Inleiding
Dit document beschrijft verschillende typen schijffouten, hoe u deze kunt classificeren en gereedschappen waarmee u deze kunt identificeren.
Voorwaarden
Vereisten
Er zijn geen specifieke vereisten van toepassing op dit document.
Gebruikte componenten
De informatie in dit document is gebaseerd op vaste schijven in Unified Computing System (UCS).
De informatie in dit document is gebaseerd op de apparaten in een specifieke laboratoriumomgeving. Alle apparaten die in dit document worden beschreven, hadden een opgeschoonde (standaard)configuratie. Als uw netwerk live is, moet u de potentiële impact van elke opdracht begrijpen.
Achtergrondinformatie
Het document schetst ook de rol van de vaste schijf (HDD) en de redundant Array of Independent Disks (RAID) controller wanneer u middelgrote fouten op de schijven herkent.
Opmerking: Medium fouten worden ook mediumfouten genoemd
Handvat HDD Medium Fouten
Wat veroorzaakt HDD medium fouten?
De meest voorkomende oorzaak van middelgrote fouten is een slechte signaalamplitude die resulteert in
- Onbetrouwbare Logical Bus Address (LBA) leeslocatie. Soms herstelbaar met meerdere herhalingen.
- Voorbijgaande omstandigheden, high fly schrijft veroorzaakt door zachte deeltjes.
- Voorbijgaande aandoeningen die worden veroorzaakt door tijdelijke schokken, trillingen of akoestische gebeurtenissen die leiden tot afwijkende schrijfresultaten.
- Slechte error map functie in HDD productie die resulteert in het opvullen van de huidige primaire defect locaties.
Hoe detecteert de vaste schijf de medium fout?
Stap 1. De vaste schijf voert periodiek achtergrondmediascannen uit om fouten te detecteren.
Stap 2. De HDD probeert te lezen van de media en is om de een of andere reden niet in staat om de geschreven gegevens terug te halen.
Stap 3. Wanneer de HDD niet in staat is om de geschreven gegevens terug te halen, wordt de HDD-herstelcode gebruikt die verschillende foutherstelstappen zal proberen om de gegevens met succes te lezen uit de media.
Stap 4. Als alle herstelstappen mislukken, zal het station een 03/11/0x fout genereren terug naar de host en de LBA(s) worden geplaatst op de wachtende defectlijst.
Hoe detecteert de Raid-controller middelgrote fouten?
- De RAID-controller stuit op middelgrote fouten tijdens Patrol Reads, Consistency Checks, Normal Reads, Rebuilds en Read / Modify / Write-bewerkingen.
- Op basis van de RAID-configuratie kan de controller de gemiddelde fout die door de vaste schijf wordt gemeld, mogelijk verwerken en is er geen verdere actie vereist.
- In sommige gevallen zal de controller de gemiddelde fout niet kunnen verwerken en zal de fout aan de host worden doorgegeven om de fout te verwerken.
Wanneer ziet het besturingssysteem middelgrote fouten?
- Als de vaste schijf een gemiddelde fout meldt en de RAID-controller het herstel niet aankan, zal de host worden geïnformeerd over de fout.
- Deze melding is niet meer alleen een advies die het systeem zou informeren dat de gebeurtenis heeft plaatsgevonden, het is een verzoek aan het OS om te handelen omdat de HDD en RAID controller niet in staat was om van de medium fout te herstellen.
- Als het besturingssysteem de vereiste context heeft om de fout in het medium correct op te lossen, moet het door het besturingssysteem worden verwerkt
- Als schijven in Just a Bunch Of Disk (JBOD) staan, ziet het besturingssysteem fouten die niet door de controller worden gecorrigeerd. Dit is gebruikelijk in HyperFlex (HX)/ Virtual Storage Area Network (VSAN)-omgevingen.
HDD-rol
Grown Defects (G-list) HDD-niveau
Terwijl een aandrijving in werking is, kan het hoofd over een sector met een verzwakt magnetisch leesniveau komen. De gegevens zijn nog steeds leesbaar, maar zouden onder de voorkeursdrempel voor gekwalificeerde leesniveaus voor de goede sector kunnen vallen. Deze diskdrive zou dit als een sector beschouwen die deze gegevens zou kunnen en zou sparen aan een nieuwe plaats beschikbaar in de bekende goede reservelijst. Zodra de gegevens zijn verplaatst, wordt het oude sectoradres toegevoegd aan de lijst Grown Defects, om nooit meer te worden gebruikt. Dit proces is een herstelbare mediafout. De drive zal een SMART trigger geven wanneer de meeste van zijn goed bekende reservesectoren uitgeput zijn.
Rol van RAID-controllers
Patrol Read
- Patrol Read is een door de gebruiker definieerbare optie die het station leest op de achtergrond en alle slechte gebieden van het station in kaart brengt.
- Met Patrol Read wordt gecontroleerd op fysieke schijffouten die tot een defect aan het station kunnen leiden. Deze controles omvatten gewoonlijk een poging tot correctieve actie. Het lezen van de patrouille kan worden in- of uitgeschakeld met automatische of handmatige activering.
- Een Patrol Read verifieert periodiek alle sectoren van fysieke schijven die zijn aangesloten op een controller, waaronder het systeem gereserveerde gebied in de RAID geconfigureerde schijven. Patrol Read werkt voor alle RAID-niveaus en alle hot spares.
- Dit proces begint alleen als de RAID-controller gedurende een bepaalde tijd inactief is en er geen andere taken op de achtergrond actief zijn, hoewel het kan blijven draaien op hetzelfde moment als zware I/O-processen (Input/Output).
- U kunt geen patrouille-leesacties uitvoeren op schijven die in JBOD zijn geconfigureerd.
Opmerking:Latent Semantic Indexing (LSI) raadt u aan de patrouille leesfrequentie en andere instellingen voor patrouillelezen te laten staan op de standaardwaarden om de beste systeemprestaties te bereiken. Als u de waarden wilt wijzigen, registreert u hier de oorspronkelijke standaardwaarde, zodat u deze later kunt herstellen.
Opmerking: Patrol Read rapporteert niet over de voortgang tijdens het gebruik. De status van het patrouilleleesvenster wordt alleen in het gebeurtenissenlogboek vermeld.
De opties voor het lezen van patrouilles zijn zoals in de afbeelding:
 MegaCLI-voorbeelden
MegaCLI-voorbeelden
Om informatie te zien over de patrouille lees status en de vertraging tussen patrouille lees loopt:
# MegaCli64 -AdpPR -Info -aALL
Voer de volgende handelingen uit om de huidige leessnelheid van de patrouille te achterhalen:
# MegaCLI64 -AdpGetProp PatrolReadRate -All
Zo schakelt u automatisch gelezen patrouilles uit:
# MegaCLI64 -AdpPR -DSBL -AALL
Automatisch patrouilleren inschakelen:
#MegaCli64 -AdpPR -EnblAuto -All
Om een handmatige patrouille leesscan te starten:
# MegaCLI64 -AdpPR -Start -AALL
Om een scan van een patrouille te stoppen bij lezen:
# MegaCli64 -AdpPR -Stop -aALL
Consistentiecontrole
- In RAID verifieert de Consistentiecontrole de juistheid van redundante gegevens in een array. Bijvoorbeeld, in een systeem met pariteit, betekent controleren van consistentie om de pariteit van de gegevensaandrijving te berekenen en de resultaten te vergelijken met de inhoud van de pariteitsaandrijving.
- JBOD ondersteunt consistentiecontrole niet.
- RAID 0 ondersteunt consistentiecontrole niet.
- RAID 1 gebruikt gegevens in plaats van pariteit.
- RAID 6 berekent pariteit voor 2 pariteitsschijven en verifieert beide.
Opmerking: het wordt aangeraden om minstens één keer per maand een consistentiecontrole uit te voeren.
De beheeropties voor de consistentiecontrole worden in het afbeelding weergegeven:
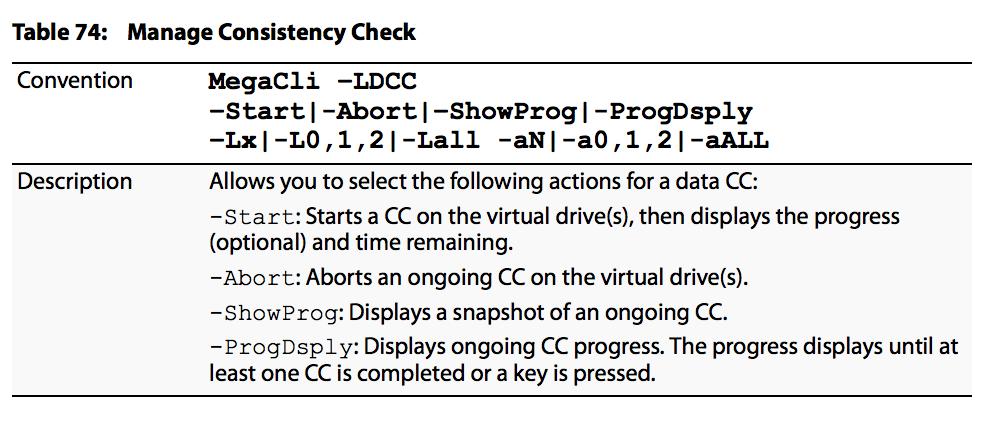
De opties voor het plannen van de consistentiecontrole zijn zoals in de afbeelding wordt getoond:

MegaCLI-voorbeelden
Om de volgende geplande tijd voor de consistentiecontrole te zien:
#MegaCli64 -AdpCcSched -Info -All
Zo wijzigt u de geplande consistentiecontroletijd:
#MegaCli64 -AdpCCSched -SetSTartTime 20171028 02 -All
Consistentiecontrole uitschakelen:
#MegaCli64 -AdpCcSched -DSBL -All
Voorwaarden wanneer een RAID-controller een gemiddelde fout niet kan herstellen
- In JBOD
- Het host OS is verantwoordelijk voor middelgrote fouten.
- In RAID 0
- Er is geen redundantie, dus de controller kan de HDD niet voorzien van de gegevens om naar de LBA te schrijven.
- In RAID 1
- Wanneer de controller niet kan zien welke kopie de juiste gegevens bevat. Dit gebeurt alleen als beide LBA's kunnen worden gelezen, maar de gegevens komen niet overeen.
- RAID 5
- Indien er 2 of meer fouten in dezelfde streep voorkomen. Het is het meest waarschijnlijk dat dit zal gebeuren als een array opnieuw wordt opgebouwd. De schijf die wordt herbouwd is één fout, en een gemiddelde fout op een andere schijf herbouwen zou de tweede fout zijn. De controller zou niet in staat zijn om de gegevens te reconstrueren die nodig zijn om de LBA op de vervangende schijf te herbouwen.
- RAID 6
- Indien er 3 of meer fouten in dezelfde streep voorkomen. Het is het meest waarschijnlijk dat dit zal gebeuren als een array opnieuw wordt opgebouwd. De schijf die wordt herbouwd is één fout, en een gemiddelde fout op twee andere stations terwijl de herbouw bezig is zou een tweede en derde fout, of een gemiddelde fout en een tweede schijf fout zijn. De controller zou niet in staat zijn om de gegevens te reconstrueren die nodig zijn om de LBA's op de schijven met de fouten te reconstrueren.
Gerelateerde informatie
 Feedback
Feedback