Problemen met prestaties oplossen in HyperFlex-clusters
Inclusief taalgebruik
De documentatie van dit product is waar mogelijk geschreven met inclusief taalgebruik. Inclusief taalgebruik wordt in deze documentatie gedefinieerd als taal die geen discriminatie op basis van leeftijd, handicap, gender, etniciteit, seksuele oriëntatie, sociaaleconomische status of combinaties hiervan weerspiegelt. In deze documentatie kunnen uitzonderingen voorkomen vanwege bewoordingen die in de gebruikersinterfaces van de productsoftware zijn gecodeerd, die op het taalgebruik in de RFP-documentatie zijn gebaseerd of die worden gebruikt in een product van een externe partij waarnaar wordt verwezen. Lees meer over hoe Cisco gebruikmaakt van inclusief taalgebruik.
Over deze vertaling
Cisco heeft dit document vertaald via een combinatie van machine- en menselijke technologie om onze gebruikers wereldwijd ondersteuningscontent te bieden in hun eigen taal. Houd er rekening mee dat zelfs de beste machinevertaling niet net zo nauwkeurig is als die van een professionele vertaler. Cisco Systems, Inc. is niet aansprakelijk voor de nauwkeurigheid van deze vertalingen en raadt aan altijd het oorspronkelijke Engelstalige document (link) te raadplegen.
Inhoud
Inleiding
In dit document worden de gevolgen voor de prestaties in een hyperlex-omgeving beschreven vanuit het perspectief van een Guest Virtual Machine (VM), ESXi-host en (SCVM)
Identificeren
Om de prestaties in een Hyperflex-omgeving probleemoplossing te kunnen bieden, is het belangrijk om het type cluster te identificeren, de werking waar de prestaties achteruitgaan, de frequentie van de prestatieachteruitgang en het niveau van de prestatie-impact die prestatieachteruitgang veroorzaakt.
Er zijn meerdere invloedsniveaus in een hyperlex-cluster, op de gast-VM, het ESXI-hostniveau en het VM-niveau van de opslagcontroller.
Clustertypen
● Hybride knooppunten: maakt gebruik van Solid State Drives (SSD) voor caching en HDD's voor de capaciteitslaag.
● All-Flash knooppunten: maakt gebruik van SSD-schijven of non-volatile Memory Express (NVMe) opslag voor caching, en SSD-schijven voor de capaciteitslaag.
● All-NVMe knooppunten: maakt gebruik van NVMe-opslag voor zowel caching als de All-NVMe knooppunten op de capaciteitslaag die de hoogste prestaties leveren voor de meest veeleisende werkbelastingen met caching
Toelichting bij het prestatiediagram
De hyperflex-systemen hebben een functie om de prestaties te bewaken, de grafieken geven de lees- en schrijfprestaties van het opslagcluster weer.
IOPS
Invoer/uitvoerbewerkingen per seconde (IOPS) is een gebruikelijke prestatiemaatstaf die wordt gebruikt voor het meten van computeropslagapparaten, met inbegrip van vaste schijven. Deze metriek wordt gebruikt om de prestaties voor willekeurige I/O-werkbelastingen te evalueren.
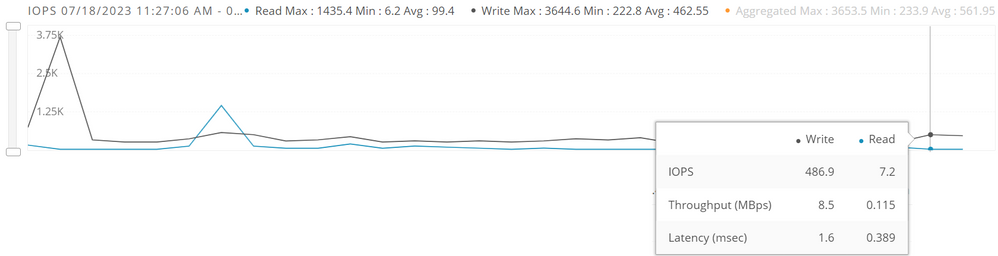 IOPS-prestatiekaart.
IOPS-prestatiekaart.
Doorvoersnelheid
Het beeld toont de snelheid van gegevensoverdracht in het opslagcluster gemeten in Mbps.
 Doorvoerprestaties.
Doorvoerprestaties.
Latentie
Latentie is een maat van hoe lang het duurt voor een enkele I/O aanvraag te voltooien. Het is de tijd tussen het afgeven van een verzoek en het ontvangen van een antwoord, gemeten in milliseconden.
 Latency performance grafiek.
Latency performance grafiek.
Frequentie
Het is belangrijk de frequentie en de duur van de prestatie-impact te definiëren om de mogelijke impact op het milieu te kunnen beoordelen.
Als de prestaties de hele tijd worden beïnvloed, is het nodig om te controleren waar het is begonnen om de prestaties te degraderen en te controleren op eventuele configuratieveranderingen of problemen tussen de cluster.
Als de prestaties met tussenpozen worden beïnvloed, is dit nodig om te controleren of er op dat moment een handeling of dienst actief is.
Externe factoren
De prestaties van het cluster kunnen worden beïnvloed door externe factoren zoals momentopnamen en back-upbewerkingen.
Bekijk deze links voor meer informatie over externe factoren:
VMware vSphere-momentopnamen: prestaties en beste praktijken.
Cisco HyperFlex Systems en Veeam Backup en replicatie-witboek.
Prestatieproblemen op het niveau van de gast-VM identificeren
Dit is het meest zichtbare niveau van impact in de hyperlex-omgeving, het beïnvloedt direct de diensten die de VM's leveren en het is duidelijker bij de gebruikers die direct worden getroffen.
Hier zijn gemeenschappelijke tests om prestaties op gemeenschappelijke werkende systemen te identificeren.
Windows
Bekijk de beschikbare tools om prestatieproblemen in Windows Guest VM's te identificeren:
ESXi-software
Na het identificeren van het effect op de prestaties en het bekijken van de mogelijke oorzaken van de verslechtering van de prestaties, zijn er enkele prestatiecontroles om de prestaties te verbeteren.
- Controleer op overprovisioning (het totale aantal vCPU’s dat aan alle VM’s wordt toegewezen, mag niet groter zijn dan het totale aantal fysieke kernen dat op de ESXi-hostmachine beschikbaar is).
- Zelfs als het gastbesturingssysteem sommige vCPU’s niet gebruikt, worden bij de configuratie van VM’s met die vCPU’s nog steeds enkele kleine resourcevereisten aan ESXi opgelegd die zich vertalen in een reëel CPU-verbruik op de host.
- Het geheugen dat te veel wordt toegewezen, verhoogt ook onnodig de overhead van het VM-geheugen en kan leiden tot geheugenconflicten, vooral als er reserveringen worden gebruikt.
- Controleer of het stuurprogramma van de ballon het geheugen niet vasthoudt. Raadpleeg voor meer informatie deze link.
Bekijk de problemen met de prestaties van de ESX/ESXi virtuele machine.
PVSCSI-controle
ParaVirtual SCSI (PVSCSI)-adapters zijn krachtige opslagadapters die kunnen leiden tot een hogere doorvoersnelheid en een lager CPU-gebruik voor virtuele machines met een hoog schijf-IO-vereiste. Het gebruik van PVSCSI-adapters wordt aanbevolen. PVSCSI-controller is een virtualisatiebewuste, hoogwaardige SCSI-adapter die de laagst mogelijke latentie en hoogste doorvoersnelheid met de laagste CPU-overhead mogelijk maakt.
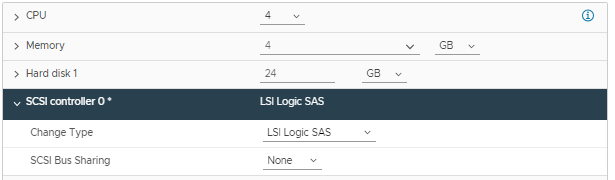 PVSCSI-adapter.
PVSCSI-adapter.
Netwerkadaptercontrole
VMXNET 3 is een geparavirtualiseerde NIC die is ontworpen voor prestaties en biedt krachtige functies die veel worden gebruikt in moderne netwerken, zoals jumboframes, ondersteuning voor meerdere wachtrijen (ook bekend als Receive Side Scaling in Windows), IPv6-offloads, en onderbreking van MSI/MSI-X-levering en hardware-offloads.
Zorg ervoor dat het adaptertype VMXNET3 is.
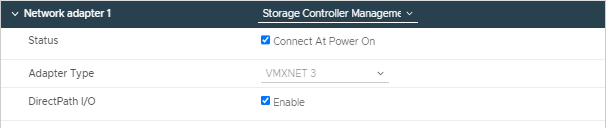 Netwerkadapter.
Netwerkadapter.
RSS-controle
Opmerking: deze controle is alleen van toepassing op de gast virtuele machines die een Windows-besturingssysteem uitvoeren.
Receive Side Schaling (RSS) is een technologie voor netwerkstuurprogramma's die de efficiënte distributie van de ontvangstverwerking van netwerken over meerdere CPU's in multiprocessorsystemen mogelijk maakt.
Windows-servers hebben een driver-configuratie die de distributie van de kernel-mode netwerkverwerkingsbelasting over meerdere CPU’s mogelijk maakt.
Controleer of deze opdracht in de Windows PowerShell is ingeschakeld:
netsh interface tcp set global rss=enabledOm RSS deze link te laten bekijken
Hot-pluggable controle van CPU
CPU hotplug is een functie waarmee de VM-beheerder CPU’s aan de VM kan toevoegen zonder deze uit te moeten schakelen. Hierdoor kunnen CPU-bronnen direct worden toegevoegd zonder onderbreking van de service. Wanneer de CPU hotplug op een VM is ingeschakeld, wordt de vNUMA-functie uitgeschakeld.
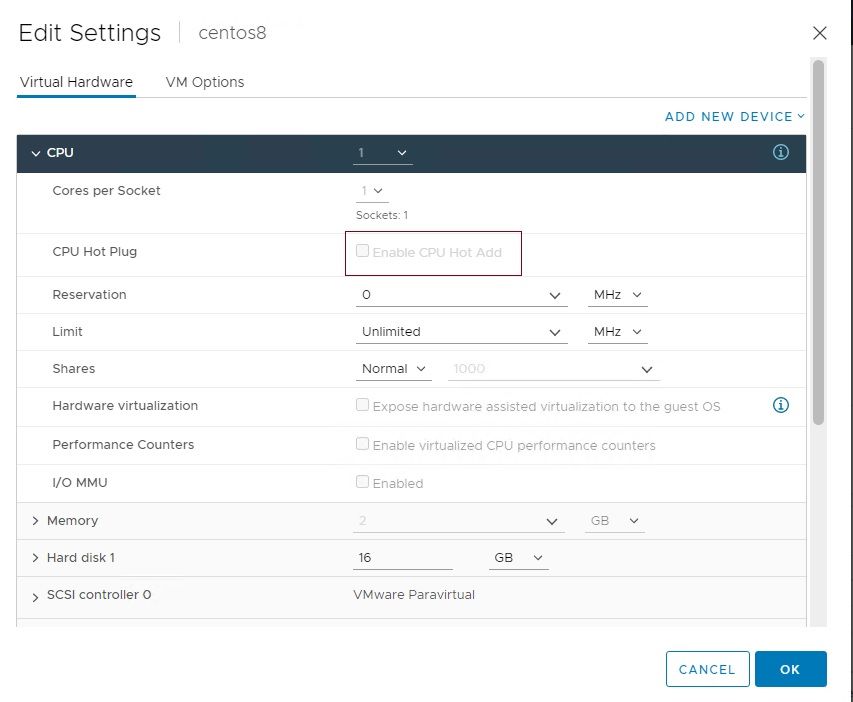 CPU hot-plug uitgeschakeld.
CPU hot-plug uitgeschakeld.
Bekijk de best practices voor gemeenschappelijke besturingssystemen en toepassingen:
Windows.
Richtlijnen voor prestatieafstemming voor Windows Server 2022.
Rode hoed.
3 tips voor de verbetering van de Linux-procesprestaties met prioriteit en affiniteit.
SQL Server.
Microsoft SQL Server op VMware ontwerpen.
Rode hoed.
Handleiding voor afstemming van prestaties.
Prestatieproblemen op hostniveau identificeren
Om de prestatie-impact op het hostniveau te identificeren, kunt u de prestatiediagrammen bekijken die de ESXI-host heeft ingebouwd in de ESXI-hypervisor, en controleren hoeveel hosts worden beïnvloed.
U kunt de prestatiekaarten in vCenter bekijken op het tabblad Monitor en op het tabblad Prestaties klikken.
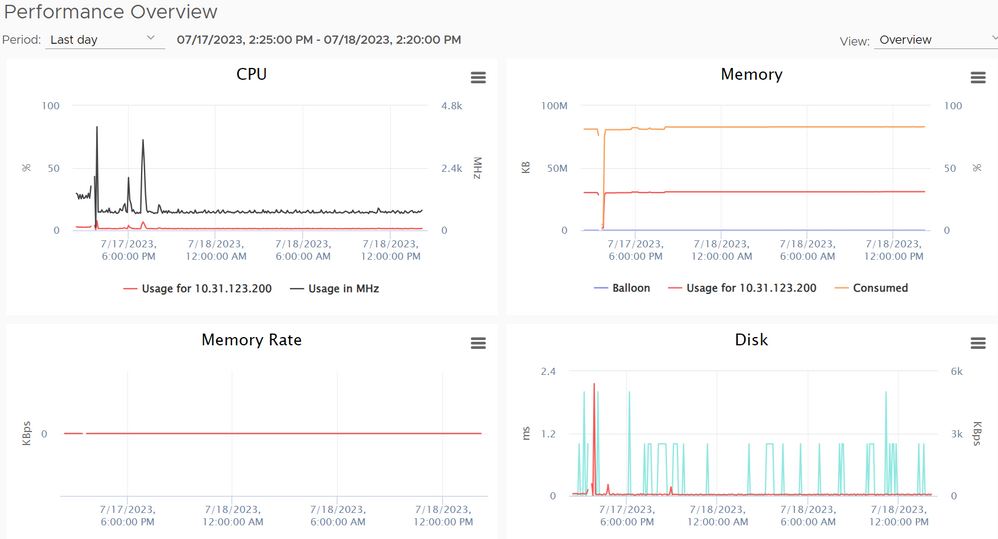 vCenter-prestatiekaarten.
vCenter-prestatiekaarten.
In deze grafieken kunt u de prestatiekaarten bekijken die betrekking hebben op de CPU, het geheugen en de schijf. Verwijs naar deze link om de grafieken te begrijpen.
Opmerking: CRC-fouten en MTU-mismatch, vooral in het opslagnetwerk, leveren latentieproblemen op. Voor opslagverkeer moeten Jumboframes worden gebruikt.
I/O-controle van opslag en diepte van wachtrij
Storage I/O Control (SIOC) wordt gebruikt om het I/O-gebruik van een virtuele machine te controleren en om geleidelijk de vooraf gedefinieerde I/O-deelniveaus af te dwingen, is nodig om deze functie in HyperFlex-clusters te laten uitschakelen.
Queue-diepte is het aantal in behandeling zijnde I/O-verzoeken (input/output) dat een opslagbron op elk moment kan verwerken.
U kunt deze stappen gebruiken om te controleren of SIOC is uitgeschakeld en dat de wachtrijconfiguratie is uitgeschakeld.
Bevestig dat SIOC wordt uitgevoerd op ESXi en de wachtrijconfiguratie
Stap 1. SSH naar een HX ESXi-host en de opdracht geven om de datastores te vermelden.
[root@] vsish -e ls /vmkModules/nfsclient/mnt
encrypted_app/
Prod/ <----- Datastore name
Dev/
App/Stap 2. Gebruik de naam van de Gegevensopslag en geef het bevel uit.
vsish -e get /vmkModules/nfsclient/mnt/
/properties [root@] vsish -e get /vmkModules/nfsclient/mnt/Prod/properties mount point information { volume name:Prod server name:7938514614702552636-8713662604223381594 server IP:127.0.0.1 server volume:172.16.3.2:Prod UUID:63dee313-dfecdf62 client src port:641 busy:0 socketSendSize:1048576 socketReceiveSize:1048576 maxReadTransferSize:65536 maxWriteTransferSize:65536 reads:0 readsFailed:0 writes:285 writesFailed:0 readBytes:0 writeBytes:10705 readTime:0 writeTime:4778777 readSplitsIssued:0 writeSplitsIssued:285 readIssueTime:0 writeIssueTime:4766494 cancels:0 totalReqsQueued:0 metadataReqsQueued(non IO):0 reqsInFlight:0 readOnly:0 hidden:0 isPE:0 isMounted:1 isAccessible:1 unstableWrites:0 unstableNoCommit:0 maxQDepth:1024 <-------- Max Qdepth configuration iormState:0 <-------- I/O control disabled latencyThreshold:30 shares:52000 podID:0 iormInfo:0 NFS operational state: 0 -> Up enableDnlc:1 closeToOpenCache:0 highToAvgLatRatio:10 latMovingAvgSmoothingLevel:2 activeWorlds:55 inPreUnmount:0 }
Stap 3. In de output kijk je naar de lijn
iormState:0 0= disabled 2= enabledDe lijn maxQDepth moet 1024 zijn
Stap 4. Voor de rest van de datastores moeten dezelfde stappen worden herhaald
SIOC uitschakelen
Om de SIOC uit te schakelen, voert u deze stappen uit.
Stap 1. Login aan vsphere met behulp van de HTML-client.
Stap 2. Selecteer in het vervolgkeuzemenu Opslag en selecteer vervolgens de gewenste HX Datastore in het linker deelvenster.
 Selecteer datastore.
Selecteer datastore.
Stap 3. Selecteer in het rechterdeelvenster bovenaan de Datastore het tabblad Configureren.
 Tabblad Configureren
Tabblad Configureren
Stap 4. In het rechter deelvenster midden onder Meer, selecteer Algemeen, en aan de rechterkant scrolt naar beneden naar DataStore-functies en klik op Bewerken
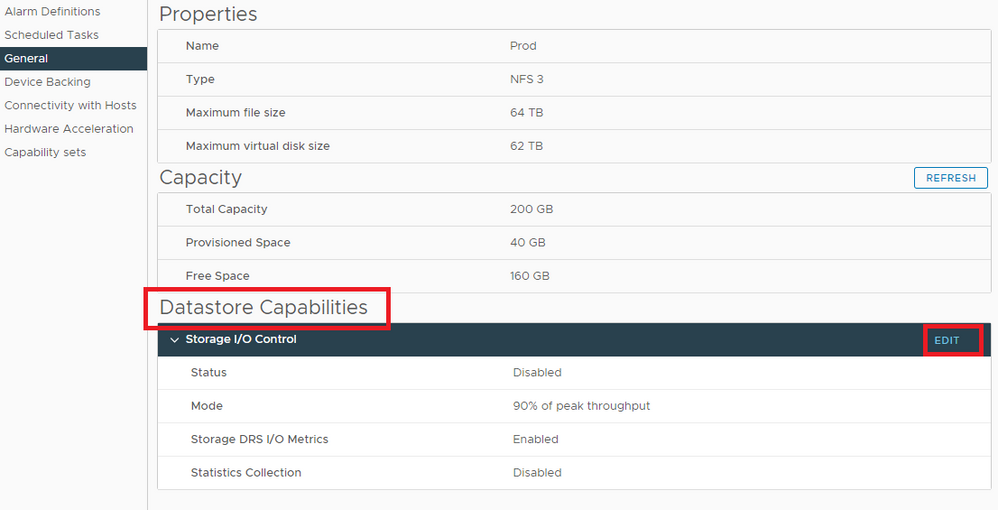 Bewerk datastore mogelijkheden.
Bewerk datastore mogelijkheden.
Als de knop I/O-controle en statistiekverzameling uitschakelen niet is ingeschakeld, controleert u dit.
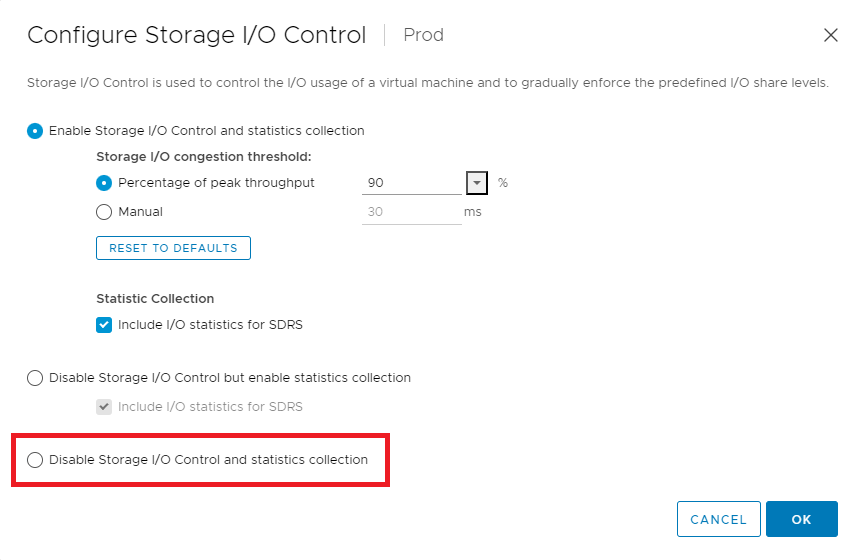 I/O-besturing voor opslag uitschakelen.
I/O-besturing voor opslag uitschakelen.
Als de knop I/O-controle voor opslag in- en uitschakelen en het keuzerondje voor verzameling van statistieken worden ingeschakeld, schakelt u tussen I/O-controle voor opslag inschakelen en verzameling van statistieken en I/O-controle voor opslag in- en uitschakelen en verzameling van statistieken.
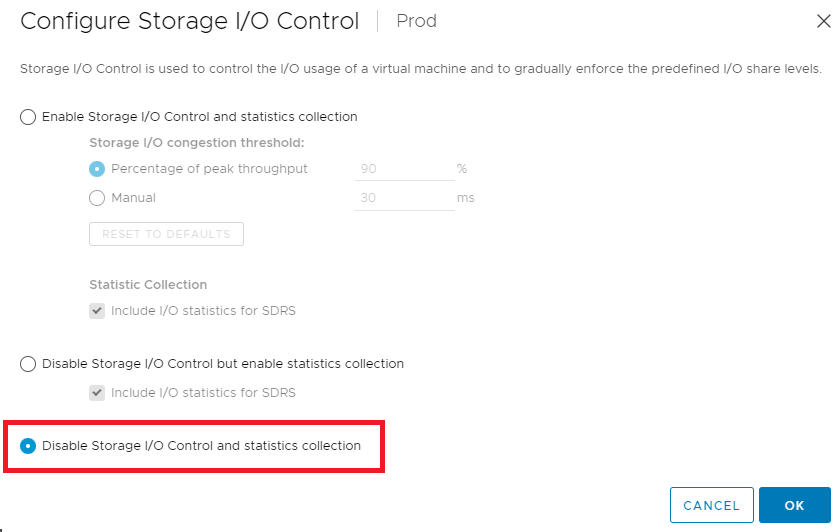 I/O-besturing voor opslag uitgeschakeld.
I/O-besturing voor opslag uitgeschakeld.
Stap 5. Herhaal Stap 1 tot en met 4 zoals nodig voor alle andere datastores.
Max. QDth wijzigen
Om de maxQDepth kwestie te wijzigen het volgende bevel voor elke datastore.
vsish -e set /vmkModules/nfsclient/mnt/
/properties maxQDepth 1024
Controleer op Rx_no_Buff
Hyperflex servers met zwaar netwerkverkeer of netwerkverkeer met microbursts kunnen pakketverlies tot gevolg hebben, zoals weergegeven in de vorm van rx_no_bufs.
Om dit probleem te identificeren voer je deze opdrachten uit in de ESXi host om de rx_no_buf tellers te controleren.
/usr/lib/vmware/vm-support/bin/nicinfo.sh | egrep "^NIC:|rx_no_buf"
NIC: vmnic0
rx_no_bufs: 1
NIC: vmnic1
rx_no_bufs: 2
NIC: vmnic2
rx_no_bufs: 2
NIC: vmnic3
rx_no_bufs: 71128211 <---------Very high rx_no_bufs counter
NIC: vmnic4
rx_no_bufs: 1730
NIC: vmnic5
rx_no_bufs: 897
NIC: vmnic6
rx_no_bufs: 24952
NIC: vmnic7
rx_no_bufs: 2
Wacht een paar minuten en voer de opdracht opnieuw uit en controleer of de rx_no_bufs tellers niet toenemen.
- Als deze tellers laag zijn (< 1.000) dan met weinig pakketverlies toe te schrijven aan de standaardwachtrijconfiguratie en waarschijnlijk hoeft geen afstemming te worden uitgevoerd.
- Als deze tellers hoog zijn (> 10.000) dan is er enige impact door deze wachtrij configuratie en tuning kan helpen een beetje.
- Als deze tellers zeer hoog zijn (> 1.000.000) dan is er een meer significante impact, het verhogen van wachtrijen wordt ten zeerste aanbevolen.
- Als rx_no_bufs actief toeneemt, betekent dit dat het pakket gemaakt over het netwerk en komt bij de gevirtualiseerde laag dan het pakket wordt gelaten vallen.
Als u de teller op deze waarden ziet, neemt u contact op met Cisco TAC om de vNIC-configuratie af te stemmen voor betere prestaties.
Bekijk de best practices en aanvullende controles op ESXI-niveau.
Best practices voor prestaties voor VMware vSphere 7.0.
Prestatieproblemen identificeren Opslagcontroller virtuele machine (SCVM)-niveau
Clustergezondheid
Controleer of het cluster gezond is.
hxshell:~$ sysmtool --ns cluster --cmd healthdetail
Cluster Health Detail:
---------------------:
State: ONLINE <---------- State of the cluster
HealthState: HEALTHY <---------- Health of the cluster
Policy Compliance: COMPLIANT
Creation Time: Tue May 30 04:48:45 2023
Uptime: 7 weeks, 19 hours, 45 mins, 51 secs
Cluster Resiliency Detail:
-------------------------:
Health State Reason: Storage cluster is healthy.
# of nodes failure tolerable for cluster to be fully available: 1
# of node failures before cluster goes into readonly: NA
# of node failures before cluster goes to be crticial and partially available: 3
# of node failures before cluster goes to enospace warn trying to move the existing data: NA
# of persistent devices failures tolerable for cluster to be fully available: 2
# of persistent devices failures before cluster goes into readonly: NA
# of persistent devices failures before cluster goes to be critical and partially available: 3
# of caching devices failures tolerable for cluster to be fully available: 2
# of caching failures before cluster goes into readonly: NA
# of caching failures before cluster goes to be critical and partially available: 3
Current ensemble size: 3
Minimum data copies available for some user data: 3
Minimum cache copies remaining: 3
Minimum metadata copies available for cluster metadata: 3
Current healing status:
Time remaining before current healing operation finishes:
# of unavailable nodes: 0
hxshell:~$
Deze output toont een ongezonde cluster toe te schrijven aan een niet beschikbare knoop.
hxshell:~$ sysmtool --ns cluster --cmd healthdetail
Cluster Health Detail:
---------------------:
State: ONLINE <-------State of the cluster
HealthState: UNHEALTHY <-------Health of the cluster
Policy Compliance: NON-COMPLIANT
Creation Time: Tue May 30 04:48:45 2023
Uptime: 7 weeks, 19 hours, 55 mins, 9 secs
Cluster Resiliency Detail:
-------------------------:
Health State Reason: Storage cluster is unhealthy.Storage node 172.16.3.9 is unavailable. <----------- Health state reason
# of nodes failure tolerable for cluster to be fully available: 0
# of node failures before cluster goes into readonly: NA
# of node failures before cluster goes to be crticial and partially available: 2
# of node failures before cluster goes to enospace warn trying to move the existing data: NA
# of persistent devices failures tolerable for cluster to be fully available: 1
# of persistent devices failures before cluster goes into readonly: NA
# of persistent devices failures before cluster goes to be critical and partially available: 2
# of caching devices failures tolerable for cluster to be fully available: 1
# of caching failures before cluster goes into readonly: NA
# of caching failures before cluster goes to be critical and partially available: 2
Current ensemble size: 3
Minimum data copies available for some user data: 2
Minimum cache copies remaining: 2
Minimum metadata copies available for cluster metadata: 2
Current healing status: Rebuilding/Healing is needed, but not in progress yet. Warning: Insufficient node or space resources may prevent healing. Storage Node 172.16.3.9 is either down or initializing disks.
Time remaining before current healing operation finishes:
# of unavailable nodes: 1
hxshell:~$
Deze output laat een ongezonde cluster zien als gevolg van de heropbouw.
Cluster Health Detail:
---------------------:
State: ONLINE
HealthState: UNHEALTHY
Policy Compliance: NON-COMPLIANT
Creation Time: Tue May 30 04:48:45 2023
Uptime: 7 weeks, 20 hours, 2 mins, 4 secs
Cluster Resiliency Detail:
-------------------------:
Health State Reason: Storage cluster is unhealthy.
# of nodes failure tolerable for cluster to be fully available: 1
# of node failures before cluster goes into readonly: NA
# of node failures before cluster goes to be crticial and partially available: 2
# of node failures before cluster goes to enospace warn trying to move the existing data: NA
# of persistent devices failures tolerable for cluster to be fully available: 1
# of persistent devices failures before cluster goes into readonly: NA
# of persistent devices failures before cluster goes to be critical and partially available: 2
# of caching devices failures tolerable for cluster to be fully available: 1
# of caching failures before cluster goes into readonly: NA
# of caching failures before cluster goes to be critical and partially available: 2
Current ensemble size: 3
Minimum data copies available for some user data: 3
Minimum cache copies remaining: 2
Minimum metadata copies available for cluster metadata: 2
Current healing status: Rebuilding is in progress, 58% completed.
Time remaining before current healing operation finishes: 18 hr(s), 10 min(s), and 53 sec(s)
# of unavailable nodes: 0Deze opdrachten tonen een algemene samenvatting van de gezondheid van het cluster en laten u weten of er iets van invloed is op de werking van het cluster, bijvoorbeeld, als er een schijf op de zwarte lijst staat, een offline knooppunt, of als het cluster geneest.
Knooppunten die deelnemen aan I/O
De prestaties kunnen worden beïnvloed door een knooppunt dat niet deelneemt aan de in- en uitvoerbewerkingen, om te controleren of de knooppunten die deelnemen aan I/O, deze opdrachten geven.
Tip: vanaf versie 5.0(2a) is diag-gebruiker beschikbaar zodat gebruikers meer rechten hebben om problemen op te lossen met toegang tot beperkte mappen en opdrachten die niet toegankelijk zijn via priv-opdrachtregel die in Hyperflex versie 4.5.x is geïntroduceerd.
Stap 1. Vul de diagramhuls in op een opslagcontroller VM.
hxshell:~$ su diag
Password:
_ _ _ _ _ _____ _ ___
| \ | (_)_ __ ___ | || | | ___(_)_ _____ / _ \ _ __ ___
| \| | | '_ \ / _ \ _____ | || |_ _____ | |_ | \ \ / / _ \ _____ | | | | '_ \ / _ \
| |\ | | | | | __/ |_____| |__ _| |_____| | _| | |\ V / __/ |_____| | |_| | | | | __/
|_| \_|_|_| |_|\___| |_| |_| |_| \_/ \___| \___/|_| |_|\___|
Enter the output of above expression: -1
Valid captcha
Stap 2. Voer deze opdracht uit om de knooppunten die deelnemen aan I/O-bewerkingen te verifiëren, het aantal IP’s moet gelijk zijn aan het aantal geconvergeerde knooppunten op het cluster.
diag# nfstool -- -m | cut -f2 | sort | uniq
172.16.3.7
172.16.3.8
172.16.3.9Interne servicescontrole
reinigingsmiddel
Een van de belangrijkste doelstellingen van Cleaner is om dode en levende opslagblokken in het systeem te identificeren en de dode te verwijderen, waardoor de opslagruimte die ze bezet houden vrij komt. Het is een achtergrond baan, en de agressiviteit wordt bepaald op basis van een beleid.
U kunt de schoonmaakdienst controleren door de volgende opdracht uit te geven.
bash-4.2# stcli cleaner info
{ 'name': '172.16.3.7', 'id': '1f82077d-6702-214d-8814-e776ffc0f53c', 'type': 'node' }: OFFLINE <----------- Cleaner shows as offline
{ 'name': '172.16.3.8', 'id': 'c4a24480-e935-6942-93ee-987dc8e9b5d9', 'type': 'node' }: OFFLINE
{ 'name': '172.16.3.9', 'id': '50a5dc5d-c419-9c48-8914-d91a98d43fe7', 'type': 'node' }: OFFLINE
Om het schonere proces te starten, geeft u deze opdracht uit.
bash-4.2# stcli cleaner start
WARNING: This command should be executed ONLY by Cisco TAC support as it may have very severe consequences. Do you want to proceed ? (y/n): y
bash-4.2# stcli cleaner info
{ 'type': 'node', 'id': '1f82077d-6702-214d-8814-e776ffc0f53c', 'name': '172.16.3.7' }: ONLINE
{ 'type': 'node', 'id': 'c4a24480-e935-6942-93ee-987dc8e9b5d9', 'name': '172.16.3.8' }: ONLINE
{ 'type': 'node', 'id': '50a5dc5d-c419-9c48-8914-d91a98d43fe7', 'name': '172.16.3.9' }: ONLINE <---------All nodes need to be online
bash-4.2# 
Waarschuwing: deze opdracht moet worden uitgevoerd met Cisco TAC-goedkeuring.
herbalanceren
Het opslagcluster wordt volgens een regelmatig schema opnieuw in balans gebracht. Het wordt gebruikt om de distributie van opgeslagen gegevens over veranderingen in beschikbare opslag te hergroeperen en de gezondheid van de opslagcluster te herstellen.
Herbalancering loopt in clusters om verschillende redenen:
- Een fysiek resource (knooppunt/schijf) is ingestort en HX verplaatst deze knooppunten naar een ander fysiek resource in het cluster.
- De afzonderlijke schijven in het cluster worden niet allemaal op vergelijkbare wijze gebruikt en daarom zijn er enkele hotspots gecreëerd in termen van beschikbaarheid van gegevens binnen het HX-cluster (data collocation).
- De herbalans kan ook lopen als de naleving van de Zone er niet is zelfs als het cluster gezond is.
- Wanneer een nieuw knooppunt aan het bestaande cluster wordt toegevoegd, nemen de toegevoegde knooppunt(en) nieuwe schrijfbewerkingen over zodra het zich bij het bestaande cluster aansluit.
Controleer of het cluster opnieuw in balans is gebracht.
hxshell:~$ stcli rebalance status
rebalanceStatus:
percentComplete: 0
rebalanceState: cluster_rebalance_not_running
rebalanceEnabled: True <---------Rebalance should be enabled
hxshell:~$
Waarschuwing: elke bewerking die betrekking heeft op opnieuw balanceren, moet worden uitgevoerd met goedkeuring van Cisco TAC.
Schijffout
Voor een goede werking mag het cluster geen schijven op de zwarte lijst of offline bronnen hebben.
U moet controleren of er een schijf op de zwarte lijst staat op het cluster in de HX Connect-interface.
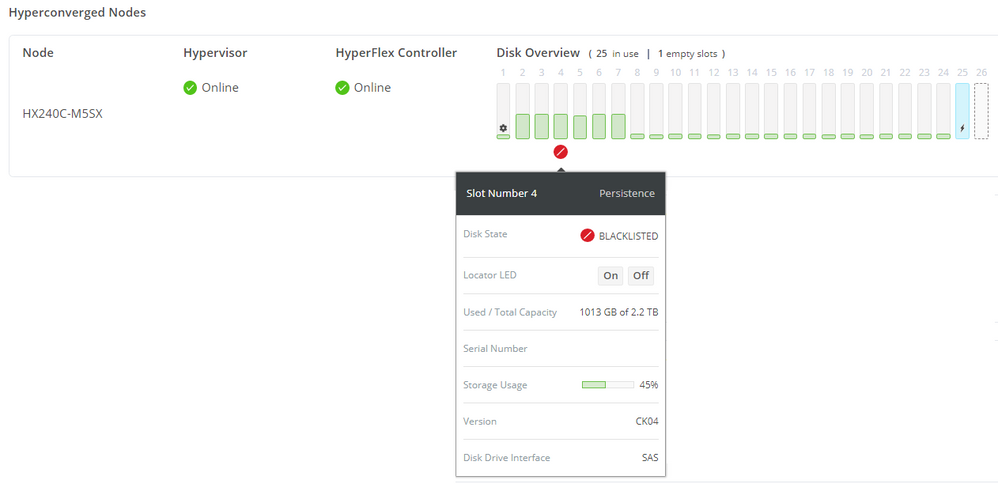 Schijf op de zwarte lijst.
Schijf op de zwarte lijst.
Controleer de CLI op alle offline resources op elk convergentieknooppunt.
sysmtool --ns cluster --cmd offlineresources
UUID Type State InUse Last modified
---- ---- ----- ----- -------------
000cca0b019b4a80:0000000000000000 DISK DELETED YES <------- Offline disk
5002538c405e0bd1:0000000000000000 DISK BLOCKLISTED NO <------- Blacklisted disk
5002538c405e299e:0000000000000000 DISK DELETED NO
Total offline resources: 3, Nodes: 0, Disks: 3Controleer of er middelen op de zwarte lijst staan.
hxshell:~$ sysmtool --ns disk --cmd list | grep -i blacklist
Blacklist Count: 0
Blacklist Count: 0
Blacklist Count: 0
Blacklist Count: 0
State: BLACKLISTED
Blacklist Count: 5
Blacklist Count: 0
Blacklist Count: 0
U dient te controleren of er bij deze opdracht een defecte schijf is in elk conversieknooppunt.
admin:~$ cat /var/log/springpath/diskslotmap-v2.txt
0.0.1:5002538e000d59a3:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M302248:HXT76F3Q:SATA:SSD:3662830:Inactive:/dev/sdj <---------Inactive disk
1.0.2:5002538c40be79ac:Samsung:SAMSUNG_MZ7LM240HMHQ-00003:S4EGNX0KC04551:GXT51F3Q:SATA:SSD:228936:Active:/dev/sdb
1.0.3:5002538e000d599e:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M302243:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sdc
1.0.4:5002538e000d59a0:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M302245:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sdd
1.0.5:5002538e000eb00b:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M302480:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sdi
1.0.6:5002538e000d599b:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M302240:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sdf
1.0.7:5002538e000d57f6:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M301819:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sdh
1.0.8:5002538e000d59ab:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M302256:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sde
1.0.9:5002538e000d59a1:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M302246:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sdg
1.0.10:5002538e0008c68f:Samsung:SAMSUNG_MZ7LH3T8HMLT-00003:S4F3NY0M200500:HXT76F3Q:SATA:SSD:3662830:Active:/dev/sdj
0.1.192:000cca0b01c83180:HGST:UCSC-NVMEHW-H1600:SDM000026904:KNCCD111:NVMe:SSD:1526185:Active:/dev/nvme0n1
admin:~$Voorbeeld van een knooppunt zonder schijffout.
hxshell:~$ sysmtool --ns cluster --cmd offlineresources
No offline resources found <-------- No offline resources
hxshell:~$ sysmtool --ns disk --cmd list | grep -i blacklist
hxshell:~$ <-------- No blacklisted disks
hxshell:~$ cat /var/log/springpath/diskslotmap-v2.txt
1.14.1:55cd2e404c234bf9:Intel:INTEL_SSDSC2BX016T4K:BTHC618505B51P6PGN:G201CS01:SATA:SSD:1526185:Active:/dev/sdc
1.14.2:5000c5008547c543:SEAGATE:ST1200MM0088:Z4009D7Y0000R637KMU7:N0A4:SAS:10500:1144641:Active:/dev/sdd
1.14.3:5000c5008547be1b:SEAGATE:ST1200MM0088:Z4009G0B0000R635L4D3:N0A4:SAS:10500:1144641:Active:/dev/sde
1.14.4:5000c5008547ca6b:SEAGATE:ST1200MM0088:Z4009F9N0000R637JZRF:N0A4:SAS:10500:1144641:Active:/dev/sdf
1.14.5:5000c5008547b373:SEAGATE:ST1200MM0088:Z4009GPM0000R634ZJHB:N0A4:SAS:10500:1144641:Active:/dev/sdg
1.14.6:5000c500854310fb:SEAGATE:ST1200MM0088:Z4008XFJ0000R6374ZE8:N0A4:SAS:10500:1144641:Active:/dev/sdh
1.14.7:5000c50085424b53:SEAGATE:ST1200MM0088:Z4008D2S0000R635M4VF:N0A4:SAS:10500:1144641:Active:/dev/sdi
1.14.8:5000c5008547bcfb:SEAGATE:ST1200MM0088:Z4009G3W0000R637K1R8:N0A4:SAS:10500:1144641:Active:/dev/sdj
1.14.9:5000c50085479abf:SEAGATE:ST1200MM0088:Z4009J510000R637KL1V:N0A4:SAS:10500:1144641:Active:/dev/sdk
1.14.11:5000c5008547c2c7:SEAGATE:ST1200MM0088:Z4009FR00000R637JPEQ:N0A4:SAS:10500:1144641:Active:/dev/sdl
1.14.13:5000c5008547ba93:SEAGATE:ST1200MM0088:Z4009G8V0000R634ZKLX:N0A4:SAS:10500:1144641:Active:/dev/sdm
1.14.14:5000c5008547b69f:SEAGATE:ST1200MM0088:Z4009GG80000R637KM30:N0A4:SAS:10500:1144641:Active:/dev/sdn
1.14.15:5000c5008547b753:SEAGATE:ST1200MM0088:Z4009GH90000R635L5F6:N0A4:SAS:10500:1144641:Active:/dev/sdo
1.14.16:5000c5008547ab7b:SEAGATE:ST1200MM0088:Z4009H3P0000R634ZK8T:N0A4:SAS:10500:1144641:Active:/dev/sdp <------All disks are active
hxshell:~$
Vrij geheugen
Controleer het vrije geheugen met deze opdracht, het vrije geheugen moet meer dan 2048 MB (gratis +cache) zijn.
hxshell:~$ free –m
total used free shared buff/cache available
Mem: 74225624 32194300 38893712 1672 3137612 41304336
Swap: 0 0 0
hxshell:~$ als het vrije + cachegeheugen kleiner is dan 2048, is nodig om het proces te identificeren dat de Out Of Memory-voorwaarde genereert.
Opmerking: u kunt de bovenste opdracht gebruiken om processen te identificeren die veel geheugen verbruiken. Alle wijzigingen moeten echter worden uitgevoerd met TAC-goedkeuring, neem contact op met Cisco TAC voor probleemoplossing voor de OME-voorwaarden.
End-of-space toestand
De beste praktijk van opslagcluster ruimtegebruik is om niet verder te gaan dan 76 procent bij de HX Connect capaciteitsweergave. Meer dan 76 procent, het gebruik op de HX Connect capaciteitsweergave resulteert in prestatievermindering.
Als het opslagcluster een ENOSPC-omstandigheid ondervindt, draait de schoner automatisch met hoge prioriteit, wat prestatieproblemen in het cluster kan veroorzaken, wordt de prioriteit bepaald door het gebruik van clusterruimte.
Als het opslagcluster een ENOSPC WAARSCHUWING-omstandigheid bereikt, verhoogt het reinigingsmiddel de intensiteit door het aantal I/O-handelingen voor het verzamelen van afval met een ENOSPC-omstandigheid te verhogen, en werkt het met de hoogste prioriteit.
U kunt de ENOSPCINFO-status op het cluster controleren met deze opdracht.
hxshell:~$ sysmtool --ns cluster --cmd enospcinfo
Cluster Space Details:
---------------------:
Cluster state: ONLINE
Health state: HEALTHY
Raw capacity: 42.57T
Usable capacity: 13.06T
Used capacity: 163.08G
Free capacity: 12.90T
Enospc state: ENOSPACE_CLEAR <--------End of space status
Space reclaimable: 0.00
Minimum free capacity
required to resume operation: 687.12G
Space required to clear
ENOSPC warning: 2.80T <--------Free space until the end of space warning appears
Rebalance In Progress: NO
Flusher in progress: NO
Cleaner in progress: YES
Disk Enospace: NO
hxshell:~$
Herzie het Capaciteitsbeheer in Cisco HyperFlex White om de beste praktijken voor het beheer van de ruimte op uw HyperFlex Cluster te identificeren.
Prestatiediagrammen voor probleemoplossing
Soms geven de hyperflex prestatiekaarten geen informatie weer.
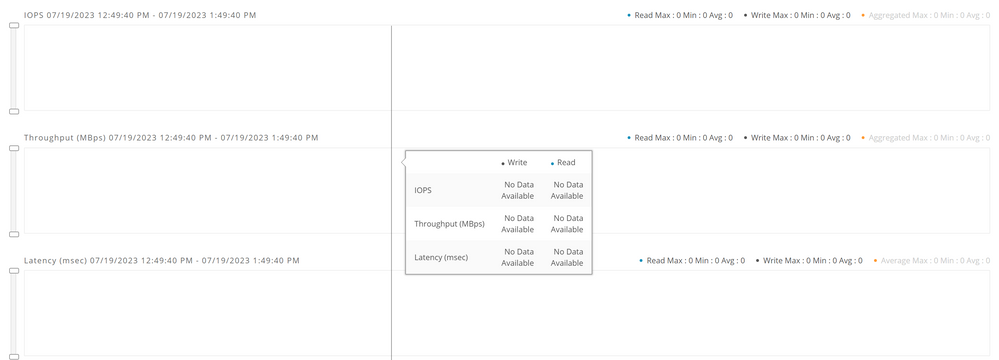 Hyperflex prestatiekaarten.
Hyperflex prestatiekaarten.
Als u met dit gedrag wordt geconfronteerd moet u herzien als de statsdiensten in de cluster lopen.
hxshell:~$ priv service carbon-cache status
carbon-cache stop/waiting
hxshell:~$ priv service carbon-aggregator status
carbon-aggregator stop/waiting
hxshell:~$ priv service statsd status
statsd stop/waiting
Als de processen niet actief zijn, kunt u de services handmatig starten.
hxshell:~$ priv service carbon-cache start
carbon-cache start/running, process 15750
hxshell:~$ priv service carbon-aggregator start
carbon-aggregator start/running, process 15799
hxshell:~$ priv service statsd start
statsd start/running, process 15855Gerelateerde informatie
Revisiegeschiedenis
| Revisie | Publicatiedatum | Opmerkingen |
|---|---|---|
1.0 |
27-Jul-2023 |
Eerste vrijgave |
Bijgedragen door Cisco-engineers
- Alan MedranoCisco TAC Engineer
- Ana MontenegroCX technisch aanvoerder
 Feedback
FeedbackContact Cisco
- Een ondersteuningscase openen

- (Vereist een Cisco-servicecontract)