フレーム リレーと ATM でのマルチリンク PPP の設計と導入
内容
概要
Multilink PPP over ATM(MLPoATM)および Multilink PPP over Frame Relay(MLPoFR)は、Cisco IOS® ソフトウェア リリース 12.1(5)T で導入されました。この機能は、Frame Relay/ATM Interworking(FR/ATM IW)を利用し、中~低速 WAN リンクで Voice over IP(VoIP)を導入するお客様を対象としています。この機能が登場する以前には、Cisco IOS が ATM とフレーム リレーの両方でサポートする共通のレイヤ 2 フラグメンテーション方式は存在しませんでした。FR/ATM IW を使用するお客様はレイヤ 3 フラグメンテーションを使用せざるを得ませんでした。
前提条件
要件
このドキュメントは、MLPoATM およびフレーム リレー ネットワークを伴う VoIP ネットワークの設計および導入に関与するネットワーク担当者を対象としてします。次の項目に関する知識があることが推奨されます。
-
フレーム リレー
-
ATM
-
PPP
-
MLP
-
フレーム リレー/ATM インターワーキング
-
音声 QoS 設定
このドキュメントの目的は、これらのテーマについて技術的なトレーニングを行うことではありません。このドキュメントの末尾に参考資料のリストがあります。このドキュメントを読む前に、次に関する資料を確認して理解しておくことを推奨します。
使用するコンポーネント
このドキュメントの情報は、次のソフトウェアとハードウェアのバージョンに基づいています。
-
FR/ATM IW での MLP:Cisco IOS ソフトウェア リリース 12.1(5)T 以降
-
ATM での Compressed Real Time Transport Protocol(cRTP):Cisco IOS ソフトウェア リリース 12.2(2)T 以降
-
フレーム リレーおよび ATM での物理インターフェイスにおける低遅延キューイング(LLQ):Cisco IOS ソフトウェア リリース 12.0(7)T
-
フレーム リレーおよび ATM での相手先固定接続(PVC)ごとの LLQ:Cisco IOS ソフトウェア リリース 12.1(2)T
このドキュメントのケース スタディは、次に示すソフトウェアとハードウェアのバージョンを使用する実稼動ネットワークに基づいています。
-
コア Cisco 3660 ルータでは、Cisco IOS ソフトウェア リリース 12.2(5.8)T を実行しています。cRTP over ATM の要件では、Cisco IOS ソフトウェア リリース 12.2T の使用を規定しています。Cisco IOS ソフトウェア リリース 12.2(8)T1 では、次の既知の問題が解決されています。
Cisco Bug ID CSCdw44216(登録ユーザ専用):クラスベース均等化キューイング(CBWFQ)/LLQ リンクが輻輳状態になると、cRTP によって CPU の使用率が高くなります。
-
ブランチ Cisco 2620 ルータは、Cisco IOS ソフトウェア リリース 12.2(3) から 2.2(6a) へのアップグレードの段階にあります。 Cisco 2620 は、ブランチ H.323 ゲートウェイとしての役割も果たします。このアップグレードは、ゲートウェイ関連の問題によって必要になったものです。WAN および QoS 機能に関する限り、Cisco IOS ソフトウェア リリース 12.2(3) で重大な問題は発生していません。
表記法
ドキュメント表記の詳細は、『シスコ テクニカル ティップスの表記法』を参照してください。
設計
ここでは、フレーム リレーおよび ATM でのマルチリンク PPP の設計と導入に関連する、いくつかの設計概念について説明します。
データリンク オーバーヘッド
MLP を使用する ATM およびフレーム リレー ネットワークを設計する場合は、データリンク オーバーヘッドについて理解していなければなりません。オーバーヘッドは、各 VoIP コールによって消費される帯域幅の量に影響を与えます。また、オーバーヘッドを理解していれば、最適な MLP フラグメント サイズの決定する上でも役立ちます。極めて重要な点は、フラグメント サイズを整数個の ATM セルが収まるように最適化することです。このことは、セルのパディングにかなりの量の帯域幅が消費される、低速の PVC では尚更重要となります。フレーム リレーおよび ATM PVC での MLP におけるデータリンク オーバーヘッドは、次の要素によって決まります。
-
FRF.8 IW デバイスの動作モード(トランスペアレントまたはトランスレーション)。
-
トラフィックの方向(ATM からフレーム リレー、またはフレーム リレーから ATM)。
-
PVC 区間。オーバーヘッドは、PVC の ATM 区間とフレーム リレー区間で異なります。
-
トラフィック タイプ。データ パケットには MLP ヘッダーがあります。VoIP パケットには MLP ヘッダーはありません。
次の表に、データ パケットのデータリンク オーバーヘッドを一覧します。ここでは、すべての FRF.8 動作モード、トラフィック方向、および PVC 区間の組み合せについて、フレーム リレー、ATM、LLC、PPP、および MLP の各種ヘッダーのバイト数を詳細に示しています。
| FRF.8 モード | トランスペアレント | 変換 | ||||||
|---|---|---|---|---|---|---|---|---|
| トラフィックの方向 | フレーム リレーから ATM | ATM からフレーム リレー | フレーム リレーから ATM | ATM からフレーム リレー | ||||
| PVC のフレーム リレー区間または ATM 区間 | フレーム リレー | ATM | ATM | フレーム リレー | フレーム リレー | ATM | ATM | フレーム リレー |
| フレーム フラグ(0x7e) | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 |
| フレーム リレー ヘッダー | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LLC DSAP/SSAP1(0xfefe) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LLC 制御(0x03) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| NLPID2(PPP の場合は 0xcf) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| MLP プロトコル ID(0x003d) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| MLP シーケンス番号 | 4 | 4 | 4 | 4 | 4 | 4 | 4 | 4 |
| PPP プロトコル ID(最初のフラグメントのみ) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ペイロード(レイヤ 3+) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ATM アダプテーション層(AAL)5 | 0 | 8 | 8 | 0 | 0 | 8 | 8 | 0 |
| フレーム チェック シーケンス(FCS) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| オーバーヘッド合計(バイト) | 15 | 18 | 20 | 17 | 15 | 20 | 20 | 15 |
1 DSAP/SSAP:宛先サービスアクセスポイント/送信元サービスアクセスポイント。
2 NLPID:Network Layer Protocol Identification(ネットワーク層プロトコルの識別)。
トランスレーション PVC は両方向でオーバーヘッドが等しいため、トランスペアレント PVC よりも理解が容易です。両方向でオーバーヘッドが等しいわけは、FRF.8 デバイスが MLPoATM 形式と MLPoFR 形式との変換を行うためです。その結果、フレーム形式はフレーム リレー区間ではどちらの方向でも MLPoFR になり、ATM 区間ではどちらの方向でも MLPoATM になります。
トランスペアレント PVC は、方向によってオーバーヘッドが異なるためやや複雑です。この複雑さの原因は、フレームリレー ルータがパケットを MLPoFR 形式で送信することにあります。IW デバイスは、この形式のままパケットを ATM 側に送信します。同様に、ATM ルータは MLPoATM 形式でパケットを送信します。IW デバイスは、この形式のままパケットをフレーム リレー側に送信します。その結果、各区間で方向によってフレーム形式が異なることになります。
FRF.12 を使用するエンドツーエンド フレームリレー PVC と比較すると、この場合のオーバーヘッドは 11 バイトです。このため、エンドツーエンド フレームリレー リンクでは、Link Fragmentation and Interleaving(LFI)に MLP を使用するよりも FRF.12 を使用する方が効率的です。エンドツーエンド ATM Virtual Circuit(VC; 仮想回線)では、利用可能な標準ベースのフラグメンテーションが存在しないため、MLP が唯一の選択肢となります。ただし、エンドツーエンド ATM VC は通常は中~高速です。そのため、LFI は必要になりません。この規則は、デジタル加入者線(DSL)での低速 ATM VC には当てはまりません。
PPP ID は最初の MLP フラグメントにのみ存在します。したがって、最初のフラグメントのオーバーヘッドは、それ以降のフラグメントよりも常に 2 バイト大きくなります。
次の表に、VoIP パケットのデータリンク オーバーヘッドを記載します。ここでは、すべての FRF.8 動作モード、トラフィック方向、および PVC 区間の組み合せについて、フレーム リレー、ATM、LLC、および PPP の各種ヘッダーのバイト数を詳しく示しています。データ パケットと VoIP パケットの主な違いは、VoIP パケットが MLP パケットとしてではなく、PPP パケットとして送信される点です。それ以外の点はすべてデータ パケットの場合と同じです。
| FRF.8 モード | トランスペアレント | 変換 | フレーム リレーからフレーム リレー | ||||||
|---|---|---|---|---|---|---|---|---|---|
| トラフィックの方向 | フレーム リレーから ATM | ATM からフレーム リレー | フレーム リレーから ATM | ATM からフレーム リレー | |||||
| PVC のフレーム リレー区間または ATM 区間 | フレーム リレー | ATM | ATM | フレーム リレー | フレーム リレー | ATM | ATM | フレーム リレー | |
| フレーム フラグ(0x7e) | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 |
| フレーム リレー ヘッダー | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LLC DSAP/SSAP(0xfefe) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| LLC 制御(0x03) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| NLPID(PPP は 0xcf) | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| PPP ID | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ペイロード(IP + User Datagram Protocol(UDP) + RTP + 音声) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| AAL5 | 0 | 8 | 8 | 0 | 0 | 8 | 8 | 0 | 0 |
| FCS | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| オーバーヘッド合計(バイト) | 9 ミリ秒 | 12 | 14 | 11 | 9 ミリ秒 | 14 | 14 | 9 ミリ秒 | 7 |
比較のため、一番右の列に、エンドツーエンド フレーム リレー PVC における VoIP パケットのデータリンク オーバーヘッドを記載しています。
VoIP の帯域幅要件
VoIP の帯域幅をプロビジョニングする際は、帯域幅の計算にデータリンク オーバーヘッドを含める必要があります。次の表に、さまざまな VoIP でコールあたりに必要になる帯域幅を一覧します。この表は PVC の特性に基づいたものです。この表の計算では、cRTP について最良のケースのシナリオが想定されています(UDP チェックサムも伝送エラーも存在しないなど)。 この場合、ヘッダーは常に 40 バイトから 2 バイトに圧縮されます。
| FRF.8 モード | トランスペアレント | 変換 | フレーム リレーからフレーム リレー | ||||||
|---|---|---|---|---|---|---|---|---|---|
| トラフィックの方向 | フレーム リレーから ATM | ATM からフレーム リレー | フレーム リレーから ATM | ATM からフレーム リレー | |||||
| PVC のフレーム リレー区間または ATM 区間 | フレーム リレー | ATM | ATM | フレーム リレー | フレーム リレー | ATM | ATM | フレーム リレー | |
| G.729 - 20 ミリ秒サンプル - cRTP なし | 27.6 | 42.4 | 42.4 | 28.4 | 27.6 | 42.4 | 42.4 | 27.6 | 26.8 |
| G.729 - 20 ミリ秒サンプル - cRTP | 12.4 | 21.2 | 21.2 | 13.2 | 12.4 | 21.2 | 21.2 | 12.4 | 11.6 |
| G.729 - 30 ミリ秒サンプル - cRTP なし | 20.9 | 28.0 | 28.0 | 21.4 | 20.9 | 28.0 | 28.0 | 20.9 | 20.3 |
| G.729 - 30 ミリ秒サンプル - cRTP | 10.8 | 14.0 | 14.0 | 11.4 | 10.8 | 14.0 | 14.0 | 10.8 | 10.3 |
| G.711 - 20 ミリ秒サンプル - cRTP なし | 83.6 | 106.0 | 106.0 | 84.4 | 83.6 | 106.0 | 106.0 | 83.6 | 82.8 |
| G.711 - 20 ミリ秒サンプル - cRTP | 68.4 | 84.8 | 84.8 | 69.2 | 68.4 | 84.8 | 84.8 | 68.4 | 67.6 |
| G.711 - 30 ミリ秒サンプル - cRTP なし | 76.3 | 97.9 | 97.9 | 76.8 | 76.3 | 97.9 | 97.9 | 76.3 | 75.8 |
| G.711 - 30 ミリ秒サンプル - cRTP | 66.3 | 84.0 | 84.0 | 66.8 | 66.3 | 84.0 | 84.0 | 66.3 | 65.7 |
オーバーヘッドは PVC の区間によって異なるため、最悪のケースのシナリオ向けに設定する必要があります。一例として、トランスペアレント PVC で 20 ミリ秒(msec)サンプリングと cRTP を使用する G.729 について考えてみます。フレーム リレー区間におけるこのシナリオの帯域幅要件は、一方の方向では 12.4 Kbps、もう一方の方向では 13.2 Kbps です。プロビジョニングは、コールにつき 13.2 Kbps が必要となるという前提で行う必要があります。
比較のため、上記の表の一番右の列に、エンドツーエンド フレームリレー PVC における VoIP の帯域幅要件も記載してあります。ネイティブのフレームリレー カプセル化と比べ、PPP のオーバーヘッドが追加される結果、帯域幅の消費量が 1 コールあたり 0.5 Kbps から 0.8 Kbps 多くなります。したがって、エンドツーエンド フレームリレー VC では、フレームリレー カプセル化に MLP を使用するよりも FRF.12 を使用する方が理にかなっています。
注:cRTP over ATMにはCisco IOSソフトウェアリリース12.2(2)T以降が必要です。
フラグメンテーション サイズの最適化
フレーム リレー/ATM PVC で MLP を使用する理由は、大きなデータ パケットを小さなチャンクに分割できるようにするためです。これにより、ルータはデータ フラグメントの間に VoIP パケットをインターリーブして VoIP パケットを高速転送できます。Cisco IOS では、フラグメンテーション サイズを直接設定することはしません。代わりに、ppp multilink fragment-delay コマンドを利用して、必要な遅延を設定します。Cisco IOS は、その設定された遅延を次の公式で使用して、適切なフラグメント サイズを計算します:。
fragment size = delay x bandwidth/8
ATM 上で MLP を実行するときは、整数個のセルが収まるようにフラグメント サイズが最適化されなければなりません。このように最適化されていなければ、パディングにより必要な帯域幅が約 2 倍に増えることになります。たとえば、各フラグメントの長さが 49 バイトだとすると、送信するフラグメントごとに 2 つの ATM セルが必要になります。したがって、49 バイトのペイロードを送信するだけのために 106 バイトが使用されることになります。
Cisco IOS は、MLPoATM および MLPoFR を実行する際、整数個の ATM セルを使用するために、自動的にフラグメント サイズを最適化します。計算されたフラグメント サイズは、ATM セルの次の整数倍に自動的に切り上げられます。新たに追加される CLI コマンドはありません。Cisco IOS は、この最適化を MLPoFR/ATM PVC のフレームリレー側と ATM 側の両方で実行します。MLP PVC がエンドツーエンド フレームリレーの場合もあります。この場合、ATM 向けに最適化する必要はありません。ただし、Cisco IOS では、リモート エンドが ATM とフレームリレーのいずれであるかを検出する手段がないため、この場合も ATM 向けの最適化が実行されます。
注:丸めが原因で、結果の遅延が設定より少し大きくなる場合があります。この丸め誤差は低速 PVC でより顕著になります。
最適化を手作業で設定することもできます。Cisco IOS ではフラグメント サイズを直接指定できないため、最適なフラグメント サイズを計算し、これを遅延に変換します。フラグメント サイズを計算する際はデータリンク オーバーヘッドを考慮する必要があります。これは、MLP コードではすべてのリンクが高レベル データリンク制御(HDLC)であり、2 バイトのデータリンク オーバーヘッドを持つものと想定されているためです。MLP コードの計算には、HDLC データリンク オーバーヘッドに加え、MLP ID、MLP シーケンス番号、および PPP ID からなる 8 バイトが含まれます(上記の最初の表を参照)。
Cisco IOS に設定する遅延を計算するには、次の手順に従います。
-
必要な遅延と PVC の帯域幅に基づいて、理論的なフラグメント サイズを計算します。
fragment = bandwidth * delay / 8
-
フラグメントは、整数個の ATM セルが収まるように 48 バイトの倍数にします。
セルに合わせてフラグメント サイズを計算するための公式は、次のとおりです。
fragment_aligned = (int(fragment/48)+1)*48
-
MLP によって考慮されないデータリンク オーバーヘッド分を補正します。
前述したように、このオーバーヘッドは PVC の特性に応じて異なります。最適化の対象は PVC の ATM 側であるため、ATM について考慮します。次の表に、ATM 側のデータリンク オーバーヘッドのバイト数を記載します。
FRF.8 モード トランスペアレント 変換 トラフィック方向 フレーム リレーから ATM ATM からフレーム リレー フレーム リレーから ATM ATM からフレーム リレー PVC のフレーム リレー区間または ATM 区間 ATM ATM ATM ATM LLC DSAP/SSAP(0xfefe) 0 0 0 0 LLC 制御(0x03) 1 1 1 1 NLPID(PPP は 0xcf) 1 1 1 1 AAL5 8 8 8 8 非 MLP オーバーヘッド(バイト) 10 12 12 12 MLP での計算の基礎になるフラグメント サイズを算出するには、セルに合わせた必要なフラグメント サイズからデータリンク オーバーヘッドを差し引きます。その値に、MLP で常に前提とされる HDLC カプセル化を補正するために 2 バイトを加えます。
MLP コードの対象となるフラグメント サイズを計算する公式は次のとおりです。
fragment_mlp = fragment_aligned - datalink_overhead + 2
-
次の公式で、算出されたフラグメント サイズを対応する遅延に変換します。
delay = fragment_mlp/bandwidth x 8bits/byte
-
ほとんどの場合、算出される遅延は整数のミリ秒になりません。Cisco IOS は整数値のみを受け入れるため、端数を切り捨てる必要があります。したがって、Cisco IOS で ppp multilink fragment-delay コマンドを利用して設定する遅延値は、次のようになります。
fragment_delay = int(fragment_mlp/bandwidth x 8bits/byte)
-
上記の丸め誤差を補正するため、遅延からフラグメントに変換する際に MLP で使用される帯域幅に誤差を持たせます。誤差を持たせた帯域幅は次の公式で計算します。この公式で算出された帯域幅を、Cisco IOS で bandwidth コマンドを利用して設定します。
bandwidth = fragment_mlp/fragment_delay * 8
次の表に、一般的な PVC 速度での ppp multilink fragment-delay および bandwidth の最適値を一覧します。ターゲットの遅延には 10 ミリ秒を想定します。表を簡素化するため、トランスペアレント PVC とトランスレーション PVC の区別、およびトラフィック方向による区別は行っていません。データリンク オーバーヘッドの差異は最大でも 2 バイトにすぎません。したがって、最悪のケースを考慮した 12 バイトのペナルティも大きなものではありません。この表には、整数個のセルが収まるようにフラグメント サイズを増やした場合の、「実際の」遅延も示されています。
| PVC 速度 | フラグメント サイズ | ppp multi-link fragment-delay | 帯域幅 | 実際の遅延 |
|---|---|---|---|---|
| (Kbps) | (セル数) | (ミリ秒) | (Kbps) | (ミリ秒) |
| 56 | 0 | 12 | 57 | 13.7 |
| 64 | 0 | 10 | 68 | 12.0 |
| 128 | 4 | 11 | 132 | 12.0 |
| 192 | 6 | 11 | 202 | 12.0 |
| 256 | 7 | 10 | 260 | 10.5 |
| 320 | 9 ミリ秒 | 10 | 337 | 10.8 |
| 384 | 11 | 10 | 414 | 11.0 |
| 448 | 12 | 10 | 452 | 10.3 |
| 512 | 14 | 10 | 529 | 10.5 |
| 576 | 16 | 10 | 606 | 10.7 |
| 640 | 17 | 10 | 644 | 10.2 |
| 704 | 19 | 10 | 721 | 10.4 |
| 768 | 21 | 10 | 798 | 10.5 |
トラフィック シェーピングおよびポリシングに関する注意事項
フレーム リレー/ATM IW 環境におけるトラフィック シェーピングおよびポリシングには、特殊な考慮事項があります。フレーム リレーから ATM の方向での問題は、ATM からフレーム リレーの方向での問題と異なります。そのため、それぞれのトピックについて個別に説明します。
フレーム リレーから ATM の方向での主な問題は、フレームからセルに移行する際に帯域幅消費が増大する可能性があることです。たとえば、フレーム リレー側で 49 バイトのフレームは、ATM 側では 2 つのセル、すなわち 106 バイトを消費します。したがって、平均セル レート(SCR)と認定情報レート(CIR)が等しいと見なすことはできません。 最悪のシナリオは、フレーム リレーの各フレームに含まれるペイロードが 1 バイトの場合です。これらのバイトのそれぞれが、ATM 側で 53 バイトのセルを消費するためです。これは概念を説明するための極端で非現実的なシナリオに過ぎませんが、このシナリオでは SCR が CIR の 53 倍になります。次に、より現実的な例を 2 つ示します
-
G.729 VoIP パケットは 60 バイト長または 69 バイト長(MLP およびフレーム リレー オーバーヘッドが含まれる場合)です。 ATM 区間では、このパケットは 2 つのセル、つまり 106 バイトを消費します。したがって、伝送されるすべてのトラフィックが VoIP であるとしたら、適切なマッピングは SCR = 106/69 = 1.5 x CIR になります。
-
1 回のキーストロークを伝送する Telnet パケットには、40 バイトの TCP/IP ヘッダーと 1 バイトのデータが含まれます。フレーム リレー側では、これはオーバーヘッドを含めて合計 56 バイトになります。ただし、ATM 側ではこのパケットが 2 つのセルに拡張されます。この場合は、SCR = 106/56 = 1.9 x CIR になります。
ATM フォーラムの標準「BISDN Inter Carrier Interface (B-ICI) Specification Version 2.0」の付録 A に、SCR と CIR 間の 2 種類のマッピング方法が説明されています。どちらも CIR から SCR を科学的に導く方法ですが、いずれの方法も、対象となるデータより正確というわけではありません。これらの公式には一般的なフレーム サイズが必要ですが、これは、実際のネットワークでは判別するのが難しい数値です。また、既存の ATM/フレーム リレー ネットワークに新規アプリケーションが展開されるごとに、当然この数値は変わってきます。この問題を解決するために推奨される方法は、キャリアと緊密に協力することです。これは、キャリアのポリシング ポリシーがきわめて重要であるためです。キャリアの支援を得ることにより、次のフェールセーフ アプローチが可能になります。
-
フレームリレーから ATM の方向:フレーム リレーから ATM の方向では、キャリアはフレームリレー入力点のみで着信トラフィックをポリシングする必要があります。たとえば、フレームリレー接続の顧客宅内機器(CPE)デバイスに接続されたフレーム リレー スイッチで、キャリアが契約 CIR に従ってトラフィックをポリシングします。次の図に、このポリシング ポリシーを次の図に示します。入力点でトラフィックのネットワークへの流入が許可されると、それ以上のポリシングは行われません。このポリシング ポリシーで注意すべき点は、フレーム リレー側で受信されたデータを、ネットワークの ATM 区間を通じて伝送するために、セル タックス、AAL オーバーヘッド、およびパディングの収容に必要な分だけ帯域幅を拡張し、消費できる点です。ほとんどの場合、必要な ATM 帯域幅は、使用されるフレームリレー帯域幅の 2 倍よりも少なくなります。
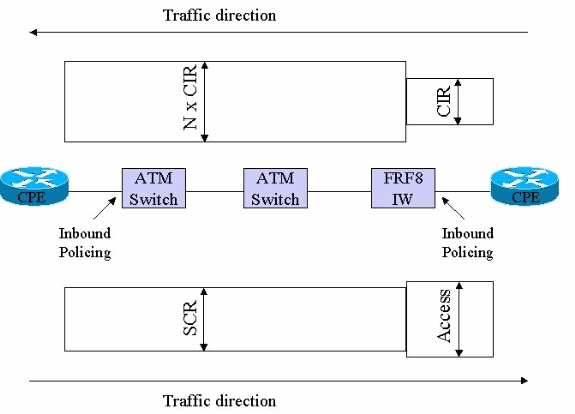
-
ATM からフレームリレーの方向:ATM からフレームリレーの方向では逆のことが起こります。ATM セルがフレームに変換される場合は、セル タックス、AAL オーバーヘッド、およびパディングが除去されるため、帯域幅使用量が減少します。ただし、ATM 側で想定される送信レートはフレーム リレー リンクよりはるかに高いため、音声の完全性を維持するためには、ATM ルータでトラフィック シェーピングを正確に設定することが不可欠です。シェーピングが緩やか過ぎる場合、ATM ルータによるデータ フィードの速度が、フレームリレー リンクのもう一方の端における物理的な速度を上回ります。結果として、FRF.8 スイッチでパケットのキューイングが開始されます。その後、ある時点でパケットの廃棄が始まります。ATM/フレームリレー ネットワークでは音声とデータを区別できないことから、VoIP パケットも廃棄されます。
その一方で、シェーピングが厳しすぎる場合はスループットが低下します。ATM セル タックスのため、AAL オーバーヘッドおよびパディングが FRF.8 デバイスによって除去されます。これにより、フレーム リレー リンクではその分の帯域幅が消費されなくなります。したがって、PVC の ATM 側ではオーバーサブスクライブが許容されます。パディングおよび AAL オーバーヘッドの量は、平均フレーム サイズや、フラグメンテーションがどれだけ積極的に行われているかに応じて異なります。このオーバーヘッドを正確に判断することは不可能なため、これについては最適化しようと考えない方が賢明です。これに対し、セル タックスは完全に確定的です。セル タックスは、ペイロード 48 バイトごとに 5 バイトと決まっています。したがって、ATM ルータでシェーピング ターゲットを 53/48 x SCR に設定すれば、セル タックスに関する最適化が可能になります。この若干のオーバーサブスクリプションを許容するよう、キャリア側のポリシングが設定される必要があります。
ヒントおよび注意事項
-
MLPoATM/フレーム リレーは現在テスト中であり、仮想テンプレートまたはダイヤラ インターフェイスに適用されたサービスポリシーでのみサポートされます。サービスポリシーを省略すると、機能が有効にならない可能性があります。この問題の一例は、Cisco Bug ID CSCdu19313(登録ユーザのみ)で文書化されています。
-
MLPoATM/フレーム リレーでは、PVC ごとに 2 つの仮想アクセス インターフェイスをコピーします。その一方は、PPP リンクを表します。もう一方は、MLP バンドルを表します。どちらがどちらに対応するかを調べるには、show ppp multilink コマンドを使用します。バンドルごとにサポートされる PPPoFR リンクは 1 つのみです。1 つのバンドル トラフィックに 2 つの PPPOFR 回線を配置しても、これらの回線で有効にロード バランシングが行われることにはなりません。実際のシリアル ドライバとは異なり、PPPOFR ドライバはフロー制御信号を送信しないためです。ATM またはフレーム リレーでの MLPPP ロード バランシングは、物理インターフェイスでの MLPPP ロード バランシングに比べ、効率性に著しく欠ける可能性があります。
-
各 PVC は 4 つの異なるインターフェイス、つまり物理インターフェイス、サブインターフェイス、および 2 つの仮想アクセス インターフェイスに関連付けられます。高度なキューイングが有効にされるのは、MLP 仮想アクセス インターフェイスのみです。他の 3 つのインターフェイスでは、First In First Out(FIFO; 先入れ先出し)キューイングを行う必要があります。
-
service-policy コマンドを仮想テンプレートに適用すると、Cisco IOS によって次の通常警告メッセージが表示されます。
cr7200(config)#interface virtual-template 1 cr7200(config-if)#service-policy output Gromit Class Based Weighted Fair Queueing (CBWFQ) not supported on interface Virtual-Access1 Note CBWFQ supported on MLP bundle interface only.
これらのメッセージは異常を表すものではありません。最初のメッセージは、サービスポリシーは PPP 仮想アクセス インターフェイスではサポートされないことを警告しています。2 番目のメッセージは、MLP バンドル仮想アクセス インターフェイスでサービスポリシーが有効になったことを確認の意味で表示しています。このことは、show interfaces virtual-access、show queue 、および show policy-map interface コマンドを利用してキューイング メカニズムを調べることで、確認できます。
-
PVC は専用回線と同じようなものであるため、厳密な PPP 認証は不要です。ただし、PPP 認証には、show ppp multilink コマンドを使用して PVC のもう一方の端のルータ名を確認できるという便利な点があります。
-
フレーム リレー ルータでは、MLPoFR PVC に対してフレーム リレー トラフィック シェーピングを有効にする必要があります。
-
Cisco IOS ソフトウェア リリース 12.2 は、当初はルータ 1 台あたり最大 25 の仮想テンプレートをサポートしていました。すべての PVC が一意の IP アドレスを持つ必要がある場合、この制限が ATM ディストリビューション ルータのスケールに影響を与える可能性があります。該当するバージョンでは、回避策として IP 非番号制を使用するか、または仮想テンプレートの代わりにダイヤラ インターフェイスを使用できます。Cisco IOS ソフトウェア リリース 12.2(8)T では、サポートされる仮想テンプレートの数が 200 まで増加されています。
-
サービス プロバイダーの中には、まだ自社の FRF.8 デバイスで PPP 変換をサポートしていないところがあります。この制限が当てはまるプロバイダーは、自社の PVC をトランスペアレント モードに設定する必要があります。
-
Cisco IOS ドキュメントのほとんどの例では、フレーム リレーまたは ATM サブインターフェイスを含む構成が示されています。このサブインターフェイスは何の役割も果たしません。物理インターフェイスには仮想テンプレートを適用してください。これにより、より簡素で管理しやすい構成になります。このことは、多数の PVC がある場合には特に重要です。
-
キャリア側でセルまたはフレームの廃棄がないかどうかを確実に判別する方法は、show ppp multilink コマンドを使用することです。許容されるフラグメント損失は、巡回冗長検査(CRC)エラーが原因のものに限られます。
-
MLPoATM/フレーム リレーは Cisco IOS ソフトウェア リリース 12.1(5)T で導入されましたが、このリリースおよびその後のリリースにバグがあるため、Cisco IOS ソフトウェア リリースを選択するときには注意が必要です。Cisco IOS 12.2 メインストリームの最新のメンテナンス リリースを使用することを推奨します。ただし、他の VoIP 機能の要件から、異なる Cisco IOS ソフトウェア リリースが必要となることがあります。たとえば、Survivable Remote Site Telephony(SRST)が必要な場合は 12.2(2)XT を使用する必要があります。次の表に、既知の問題のいくつかを一覧します。Cisco IOS を選択する際は、選択した IOS に対して各 Cisco Bug ID を評価してください。
| Cisco Bug ID | 説明 |
|---|---|
| CSCdt09293(登録ユーザ専用) | LFI- 7200 でのファースト スイッチングにより単方向音声コールが発生する |
| CSCdt25586(登録ユーザ専用) | PPPoA アクセス フラッピングまたは相手先選択接続(SVC)がアイドル タイムアウトで切断されない |
| CSCdt29661(登録ユーザ専用) | MLP- ファースト スイッチング中の ATM インターフェイスのシャットダウンによりルータがクラッシュする |
| CSCdt53065(登録ユーザ専用) | ATM LFI 機能に関する atm_lfi コードのパフォーマンス改善 |
| CSCdt59038(登録ユーザ専用) | MLPoATM:PA-A3 で大きなパケットによる ping が失敗する |
| CSCdu18344(登録ユーザ専用) | MLPoATM/フレーム リレー PVC のスループットが SCR/CIR の半分に満たない |
| CSCdu19297(登録ユーザ専用) | サービス ポリシーを使用しない場合、MLPoATM PVC でエラーが発生する |
| CSCdu41056(登録ユーザ専用) | MLPoATM:ドライバ vc_soutput ルーチンが 2 回コールされる |
| CSCdu44491(登録ユーザ専用) | MLPoFR の VirtualAccess カウンタが正しくない |
| CSCdu51306(登録ユーザ専用) | PPPoX でキープアライブが途絶える |
| CSCdu57004(登録ユーザ専用) | MLP 使用時に CEF が動作しない |
| CSCdu84437(登録ユーザ専用) | MLP と tx-ring が調整されたドライバ間でのフロー制御の実装 |
| CSCdv03443(登録ユーザ専用) | Cisco IOS® ソフトウェア リリース 12.2 での u76585 に関する修正のコミット:着信 MLP パケットがプロセス交換される |
| CSCdv10629(登録ユーザ専用) | MLPoATM:音声パケットが LLQ でキューイングされない |
| CSCdv20977(登録ユーザ専用) | 着信 MLP パケットがプロセス交換される |
| CSCdw44216(登録ユーザ専用) | CBWFQ/LLQ リンクが輻輳状態になると、cRTP によって CPU の使用率が非常に高くなる |
| CSCdy70337(登録ユーザ専用) | MLP に QoS をバンドルすると、サービス ポリシーが使用される |
| CSCdx71203(登録ユーザ専用) | MLP バンドルに少数の非アクティブ リンクが含まれることがある |
ケース スタディ
概要
この項では、MLPoATM/フレーム リレー機能を最初にお客様に展開したときの一例について説明します。お客様は架空の名前のXYZ Ltd.と呼ばれます。2001年、XYZ LtdはPBXをIPテレフォニーソリューションに置き換えました。このプロジェクトの一環として、新しい IP ネットワークが構築されました。WAN にはフレームリレー/ATM インターワーキングが選択されました。WAN サービスを提供するキャリアは、Newbridge スイッチを使用して ATM およびフレームリレー サービスを提供しています。
ネットワークの概要
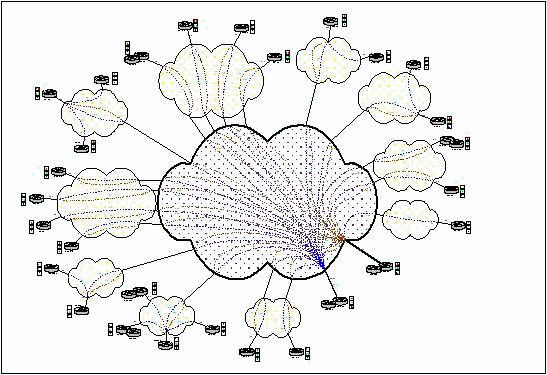
XYZ Ltd のネットワークは、26 のブランチを 2 つのコア サイトで接続するハブアンドスポーク ネットワークです。各コア サイトでは、E3 ATM が接続された Cisco 3660 ルータを使用します。26 のブランチのうち、18 は中程度の規模です。これらのブランチでは、ATM/フレーム リレー IW を介して 2 つのコア サイトにある 3660 に接続する、デュアル フレームリレー PVC を使用しています。残りの 8 つのブランチはごく小規模です。これらのブランチは単一フレーム リレー PVC を経由して最も近い中規模ブランチに接続します。ブランチ ルータはすべて Cisco 2620 です。エンドツーエンド ATM PVC はそれぞれ 2 つのハブ サイトの 2 台の 3660 ルータに接続します。次の図に、このトポロジを示します。
次の表に、フレーム リレー アクセス速度と CIR を一覧します。CIR は 32 kbps から 256 kbps までさまざまです。また、各 PVC が伝送する同時 VoIP コールの最大数も示しています。
| サイト | リモート サイト | アクセス(kbps) | CIR(kbps) | コール数 |
|---|---|---|---|---|
| ブランチ 1 | コア 1 | 320 | 192 | 6 |
| ブランチ 2 | ブランチ 22 | 128 | 64 | 2.0 |
| ブランチ 3 | コア 1 | 576 | 256 | 8.0 |
| ブランチ 4 | ブランチ 16 | 64 | 32 | 2.0 |
| ブランチ 5 | コア 1 | 128 | 64 | 2.0 |
| ブランチ 6 | ブランチ 3 | 64 | 32 | 2.0 |
| ブランチ 7 | コア 1 | 512 | 256 | 8.0 |
| ブランチ 8 | コア 1 | 512 | 256 | 8.0 |
| ブランチ 9 | ブランチ 13 | 128 | 256 | 2.0 |
| ブランチ 10 | コア 1 | 256 | 128 | 4.0 |
| ブランチ 11 | コア 2 | 128 | 96 | 2.0 |
| ブランチ 12 | コア 1 | 128 | 64 | 2.0 |
| ブランチ 13 | コア 1 | 768 | 256 | 12.0 |
| ブランチ 14 | コア 1 | 192 | 96 | 4.0 |
| ブランチ 15 | コア 1 | 192 | 96 | 4.0 |
| ブランチ 16 | コア 1 | 448 | 192 | 8.0 |
| ブランチ 17 | ブランチ 13 | 128 | 64 | 2.0 |
| ブランチ 18 | コア 1 | 128 | 96 | 2.0 |
| ブランチ 19 | ブランチ 16 | 128 | 64 | 2.0 |
| ブランチ 20 | コア 1 | 64 | 32 | 2.0 |
| コア 2 | コア 1 | 34000 | 256 | 12.0 |
| ブランチ 21 | ブランチ 13 | 128 | 64 | 2.0 |
| ブランチ 22 | コア 1 | 384 | 192 | 6.0 |
| ブランチ 23 | コア 1 | 512 | 256 | 8.0 |
| ブランチ 24 | コア 1 | 192 | 96 | 2.0 |
| ブランチ 25 | コア 1 | 128 | 96 | 4.0 |
| ブランチ 26 | ブランチ 1 | 64 | 32 | 2.0 |
フレーム リレー トラフィック シェーピングはブランチ ルータによって実行されます。CIR を超えるバーストは許容されます。Cisco IOS トラフィック シェーピングは、mincir を CIR と同じ値とし、アクセス速度にシェーピングするように設定されます。逆方向明示的輻輳通知(BECN)がキャリアから送信された場合、ルータによって mincir に再びスロットルされます。このアプローチは、VoIP over Frame Relay を行う場合のシスコの推奨に反します。ルータが輻輳通知に応答したときには、すでに音声に問題が生じているためです。しかし、このケースでは、ネットワークで十分な帯域が提供されているためフレームやセルが廃棄されることはなく、したがって BECN が発生することはないとキャリアが確信しています。
ATM トラフィック シェーピングは、セル タックスを加えたリモート エンドのフレーム アクセス速度でシェーピングするように設定されています。たとえば、アクセス速度が 512 Kbps であれば、SCR は 512x53/48 = 565 Kbps に設定されます。このシェーピング レートはスループットを最大化するために使用されます。セル タックスは IW ポイントで除去されるため、このシェーピング レートは安全と考えられます。キャリア側のポリシングは、若干の加入過多が許容されるように余裕をもって設定されています。
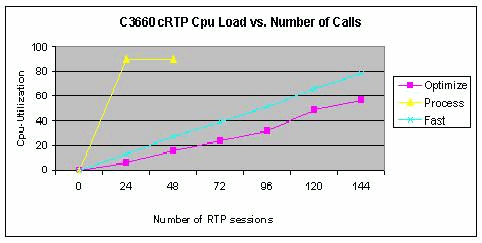
cRTP は WAN 全体を通じて使用されます。CPUに関するホットスポットは、コアサイト1のCisco 3660ディストリビューションルータです。上記の表に番号を追加すると、このルータを通過するVoIPコールの理論上の最大数は102コールと判断されます。次のグラフのパフォーマンス値から、(ファスト スイッチングが行われる)100 の cRTP セッションに対する Cisco 3660 の CPU 負荷は約 50 % です。
IP 番号制 WAN リンクでは仮想テンプレートが使用されます。各 PVC に 1 つの仮想テンプレートが必要ですが、個々の Cisco 3660 で終端する PVC の総数は 25 未満であるため、これは可能です。
設定
このドキュメントでは、次の構成を使用します。
| コア ATM ルータ |
|---|
!--- Note: This section shows the parts of a core Cisco 3660 router !--- configuration that is relevant to MLPoATM.
class-map match-all Voice_Stream
match access-group 100
class-map match-all Voice_Control
match access-group 101
policy-map toortr01
class Voice_Stream
priority 175
class Voice_Control
bandwidth 18
random-detect
interface loopback0
ip address 10.16.0.105 255.255.255.252
interface ATM2/0
description To Carrier E3 ATM Service
no ip address
interface ATM2/0.15 point-to-point
pvc toortr01 0/58
vbr-nrt 406 406
tx-ring-limit 8
protocol ppp Virtual-Template15
interface Virtual-Template15
bandwidth 320
ip unnumbered loopback0
ip tcp header-compression iphc-format
service-policy output toortr01
ppp multilink
ppp multilink fragment-delay 14
ppp multilink interleave
ip rtp header-compression iphc-format
!--- Note: Do not configure !--- IP addresses directly on any configuration source, !--- such as a virtual template, whenever the possibility !--- exists that this information is cloned to multiple !--- active interfaces. The exception to this rule is the !--- rare case where the intent is to define multiple parallel !--- IP routes and have IP do load balancing between them. !--- If an IP address is present on the configuration source, !--- this IP address is copied to all the cloned interfaces. !--- IP installs a route to each of these interfaces.
|
| ブランチ フレーム リレー ルータ |
|---|
!--- Note: This section shows the parts of a branch Cisco 2600 router !--- configurations that is relevant to MLPoFR.
class-map match-all Voice_Stream
match access-group 100
class-map match-all Voice_Control
match access-group 101
policy-map dhartr21
class Voice_Stream
priority 240
class Voice_Control
bandwidth 18
random-detect
interface loopback0
ip address 10.16.0.106 255.255.255.252
interface Serial0/0
description To Carrier Frame Relay Service
encapsulation frame-relay IETF
frame-relay traffic-shaping
interface Serial0/0.1 point-to-point
frame-relay interface-dlci 38 ppp Virtual-Template1
class dhartr21
interface Virtual-Template1
bandwidth 320
ip unnumbered loopback0
max-reserved-bandwidth 85
service-policy output dhartr21
ppp multilink
ppp multilink fragment-delay 10
ppp multilink interleave
map-class frame-relay dhartr21
frame-relay adaptive-shaping becn
frame-relay cir 320000
frame-relay bc 3200
frame-relay mincir 320000 |
関連情報
- QoS(フラグメンテーション、トラフィック シェーピング、LLQ/IP RTP プライオリティ)が備わった VoIP over Frame Relay
- LLQ、PPP LFI、および cRTP を使用したフレーム リレー ATM インターワーキングの VoIP QOS
- フレーム リレーおよび ATM 仮想回線に関するリンク断片化およびインターリービングの設定
- RFC 2364 - PPP Over AAL5(1998 年 7 月)

- RFC1973 - PPP in Frame Relay(1996 年 6 月)
- RFC 1717 - The PPP Multilink Protocol (MP)(1994 年 11 月)
- RFC 2508 - Compressing IP/UDP/RTP Headers for Low-Speed Serial Links(1999 年 2 月)
- Frame Relay / ATM PVC Service Interworking Implementation Agreement FRF.8.2
- Frame Relay Fragmentation Implementation Agreement FRF.12
- 音声に関する技術サポート
- 音声と IP 通信製品サポート
- Cisco IP Telephony のトラブルシューティング
- テクニカル サポートとドキュメント – Cisco Systems
 フィードバック
フィードバック