FMCの未処理イベントのドレインとイベントの頻繁なドレインのトラブルシューティング:ヘルスモニタアラート
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
はじめに
このドキュメントでは、Firepower Management Center(FMC)で未処理のイベントのドレインおよびイベントの頻繁なドレインのヘルスアラートをトラブルシューティングする方法について説明します。
問題の概要
Firepower Management Center(FMC)は、次のいずれかのヘルスアラートを生成します。
- 優先順位の低い統合イベントの頻繁な枯渇
- 優先順位の低い統合イベントからの未処理イベントの排出
これらのイベントは生成されてFMCに表示されますが、Firepower Threat Defense(FTD)デバイスでも次世代侵入防御システム(NGIPS)デバイスでも、管理対象デバイスセンサーに関連するものです。これ以降、このドキュメントでは、特に指定のない限り、センサーという用語はFTDとNGIPSの両方のデバイスを指します。
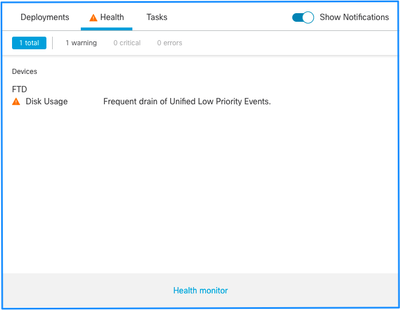
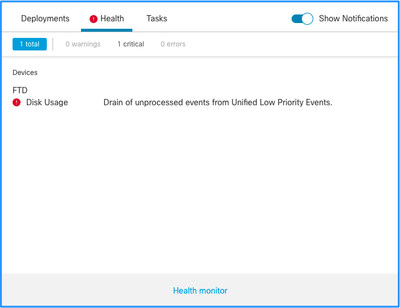
ヘルスアラートの構造を次に示します。
- <サイロ名>の頻繁なドレイン
- 未処理のイベントを<SILO NAME>からドレイン
この例では、SILO NAMEはUnified Low Priority Eventsです。これは、ディスクマネージャのサイロの1つです(より包括的な説明については、「背景説明」のセクションを参照してください)。
その他:
- どのサイロでも<SILO NAME> healthアラートの頻繁なドレインを技術的に生成できますが、最も一般的に見られるのはイベントに関連するイベントで、その中でも優先度の低いイベントは、単にこれらがセンサーによってより頻繁に生成されるタイプのイベントであるためです。
- <SILO NAME>イベントの頻繁なドレインは、イベント関連のサイロの場合はWarningの重大度になります。これは、これが処理された場合(未処理のイベントを構成する説明が次に示される)は、FMCデータベース内にあるためです。
- Backupsサイロなどのイベントに関連しないサイロでは、この情報が失われるため、アラートはCriticalです。
- イベント・タイプ・サイロのみが<SILO NAME>のヘルス・アラートから未処理のイベントのドレインを生成します。このアラートの重大度は常にCriticalです。
その他の症状には次のものがあります。
- FMC UIの速度低下
- イベントの損失
一般的なトラブルシューティングシナリオ
<SILO NAME>イベントの頻繁なドレインは、サイロサイズに対してサイロへの入力が多すぎることが原因で発生します。この場合、ディスク・マネージャは、最後の5分インターバルの間に少なくとも2回、そのファイルを排出(パージ)します。イベントタイプサイロでは、これは通常、そのイベントタイプの過剰なロギングが原因で発生します。<SILO NAME>のヘルスアラートの未処理イベントのドレインの場合は、イベント処理パスのボトルネックが原因である可能性もあります。
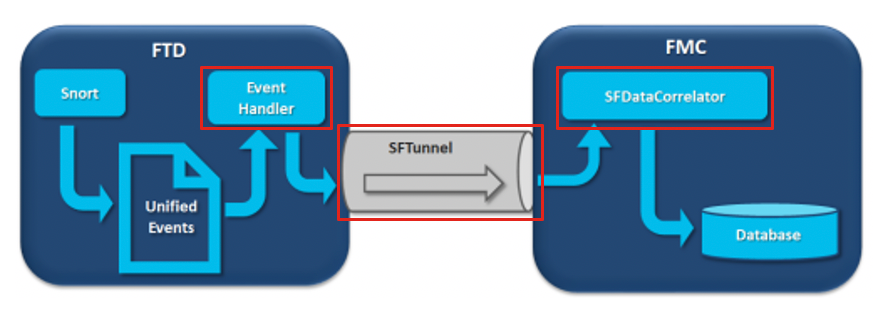
この図では、3つの潜在的なボトルネックがあります。
- FTDのEventHandlerプロセスがオーバーサブスクライブされている(読み取りがSnortの書き込みより遅い)。
- イベントインターフェイスがオーバーサブスクライブです。
- FMCのSFDataCorrelatorプロセスがオーバーサブスクライブされている
イベント処理アーキテクチャについて詳しく理解するには、それぞれの詳細セクションを参照してください。
Case 1.過剰なロギング
前のセクションで説明したように、このタイプのヘルスアラートの最も一般的な原因の1つは過剰な入力です。
show disk-manager CLISHコマンドで収集されたLow Water Mark(LWM)とHigh Water Mark(HWM)の違いは、LWM(新たに排水)からHWM値に移行するために、そのサイロ上でどのくらいのスペースが必要であるかを示します。イベントのドレインが頻繁に発生する場合(未処理のイベントがある場合とない場合がある)、最初に確認する必要があるのは、ロギング設定です。
ディスクマネージャのプロセスの詳細については、それぞれの「ディープダイブ」のセクションを参照してください。
二重ロギングであっても、マネージャセンサーのエコシステム全体でのイベントの発生率が高いだけであっても、ロギング設定のレビューを行う必要があります。
推奨される対処法
ステップ 1:二重ロギングを確認します。
二重ロギングシナリオは、次の出力に示すように、FMCの相関器perfstatsを確認すると識別できます。
admin@FMC:~$ sudo perfstats -Cq < /var/sf/rna/correlator-stats/now
129 statistics lines read
host limit: 50000 0 50000
pcnt host limit in use: 0.01 0.01 0.01
rna events/second: 0.00 0.00 0.06
user cpu time: 0.48 0.21 10.09
system cpu time: 0.47 0.00 8.83
memory usage: 2547304 0 2547304
resident memory usage: 28201 0 49736
rna flows/second: 126.41 0.00 3844.16
rna dup flows/second: 69.71 0.00 2181.81
ids alerts/second: 0.00 0.00 0.00
ids packets/second: 0.00 0.00 0.00
ids comm records/second: 0.02 0.01 0.03
ids extras/second: 0.00 0.00 0.00
fw_stats/second: 0.00 0.00 0.03
user logins/second: 0.00 0.00 0.00
file events/second: 0.00 0.00 0.00
malware events/second: 0.00 0.00 0.00
fireamp events/second: 0.00 0.00 0.00
この場合、重複したフローの高いレートが出力に表示される可能性があります。
ステップ 2:ACPのロギング設定を確認します。
まず、アクセスコントロールポリシー(ACP)のロギング設定を確認する必要があります。このドキュメント『接続ロギングのベストプラクティス』に記載されているベストプラクティスを使用していることを確認します。
リストされている推奨事項は単にロギングの重複のシナリオをカバーしているわけではないため、どのような状況でもロギング設定を確認することをお勧めします。
FTDで生成されたイベントのレートを確認するには、次のファイルをチェックし、TotalEvents列とPerSec列に注目します。
admin@firepower:/ngfw/var/log$ sudo more EventHandlerStats.2023-08-13 | grep Total | more
{"Time": "2023-08-13T00:03:37Z", "TotalEvents": 298, "PerSec": 0, "UserCPUSec": 0.995, "SysCPUSec": 4.598, "%CPU": 1.9, "MemoryKB": 33676}
{"Time": "2023-08-13T00:08:37Z", "TotalEvents": 298, "PerSec": 0, "UserCPUSec": 1.156, "SysCPUSec": 4.280, "%CPU": 1.8, "MemoryKB": 33676}
{"Time": "2023-08-13T00:13:37Z", "TotalEvents": 320, "PerSec": 1, "UserCPUSec": 1.238, "SysCPUSec": 4.221, "%CPU": 1.8, "MemoryKB": 33676}
{"Time": "2023-08-13T00:18:37Z", "TotalEvents": 312, "PerSec": 1, "UserCPUSec": 1.008, "SysCPUSec": 4.427, "%CPU": 1.8, "MemoryKB": 33676}
{"Time": "2023-08-13T00:23:37Z", "TotalEvents": 320, "PerSec": 1, "UserCPUSec": 0.977, "SysCPUSec": 4.465, "%CPU": 1.8, "MemoryKB": 33676}
{"Time": "2023-08-13T00:28:37Z", "TotalEvents": 299, "PerSec": 0, "UserCPUSec": 1.066, "SysCPUSec": 4.361, "%CPU": 1.8, "MemoryKB": 33676}
ステップ 3: 過剰なロギングが予想されるかどうかを確認します。
過度のロギングが予想される原因であるかどうかを確認する必要があります。過剰なロギングがDOS/DDoS攻撃やルーティングループ、または膨大な数の接続を行う特定のアプリケーション/ホストによって引き起こされている場合は、予期しない過剰な接続ソースからの接続をチェックして緩和/停止する必要があります。
ステップ 4: 破損したdiskmanager.logファイルがないか確認します。
通常、1つのエントリは12個のカンマ区切り値を持つことができます。フィールドの数が異なる破損した行を確認するには、次の手順を実行します。
admin@firepower:/ngfw/var/log$ sudo cat diskmanager.log | awk -F',' 'NF != 12 {print}'
admin@firepower:/ngfw/var/log$
12個のフィールド以外の破損した行がある場合は表示されます。
ステップ 5:モデルのアップグレード。
FTDハードウェアデバイスを高性能モデル(FPR2100 —> FPR4100など)にアップグレードすると、サイロのソースが増加します。
手順 6:Ramdiskへのログを無効にできるかどうかを検討します。
統合された低優先度イベント(LLI)サイロの場合は、Log to Ramdiskを無効にしてサイロサイズを増やすことができます。これについては、それぞれのディープダイブのセクションで説明します。
Case 2.センサーとFMC間の通信チャネルのボトルネック
このタイプのアラートのもう1つの一般的な原因は、センサーとFMC間の通信チャネル(sftunnel)の接続の問題や不安定さです。通信の問題の原因としては、次のことが考えられます。
- sftunnelがダウンしているか、不安定です(フラップ)。
- sftunnelがオーバーサブスクライブされています。
sftunnel接続の問題に関しては、FMCとセンサーがTCPポート8305の管理インターフェイス間で到達可能であることを確認します。
FTDでは、[/ngfw]/var/log/messagesファイルでsftunneld文字列を検索できます。接続の問題により、次のようなメッセージが生成されます。
Sep 9 15:41:35 firepower SF-IMS[5458]: [27602] sftunneld:sf_ch_util [INFO] Delay for heartbeat reply on channel from 10.62.148.75 for 609 seconds. dropChannel... Sep 9 15:41:35 firepower SF-IMS[5458]: [27602] sftunneld:sf_connections [INFO] Ping Event Channel for 10.62.148.75 failed Sep 9 15:41:35 firepower SF-IMS[5458]: [27602] sftunneld:sf_channel [INFO] >> ChannelState dropChannel peer 10.62.148.75 / channelB / EVENT [ msgSock2 & ssl_context2 ] << Sep 9 15:41:35 firepower SF-IMS[5458]: [27602] sftunneld:sf_channel [INFO] >> ChannelState freeChannel peer 10.62.148.75 / channelB / DROPPED [ msgSock2 & ssl_context2 ] << Sep 9 15:41:35 firepower SF-IMS[5458]: [27602] sftunneld:sf_connections [INFO] Need to send SW version and Published Services to 10.62.148.75 Sep 9 15:41:35 firepower SF-IMS[5458]: [27602] sftunneld:sf_peers [INFO] Confirm RPC service in CONTROL channel Sep 9 15:41:35 firepower SF-IMS[5458]: [27602] sftunneld:sf_channel [INFO] >> ChannelState do_dataio_for_heartbeat peer 10.62.148.75 / channelA / CONTROL [ msgSock & ssl_context ] << Sep 9 15:41:48 firepower SF-IMS[5458]: [5464] sftunneld:tunnsockets [INFO] Started listening on port 8305 IPv4(10.62.148.180) management0 Sep 9 15:41:51 firepower SF-IMS[5458]: [27602] sftunneld:control_services [INFO] Successfully Send Interfaces info to peer 10.62.148.75 over managemen Sep 9 15:41:53 firepower SF-IMS[5458]: [5465] sftunneld:sf_connections [INFO] Start connection to : 10.62.148.75 (wait 10 seconds is up) Sep 9 15:41:53 firepower SF-IMS[5458]: [27061] sftunneld:sf_peers [INFO] Peer 10.62.148.75 needs the second connection Sep 9 15:41:53 firepower SF-IMS[5458]: [27061] sftunneld:sf_ssl [INFO] Interface management0 is configured for events on this Device Sep 9 15:41:53 firepower SF-IMS[5458]: [27061] sftunneld:sf_ssl [INFO] Connect to 10.62.148.75 on port 8305 - management0 Sep 9 15:41:53 firepower SF-IMS[5458]: [27061] sftunneld:sf_ssl [INFO] Initiate IPv4 connection to 10.62.148.75 (via management0) Sep 9 15:41:53 firepower SF-IMS[5458]: [27061] sftunneld:sf_ssl [INFO] Initiating IPv4 connection to 10.62.148.75:8305/tcp Sep 9 15:41:53 firepower SF-IMS[5458]: [27061] sftunneld:sf_ssl [INFO] Wait to connect to 8305 (IPv6): 10.62.148.75
FMC管理インターフェイスのオーバーサブスクリプションは、管理トラフィックのスパイクまたは継続的なオーバーサブスクリプションの可能性があります。ヘルスモニタからの履歴データは、この良い指標です。
最初に注意する点は、ほとんどの場合、FMCは管理用に単一のNICとともに展開されていることです。このインターフェイスは、次の目的で使用されます。
- FMC管理
- FMCセンサー管理
- センサーからのFMCイベント収集
- インテリジェンスフィードの更新
- ソフトウェアダウンロードサイトからのSRU、ソフトウェア、VDB、およびGeoDBの更新のダウンロード
- URLレピュテーションとカテゴリのクエリ(該当する場合)
- ファイルの破棄に関するクエリ(該当する場合)
推奨される対処法
イベント専用インターフェイス用の2つ目のNICをFMCに導入できます。実装はユースケースによって異なります。
一般的なガイドラインについては、『FMC Hardware Guide Deploying on a Management Network』を参照してください。
Case 3.SFDataCorrelatorプロセスのボトルネック
最後に取り上げるシナリオは、SFDataCorrelator側(FMC)でボトルネックが発生した場合です。
最初にdiskmanager.logファイルを調べます。収集すべき重要な情報は次のとおりです。
- ドレインの周波数。
- 未処理のイベントがドレインされたファイルの数です。
-
未処理イベントを含むドレインの発生。
diskmanager.logファイルとその解釈方法については、「ディスクマネージャ」のセクションを参照してください。diskmanager.logから収集した情報を使用して、以降の手順を絞り込むことができます。
さらに、相関器のパフォーマンス統計情報を確認する必要があります。
admin@FMC:~$ sudo perfstats -Cq < /var/sf/rna/correlator-stats/now
129 statistics lines read
host limit: 50000 0 50000 pcnt host limit in use: 100.01 100.00 100.55 rna events/second: 1.78 0.00 48.65 user cpu time: 2.14 0.11 58.20 system cpu time: 1.74 0.00 41.13 memory usage: 5010148 0 5138904 resident memory usage: 757165 0 900792 rna flows/second: 101.90 0.00 3388.23 rna dup flows/second: 0.00 0.00 0.00 ids alerts/second: 0.00 0.00 0.00 ids packets/second: 0.00 0.00 0.00 ids comm records/second: 0.02 0.01 0.03 ids extras/second: 0.00 0.00 0.00 fw_stats/second: 0.01 0.00 0.08 user logins/second: 0.00 0.00 0.00 file events/second: 0.00 0.00 0.00 malware events/second: 0.00 0.00 0.00 fireamp events/second: 0.00 0.00 0.01
これらの統計情報はFMC用のもので、FMCによって管理されるすべてのセンサーの集約に対応します。優先順位の低い統合イベントの場合は、主に次の項目を検索します。
- SFDataCorrelatorプロセスのオーバーサブスクリプションの可能性を評価するための、任意のイベントタイプの1秒あたりの合計フロー数。
- 上記の出力で強調表示されている2つの行は、次のとおりです。
- rna flows/second - SFDataCorrelatorによって処理された優先度の低いイベントの比率を示します。
- rna dup flows/second - SFDataCorrelatorによって処理される、重複した優先順位の低いイベントの割合を示します。これは、前のシナリオで説明した二重ロギングによって生成されます。
この出力から、次のように結論付けられます。
- rna dup flows/second行に示されているように、重複するロギングはありません。
- rna flows/second行では、Maximum値がAverage値よりも大幅に高いため、SFDataCorrelatorプロセスによって処理されるイベントのレートが急上昇しました。これは、ユーザの勤務時間が始まったばかりの早朝を見ると予想されますが、一般的にはレッドフラッグであり、さらに調査が必要です。
SFDataCorrelatorプロセスの詳細については、「イベント処理」セクションを参照してください。
推奨される対処法
最初に、スパイクが発生したタイミングを判断する必要があります。これを行うには、5分の各サンプル間隔ごとの相関統計情報を調べる必要があります。diskmanager.logから収集された情報は、重要な期間に直接移動するのに役立ちます。
ヒント:簡単に検索できるように、出力をLinuxのページャにパイプする手間を減らします。
admin@FMC:~$ sudo perfstats -C < /var/sf/rna/correlator-stats/now
<OUTPUT OMITTED FOR READABILITY>
Wed Sep 9 16:01:35 2020 host limit: 50000 pcnt host limit in use: 100.14 rna events/second: 24.33 user cpu time: 7.34 system cpu time: 5.66 memory usage: 5007832 resident memory usage: 797168 rna flows/second: 638.55 rna dup flows/second: 0.00 ids alerts/second: 0.00 ids pkts/second: 0.00 ids comm records/second: 0.02 ids extras/second: 0.00 fw stats/second: 0.00 user logins/second: 0.00 file events/second: 0.00 malware events/second: 0.00 fireAMP events/second: 0.00 Wed Sep 9 16:06:39 2020 host limit: 50000 pcnt host limit in use: 100.03 rna events/second: 28.69 user cpu time: 16.04 system cpu time: 11.52 memory usage: 5007832 resident memory usage: 801476 rna flows/second: 685.65 rna dup flows/second: 0.00 ids alerts/second: 0.00 ids pkts/second: 0.00 ids comm records/second: 0.01 ids extras/second: 0.00 fw stats/second: 0.00 user logins/second: 0.00 file events/second: 0.00 malware events/second: 0.00 fireAMP events/second: 0.00 Wed Sep 9 16:11:42 2020 host limit: 50000 pcnt host limit in use: 100.01 rna events/second: 47.51 user cpu time: 16.33 system cpu time: 12.64 memory usage: 5007832 resident memory usage: 809528 rna flows/second: 1488.17 rna dup flows/second: 0.00 ids alerts/second: 0.00 ids pkts/second: 0.00 ids comm records/second: 0.02 ids extras/second: 0.00 fw stats/second: 0.01 user logins/second: 0.00 file events/second: 0.00 malware events/second: 0.00 fireAMP events/second: 0.00 Wed Sep 9 16:16:42 2020 host limit: 50000 pcnt host limit in use: 100.00 rna events/second: 8.57 user cpu time: 58.20 system cpu time: 41.13 memory usage: 5007832 resident memory usage: 837732 rna flows/second: 3388.23 rna dup flows/second: 0.00 ids alerts/second: 0.00 ids pkts/second: 0.00 ids comm records/second: 0.01 ids extras/second: 0.00 fw stats/second: 0.03 user logins/second: 0.00 file events/second: 0.00 malware events/second: 0.00 fireAMP events/second: 0.00 197 statistics lines read host limit: 50000 0 50000 pcnt host limit in use: 100.01 100.00 100.55 rna events/second: 1.78 0.00 48.65 user cpu time: 2.14 0.11 58.20 system cpu time: 1.74 0.00 41.13 memory usage: 5010148 0 5138904 resident memory usage: 757165 0 900792 rna flows/second: 101.90 0.00 3388.23 rna dup flows/second: 0.00 0.00 0.00 ids alerts/second: 0.00 0.00 0.00 ids packets/second: 0.00 0.00 0.00 ids comm records/second: 0.02 0.01 0.03 ids extras/second: 0.00 0.00 0.00 fw_stats/second: 0.01 0.00 0.08 user logins/second: 0.00 0.00 0.00 file events/second: 0.00 0.00 0.00 malware events/second: 0.00 0.00 0.00 fireamp events/second: 0.00 0.00 0.01
出力の情報を使用して、次の操作を実行できます。
- イベントの通常/ベースライン率を決定します。
- スパイクが発生した5分インターバルを判別します。
前の例では、16:06:39以降に受信したイベントのレートに明らかな急上昇が見られます。これらは5分間の平均であるため、増加は図に示されている(バースト)よりも急激ですが、この5分間の間隔の最後に始まった場合は薄くなります。
これは、イベントのこのスパイクが未処理イベントのドレインの原因になったと結論付けますが、適切なタイムウィンドウでFMCのグラフィカルユーザインターフェイス(GUI)から接続イベントを調べると、このスパイク内のどの種類の接続がFTDボックスを通過したかを理解できます。
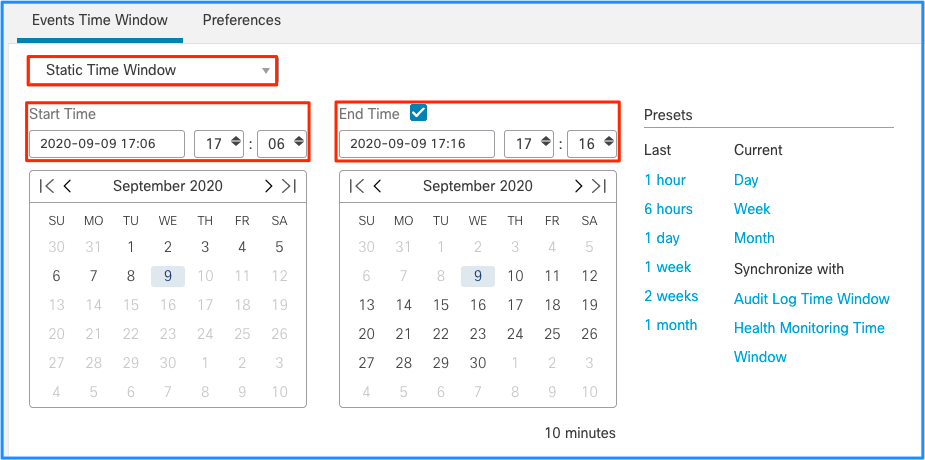
このタイムウィンドウを適用して、フィルタリングされた接続イベントを取得します。タイムゾーンを忘れずに設定してください。この例では、センサーはUTCとFMC UTC+1を使用します。テーブルビューを使用して、イベントの過負荷を引き起こしたイベントを確認し、それに応じたアクションを実行します。
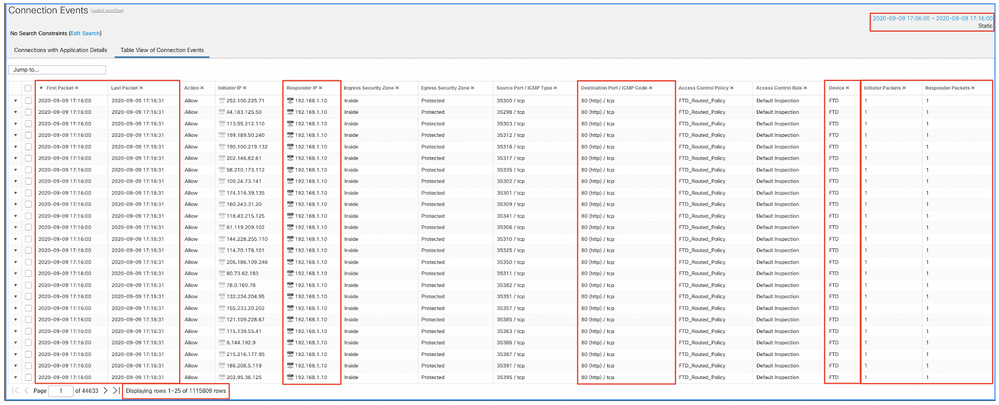
タイムスタンプ(最初と最後のパケットの時間)に基づくと、これらは短期間の接続であることがわかります。さらに、Initiator and Responder Packets列は、各方向で交換されたパケットが1つだけであることを示しています。これにより、接続が短時間で終了し、ほとんどデータが交換されなかったことが確認されます。
また、すべてのフローが同じレスポンダIPとポートを対象としていることを確認できます。また、これらはすべて同じセンサーによって報告されます(入力および出力インターフェイス情報とともに、このフローの場所と方向と通信できます)。その他のアクション:
- 宛先エンドポイントのSyslogを確認します。
- DOS/DDOS保護を実装するか、その他の予防措置を講じます。
注:この記事の目的は、Drain of Unprocessed Eventsアラートをトラブルシューティングするためのガイドラインを提供することです。 この例では、hping3を使用して、宛先サーバへのTCP SYNフラッドを生成しました。FTDデバイスを強化するためのガイドラインについては、『Cisco Firepower Threat Defense強化ガイド』を参照してください。
Cisco Technical Assistance Center(TAC)に問い合わせる前に収集すべき項目
Cisco TACに連絡する前に、次の項目を収集することを強く推奨します。
- 表示されるヘルスアラートのスクリーンショット。
- FMCから生成されたファイルのトラブルシューティングを行います。
- 影響を受けるセンサーから生成されたファイルのトラブルシューティングを行う。
- 問題が最初に発生した日時。
- ポリシーに対して最近行った変更に関する情報(該当する場合)。
- 影響を受けるセンサーのメンションとともに「イベント処理」セクションで説明したstats_unified.plコマンドの出力。
分析 [英語]
このセクションでは、このタイプのヘルスアラートに関与する可能性のあるさまざまなコンポーネントについて詳しく説明します。これには、次のような特徴があります。
- イベント処理:センサーデバイスとFMCの両方でイベントが通るパスをカバーします。これは主に、ヘルスアラートがイベントタイプサイロを参照する場合に役立ちます。
- ディスク・マネージャ:ディスク・マネージャのプロセス、サイロ、およびそれらのドレイン方法について説明します。
- ヘルスモニタ:ヘルスモニタモジュールを使用してヘルスアラートを生成する方法について説明します。
- Log to Ramdisk:RAMディスクへのロギング機能と、その機能がヘルスアラートに与える可能性のある影響について説明します。
イベントの枯渇に関するヘルスアラートを理解し、潜在的な障害ポイントを特定するには、これらのコンポーネントがどのように機能し、相互に作用するかを調べる必要があります。
イベント処理
頻繁な枯渇タイプのヘルスアラートは、イベントに関連しないサイロによってトリガーされる可能性がありますが、Cisco TACで確認されるケースの大部分は、イベント関連情報の枯渇に関連しています。また、未処理のイベントのドレインを構成するものを理解するには、イベント処理アーキテクチャとそれを構成するコンポーネントを調べる必要があります。
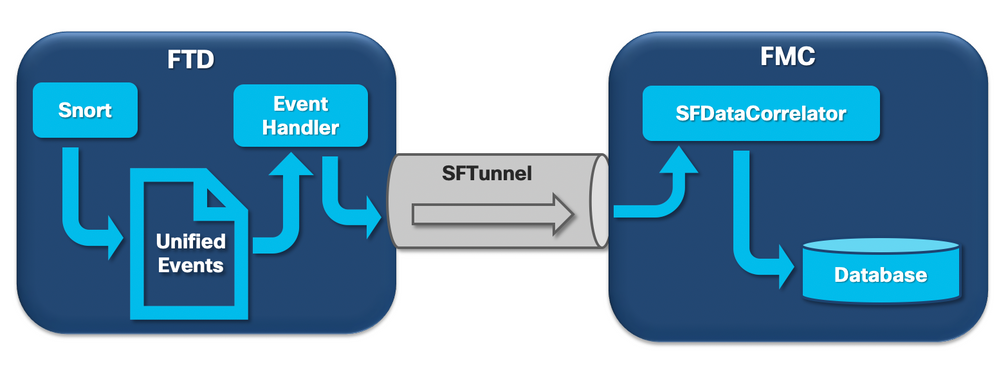
Firepowerセンサーが新しい接続からパケットを受信すると、snortプロセスは、より高速な読み取り/書き込みと軽いイベントを可能にするバイナリ形式であるunified2形式でイベントを生成します。
この出力は、新しく作成された接続を確認できるFTDコマンドsystem support traceを示しています。重要な部分は次のように強調表示され、説明されています。
192.168.0.2-42310 - 192.168.1.10-80 6 AS 1-1 CID 0 Packet: TCP, SYN, seq 3310981951
192.168.0.2-42310 - 192.168.1.10-80 6 AS 1-1 CID 0 Session: new snort session
192.168.0.2-42310 - 192.168.1.10-80 6 AS 1-1 CID 0 AppID: service unknown (0), application unknown (0)
192.168.0.2-42310 > 192.168.1.10-80 6 AS 1-1 I 0 new firewall session
192.168.0.2-42310 > 192.168.1.10-80 6 AS 1-1 I 0 using HW or preset rule order 4, 'Default Inspection', action Allow and prefilter rule 0
192.168.0.2-42310 > 192.168.1.10-80 6 AS 1-1 I 0 HitCount data sent for rule id: 268437505,
192.168.0.2-42310 > 192.168.1.10-80 6 AS 1-1 I 0 allow action
192.168.0.2-42310 - 192.168.1.10-80 6 AS 1-1 CID 0 Firewall: allow rule, 'Default Inspection', allow
192.168.0.2-42310 - 192.168.1.10-80 6 AS 1-1 CID 0 Snort id 0, NAP id 1, IPS id 0, Verdict PASS
Snort unified_eventsファイルは、インスタンスごとにパス[/ngfw]var/sf/detection_engine/*/instance-N/に生成されます。値は次のとおりです。
- *はSnort UUIDです。これはアプライアンスごとに異なります。
- NはSnortのインスタンスIDで、前の出力(この例では強調表示0)のインスタンスIDと1を合わせて計算できます
任意のSnortインスタンスフォルダに、次の2種類のunified_eventsファイルを格納できます。
- unified_events-1(優先度の高いイベントを含む)
- unified_events-2(優先度の低いイベントを含む)
高優先度イベントとは、潜在的に悪意のある接続に対応するイベントです。
イベントのタイプと優先度:
| 高い優先度(1) |
低い優先度(2) |
| 侵入 |
Connection |
| マルウェア |
ディスカバリ |
| セキュリティ インテリジェンス |
ファイル |
| 関連する接続イベント |
統計情報 |
次の出力は、前の例でトレースした新しい接続に属するイベントを示しています。この形式はunified2であり、[/ngfw]/var/sf/detection_engine/*/instance-1/に配置されたそれぞれのユニファイドイベントログの出力から取得されます。ここで、1は上記の出力+1で太字で示されているsnortインスタンスIDです。統一されたイベントログ形式の名前は、unified_events-2.log.1599654750という構文を使用します。ここで、2は表に示すイベントの優先順位を表し、太字(1599654750)の最後の部分はファイルが作成されたときのタイムスタンプ(UNIX時間)です。
ヒント: Linuxのdate コマンドを使用して、Unixの時刻を読み取り可能な日付に変換できます。
admin@FP1120-2:~$ sudo日付-d@1599654750
2020年9月9日(水)14:32:30 CEST
Unified2 Record at offset 2190389
Type: 210(0x000000d2)
Timestamp: 0
Length: 765 bytes
Forward to DC: Yes
FlowStats:
Sensor ID: 0
Service: 676
NetBIOS Domain: <none>
Client App: 909, Version: 1.20.3 (linux-gnu)
Protocol: TCP
Initiator Port: 42310
Responder Port: 80
First Packet: (1599662092) Tue Sep 9 14:34:52 2020
Last Packet: (1599662092) Tue Sep 9 14:34:52 2020
<OUTPUT OMITTED FOR READABILITY>
Initiator: 192.168.0.2
Responder: 192.168.1.10
Original Client: ::
Policy Revision: 00000000-0000-0000-0000-00005f502a92
Rule ID: 268437505
Tunnel Rule ID: 0
Monitor Rule ID: <none>
Rule Action: 2
すべてのunified_eventsファイルの横には、次の2つの重要な値を含むブックマークファイルがあります。
- タイムスタンプは、そのインスタンスと優先度の現在のunified_eventsファイルに対応します。
- unified_eventファイルの最後の読み取りイベントの位置(バイト)。
値は、次の例に示すように、カンマで区切られた順番になっています。
root@FTD:/home/admin# cat /var/sf/detection_engines/d5a4d5d0-6ddf-11ea-b364-2ac815c16717/instance-1/unified_events-2.log.bookmark.1a3d52e6-3e09-11ea-838f-68e7af919059
1599862498, 18754115
これにより、ディスク・マネージャ・プロセスは、どのイベントがすでに処理され(FMCに送信され)、どのイベントが処理されていないかを認識できます。

注:ディスクマネージャは、イベントサイロを排除すると、統合されたイベントファイルを削除します。
サイロの排除に関する詳細については、「ディスクマネージャ」の項を参照してください。
ドレインされた統合ファイルは、次のいずれかに該当する場合、未処理のイベントと見なされます。
- ブックマークのタイムスタンプがファイルの作成時刻より小さい。
- ブックマークのタイムスタンプはファイルの作成時刻と同じであり、ファイル内のバイト単位の位置はサイズよりも小さくなります。
EventHandlerプロセスは、統合ファイルからイベントを読み取り、(メタデータとして)sftunnel経由でFMCにストリーミングします。sftunnelは、センサーとFMC間の暗号化された通信を担当するプロセスです。これはTCPベースの接続であるため、イベントストリーミングはFMCによって確認応答されます
これらのメッセージは、[/ngfw]/var/log/messagesファイルで確認できます。
sfpreproc:OutputFile [INFO] *** Opening /ngfw/var/sf/detection_engines/77d31ce2-c2fc-11ea-b470-d428d53ed3ae/instance-1/unified_events-2.log.1597810478 for output" in /var/log/messages
EventHandler:SpoolIterator [INFO] Opened unified event file /var/sf/detection_engines/77d31ce2-c2fc-11ea-b470-d428d53ed3ae/instance-1/unified_events-2.log.1597810478
sftunneld:FileUtils [INFO] Processed 10334 events from log file var/sf/detection_engines/77d31ce2-c2fc-11ea-b470-d428d53ed3ae/instance-1/unified_events-2.log.1597810478
この出力は次の情報を提供します。
- Snortは出力用にunified_eventsファイルを開きました(書き込み用)。
- イベントハンドラは、同じunified_eventsファイルを開きました(このファイルから読み取るため)。
- sftunnelは、そのunified_eventsファイルから処理されたイベントの数を報告しました。
その後、それに応じてブックマークファイルが更新されます。sftunnelは、高優先度イベントと低優先度イベントにそれぞれユニファイドイベント(UE)チャネル0および1と呼ばれる2つの異なるチャネルを使用します。
FTDのsfunnel_status CLIコマンドを使用すると、ストリームされたイベントの数を確認できます。
Priority UE Channel 1 service
TOTAL TRANSMITTED MESSAGES <530541> for UE Channel service
RECEIVED MESSAGES <424712> for UE Channel service
SEND MESSAGES <105829> for UE Channel service
FAILED MESSAGES <0> for UE Channel service
HALT REQUEST SEND COUNTER <17332> for UE Channel service
STORED MESSAGES for UE Channel service (service 0/peer 0)
STATE <Process messages> for UE Channel service
REQUESTED FOR REMOTE <Process messages> for UE Channel service
REQUESTED FROM REMOTE <Process messages> for UE Channel service
FMCでは、イベントはSFDataCorrelatorプロセスによって受信されます。
各センサーで処理されたイベントのステータスは、stats_unified.plコマンドで表示できます。
admin@FMC:~$ sudo stats_unified.pl
Current Time - Fri Sep 9 23:00:47 UTC 2020
**********************************************************************************
* FTD - 60a0526e-6ddf-11ea-99fa-89a415c16717, version 6.6.0.1
**********************************************************************************
Channel Backlog Statistics (unified_event_backlog)
Chan Last Time Bookmark Time Bytes Behind
0 2020-09-09 23:00:30 2020-09-07 10:41:50 0
1 2020-09-09 23:00:30 2020-09-09 22:14:58 6960
このコマンドは、チャネルごとの特定のデバイスのイベントのバックログのステータスを表示します。使用されるチャネルIDはsftunnelと同じです。
Bytes Behind値は、統合イベントブックマークファイルに表示される位置と統合イベントファイルのサイズの差、およびブックマークファイルよりもタイムスタンプの高い後続ファイルの差として計算できます。
SFDataCorrelatorプロセスは、パフォーマンス統計情報も保存します。これらの統計情報は、/var/sf/rna/correlator-stats/に保存されます。1日に1つのファイルが作成され、その日のパフォーマンス統計情報がCSV形式で保存されます。ファイルの名前はYYYY-MM-DDの形式を使用し、現在の日付に対応するファイルが呼び出されます。
統計情報は5分ごとに収集されます(5分インターバルごとに1行ずつ存在します)。
このファイルの出力は、perfstatsコマンドで読み取ることができます。
注:このコマンドは、Snortパフォーマンス統計情報ファイルの読み取りにも使用されるため、適切なフラグを使用する必要があります。
-C:perfstatsに、入力が相関統計ファイルであることを指示します(このフラグがないと、perfstatsは入力がSnortパフォーマンス統計ファイルであると仮定します)。
-q: Quietモードで、ファイルの概要だけを出力します。
admin@FMC:~$ sudo perfstats -Cq < /var/sf/rna/correlator-stats/now
287 statistics lines read
host limit: 50000 0 50000
pcnt host limit in use: 100.01 100.00 100.55
rna events/second: 1.22 0.00 48.65
user cpu time: 1.56 0.11 58.20
system cpu time: 1.31 0.00 41.13
memory usage: 5050384 0 5138904
resident memory usage: 801920 0 901424
rna flows/second: 64.06 0.00 348.15
rna dup flows/second: 0.00 0.00 37.05
ids alerts/second: 1.49 0.00 4.63
ids packets/second: 1.71 0.00 10.10
ids comm records/second: 3.24 0.00 12.63
ids extras/second: 0.01 0.00 0.07
fw_stats/second: 1.78 0.00 5.72
user logins/second: 0.00 0.00 0.00
file events/second: 0.00 0.00 3.25
malware events/second: 0.00 0.00 0.06
fireamp events/second: 0.00 0.00 0.00
サマリーの各行には、平均、最小、最大の3つの値がこの順序で表示されます。
-qフラグを付けずに出力すると、5分の間隔値も表示されます。最後に要約を示します。
注:各FMCには、データシートに記載されている最大フローレートがあります。次の表に、各データシートのモジュールごとの値を示します。
| モデル |
FMC 750 |
FMC 1000 |
FMC 1600 |
FMC 2000 |
FMC 2500 |
FMC 2600 |
FMC 4000 |
FMC 4500 |
FMC 4600 |
FMCv |
FMCv300 |
| 最大流量(fps) |
2000 |
5000 |
5000 |
12000 |
12000 |
12000 |
20,000 |
20,000 |
20,000 |
可変 |
12000 |
注:これらの値は、SFDataCorrelator統計情報の出力で太字で示されているすべてのイベントタイプの集約に使用されます。
出力を見て、最悪のシナリオ(すべての最大値が同時に発生する場合)に備えてFMCのサイズを設定すると、このFMCが認識するイベントのレートは、48.65 + 348.15 + 4.63 + 3.25 + 0.06 = 404.74 fpsになります。
この合計値は、各モデルのデータシートの値と比較できます。
また、SFDataCorrelatorは、受信したイベントに加えて追加の作業(相関ルールなど)を実行し、それらをデータベースに保存します。データベースは、ダッシュボードやイベントビューなど、FMCのグラフィカルユーザインターフェイス(GUI)のさまざまな情報を入力するために照会されます。
ディスクマネージャ
次の論理ダイアグラムは、ディスク関連のヘルスアラートを生成するためにHealth MonitorプロセスとDisk Managerプロセスの両方の論理コンポーネントが相互に関連づけられていることを示しています。
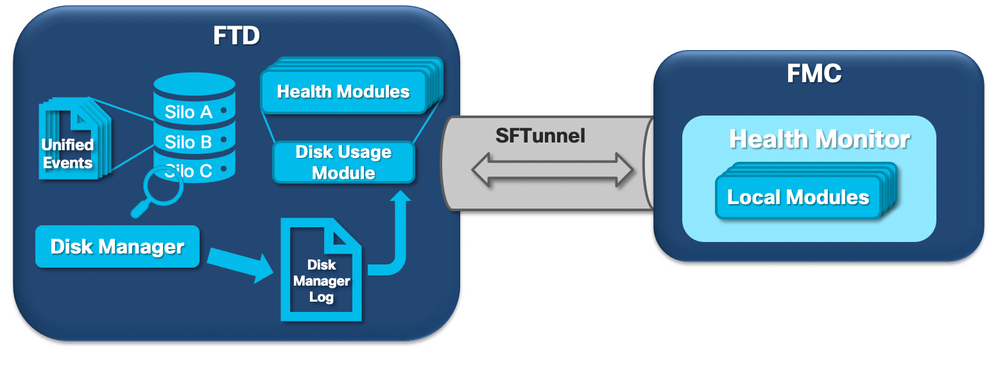
簡単に言えば、ディスクマネージャプロセスはボックスのディスク使用量を管理し、コンフィギュレーションファイルは[/ngfw]/etc/sf/フォルダにあります。ディスクマネージャプロセスには、特定の状況で使用される複数のコンフィギュレーションファイルがあります。
- diskmanager.conf – 標準構成ファイル。
- diskmanager_2hd.conf – ボックスに2つのハードドライブがインストールされている場合に使用します。2番目のハードドライブは、ファイルポリシーで定義されているようにファイルを保存するために使用されるマルウェア拡張に関連するものです。
- ramdisk-diskmanager.conf - Log to Ramdiskが有効な場合に使用します。詳細については、「Ramdiskへのログの記録」の項を参照してください。
ディスク・マネージャが監視する各タイプのファイルには、サイロが割り当てられます。システムで使用可能なディスク容量に基づいて、ディスクマネージャは各サイロの最高水準点(HWM)と最低水準点(LWM)を計算します。
ディスク・マネージャ・プロセスがサイロから解放されるのは、LWMに達する時点です。イベントはファイルごとにドレインされるため、このしきい値を超える可能性があります。
センサーデバイスのサイロのステータスを確認するには、次のコマンドを使用します。
> show disk-manager Silo Used Minimum Maximum misc_fdm_logs 0 KB 65.208 MB 130.417 MB Temporary Files 0 KB 108.681 MB 434.726 MB Action Queue Results 0 KB 108.681 MB 434.726 MB User Identity Events 0 KB 108.681 MB 434.726 MB UI Caches 4 KB 326.044 MB 652.089 MB Backups 0 KB 869.452 MB 2.123 GB Updates 304.367 MB 1.274 GB 3.184 GB Other Detection Engine 0 KB 652.089 MB 1.274 GB Performance Statistics 45.985 MB 217.362 MB 2.547 GB Other Events 0 KB 434.726 MB 869.452 MB IP Reputation & URL Filtering 0 KB 543.407 MB 1.061 GB arch_debug_file 0 KB 2.123 GB 12.736 GB Archives & Cores & File Logs 0 KB 869.452 MB 4.245 GB Unified Low Priority Events 974.109 MB 1.061 GB 5.307 GB RNA Events 879 KB 869.452 MB 3.396 GB File Capture 0 KB 2.123 GB 4.245 GB Unified High Priority Events 252 KB 3.184 GB 7.429 GB IPS Events 3.023 MB 2.547 GB 6.368 GB
ディスクマネージャプロセスは、次のいずれかの条件が満たされると実行されます。
ディスク・マネージャ・プロセスを実行するたびに、[/ngfw]/var/log/diskmanager.logの下に配置され、CSV形式のデータを持つ独自のログ・ファイルに、異なるサイロのエントリーが生成されます。
次に、diskmanager.logファイルのサンプル行を示します。これは、ユニファイド低優先度イベントのヘルスアラートからの未処理イベントのドレインをトリガーしたセンサーと、それぞれのカラムの内訳から取得されました。
priority_2_events,1599668981,221,4587929508,1132501868,20972020,4596,1586044534,5710966962,1142193392,110,0
| カラム | 値 |
| サイロラベル |
priority_2_events(プライオリティ2_イベント) |
| 排水時間(エポック時間) |
1599668981 |
| 排出されたファイルの数 | 221 |
| 排出されたバイト | 4587929508 |
| ドレイン後のデータの現在のサイズ(バイト) | 1132501868 |
| 排出される最大ファイル(バイト) | 20972020 |
| 排出される最小ファイル(バイト) | 4596 |
| 排出された最も古いファイル(エポック時間) | 1586044534 |
| 高水準点(バイト) | 5710966962 |
| ローウォーターマーク(バイト) | 1142193392 |
| 未処理のイベントが排出されたファイルの数 | 110 |
| Diskmanager状態フラグ | 0 |
この情報は、それぞれのヘルスモニタモジュールによって読み取られ、関連するヘルスアラートがトリガーされます。
サイロを手動で削除
特定のシナリオでは、サイロを手動で削除できます。たとえば、手動でファイルを削除するのではなく、手動でサイロドレインを行ってディスク領域をクリアする場合、ディスクマネージャが保持するファイルと削除するファイルを決定できるという利点があります。ディスクマネージャは、そのサイロの最新ファイルを保持します。
どのサイロでもドレインが可能で、すでに説明したとおりに動作します(データ量がLWMしきい値を下回るまで、ディスクマネージャはデータをドレインします)。コマンドsystem support silo-drainはFTD CLISHモードで使用でき、使用可能なサイロ(名前+数値ID)のリストを提供します。
次に、統合された低優先度イベントのサイロを手動で解放する例を示します。
> show disk-manager Silo Used Minimum Maximum misc_fdm_logs 0 KB 65.213 MB 130.426 MB Temporary Files 0 KB 108.688 MB 434.753 MB Action Queue Results 0 KB 108.688 MB 434.753 MB User Identity Events 0 KB 108.688 MB 434.753 MB UI Caches 4 KB 326.064 MB 652.130 MB Backups 0 KB 869.507 MB 2.123 GB Updates 304.367 MB 1.274 GB 3.184 GB Other Detection Engine 0 KB 652.130 MB 1.274 GB Performance Statistics 1.002 MB 217.376 MB 2.547 GB Other Events 0 KB 434.753 MB 869.507 MB IP Reputation & URL Filtering 0 KB 543.441 MB 1.061 GB arch_debug_file 0 KB 2.123 GB 12.737 GB Archives & Cores & File Logs 0 KB 869.507 MB 4.246 GB Unified Low Priority Events 2.397 GB 1.061 GB 5.307 GB RNA Events 8 KB 869.507 MB 3.397 GB File Capture 0 KB 2.123 GB 4.246 GB Unified High Priority Events 0 KB 3.184 GB 7.430 GB IPS Events 0 KB 2.547 GB 6.368 GB > system support silo-drain Available Silos 1 - misc_fdm_logs 2 - Temporary Files 3 - Action Queue Results 4 - User Identity Events 5 - UI Caches 6 - Backups 7 - Updates 8 - Other Detection Engine 9 - Performance Statistics 10 - Other Events 11 - IP Reputation & URL Filtering 12 - arch_debug_file 13 - Archives & Cores & File Logs 14 - Unified Low Priority Events 15 - RNA Events 16 - File Capture 17 - Unified High Priority Events 18 - IPS Events 0 - Cancel and return Select a Silo to drain: 14 Silo Unified Low Priority Events being drained. > show disk-manager Silo Used Minimum Maximum misc_fdm_logs 0 KB 65.213 MB 130.426 MB Temporary Files 0 KB 108.688 MB 434.753 MB Action Queue Results 0 KB 108.688 MB 434.753 MB User Identity Events 0 KB 108.688 MB 434.753 MB UI Caches 4 KB 326.064 MB 652.130 MB Backups 0 KB 869.507 MB 2.123 GB Updates 304.367 MB 1.274 GB 3.184 GB Other Detection Engine 0 KB 652.130 MB 1.274 GB Performance Statistics 1.002 MB 217.376 MB 2.547 GB Other Events 0 KB 434.753 MB 869.507 MB IP Reputation & URL Filtering 0 KB 543.441 MB 1.061 GB arch_debug_file 0 KB 2.123 GB 12.737 GB Archives & Cores & File Logs 0 KB 869.507 MB 4.246 GB Unified Low Priority Events 1.046 GB 1.061 GB 5.307 GB RNA Events 8 KB 869.507 MB 3.397 GB File Capture 0 KB 2.123 GB 4.246 GB Unified High Priority Events 0 KB 3.184 GB 7.430 GB IPS Events 0 KB 2.547 GB 6.368 GB
ヘルスモニタ
主なポイントは次のとおりです。
- FMCのHealth MonitorメニューまたはMessage CenterのHealthタブに表示されるヘルスアラートは、Health Monitorプロセスによって生成されます。
- このプロセスは、FMCと管理対象センサーの両方についてシステムの健全性を監視し、多数の異なるモジュールで構成されます。
- ヘルスアラートモジュールは、デバイスごとに適用可能なヘルスポリシーで定義されます。
- ヘルスアラートは、FMCによって管理される各センサーで実行できるディスク使用量モジュールによって生成されます。
- FMC上でヘルスモニタプロセスが実行されると(5分に1回、または手動実行がトリガーされると)、ディスク使用量モジュールはdiskmanager.logファイルを調べ、正しい条件が満たされると、それぞれのヘルスアラートがトリガーされます。
Drain of Unprocessed eventsヘルスアラートをトリガーするには、次のすべての条件を満たす必要があります。
- Bytes drainedフィールドが0より大きい(このサイロのデータがドレインされたことを示します)。
- 未処理のイベントが0より大きい状態でドレインされたファイルの数です(これは、ドレインされたデータ内に未処理のイベントがあったことを示します)。
- ドレインの時間は過去1時間以内です。
Frequent Drain of eventsヘルスアラートがトリガーされるには、次の条件が満たされている必要があります。
- diskmanager.logファイルの最後の2つのエントリは、次の操作を行う必要があります。
- Have Bytes drainedフィールドが0より大きい(これは、このサイロのデータがドレインされたことを示します)。
- 間隔は5分未満にしてください。
- このサイロの最後のエントリのドレイン時間は、過去1時間以内です。
ディスク使用率モジュールから収集された結果(および他のモジュールから収集された結果)は、sftunnel経由でFMCに送信されます。sftunnel_statusコマンドを使用して、sftunnel経由で交換されたヘルスイベントのカウンタを確認できます。
TOTAL TRANSMITTED MESSAGES <3544> for Health Events service
RECEIVED MESSAGES <1772> for Health Events service
SEND MESSAGES <1772> for Health Events service
FAILED MESSAGES <0> for Health Events service
HALT REQUEST SEND COUNTER <0> for Health Events service
STORED MESSAGES for Health service (service 0/peer 0)
STATE <Process messages> for Health Events service
REQUESTED FOR REMOTE <Process messages> for Health Events service
REQUESTED FROM REMOTE <Process messages> for Health Events service
RAMディスクへのログ
ほとんどのイベントはディスクに保存されますが、ディスクへのイベントの継続的な書き込みと削除によってSSDが徐々に損傷を受けるのを防ぐために、デバイスはデフォルトでRAMディスクにログを記録するように設定されています。
このシナリオでは、イベントは[/ngfw]/var/sf/detection_engine/*/instance-N/の下には保存されませんが、[/ngfw]/var/sf/detection_engines/*/instance-N/connection/にあります。これは、/dev/shm/instance-N/connectionへのシンボリックリンクです。この場合、イベントは物理メモリではなく仮想メモリに存在します。
admin@FTD4140:~$ ls -la /ngfw/var/sf/detection_engines/b0c4a5a4-de25-11ea-8ec3-4df4ea7207e3/instance-1/connection
lrwxrwxrwx 1 sfsnort sfsnort 30 Sep 9 19:03 /ngfw/var/sf/detection_engines/b0c4a5a4-de25-11ea-8ec3-4df4ea7207e3/instance-1/connection -> /dev/shm/instance-1/connection
デバイスで現在設定されている動作を確認するには、FTD CLISHからコマンドshow log-events-to-ramdiskを実行します。これは、configure log-events-to-ramdisk <enable/disable>:
> show log-events-to-ramdisk
Logging connection events to RAM Disk.
> configure log-events-to-ramdisk
Enable or Disable enable or disable (enable/disable)
警告:configure log-events-to-ramdisk disableコマンドを実行する際に、SnortがD状態(無中断スリープ)のままにならないように(無中断スリープ)FTDで2つの展開を行う必要があります。これにより、トラフィックが停止します。
この動作は、Cisco Bug ID CSCvz53372の不具合に記載されています。最初の展開では、Snortメモリ段階の再評価がスキップされ、SnortがD状態になります。回避策は、ダミーの変更を使用して別の展開を行うことです。
ramdiskにログインする際の主な欠点は、それぞれのサイロに割り当てられるスペースが小さいため、同じ状況ではより頻繁に空き領域が増えることです。次の出力はFPR 4140からのディスクマネージャで、比較のためにramdiskへのログイベントを有効にした場合と無効にした場合があります。
Ramdiskへのログが有効になっている。
> show disk-manager
Silo Used Minimum Maximum
Temporary Files 0 KB 903.803 MB 3.530 GB
Action Queue Results 0 KB 903.803 MB 3.530 GB
User Identity Events 0 KB 903.803 MB 3.530 GB
UI Caches 4 KB 2.648 GB 5.296 GB
Backups 0 KB 7.061 GB 17.652 GB
Updates 305.723 MB 10.591 GB 26.479 GB
Other Detection Engine 0 KB 5.296 GB 10.591 GB
Performance Statistics 19.616 MB 1.765 GB 21.183 GB
Other Events 0 KB 3.530 GB 7.061 GB
IP Reputation & URL Filtering 0 KB 4.413 GB 8.826 GB
arch_debug_file 0 KB 17.652 GB 105.914 GB
Archives & Cores & File Logs 0 KB 7.061 GB 35.305 GB
RNA Events 0 KB 7.061 GB 28.244 GB
File Capture 0 KB 17.652 GB 35.305 GB
Unified High Priority Events 0 KB 17.652 GB 30.892 GB
Connection Events 0 KB 451.698 MB 903.396 MB
IPS Events 0 KB 12.357 GB 26.479 GB
RAMディスクへのログが無効です。
> show disk-manager
Silo Used Minimum Maximum
Temporary Files 0 KB 976.564 MB 3.815 GB
Action Queue Results 0 KB 976.564 MB 3.815 GB
User Identity Events 0 KB 976.564 MB 3.815 GB
UI Caches 4 KB 2.861 GB 5.722 GB
Backups 0 KB 7.629 GB 19.074 GB
Updates 305.723 MB 11.444 GB 28.610 GB
Other Detection Engine 0 KB 5.722 GB 11.444 GB
Performance Statistics 19.616 MB 1.907 GB 22.888 GB
Other Events 0 KB 3.815 GB 7.629 GB
IP Reputation & URL Filtering 0 KB 4.768 GB 9.537 GB
arch_debug_file 0 KB 19.074 GB 114.441 GB
Archives & Cores & File Logs 0 KB 7.629 GB 38.147 GB
Unified Low Priority Events 0 KB 9.537 GB 47.684 GB
RNA Events 0 KB 7.629 GB 30.518 GB
File Capture 0 KB 19.074 GB 38.147 GB
Unified High Priority Events 0 KB 19.074 GB 33.379 GB
IPS Events 0 KB 13.351 GB 28.610 GB
サイロのサイズが小さいほど、イベントにアクセスしてFMCにストリームする速度が速くなります。これは適切な条件下では優れたオプションですが、欠点を考慮する必要があります。
よく寄せられる質問(FAQ)
イベントの枯渇のヘルスアラートは、接続イベントによってのみ生成されますか。
No.
- 頻繁なドレインのアラートは、任意のディスク・マネージャ・サイロで生成できます。
- 未処理イベントのドレインのアラートは、イベント関連の任意のサイロで生成できます。
最も一般的な原因は接続イベントです。
頻繁なドレインのヘルスアラートが表示される場合、Log to Ramdiskを無効にすることは常に推奨されますか。
いいえ。影響を受けるサイロが接続イベントサイロである場合、およびロギング設定をさらに調整できない場合に限り、DOS/DDOSを除く過剰なロギングのシナリオでのみ使用します。
DOS/DDOSが原因で過剰なロギングが発生する場合は、DOS/DDOS保護を実装するか、DOS/DDOS攻撃の発信元を排除します。
デフォルトの機能であるLog to Ramdiskを使用すると、SSDの消耗が減るため、使用することを強くお勧めします。
未処理のイベントを構成するものはどれか?
イベントは個別に未処理としてマークされません。次の場合、ファイルに未処理のイベントがあります。
その作成タイムスタンプは、各ブックマークファイルのタイムスタンプフィールドよりも大きくなります。
または
その作成タイムスタンプは、各ブックマークファイルのtimestampフィールドと同じで、サイズは各ブックマークファイルのBytesフィールドの位置よりも大きくなります。
FMCは特定のセンサーの背後にあるバイト数をどのようにして知りますか。
センサーは、unified_eventsファイルの名前とサイズ、およびブックマークファイルの情報に関するメタデータを送信します。これにより、FMCは次のように背後のバイトを計算するのに十分な情報を取得できます。
現在のunified_eventsファイルサイズ:ブックマークファイルからのBytesフィールド内の位置+各ブックマークファイル内のタイムスタンプよりも高いタイムスタンプを持つすべてのunified_eventsファイルのサイズ。
既知の問題
Bug Search Toolを開いて、次のクエリを使用します。

更新履歴
| 改定 | 発行日 | コメント |
|---|---|---|
3.0 |
03-May-2024 |
「概要」、「PII」、「代替テキスト」、「機械翻訳」、「リンクターゲット」、「フォーマット」が更新されました。 |
1.0 |
25-Sep-2020 |
初版 |
シスコ エンジニア提供
- ジョアオ・デルガドCisco TACエンジニア
- Mikis ZafeiroudisCisco TACエンジニア
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)