin > Serviços de Comunicação > Serviços de Comunicação

- Desativar hiperthreading:
Computação > BIOS > Configurar BIOS > Avançado > Configuração do processador

Note: A imagem mostrada aqui e as etapas de configuração mencionadas nesta seção referem-se à versão de firmware 3.0(3e) e pode haver pequenas variações se você trabalhar em outras versões.
Adicione o novo nó de computação à nuvem geral
As etapas mencionadas nesta seção são comuns independentemente da VM hospedada pelo nó de computação.
- Adicionar servidor de computação com um índice diferente
Crie um arquivo add_node.json com apenas os detalhes do novo servidor de computação a ser adicionado. Verifique se o número de índice do novo servidor de computação não foi usado antes. Geralmente, aumente o próximo valor de computação mais alto.
Exemplo: O anterior mais alto foi o computador-17, portanto, criou o computador-18 no caso do sistema de 2 vnf.
Note: Lembre-se do formato json.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
- Importar o arquivo json:
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
- Execute a introspecção de nó com o uso do UUID observado na etapa anterior:
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
- Execute o script Deployment.sh que foi usado anteriormente para implantar a pilha, para adicionar o novo nó de computação à pilha de nuvem:
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
- Aguarde até que o status da pilha de openstack seja concluído:
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
- Verifique se o novo nó de computação está no estado Ativo:
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep compute-18
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-compute-18 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep compute-18
| 63 | pod1-compute-18.localdomain |
Configurações de substituição de pós-servidor
Depois de adicionar o servidor à nuvem geral, consulte o link abaixo para aplicar as configurações que estavam anteriormente presentes no servidor antigo:
Restaure as VMs
Caso 1. Computador nó hospeda somente a VM SF
Adição à lista agregada Nova
- Adicione o nó de computação ao aggregate-host e verifique se o host foi adicionado:
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-SERVICE2 pod1-compute-18.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-SERVICE2
Recuperação de VM SF do ESC
- A VM SF estaria em estado de erro na lista nova:
[stack@director ~]$ nova list |grep VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d | ERROR | - | NOSTATE |
- Recupere a VM SF do ESC:
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
- Monitore o yangesc.log:
admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d].
- Verifique se a placa SF vem como SF de standby no VNF
Caso 2. O nó de computação hospeda CF, ESC, EM e UAS
Adição à lista agregada Nova
Adicione o nó de computação aos aggregate-hosts e verifique se o host foi adicionado. Nesse caso, o nó de computação deve ser adicionado aos agregados de host CF e EM.
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-CF-MGMT2 pod1-compute-18.localdomain
[stack@director ~]$ nova aggregate-add-host VNF2-EM-MGMT2 pod1-compute-18.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-CF-MGMT2
[stack@director ~]$ nova aggregate-show VNF2-EM-MGMT2
Recuperação da VM UAS
- Verifique o status da VM UAS na lista nova e exclua-a:
[stack@director ~]$ nova list | grep VNF2-UAS-uas-0
| 307a704c-a17c-4cdc-8e7a-3d6e7e4332fa | VNF2-UAS-uas-0 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.10; VNF2-UAS-uas-management=172.168.10.3
[stack@tb5-ospd ~]$ nova delete VNF2-UAS-uas-0
Request to delete server VNF2-UAS-uas-0 has been accepted.
- Para recuperar a VM autovnf-uas, execute o script uas-check para verificar o estado. Ele deve relatar um erro. Em seguida, execute novamente com a opção —fix para recriar a VM UAS ausente:
[stack@director ~]$ cd /opt/cisco/usp/uas-installer/scripts/
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS
2017-12-08 12:38:05,446 - INFO: Check of AutoVNF cluster started
2017-12-08 12:38:07,925 - INFO: Instance 'vnf1-UAS-uas-0' status is 'ERROR'
2017-12-08 12:38:07,925 - INFO: Check completed, AutoVNF cluster has recoverable errors
[stack@director scripts]$ ./uas-check.py auto-vnf VNF2-UAS --fix
2017-11-22 14:01:07,215 - INFO: Check of AutoVNF cluster started
2017-11-22 14:01:09,575 - INFO: Instance VNF2-UAS-uas-0' status is 'ERROR'
2017-11-22 14:01:09,575 - INFO: Check completed, AutoVNF cluster has recoverable errors
2017-11-22 14:01:09,778 - INFO: Removing instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Removed instance VNF2-UAS-uas-0'
2017-11-22 14:01:13,568 - INFO: Creating instance VNF2-UAS-uas-0' and attaching volume ‘VNF2-UAS-uas-vol-0'
2017-11-22 14:01:49,525 - INFO: Created instance ‘VNF2-UAS-uas-0'
- Faça login em autovnf-uas. Aguarde alguns minutos e o UAS deve retornar ao estado bom:
VNF2-autovnf-uas-0#show uas
uas version 1.0.1-1
uas state ha-active
uas ha-vip 172.17.181.101
INSTANCE IP STATE ROLE
-----------------------------------
172.17.180.6 alive CONFD-SLAVE
172.17.180.7 alive CONFD-MASTER
172.17.180.9 alive NA
Note: Se uas-check.py —fix falhar, talvez seja necessário copiar esse arquivo e executá-lo novamente.
[stack@director ~]$ mkdir –p /opt/cisco/usp/apps/auto-it/common/uas-deploy/
[stack@director ~]$ cp /opt/cisco/usp/uas-installer/common/uas-deploy/userdata-uas.txt /opt/cisco/usp/apps/auto-it/common/uas-deploy/
Recuperação de VM ESC
- Verifique o status da VM ESC da lista nova e exclua-a:
stack@director scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | VNF2-ESC-ESC-1 | ACTIVE | - | Running | VNF2-UAS-uas-orchestration=172.168.11.14; VNF2-UAS-uas-management=172.168.10.4 |
[stack@director scripts]$ nova delete VNF2-ESC-ESC-1
Request to delete server VNF2-ESC-ESC-1 has been accepted.
- No AutoVNF-UAS, localize a transação de implantação ESC e, no registro da transação, localize a linha de comando boot_vm.py para criar a instância ESC:
ubuntu@VNF2-uas-uas-0:~$ sudo -i
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show transaction
TX ID TX TYPE DEPLOYMENT ID TIMESTAMP STATUS
-----------------------------------------------------------------------------------------------------------------------------
35eefc4a-d4a9-11e7-bb72-fa163ef8df2b vnf-deployment VNF2-DEPLOYMENT 2017-11-29T02:01:27.750692-00:00 deployment-success
73d9c540-d4a8-11e7-bb72-fa163ef8df2b vnfm-deployment VNF2-ESC 2017-11-29T01:56:02.133663-00:00 deployment-success
VNF2-uas-uas-0#show logs 73d9c540-d4a8-11e7-bb72-fa163ef8df2b | display xml
<config xmlns="http://tail-f.com/ns/config/1.0">
<logs xmlns="http://www.cisco.com/usp/nfv/usp-autovnf-oper">
<tx-id>73d9c540-d4a8-11e7-bb72-fa163ef8df2b</tx-id>
<log>2017-11-29 01:56:02,142 - VNFM Deployment RPC triggered for deployment: VNF2-ESC, deactivate: 0
2017-11-29 01:56:02,179 - Notify deployment
..
2017-11-29 01:57:30,385 - Creating VNFM 'VNF2-ESC-ESC-1' with [python //opt/cisco/vnf-staging/bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689 --net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username ****** --os_password ****** --bs_os_auth_url http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username ****** --bs_os_password ****** --esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --encrypt_key ****** --user_pass ****** --user_confd_pass ****** --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3 172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh --file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py --file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
Salve a linha boot_vm.py em um arquivo de script shell (esc.sh) e atualize todas as linhas de nome de usuário ***** e senha ***** com as informações corretas (tipicamente core/<PASSWORD>). Você também precisa remover a opção -encrypt_key. Para user_pass e user_confd_pass, você precisa usar o formato - nome de usuário: password (exemplo - admin:<PASSWORD>).
- Localize o URL para bootvm.py a partir de running-config e obtenha o arquivo bootvm.py para a VM autovnf-uas. Nesse caso, 10.1.2.3 é o IP da VM de TI automática:
root@VNF2-uas-uas-0:~# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on VNF2-uas-uas-0
VNF2-uas-uas-0#show running-config autovnf-vnfm:vnfm
…
configs bootvm
value http:// 10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
!
root@VNF2-uas-uas-0:~# wget http://10.1.2.3:80/bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
--2017-12-01 20:25:52-- http://10.1.2.3 /bundles/5.1.7-2007/vnfm-bundle/bootvm-2_3_2_155.py
Connecting to 10.1.2.3:80... connected.
HTTP request sent, awaiting response... 200 OK
Length: 127771 (125K) [text/x-python]
Saving to: ‘bootvm-2_3_2_155.py’
100%[=====================================================================================>] 127,771 --.-K/s in 0.001s
2017-12-01 20:25:52 (173 MB/s) - ‘bootvm-2_3_2_155.py’ saved [127771/127771]
- Crie um arquivo /tmp/esc_params.cfg:
root@VNF2-uas-uas-0:~# echo "openstack.endpoint=publicURL" > /tmp/esc_params.cfg
- Executar script shell para implantar o ESC do nó UAS:
root@VNF2-uas-uas-0:~# /bin/sh esc.sh
+ python ./bootvm.py VNF2-ESC-ESC-1 --flavor VNF2-ESC-ESC-flavor --image 3fe6b197-961b-4651-af22-dfd910436689
--net VNF2-UAS-uas-management --gateway_ip 172.168.10.1 --net VNF2-UAS-uas-orchestration --os_auth_url
http://10.1.2.5:5000/v2.0 --os_tenant_name core --os_username core --os_password <PASSWORD> --bs_os_auth_url
http://10.1.2.5:5000/v2.0 --bs_os_tenant_name core --bs_os_username core --bs_os_password <PASSWORD>
--esc_ui_startup false --esc_params_file /tmp/esc_params.cfg --user_pass admin:<PASSWORD> --user_confd_pass
admin:<PASSWORD> --kad_vif eth0 --kad_vip 172.168.10.7 --ipaddr 172.168.10.6 dhcp --ha_node_list 172.168.10.3
172.168.10.6 --file root:0755:/opt/cisco/esc/esc-scripts/esc_volume_em_staging.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_volume_em_staging.sh
--file root:0755:/opt/cisco/esc/esc-scripts/esc_vpc_chassis_id.py:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc_vpc_chassis_id.py
--file root:0755:/opt/cisco/esc/esc-scripts/esc-vpc-di-internal-keys.sh:/opt/cisco/usp/uas/autovnf/vnfms/esc-scripts/esc-vpc-di-internal-keys.sh
- Faça login no novo ESC e verifique o estado de backup:
ubuntu@VNF2-uas-uas-0:~$ ssh admin@172.168.11.14
…
####################################################################
# ESC on VNF2-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@VNF2-esc-esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@VNF2-esc-esc-1 ~]$ health.sh
============== ESC HA (BACKUP) ===================================================
ESC HEALTH PASSED
Recuperar VMs CF e EM do ESC
- Verifique o status das VMs CF e EM na lista nova. Eles devem estar no estado ERRO
[stack@director ~]$ source corerc
[stack@director ~]$ nova list --field name,host,status |grep -i err
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | None | ERROR|
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 |None | ERROR
- Faça login no ESC Master, execute recovery-vm-action para cada VM e CF afetadas. Seja paciente. O ESC programaria a ação de recuperação e isso poderia não acontecer por alguns minutos. Monitore o yangesc.log:
sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
[admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYMENT-_VNF2-D_0_a6843886-77b4-4f38-b941-74eb527113a8]
- Faça login no novo EM e verifique se o estado EM está ativo:
ubuntu@VNF2vnfddeploymentem-1:~$ /opt/cisco/ncs/current/bin/ncs_cli -u admin -C
admin connected from 172.17.180.6 using ssh on VNF2vnfddeploymentem-1
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY
---------------------
2 up up up
3 up up up
- Efetue login na VNF do StarOS e verifique se a placa CF está no estado de espera
Lidar com falha de recuperação do ESC
Nos casos em que o ESC não inicia a VM devido a um estado inesperado, a Cisco recomenda executar um switchover ESC reiniciando o ESC mestre. A transição para o ESC levaria cerca de um minuto. Execute o script "health.sh" no novo ESC principal para verificar se o status está ativo. Mestre ESC para iniciar a VM e corrigir o estado da VM. Essa tarefa de recuperação levaria até 5 minutos para ser concluída.
Você pode monitorar /var/log/esc/yangesc.log e /var/log/esc/escmanager.log. Se você NÃO vir a VM sendo recuperada após 5 a 7 minutos, o usuário precisaria ir e fazer a recuperação manual das VMs afetadas.
Implantar automaticamente a atualização da configuração
Em AutoDeploy VM, edite o autoDeployment.cfg e substitua o servidor de computação antigo pelo novo. Em seguida, carregar substituir em confd_cli. Esta etapa é necessária para uma desativação de implantação bem-sucedida posteriormente.
root@auto-deploy-iso-2007-uas-0:/home/ubuntu# confd_cli -u admin -C
Welcome to the ConfD CLI
admin connected from 127.0.0.1 using console on auto-deploy-iso-2007-uas-0
auto-deploy-iso-2007-uas-0#config
Entering configuration mode terminal
auto-deploy-iso-2007-uas-0(config)#load replace autodeploy.cfg
Loading. 14.63 KiB parsed in 0.42 sec (34.16 KiB/sec)
auto-deploy-iso-2007-uas-0(config)#commit
Commit complete.
auto-deploy-iso-2007-uas-0(config)#end
Reinicie uas-confd e implante automaticamente os serviços após a alteração da configuração.
root@auto-deploy-iso-2007-uas-0:~# service uas-confd restart
uas-confd stop/waiting
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service uas-confd status
uas-confd start/running, process 14078
root@auto-deploy-iso-2007-uas-0:~# service autodeploy restart
autodeploy stop/waiting
autodeploy start/running, process 14017
root@auto-deploy-iso-2007-uas-0:~# service autodeploy status
autodeploy start/running, process 14017
Habilitando syslogs
Para habilitar os syslogs para o servidor UCS, os componentes do Openstack e as VMs recuperadas, siga as seções
"Reative o syslog para componentes UCS e Openstack" e "Enable syslog for the VNFs" no link abaixo:
Informações Relacionadas
- https://access.redhat.com/documentation/en-us/red_hat_openstack_platform/10/html/director_installation_and_usage/sect-Scaling_the_Overcloud - sect-Removing_Compute_Nodes
- https://access.redhat.com/documentation/en-us/red_hat_openstack_platform/10/html/director_installation_and_usage/sect-Scaling_the_Overcloud#sect-Adding_Compute_or_Ceph_Storage_Nodes
- Suporte Técnico e Documentação - Cisco Systems
Histórico de revisões
| Revisão | Data de publicação | Comentários |
|---|---|---|
1.0 |
01-Jun-2018 |
Versão inicial |
Colaborado por engenheiros da Cisco
- Partheeban RajagopalCisco Advanced Services
- Padmaraj RamanoudjamCisco Advanced Services
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)