ユニキャスト、マルチキャスト、および音声トラフィックが混在する Cisco 12000 シリーズ インターネット ルータでの WRED と MDRR の設定例
内容
概要
このドキュメントでは、「RFC 2309」で説明されている Weighted Random Early Detection(WRED; 重み付けランダム早期検出)用に、Cisco 12000 シリーズ ラインカードをマルチサービス環境で設定する方法を説明します。 ![]()
前提条件
要件
この文書を読むには、次の知識が必要です。
使用するコンポーネント
この文書の情報は、次のソフトウェアとハードウェアのバージョンに基づいています。
-
Cisco 12000 シリーズ インターネット ルータをサポートするすべての Cisco IOS® ソフトウェア リリース。通常は、12.0S および 12.0ST リリースです。
-
この文書では Cisco 12000 プラットフォームのすべてを対象としています。12008、12012、12016、12404、12406、12410、および 12416 が含まれます。
このドキュメントの情報は、特定のラボ環境にあるデバイスに基づいて作成されました。このドキュメントで使用するすべてのデバイスは、初期(デフォルト)設定の状態から起動しています。対象のネットワークが実稼働中である場合には、どのようなコマンドについても、その潜在的な影響について確実に理解しておく必要があります。
表記法
ドキュメント表記の詳細は、『シスコ テクニカル ティップスの表記法』を参照してください。
背景説明
Cisco 12000 シリーズは、広帯域 IP コア ネットワークを構築する最も一般的なプラットフォームです。このプラットフォームを使用すると、他にはない方法で Quality of Service(QoS)を設定できます。
さまざまな IP トラフィック(Voice over IP(VoIP)やマルチキャストなど)が同じネットワークに混在することがさらに一般的になってきているため、プライオリティ設定とドロップ動作の制御に対する要件が非常に重要になり、多くの場合、それらの要件は、VoIP などの新しいサービスを開始するときの成功と失敗を左右します。
さまざまなタイプの IP トラフィックのネットワーク要件は、このドキュメントの対象外です。このドキュメントでは、Cisco 12000 シリーズ、3 ポート ギガビット イーサネット(3 ポート GbE)ラインカードなど、異なるラインカードに適用可能な設定を調べるために行われたラボ テストに焦点を当てます。これらのテストによって、音声、データ、マルチキャスト トラフィックが混在するネットワーク環境には、3 ポート GbE エンジン 2 ラインカードが適切であるという結果が示されました。また、輻輳のあるネットワークでの QoS 設定の効果が証明されました。
テストで使用される優先クラス
異なるクラスに割り当てられている優先値は、ネットワーク全体で同じにする必要があります。全般的なポリシーを決定する必要があります。
| クラス | 優先度 | トラフィック |
|---|---|---|
| 悪意のあるトラフィック | 身元が分からないすべてのオフ ネット トラフィック(オフ ネット) | |
| オン ネット --- オン ネット | 1 | SP ネットワーク内でやり取りされるトラフィック(オン ネット) |
| インターネット サービス プロバイダー(ISP)サービス | 0 | ISP トラフィック、SMTP、POP、FTP、DNS、Telnet、SSH、www、https |
| 中小規模のエンタープライズ(SME) | 3 | エンタープライズのお客様、ゴールド サービス |
| リアルタイム、音声以外 | 4 | TV、リアルタイム ゲーム |
| 音声 | 5 | RTP VoIP トラフィック |
| ネットワーク制御メッセージ | 6-7 | ボーダーゲートウェイ プロトコル(BGP)およびその他の制御メッセージ |
IP パケットのカラーリング
ネットワークのコアに QoS を実装する場合、ネットワーク内で転送されるすべての IP パケットの優先値をサービス プロバイダーが制御することが前提条件です。これを行う唯一の方法は、パケットがネットワークに送信されたときにすべてのパケットをマーキングして、お客様、エンド ユーザ、インターネットなど、そのパケットの送信元を区別しないようにすることです。コアでマーキングやカラーリングを行わないでください。
期待される結果
この設計の目的は、クラス0 ~ 3で真のWRED動作を行うことです。つまり、輻輳中に優先順位0のパケットが廃棄され始める状況を望んでいます。その後、輻輳が続く場合は優先順位1のドロップを開始し、次に優先順位2と3のドロップを開始します。これらはすべて次のグラフで説明されています。
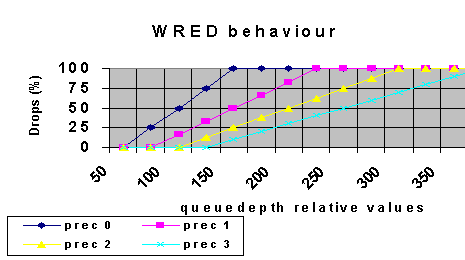
音声パケットの遅延は最も小さくなるようにし、すべての音声とマルチキャスト トラフィックではドロップが発生しないようにしてください。
ネットワークのセットアップ
設定のテストと検証には、Cisco 12410 および Agilant から生成されたパケットが使用されました。Cisco 12000 ルータは、Cisco IOS ソフトウェア リリース 12.0(21)S1 ベースのエンジニアリング リリースを実行しています。
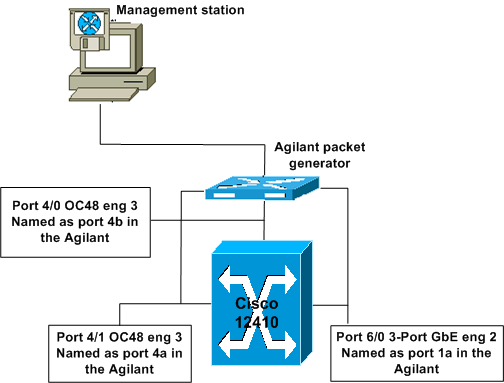
3 ポート GbE エンジン 2 キューイングの実装
通常、エンジン 2 カードには、宛先スロットにつき 8 つの fromfab キューと 1 つの低遅延キュー、および 8 つの tofab キューがあります。また、個別の tofab マルチキャスト キューが 1 つあります。3 ポート GbE カードでは、物理ポートにつき fromfab キューが 1 つだけがあります。このテストに適用した設定では、これ以上のキューが指定されました。結果として、3 ポート GbE カードではこの設定を使用でき、キューは利用可能なキューに自動的にマッピングされました。
Cisco IOS ソフトウェアのエンジン 2 WRED アルゴリズム
キューの深さの最小値と最大値を設定するときには、エンジン 2 ラインカードの WRED に使用されるアルゴリズムを熟知している必要があります。設定されている最小値をコードが認識することはありません。その代わり、コードは(設定された最大値に基づく)独自の計算式を使用して、最小値を設定します。
計算式:
最小値 = 最大値 -(負の結果にならない 2 の最大出力)
このテストで使用された値は、Application-Specific Integrated Circuit(ASIC; 特定用途向け集積回路)にプログラムされている次の最小値になりました。
| 優先度 | 設定されている最小値 | 設定されている最大値 | 2 の最大出力 | ASIC の最小値 |
|---|---|---|---|---|
| 0 | 50 | 5000 | 4096 | 5000-4096 = 904 |
| 1 | 60 | 6000 | 4096 | 6000-4096 = 1904 |
| 0 | 70 | 7000 | 4096 | 7000-4096 = 2904 |
| 3 | 80 | 8000 | 4096 | 8000-4096 = 3904 |
この計算式を使用して最小値を計算する場合、WRED パラメータを設定するときにこの点を考慮しないと、パケット処理動作が不正確になります。次の例を参照してください。
| 優先度 | 設定されている最小値 | 設定されている最大値 | 2 の最大出力 | ASIC の最小値 |
|---|---|---|---|---|
| 0 | 50 | 150 | 128 | 150-128 = 22 |
| 1 | 75 | 225 | 128 | 225-128 = 97 |
| 0 | 100 | 300 | 256 | 300-256 = 44 |
| 3 | 125 | 375 | 256 | 375-256 = 119 |
つまり、ルール0、1、2、および最後の3(上)に従って値の廃棄を開始するように設定されている場合でも、ASICに書き込まれた場合は、優先順位0、優先順位2、優先順位1、優先順位3の廃棄が実際に開始されます。エンジン 3 カードにこの設定を適用する場合、設定に表示される値は実際の値(再計算された最小値)です。
QoS 設定
QoS 設定の詳細は、『Cisco 12000 シリーズ インターネット ルータでの MDRR および WRED の理解と設定』を参照してください。
Rx CoS
rx-cos-slot 2 B2-Table rx-cos-slot 3 B2-Table rx-cos-slot 6 B2-Table
ほとんどの場合、rx-cos-slot all コマンドを使用できます。このテスト ケースでは、一部に tofab キューイングをサポートしないカードを使用したため、常に rx-cos-slot all コマンドを使用できたわけではありませんでした。その代わり、テストに使用されるラインカードにスロット テーブルを割り当てました。
! slot-table-cos B2-Table destination-slot all B2 multicast B2 !--- If you don't fulfill the steps above, you will not be able to reach the goal of 0 drops for Multicast traffic. With no rx-cos configured, multicast will be treated in the default queue, meaning it will drop as soon as there is congestion. !
Tx QoS
tx-cos を設定できるようになりました。「cos-queue-group B2」など、tx qos の名前を選択します。
ドロップ動作を設定する各優先値は、個別の random-detect-label にマップする必要があります。
precedence 0 random-detect-label 0 precedence 1 random-detect-label 1 precedence 2 random-detect-label 2 precedence 3 random-detect-label 3
Modified Deficit Round Robin(MDRR; 欠陥修正ラウンド ロビン)では、各優先度を MDRR キューにマップします。この例では、ビデオ(マルチキャスト トラフィック)の帯域を予約するために、優先度 0 ~ 3 を同じ MDRR キューにマップしました。 このマッピングにより、目的のとおりに動作するようになります。
precedence 0 queue 0 precedence 1 queue 0 precedence 2 queue 0 precedence 3 queue 0 precedence 4 queue 4
音声は優先度 5 とマークされます。そのため、優先度 5 は低遅延キューにマップされています。
precedence 5 queue low-latency precedence 6 queue 6 precedence 7 queue 6
次に、各 random-detect-label のドロップ動作を設定する必要があります。テスト中、目的のドロップ パターンを実行する値が見つかるまで、これらの数字を変更していきました。詳細は、「予想される結果」のセクションを参照してください。キューの深さは、物理キューで計測され、MDRR や RED-Label キューでは計測されません。
random-detect-label 0 50 5000 1 random-detect-label 1 60 6000 1 random-detect-label 2 70 7000 1 random-detect-label 3 80 8000 1
Cisco 12000 では、作成する Class-Based, Weighted Fair Queuing(CBWFQ; クラスベース重み付け均等化キューイング)の動作の MDRR キューに異なる重み付けを設定できます。デフォルトの重み付けは、キューにつき 10 です。MDRR サイクルごとに送信されるバイト数は、重み値の関数です。1 の値は各サイクル 1500 バイトを表します。10 の値は各サイクル 1500+(9*512) バイトを表します。
queue 0 20 queue 4 20 queue 6 20 !
インターフェイス マッピング
WRED には各インターフェイスを設定する必要があります。設定するには、次のコマンドを使用します。
-
configure terminal
-
interface gig 6/0
-
tx-cos B2
ドロップなしの開始
生成されたストリームでは、他の値が示されない限り、次の値が使用されます。
MTU all three data streams 300byte, MTU voice 80byte, MTU MC 1500byte 126Mb MC, 114Mb voip
これにより、バックグラウンド ストリームは 240 Mb(VoIP とマルチキャスト)になります。
次に、同じサイズのデータ ストリームを 4 つ追加し、優先度 0 ~ 3(ストリームにつき 1 つの優先値)を設定します。
1 つあたり 151 Mb のデータ ストリームが 4 つ
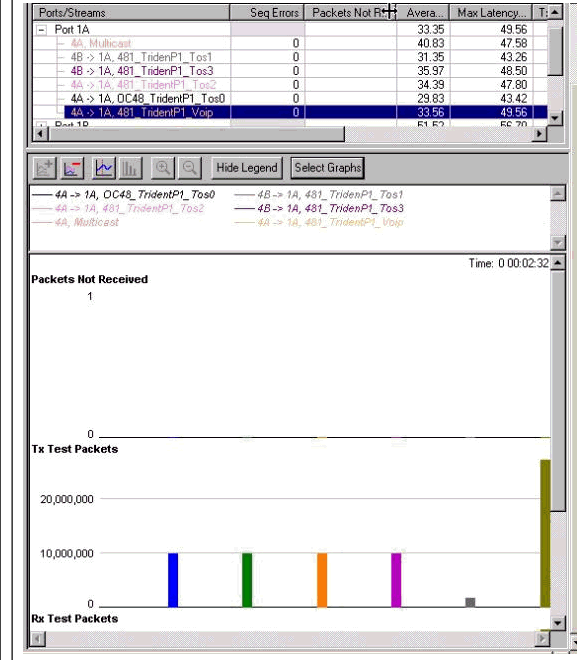
この設定の合計帯域幅は 844 Mb になります。次のグラフには、パケット ドロップが 0 であり、超低遅延(音声を含む各ストリームで約 50 マイクロ秒)であることが示されています。
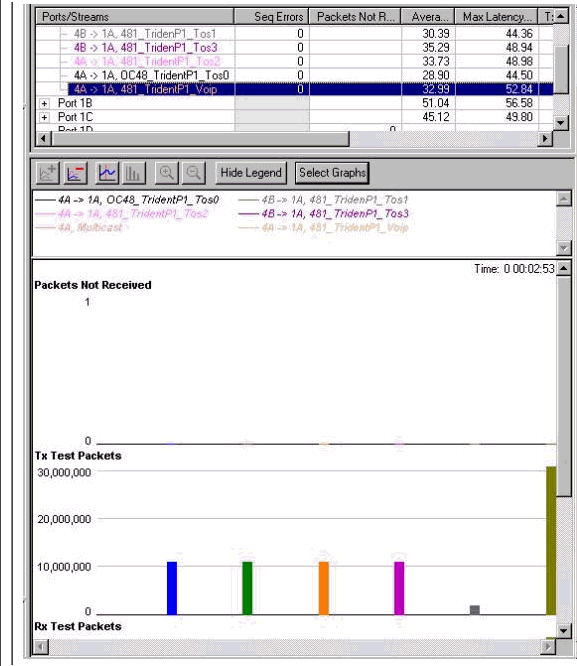
1 つあたり 160 Mb のデータ ストリームが 4 つ
この設定の合計帯域幅は 880 Mb になります。次のグラフには、優先度 0 クラスからパケットのドロップが始まり、音声の遅延は 6 ミリ秒に増加していることが示されています。
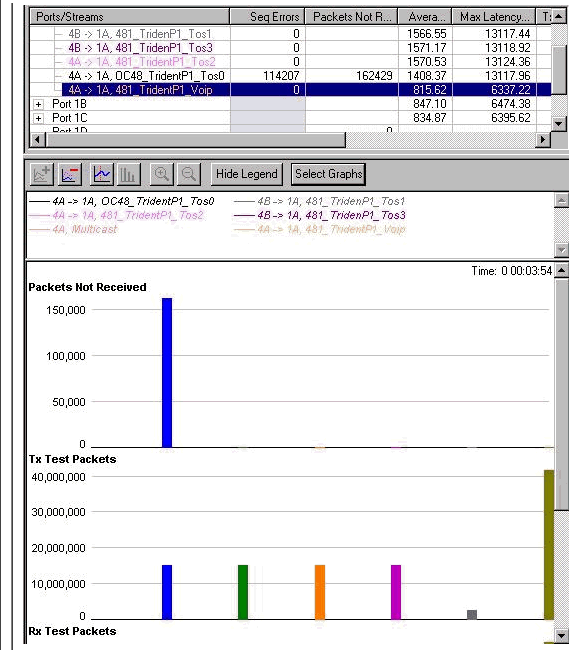
1 つあたり 167 Mb のデータ ストリームが 4 つ
この設定の合計帯域幅は 908 Mb になります。優先度 1 のクラスでもドロップが開始しています。音声トラフィックの遅延は依然として同じです。
注:ストリームは増加する前に停止されなかったため、ストリーム0と1のドロップ数の差は累積されます。
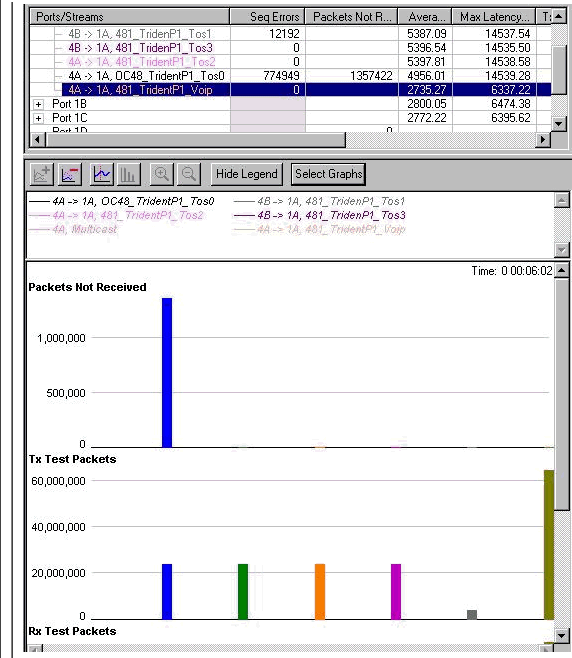
1 つあたり 191 Mb のデータ ストリームが 4 つ
合計帯域幅が増加すると、優先度 2 のキューからもパケットがドロップされ始めます。このとき、ギガビット イーサネット インターフェイスが到達しようとしている合計帯域幅は 1004 Mb です。これは、次のグラフのシーケンス エラー カウンタに示されています。
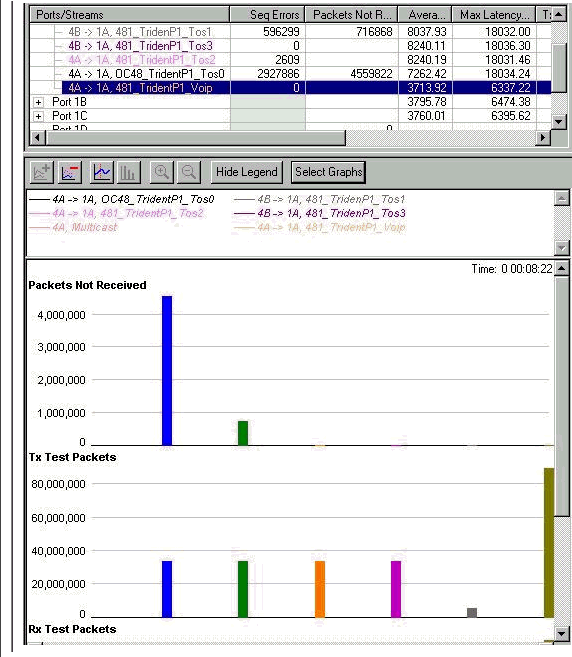
1 つあたり 244 Mb のデータ ストリームが 4 つ
優先度 3 のシーケンス エラーも増加し始めています。これは、そのキューからドロップが開始する最初のサインです。このとき、GbE インターフェイスを送信しようとしている合計帯域幅は 1216 Mb です。Multicast(MC; マルチキャスト)と音声キューのドロップが引き続きゼロであり、音声キューの遅延が増加していないことに注目してください。
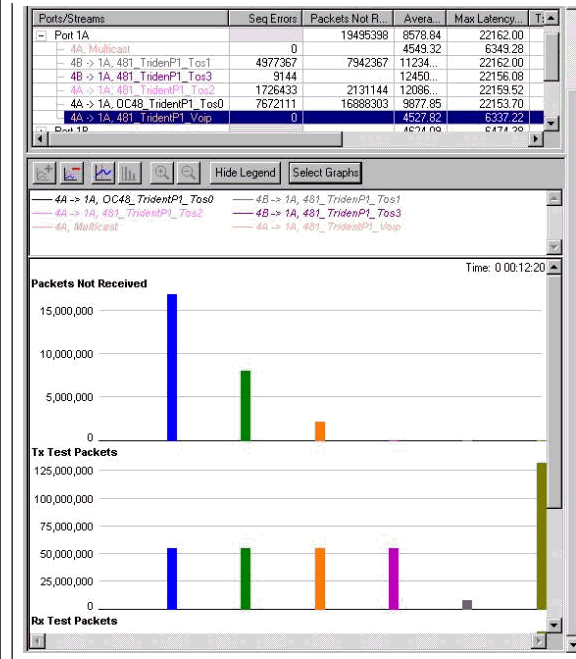
停止と開始
カウンタをクリアしたグラフを作成するために、すべてのストリームを停止して開始しました。次に、高い輻輳での表示を示します。次の図では、目的のとおりに動作していることが分かります。
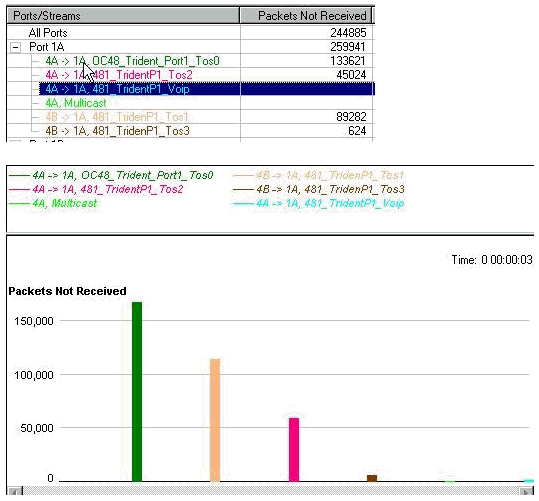
すべての QoS の削除
輻輳中に QoS によってパフォーマンスが実際に向上していることを証明するために、QoS を削除して、インターフェイスが輻輳するようにしています。その結果を次に示します(生成されたストリームでは、他の値が示されない限り、次の値が使用されます)。
MTU all three data streams 300byte, MTU voice 80byte, MTU MC 1500byte 126Mb MC, 114Mb VoIP
これにより、バックグラウンド ストリームは 240 Mb(VoIP とマルチキャスト)になります。
次に、同じサイズのデータ ストリームを 4 つ追加し、優先度 0 ~ 3(ストリームにつき 1 つの優先値)を設定します。
1 つあたり 153 Mb のデータ ストリームが 4 つ
合計帯域幅は 852 Mb になります。ドロップは 0 であり、遅延は 50 マイクロ秒以下です。
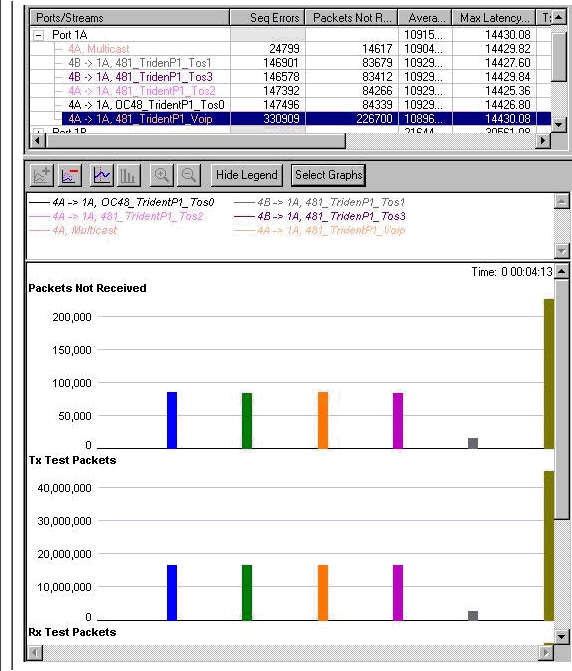
1 つあたり 158 Mb のデータ ストリームが 4 つ
WRED が適用されているときと同じ使用率でドロップを開始します(872 Mb)。 今回の相違は、音声パケットの遅延が 14 ミリ秒(WRED テスト時よりも 2 倍以上)になり、VoIP およびマルチキャストを含むすべてのクラスで平等にドロップが発生している点です。
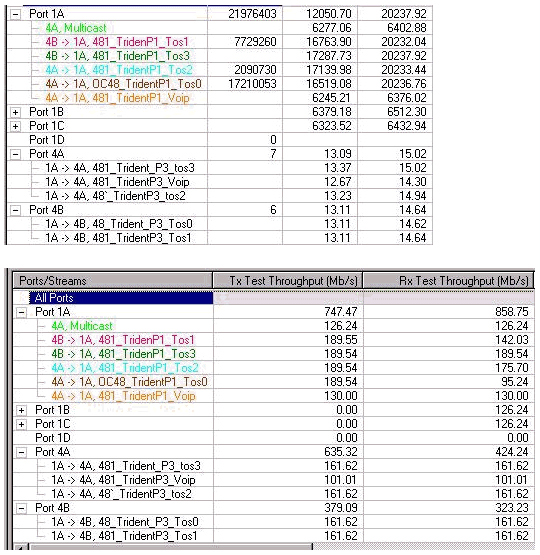
入力ロードの追加
これまでのすべてのテストでは、ギガビット イーサネット インターフェイスからの送信のみを対象としていました。もう 1 つの方向のインターフェイスで輻輳が発生したときに、インターフェイスがどのように反応するかを確認するために、次のテストを行いました。
このテストでは、1056 Mb の合計帯域幅を持つギガビット イーサネット インターフェイスをロードしました。この結果、優先度 0 ~ 2 のトラフィックではドロップが発生し、優先度 3 のトラフィックではドロップが発生しませんでした(MC と VoIP では同じ結果になり、ドロップは発生しませんでした)。 次に、パケット ジェネレータが生成して、ギガビット イーサネット インターフェイスから送信できる限りのトラフィックをもう 1 つの方向に追加しました。その結果は非常に興味深いものになりました。受信側の輻輳はキューの送信にまったく影響を与えず、受信トラフィックの遅延は音声で 13 マイクロ秒未満という極端に小さいものでした。
12-RP#show interfaces g 6/0
show interfaces コマンドを使用して、ギガビット リンクの負荷を監視できます。
Router#show interfaces gig 6/0
GigabitEthernet6/0 is up, line protocol is up
Hardware is GigMac 3 Port GigabitEthernet, address is 0004.de56.c264
(bia 0004.de56.c264)
Internet address is 178.6.0.1/24
MTU 1500 bytes, BW 1000000 Kbit, DLY 10 usec, rely 255/255, load 232/255
Encapsulation ARPA, loopback not set
Keepalive set (10 sec)
Full-duplex mode, link type is force-up, media type is SX
output flow-control is unsupported, input flow-control is off
ARP type: ARPA, ARP Timeout 04:00:00
Last input 00:00:05, output 00:00:05, output hang never
Last clearing of "show interface" counters 08:52:40
Queueing strategy: random early detection (WRED)
Output queue 0/40, 2174119522 drops; input queue 0/75, 0 drops
30 second input rate 838969000 bits/sec, 792079 packets/sec
30 second output rate 910819000 bits/sec, 464704 packets/sec
7584351146 packets input, 1003461987270 bytes, 0 no buffer
Received 0 broadcasts, 0 runts, 0 giants, 0 throttles
0 input errors, 0 CRC, 0 frame, 0 overrun, 0 ignored
0 watchdog, 514 multicast, 0 pause input
11167110605 packets output, 2241229569668 bytes, 0 underruns
0 output errors, 0 collisions, 0 interface resets
0 babbles, 0 late collision, 0 deferred
0 lost carrier, 0 no carrier, 0 pause output
0 output buffer failures, 0 output buffers swapped out
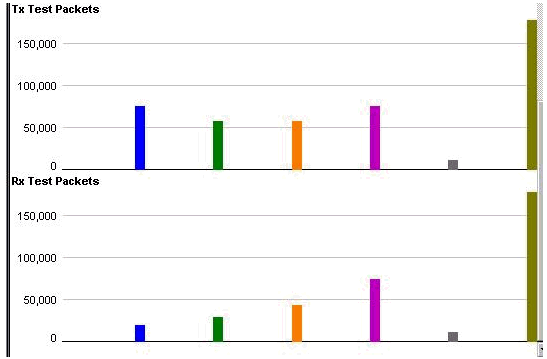
ストリーム サイズの変更
すべてのストリームが同じ帯域幅であるためにこのテスト結果が生じたわけではないことを検証するために、異なるデータ量を送信するようにストリームを変更しました。また、ストリームごとに Maximum Transmission Unit(MTU; 最大伝送ユニット)が異なるように変更しました。結果は引き続き同じであり、設定したキュー値では、優先度 0 が最初にドロップされ、優先度 1、2 と続き、最後に優先度 3 がドロップされました。
10 ポート ギガビット イーサネット エンジンの 4 ラインカードによる確認
テストでの VoIP キュー(低遅延キュー)の遅延はかなり高かったため、10 ポート ギガビット イーサネット エンジン 4 ラインカードでも同じテストを行いました。予測どおり、このラインカードでの結果は、Low Latency Queue(LLQ; 低遅延キュー)の遅延という点では、著しい向上が見られました。 ドロップの発生方法については同じ結果でした。LLQ の遅延は約 10 マイクロ秒であり、3 ポート ギガビット イーサネット エンジン 2 ラインカードの遅延の 1:1000 です。
 フィードバック
フィードバック