Como escolher o melhor caminho de switching de roteador para sua rede
Contents
Introduction
Há uma infinidade de caminhos de switching disponíveis para vários roteadores Cisco e versões do Cisco IOS®. Qual é o melhor para a sua rede e como eles funcionam? Esta documentação é uma tentativa de explicar cada um dos seguintes caminhos de switching, para seja possível decidir sobre qual deles melhor se adapta à sua rede.
Primeiro, examine o próprio processo de encaminhamento. Há três etapas para encaminhar um pacote através de um roteador:
-
Determine se o destino do pacote é alcançável.
-
Determine o próximo salto em direção ao destino e a interface através da qual o próximo salto pode ser alcançado.
-
Reescreva o cabeçalho de MAC no pacote para que ele alcance o salto seguinte.
Cada uma dessas etapas é crítica para que o pacote alcance seu destino.
Observação: neste documento, o caminho de switching IP é usado como exemplo; praticamente todas as informações fornecidas aqui são aplicáveis aos caminhos de switching equivalentes para outros protocolos, se houver.
Switching de processo
A comutação de processos é o menor denominador comum nos caminhos de comutação; está disponível em todas as versões do IOS, em todas as plataformas e para todos os tipos de tráfego que estão sendo comutados. A comutação de processos é definida por dois conceitos essenciais:
-
A decisão e as informações de encaminhamento utilizadas para regravar o cabeçalho MAC no pacote são tiradas do cache da tabela de roteamento (da Base de Informações de Roteamento, ou RIB) e do Protocolo de Resolução de Endereços (ARP) ou de alguma outra tabela que contenha as informações de cabeçalho MAC mapeadas para o endereço IP de cada host que esteja diretamente conectado ao roteador.
-
O pacote é comutado por um processo normal em execução no IOS. Em outras palavras, a decisão de encaminhamento é tomada por um processo programado através do agendador do IOS e executado como um par para outros processos no roteador, como protocolos de roteamento. Os processos que normalmente são executados no roteador não são interrompidos para processar um pacote no switch.
A figura abaixo ilustra o caminho de switching do processo.
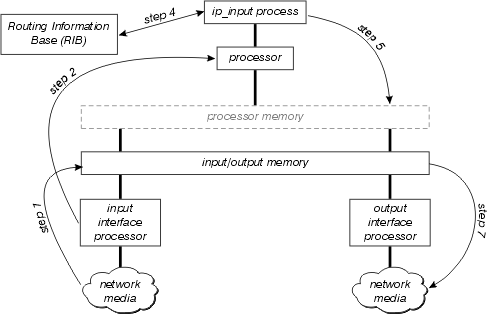
Examine este diagrama com mais detalhes:
-
O processador da interface primeiro detecta que há um pacote na mídia da rede e o transfere à memória de entrada/saída no roteador.
-
O processador de interface gera uma interrupção de recebimento. Durante essa interrupção, o processador central determina que tipo de pacote é esse (suponha que seja um pacote IP) e o copia na memória do processador, se necessário (essa decisão depende da plataforma). Finalmente, o processador coloca o pacote na fila de entrada do processo apropriado e a interrupção é liberada.
-
Na próxima vez em que o agendador for executado, ele perceberá o pacote na fila de entrada de ip_input e agendará a execução deste processo.
-
Quando ip_input é executado, ele consulta o RIB para determinar o próximo salto e a interface de saída, em seguida consulta o cache ARP para determinar o endereço correto da camada física para esse próximo salto.
-
Em seguida, ip_input regrava o cabeçalho de MAC do pacote e coloca esse pacote na fila de saída da interface de saída correta.
-
O pacote é copiado da fila de saída da interface de saída para a fila de transmissão da interface de saída; qualquer qualidade de serviço de saída ocorre entre essas duas filas.
-
O processador de interface de emissor detecta o pacote em sua fila de transmissão e o transfere para a mídia da rede.
Quase todos os recursos que afetam a comutação de pacotes, como Network Address Translation (NAT) e Policy Routing, fazem sua estreia no caminho de comutação de processos. Depois de comprovados e otimizados, esses recursos podem ou não aparecer na comutação de contexto de interrupção.
Interromper a switching de contexto
A comutação de contexto de interrupção é o segundo dos principais métodos de comutação usados pelos roteadores Cisco. As principais diferenças entre a comutação de contexto de interrupção e a comutação de processo são:
-
O processo atualmente em execução no processador é interrompido para comutar o pacote. Os pacotes são comutados sob demanda, em vez de comutados somente quando o processo ip_input pode ser programado.
-
O processador usa alguma forma de cache de rota para encontrar todas as informações necessárias para comutar o pacote.
Esta figura ilustra a comutação de contexto de interrupção:
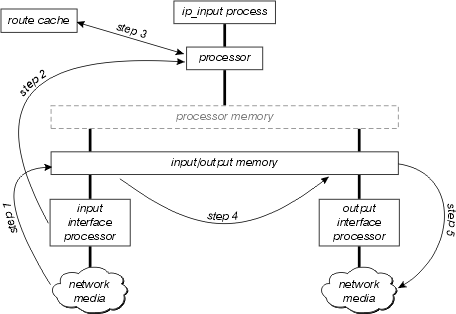
Examine este diagrama com mais detalhes:
-
O processador da interface primeiro detecta que há um pacote na mídia da rede e o transfere à memória de entrada/saída no roteador.
-
O processador de interface gera uma interrupção de recebimento. Durante essa interrupção, o processador central determina que tipo de pacote é esse (suponha que seja um pacote IP) e começa a comutar o pacote.
-
O processador procura no cache de rotas para determinar se o destino do pacote é alcançável, qual deve ser a interface de saída, qual o próximo salto para esse destino e, finalmente, qual cabeçalho MAC o pacote deve ter para alcançar com êxito o próximo salto. O processador usa essas informações para reescrever o cabeçalho MAC do pacote.
-
O pacote agora é copiado para a fila de transmissão ou de saída da interface de saída (dependendo de vários fatores). A interrupção de recebimento agora retorna e o processo que estava sendo executado no processador antes da interrupção continua sendo executado.
-
O processador de interface de emissor detecta o pacote em sua fila de transmissão e o transfere para a mídia da rede.
A primeira pergunta que vem à mente após ler essa descrição é "O que há no cache?" Há três respostas possíveis, dependendo do tipo de switching de contexto de interrupção:
Switching rápida
A comutação rápida armazena as informações de encaminhamento e a string de regravação do cabeçalho MAC usando uma árvore binária para consulta e referência rápidas. Esta figura ilustra uma árvore binária:
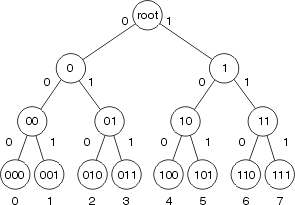
Em Fast Switching, as informações de acessibilidade são indicadas pela existência de um nó na árvore binária para o destino do pacote. O cabeçalho MAC e a interface de saída para cada destino são armazenados como parte das informações do nó na árvore. A árvore binária pode, na verdade, ter 32 níveis (a árvore acima é extremamente abreviada para fins de ilustração).
Para pesquisar uma árvore binária, você simplesmente começa da esquerda (com o dígito mais significativo) no número (binário) que está procurando, e se ramifica à direita ou à esquerda na árvore com base nesse número. Por exemplo, se você estiver procurando as informações relacionadas ao número 4 nesta árvore, você começará pela ramificação para a direita, porque o primeiro dígito binário é 1. Você seguiria a árvore para baixo, comparando o próximo dígito no número (binário), até chegar ao final.
Características do Fast Switching
A switching rápida tem várias características que resultam da estrutura de árvore binária e do armazenamento das informações de regravação do cabeçalho MAC como parte dos nós de árvore.
-
Como não há correlação entre a tabela de roteamento e o conteúdo rápido do cache (regravação de cabeçalho MAC, por exemplo), criar entradas de cache envolve todo o processamento que deve ser feito no caminho de switching do processo. Portanto, entradas rápidas de cache são criadas à medida que os pacotes são comutados por processo.
-
Como não há correlação entre os cabeçalhos MAC (usados para regravações) no cache ARP e a estrutura do cache rápido, quando a tabela ARP muda, alguma parte do cache rápido deve ser invalidada (e recriada através da comutação de processos de pacotes).
-
O cache rápido só pode criar entradas em uma profundidade (um comprimento de prefixo) para qualquer destino específico na tabela de roteamento.
-
Não há como apontar de uma entrada para outra dentro do cache rápido (espera-se que as informações do cabeçalho MAC e da interface de saída estejam dentro do nó), portanto, todas as recursões de roteamento devem ser resolvidas enquanto uma entrada rápida do cache está sendo criada. Em outras palavras, rotas recursivas não podem ser resolvidas dentro do próprio cache rápido.
Envelhecimento de Entradas de Switching Rápida
Para impedir que as entradas de switching rápida percam sua sincronização com a tabela de roteamento e o cache ARP, e para impedir que as entradas não utilizadas no cache rápido consumam memória injustificada no roteador, 1/20 do cache rápido é invalidado, aleatoriamente, a cada minuto. Se a memória do roteador cair abaixo de uma marca d'água muito baixa, 1/5 das entradas de cache rápido serão invalidadas a cada minuto.
Comprimento de prefixo de switching rápida
Para qual comprimento de prefixo a switching rápida cria entradas se apenas pode criar para um comprimento de prefixo em cada destino? Dentro dos termos de switching rápida, um destino é um único destino alcançável na tabela de roteamento, ou uma rede principal. As regras para decidir qual comprimento do prefixo construir uma determinada entrada de cache são:
-
Se estiver criando uma entrada de política de ocupado, sempre armazene em cache em /32.
-
Ao criar uma entrada com base em multiprotocolo no circuito virtual do ATM (MPOA VC), faça sempre o armazenamento em cache para /32.
-
Se a rede não estiver dividida em sub-redes (sendo, portanto, uma entrada de rede principal):
-
Se estiver diretamente conectado, use /32;
-
Caso contrário, use a máscara de rede principal.
-
-
Se for uma supernet, use a máscara de supernet.
-
Se a rede for colocada em sub-rede:
-
Se conectado diretamente, use /32;
-
Se há múltiplos caminhos para essa sub-rede, utilize /32;
-
Em todos os outros casos, use o comprimento de prefixo mais longo nessa rede principal.
-
Compartilhamento de carga
A comutação rápida é totalmente baseada no destino; o compartilhamento de carga ocorre por destino. Se houver vários caminhos de custo igual para uma rede de destino específica, o cache rápido tem uma entrada para cada host alcançável nessa rede, mas todo o tráfego destinado a um host específico segue um link.
Switching ideal
A comutação ideal armazena as informações de encaminhamento e as informações de regravação do cabeçalho MAC em uma árvore multiway de 256 vias (mtree de 256 vias). O uso de uma árvore reduz o número de etapas que devem ser realizadas ao procurar um prefixo, como ilustrado na figura a seguir.
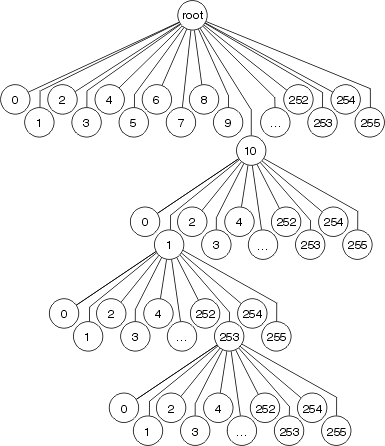
Cada octeto é usado para determinar qual das 256 ramificações tomar em cada nível da árvore, o que significa que há, no máximo, 4 pesquisas envolvidas na localização de qualquer destino. Para comprimentos de prefixo mais curtos, somente uma ou três pesquisas podem ser necessárias. As informações da interface de saída e reescrita do cabeçalho MAC são armazenadas como parte do nó da árvore, de modo que a invalidação do cache e o envelhecimento ainda ocorrem como na comutação rápida.
A switching ideal também determina o comprimento do prefixo para cada entrada cache do mesmo modo que a switching rápida.
Cisco Express Forwarding
O Cisco Express Forwarding também usa uma estrutura de dados de 256 vias para armazenar informações de encaminhamento e reescrita de cabeçalho MAC, mas não usa uma árvore. O Cisco Express Forwarding usa uma trie, o que significa que as informações reais que estão sendo pesquisadas não estão na estrutura de dados; em vez disso, os dados são armazenados em uma estrutura de dados separada, e a trie simplesmente aponta para ela. Em outras palavras, em vez de armazenar a interface de saída e a reescrita do cabeçalho MAC dentro da própria árvore, o Cisco Express Forwarding armazena essas informações em uma estrutura de dados separada chamada tabela de adjacência.
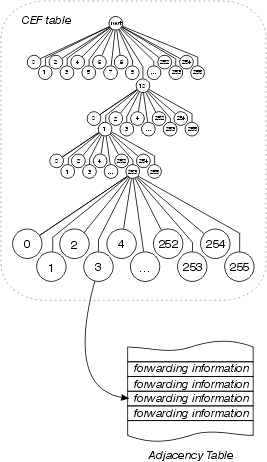
Esta separação das informações de acessibilidade (na tabela de Cisco Express Forwarding) e informações de encaminhamento (na tabela de adjacência) fornece diversos benefícios:
-
A tabela de adjacências pode ser criada separadamente da tabela Cisco Express Forwarding, permitindo que ambos sejam construídos sem a comutação de processos de pacotes.
-
A regravação do cabeçalho MAC usada para encaminhar um pacote não é armazenada em entradas de cache, portanto as alterações em uma string de regravação do cabeçalho MAC não exigem a invalidação das entradas de cache.
-
Você pode apontar diretamente para as informações de encaminhamento, em vez do próximo salto recursivo, para resolver rotas recursivas.
Essencialmente, todo o envelhecimento do cache é eliminado, e o cache é pré-criado com base nas informações contidas na tabela de roteamento e no cache ARP. Não há necessidade de processar qualquer pacote de switch para criar uma entrada de cache.
Outras entradas na tabela Adjacência
A tabela de adjacências pode conter entradas diferentes das strings de regravação de cabeçalho MAC e das informações de interface de saída. Alguns dos vários tipos de entradas que podem ser colocadas na tabela de adjacência incluem:
-
cache —Uma string de regravação do cabeçalho MAC e uma interface de saída usadas para alcançar um host ou roteador adjacente específico.
-
receive —Os pacotes destinados a este endereço IP devem ser recebidos pelo roteador. Isso inclui endereços de broadcast e endereços configurados no próprio roteador.
-
drop — Pacotes destinados a este endereço IP devem ser descartados. Isso pode ser usado para o tráfego negado por uma lista de acesso ou roteado para uma interface NULL.
-
punt — O Cisco Express Forwarding não pode comutar este pacote; transmita-o ao próximo método de switching mais conveniente (em geral, switching rápida) para processamento.
-
glean — O salto seguinte está diretamente conectado, mas não há strings de regravação de cabeçalho MAC disponíveis no momento.
Adjacências Glean
Uma entrada de adjacência glean indica que um próximo salto específico deve ser conectado diretamente, mas não há informações de regravação de cabeçalho MAC disponíveis. Como eles são construídos e usados? Um roteador executando o Cisco Express Forwarding e conectado a uma rede de transmissão, como mostrado na figura a seguir, cria algumas entradas da tabela de adjacência por padrão.
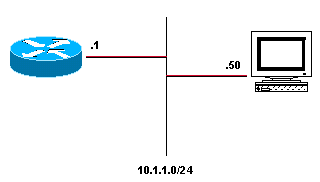
As quatro entradas da tabela de adjacência criadas por padrão são:
10.1.1.0/24, version 17, attached, connected
0 packets, 0 bytes
via Ethernet2/0, 0 dependencies
valid glean adjacency
10.1.1.0/32, version 4, receive
10.1.1.1/32, version 3, receive
10.1.1.255/32, version 5, receive
Observe que existem quatro entradas: três recebem e um ganha. Cada entrada de recepção representa um endereço de broadcast ou um endereço configurado no roteador, enquanto a entrada glean representa o restante do espaço de endereço na rede conectada. Se um pacote for recebido para o host 10.1.1.50, o roteador tentará comutá-lo e o encontrará resolvido para essa adjacência glean. O Cisco Express Forwarding sinaliza que uma entrada de cache ARP é necessária para 10.1.1.50, o processo ARP envia um pacote ARP e a entrada de tabela de adjacência apropriada é criada a partir das novas informações de cache ARP. Após a conclusão desta etapa, a tabela de adjacência tem uma entrada para 10.1.1.50.
10.1.1.0/24, version 17, attached, connected
0 packets, 0 bytes
via Ethernet2/0, 0 dependencies
valid glean adjacency
10.1.1.0/32, version 4, receive
10.1.1.1/32, version 3, receive
10.1.1.50/32, version 12, cached adjacency 208.0.3.2
0 packets, 0 bytes
via 208.0.3.2, Ethernet2/0, 1 dependency
next hop 208.0.3.2, Ethernet2/0
valid cached adjacency
10.1.1.255/32, version 5, receive
O próximo pacote que o roteador recebe destinado a 10.1.1.50 é comutado por meio desta nova adjacência.
Compartilhamento de carga
O Cisco Express Forwarding também aproveita a separação entre a tabela Cisco Express Forwarding e a tabela de adjacência para fornecer uma forma melhor de compartilhamento de carga do que qualquer outro modo de switching de contexto de interrupção. Uma tabela de compartilhamento de carga é inserida entre a tabela Cisco Express Forwarding e a tabela de adjacência, como ilustrado nesta figura:
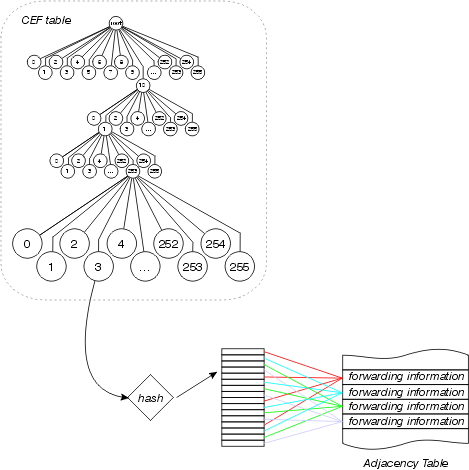
A tabela Cisco Express Forwarding aponta para esta tabela de compartilhamento de carga, que contém indicadores para as várias entradas da tabela de adjacência para caminhos paralelos disponíveis. Os endereços origem e destino são passados por um algoritmo hash para determinar qual entrada da tabela de compartilhamento de carga usar para cada pacote. O compartilhamento de carga por pacote pode ser configurado, caso em que cada pacote usa uma entrada diferente da tabela de compartilhamento de carga.
Cada tabela de compartilhamento de carga tem 16 entradas entre as quais os caminhos disponíveis são divididos com base no contador de compartilhamento de tráfego na tabela de roteamento. Se os contadores de compartilhamento de tráfego na tabela de roteamento forem todos 1 (como no caso de vários caminhos de custo igual), cada próximo salto possível receberá um número igual de ponteiros da tabela de compartilhamento de carga. Se o número de caminhos disponíveis não for uniformemente divisível em 16 (já que há 16 entradas na tabela de compartilhamento de carga), alguns caminhos terão mais entradas que outros.
Começando no Cisco IOS Software Release 12.0, o número de entradas na tabela de compartilhamento de carga é reduzido para garantir que cada caminho tenha um número proporcional de entradas na tabela de compartilhamento de carga. Por exemplo, se houver três caminhos de custo igual na tabela de roteamento, somente 15 entradas da tabela de compartilhamento de carga serão usadas.
Qual é o melhor caminho de switching?
Sempre que possível, você deseja que os roteadores estejam alternando no contexto de interrupção porque é pelo menos uma ordem de magnitude mais rápida que a switching no nível do processo. O switching do Cisco Express Forwarding é definitivamente mais rápido e melhor do que qualquer outro modo de switching. Recomendamos que você use o Cisco Express Forwarding se o protocolo e o IOS que você está executando o suportarem. Isso é particularmente verdadeiro se você tiver vários links paralelos através dos quais o tráfego deve ser compartilhado de carga. Acesse a página Cisco Feature Navigator (somente clientes registrados) para determinar qual IOS você precisa para suporte CEF.
Informações Relacionadas
- Como verificar a switching Cisco Express Forwarding
- Troubleshooting do balanceamento de carga em links paralelos usando o Cisco Express Forwarding
- Balanceamento de carga com CEF
- Página de suporte do Cisco Express Forwarding
- Página de Suporte do IP Routing
- Guia de configuração de serviços de switching do Cisco IOS, versão 12.1
- Suporte Técnico - Cisco Systems
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)