소개
이 문서에서는 Hyperflex 클러스터에 대한 일반적인 Intersight 상태 검사 오류를 해결하는 방법에 대해 설명합니다.
사전 요구 사항
요구 사항
다음 주제에 대한 지식을 보유하고 있으면 유용합니다.
- NTP(Network Time Protocol) 및 DNS(Domain Name System)에 대한 기본적인 이해
- Linux 명령줄에 대한 기본 이해
- VMware ESXi에 대한 기본 이해
- VI 텍스트 편집기에 대한 기본적인 이해.
- Hyperflex 클러스터 작업.
사용되는 구성 요소
이 문서의 정보는 다음을 기반으로 합니다.
Hyperflex Data Platform(HXDP) 5.0.(2a) 이상
이 문서의 정보는 특정 랩 환경의 디바이스를 토대로 작성되었습니다. 이 문서에 사용된 모든 디바이스는 초기화된(기본) 컨피그레이션으로 시작되었습니다. 현재 네트워크가 작동 중인 경우 모든 명령의 잠재적인 영향을 미리 숙지하시기 바랍니다.
배경 정보
Cisco Intersight는 Hyperflex 클러스터에서 일련의 테스트를 실행하여 일상적인 운영 및 유지 관리 작업에 대해 클러스터 상태가 최적의 상태인지 확인하는 기능을 제공합니다.
HX 5.0(2a)부터 Hyperflex는 Hyperflex 명령줄에서 문제 해결을 위해 에스컬레이션된 권한이 있는 diag 사용자 계정을 제공합니다. SSH를 관리 사용자로 사용하여 CMIP(Hyperflex Cluster Management IP)에 연결한 다음 진단 사용자로 전환합니다.
HyperFlex StorageController 5.0(2d)
admin@192.168.202.30's password:
This is a Restricted shell.
Type '?' or 'help' to get the list of allowed commands.
hxshell:~$ su diag
Password:
____ __ _____ _ _ _ _____
| ___| / /_ _ | ____(_) __ _| |__ | |_ |_ _|_ _____
|___ \ _____ | '_ \ _| |_ | _| | |/ _` | '_ \| __| _____ | | \ \ /\ / / _ \
___) | |_____| | (_) | |_ _| | |___| | (_| | | | | |_ |_____| | | \ V V / (_) |
|____/ \___/ |_| |_____|_|\__, |_| |_|\__| |_| \_/\_/ \___/
|___/
Enter the output of above expression: 5
Valid captcha
diag#
문제 해결
ESXi VIB 수정 "설치된 일부 VIB가 더 이상 사용되지 않는 vmkAPI를 사용하고 있습니다."
ESXi 7.0 이상으로 업그레이드할 경우 Intersight에서 Hyperflex 클러스터의 ESXi 호스트에 이전 vmkapi 버전에 종속된 드라이버가 없도록 보장합니다. VMware는 영향을 받는 vSphere Installation Bundles(VIB) 목록을 제공하며 이 문서에서 이 문제를 설명합니다. KB 78389
Hyperflex Connect 웹 UI(사용자 인터페이스)에 로그인하고 시스템 정보로 이동합니다. Nodes(노드)를 클릭하고 Hyperflex (HX) 노드를 선택합니다. 그런 다음 Enter HX Maintenance Mode(HX 유지 관리 모드 입력)를 클릭합니다.
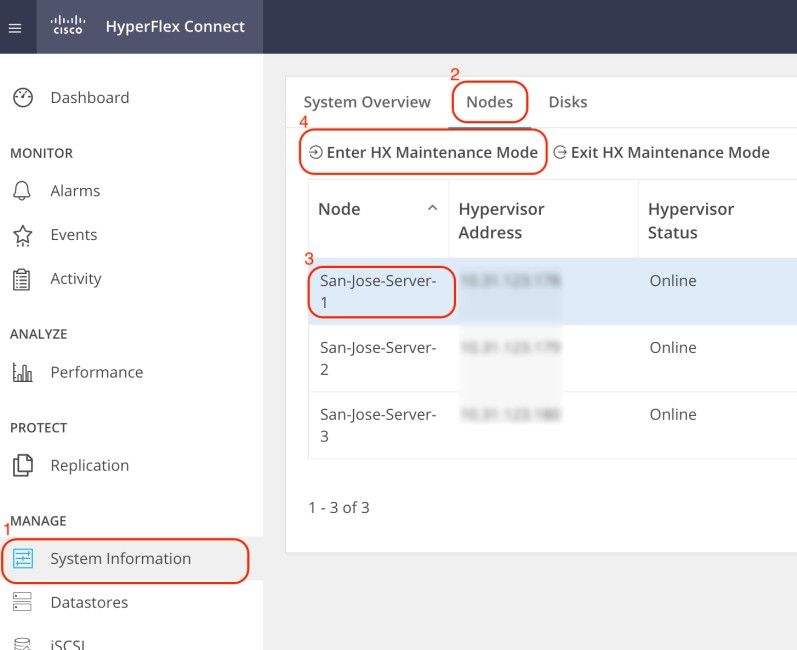
SSH 클라이언트를 사용하여 ESXi 호스트의 관리 IP 주소에 연결합니다. 그런 다음 다음 다음 명령을 사용하여 ESXi 호스트의 VIB를 확인합니다.
esxcli software vib list
다음 명령을 사용하여 VIB를 제거합니다.
esxcli software vib remove -n driver_VIB_name
ESXi 호스트를 재부팅합니다. 다시 온라인 상태가 되면 HX Connect에서 HX 노드를 선택하고 Exit HX Maintenance Mode(HX 유지 관리 모드 종료)를 클릭합니다.
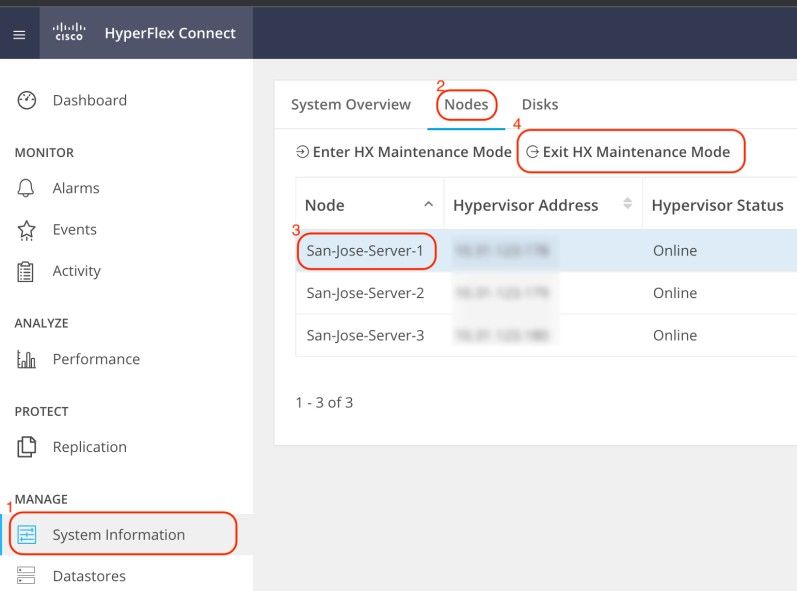
HX 클러스터가 Healthy가 될 때까지 기다립니다. 그런 다음 클러스터의 다른 노드에 대해 동일한 단계를 수행합니다.
vMotion 활성화 수정 "VMotion이 ESXi 호스트에서 비활성화됨"
이 검사를 수행하면 HX 클러스터의 모든 ESXi 호스트에서 vMotion이 활성화됩니다. vCenter에서 각 ESXi 호스트에는 vSwitch(가상 스위치)와 vMotion용 vmkernel 인터페이스가 있어야 합니다.
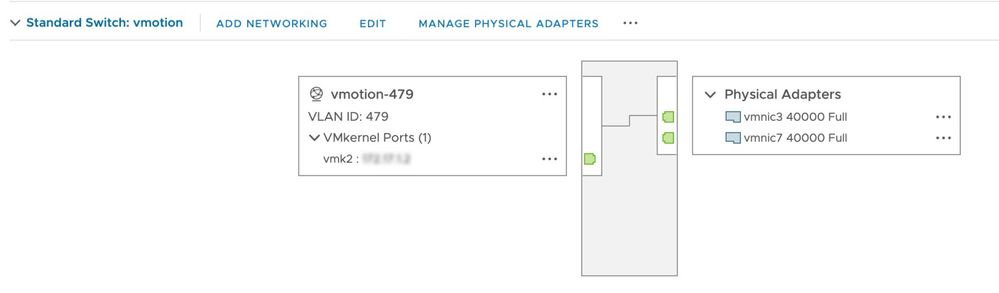
SSH를 관리 사용자로 사용하여 CMIP(Hyperflex Cluster Management IP)에 연결한 다음 다음 이 명령을 실행합니다.
hx_post_install
vMotion을 구성하려면 옵션 1을 선택합니다.
admin@SpringpathController:~$ hx_post_install
Select hx_post_install workflow-
1. New/Existing Cluster
2. Expanded Cluster (for non-edge clusters)
3. Generate Certificate
Note: Workflow No.3 is mandatory to have unique SSL certificate in the cluster. By Generating this certificate, it will replace your current certificate. If you're performing cluster expansion, then this option is not required.
Selection: 1
Logging in to controller HX-01-cmip.example.com
HX CVM admin password:
Getting ESX hosts from HX cluster...
vCenter URL: 192.168.202.35
Enter vCenter username (user@domain): administrator@vsphere.local
vCenter Password:
Found datacenter HX-Clusters
Found cluster HX-01
post_install to be run for the following hosts:
HX-01-esxi-01.example.com
HX-01-esxi-02.example.com
HX-01-esxi-03.example.com
Enter ESX root password:
Enter vSphere license key? (y/n) n
Enable HA/DRS on cluster? (y/n) y
Successfully completed configuring cluster HA.
Disable SSH warning? (y/n) y
Add vmotion interfaces? (y/n) y
Netmask for vMotion: 255.255.254.0
VLAN ID: (0-4096) 208
vMotion MTU is set to use jumbo frames (9000 bytes). Do you want to change to 1500 bytes? (y/n) y
vMotion IP for HX-01-esxi-01.example.com: 192.168.208.17
Adding vmotion-208 to HX-01-esxi-01.example.com
Adding vmkernel to HX-01-esxi-01.example.com
vMotion IP for HX-01-esxi-02.example.com: 192.168.208.18
Adding vmotion-208 to HX-01-esxi-02.example.com
Adding vmkernel to HX-01-esxi-02.example.com
vMotion IP for HX-01-esxi-03.example.com: 192.168.208.19
Adding vmotion-208 to HX-01-esxi-03.example.com
Adding vmkernel to HX-01-esxi-03.example.com
참고: HX Installer로 구축된 Edge 클러스터의 경우 HX_post_install 스크립트를 HX Installer CLI에서 실행해야 합니다.
vCenter 연결 검사 수정 "vCenter 연결 검사 실패"
SSH를 관리 사용자로 사용하여 CMIP(Hyperflex Cluster Management IP)에 연결하고 진단 사용자로 전환합니다. HX 클러스터가 다음 명령을 사용하여 vCenter에 등록되었는지 확인합니다.
diag# hxcli vcenter info
Cluster Name : San_Jose
vCenter Datacenter Name : MX-HX
vCenter Datacenter ID : datacenter-3
vCenter Cluster Name : San_Jose
vCenter Cluster ID : domain-c8140
vCenter URL : 10.31.123.186
vCenter URL은 vCenter 서버의 IP 주소 또는 FQDN(Fully Qualified Domain Name)을 표시해야 합니다. 올바른 정보가 표시되지 않으면 다음 명령을 사용하여 HX 클러스터를 vCenter에 다시 등록합니다.
diag# stcli cluster reregister --vcenter-datacenter MX-HX --vcenter-cluster San_Jose --vcenter-url 10.31.123.186 --vcenter-user administrator@vsphere.local
Reregister StorFS cluster with a new vCenter ...
Enter NEW vCenter Administrator password:
Cluster reregistration with new vCenter succeeded
다음 명령을 사용하여 HX CMIP와 vCenter 간에 연결이 있는지 확인합니다.
diag# nc -uvz 10.31.123.186 80
Connection to 10.31.123.186 80 port [udp/http] succeeded!
diag# nc -uvz 10.31.123.186 443
Connection to 10.31.123.186 443 port [udp/https] succeeded!
클리너 상태 확인 수정 "클리너 확인 실패"
SSH를 관리 사용자로 사용하여 Hyperflex CMIP에 연결한 다음 diag 사용자로 전환합니다. 다음 명령을 실행하여 cleaner 서비스가 실행되고 있지 않은 노드를 식별합니다.
diag# stcli cleaner info
{ 'type': 'node', 'id': '7e83a6b2-a227-844b-87fb-f6e78e6a59be', 'name': '172.16.1.6' }: ONLINE
{ 'type': 'node', 'id': '8c83099e-b1e0-6549-a279-33da70d09343', 'name': '172.16.1.8' }: ONLINE
{ 'type': 'node', 'id': 'a697a21f-9311-3745-95b4-5d418bdc4ae0', 'name': '172.16.1.7' }: OFFLINE
이 경우 172.16.1.7은 클리너가 실행되고 있지 않은 SCVM(Storage Controller Virtual Machine)의 IP 주소입니다. SSH를 사용하여 클러스터에 있는 각 SCVM의 관리 IP 주소에 연결한 다음 다음 다음 명령을 사용하여 eth1의 IP 주소를 찾습니다.
diag# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 00:0c:29:38:2c:a7
inet addr:172.16.1.7 Bcast:172.16.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
RX packets:1036633674 errors:0 dropped:1881 overruns:0 frame:0
TX packets:983950879 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:723797691421 (723.7 GB) TX bytes:698522491473 (698.5 GB)
다음 명령을 사용하여 영향을 받는 노드에서 클리너 서비스를 시작합니다.
diag# sysmtool --ns cleaner --cmd start
NTP 서비스 상태 수정 "NTPD 서비스 상태가 DOWN입니다."
SSH를 관리 사용자로 사용하여 HX CMIP에 연결한 다음 diag 사용자로 전환합니다. NTP 서비스가 중지되었는지 확인하려면 이 명령을 실행합니다.
diag# service ntp status
* NTP server is not running
NTP 서비스가 실행되고 있지 않으면 이 명령을 실행하여 NTP 서비스를 시작합니다.
diag# priv service ntp start
* Starting NTP server
...done.
NTP 서버 연결성 수정 "NTP 서버 연결성 검사 실패"
SSH를 관리 사용자로 사용하여 HX CMIP에 연결한 다음 diag 사용자로 전환합니다. HX 클러스터가 구성된 NTP 서버에 연결할 수 있는지 확인합니다. 이 명령을 실행하여 클러스터의 NTP 컨피그레이션을 표시합니다.
diag# stcli services ntp show
10.31.123.226
HX 클러스터의 각 SCVM과 포트 123의 NTP 서버 간에 네트워크 연결이 있는지 확인합니다.
diag# nc -uvz 10.31.123.226 123
Connection to 10.31.123.226 123 port [udp/ntp] succeeded!
클러스터에 구성된 NTP 서버가 더 이상 사용되지 않는 경우 클러스터에 다른 NTP 서버를 구성할 수 있습니다.
stcli services ntp set NTP-IP-Address
경고: stcli 서비스 ntp 집합은 클러스터의 현재 NTP 컨피그레이션을 덮어씁니다.
DNS 서버 연결성 수정 "DNS 연결성 검사 실패"
SSH를 관리 사용자로 사용하여 HX CMIP에 연결한 다음 diag 사용자로 전환합니다. HX 클러스터에서 연결 가능한 DNS 서버가 구성되어 있는지 확인합니다. 이 명령을 실행하여 클러스터의 DNS 컨피그레이션을 표시합니다.
diag# stcli services dns show
10.31.123.226
HX 클러스터의 각 SCVM과 포트 53의 DNS 서버 간에 네트워크 연결이 있는지 확인합니다.
diag# nc -uvz 10.31.123.226 53
Connection to 10.31.123.226 53 port [udp/domain] succeeded!
클러스터에 구성된 DNS 서버가 더 이상 사용되지 않는 경우 클러스터에 다른 DNS 서버를 구성할 수 있습니다.
stcli services dns set DNS-IP-Adrress
경고: stcli 서비스 dns 집합이 클러스터의 현재 DNS 컨피그레이션을 덮어씁니다.
컨트롤러 VM 버전 수정 "ESXi 호스트의 설정 파일에 컨트롤러 VM 버전 값이 없습니다."
이 검사는 각 SCVM이 컨피그레이션 파일에 guestinfo.stctlvm.version = "3.0.6-3"을 포함하는지 확인합니다.
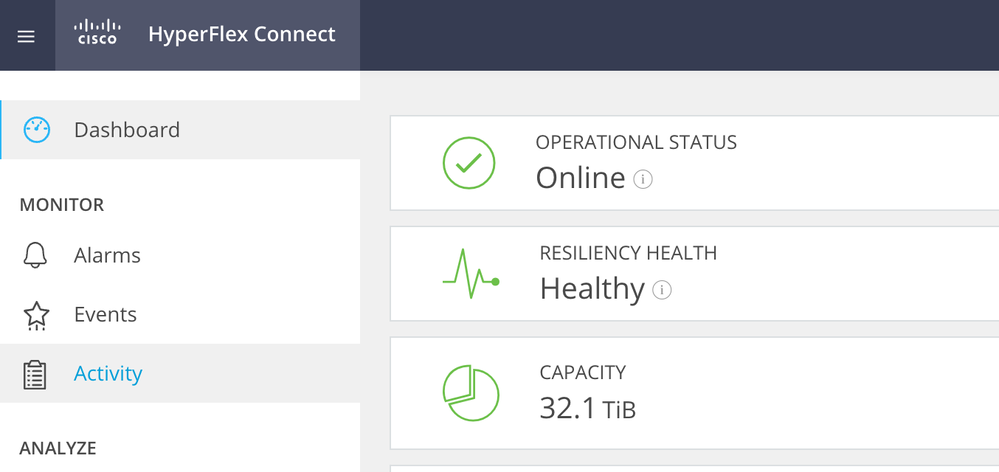
HX Connect에 로그인하여 클러스터가 정상인지 확인합니다.
루트 계정과의 SSH를 사용하여 클러스터의 각 ESXi 호스트에 연결합니다. 그런 다음 이 명령을 실행합니다
[root@San-Jose-Server-1:~] grep guestinfo /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx
guestinfo.stctlvm.version = "3.0.6-3"
guestinfo.stctlvm.configrdm = "False"
guestinfo.stctlvm.hardware.model = "HXAF240C-M4SX"
guestinfo.stctlvm.role = "storage"

주의: 데이터 저장소 이름과 SCVM 이름은 클러스터에서 다를 수 있습니다. Spring을 입력한 다음 Tab 키를 눌러 데이터 저장소 이름을 자동으로 완성할 수 있습니다. SCVM 이름에 stCtl을 입력한 다음 Tab 키를 눌러 SCVM 이름을 자동으로 완성할 수 있습니다.
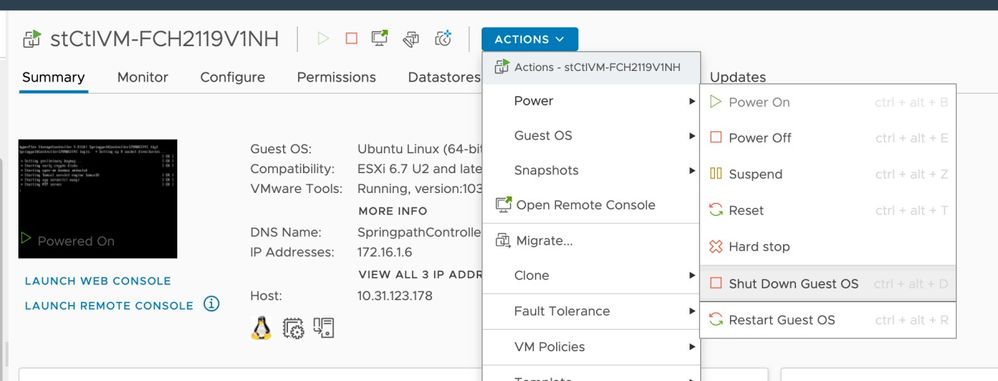
SCVM의 컨피그레이션 파일에 guestinfo.stctlvm.version = "3.0.6-3"이 포함되지 않으면 vCenter에 로그인하고 SCVM을 선택합니다. Actions(작업)를 클릭하고 Power(전원)로 이동한 다음 Shut Down Guest OS(게스트 OS 종료)를 선택하여 SCVM의 전원을 정상적으로 끕니다.
ESXi CLI(Command Line Interface)에서 다음 명령을 사용하여 SCVM 컨피그레이션 파일의 백업을 생성합니다.
cp /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx.bak
그런 다음 이 명령을 실행하여 SCVM의 컨피그레이션 파일을 엽니다.
[root@San-Jose-Server-1:~] vi /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx
I 키를 눌러 파일을 편집한 다음 파일의 끝으로 이동하여 다음 줄을 추가합니다.
guestinfo.stctlvm.version = "3.0.6-3"
Esc 키를 누르고 :wq를 입력하여 변경 사항을 저장합니다.
vim-cmd vmsvc/getallvms 명령을 사용하여 SCVM의 VMID(Virtual Machine ID)를 식별하고 SCVM의 컨피그레이션 파일을 다시 로드합니다.
[root@San-Jose-Server-1:~] vim-cmd vmsvc/getallvms
Vmid Name File Guest OS Version Annotation
1 stCtlVM-FCH2119V1NH [SpringpathDS-FCH2119V1NH] stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx ubuntu64Guest vmx-15
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1
다음 명령을 사용하여 SCVM을 다시 로드하고 전원을 켭니다.
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1
[root@San-Jose-Server-1:~] vim-cmd vmsvc/power.on 1
다음 SCVM으로 이동하기 전에 HX 클러스터가 다시 정상화될 때까지 기다려야 합니다.
영향을 받는 SCVM에 대해 동일한 절차를 한 번에 하나씩 반복합니다.
마지막으로, SSH를 사용하여 각 SCVM에 로그인하고 diag 사용자 계정으로 전환합니다. 다음 명령을 사용하여 한 번에 한 노드씩 stMgr을 다시 시작합니다.
diag# priv restart stMgr
stMgr start/running, process 22030
다음 SCVM으로 이동하기 전에 다음 명령을 사용하여 stMgr이 완전히 작동하는지 확인하십시오.
diag# stcli about
Waiting for stmgr management server on port 9333 to get ready . .
productVersion: 5.0.2d-42558
instanceUuid: EXAMPLE
serialNumber: EXAMPLE,EXAMPLE,EXAMPLE
locale: English (United States)
apiVersion: 0.1
name: HyperFlex StorageController
fullName: HyperFlex StorageController 5.0.2d
serviceType: stMgr
build: 5.0.2d-42558 (internal)
modelNumber: HXAF240C-M4SX
displayVersion: 5.0(2d)
관련 정보
 피드백
피드백