Substituição do servidor de computação UCS C240 M4 - CPAR
Opções de download
Linguagem imparcial
O conjunto de documentação deste produto faz o possível para usar uma linguagem imparcial. Para os fins deste conjunto de documentação, a imparcialidade é definida como uma linguagem que não implica em discriminação baseada em idade, deficiência, gênero, identidade racial, identidade étnica, orientação sexual, status socioeconômico e interseccionalidade. Pode haver exceções na documentação devido à linguagem codificada nas interfaces de usuário do software do produto, linguagem usada com base na documentação de RFP ou linguagem usada por um produto de terceiros referenciado. Saiba mais sobre como a Cisco está usando a linguagem inclusiva.
Sobre esta tradução
A Cisco traduziu este documento com a ajuda de tecnologias de tradução automática e humana para oferecer conteúdo de suporte aos seus usuários no seu próprio idioma, independentemente da localização. Observe que mesmo a melhor tradução automática não será tão precisa quanto as realizadas por um tradutor profissional. A Cisco Systems, Inc. não se responsabiliza pela precisão destas traduções e recomenda que o documento original em inglês (link fornecido) seja sempre consultado.
Contents
Introduction
Este documento descreve as etapas necessárias para substituir um servidor de computação defeituoso em uma configuração Ultra-M.
Este procedimento aplica-se a um ambiente Openstack usando a versão NEWTON em que o controlador de servidor elástico (ESC) não gerencia o Cisco Prime Access Registrar (CPAR) e o CPAR é instalado diretamente na VM implantada no Openstack.
Informações de Apoio
O Ultra-M é uma solução de núcleo de pacotes móveis virtualizados pré-embalada e validada, projetada para simplificar a implantação de VNFs. O OpenStack é o Virtualized Infrastructure Manager (VIM) para Ultra-M e consiste nos seguintes tipos de nó:
- Computação
- Disco de Armazenamento de Objeto - Computação (OSD - Compute)
- Controlador
- Plataforma OpenStack - Diretor (OSPD)
A arquitetura de alto nível da Ultra-M e os componentes envolvidos estão descritos nesta imagem:
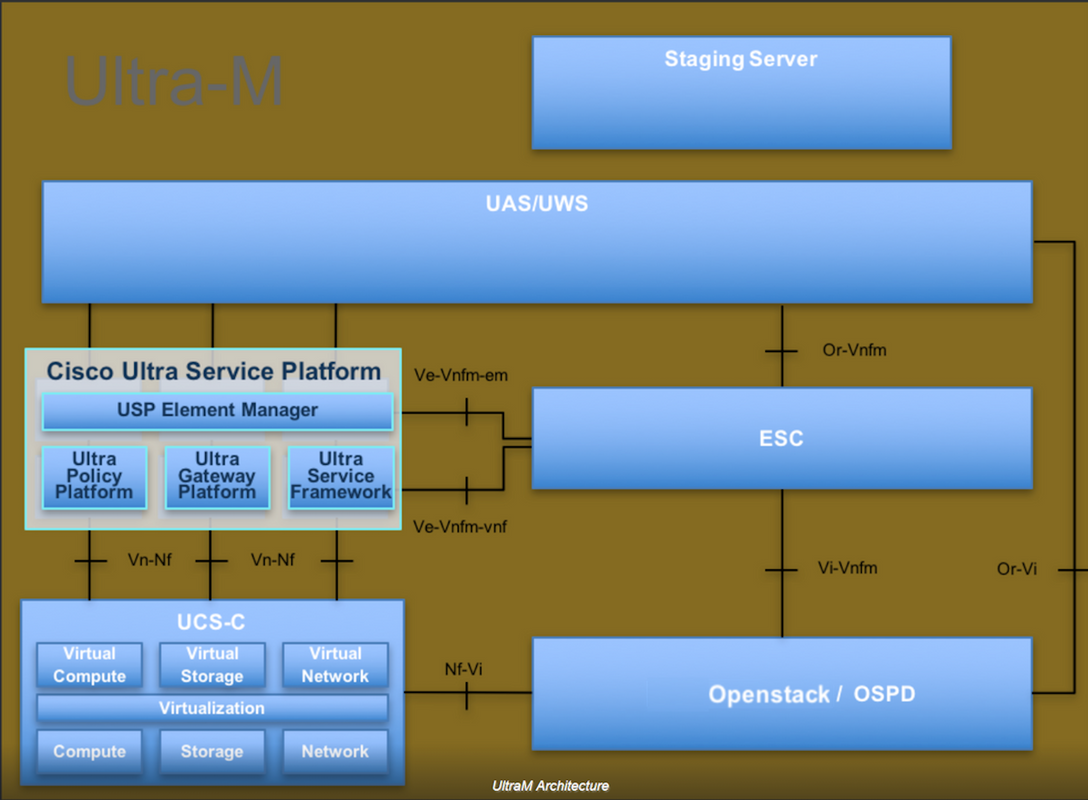
Este documento destina-se aos funcionários da Cisco que estão familiarizados com a plataforma Cisco Ultra-M e detalha as etapas necessárias para serem executadas no OpenStack e no sistema operacional Redhat.
Note: A versão Ultra M 5.1.x é considerada para definir os procedimentos neste documento.
Abreviaturas
| MOP | Método de Procedimento |
| OSD | Discos de Armazenamento de Objeto |
| OSPD | OpenStack Platform Diretor |
| HDD | Unidade de disco rígido |
| SSD | Unidade de estado sólido |
| VIM | Virtual Infrastructure Manager |
| VM | Máquina virtual |
| EM | Gestor de Elementos |
| UAS | Ultra Automation Services |
| UUID | Identificador de ID universal exclusivo |
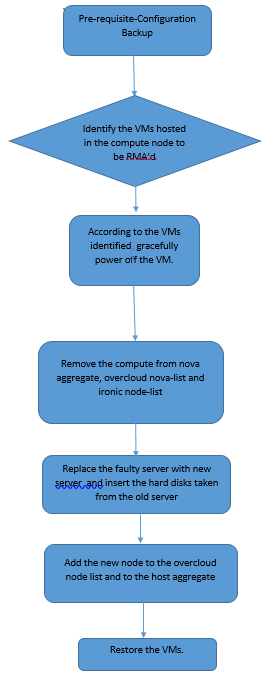
Fluxo de trabalho do MoP
Prerequisites
Backup
Antes de substituir um nó de computação, é importante verificar o estado atual do ambiente da plataforma Red Hat OpenStack. Recomenda-se que você verifique o estado atual para evitar complicações quando o processo de substituição Compute estiver ativo. Isso pode ser feito por meio desse fluxo de substituição.
Em caso de recuperação, a Cisco recomenda fazer um backup do banco de dados OSPD com o uso destas etapas:
[root@ al03-pod2-ospd ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@ al03-pod2-ospd ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
Esse processo garante que um nó possa ser substituído sem afetar a disponibilidade de quaisquer instâncias.
Note: Certifique-se de ter o instantâneo da instância para que você possa restaurar a VM quando necessário. Siga o procedimento abaixo sobre como fazer um snapshot da VM.
Identificar as VMs hospedadas no nó de computação
Identifique as VMs hospedadas no servidor de computação.
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
Note: Na saída mostrada aqui, a primeira coluna corresponde ao UUID (Universal Unique IDentifier), a segunda coluna é o nome da VM e a terceira coluna é o nome do host onde a VM está presente. Os parâmetros dessa saída serão usados em seções subsequentes.
Processo de Instantâneo
Desligamento do aplicativo CPAR
Etapa 1. Abra qualquer cliente SSH conectado à rede e conecte-se à instância do CPAR.
É importante não desligar todas as 4 instâncias de AAA em um site ao mesmo tempo, fazer isso de uma forma por uma.
Etapa 2. Desative o aplicativo CPAR com este comando:
/opt/CSCOar/bin/arserver stop
Uma mensagem informa "Cisco Prime Access Registrar Server Agent shutdown complete". deve aparecer.
Note: Se um usuário deixou uma sessão CLI aberta, o comando arserver stop não funcionará e a seguinte mensagem será exibida:
ERROR: You can not shut down Cisco Prime Access Registrar while the
CLI is being used. Current list of running
CLI with process id is:
2903 /opt/CSCOar/bin/aregcmd –s
Neste exemplo, a ID de processo 2903 destacada precisa ser encerrada para que o CPAR possa ser interrompido. Se for esse o caso, encerre o processo com este comando:
kill -9 *process_id*
Em seguida, repita a etapa 1.
Etapa 3. Verifique se o aplicativo CPAR foi desligado por este comando:
/opt/CSCOar/bin/arstatus
Essas mensagens devem aparecer:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
Tarefa de Instantâneo da VM
Etapa 1. Digite o site da GUI do Horizon que corresponde ao Site (Cidade) em que está sendo trabalhado. Quando o Horizonte é acessado, a tela mostrada na imagem é observada:
Etapa 2. Como mostrado na imagem, navegue para Project > Instances.
Se o usuário usado for cpar, somente as 4 instâncias AAA aparecerão neste menu.
Etapa 3. Desligar apenas uma instância por vez, repita todo o processo neste documento. Para desligar a VM, navegue para Ações > Desligar instância e confirme sua seleção.

Etapa 4 Validar se a instância foi realmente desligada por Status = Desligamento e Estado de energia = Desligado.
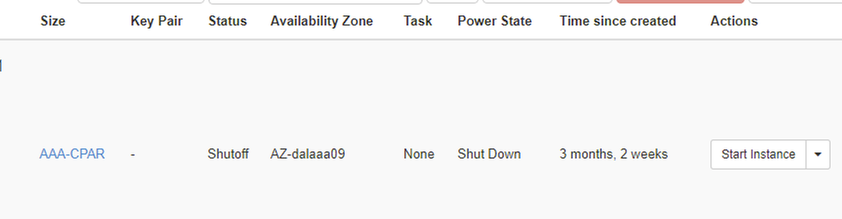
Esta etapa encerra o processo de encerramento do CPAR.
Instantâneo de VM
Quando as VMs CPAR estiverem desativadas, os snapshots podem ser obtidos em paralelo, pois pertencem a computadores independentes.
Os quatro arquivos QCOW2 são criados em paralelo.
Tire um instantâneo de cada instância AAA (25 minutos - 1 hora) (25 minutos para instâncias que usaram uma imagem de qcou como origem e 1 hora para instâncias que usam uma imagem bruta como origem).
Etapa 1. Faça login na GUI do Openstack do POD.
Etapa 2. Depois de fazer login, vá para a seção Project > Compute > Instances, no menu superior e procure as instâncias de AAA.
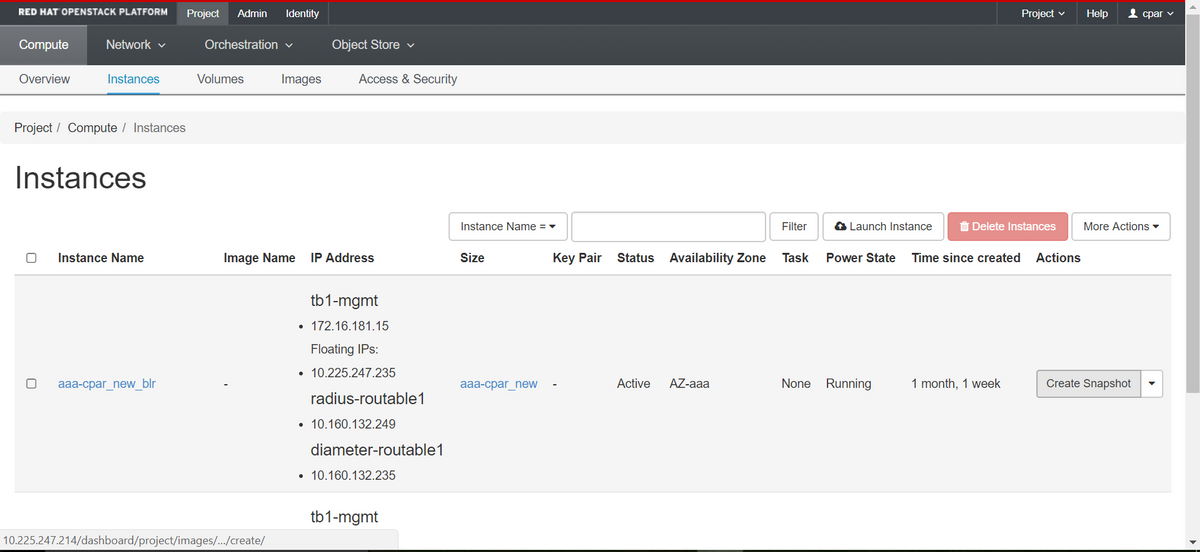
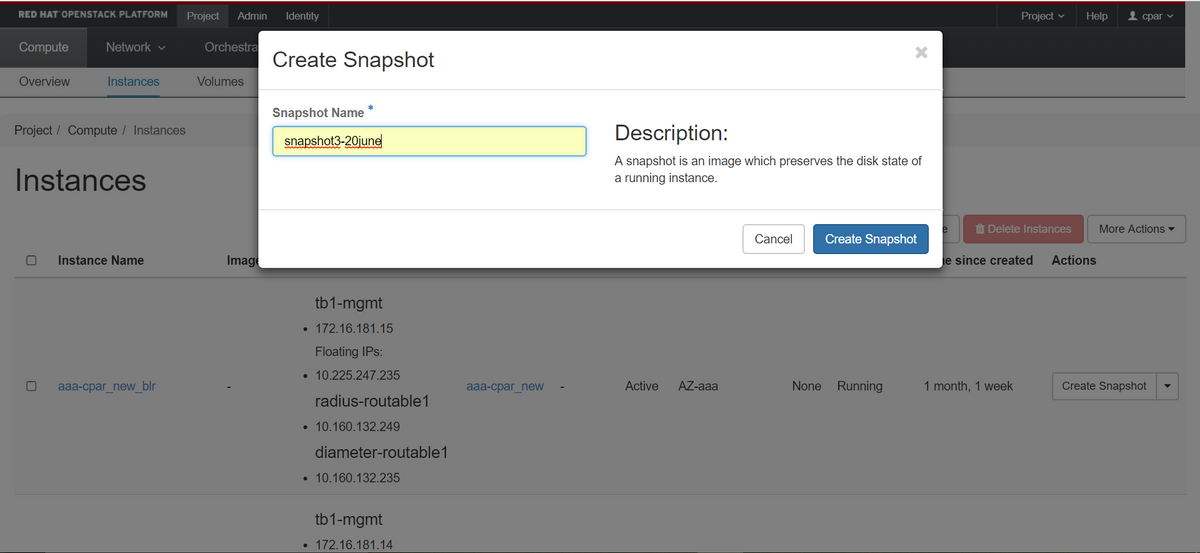
Etapa 3. Clique em Criar instantâneo para continuar com a criação de instantâneos (isso precisa ser executado na instância AAA correspondente).
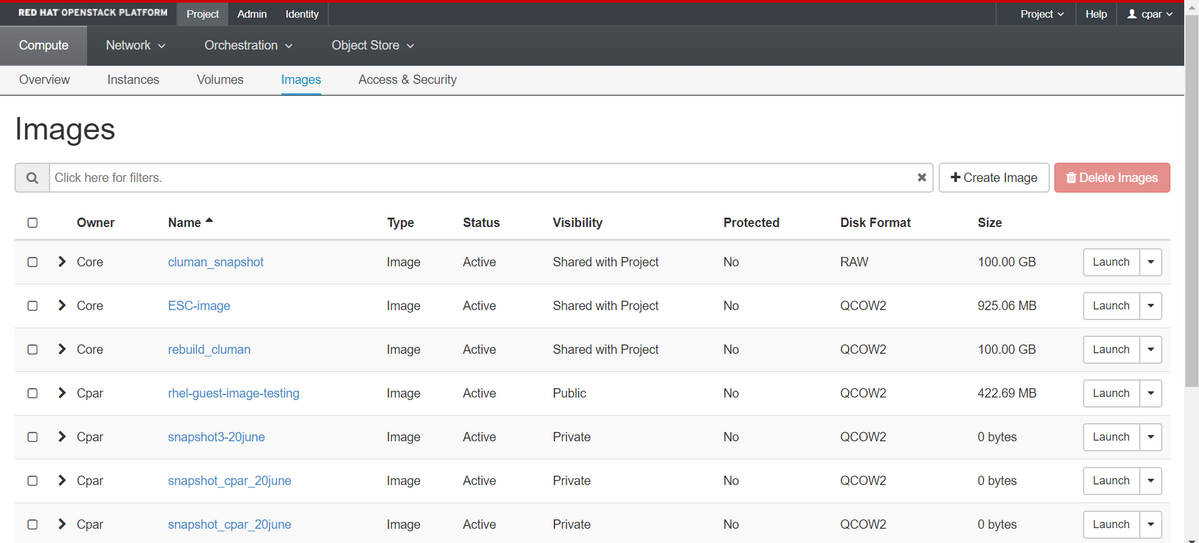
Etapa 4. Depois que o snapshot for executado, navegue até o menu Imagens e verifique se ele termina e informa nenhum problema.
Etapa 5. A próxima etapa é baixar o snapshot em um formato QCOW2 e transferi-lo para uma entidade remota caso o OSPD seja perdido durante esse processo. Para conseguir isso, identifique o snapshot com este comando glance image-list no nível OSPD
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Etapa 6. Depois de identificado o snapshot a ser baixado (nesse caso será o marcado acima em verde), ele será baixado em um formato QCOW2 por meio desse comando glance image-download, como mostrado aqui.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- O "&" envia o processo ao segundo plano. Leva algum tempo para concluir esta ação, uma vez concluída, a imagem pode ser localizada no diretório /tmp.
- Quando o processo é enviado ao segundo plano, se a conectividade é perdida, o processo também é interrompido.
- Execute o comando disown -h para que, caso a conexão do Secure Shell (SSH) seja perdida, o processo ainda seja executado e concluído no OSPD.
Passo 7. Quando o processo de download for concluído, um processo de compactação precisará ser executado, pois esse snapshot poderá ser preenchido com ZEROES devido a processos, tarefas e arquivos temporários tratados pelo sistema operacional. O comando a ser usado para compactação de arquivos é virt-sparsify.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Esse processo leva algum tempo (cerca de 10 a 15 minutos). Uma vez concluído, o arquivo resultante é aquele que precisa ser transferido para uma entidade externa conforme especificado na próxima etapa.
A verificação da integridade do arquivo é necessária, para conseguir isso, execute o próximo comando e procure o atributo corrompido no final de sua saída.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Para evitar um problema em que o OSPD é perdido, o snapshot recém-criado no formato QCOW2 precisa ser transferido para uma entidade externa. Antes de iniciar a transferência de arquivos, precisamos verificar se o destino tem espaço em disco disponível suficiente, use o comando df -kh, para verificar o espaço de memória. Recomenda-se transferi-lo temporariamente para o OSPD de outro site através do SFTP sftp root@x.x.x.x, onde x.x.x.x é o IP de um OSPD remoto. Para acelerar a transferência, o destino pode ser enviado a vários OSPDs. Da mesma forma, esse comando pode ser usado scp *name_of_the_file*.qcou2 root@ x.x.x.x:/tmp (onde x.x.x.x é o IP de um OSPD remoto) para transferir o arquivo para outro OSPD.
Desligamento normal
Desligar nó
- Para desligar a instância: nova stop <INSTANCE_NAME>
- Agora você vê o nome da instância com o status shutoff.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Eliminação do nó de computação
As etapas mencionadas nesta seção são comuns independentemente das VMs hospedadas no nó de computação.
Excluir nó de computação da lista de serviços
Exclua o serviço de computação da lista de serviços:
[stack@director ~]$ openstack compute service list |grep compute-3 | 138 | nova-compute | pod2-stack-compute-3.localdomain | AZ-aaa | enabled | up | 2018-06-21T15:05:37.000000 |
openstack computação service delete <ID>
[stack@director ~]$ openstack compute service delete 138
Excluir Agentes Neutron
Exclua o antigo agente de nêutrons associado e o agente de vswitch aberto para o servidor de computação:
[stack@director ~]$ openstack network agent list | grep compute-3 | 3b37fa1d-01d4-404a-886f-ff68cec1ccb9 | Open vSwitch agent | pod2-stack-compute-3.localdomain | None | True | UP | neutron-openvswitch-agent |
openstack network agent delete <ID>
[stack@director ~]$ openstack network agent delete 3b37fa1d-01d4-404a-886f-ff68cec1ccb9
Excluir do banco de dados irônico
Exclua um nó do banco de dados irônico e verifique-o:
nova show <computação-node> | hipervisor grep
[root@director ~]# source stackrc [root@director ~]# nova show pod2-stack-compute-4 | grep hypervisor | OS-EXT-SRV-ATTR:hypervisor_hostname | 7439ea6c-3a88-47c2-9ff5-0a4f24647444
ironic node-delete <ID>
[stack@director ~]$ ironic node-delete 7439ea6c-3a88-47c2-9ff5-0a4f24647444 [stack@director ~]$ ironic node-list
O nó excluído não deve estar listado agora na ironic node-list.
Excluir do Overcloud
Etapa 1. Crie um arquivo de script chamado delete_node.sh com o conteúdo como mostrado. Certifique-se de que os modelos mencionados sejam os mesmos usados no script Deployment.sh usado para a implantação da pilha:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack <stack-name> <UUID>
[stack@director ~]$ source stackrc [stack@director ~]$ /bin/sh delete_node.sh + openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod2-stack 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Deleting the following nodes from stack pod2-stack: - 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae real 0m52.078s user 0m0.383s sys 0m0.086s
Etapa 2. Aguarde até que a operação da pilha do OpenStack passe para o estado COMPLETO:
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod2-stack | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
Instale o novo nó de computação
As etapas para instalar um novo servidor UCS C240 M4 e as etapas de configuração inicial podem ser consultadas a partir do Guia de instalação e serviços do servidor Cisco UCS C240 M4
Etapa 1. Após a instalação do servidor, insira os discos rígidos nos respectivos slots como o servidor antigo.
Etapa 2. Faça login no servidor com o uso do IP do CIMC.
Etapa 3. Execute a atualização do BIOS se o firmware não estiver de acordo com a versão recomendada usada anteriormente. As etapas para a atualização do BIOS são fornecidas aqui: Guia de atualização do BIOS de servidor com montagem em rack Cisco UCS C-Series
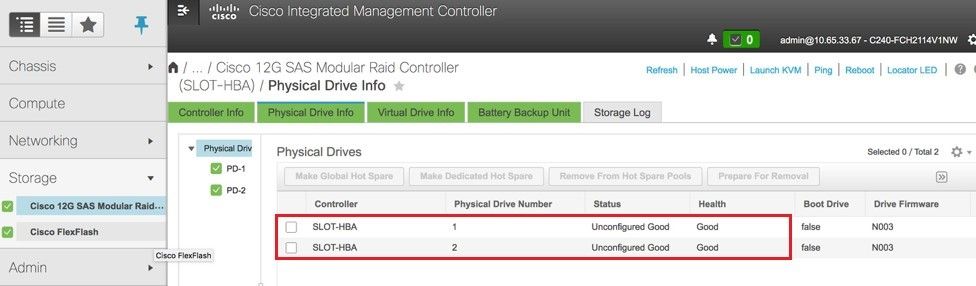
Etapa 4. Para verificar o status das unidades físicas, que é Inconfigurável em boas condições, navegue para Armazenamento > Controlador RAID modular SAS Cisco 12G (SLOT-HBA) > Informações da unidade física.
Etapa 5. Para criar uma unidade virtual a partir das unidades físicas com RAID Nível 1, navegue para Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Controller Info > Create Virtual Drive from Unused Physical Drives (Armazenamento > Controlador RAID modular SAS Cisco 12G) > Informações do controlador > Criar unidade virtual a partir de unidades físicas não utilizadas.
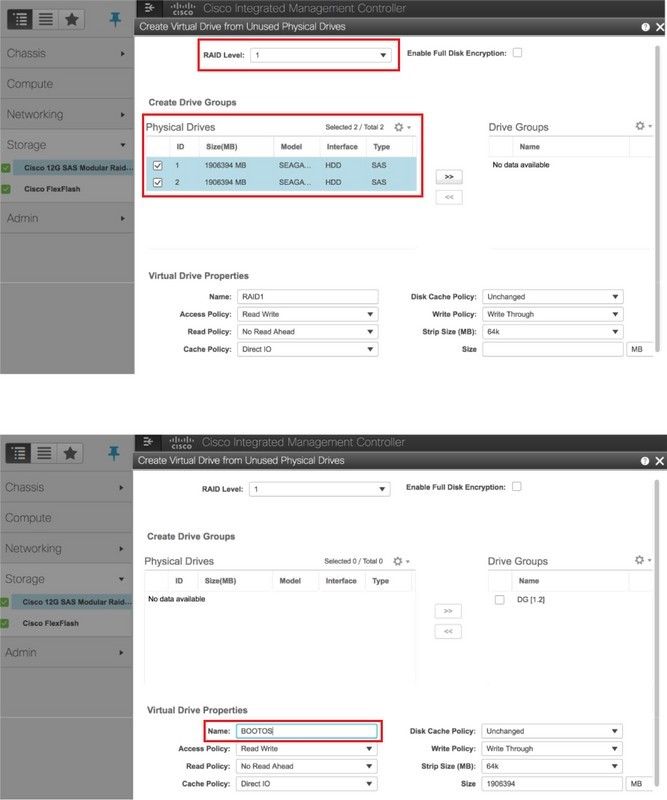
Etapa 6. Selecione o VD e configure Set as Boot Drive (Definir como unidade de inicialização), como mostrado na imagem.

Passo 7. Para habilitar o IPMI na LAN, navegue até Admin > Communication Services > Communication Services, como mostrado na imagem.

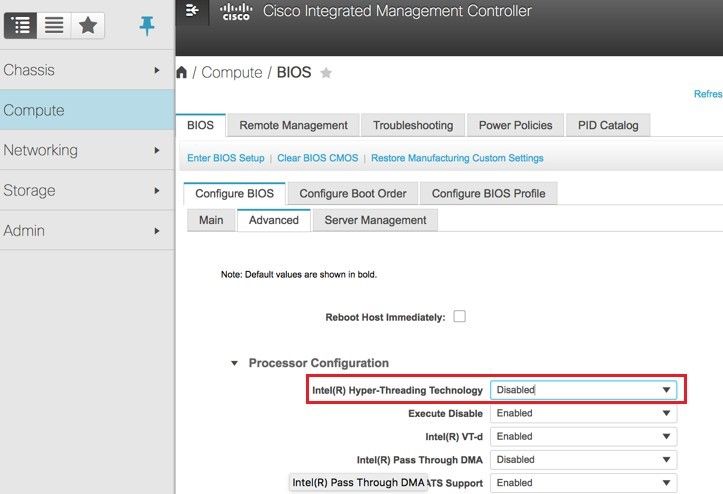
Etapa 8. Para desabilitar o hyperthreading, navegue para Compute > BIOS > Configure BIOS > Advanced > Processor Configuration.
Note: A imagem mostrada aqui e as etapas de configuração mencionadas nesta seção referem-se à versão de firmware 3.0(3e) e pode haver pequenas variações se você trabalhar em outras versões.
Adicione o novo nó de computação à nuvem geral
As etapas mencionadas nesta seção são comuns independentemente da VM hospedada pelo nó de computação.
Etapa 1. Adicionar servidor de computação com um índice diferente
Crie um arquivo add_node.json com apenas os detalhes do novo servidor de computação a ser adicionado. Certifique-se de que o número de índice do novo servidor de computação não tenha sido usado antes. Normalmente, incremente o próximo valor de computação mais alto.
Exemplo: O mais alto anterior foi o computador-17, portanto, criou o computador-18 no caso do sistema de 2 vnf.
Note: Lembre-se do formato json.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
Etapa 2. Importar o arquivo json.
[stack@director ~]$ openstack baremetal import --json add_node.json Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e Successfully set all nodes to available.
Etapa 3. Execute a introspecção de nó com o uso do UUID observado na etapa anterior.
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e [stack@director ~]$ ironic node-list |grep 7eddfa87 | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False | [stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c Waiting for introspection to finish... Successfully introspected all nodes. Introspection completed. Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9 Successfully set all nodes to available. [stack@director ~]$ ironic node-list |grep available | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
Etapa 4. Execute o script Deployment.sh que foi usado anteriormente para implantar a pilha, para adicionar o novo modo de computação à pilha da nuvem:
[stack@director ~]$ ./deploy.sh ++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180 … Starting new HTTP connection (1): 192.200.0.1 "POST /v2/action_executions HTTP/1.1" 201 1695 HTTP POST http://192.200.0.1:8989/v2/action_executions 201 Overcloud Endpoint: http://10.1.2.5:5000/v2.0 Overcloud Deployed clean_up DeployOvercloud: END return value: 0 real 38m38.971s user 0m3.605s sys 0m0.466s
Etapa 5. Aguarde a conclusão do status da pilha de openstack.
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
Etapa 6. Verifique se o novo nó de computação está no estado Ativo.
[root@director ~]# nova list | grep pod2-stack-compute-4 | 5dbac94d-19b9-493e-a366-1e2e2e5e34c5 | pod2-stack-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.116 |
Restaure as VMs
Recuperar uma instância por meio de instantâneo
Processo de recuperação:
É possível reimplantar a instância anterior com o snapshot realizado nas etapas anteriores.
Etapa 1 [OPCIONAL]. Se não houver nenhum VMsnapshot anterior disponível, conecte-se ao nó OSPD onde o backup foi enviado e faça o sftp de volta ao nó OSPD original. Através de sftp root@x.x.x.x, onde x.x.x.x é o IP do OSPD original. Salve o arquivo de snapshot no diretório /tmp.
Etapa 2. Conecte-se ao nó OSPD onde a instância é reimplantada.

Origem das variáveis de ambiente com o seguinte comando:
# source /home/stack/pod1-stackrc-Core-CPAR
Etapa 3. Usar o snapshot como uma imagem é necessário para carregá-lo no horizonte como tal. Use o próximo comando para fazer isso.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
O processo pode ser visto no horizonte.

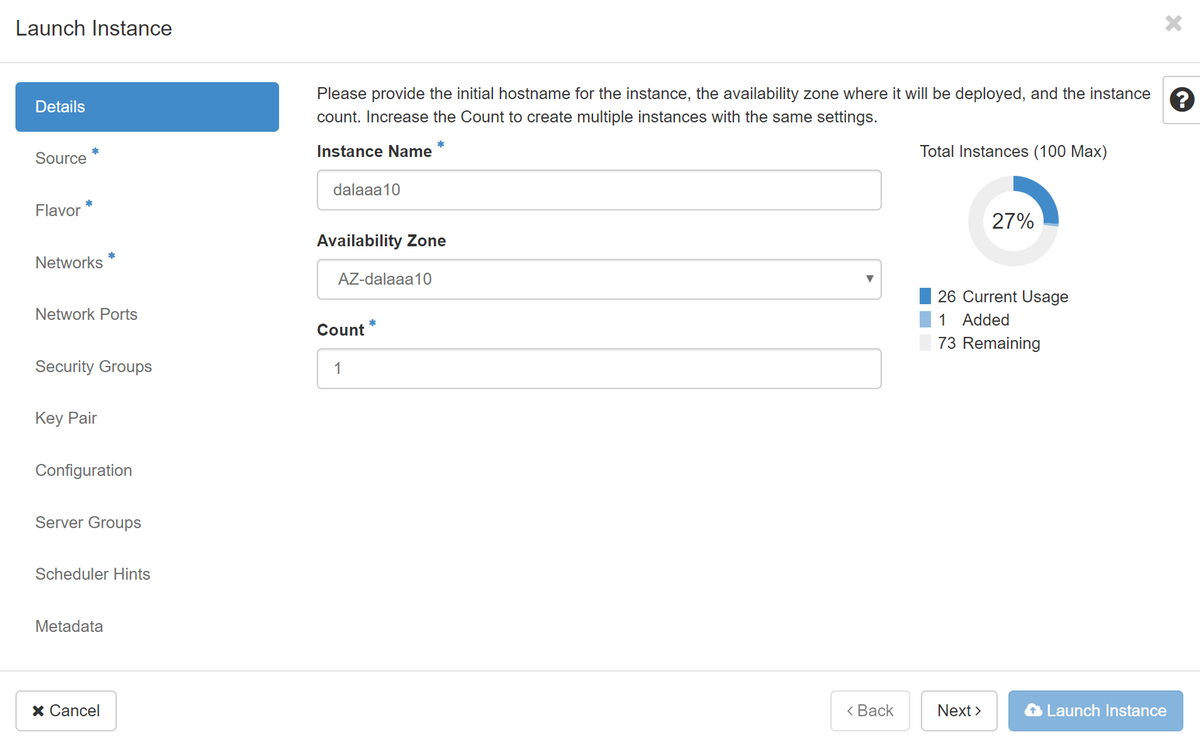
Etapa 4. No Horizon, navegue até Project > Instances e clique em Launch Instance, como mostrado na imagem.

Etapa 5. Digite o Nome da instância e escolha a Zona de disponibilidade, como mostrado na imagem.
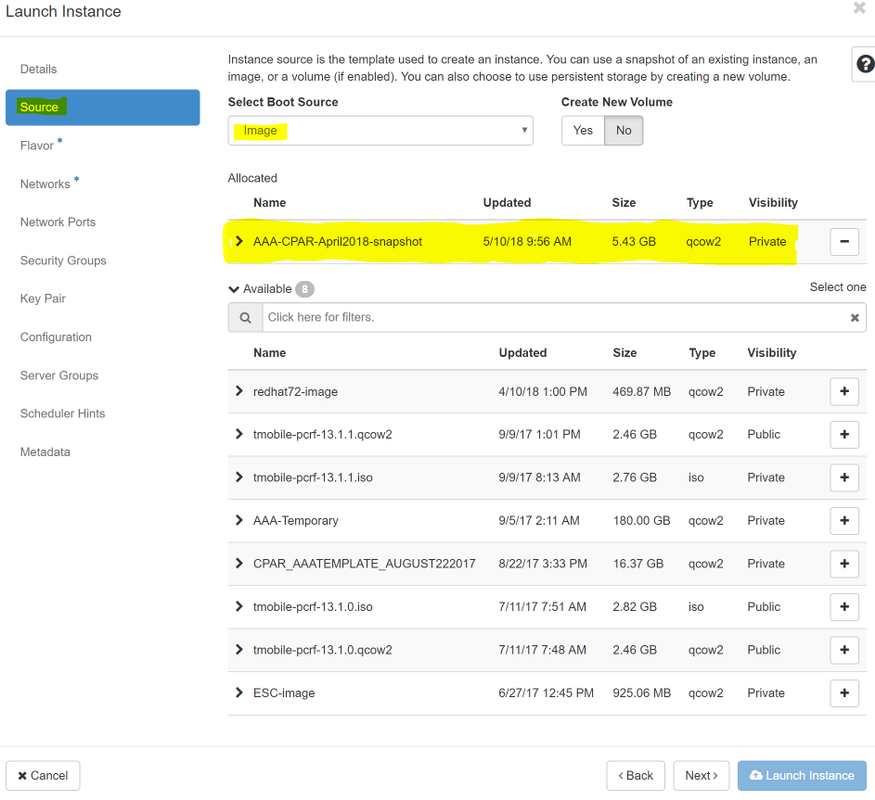
Etapa 6. Na guia Origem, escolha a imagem para criar a instância. No menu Select Boot Source (Selecionar fonte de inicialização) selecione image, uma lista de imagens é mostrada aqui; escolha a que foi carregada anteriormente quando você clica no + sinal.
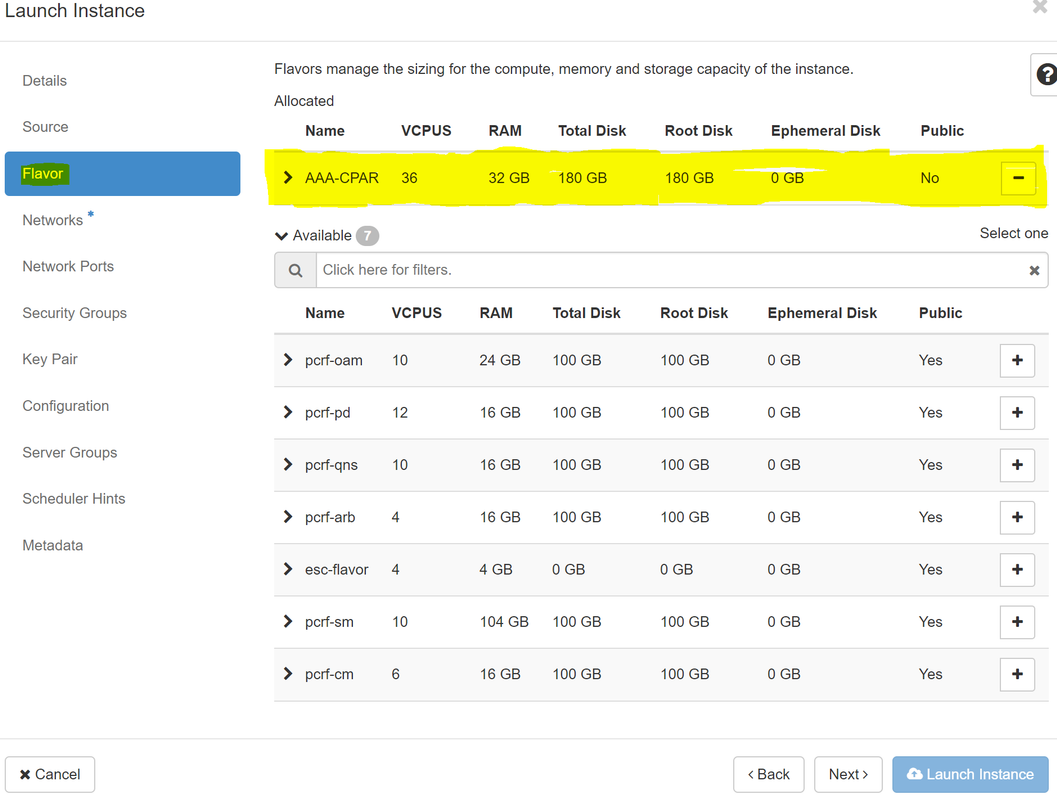
Passo 7. Na guia Flavor, escolha o sabor AAA quando você clica no + sinal, como mostrado na imagem.
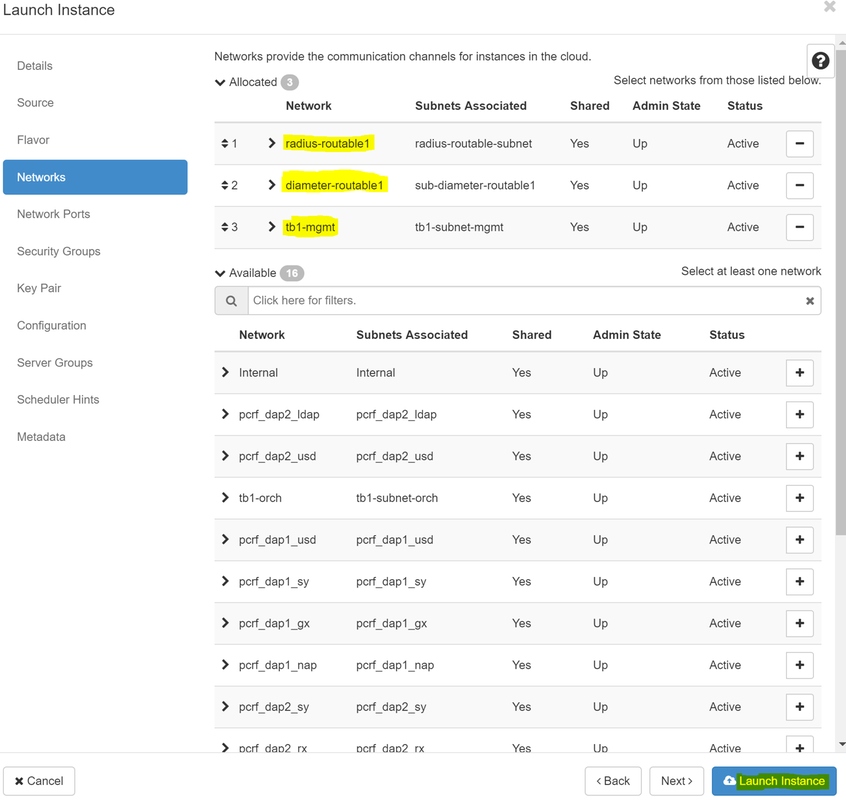
Etapa 8. Agora, navegue até a guia Redes e escolha as redes de que a instância precisa enquanto clica no sinal +. Nesse caso, selecione diâmetro-soutable1, radius-routable1 e tb1-mgmt, como mostrado na imagem.
Etapa 9. Clique em Iniciar instância para criá-la. O progresso pode ser monitorado no Horizon:
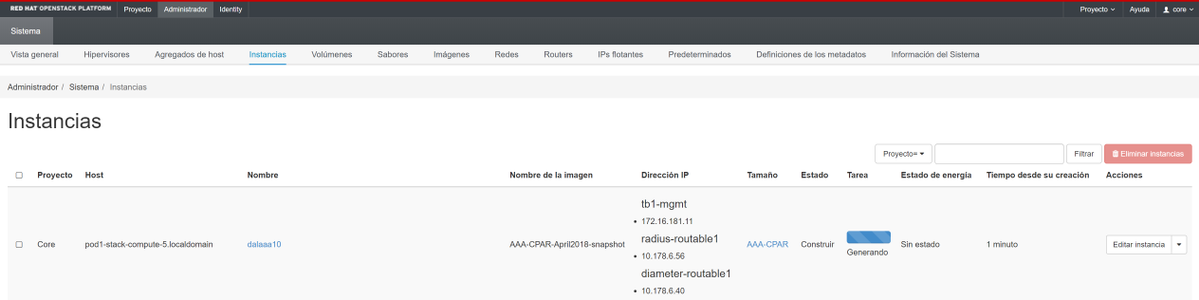
Após alguns minutos, a instância será completamente implantada e pronta para uso.

Criar e atribuir um endereço IP flutuante
Um endereço IP flutuante é um endereço roteável, o que significa que ele pode ser alcançado de fora da arquitetura Ultra M/Openstack e pode se comunicar com outros nós da rede.
Etapa 1. No menu superior do Horizon, navegue até Admin > IPs flutuantes.
Etapa 2. Clique no botão Alocar IP para projeto.
Etapa 3. Na janela Alocar IP Flutuante, selecione o Pool do qual o novo IP flutuante pertence, o Projeto onde ele será atribuído e o novo Endereço IP Flutuante propriamente dito.
Por exemplo:
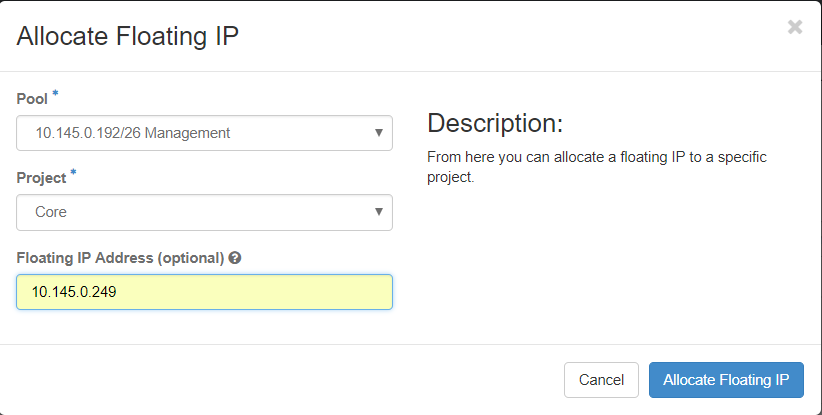
Etapa 4. Clique no botão Alocar IP flutuante.
Etapa 5. No menu superior do Horizon, navegue até Project > Instances.
Etapa 6. Na coluna Ação, clique na seta que aponta para baixo no botão Criar instantâneo, um menu deve ser exibido. Selecione a opção Associar IP flutuante.
Passo 7. Selecione o endereço IP flutuante correspondente destinado a ser usado no campo Endereço IP e escolha a interface de gerenciamento correspondente (eth0) da nova instância onde esse IP flutuante será atribuído na Porta a ser associada. Consulte a próxima imagem como um exemplo deste procedimento.
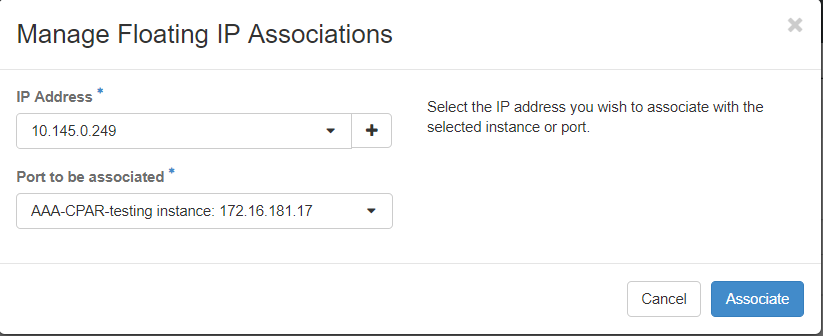
Etapa 8. Clique em Associar.
Habilitar SSH
Etapa 1. No menu superior do Horizon, navegue até Project > Instances.
Etapa 2. Clique no nome da instância/VM que foi criada na seção Iniciar uma nova instância.
Etapa 3. Clique na guia Console. Exibe a CLI da VM.
Etapa 4. Depois que a CLI for exibida, insira as credenciais de login adequadas:
Nome de usuário: root
Senha: cisco123
Etapa 5. Na CLI, digite o comando vi /etc/ssh/sshd_config para editar a configuração do ssh.
Etapa 6. Quando o arquivo de configuração ssh estiver aberto, pressione I para editar o arquivo. Em seguida, procure a seção mostrada abaixo e altere a primeira linha de PasswordAuthentication no para PasswordAuthentication yes.

Passo 7. Pressione ESC e digite :wq! para salvar as alterações no arquivo sshd_config.
Etapa 8. Execute o comando service sshd restart.
Etapa 9. Para testar se as alterações na configuração do SSH foram aplicadas corretamente, abra qualquer cliente SSH e tente estabelecer uma conexão segura remota usando o IP flutuante atribuído à instância (por exemplo, 10.145.0.249) e a raiz do usuário.
Estabelecer uma sessão SSH
Abra uma sessão SSH com o endereço IP da VM/servidor correspondente onde o aplicativo está instalado.

Início da instância do CPAR
Siga as etapas abaixo, depois que a atividade tiver sido concluída e os serviços CPAR puderem ser restabelecidos no site que foi encerrado.
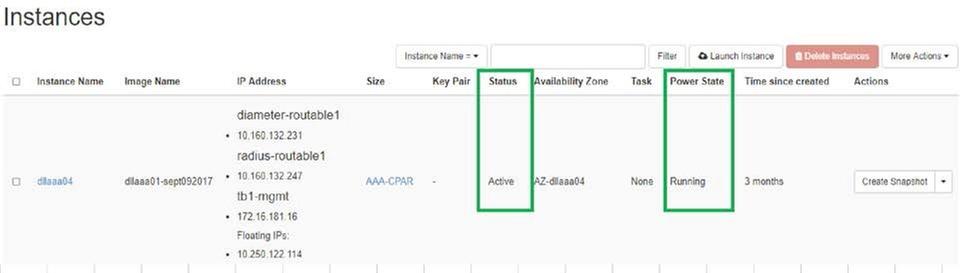
- Para fazer login novamente no Horizon, navegue até Project > Instance > Start Instance.
- Verifique se o status da instância está ativo e se o estado de energia está em execução:
Verificação de integridade pós-atividade
Etapa 1. Execute o comando /opt/CSCOar/bin/arstatus no nível do SO.
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Etapa 2. Execute o comando /opt/CSCOar/bin/aregcmd no nível do SO e insira as credenciais de administrador. Verifique se o CPAR Health está em 10 de 10 e se a CLI do CPAR de saída está em 10.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd
Cisco Prime Access Registrar 7.3.0.1 Configuration Utility
Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved.
Cluster:
User: admin
Passphrase:
Logging in to localhost
[ //localhost ]
LicenseInfo = PAR-NG-TPS 7.2(100TPS:)
PAR-ADD-TPS 7.2(2000TPS:)
PAR-RDDR-TRX 7.2()
PAR-HSS 7.2()
Radius/
Administrators/
Server 'Radius' is Running, its health is 10 out of 10
--> exit
Etapa 3.Executar o comando netstat | diâmetro de grep e verifique se todas as conexões DRA estão estabelecidas.
A saída mencionada abaixo destina-se a um ambiente em que são esperados links de diâmetro. Se menos links forem exibidos, isso representa uma desconexão do DRA que precisa ser analisada.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Etapa 4. Verifique se o registro TPS mostra solicitações sendo processadas pelo CPAR. Os valores destacados representam o TPS e são a esses que devemos prestar atenção.
O valor do TPS não deve exceder 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Etapa 5. Procure qualquer mensagem de "erro" ou "alarme" em name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Etapa 6.Verifique a quantidade de memória que o processo CPAR está, com este comando:
superior | raio de grep
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Este valor destacado deve ser inferior a: 7 Gb, que é o máximo permitido em um nível de aplicativo.
Colaborado por engenheiros da Cisco
- Karthikeyan DachanamoorthyCisco Advance Services
- Harshita BhardwajCisco Advance Services
 Feedback
FeedbackContate a Cisco
- Abrir um caso de suporte

- (É necessário um Contrato de Serviço da Cisco)