パケット音声ネットワークでの遅延について
内容
概要
パケット、フレーム、またはセル インフラストラクチャ経由で音声を転送するネットワークを設計する際に、ネットワークで遅延を引き起こすコンポーネントを理解し、考慮に入れることが重要です。発生する可能性のあるすべての遅延を正しく考慮すると、ネットワーク全体で許容可能なパフォーマンスを得ることができます。全体的な音声品質は、圧縮アルゴリズム、エラーとフレーム損失、エコー キャンセレーション、遅延などのさまざまな要因に基づいています。このホワイト ペーパーでは、パケット ネットワークで Cisco のルータ/ゲートウェイを使用する場合の遅延の原因について説明しています。示されている例はフレーム リレーの例ですが、その概念は Voice over IP(VoIP)および Voice over ATM(VoATM)ネットワークにも適用されます。
基本的な音声フロー
このダイアグラムでは、圧縮音声による回線のフローを示しています。電話機からのアナログ信号は、音声符号/復号化(コーデック)により、Pulse Code Modulation(PCM; パルス符号変調)としてデジタル化されます。 次に、PCM サンプルは、圧縮アルゴリズムに渡され、そこで音声はパケット形式に圧縮されてから、WAN 上に送信されます。クラウドの遠端側では、まったく同様の処理が逆の順序で実行されます。全体のフローを図 2-1 に示します。
図 2-1 エンドツーエンドボイスフロー 
ネットワークの構成に基づいて、ルータ/ゲートウェイでは、コーデックと圧縮の両方、またはいずれか一方を実行できます。たとえば、アナログ音声システムを使用している場合は、ルータ/ゲートウェイは図 2-2 に示すように、コーデックおよび圧縮の両方の機能を実行します。
図 2-2 ルータ/ゲートウェイでのコーデック機能 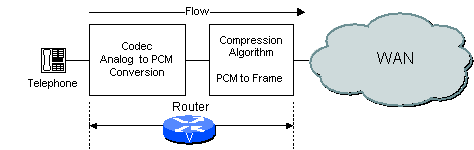
デジタル PBX が使用されている場合は、PBX がコーデック処理を実行し、ルータは PBX より渡された PCM サンプルを処理します。構成例を、図 2-3 に示します。
図 2-3:PBX でのコーデック機能 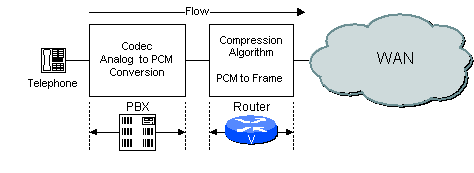
音声圧縮の仕組み
Cisco のルータとゲートウェイで使用される高度な圧縮アルゴリズムでは、音声コーデックにより提供される PCM サンプルのブロックを分析します。これらのブロックは、コーダによって長さが異なります。たとえば、G.729 アルゴリズムが使用する基本ブロック サイズは 10 ミリ秒で、G 723.1 が使用する基本ブロック サイズは 30 ミリ秒です。G.729 圧縮システムの動作の例を図 3-1 に示します。
図 3-1 音声圧縮 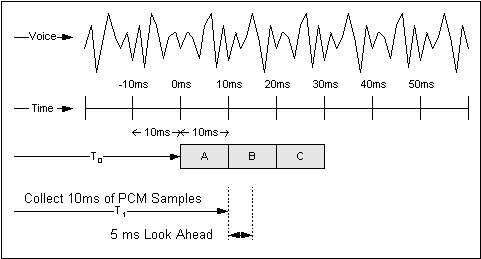
アナログ音声ストリームは、10 ミリ秒単位で PCM サンプルとしてデジタル化されて、圧縮アルゴリズムに送られます。ルック アヘッドについては、アルゴリズム遅延で説明しています。
遅延制限に関する標準
International Telecommunication Union(ITU;国際電気通信連合)は、勧告G.114の音声アプリケーションのネットワーク遅延を考慮しています。この勧告では、表4.1に示すように、一方向の遅延の3つの帯域を定義しています。
表 4.1 遅延に関する仕様
| 範囲(ミリ秒) | 説明 |
|---|---|
| 0-150 | ほとんどのユーザ アプリケーションにとって許容範囲である。 |
| 150-400 | 管理者が、伝送時間とユーザ アプリケーションの伝送品質に与える影響を認識している場合に限り、許容範囲である。 |
| 400 を超える値 | 一般的なネットワーク プランニングの目的には許容範囲外である。ただし、この限界値を超える例外的なケースがあることが認識されている。 |
注:これらの推奨事項は、エコーが適切に制御された接続に関するものです。つまり、エコー キャンセラが使用されている接続に対するものです。エコー キャンセラが必要なのは、一方向遅延が 25 ミリ秒を超える場合です(G.131)。
これらの勧告は、国内の通信事業者向けです。したがって、通常のプライベート音声ネットワークに適用される場合よりも厳しい内容になっています。ネットワーク設計者が、エンド ユーザの位置や業務上のニーズを熟知している場合には、より大きい遅延を許容できる場合があります。プライベート ネットワークの場合、適切な目標値は 200 ミリ秒で、限界値は 250 ミリ秒です。予測される音声接続の最大遅延を認識し、かつ遅延を最小限に抑制するように、すべてのネットワークを構築する必要があります。
遅延の要因
遅延には、固定と可変の 2 つのタイプがあります。
-
固定遅延の要素は、接続上の全体的な遅延に直接関わります。
-
可変遅延は、WAN に接続しているシリアル ポート上の出力トランクで、バッファによるキューイング遅延から発生します。これらのバッファによって、ジッタと呼ばれる可変遅延がネットワークに発生します。可変遅延は、受信側のルータ/ゲートウェイでデジッタ バッファにより処理されます。デジッタバッファについては、このドキュメントの「デジッタ遅延(Δn)」セクションで説明しています。
図 5-1 では、ネットワーク内に存在するすべての固定および可変の遅延要素を示します。各要因については、このドキュメントで詳細に説明しています。
図 5-1:遅延要因 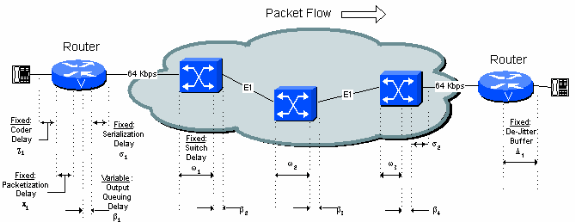
コーダ(処理)の遅延
コーダ遅延とは、Digital Signal Processor(DSP; デジタル信号プロセッサ)が、PCM サンプルのブロックの圧縮に要する時間です。これは、処理遅延(cn)とも呼ばれます。 コーダ遅延は使用する音声コーダやプロセッサの速度によって変わります。たとえば、Algebraic Code Excited Linear Prediction(ACELP; 代数的符号励振線形予測)アルゴリズムでは、PCM サンプルの 10 ミリ秒のブロックを分析してから圧縮します。
Conjugate Structure Algebraic Code Excited Linear Prediction(CS-ACELP; 共役構造代数符号励振線形予測)プロセスの圧縮時間は、DSP プロセッサのロード状態によって、2.5 ミリ秒から 10 ミリ秒までの範囲です。DSP に 4 つの音声チャネルすべての負荷がかかっている場合、コーダ遅延は 10 ミリ秒になります。DSPに1つの音声チャネルだけがロードされている場合、コーダ遅延は2.5ミリ秒です。設計目的では、最悪のケース時間10ミリ秒を使用します。
圧縮解除に要する時間は、ブロック単位の圧縮時間のおよそ 10 % です。しかし、複数のサンプルが存在する場合もあるので、圧縮解除時間は各フレームのサンプル数に比例します。したがって、1 フレームに 3 つのサンプルが含まれていると、1 フレームの圧縮解除に要する時間の最悪のケースは、3 x 1 ミリ秒、つまり 3 ミリ秒になります。通常は、G.729 の圧縮の場合、2 つまたは 3 つのブロックが 1 つのフレームに配置されますが、G. 723.1 による圧縮の場合は、1 つのサンプルに対して 1 つのフレームが配置されます。
表 5.1 に、最良および最悪のケースの各コーダ遅延を示します。
表 5.1 最良および最悪のケースの処理遅延
| コーダ | 速度 | 必要なサンプル ブロック | 最良のケースのコーダ遅延 | 最悪のケースのコーダ遅延 |
|---|---|---|---|---|
| ADPCM、G.726 | 32 Kbps | 10 ms | 2.5 ミリ秒 | 10 ms |
| CS-ACELP, G.729A | 8.0 Kbps | 10 ms | 2.5 ミリ秒 | 10 ms |
| MP-MLQ、G.723.1 | 6.3 Kbps | 30 ミリ秒 | 5 ミリ秒 | 20 ms |
| MP-ACELP、G.723.1 | 5.3 Kbps | 30 ミリ秒 | 5 ミリ秒 | 20 ms |
アルゴリズム遅延
圧縮アルゴリズムは、既知の音声特性に基づいてサンプル ブロック N を正確に処理します。サンプル ブロックを正確に再生するには、ブロック N+1 に何が含まれるのかを認識しておく必要があります。このルック アヘッドは、実際には追加の遅延ですが、アルゴリズム遅延と呼ばれます。これにより、圧縮ブロック長が効率的に増加されます。
これは、ブロック N+1 がブロック N+2 を調べるというように繰り返し発生します。リンク上の全体的な遅延への実質的な影響として、5 ms が追加されます。つまり、情報ブロックの処理に必要な総時間は、10 ミリ秒と固定オーバーヘッド要素の 5 ミリ秒です。図3-1を参照してください。音声圧縮.
-
G.726 コーダのアルゴリズム遅延は 0 ミリ秒です。
-
G.729 コーダのアルゴリズム遅延は 5 ミリ秒です。
-
G.723.1 コーダのアルゴリズム遅延は 7.5 ミリ秒です。
このドキュメントの以降の例では、30 ミリ秒/30 バイトのペイロードがかかる G.729 圧縮を想定しています。設計を容易にし、かつ慎重なアプローチを取るためにも、このドキュメントの以降の表では最悪のケースのコーダ遅延を想定しています。また、コーダ遅延、圧縮解除遅延、およびアルゴリズム遅延を、コーダ遅延と呼ぶ 1 つの要因に統括してあります。
次に、統括したコーダ遅延パラメータを生成する式を示します。
式 1:統括コーダ遅延パラメータ 
次に、このドキュメントの残りの部分で使用する G.729 の統括したコーダ遅延を示します。
最悪のケースのブロック単位の圧縮時間:10 ms
ブロック単位の圧縮解除時間 X 3 ブロック:3 ミリ秒
アルゴリズム遅延:5 ミリ秒 ---------------------------
合計時間(<FONT style="FONT-WEIGHT: normal; FONT-STYLE: normal; FONT-FAMILY: Symbol">c)18 ms
パケット化の遅延
パケット化遅延とは、符号化または圧縮されたボイスをパケットのペイロードに埋め込むのに必要な時間です。この遅延は、ボコーダに必要なサンプル ブロック サイズ、および 1 つのフレームに配置されるブロック数からなる関数です。音声サンプルは、送出される前にバッファに累積されるため、パケット化遅延は累積遅延とも呼ばれます。
一般的に、パケット化遅延が30ミリ秒以下になるように努力する必要があります。Ciscoルータ/ゲートウェイでは、設定されたペイロードサイズに基づいて、表5.2の次の図を使用する必要があります。
表5.2:一般的なパケット化遅延
| コーダ | ペイロード サイズ(バイト) | パケット化遅延(ミリ秒) | ペイロード サイズ(バイト) | パケット化遅延(ミリ秒) | |
|---|---|---|---|---|---|
| PCM, G.711 | 64 Kbps | 160 | 20 | 240 | 30 |
| ADPCM、G.726 | 32 Kbps | 80 | 20 | 120 | 30 |
| CS-ACELP、G.729 | 8.0 Kbps | 20 | 20 | 30 | 30 |
| MP-MLQ、G.723.1 | 6.3 Kbps | 24 | 24 | 60 | 48 |
| MP-ACELP、G.723.1 | 5.3 Kbps | 20 | 30 | 60 | 60 |
パケット化遅延は CPU の負荷に対して調整する必要があります。遅延を小さくする場合、フレーム サイズのレートも大きくなり、CPU の負荷も高くなります。古いプラットフォームによっては、20 ミリ秒のペイロードでメイン CPU に負荷がかかる可能性があります。
パケット化プロセスでのパイプライニング遅延
各ボイスサンプルでは、アルゴリズム遅延とパケット化遅延の両方が発生していますが、実際には、これらのプロセスは重複することがあり、このパイプライニングから実質的に有利な効果があります。図 2-1 に示す例を参照してください。
図 5-2:パイプライニングとパケット化 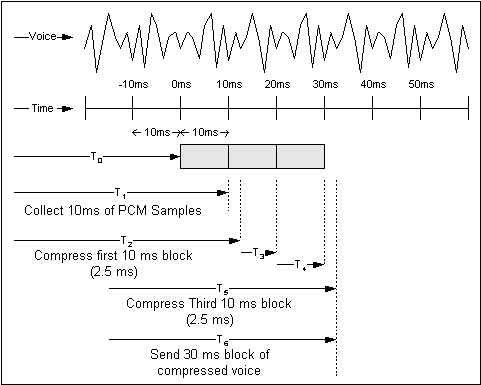
図の 1 番上の行では、サンプルの音声波を示しており、2 行目では、10 ミリ秒単位で増加する時間の幅が示されています。T0 では、CS-ACELP アルゴリズムがコーデックからの PCM サンプルの収集を開始します。T1 で、アルゴリズムはサンプルの最初の 10 ミリ秒ブロックの収集を終えて、圧縮を開始します。T2 では、サンプルの最初のブロックが圧縮されました。T2-T1 で示されるように、この例では圧縮時間は 2.5 ミリ秒です。
2番目と3番目のブロックはT3とT4で収集されます。3番目のブロックはT5で圧縮されます。パケットはT6で組み立てられ、送信されます(瞬間的であると想定されます)。圧縮およびパケット化プロセスののの性質によりがTTT6 -T0、または約32.5 ms
説明のため、この例は最良のケースの遅延に基づいています。最悪のケースを想定した場合、遅延の値は 40 ミリ秒になります。内訳は、10 ミリ秒がコーダ遅延で、30 ミリ秒がパケット化遅延です。
これらの例では、アルゴリズム遅延を無視していることに注意してください。
シリアル化遅延
シリアライゼーション遅延(σn)は、ネットワークインターフェイス上で音声またはデータフレームをクロックするために必要な固定遅延です。トランク上のクロック レートに直接関連しています。クロック速度が低く、フレーム サイズが小さい場合には、フレームを分割するのに必要な追加フラグが大きな割合を占めます。
表 5.3 では、フレーム サイズごとに必要なシリアライゼーション遅延を回線速度別に表示しています。この表では、ペイロードのサイズではなく、総フレーム サイズを計算に使用しています。
表 5.3:フレーム サイズ別のシリアライゼーション遅延(ミリ秒単位)
| フレーム サイズ(バイト) | 回線速度(Kbps) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| 19.2 | 56 | 64 | 128 | 256 | 384 | 512 | 768 | 1024 | 1544 | 2048 | |
| 38 | 15.83 | 5.43 | 4.75 | 2.38 | 1.19 | 0.79 | 0.59 | 0.40 | 0.30 | 0.20 | 0.15 |
| 48 | 20.00 | 6.86 | 6.00 | 3.00 | 1.50 | 1.00 | 0.75 | 0.50 | 0.38 | 0.25 | 0.19 |
| 64 | 26.67 | 9.14 | 8.00 | 4.00 | 2.00 | 1.33 | 1.00 | 0.67 | 0.50 | 0.33 | 0.25 |
| 128 | 53.33 | 18.29 | 16.00 | 8.00 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 | 0.66 | 0.50 |
| 256 | 106.67 | 36.57 | 32.00 | 16.00 | 8.00 | 5.33 | 4.00 | 2.67 | 2.00 | 1.33 | 1.00 |
| 512 | 213.33 | 73.14 | 64.00 | 32.00 | 16.00 | 10.67 | 8.00 | 5.33 | 4.00 | 2.65 | 2.00 |
| 1024 | 426.67 | 149.29 | 128.00 | 64.00 | 32.00 | 21.33 | 16.00 | 10.67 | 8.00 | 5.31 | 4.00 |
| 1,500 | 625.00 | 214.29 | 187.50 | 93.75 | 46.88 | 31.25 | 23.44 | 15.63 | 11.72 | 7.77 | 5.86 |
| 2048 | 853.33 | 292.57 | 256.00 | 128.00 | 64.00 | 42.67 | 32.00 | 21.33 | 16.00 | 10.61 | 8.00 |
この表では、64 Kbps 回線での 38 バイト(37 + 1 フラグ)長の CS-ACELP 音声フレームのシリアライゼーション遅延は 4.75 ミリ秒になります。
注:53バイトのATMセル(T1:0.275ms、E1:0.207ms)は、高速でセルサイズが小さいため、無視できます。
キューイング/バッファリング遅延
圧縮された音声ペイロードが作成されてから、ヘッダーが付加され、そのフレームはネットワーク上に送信されるためにキューイングされます。音声は、ルータやゲートウェイで絶対的な優先順位を持つ必要があります。したがって、音声フレームが待つ必要があるのは、すでに再生されているデータ フレームか、先行する他の音声フレームのいずれかだけです。実質的に、音声フレームが待つのは、出力キュー内の先行する各フレームのシリアライゼーション遅延分になります。キューイング遅延は可変遅延で、トランクの速度やキューの状態に依存します。キューイング遅延には、不確定な要素が関係しています。
たとえば、現在の回線速度が 64 Kbps だとして、1 つのデータ フレーム(48 バイト)と 1 つの音声フレーム(42 バイト)の後にキューイングされているとします。 48 バイトのフレームの中のどのくらいが再生されたのかについてはランダムな要素が関連しているので、平均的に、データ フレームの半分が再生済みと想定して支障はありません。シリアライゼーション テーブルのデータに基づくと、データ フレームのコンポーネントは 6 ミリ秒 * 0.5 = 3 ミリ秒になります。キューで先行する他の音声フレームの時間(5.25 ミリ秒)を追加すると、キューイング遅延の合計時間は 8.25 ミリ秒になります。
キューイング遅延の特性をどのように考慮するかは、ネットワーク技術者に任せられます。一般的には、最悪のシナリオを想定して設計し、ネットワークの導入後にパフォーマンスを調整する必要があります。ユーザが使用できる音声回線が増えるほど、音声パケットがキューで待機する平均的な時間が長くなります。この優先制御構造により、音声フレームが待つことになるデータ フレームは最大でも 1 つだけです。
ネットワーク スイッチングの遅延
エンドポイントのロケーションを相互接続するパブリック フレーム リレーまたは ATM ネットワークは、音声接続での最大の遅延の要因となります。ネットワークスイッチング遅延(ωn)も、定量化が最も困難です。
Cisco の機器またはその他のプライベート ネットワークにより広範囲の接続が提供されている場合、それぞれの遅延要素の識別は可能です。一般的に、固定遅延要素は、ネットワーク内のトランク上の伝搬遅延によって、また可変遅延は、クロッキング フレームが中継スイッチに入出力することによるキューイング遅延によって発生します。伝搬遅延を予測する場合、10 マイクロ秒/マイルまたは 6 マイクロ秒/km(G.114)という一般的な予測値がよく使われますが、中継多重化機器、バックホーリング、マイクロ波リンク、およびキャリア ネットワークが持つその他の要因により、例外が多数発生します。
その他の重要な遅延要素は、広域ネットワーク内のキューイングが原因となります。プライベート ネットワークの場合、既存のキューイング遅延を算出したり、広域ネットワーク内のホップ単位のバジェットを予測したりできる場合があります。
米国のフレームリレー接続の一般的なキャリア遅延は、固定40ミリ秒、可変25ミリ秒で、最悪ケース全体の遅延は65ミリ秒です。簡単にするために、例6-1、6-2、および6-3には、40ミリ秒の固定遅延における低速シリアル化遅延が含まれています。
これらの数値は、米国のフレームリレーの通信事業者が合衆国内の任意の場所間をカバーするために公表した値です。最悪のケースよりも地理的に近い 2 か所の間の通信では、遅延のパフォーマンスが改善されることが期待されますが、通常、通信事業者で公表されるのは最悪のケースだけです。
フレームリレーの通信事業者では、プレミアム サービスが提供される場合があります。これらのサービスは通常は音声または Systems Network Architecture(SNA; システム ネットワーク アーキテクチャ)のトラフィック向けであり、ネットワークの遅延が保証され、しかもネットワーク遅延が標準サービスのレベルよりも低減されています。たとえば、ある米国の通信事業者は最近、全体的な遅延制限値が、標準サービスの 65 ms よりもさらに低い 50 ms サービスの提供を発表しました。
デジッタ遅延
音声は固定ビット レート サービスなので、可変遅延であるすべてのジッタは、信号がネットワークから出る前に除去される必要があります。シスコのルータ/ゲートウェイでは、遠端(受信)のルータ/ゲートウェイでデジッタ(Δn)バッファを使用して実現します。デジッタ バッファにより、可変遅延が固定遅延に変換されます。受信した最初のサンプルを一定期間保持し、その後で再生します。この保持期間は、初期再生遅延(Initial Playout Delay)として知られています。
図 5-3:デジッタ バッファの動作 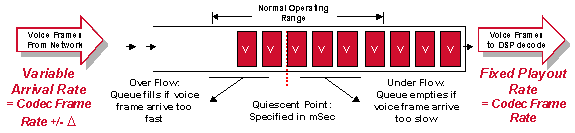
デジッタ バッファの取り扱いには正確さが必要です。サンプルの保持時間が短すぎると、遅延の変動によりバッファはアンダーラン状態となり音声に途切れ(gap)が生じる可能性があります。また、サンプルの保持時間が長すぎると、バッファはオーバーランし、ドロップされたパケットが原因で、ここでも音声に途切れが発生する場合があります。最後に、パケットの保持時間が長過ぎた場合は、接続全体での遅延が許容範囲レベルを超える可能性があります。
デジッタバッファについての最適な初期再生遅延は、接続での可変遅延の合計値と同等です。これを図 5-4 に示します。
注:デジッタバッファは適応可能ですが、最大遅延は固定されています。調整可能なバッファを設定すると、遅延は可変要素となります。ただし、設計する目的では、最大遅延を最悪のケースとして使用できます。
調整可能なバッファについての詳細は、『Voice over IP の再生遅延の拡張機能』を参照してください。
図5-4:可変遅延とデジッタ バッファ 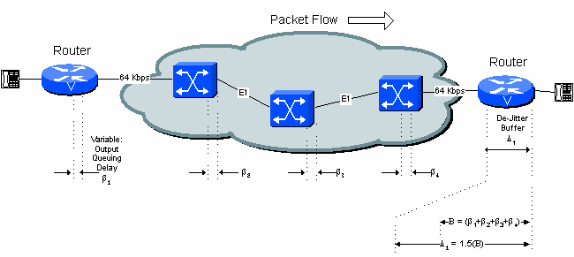
初期再生遅延は設定が可能です。オーバーフローに至るまでのバッファの最大深度は、通常、この値の 1.5 倍または 2.0 倍に設定されます。
公称遅延を 40 ミリ秒に設定した場合、デジッタバッファが空のときに受信した最初の音声サンプルは、再生される前に 40 ミリ秒の間保持されます。つまり、音声が途切れることなくネットワークから後続のパケットを受信するための遅延は、最初のパケットを基準として最大 40 ミリ秒ほどになります。40 ミリ秒よりも遅れると、デジッタ バッファは空になり、次に受信したパケットは、40 ミリ秒の間保持されてから再生され、バッファがリセットされます。その結果、再生された音声に 40 ミリ秒のずれが生じます。
遅延に対するデジッタ バッファの実際の効果は、デジッタ バッファの初期再生遅延とネットワークで最初のパケットをバッファリングした実際の量になります。最悪のケースでは、デジッタ バッファの初期遅延が 2 倍になります(ネットワークから受信した最初のパケットで、最小限のバッファリング遅延が発生したことを想定しています)。 実際上、ネットワークの多数のスイッチ ホップに対して、おそらく最悪のケースを想定する必要はありません。このドキュメントの以降の例での計算では、これを考慮して 1.5 の倍数で初期再生遅延を増やしています。
注:受信ルータ/ゲートウェイでは、圧縮解除機能による遅延があります。しかし、前述したように、この遅延は圧縮処理遅延としてまとめて考慮されています。
遅延バジェットの構築
高品質音声接続の遅延の一般的な許容値は、一方向で 200 ミリ秒(または限界値は 250 ミリ秒)です。 遅延がこの値を超えると、話し手と聞き手の間で会話のタイミングが取れないため、お互いに同時に話したり、または相手が話すのを待ったりすることになります。この状態は、一般的にダブルトーク(talker overlap)と呼ばれます。全体的な音声品質は許容できても、ぎごちない通話は我慢できないほど不快だと感じられる場合があります。ダブルトークは、衛星通信を経由して送られる国際通話に発生する場合があります(衛星の遅延は、500 ミリ秒、250 ミリ秒以上、および 250 ミリ秒未満の順です)。
下記の例では、各種のネットワーク構成、およびネットワーク設計者が考慮する必要がある遅延について説明しています。
シングル ホップ接続
図6 - 1:シングル ホップの接続例 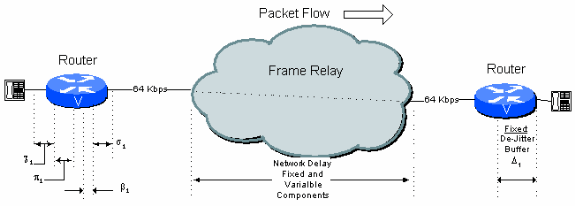
この図のパブリック フレームリレー接続上の典型的なシングル ホップ接続では、次の表 6.1 に示す遅延バジェットが存在する場合があります。
表6.1:シングル ホップ遅延の計算
| 遅延のタイプ | 固定(ミリ秒) | 可変(ミリ秒) |
|---|---|---|
| コーダ遅延、c1 | 18 | |
| パケット化遅延、p1 | 30 | |
| キューイング/バッファリング遅延、b1 | 8 | |
| シリアライゼーション遅延(64 kbps)、s1 | 5 | |
| ネットワーク遅延(公衆フレーム)w1 | 40 | 25 |
| デジッタバッファ遅延、D1 | 45 | |
| 合計 | 138 | 33 |
注:キューイング遅延とネットワーク遅延の可変要素は、デジッタバッファの計算ですでに考慮されているため、遅延合計は実質的にすべての固定遅延の合計に過ぎません。この場合、遅延合計は 138 ミリ秒です。
タンデム スイッチとして動作する C7200 ルータを設置したパブリック ネットワークでの 2 ホップ
図6 - 2:ルータおよびゲートウェイ タンデムを配置した 2 つのホップからなるパブリック ネットワーク例 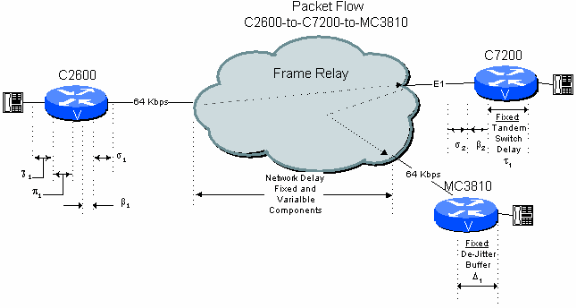
ここで、本社の C7200 がコールを支店にタンデムする、スター型トポロジ ネットワークの支店間接続を考えます。この場合、信号は中央のC7200を介して圧縮形式のままになります。これにより、次の例「PBXタンデムスイッチを使用したパブリックネットワーク上の2ホップ接続」に関する遅延バジェットが大幅に削減されます。
表 6.2:ルータおよびゲートウェイ タンデムを配置した 2 つのホップからなるパブリック ネットワークの遅延計算
| 遅延のタイプ | 固定(ミリ秒) | 可変(ミリ秒) |
|---|---|---|
| コーダ遅延、c1 | 18 | |
| パケット化遅延、p1 | 30 | |
| キューイング/バッファリング遅延、b1 | 8 | |
| シリアライゼーション遅延(64 kbps)、s1 | 5 | |
| ネットワーク遅延(公衆フレーム)w1 | 40 | 25 |
| MC3810 のタンデム遅延、t1 | 1 | |
| キューイング/バッファリング遅延、b2 | 0.2 | |
| シリアライゼーション遅延(2 Mbps)、s2 | 0.1 | |
| ネットワーク遅延(公衆フレーム)w2 | 40 | 25 |
| デジッタバッファ遅延、D1 | 75 | |
| 合計 | 209.1 | 58.2 |
注:キューイング遅延とネットワーク遅延の可変要素は、デジッタバッファの計算ですでに考慮されているため、遅延合計は実質的にすべての固定遅延の合計に過ぎません。この場合、遅延合計は 209.1 ミリ秒です。
PBX タンデム スイッチを設置したパブリック ネットワークでの 2 ホップ接続
図 6-3:PBX タンデムを配置した 2 つのホップからなるパブリック ネットワーク例 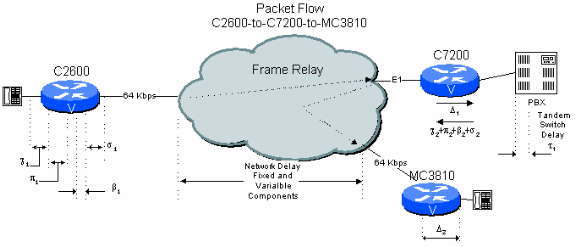
本社サイトのC7200が本社のPBXに接続を通過してスイッチングを行う支社間ネットワークでの支社間接続を考えてみましょう。この接続では、音声信号は圧縮解除されてデジッタされてから、また再度圧縮されて、もう一度デジッタされます。その結果、前の例と比べると遅延が余分に発生します。他にも、2 つの CS-ACELP 圧縮サイクルによって音声品質が劣化します(「複数の圧縮サイクルによる影響」を参照してください)。
表 6.3:PBX タンデムを配置した 2 つのホップからなるパブリック ネットワークの遅延計算
| 遅延のタイプ | 固定(ミリ秒) | 可変(ミリ秒) |
|---|---|---|
| コーダ遅延、c1 | 18 | |
| パケット化遅延、p1 | 30 | |
| キューイング/バッファリング遅延、b1 | 8 | |
| シリアライゼーション遅延(64 kbps)、s1 | 5 | |
| ネットワーク遅延(公衆フレーム)w1 | 40 | 25 |
| デジッタバッファ遅延、D1 | 40 | |
| コーダ遅延、c2 | 15 | |
| パケット化遅延、p2 | 30 | |
| キューイング/バッファリング遅延、b2 | 0.1 | |
| シリアライゼーション遅延(2 Mbps)、s2 | 0.1 | |
| ネットワーク遅延(公衆フレーム)w2 | 40 | 25 |
| デジッタバッファ遅延、D2 | 40 | |
| 合計 | 258.1 | 58.1 |
注:キューイング遅延とネットワーク遅延の可変要素は、デジッタバッファの計算にすでに含まれているため、遅延合計は実質的にすべての固定遅延とデジッタバッファ遅延の合計に過ぎません。この場合、遅延合計は 258.1 ミリ秒です。
中央サイトのPBXをスイッチとして使用すると、単方向接続遅延が206ミリ秒から255ミリ秒に増加します。これは、一方向の遅延に関するITUの制限に近づいています。このようなネットワーク構成の場合、技術者は遅延を最小限に抑えるように設計する必要があります。
可変遅延の最悪のケースを想定します(ただし、パブリック ネットワークの両側の遅延が同時に最大になることはありません)。 より楽観的に可変遅延を想定したとしても、状況は最小限、改善されるだけです。しかし、キャリアのフレームリレーのネットワークの固定遅延と可変遅延に関してより詳細な情報があれば、遅延の計算結果も低減する可能性があります。米国では、州内などのローカル接続の場合、遅延特性が改善されることも期待できますが、通常、通信事業者からは遅延の限界値は提示されません。
PBX タンデム スイッチを設置した私設ネットワーク上の 2 つのホップ接続
図 6-4:PBX タンデムを配置した 2 つのホップからなるプライベート ネットワーク例 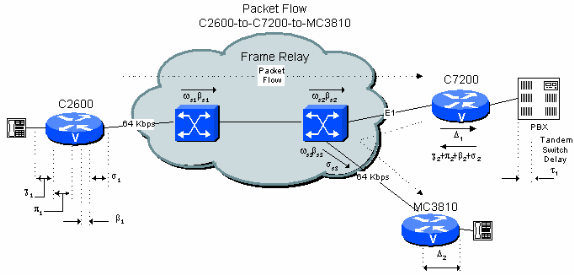
例 4.3 では、最悪ケースの遅延を想定していますが、支店間接続の中心サイトに PBX タンデム ホップが含まれ、いずれかの側にパブリック フレームリレー ネットワーク接続がある場合には、遅延の計算結果を 200 ミリ秒未満に抑えることは困難です。しかし、ネットワーク トポロジとトラフィックがわかっていれば、実質的に計算結果の値を抑えることができます。一般的に通信事業者から提示される値は、ワイドエリア上の最悪ケースの伝送とキューイングの遅延に制限されていますが、プライベート ネットワークではより適切な制限値を簡単に設定できるからです。
スイッチ間の伝送遅延について一般的な許容値は、およそ 10 マイクロ秒/マイルです。機器によっては、フレームリレー ネットワークの伝送スイッチ遅延が固定遅延 1 ミリ秒とキューイングの可変遅延 5 ミリ秒程度である必要があります。これらの値は、機器やトラフィックによって異なります。Cisco MGX WAN スイッチの遅延値は、E1/T1 トランクが使用された場合、スイッチごとに 1 ミリ秒未満です。距離が 500 マイルであると仮定すると、遅延計算値はホップごとに 1 ミリ秒の固定遅延と 5 ミリ秒の可変遅延になります。
表6.4:PBX タンデムを配置した 2 つのホップからなるプライベート ネットワークの遅延計算
| 遅延のタイプ | 固定(ミリ秒) | 可変(ミリ秒) |
|---|---|---|
| コーダ遅延、c1 | 18 | |
| パケット化遅延、p1 | 30 | |
| キューイング/バッファリング遅延、b1 | 8 | |
| シリアライゼーション遅延(64 kbps)、s1 | 5 | |
| ネットワーク遅延(私設フレーム)、wS1 + <FONT face=Symbol>bS1+ wS2 + bS2 | 0 | 10 |
| デジッタバッファ遅延、D1 | 40 | |
| コーダ遅延、c2 | 15 | |
| パケット化遅延、p2 | 30 | |
| キューイング/バッファリング遅延、b2 | 0.1 | |
| シリアライゼーション遅延(2 Mbps)、s2 | 0.1 | |
| ネットワーク遅延(私設フレーム)、wS3 + <FONT face=Symbol>bS3 | 1 | 8 |
| シリアライゼーション遅延(64 kbps)、sS3 | 5 | |
| デジッタバッファ遅延、D2 | 40 | |
| 伝送/距離遅延(非切断) | 5 | |
| 合計 | 191.1 | 26.1 |
注:キューイング遅延とネットワーク遅延の可変要素は、デジッタバッファの計算ですでに考慮されているため、遅延合計は、すべての固定遅延の合計にすぎません。この場合、遅延合計は 191.1 ミリ秒です。
プライベート フレームリレーのネットワーク上では、ハブ サイトの PBX を経由してスポーク間接続を確立して、遅延値を 200 ミリ秒以内に抑えることができます。
複数の圧縮サイクルの影響
CS-ACELP 圧縮アルゴリズムは決定論的ではありません。つまり、入力データ ストリームは、出力データ ストリームと完全に同じではありません。図 7-1 に示すように、圧縮サイクルごとに少量の歪みが生じます。
図 7-1:圧縮の影響 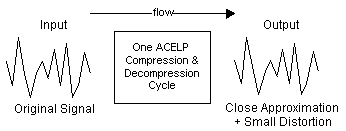
したがって、複数の CS-ACELP 圧縮サイクルでは、すぐに高レベルの歪みが生じます。この付加的な歪みの影響は、Adaptive Differential Pulse Code Modulation(ADPCM; 適応差分パルス符号変調)アルゴリズムでは報告されていません。
遅延の影響に加えて、この歪みの特性による影響を考えると、ネットワーク設計者は、パス内での CS-ACELP 圧縮サイクルの数を考慮する必要があります。
音声の品質は主観的なものです。ほとんどのユーザでは二度目の圧縮サイクルまでは適切な音声品質であると感じられます。三度目の圧縮サイクルを行うと、通常、顕著な品質低下が起こり、許容できないと感じられる場合があります。一般的に、ネットワーク設計者は、パス内の CS-ACELP 圧縮サイクルの数を 2 に制限する必要があります。二度よりも多いサイクルを使用する必要が生じた場合には、まずはカスタマーに確認してください。
前の例(PBXの場合)では、本社サイトのPBX(PCM形式)を介して分岐間接続をタンデムスイッチする場合、本社のC7200でタンデムスイッチする場合よりも遅延が大幅に大きくなることが示されていますフレーム化された音声が中央のC7200によって切り替えられると、1サイクルになります。音声品質は、C7200スイッチの例(4.2)により向上します。ただし、コールプラン管理など、パスにPBXが含まれる理由もあります。
支店間接続が本社 PBX 経由で開始され、さらに支店からパブリック音声ネットワークを経由して携帯(セルラー)電話ネットワークに着信させる場合、遅延値が大幅に高まるだけでなく、パス内には CS-ACELP 圧縮サイクルが三度存在することになります。このシナリオでは、音声品質が顕著に低下します。ここでも、ネットワーク設計者は、最悪ケースのコール パスを想定して、ユーザのネットワーク、期待値、およびビジネス要件などに基づいて、その構成が許容範囲内かどうかを判断する必要があります。
高遅延接続に関する考慮点
パケット音声ネットワークの設計では、ITU で通常許容されている 150 ミリ秒の一方向遅延制限値は、比較的簡単に超えてしまいます。
パケット音声ネットワークを設計するとき、技術者は音声コールの利用頻度、ユーザの要求内容、および関係する業務活動の種類などを考慮する必要があります。特定の環境に限って、このような接続が許容されることは珍しくありません。
フレームリレーの接続距離が長距離でなければ、ネットワークの遅延パフォーマンスは、このドキュメントの例よりも改善されることが十分に考えられます。
タンデム ルータおよびゲートウェイ接続の総遅延値が大きくなりすぎた場合、エンドポイントの MC3810 間に直接追加の PVC を設定する、別の方法があります。キャリアは通常、PVC 単位で請求してくるので、PVC の追加によりネットワークに重複コストが発生しますが、それでも追加が必要な場合もあります。
 フィードバック
フィードバック