Árvore de falha e erro de paridade do Cisco 12000 Series Internet Router
Contents
Introduction
Este documento explica as etapas para solucionar e isolar uma peça ou componente defeituoso do Cisco 12000 Series Internet Router após a detecção de uma série de mensagens de erro de paridade.
Observação: este documento não aborda a causa de erros de paridade. Se estiver interessado em uma definição mais concisa sobre os erros de paridade (também conhecidos como Single Event Upsets - SEUs) e sua possível causa, recomendamos a leitura dos documentos associados em Aumentando a Disponibilidade de Rede.
Antes de Começar
Conventions
Para obter mais informações sobre convenções de documento, consulte as Convenções de dicas técnicas Cisco.
Prerequisites
Antes de continuar com esta leitura, recomendamos que você leia os seguintes documentos:
Componentes Utilizados
As informações neste documento são baseadas nas versões de software e hardware abaixo.
-
Cisco 12000 Series Internet Router
-
Todas as versões do software Cisco IOS®
As informações neste documento foram criadas a partir de dispositivos em um ambiente de laboratório específico. All of the devices used in this document started with a cleared (default) configuration. Se você estiver trabalhando em uma rede ativa, certifique-se de que entende o impacto potencial de qualquer comando antes de utilizá-lo.
Overview
A maioria dos processadores de rota Cisco 12000 Series Internet Router e das placas de linha incluem a funcionalidade ECC (Correção de Código de Erro). No entanto, há algumas placas de linha existentes no campo que não têm o recurso ECC. A funcionalidade ECC cobre apenas a memória RAM ou SDRAM (Synchronous Dynamic RAM, RAM dinâmica síncrona) nas placas. O restante não é protegido por ECC.
Aqui está uma comparação da funcionalidade ECC para placas de linha usadas com o Cisco 12000:
-
Todas as placas Engine 2 e posterior têm funcionalidade ECC.
-
Placas do tipo Engine 1 alteradas para ECC depois de FCS.
-
Placas Engine 0 não têm a funcionalidade ECC.
-
É possível atualizar algumas placas com produtos similares que integrem a funcionalidade do ECC.
A tabela abaixo lista os produtos que têm a funcionalidade ECC:
| Produtos não-ECC | Produtos ECC |
|---|---|
| GRP(=) | GRP-B(=) |
| GE-SX/LH-SC(=) | GE-GBIC-SC-B(=) |
| GE-GBIC-SC-A(=) | GE-GBIC-SC-B(=) |
| 8FE-FX-SC(=) | 8FE-FX-SC-B(=) |
| 8FE-TX-RF45(=) | 8FE-TX-RJ45-B(=) |
| 6DS3-SMB(=) | 6DS3-SMB-B(=) |
| 12DS3-SBM(=) | 12DS3-SMB-B(=) |
| OC12/SRP-MM-SC(=) | OC12/SRP-IR-SC-B(=) |
| OC12/SRP-MM-SC(=) | OC12/SRP-mm-SC-B(=) |
| OC12/SRP-mm-SC-B(=) | OC12/SRP-LR-SC-B(=) |
Observação: o B e o ECC são independentes. -B significa que o produto é a segunda e principal revisão solicitada da placa. Em alguns casos, esta foi a revisão para ECC.
A Cisco oferece um Technology Migration Plan (TMP) que permite atualizar uma placa não-ECC para uma nova placa ECC. Um crédito será aplicado à compra da nova placa ECC em troca da placa não-ECC.
Análise de árvore de falha de erro de paridade do GRP (Gigabit Route Processor)
O fluxograma abaixo ajuda a determinar qual componente do Roteador de Internet do Cisco 12000 Series é responsável pelas mensagens de erro de paridade/ECC (correção de código de erro) no GRP (processador de rota de gigabit).
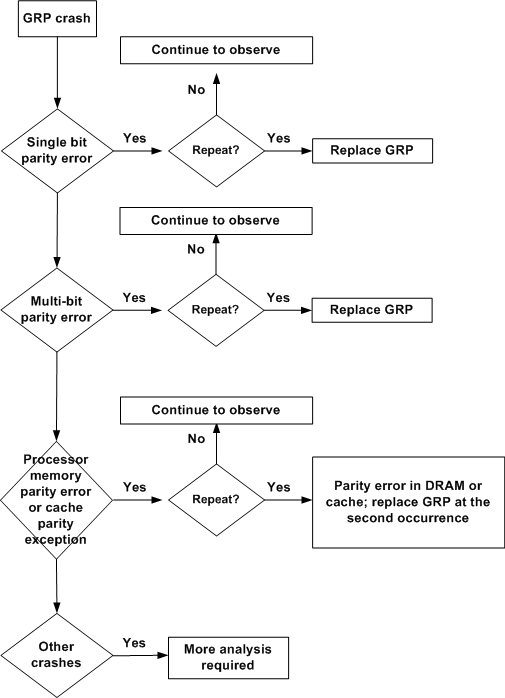
Nota: Capture e grave os registros de saída e console show tech-support e colete todos os arquivos crashinfo durante eventos de erro de paridade/ECC.
Análise de árvore de falha de erro de paridade da placa de linha
O fluxograma abaixo ajuda a determinar qual componente de um roteador de Internet do Cisco 12000 Series é responsável pelas mensagens de erro de paridade/ECC (Error Code Correction).
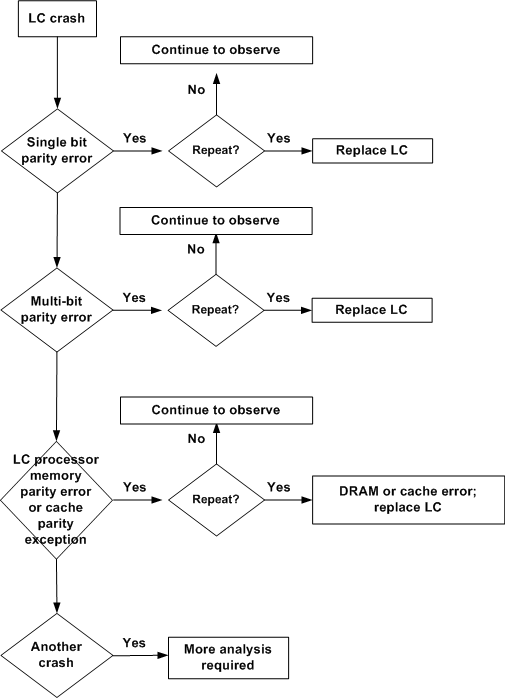
Observação: sempre que uma placa de linha experimentar um evento de erro de paridade/ECC, colete o máximo de informações possível (consulte Troubleshooting Line Card Crashes no Cisco 12000 Series Internet Router para obter detalhes).
O roteador de Internet Cisco série 12000 recupera-se de erros de paridade em outras memórias de cartão de linha (SDRAM e SRAM) sem travar.
Erros de paridade/ECC no Gigabit Route Processor do Cisco 12000 Series
Os dados com paridade ruim podem ser relatados por vários dispositivos de verificação de paridade para qualquer operação de leitura ou gravação no Cisco 12000 Series Internet Router.
O GRP-B e o PRP usam correção de erro de bit único e detecção de erro de vários bits ECC para memória compartilhada (SDRAM). Um erro de bit único no SDRAM é corrigido automaticamente e o sistema continua a funcionar normalmente.
Erros de bit único (SBEs)
O PRP e o GRP-B têm a controladora avançada de RAM dinâmica (DRAM) que suporta ECC. Portanto, eles podem corrigir erros de bit único e relatar erros de vários bits. A correção de um erro de bit único é semelhante a:
%Tiger-3-SBE: Single bit error detected and corrected at <address>
Os SBEs são corrigidos pelo Circuito de Correção de Erro e não afetam a funcionalidade do GRP-B ou PRP. Nenhuma ação é necessária para erros de bit único, a menos que eles ocorram com frequência. Nesse caso, é recomendável substituir a placa de processador.
Erros de Multibits (MBEs)
A detecção de um erro de vários bits é relatada através de uma exceção de erro de barramento ou de uma exceção de erro de paridade de cache da CPU.
Erros de paridade de memória do processador (PMPE)
R. A mensagem de erro de paridade da memória do processador será reportada se a CPU detectar um erro de paridade ao acessar o cache externo do processador (L3 no GRP) por meio do barramento SysAD ou uma das memórias de cache interno da CPU (L1 ou L2). A Tabela 1 lista exemplos das mensagens que seriam impressas para cada tipo de erro de paridade de cache:
Tabela 1: Local de Erro de Paridade de Cache
| Localização do erro de paridade | Mensagem de erro |
|---|---|
| Cache de instrução L1 | Erro: Principal, cache de instr, campos: dados |
| Cache de dados L1 | Erro: Principal, cache de dados, campos: dados |
| Cache de instrução L2 | Erro: SysAD, cache de instr, campos: dados |
| Cache de dados L2 | Erro: SysAD, cache de dados, campos: dados |
| Cache de instrução L3 | Erro: SysAD, cache de instr, campos: 1st dword |
| Cache de dados L3 | Erro: SysAD, cache de dados, campos: 1st dword |
Exemplo:
A primeira linha da mensagem de erro indica o local do erro de paridade, que pode ser qualquer um listado na Tabela 1. Nesse exemplo, o local é o cache de instruções L3.
Error: SysAD, instr cache, fields: data, 1st dword
Physical addr(21:3) 0x000000,
virtual addr 0x6040BF60, vAddr(14:12) 0x3000
virtual address corresponds to main:text, cache word 0
Low Data High Data Par Low Data High Data Par
L1 Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
Low Data High Data Par Low Data High Data Par
DRAM Data: 0:0xAE620068 0x8C830000 0x00 1:0x50400001 0xAC600004 0x01
2:0xAC800000 0x00000000 0x02 3:0x1600000B 0x00000000 0x01
A saída de show version deve ser semelhante a esta:
...System was restarted by processor memory parity error at PC 0x602310D0, address 0x0 at 03:18:21 GMT Sun Oct 27 2002 ...
Na saída show context, você pode ver que o sistema foi reiniciado por uma exceção de paridade de cache:
Router#show context slot 11 CRASH INFO: Slot 11, Index 1, Crash at 19:08:07 CST Thu Nov 14 2002 VERSION: GS Software (GSR-P-M), Version 12.0(22)S1, EARLY DEPLOYMENT RELEASE SOFTWARE (fc1) TAC Support: http://www.cisco.com/tac Compiled Mon 16-Sep-02 17:36 by nmasa Card Type: Route Processor, S/N LC uptime was 0 minutes. System exception: sig=20, code=0xE42F3E4B, context=0x52CF3D44 System restarted by a Cache Parity Exception STACK TRACE: -Traceback= 5020453C 500E5E24 5010E6DC 5015F89C 501E9F6C 501E9F58 ...
Substitua o GRP ou o PRP após uma segunda falha.
Mensagem de erro %GRP-3-PARITYERR
A seguinte mensagem poderá aparecer na saída do console:
SEC 7: %GRP-3-PARITYERR: Parity error detected in the fabric buffers. Data (8)
Esta mensagem significa que um erro de paridade foi detectado pelo hardware de interface de construção no GRP. O número hexa indica o vetor de interrupção de erro. Isso normalmente indica um problema de hardware no GRP que relata o erro (nesse caso, slot 7). O GRP defeituoso deverá ser substituído na segunda ocorrência de um problema semelhante.
%PRP-3-SBE_DATA: Dados inválidos [hex] [hex] ECC rec [hex] calc [hex]
Essa mensagem de erro é exibida quando o roteador recebe dados com paridade incorreta.
Os dados com paridade incorreta são relatados por vários dos dispositivos de verificação de paridade para qualquer operação de leitura ou gravação realizada no Cisco 12000 Series Internet Router.
O PRP usa correção de erro de bit único e detecção de erro de vários bits ECC para compartilhar memória (SDRAM). Um erro de bit único no SDRAM é corrigido automaticamente e o sistema continua a funcionar normalmente.
Os erros de bit único (SBE) são corrigidos pelo ECC (Error Correction Circuit) e não afetam a funcionalidade do PRP. Nenhuma ação é necessária para erros de bit único, a menos que eles ocorram com frequência.
Se o erro ocorrer com frequência, é aconselhável substituir a placa do processador.
Erros de paridade/ECC nas placas de linha do Cisco 12000 Series
Erros SDRAM ECC
-
Erros do ECC (Código de Correção de Erros de Bit Único) da SDRAM
Um erro de bit único é um bit único de dados que está incorreto em uma leitura de palavras da memória. Para SBEs, o erro pode ser corrigido sem interrupção das operações.
Erros de bit único são detectados e os dados corrigidos são apresentados. Por exemplo, erros de bit único são relatados da seguinte forma no Engine 4/4+:
SLOT 6:Jul 19 07:37:34: %TX192-3-SDRAM_SBE: Error=0x2 - DIMM1 Syndrome=0x7600 Addr=0xBEA09 Data bit80-Traceback= 401C8C9C 401C9508 401CDE08 401CDE40 4007F674 4009ED0C 4009ECF8
Os SBEs são corrigidos pelo Circuito de Correção de Erro e não afetam a funcionalidade da placa. Nenhuma ação é necessária para erros de bit único, a menos que eles ocorram com frequência. Nesse caso, é recomendável substituir a placa de linha.
-
Erros SDRAM Multi-bit ECC
Um erro de vários bits ocorre quando mais de um bit está incorreto na mesma palavra. Para MBEs, o erro é detectado e a placa de linha trava. A ocorrência de SBEs e MBEs é muito rara.
Aqui está um exemplo da mensagem impressa no console em resposta a um erro de ECC de vários bits no SDRAM:
SLOT 5:Jul 25 16:58:51: %MCC192-3-SDRAM_SBE: Error=0x808 - DIMM0 Syndrome=0x31000000 Addr=0x81034 Data bit120 -Traceback= 401C8C9C 401C9508 40450018 400BF7D4 SLOT 5:Jul 25 16:58:51: %MCC192-3-SDRAM_MBE: Error=0x808 - DIMM0 Syndrome=0x18000000 Addr=0x80834 -Traceback= 401C8D88 401C9508 40450018 400BF7D4
MBEs não podem ser corrigidos por ECC e causam travamento da placa de linha. A placa de ingresso será então recarregada e trazida de volta à operação normal pelo processador de rotas.
Os diagnósticos de campo podem ser usados para verificar MBEs na memória da placa de linha. Os MBEs são detectados pelo diagnóstico de campo como erros de memória. Abaixo há um exemplo de placa que apresentou um erro multibits no TX SDRAM que falhou no diagnóstico de campo:
FDIAG_STAT_IN_PROGRESS(5): test #12 TX SDRAM Marching Pattern FD 5> RIM: FD 5> TX Registers FD 5> INT_CAUSE_REG = 0x00000680 FD 5> Unexpected L3FE Interrupt occured. FD 5> ERROR: TX BMA Asic Interrupt Occured FD 5> *** 0-INT: External Interrupt *** FDIAG_STAT_DONE_FAIL(5) test_num 12, error_code 1 Field Diagnostic: ****TEST FAILURE**** slot 5: last test run 12, TX SDRAM Marching Pattern, error 1 Field Diag eeprom values: run 5 fail mode 1 (TEST FAILURE) slot 5 last test failed was 12, error code 1
Se você tiver uma placa de linha QOC48 ou OC192, consulte este Aviso de Campo: QOC48/OC192 SBEs/MBEs. Caso contrário, é necessário substituir a placa de linha depois de uma segunda falha.
Exceções de paridade de cache
Verifique o valor do campo sig= na saída show context slot [slot#]:
Router#show context slot 4
CRASH INFO: Slot 4, Index 1, Crash at 04:28:56 EDT Tue Apr 20 1999
VERSION:
GS Software (GLC1-LC-M), Version 11.2(15)GS1a, EARLY DEPLOYMENT RELEASE
SOFTWARE (fc1)
Compiled Mon 28-Dec-98 14:53 by tamb
Card Type: 1 Port Packet Over SONET OC-12c/STM-4c, S/N CAB020500AL
System exception: SIG=20, code=0xA414EF5A,
context=0x40337424
System restarted by a Cache Parity Exception
Algumas placas baseadas no mecanismo de encaminhamento Engine 1 são susceptíveis a problemas de corrupção de cache interno ao operar em condições de voltagem e temperatura muito específicas.
O CERF (Cache Error Recovery Feature, recurso de recuperação de erros de cache) é um recurso de software nas placas de linha Engine 1 que detecta e corrige erros de paridade de cache, descarregando erros do cache externo da CPU e atualizando a linha de cache da DRAM. Este recurso fornece inteligência ao algoritmo de gerenciamento do cache da CPU que habilita a CPU a se recuperar de um erro de paridade na memória cache, evitando o travamento da placa de linha sem prejudicar o desempenho.
Observação: o CERF está ativado por padrão. A atividade deste ECC (Error Correction Code) de software pode ser monitorada pelo comando show controller cerf. Para desativar o recurso, utilize o comando de configuração global no service cerf.
Consulte Aviso de Campo: Erro de paridade de cache na placa GSR 1GE para obter informações adicionais.
Para determinar em qual mecanismo de encaminhamento a placa de linha se baseia, consulte Como posso determinar qual placa de mecanismo está sendo executada na caixa? do Cisco 12000 Series Internet Router: Documento com perguntas freqüentes.
Se a placa de linha for baseada no Engine 1, a solução alternativa é atualizar o software Cisco IOS para uma versão que contém o CERF (Cache Error Recovery Feature, Recurso de recuperação de erro de cache). Esse recurso esteve primeiro disponível no Cisco IOS Software versão 12.0(21)S3. Se ainda estiver travando pela exceção de paridade de cache, a placa de linha precisará ser substituída.
Se a placa de linha for baseada em outro tipo de mecanismo, você deverá substituir a placa de linha na segunda ocorrência de um travamento semelhante.
Mensagens de erro da placa de linha com base no mecanismo 0
Você pode ver a seguinte mensagem nos registros do console:
SLOT 2:Oct 23 17:07:45.531 EST: %LC-3-L3FEERRS: L3FE DRAM error 12 address 41E9B9A0 SLOT 2:Oct 23 17:07:45.531 EST: %LC-3-L3FEERR: L3FE error: rxbma 0 addr 0 txbma 0 addr 0 dram 12 addr 41E9B9A0 io 0 addr 0 SLOT 2:Oct 23 17:07:45.531 EST: %GSR-3-INTPROC: Process Traceback= 40080BAC -Traceback= 40357084 40495D30 40496EE0 400CCF98
Esta mensagem relata um erro de paridade de gravação da DRAM da CPU. L3FE significa mecanismo de encaminhamento de Camada 3. A placa de linha deve ser substituída na segunda ocorrência de um problema similar.
Mensagens de erro de placa de linha baseadas em Engine 1
Aqui temos algumas mensagens de erro que você pode encontrar:
-
Nos registros de uma placa de ingresso Gigabit: de uma porta
SLOT 5: %LCGE-3-INTR: TX GigaTranslator external interface parity error
Para placas mais novas, uma correção foi substituir o TX GigaTranslator ASIC por um FPGA (field-programmable gate array). Na segunda ocorrência de um problema semelhante, a placa deve ser substituída.
-
Na saída do console:
SLOT 6: %LC-3-ECC: Salsa ECC: About to handle ECC single bit error, ECC status = 2 DRAM error status = = 21 SLOT 6: %LC-3-L3FEERR: L3FE error: rxbma 0 addr 0 txbma 0 addr 0 dram 21 addr 200020 io 0 addr 0 SLOT 6: %LC-3-ECC: Salsa ECC: Addresses: Salsa returned =429BFDE8 correcting on = 429BFDE8 SLOT 6: %MEM_ECC-3-SBE: Single bit error detected and corrected at 0x429BFDE8 SLOT 6: %MEM_ECC-3-SYNDROME_SBE: 8-bit Syndrome for the detected Single-bit error: 0x8A SLOT 4: %MEM_ECC-3-SBE_HARD: Single bit *hard* error detected at 0x6299FB60 SLOT 1:Jun 10 05:29:47.690 EDT: %LC-3-ECC: Salsa ECC: About to handle ECC single bit error,ECC status = 0 DRAM error status =12 SLOT 6:Sep 26 15:18:01: %LC-3-SWECC: L2 event cleared: EPC = 0x40631CCC, CERR = 0xE40BB933, SysAD Addr = 1, total = 1 SLOT 0:Dec 7 13:48:11.480: %LC-3-SWECC_DATA: L2 event cleared: EPC = 0x400A8040, CERR = 0xA01DCE58, l1v = 0x41E3C20441E3C1C5, dv =0x41E3C1C441E3C204, SysAD Addr = 0, total = 1
Essas mensagens podem ser divididas nas seguintes partes:
-
%LC-3-ECC: Salsa ECC - Há um erro no L3FE ASIC da placa de linha.
-
%LC-3-L3FEERR - Há um erro no registro L3FE ASIC da placa de linha. Informações.
-
%MEM_ECC-3-SBE - Um erro corrigível de bit único foi detectado em uma leitura da DRAM. O comando show memory ecc pode ser usado para despejar erros de bit único registrados até o momento. É o mesmo que a mensagem de erro %MEM_ECC-3-SBE_LIMIT.
-
%MEM_ECC-3-SYNDROME_SBE - A síndrome de 8 bits para erro de bit único detectado. Esse valor não indica as posições exatas dos bits em erro, mas pode ser utilizado para aproximar suas posições. Isso é igual à mensagem de erro %MEM_ECC-3-SYNDROME_SBE_LIMIT.
Basicamente, a placa de linha reportou um erro de bit único e corrigiu-o automaticamente. Nenhuma ação necessária de sua parte, a menos que isso ocorra com freqüência. Nesse caso, é recomendável substituir a placa de linha.
-
%LC-3-SWECC_DATA - Indica que um evento de cache foi corrigido no LC no SLOT 0 pelo Software Error Correction Code (SWECC).
-
-
Uma outra mensagem que você poderá encontrar é:
SLOT 4: %MEM_ECC-3-SBE_HARD: Single bit *hard* error detected at 0x6299FB60
Esta mensagem significa que um erro incorrigível de bit simples [erro de hardware] foi detectado em uma leitura de CPU da DRAM. O comando show memory ecc descarta os erros de bit único registrados até agora e indica os locais de endereço de erro de hardware detectados.
Monitore o sistema usando o comando show memory ecc e substitua a DRAM se houver muitas ocorrências desses erros.
Mensagens de erro da placa de linha com base em Engine 2
Você pode ver o seguinte erro na saída do console:
SLOT 6: %LC-6-PSAECC: An TLU SDRAM ECC correctable error occurred address 19C49FD SLOT 2:035610: Feb 26 13:09:13.628 UTC: %LC-6-PSAECC: An PLU SDRAM ECC correctable error occurred address 1956059
Isso significa que a SDRAM protegida por ECC de ASIC de Comutação de Pacotes (PSA - Packet Switching ASIC) identificou um erro de um bit corrigível. Nenhuma ação é necessária da sua parte, a menos que essas mensagens ocorram com frequência. Nesse caso, é recomendável substituir a placa de linha.
Mensagens de erro da placa de linha com base em Engine 3
Você pode ver estes erros na saída do console:
SLOT 6:00:03:53: %PM622-3-SAR_SRAM_PARITY_ERR: (6/0): Parity error in Reassembly SAR SRAM address: 80000000.Resetting the port SLOT 3:00:00:53: %PM622-3- SAR_MULTIBIT_ECC_ERR: (3/0): Multi-bit ECC Uncorrectable error in SAR SDRAM address: 80000000. Resseting the port. SLOT 4:00:00:53: %PM622-3 SAR_SINGLE_BIT_ECC_ERR: (3/0): ECC corrected an error in SAR SDRAM address: 800000. SLOT 0:Jun 25 20:45:53 KST: %EE48-6-ALPHAECC: RX ALPHA: An PLU SDRAM ECC correctable error occured address 1000C254 SLOT 0:Jun 25 20:45:53 KST: %EE48-6-ALPHAECC2: RX ALPHA: An PLU SDRAM ECC multibit error occured at address 1000E254 SLOT 5:Nov 17 09:46:30.171: %EE48-6-ALPHA_PARITY: TX ALPHA: Transient SRAM64 parity corrected error 3E Data 0 100000 Parity bits 0 SLOT 10:Feb 21 16:55:36: %EE48-3-ALPHA_SRAM64_ERR: TX ALPHA: ALPHA_PST_RANGE_ERR error 11003F Data 0 0 Parity bits 0 SLOT 4:Jan 15 06:30:00.942 UTC: %EE48-2-GULF_TX_SRAM_ERROR: ASIC GULF: TX SRAM uncorrectable error detected. Details=0x0000 SLOT 0:Mar 16 19:50:22.464 cst: %EE48-4-QM_ZBT_PARITY: ToFab Address 0xB95E Data 0x1 SLOT 5:May 17 06:17:35.507: %EE48-4-QM_NON_ZBT_PARITY: ToFab Error 0x10000028 SLOT 5:May 17 06:17:53.883: %EE48-4-QM_ZBT_PARITY_TRANSIENT: FrFab Address 0x0 Data 0x7E SLOT 5:May 17 06:17:53.883: %EE48-4- GULF_RX_TB_PARITY_ERROR: ASIC GULF: RX telecom bus parity error on port 0 SLOT 1:Dec 13 00:27:42: %EE48-3-SRAM_PARITY: SRAM parity: Unable to find shadow 281B9EB4 SLOT 0:Aug 4 08:55:37: %EE48-3-QM_PARITY: FrFab Address 0x1859E Data 0x10 SLOT 0:Aug 4 08:55:37: %EE48-3-QM_ERROR: FrFab error register 0x80000.
Mensagens de erro de placa de linha baseadas em Engine 4/4+
-
Você pode encontrar as seguintes mensagens em placas de linhas baseadas no Engine 4/4:
SLOT 4: %RX192-3-HINTR: status = 0x4000000, mask = 0x3FFFFFFF - Parity error on rx_pbc_mem. -Traceback= 401C37C0 403D8814 400BE1EC SLOT 4: %LC-3-ERR_INTR: Error interrupt occurred -Traceback= 400CE028 400C8DF0 40010A24
or
SLOT 3: %RX192-3-HINTR: status = 0x4000000, mask = 0x3FFFFFFF - Parity error on rx_pbc_mem. -Traceback= 406012E0 406972A0 400C555C %FIB-3-FIBDISABLE: Fatal error, slot 3: IPC failure
or
SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_SBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 2:00:03:41: %MCC192-6-RED_PARAM1_SBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 2:00:03:41: %MCC192-6-RED_PARAM2_SBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 5:Apr 26 11:56:08.160: %MCC192-3-SDRAM_MBE: Error=0x200 - DIMM1 Syndrome=0x3000 Addr=0x811C3 SLOT 10:Mar 6 05:05:26.965: %RX192-3-ADJ_MEM_MBE: phy addr 0x7905E648, offset 0xBCC9, old ecc 0x0, new ecc 0x0, bit -1, value 0x0 - MBE on Adjacency Memory.. SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_MBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 2:00:03:41: %MCC192-6-RED_PARAM1_MBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No SLOT 2:00:03:41: %MCC192-3-RED: Error=0x80000 - RED PARAM 1 ECC SBE Error. -Traceback= 405AF5E0 405B1CEC 406DFF7C 406E057C 400FC7E SLOT 2:00:03:41: %MCC192-6-RED_PARAM2_MBE: Parameter 1 - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x43, samebit No, diffbit No Sep 8 14:32:09 jst: %MEM_ECC-3-SYNDROME_SBE_LIMIT: 8-bit Syndrome for the detected Single-bit error: 0xD5
Os sintomas para esse problema incluem:
-
O Cisco Express Forwarding nesta placa de linha fica desativado
-
As portas associadas permanecem ativas/ativas
-
A placa de linha pode ser reinicializada automaticamente
Se a placa de linha não for redefinida, a solução alternativa é executar o comando microcode reload <slot>:
Esta mensagem nem sempre indica um problema de hardware com o módulo RX192. Alguns bugs do Cisco IOS Software podem produzir essa mensagem de erro como um efeito colateral. Se essa mensagem aparecer apenas uma vez, continue monitorando a placa. O dispositivo será reinicializado. Se o problema persistir, a placa será reinicializada automaticamente. Entre em contato com o representante de Suporte técnico Cisco para obter ajuda se essa mensagem persistir.
-
-
Os eventos SBE podem ser verificados no E4/E4+ com o comando show controllers mcc192 ecc:
LC-Slot4#show controllers mcc192 ecc MCC192 SDRAM ECC Counters SBE = 0x0, MBE = 0x0 TX192 SDRAM ECC Counters SBE = 0x0, MBE = 0x0Isso reporta na memória RX e TX.
Mensagens de erro de placa de linha baseadas em Engine 5/5+
Você pode ver estes erros na saída do console:
SLOT 1:Jun 26 20:45:53 KST: %EE192-6-WAHOOECC: RX WAHOO: An PLU SDRAM ECC correctable error occured address 20000254 SLOT 9:Sep 2 21:27:49.680 GMT+8: %MCC192-3-PKTMEM_SBE: Single bit error detected and corrected SLOT 14:Jul 18 07:19:24.637: RX_XBMA: 1-bit CPUIM_ECCERR1 error 0x2 SLOT 15:Jan 4 16:53:16.591: TX_XBMA: (1) QSRAM qinfo SBE detected. info: 0x82605455 SLOT 12:Dec 12 22:34:15: %EE192-4-BM_ERRSSS: FrFab BM BADDR ECC ERR info single bit error(s) corrected, error 8250F63E count: 2 SLOT 1:Nov 22 13:40:02 JST: %EE192-3-QM_ERROR: RX_XBMA OQLLM error error register 0x1 -Traceback= 40AE71AC 406078C4 405F5EC0 SLOT 7:001113: Oct 24 10:50:28.520 BST: %EE192-3-WAHOOERRS: RX WAHOO: WAHOO_CSRAM_CNTRL_INT PIPE0 error 8 SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRSSS: RX WAHOO: WAHOO_FFCRAM_CNTRL_INT PIPE0 error 4 addr 3FBFAB8 agent 94 SLOT 7:001114: Oct 24 10:50:28.520 BST: %EE192-3-WAHOOERRSSSS: RX WAHOO: WAHOO_PPC_INT PIPE1 error pl_ctl 4000226 pl_aa_avl F9F7B pl_aa_end 7FF9 pl_aa_fatal 4800000 SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: RX WAHOO WAHOO_NFC_SRAM_MULTI_ECC_ERR multi-bit CSSRAM error SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_CTCAM_CNTRL_INT multi-bit CSRAM error SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_FFCRAM_CNTRL_INT MBE SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: FSRAM not OK WAHOO_FSRAM_CNTRL_INT ECC_1_BIT_EE | ECC_UNCORR_EE SLOT 6:Oct 4 16:48:00.487: %EE192-3-WAHOOERRS: WAHOO_CTCAM_CNTRL_INT multi-bit CSRAM error SLOT 1:00:01:14: WEEKLY_THROTTLE_SOCKEYE_SBE: SOCKEYE SBE: addr: 0xC2A007C0, synd: 0xC4 SLOT 1:00:01:14: WEEKLY_THROTTLE_CBSRAM_SBE_TX+i: CBSRAM SBE TX: 1-bit CBSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CBSRAM_SBE_RX+i: CBSRAM SBE RX: 1-bit CBSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSSRAM_SBE_TX+i: CSSRAM SBE TX: 1-bit CSSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSSRAM_SBE_RX+i: CSSRAM SBE RX: 1-bit CSSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSRAM_SBE_TX+i: CSRAM SBE TX: 1-bit CSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_CSRAM_SBE_RX+i: CSRAM SBE RX: 1-bit CSRAM error. SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FW_TCAM_PRTY_TX+throttle_i: TX FTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FW_TCAM_PRTY_RX+throttle_i: RX FTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_CL_TCAM_PRTY_TX+throttle_i: TX CLTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_CL_TCAM_PRTY_RX+throttle_i: RX CLTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_NF_TCAM_PRTY_TX+throttle_i: TX NFTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_NF_TCAM_PRTY_RX+throttle_i: RX NFTCAM PRTY error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_TCAM_PRTY_VMR: TCAM PRTY VMR error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_TCAM_PRTY_NO-VMR: TCAM PRTY NO-VMR error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_SBE_TX: FCRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_SBE_RX: FCRAM SBE TX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FCRAM_PER_CHIP_SBE_TX: FCRAM CHIP SBE error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FCRAM_PER_CHIP_SBE_RX: FCRAM CHIP SBE error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FSRAM_SBE_TX: FSRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_FSRAM_SBE_RX: FSRAM SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FSRAM_MBE_TX: FSRAM MBE RX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_W_ FSRAM_MBE_RX: FSRAM MBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_ISERR_TX: ISERR TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_ISERR_RX: ISERR RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_FCRAM_SBE_TX: FCRAM SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_BM_FCRAM_SBE_RX: FCRAM SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_LINK_SBE_TX: QSRAM LINK SBE TX error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_LINK_SBE_RX: QSRAM LINK SBE RX error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_QEINFO_SBE_TX: QSRAM queue info sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_QEINFO_SBE_TX: QSRAM queue info sbe rx error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_QSRAM_BADDR_SBE_TX: qsram bad addr sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_ QM_QSRAM_BADDR_SBE_RX: qsram bad addr sbe rx error, status = 0x3 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_OQLLM_SBE_TX: oqllm sbe tx error, status = 0x2 SLOT 1:00:01:14: WEEKLY_THROTTLE_QM_OQLLM_SBE_RX: oqllm sbe rx error status = 0x3
Mensagens de erro da placa de linha com base em Engine 6
Você pode ver estes erros na saída do console:
SLOT 0:Jan 14 08:53:44.581 GMT: %FIA-3-RAMECCERR: To Fabric ECC error was detected Single Bit Error RAM2 status = 0x8000 Syndrome = 0x0 addr = 0x0 SLOT 6:Apr 29 09:36:12: %E6LC-4-ECC_THRESHOLD: HERMES VID SBE exceeded threshold, possible memory failure SLOT 4:*Mar 13 23:38:19.295: %E6_RX192-3-MTRIE_SBE: Head1 Syndrome=0x94 Addr=0xFFF2B -Traceback= 40544830 40546A90 40688C94 400EDC18 SLOT 7:*Mar 4 1234:19.295: %E6_RX192-3-ADJ_SBE: Syndrome=0x59 Addr=0xFFF2B -Traceback= 40000830 40036A90 40555D44 400ddd23 SLOT 14:Dec 9 20:02:29: %E6_RX192-6-PBC_SBE: Single bit error detected and corrected RLDRAM Syndrome=0x61 Addr=0xF855 Dec 9 20:02:33: %GRP-4-RSTSLOT: Resetting the card in the slot: 14,Event: linecard error report SLOT 4:06:21:43: %E6_RX192-3-ACL_SBE: ACTION MEM Syndrome=0x7 Addr=0x0 -Traceback= 40549740 4054A7E0 4068D814 400EE018 SLOT 6:Mar 28 03:30:19: %RX192-3-HINTR: status = 0x1000000000000, mask = 0x7FFFFF0FA320F - L3X SBE error. -Traceback= 405816DC 406A1010 406A1650 400F70E8 SLOT 6:Mar 28 03:30:19: %E6_RX192-6-VID_SBE: Single bit error detected and corrected VID memory Syndrome=0x19 Addr=0xE51B SLOT 6:Nov 27 23:32:36: %HERA-3-PKTMEM_SBE: Single bit error detected and corrected Error=0x80 – Syndrome=0x5100000000000000 Addr=0x894620 Data bit116 SLOT 7:Oct 2 23:32:36: %HERA-6- MCD_SBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 1:Jun 22 03:32:36: %HERA-6- MRW_SBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 12:May 24 03:03:36: %HERA-6- UPF_SBE: Single bit error detected and corrected Error=0x60 – Syndrome=0x4100000000000000 Addr=0x451140 Data bit216 SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_SBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 9:May 5 18:52:14: %HERA-6-QM_FBF_SBE: Free Block FIFO - Single Bit Error detected and corrected Syndrom = 0x10, Addr = 0x778, samebit Yes, diffbit No SLOT 9:May 5 18:52:14: %HERA-3-QM: Error=0x40 - FBF RAM ECC SBE. -Traceback= 405AD4CC 405AF5D0 405F2E80 406DCDB8 406DD434 400FC500 SLOT 3:Aug 16 00:45:14: %MCC192-6-RED_AQD_SBE: Average Queue Depth - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x89, samebit No, diffbit No SLOT 2:Jan 23 06:29:56 KST: %MCC192-6-RED_STAT_SBE: Statistics - Single Bit Error detected and corrected Syndrome = 0x38, Address = 0xFF, samebit No, diffbit No SLOT 4:*Mar 13 23:38:19.295: %E6_RX192-3-MTRIE_MBE: Single bit error detected and corrected Head1 Syndrome=0x94 Addr=0xFFF2B SLOT 7:*Mar 4 1234:19.295: %E6_RX192-3-ADJ_MBE: Syndrome=0x59 Addr=0xFFF2B -Traceback= 40000830 40036A90 40555D44 400ddd23 00:00:18: %E6_RX192-3-PBC_MBE: ADJ OBANK LO Syndrome=0xE5 Addr=0x142 -Traceback= 405BF8B0 405C0F08 406E8D78 406E93B8 400FCCE0 SLOT 6:Mar 28 03:30:19: %E6_RX192-6-VID_MBE: Single bit error detected and corrected VID memory Syndrome=0x19 Addr=0xE51B SLOT 0:Apr 18 06:44:53.751 GMT: %HERA-3-PKTMEM_MBE: Error=0x1010 - Syndrome=0x9900000000 SLOT 7:Oct 2 23:32:36: %HERA-6- MCD_MBE: Single bit error detected and corrected Error=0x50 – Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 1:Jun 22 03:32:36: %HERA-6- MRW_MBE: Single bit error detected and corrected Error=0x50 - Syndrome=0x3100000000000000 Addr=0x331110 Data bit216 SLOT 13:Dec 5 07:30:15.272 cst: %HERA-6-PAM_ACL_MBE: PKT CNT MEM Syndrome=0x8 Addr=0x523C SLOT 9:May 5 18:52:14: %HERA-6-QM_FBF_MBE: Free Block FIFO - Single Bit Error detected and corrected Syndrome = 0x10, Addr = 0x778, samebit Yes, diffbit No SLOT 3:Aug 16 00:45:14: %MCC192-6-RED_AQD_MBE: Average Queue Depth - Single Bit Error detected and corrected Syndrome = 0x7, Address = 0x89, samebit No, diffbit No SLOT 2:Jan 23 06:29:56 KST: %MCC192-6-RED_STAT_MBE: Statistics - Single Bit Error detected and corrected Syndrome = 0x38, Address = 0xFF, samebit No, diffbit No
Mensagens de erro SPA
Você pode ver estes erros na saída do console:
SLOT 7:Jan 4 02:04:00.487: %SPA_CHOC_DSX-3-UNCOR_PARITY_ERR: SPA4/0: CHOC SPA parity error(s) encountered SLOT 7:Jan 4 02:04:00.487: %MCT1E1-3-UNCOR_PARITY_ERR: SPA5/0: T1E1 SPA parity error(s) encountered SLOT 3: 00:33:48: %MCT1E1-3-UNCOR_MEM_ERR: SPA3/0: 1 uncorrectable HDLC SRAM memory error(s) encountered. SLOT 1:Oct 3 14:42:45.727: %SPA_PLIM-4-SBE_ECC: SPA-4XT3/E3[1/2] reports 2 SBE occurrence at 1 addresses SLOT 1: Jul 22 05:26:29.613 UTC: %SPA_DATABUS-3-SPI4_SINGLE_DIP4_PARITY: SIP Sbslt 0 Ingress Sink - A single DIP4 parity error has occurred on the data bus. SLOT 4: Dec 2 22:44:05: %SPA_DATABUS-3-SPI4_SINGLE_DIP2_PARITY: SIP Sbslt 0 Egress Source - A single DIP 2 parity error on the FIFO status bus has occurred. SLOT 1:Oct 3 14:42:45.727: %SPA_PLIM-4-SBE_OVERFLOW: SPA-4XT3/E3[1/2] reports SBE table (2 elements) overflows SLOT 1:Oct 3 14:42:45.727: % SPA_PLUGIN-3-SPI4_SETCB: SPA-4XT3/E3[1/2] : IPC SPI4 set callback failed(status 2).
Erros de paridade nos Cisco 12000 Series Switching Fabric Cards
Todas as mensagens de erro de paridade relacionadas às placas de tela de switching são explicadas em detalhes em Hardware Troubleshooting for the Cisco 12000 Series Internet Router (Solução de problemas de hardware do roteador de Internet da série Cisco 12000). Essas mensagens incluem (lista não exaustiva):
%FABRIC-3-PARITYERR: To Fabric parity error was detected. Grant parity error Data = 0x2. SLOT 1:%FABRIC-3-PARITYERR: To Fabric parity error was detected. Grant parity error Data = 0x1
Informações Relacionadas
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)