소개
이 문서에서는 CEF(Cisco Express Forwarding)에 대해 설명합니다. switching Cisco 12000 Series Internet Router의 구현 방식을 알아보십시오.
사전 요구 사항
요구 사항
이 문서에 대한 특정 요건이 없습니다.
사용되는 구성 요소
이 문서는 특정 소프트웨어 및 하드웨어 버전으로 한정되지 않습니다.
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다. 이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다. 현재 네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 미리 숙지하시기 바랍니다.
표기 규칙
문서 규칙에 대한 자세한 내용은 Cisco 기술 팁 표기 규칙을 참조하십시오.
개요
Cisco CEF(Express Forwarding) 스위칭은 수요 캐싱과 관련된 문제를 해결하기 위한 확장형 스위칭의 독점적인 형식입니다. CEF 스위칭에서는 일반적으로 경로 캐시에 저장된 정보를 여러 데이터 구조로 나눕니다. CEF 코드는 GRP(Gigabit Route Processor) 및 12000 라우터의 라인 카드와 같은 보조 프로세서에서 이러한 데이터 구조를 유지할 수 있습니다. 효율적인 패킷 전달을 위해 최적화된 조회 기능을 제공하는 데이터 구조는 다음과 같습니다.
-
FIB(Forwarding Information Base) 테이블 - CEF는 FIB를 사용하여 IP 대상 접두사 기반 스위칭 결정을 내립니다. FIB는 라우팅 테이블 또는 정보 베이스와 개념상 유사합니다. IP 라우팅 테이블에 포함된 포워딩 정보의 미러 이미지를 유지 관리합니다. 네트워크에서 라우팅 또는 토폴로지 변경이 발생하면 IP 라우팅 테이블이 업데이트되고 이러한 변경 사항이 FIB에 반영됩니다. FIB는 IP 라우팅 테이블의 정보를 기반으로 next-hop 주소 정보를 유지 관리합니다. FIB 엔트리와 라우팅 테이블 엔트리 간에는 일대일 상관관계가 있으므로 FIB에는 알려진 모든 경로가 포함되며 고속 스위칭, 최적 스위칭 등의 스위칭 경로와 관련된 경로 캐시 유지 보수의 필요성을 제거합니다.
-
인접성 테이블 - 네트워크의 노드는 링크 레이어에 걸쳐 단일 홉으로 서로 도달할 수 있는 경우 인접하다고 합니다. FIB 외에도 CEF는 인접성 테이블을 사용하여 레이어 2 주소 지정 정보를 추가합니다. 인접성 테이블은 모든 FIB 항목에 대한 레이어 2 next-hop 주소를 유지 관리합니다.
CEF는 다음 두 모드 중 하나로 활성화할 수 있습니다.
-
Central CEF mode(중앙 CEF 모드) - CEF 모드가 활성화되면 CEF FIB 및 인접성 테이블이 경로 프로세서에 상주하며 경로 프로세서가 빠른 전달을 수행합니다. 라인 카드를 CEF 스위칭에 사용할 수 없거나 분산 CEF 스위칭과 호환되지 않는 기능을 사용해야 하는 경우 CEF 모드를 사용할 수 있습니다.
-
dCEF(Distributed CEF) 모드 - dCEF가 활성화된 경우 라인 카드는 FIB 및 인접성 테이블의 동일한 복사본을 유지합니다. 라인 카드는 직접 익스프레스 포워딩을 수행할 수 있으며, 이는 주 프로세서인 GRP(Gigabit Route Processor)가 스위칭 작업에 관여하는 것을 완화합니다. 이는 Cisco 12000 Series Router에서 사용할 수 있는 유일한 스위칭 방법입니다.
dCEF는 IPC(Inter-Process Communication) 메커니즘을 사용하여 경로 프로세서와 라인 카드의 FIB 및 인접성 테이블의 동기화를 보장합니다.
CEF 스위칭에 대한 자세한 내용은 Cisco Express Forwarding (CEF) 백서를 참조하십시오.
CEF 운영
GRP 라우팅 테이블 업데이트
그림 1은 라우팅 업데이트 패킷이 GRP(Gigabit Route Processor)로 전송되고 그 결과 포워딩 업데이트 메시지가 라인 카드의 FIB 테이블로 전송되는 프로세스를 보여줍니다.
명확하게 하기 위해 다음 단락의 번호 매기는 그림 1의 번호 매기와 일치합니다.
다음 프로세스는 경로 테이블을 초기화하는 동안 또는 네트워크 토폴로지가 변경될 때(경로가 추가, 제거 또는 변경될 때) 발생합니다. 그림 1의 프로세스는 크게 5단계로 이루어져 있습니다.
-
IP 데이터그램이 수신 라인 카드(인그레스 라인 카드)의 입력 버퍼에 배치되고 L2/L3 포워딩 엔진은 패킷의 레이어 2 및 레이어 3 정보에 액세스하여 포워딩 프로세서로 전송합니다. 포워딩 프로세서는 패킷에 라우팅 정보가 포함되어 있다고 확인합니다. 포워딩 프로세서는 포인터를 GRP VOQ(virtual output queue)로 전송하고 버퍼 메모리의 패킷을 GRP로 전송해야 함을 나타냅니다.
-
라인 카드는 CSC(Clock and Scheduler Card)에 요청을 보냅니다. 스케줄러 카드는 승인을 발행하고, 패킷은 스위칭 패브릭을 통해 GRP로 전송됩니다.
-
GRP는 라우팅 정보를 처리합니다. GRP의 R5000(프로세서)이 네트워크 라우팅 테이블을 업데이트합니다. 패킷의 라우팅 정보에 따라 레이어 3 프로세서는 인접한 라우터에 링크 상태 정보를 플러딩해야 할 수 있습니다(내부 라우팅 프로토콜이 OSPF[Open Shortest Path First]인 경우). 프로세서는 링크 상태 정보 및 FIB 테이블에 대한 내부 업데이트를 전달하는 IP 패킷을 생성한다. 또한 GRP는 내부 프로토콜과 외부 게이트웨이 프로토콜(예: BGP(Border Gateway Protocol))에 대해 모두 지원을 제공할 때 발생하는 모든 재귀 경로를 계산합니다.
계산된 재귀적 경로 정보는 각 라인 카드의 FIB로 전송됩니다. 이렇게 하면 라인 카드의 레이어 3 프로세서가 패킷 전달에 집중할 수 있으며 재귀적 경로를 계산하지 않기 때문에 전달 프로세스의 속도가 크게 빨라집니다.
-
GRP는 모든 라인 카드의 FIB 테이블에 내부 업데이트를 전송하고 GRP에 있는 업데이트를 포함합니다. 라인 카드에 대한 FIB 업데이트가 모니터링되고 필요한 경우 조절(throttled)됩니다. GRP에는 각 라인 카드 FIB 테이블의 사본이 있으므로 새 라인 카드가 섀시에 삽입될 경우 해당 카드가 활성화되면 GRP는 새 카드에 최신 전달 정보를 다운로드합니다.
-
새 인접 라우터가 12000 라우터에 연결될 때마다 GRP가 라인 카드로부터 알림을 받습니다. 라인 카드의 프로세서는 새 레이어 2 정보(일반적으로 PPP(Point-to-Point Protocol) 헤더 정보)가 포함된 GRP에 패킷을 전송합니다. GRP는 이 레이어 2 정보를 사용하여 GRP 및 라인 카드에 있는 인접성 테이블을 업데이트합니다. 각 라인 카드는 패킷이 12000 라우터에서 전송될 때 이 레이어 2 정보를 각 패킷에 추가합니다. 인접성 테이블의 사본은 초기화를 위해 GRP에서 유지됩니다.
그림 1: 경로 결정 및 레이어 3 스위칭 다이어그램
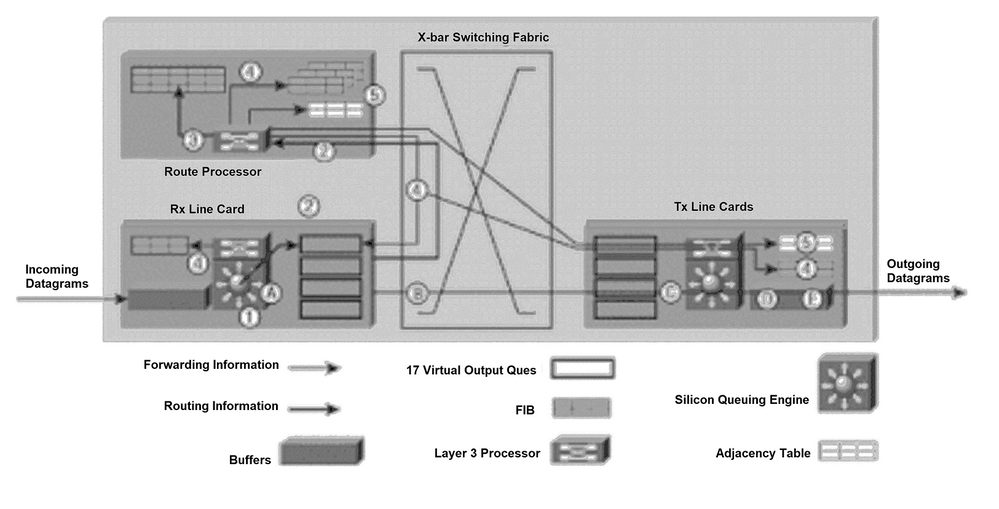 경로 결정 및 레이어 3 스위칭 다이어그램
경로 결정 및 레이어 3 스위칭 다이어그램
OC48 및 QOC12를 제외한 모든 라인 카드에 대한 패킷 포워딩
라인 카드의 포워딩 정보가 스위칭 패브릭을 통한 경로(예: 다음 홉의 대상)를 결정하는 데 충분하면 12000 라우터는 패킷을 전달할 준비가 됩니다. 다음 단계는 12000 라우터에서 사용하는 간단하고 빠른 포워딩 기술에 대해 간략하게 설명합니다(그림 1 참조). 문단의 레터링은 명확성을 위해 그림 1의 레터링에 해당한다.
-
A. IP 데이터그램이 수신 라인 카드(Rx 라인 카드)의 입력 버퍼에 배치되고 L2/L3 포워딩 엔진은 패킷의 레이어 2 및 레이어 3 정보에 액세스하여 포워딩 프로세서로 전송합니다. 포워딩 프로세서는 패킷에 데이터가 포함되어 있으며 라우팅 업데이트가 아닌 것으로 확인합니다. FIB 테이블의 레이어 2 및 레이어 3 정보에 기초하여 포워딩 프로세서는 버퍼 메모리의 패킷이 해당 라인 카드로 전송됨을 나타내는 포인터를 해당 라인 카드 VOQ로 전송합니다.
-
B. 라인 카드 스케줄러는 스케줄러에 요청을 보냅니다. 스케줄러는 승인을 발행하고, 패킷은 스위칭 패브릭을 통해 버퍼 메모리에서 라인 카드(Tx 라인 카드)로 전송됩니다.
-
C.Tx 라인 카드는 수신 패킷을 버퍼링합니다.
-
D. Tx 라인 카드의 레이어 3 프로세서 및 관련 ASIC(application-specific integrated circuits)는 전송된 각 패킷에 레이어 2 정보(PPP 주소)를 연결합니다. 패킷은 라인 카드의 각 포트에 대해 복제됩니다(필요한 경우).
-
예: Tx 라인 카드 송신기는 파이버 인터페이스를 통해 패킷을 전송합니다.
이 간단한 포워딩 프로세스의 장점은 대부분의 데이터 전송 작업이 ASIC에서 수행될 수 있고, ASIC가 기가비트 속도로 12000 수 있다는 것입니다. 또한 데이터 패킷은 GRP로 전송되지 않습니다.
OC48 및 QOC12 라인 카드에 대한 패킷 포워딩
라인 카드의 포워딩 정보가 스위칭 패브릭을 통한 경로(예: 다음 홉의 대상)를 결정하는 데 충분하면 12000 라우터는 패킷을 포워딩할 준비가 됩니다. 다음 단계는 네트워크에서 사용하는 간단하고 빠른 전달 기술을 12000(그림 2 참조). 문단의 레터링은 명확성을 위해 그림 2의 레터링에 해당한다.
-
A. IP 데이터그램(라우팅 업데이트, ICMP(Internet Control Message Protocol) 및 옵션이 있는 IP 패킷 아님)이 라인 카드로 수신되고 레이어 2 프로세싱을 거칩니다. Fast Packet Processor는 로컬 FIB 테이블의 레이어 2 및 레이어 3 정보를 기반으로 패킷의 목적지를 결정하고 패킷 헤더를 수정합니다. 목적지를 기준으로 패킷이 적절한 라인 카드 VOQ에 배치됩니다.
-
B. Fast Packet Processor에서 패킷을 제대로 전달할 수 없는 드문 경우에는 포워딩 Processor에서 패킷을 처리합니다. 포워딩 프로세서는 로컬 FIB 테이블에 대한 레이어 2 및 레이어 3 정보를 기반으로, 버퍼 메모리의 패킷이 해당 라인 카드로 전송됨을 나타내는 적절한 라인 카드 VOQ에 포인터를 전송합니다.
-
C. 패킷이 적절한 VOQ에 들어오면 라인 카드 스케줄러가 스케줄러에 요청을 보냅니다. 스케줄러는 승인을 발행하고, 패킷은 스위칭 패브릭을 통해 버퍼 메모리에서 라인 카드(Tx 라인 카드)로 전송됩니다.
-
D. Tx 라인 카드가 수신 패킷을 버퍼링합니다.
-
예. Tx 라인 카드의 레이어 3 프로세서 및 관련 ASIC는 전송된 각 패킷에 레이어 2 정보(PPP 주소)를 연결합니다. 패킷은 라인 카드의 각 포트에 대해 복제됩니다(필요한 경우).
-
F. Tx 라인 카드 송신기는 파이버 인터페이스를 통해 패킷을 전송합니다.
새로운 포워딩 프로세스의 이점은 OC48/STM16과 같이 더욱 빠른 속도를 위해 카드를 최적화한다는 것입니다.
그림 2: 더 빠른 라인 카드를 위한 패킷 스위칭
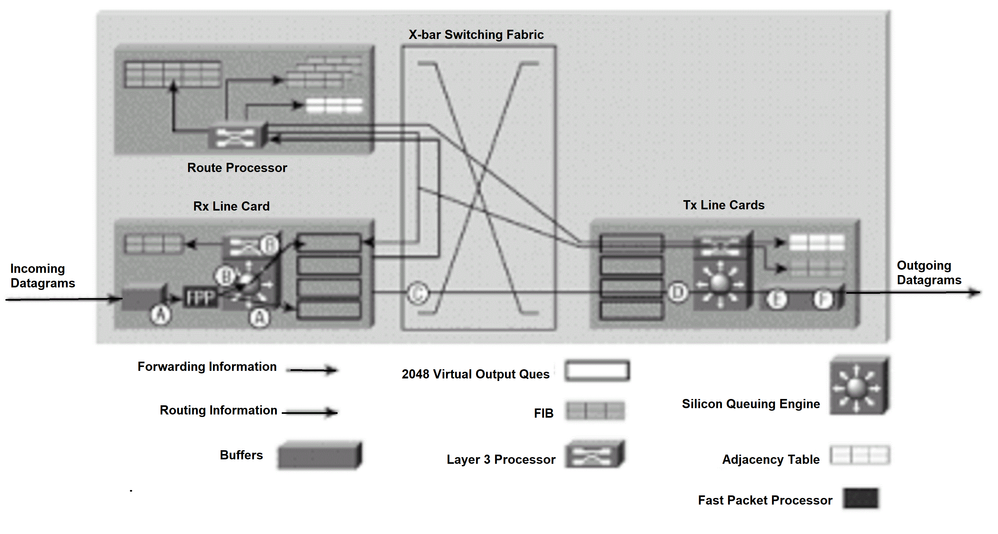 더 빠른 라인 카드를 위한 패킷 스위칭
더 빠른 라인 카드를 위한 패킷 스위칭
관련 정보
 피드백
피드백