Ultra-M UCS 240M4 서버의 마더보드 교체 - CPS
다운로드 옵션
편견 없는 언어
본 제품에 대한 문서 세트는 편견 없는 언어를 사용하기 위해 노력합니다. 본 설명서 세트의 목적상, 편견 없는 언어는 나이, 장애, 성별, 인종 정체성, 민족 정체성, 성적 지향성, 사회 경제적 지위 및 교차성에 기초한 차별을 의미하지 않는 언어로 정의됩니다. 제품 소프트웨어의 사용자 인터페이스에서 하드코딩된 언어, RFP 설명서에 기초한 언어 또는 참조된 서드파티 제품에서 사용하는 언어로 인해 설명서에 예외가 있을 수 있습니다. 시스코에서 어떤 방식으로 포용적인 언어를 사용하고 있는지 자세히 알아보세요.
이 번역에 관하여
Cisco는 전 세계 사용자에게 다양한 언어로 지원 콘텐츠를 제공하기 위해 기계 번역 기술과 수작업 번역을 병행하여 이 문서를 번역했습니다. 아무리 품질이 높은 기계 번역이라도 전문 번역가의 번역 결과물만큼 정확하지는 않습니다. Cisco Systems, Inc.는 이 같은 번역에 대해 어떠한 책임도 지지 않으며 항상 원본 영문 문서(링크 제공됨)를 참조할 것을 권장합니다.
목차
소개
이 문서에서는 CPS VNF(Virtual Network Functions)를 호스팅하는 Ultra-M 설정에서 서버의 결함이 있는 마더보드를 교체하는 데 필요한 단계를 설명합니다.
배경 정보
Ultra-M은 VNF 구축을 간소화하기 위해 설계된 사전 패키지 및 검증된 가상화 모바일 패킷 코어 솔루션입니다.OpenStack은 Ultra-M용 VIM(Virtualized Infrastructure Manager)이며 다음 노드 유형으로 구성됩니다.
- 컴퓨팅
- 개체 스토리지 디스크 - 컴퓨팅(OSD - 컴퓨팅)
- 컨트롤러
- OpenStack Platform - 디렉터(OSPD)
Ultra-M 및 관련 구성 요소의 고급 아키텍처는 다음 이미지에 설명되어 있습니다.

이 문서는 Cisco Ultra-M 플랫폼에 익숙한 Cisco 담당자를 대상으로 하며, 서버에서 마더보드 교체 시 OpenStack 및 StarOS VNF 레벨에서 수행해야 하는 단계를 자세히 설명합니다.
참고:Ultra M 5.1.x 릴리스는 이 문서의 절차를 정의하기 위해 고려됩니다.
약어
| VNF | 가상 네트워크 기능 |
| ESC | Elastic Service Controller |
| MOP | 절차 방법 |
| OSD | 개체 스토리지 디스크 |
| HDD | 하드 디스크 드라이브 |
| SSD | 솔리드 스테이트 드라이브 |
| VIM | 가상 인프라 관리자 |
| VM | 가상 머신 |
| EM | 요소 관리자 |
| UAS | Ultra Automation 서비스 |
| UUID | 보편적으로 고유한 IDentifier |
MoP 워크플로
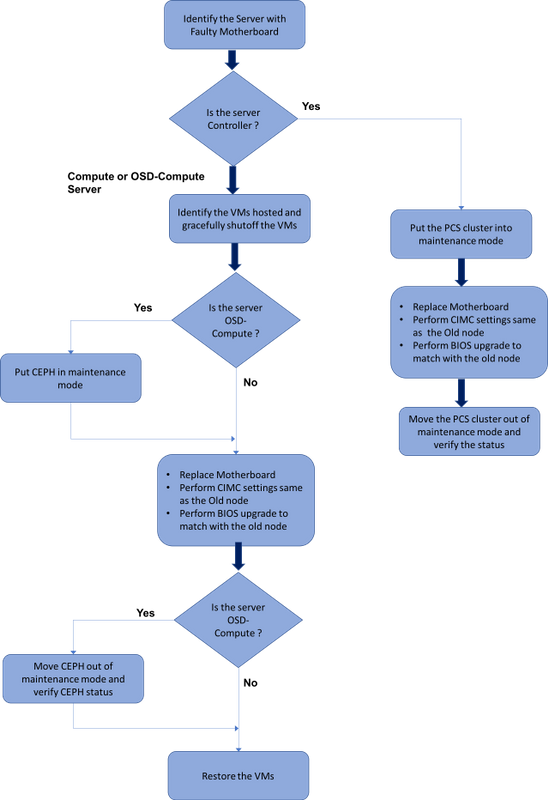
Ultra-M 설정에서 마더보드 교체
Ultra-M 설정에서는 다음 서버 유형에서 마더보드 교체가 필요한 경우가 있을 수 있습니다.컴퓨팅, OSD-컴퓨팅 및 컨트롤러
참고:마더보드를 교체한 후 openstack이 설치된 부팅 디스크가 교체됩니다.따라서 노드를 다시 오버클라우드에 추가할 필요가 없습니다.교체 작업 후 서버의 전원이 켜지면 오버클라우드 스택에 다시 등록됩니다.
컴퓨팅 노드의 마더보드 교체
활동 전에 컴퓨팅 노드에 호스팅된 VM이 정상적으로 차단됩니다.마더보드를 교체하면 VM이 다시 복원됩니다.
컴퓨팅 노드에서 호스팅되는 VM 식별
컴퓨팅 서버에서 호스팅되는 VM을 식별합니다.
컴퓨팅 서버에는 CPS 또는 ESC(Elastic Services Controller) VM이 포함되어 있습니다.
[stack@director ~]$ nova list --field name,host | grep compute-8
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
참고:여기에 표시된 출력에서 첫 번째 열은 UUID(Universally Unique IDenticfier)에 해당하고, 두 번째 열은 VM 이름이고, 세 번째 열은 VM이 있는 호스트 이름입니다.이 출력의 매개변수는 후속 섹션에서 사용됩니다.
정상 전원 끄기
컴퓨팅 노드는 CPS/ESC VM을 호스팅합니다.
1단계. VNF에 해당하는 ESC 노드에 로그인하고 VM의 상태를 확인합니다.
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_ALIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
<state>VM_ALIVE_STATE</state>
<snip>
2단계. VM 이름을 사용하여 CPS VM을 하나씩 중지합니다.(VM 이름은 컴퓨팅 노드에서 호스팅되는 VM을 식별하는 섹션에서 표시됨)
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli vm-action STOP VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea
3단계. 중지되면 VM이 SHUTOFF 상태로 전환되어야 합니다.
[admin@VNF2-esc-esc-0 ~]$ cd /opt/cisco/esc/esc-confd/esc-cli
[admin@VNF2-esc-esc-0 esc-cli]$ ./esc_nc_cli get esc_datamodel | egrep --color "<state>|<vm_name>|<vm_id>|<deployment_name>"
<snip>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229</vm_name>
<state>VM_SHUTOFF_STATE</state>
<vm_name>VNF2-DEPLOYM_c3_0_3e0db133-c13b-4e3d-ac14-
<state>VM_ALIVE_STATE</state>
<deployment_name>VNF2-DEPLOYMENT-em</deployment_name>
<vm_id>507d67c2-1d00-4321-b9d1-da879af524f8</vm_id>
<vm_id>dc168a6a-4aeb-4e81-abd9-91d7568b5f7c</vm_id>
<vm_id>9ffec58b-4b9d-4072-b944-5413bf7fcf07</vm_id>
<state>SERVICE_ACTIVE_STATE</state>
<vm_name>VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea</vm_name>
VM_SHUTOFF_STATE
<snip>
4단계. 컴퓨팅 노드에 호스팅된 ESC에 로그인하여 마스터 상태에 있는지 확인합니다.대답이 "예"인 경우 ESC를 대기 모드로 전환합니다.
[admin@VNF2-esc-esc-0 esc-cli]$ escadm status
0 ESC status=0 ESC Master Healthy
[admin@VNF2-esc-esc-0 ~]$ sudo service keepalived stop
Stopping keepalived: [ OK ]
[admin@VNF2-esc-esc-0 ~]$ escadm status
1 ESC status=0 In SWITCHING_TO_STOP state. Please check status after a while.
[admin@VNF2-esc-esc-0 ~]$ sudo reboot
Broadcast message from admin@vnf1-esc-esc-0.novalocal
(/dev/pts/0) at 13:32 ...
The system is going down for reboot NOW!
ESC 백업
1단계. ESC는 UltraM 솔루션에서 1:1 리던던시를 갖습니다.2 ESC VM이 구축되어 UltraM에서 단일 장애를 지원합니다.즉, 시스템에 단일 장애가 발생하면 시스템이 복구됩니다.
참고:하나 이상의 장애가 있는 경우 지원되지 않으며 시스템 재구축이 필요할 수 있습니다.
ESC 백업 세부 정보:
- 실행 중인 컨피그레이션
- ConfD CDB DB
- ESC 로그
- Syslog 컨피그레이션
2단계. ESC DB 백업의 빈도는 까다롭기 때문에 ESC가 구축된 다양한 VNF VM에 대해 다양한 상태 시스템을 모니터링하고 유지 관리할 때 신중하게 처리해야 합니다.이러한 백업은 지정된 VNF/POD/사이트에서 다음 작업을 수행한 후에 수행하는 것이 좋습니다.
3단계. ESC의 상태가 health.sh 스크립트를 사용하는 데 적합한지 확인합니다.
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Master Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (MASTER) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
4단계. 실행 중인 컨피그레이션의 백업을 수행하고 파일을 백업 서버로 전송합니다.
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
ESC 데이터베이스 백업
1단계. 백업을 수행하기 전에 ESC VM에 로그인하고 이 명령을 실행합니다.
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
2단계. ESC 모드를 선택하고 유지 관리 모드에 있는지 확인합니다.
[root@esc esc-scripts]# escadm op_mode show
3단계. ESC에서 데이터베이스 백업 복원 도구를 사용하여 데이터베이스를 백업합니다.
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://
:
@
:
4단계. Esc를 Operation Mode(작업 모드)로 설정하고 모드를 확인합니다.
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
5단계. scripts 디렉토리로 이동하여 로그를 수집합니다.
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
6단계. ESC의 스냅샷을 생성하려면 먼저 ESC를 종료합니다.
shutdown -r now
7단계. OSPD에서 이미지 스냅샷을 생성합니다.
-
nova image-create --poll esc1 esc_snapshot_27aug2018
8단계. 스냅샷이 생성되었는지 확인합니다.
openstack image list | grep esc_snapshot_27aug2018
9단계. OSPD에서 ESC를 시작합니다.
nova start esc1
10단계. 대기 ESC VM에서 동일한 절차를 반복하고 로그를 백업 서버로 전송합니다.
11단계. ESC VMS 양쪽에서 syslog 컨피그레이션 백업을 수집하고 이를 백업 서버로 전송합니다.
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
마더보드 교체
1단계. UCS C240 M4 서버의 마더보드를 교체하기 위한 단계는 다음 위치에서 참조할 수 있습니다.
Cisco UCS C240 M4 서버 설치 및 서비스 가이드
2단계. CIMC IP를 사용하여 서버에 로그인합니다.
3단계. 펌웨어가 이전에 사용한 권장 버전에 따라 다르면 BIOS 업그레이드를 수행합니다.BIOS 업그레이드 단계는 다음과 같습니다.
Cisco UCS C-Series 랙 마운트 서버 BIOS 업그레이드 가이드
VM 복원
컴퓨팅 노드 CPS 호스트, ESC
ESC VM 복구
1단계. VM이 오류 또는 종료 상태인 경우 ESC VM을 복구할 수 있습니다. VM이 영향을 받는 VM을 가져오기 위해 하드 리부팅을 수행합니다.다음 단계를 실행하여 ESC를 복구합니다.
2단계. ERROR 또는 Shutdown 상태의 VM을 식별한 후 ESC VM을 하드 재부팅합니다.이 예에서는 auto-test-vnfm1-ESC-0을 재부팅합니다.
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.57.12.11; auto-testautovnf1-uas-management=172.57.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.57.12.15; auto-testautovnf1-uas-management=172.57.11.5 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
3단계. ESC VM이 삭제되어 다시 시작해야 하는 경우
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.14; vnf1-UAS-uas-management=172.168.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
4단계. OSPD에서 새 ESC VM이 활성/실행 중인지 확인합니다.
[stack@pod1-ospd ~]$ nova list|grep -i esc
| 934519a4-d634-40c0-a51e-fc8d55ec7144 | vnf1-ESC-ESC-0 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.13; vnf1-UAS-uas-management=172.168.10.3 |
| 2601b8ec-8ff8-4285-810a-e859f6642ab6 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.168.11.14; vnf1-UAS-uas-management=172.168.10.6 |
#Log in to new ESC and verify Backup state. You may execute health.sh on ESC Master too.
…
####################################################################
# ESC on vnf1-esc-esc-1.novalocal is in BACKUP state.
####################################################################
[admin@esc-1 ~]$ escadm status
0 ESC status=0 ESC Backup Healthy
[admin@esc-1 ~]$ health.sh
============== ESC HA (BACKUP) =================
=======================================
ESC HEALTH PASSED
[admin@esc-1 ~]$ cat /proc/drbd
version: 8.4.7-1 (api:1/proto:86-101)
GIT-hash: 3a6a769340ef93b1ba2792c6461250790795db49 build by mockbuild@Build64R6, 2016-01-12 13:27:11
1: cs:Connected ro:Secondary/Primary ds:UpToDate/UpToDate C r-----
ns:0 nr:504720 dw:3650316 dr:0 al:8 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
5단계. ESC VM을 복구할 수 없고 데이터베이스를 복원해야 하는 경우 이전에 수행한 백업에서 데이터베이스를 복원하십시오.
6단계. ESC 데이터베이스 복원의 경우 데이터베이스를 복원하기 전에 Esc 서비스를 중지해야 합니다.ESC HA의 경우 먼저 보조 VM에서 실행한 다음 기본 VM에서 실행합니다.
# service keepalived stop
7단계. ESC 서비스 상태를 확인하고 HA용 기본 및 보조 VM에서 모두 중지되었는지 확인합니다.
# escadm status
8단계. 스크립트를 실행하여 데이터베이스를 복원합니다.DB를 새로 생성된 ESC 인스턴스로 복원하는 과정에서 이 툴은 인스턴스 중 하나를 기본 ESC로 승격하고 해당 DB 폴더를 DRBD 디바이스에 마운트하고 PostgreSQL 데이터베이스를 시작합니다.
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://
:
@
:
9단계. ESC 서비스를 다시 시작하여 데이터베이스 복원을 완료합니다.
두 VM에서 HA를 실행하려면 keepalive 서비스를 다시 시작하십시오.
# service keepalived start
10단계. VM이 성공적으로 복원되고 실행되면이전에 성공한 알려진 백업에서 모든 syslog 관련 컨피그레이션이 복원되었는지 확인합니다.모든 ESC VM에서 복원되었는지 확인합니다.
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
11단계. OSPD 스냅샷에서 ESC를 다시 작성해야 하는 경우 백업 중에 생성된 스냅샷을 사용하여 아래 명령을 사용하십시오.
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
12단계. 재구축이 완료된 후 ESC의 상태를 확인합니다.
nova list --fileds name,host,status,networks | grep esc
13단계. 아래 명령을 사용하여 ESC 상태를 확인합니다.
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
CPS VM을 복원합니다.
CPS VM은 nova 목록에서 오류 상태가 됩니다.
[stack@director ~]$ nova list |grep VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d | ERROR | - | NOSTATE |
ESC에서 CPS VM을 복구합니다.
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
<?xml version="1.0" encoding="UTF-8"?>
<rpc-reply xmlns="urn:ietf:params:xml:ns:netconf:base:1.0" message-id="1">
<ok/>
</rpc-reply>
양세초로그를 모니터링합니다.
admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d].
ESC가 VM을 시작하지 못하는 경우
1단계. 예기치 않은 상태로 인해 ESC가 VM을 시작하지 못하는 경우도 있습니다.해결 방법은 마스터 ESC를 재부팅하여 ESC 전환을 수행하는 것입니다.ESC 전환에는 약 1분이 소요됩니다. 새 마스터 ESC에서 health.sh를 실행하여 작동 중인지 확인합니다.ESC가 마스터가 되면 ESC는 VM 상태를 수정하고 VM을 시작할 수 있습니다.이 작업이 예약되었으므로 작업이 완료될 때까지 5-7분 기다려야 합니다.
2단계. /var/log/esc/yangesc.log 및 /var/log/esc/escmanager.log을 모니터링할 수 있습니다.5~7분 후 VM이 복구되지 않는 경우, 사용자는 이동하여 영향을 받는 VM을 수동으로 복구해야 합니다.
3단계 VM이 성공적으로 복원되고 실행되면이전에 성공한 알려진 백업에서 모든 syslog 관련 컨피그레이션이 복원되었는지 확인합니다.모든 ESC VM에서 복원되었는지 확인합니다.
root@autotestvnfm1esc2:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@autotestvnfm1esc2:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
OSD 컴퓨팅 노드의 마더보드 교체
활동 전에 컴퓨팅 노드에 호스팅된 VM이 정상적으로 종료되고 CEPH가 유지 관리 모드로 전환됩니다.마더보드를 교체하면 VM이 다시 복원되고 CEPH가 유지 보수 모드에서 벗어납니다.
CEPH를 유지 관리 모드로 전환
1단계. CEPH osd 트리 상태가 서버에 있는지 확인합니다.
[heat-admin@pod1-osd-compute-1 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod1-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod1-osd-compute-2
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod1-osd-compute-1
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
2단계. OSD Compute(OSD 컴퓨팅) 노드에 로그인하고 CEPH를 유지 관리 모드로 설정합니다.
[root@pod1-osd-compute-1 ~]# sudo ceph osd set norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd set noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e194: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v584865: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 463 kB/s rd, 14903 kB/s wr, 263 op/s rd, 542 op/s wr
참고:CEPH를 제거하면 VNF HD RAID가 저하됨(Degraded) 상태로 전환되지만 hd-disk에 계속 액세스할 수 있어야 합니다.
OSD-컴퓨팅 노드에서 호스팅되는 VM 식별
OSD 컴퓨팅 서버에서 호스팅되는 VM을 식별합니다.
컴퓨팅 서버에는 ESC(Elastic Services Controller) 또는 CPS VM이 포함되어 있습니다.
[stack@director ~]$ nova list --field name,host | grep osd-compute-1
| 507d67c2-1d00-4321-b9d1-da879af524f8 | VNF2-DEPLOYM_XXXX_0_c8d98f0f-d874-45d0-af75-88a2d6fa82ea | pod1-compute-8.localdomain |
| f9c0763a-4a4f-4bbd-af51-bc7545774be2 | VNF2-DEPLOYM_c1_0_df4be88d-b4bf-4456-945a-3812653ee229 | pod1-compute-8.localdomain |
| 75528898-ef4b-4d68-b05d-882014708694 | VNF2-ESC-ESC-0 | pod1-compute-8.localdomain |
| f5bd7b9c-476a-4679-83e5-303f0aae9309 | VNF2-UAS-uas-0 | pod1-compute-8.localdomain |
참고:여기에 표시된 출력에서 첫 번째 열은 UUID(Universally Unique IDentifier)에 해당하고, 두 번째 열은 VM 이름이고, 세 번째 열은 VM이 있는 호스트 이름입니다.이 출력의 매개변수는 후속 섹션에서 사용됩니다.
정상 전원 끄기
케이스 1. OSD-Compute 노드가 ESC를 호스팅함
ESC 또는 CPS VM의 전원을 정상적으로 켜는 절차는 VM이 컴퓨팅 또는 OSD-컴퓨팅 노드에서 호스팅되는지 여부와 상관없이 동일합니다.
"컴퓨팅 노드의 마더보드 교체"에서 VM의 전원을 정상적으로 끄려면 다음 단계를 수행하십시오.
마더보드 교체
1단계. UCS C240 M4 서버의 마더보드를 교체하기 위한 단계는 다음 사이트에서 참조할 수 있습니다.
Cisco UCS C240 M4 서버 설치 및 서비스 가이드
2단계. CIMC IP를 사용하여 서버에 로그인합니다.
3. 펌웨어가 이전에 사용한 권장 버전에 따라 다르면 BIOS 업그레이드를 수행합니다.BIOS 업그레이드 단계는 다음과 같습니다.
Cisco UCS C-Series 랙 마운트 서버 BIOS 업그레이드 가이드
유지 관리 모드에서 CEPH 이동
OSD Compute(OSD 컴퓨팅) 노드에 로그인하고 CEPH를 유지 보수 모드에서 꺼냅니다.
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset norebalance
[root@pod1-osd-compute-1 ~]# sudo ceph osd unset noout
[root@pod1-osd-compute-1 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod1-controller-0=11.118.0.40:6789/0,pod1-controller-1=11.118.0.41:6789/0,pod1-controller-2=11.118.0.42:6789/0}
election epoch 58, quorum 0,1,2 pod1-controller-0,pod1-controller-1,pod1-controller-2
osdmap e196: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v584954: 704 pgs, 6 pools, 531 GB data, 344 kobjects
1585 GB used, 11808 GB / 13393 GB avail
704 active+clean
client io 12888 kB/s wr, 0 op/s rd, 81 op/s wr
VM 복원
케이스 1. ESC 또는 CPS VM을 호스팅하는 OSD-컴퓨팅 노드
CF/ESC/EM/UAS VM의 복원 절차는 VM이 컴퓨팅 또는 OSD-컴퓨팅 노드에서 호스팅되는지 여부에 관계없이 동일합니다.
"Case 2. Compute Node Hosts CF/ESC/EM/UAS"에서 VM을 복원하려면 다음 단계를 수행합니다.
컨트롤러 노드의 마더보드 교체
컨트롤러 상태를 확인하고 클러스터를 유지 관리 모드로 전환
OSPD에서 컨트롤러에 로그인하고 pcs가 정상인지 확인합니다. 세 컨트롤러 모두 온라인 및 갤러리에서 3개의 컨트롤러를 모두 마스터로 표시합니다.
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:46:10 2017 Last change: Wed Nov 29 01:20:52 2017 by hacluster via crmd on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-0
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-0
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
클러스터를 유지 관리 모드로 설정합니다.
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 00:48:24 2017 Last change: Mon Dec 4 00:48:18 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Node pod1-controller-0: standby
Online: [ pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-1 pod1-controller-2 ]
Stopped: [ pod1-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-1 pod1-controller-2 ]
Slaves: [ pod1-controller-0 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-1 ]
Stopped: [ pod1-controller-0 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
마더보드 교체
1단계. UCS C240 M4 서버의 마더보드를 교체하기 위한 단계는 다음 위치에서 참조할 수 있습니다.
Cisco UCS C240 M4 서버 설치 및 서비스 가이드
2단계. CIMC IP를 사용하여 서버에 로그인합니다.
3단계. 펌웨어가 이전에 사용한 권장 버전에 따라 다르면 BIOS 업그레이드를 수행합니다.BIOS 업그레이드 단계는 다음과 같습니다.
Cisco UCS C-Series 랙 마운트 서버 BIOS 업그레이드 가이드
클러스터 상태 복원
영향을 받는 컨트롤러에 로그인하고, 대기 모드 제거(unstandby 설정)를 설정합니다.컨트롤러가 클러스터와 함께 온라인 상태로 오는지 확인하고 Galera는 세 개의 컨트롤러를 모두 마스터로 표시합니다.몇 분 정도 걸릴 수 있습니다.
[heat-admin@pod1-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod1-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod1-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Mon Dec 4 01:08:10 2017 Last change: Mon Dec 4 01:04:21 2017 by root via crm_attribute on pod1-controller-0
3 nodes and 22 resources configured
Online: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Full list of resources:
ip-11.118.0.42 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-11.119.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
ip-11.120.0.49 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
ip-192.200.0.102 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: haproxy-clone [haproxy]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
ip-11.120.0.47 (ocf::heartbeat:IPaddr2): Started pod1-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod1-controller-0 pod1-controller-1 pod1-controller-2 ]
Master/Slave Set: redis-master [redis]
Masters: [ pod1-controller-2 ]
Slaves: [ pod1-controller-0 pod1-controller-1 ]
ip-10.84.123.35 (ocf::heartbeat:IPaddr2): Started pod1-controller-1
openstack-cinder-volume (systemd:openstack-cinder-volume): Started pod1-controller-2
my-ipmilan-for-controller-0 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-1 (stonith:fence_ipmilan): Started pod1-controller-1
my-ipmilan-for-controller-2 (stonith:fence_ipmilan): Started pod1-controller-2
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enable
Cisco 엔지니어가 작성
- Nitesh Bansal
- Rishi ShekharCisco 고급 서비스
 피드백
피드백지원 문의
- 지원 케이스 접수

- (시스코 서비스 계약 필요)