はじめに
このドキュメントでは、サーバーの電源状態(MC エラー)が原因でブレードが検出に失敗する問題のトラブルシュート手順について説明します。
前提条件
要件
次のトピックに関する知識があることが推奨されます。
- Cisco Unified Computing System(UCS)
- Ciscoファブリックインターコネクト(FI)
使用するコンポーネント
このドキュメントの情報は、次のソフトウェアとハードウェアのバージョンに基づいています。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、クリアな(デフォルト)設定で作業を開始しています。本稼働中のネットワークでは、各コマンドによって起こる可能性がある影響を十分確認してください。
背景説明
- ブレードのファームウェアアップグレードで、アップタイムポリシーの再起動後にサーバがダウンしました。
- データセンター内の電力イベント
上記が問題の原因である可能性があります。
問題
このエラーメッセージは、リブート時または検出時に発生します。
「ブレードの電源状態を変更できない」
UCSMは、電源オンに失敗したブレードに対してこのアラートを報告します
ファームウェアのアップグレードまたはその他のメンテナンスの一環としてブレードがリブートした場合、FSMで次のメッセージが表示されて検出/起動に失敗します。
「Unable to change server power state-MC Error(-20): Management controller cannot or failed in processing request(sam:dme:ComputePhysicalTurnup:Execute)」
SELログには、次のようなエラーエントリが表示されます。
CIMC | プラットフォームアラートPOWER_ON_FAIL #0xde | 予測障害のデアサート | デアサート
CIMC | プラットフォームアラートPOWER_ON_FAIL #0xde | プレディクティブ障害のアサート | アサート
トラブルシュート
UCSM CLIシェルからブレードのcimcに接続し、power コマンドを使用してブレードの電源ステータスを確認します
- ssh FI-IP-ADDRを設定します。
- cimc Xの接続
- 電力
Failure Scenario # 1
OP:[ status ]
Power-State: [ on ]
VDD-Power-Good: [ inactive ]
Power-On-Fail: [ active ]
Power-Ctrl-Lock: [ unlocked ]
Power-System-Status: [ Good ]
Front-Panel Power Button: [ Enabled ]
Front-Panel Reset Button: [ Enabled ]
OP-CCODE:[ Success ]
Failure Scenario #2
OP:[ status ]
Power-State: [ off ]
VDD-Power-Good: [ inactive ]
Power-On-Fail: [ inactive ]
Power-Ctrl-Lock: [ permanent lock ] <<<----------------
Power-System-Status: [ Bad ] <<<---------------
Front-Panel Power Button: [ Disabled ]
Front-Panel Reset Button: [ Disabled ]
OP-CCODE:[ Success ]
稼働シナリオからの出力#
[ help ]# power
OP:[ status ]
Power-State: [ on ]
VDD-Power-Good: [ active ]
Power-On-Fail: [ inactive ]
Power-Ctrl-Lock: [ unlocked ]
Power-System-Status: [ Good ]
Front-Panel Power Button: [ Enabled ]
Front-Panel Reset Button: [ Enabled ]
OP-CCODE:[ Success ]
[ power ]#
センサーの値#
電源投入時の障害 | ディスク – > | 離散的 | 0x0200 | na | na | na | na | na | na | >>>動作しない
センサー値#
電源投入時の障害 | ディスク – > | 離散的 | 0x0100 | na | na | na | na | na | na | >>>>稼働中
sensorsコマンドを実行し、電力および電圧センサーの値を確認します。同じモデルのブレードが電源オン状態である場合の出力と比較してください。
特定のセンサーのReading列またはStatus列がNAの場合は、常にハードウェア障害が発生しているとは限りません。
ログのスニペット#
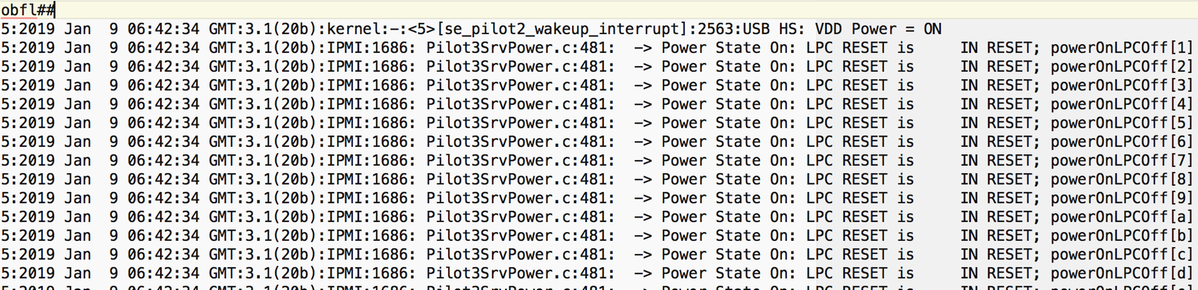
Sel.log番号
CIMC | プラットフォームアラートPOWER_ON_FAIL #0xde | プレディクティブ障害のアサート | アサート
power-on-fail.hist(tmp/techsupport_pidXXXX/CIMCX_TechSupport-nvram.tar.gz内)
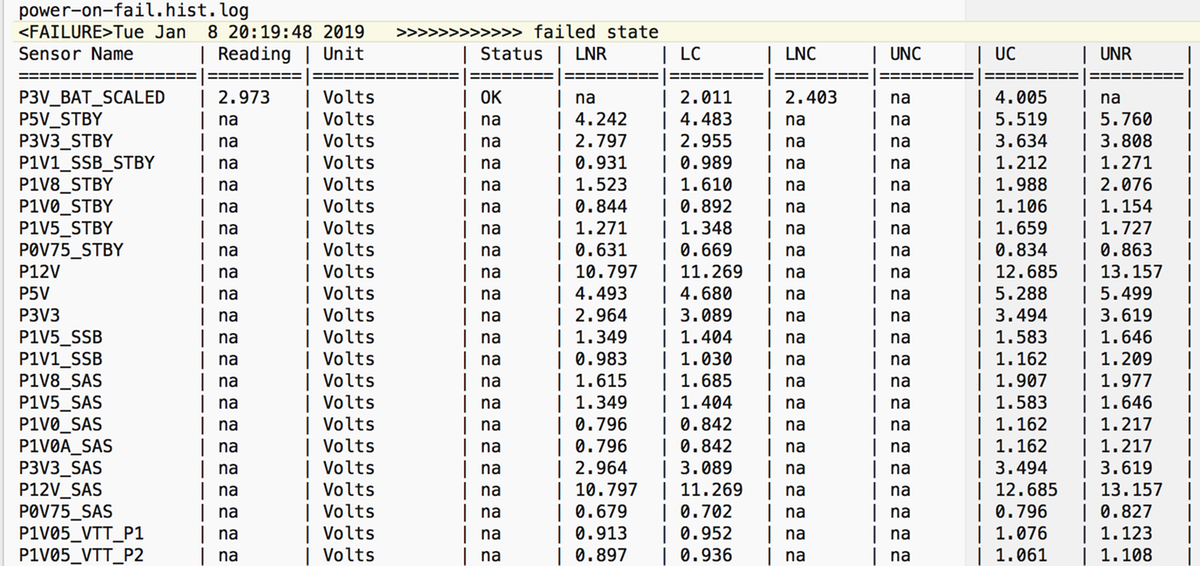
上記の手順で解決できない場合は、次のステップとして、UCSMとシャーシのtechsupportログバンドルを収集します。
問題をさらに調査するのに役立ちます。
前述の症状がある場合は、次の手順を実行して問題を解決してください。
ステップ1:ブレードFSMのステータスが「Failed」で、説明が「state-MC Error(-20)」であることを確認します。
Equipment > Chassis X > Server Y > FSMの順に移動します。

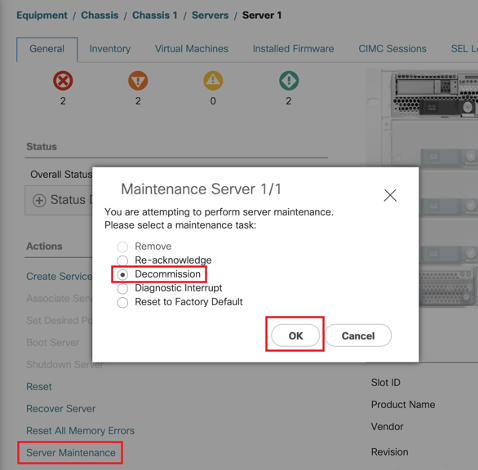
ステップ2:影響を受けるブレードのシリアル番号をメモし、ブレードを使用停止にします。
<<< IMP:廃棄する前に、Generalタブで問題のブレードのシリアル番号を書き留めます。これは、手順4の後半で必要になります>>
Equipment > Chassis X > Server Y > General > Server Maintenance > Decommission > Okの順に移動します。
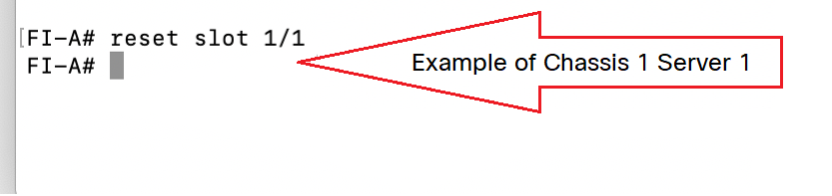
ステップ 3:FI-A/B# reset slot x/y
たとえば、#Chassis2-Server 1が影響を受けます。
FI-A# reset slot 2/1
上記のコマンドを実行した後、30 ~ 40秒待ちます
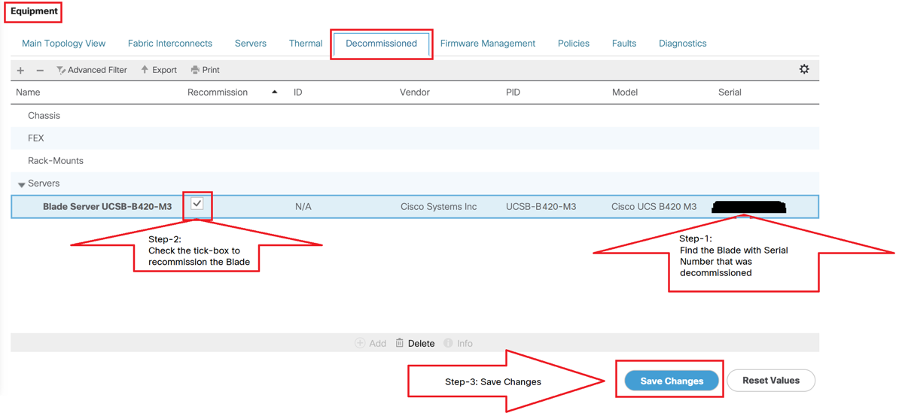
ステップ4:使用停止になったブレードを再コミットします。
Equipment > Decommissioned > Servers > Look for the server we decommissioned(Find correct blade with Serial number Noted in Step-2 before decommissioned) > Check Recommission Tick box against correct Blade(Validate with Serial number) > Save Changesの順に移動します。
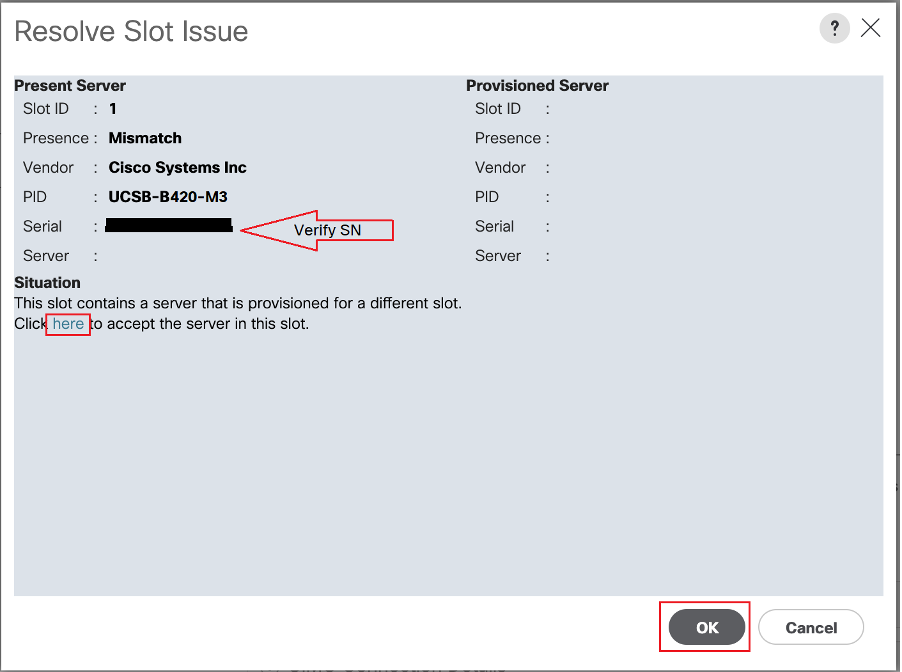
ステップ5:スロットを解決します(確認された場合)。
Equipment > Chassis X > Server Yの順に移動します。
推奨したブレードの「スロットの問題の解決」ポップアップが表示されたら、そのシリアル番号を確認し、「ここ」をクリックしてスロット内のサーバを受け入れます。
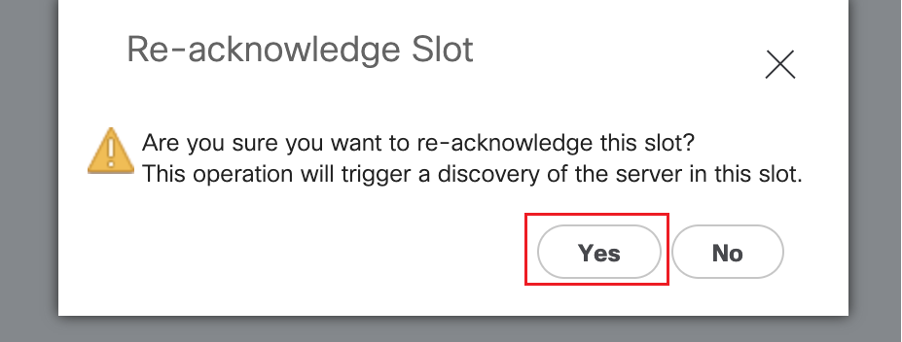
ブレードの検出を今すぐ開始します。
サーバ検出が完了するまで待ちます。Server FSMタブで進行状況を監視します。
手順 6:ステップ1 ~ 5が役に立たず、FSMが再び失敗する場合は、ブレードを取り外し、物理的に再装着します。
それでもサーバが検出できない場合は、ハードウェアの問題であればCisco TACに問い合せてください。
NOTE: If you have B200 M4 blade and notice failure scenario #2 , please refer following bug and Contact TAC
CSCuv90289
B200 M4 fails to power on due to POWER_SYS_FLT
関連情報
シャーシの検出手順
UCSMサーバ管理ガイド
 フィードバック
フィードバック