Ultra-M UCS 240M4サーバのマザーボード交換 – CPAR
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
概要
このドキュメントでは、Ultra-Mセットアップでサーバのマザーボードの障害を交換するために必要な手順について説明します。
この手順は、ESCがCPARを管理しておらず、CPARがOpenstackに導入されたVMに直接インストールされているNEWTONバージョンを使用するOpenstack環境に適用されます。
背景説明
Ultra-Mは、VNFの導入を簡素化するために設計された、パッケージ化および検証済みの仮想化モバイルパケットコアソリューションです。OpenStackは、Ultra-M向けのVirtualized Infrastructure Manager(VIM)であり、次のノードタイプで構成されています。
- 計算
- オブジェクトストレージディスク – コンピューティング(OSD – コンピューティング)
- コントローラ
- OpenStackプラットフォーム – Director(OSPD)
Ultra-Mのアーキテクチャと関連するコンポーネントを次の図に示します。
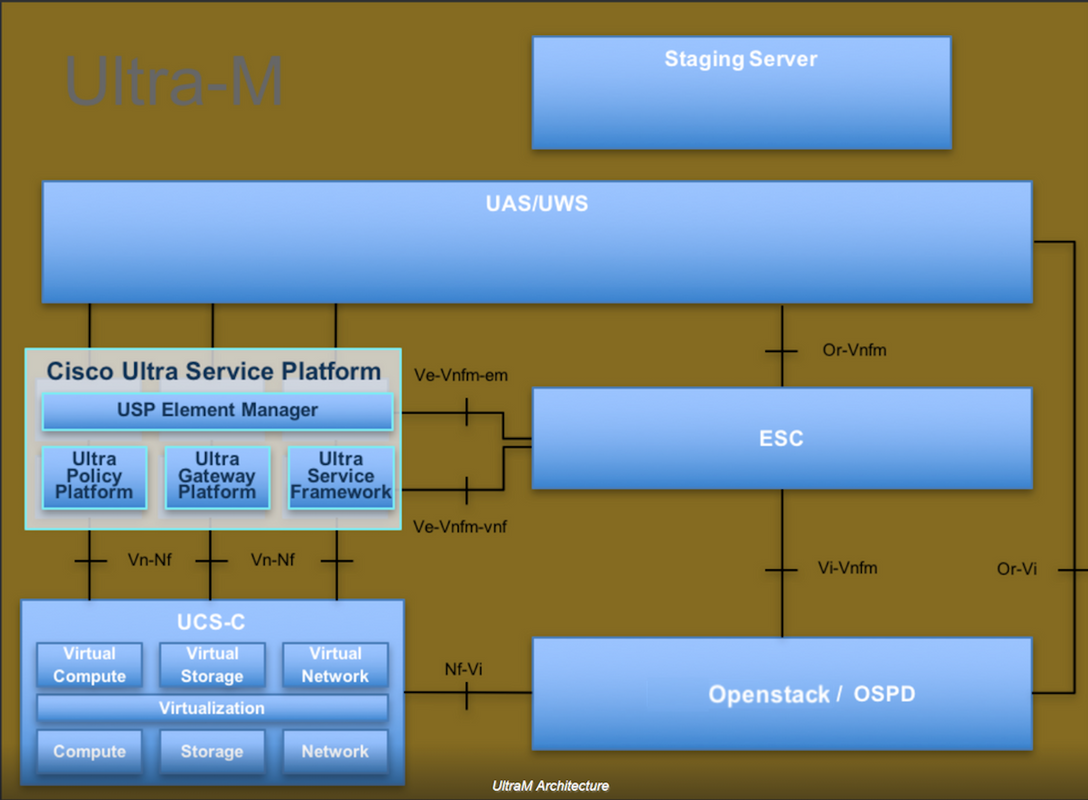
このドキュメントは、Cisco Ultra-Mプラットフォームに精通しているシスコの担当者を対象としており、OpenStackおよびRedhat OSで実行する必要がある手順について詳しく説明しています。
注:このドキュメントの手順を定義するために、Ultra M 5.1.xリリースが検討されています。
省略形
| MOP | 手続きの方法 |
| OSD | オブジェクトストレージディスク |
| OSPD | OpenStack Platform Director |
| HDD | ハードディスクドライブ |
| SSD | ソリッドステートドライブ |
| VIM | 仮想インフラストラクチャマネージャ |
| VM | 仮想マシン |
| EM | エレメント マネージャ |
| UAS | Ultra Automation Services |
| UUID | ユニバーサル一意IDentifier |
MoPのワークフロー
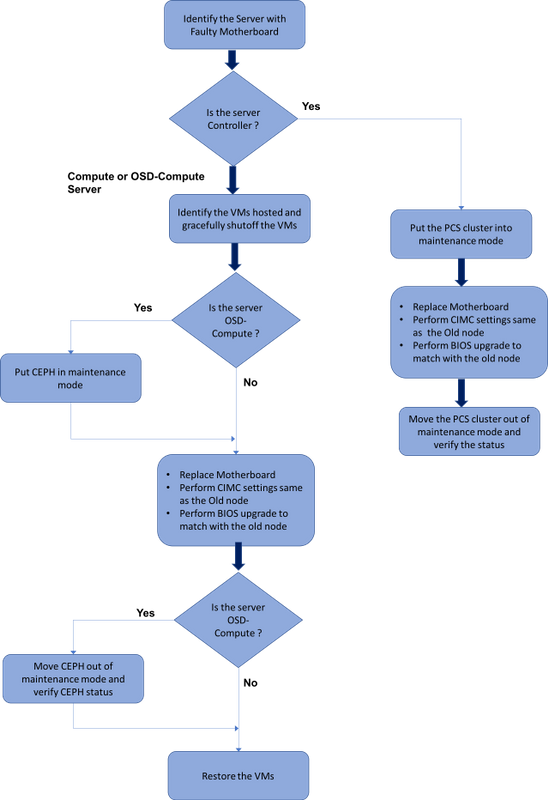
Ultra-Mセットアップでのマザーボードの交換
Ultra-Mセットアップでは、次のサーバタイプでマザーボードの交換が必要になる場合があります。コンピューティング、OSDコンピューティング、コントローラ
注:openstackをインストールしたブートディスクは、マザーボードの交換後に交換されます。したがって、ノードをオーバークラウドに追加する必要はありません。交換アクティビティの後にサーバの電源がオンになると、サーバ自体がオーバークラウドスタックに登録されます。
前提条件
コンピュートノードを置き換える前に、Red Hat OpenStackプラットフォーム環境の現在の状態を確認することが重要です。コンピューティングの交換プロセスがオンの場合は、複雑さを避けるために現在の状態を確認することをお勧めします。この交換フローによって実現できます。
リカバリの場合は、次の手順を使用してOSPDデータベースのバックアップを取ることを推奨します。
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
このプロセスにより、インスタンスの可用性に影響を与えることなく、ノードを確実に交換できます。
注:必要に応じてVMをリストアできるように、インスタンスのスナップショットがあることを確認します。VMのスナップショットを作成する手順は、次のとおりです。
コンピューティングノードでのマザーボードの交換
このアクティビティの前に、コンピューティングノードでホストされているVMは正常にシャットオフされます。マザーボードを交換すると、VMが復元されます。
コンピューティングノードでホストされるVMの特定
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
注:ここに示す出力では、最初の列が汎用一意識別子(UUID)に対応し、2番目の列がVM名、3番目の列がVMが存在するホスト名です。この出力のパラメータは、以降のセクションで使用します。
バックアップ:スナップショットプロセス
ステップ1:CPARアプリケーションのシャットダウン。
ステップ1:ネットワークに接続されているすべてのsshクライアントを開き、CPARインスタンスに接続します。
1つのサイト内のすべての4つのAAAインスタンスを同時にシャットダウンしないようにし、1つずつ実行することが重要です。
ステップ 2:次のコマンドを使用して、CPARアプリケーションをシャットダウンします。
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
ユーザがCLIセッションを開いたままにすると、arserver stopコマンドが動作せず、次のメッセージが表示されます。
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
この例では、CPARを停止する前に、強調表示されたプロセスID 2903を終了する必要があります。このような場合は、次のコマンドを使用してこのプロセスを終了してください。
kill -9 *process_id*
次に、手順1を繰り返します。
ステップ 3:次のコマンドを発行して、CPARアプリケーションが実際にシャットダウンされたことを確認します。
/opt/CSCOar/bin/arstatus
次のメッセージが表示されます。
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VMスナップショットタスク
ステップ 1:現在作業中のサイト(都市)に対応するHorizon GUI Webサイトを入力します。
Horizonにアクセスすると、次の画面が表示されます。
ステップ 2:図に示すように、[Project] > [Instances]に移動します。
ユーザがCPARの場合、このメニューには4つのAAAインスタンスだけが表示されます。
ステップ 3:一度に1つのインスタンスだけをシャットダウンします。このドキュメントのプロセス全体を繰り返してください。
VMをシャットダウンするには、[Actions] > [Shut Off Instance]に移動し、選択を確定します。

ステップ 4:ステータス=シャットオフおよび電力状態=シャットダウンをチェックして、インスタンスが実際にシャットダウンされたことを確認します。
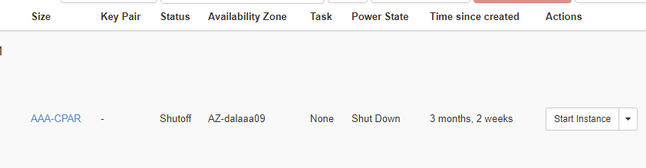
この手順により、CPARシャットダウンプロセスが終了します。
VMスナップショット
CPAR VMがダウンすると、スナップショットは独立した計算に属するため、並行して取得できます。
4つのQCOW2ファイルが並行して作成されます。
各AAAインスタンスのスナップショット(25分~1時間)(ソースとしてqcowイメージを使用したインスタンスは25分、ソースとしてrawイメージを使用するインスタンスは1時間)
ステップ1:PODのOpenstackの地平線にログインするGUI
ステップ2:ログインしたら、トップメニューの[Project] > [Compute] > [Instances]セクションに進み、AAAインスタンスを探します。
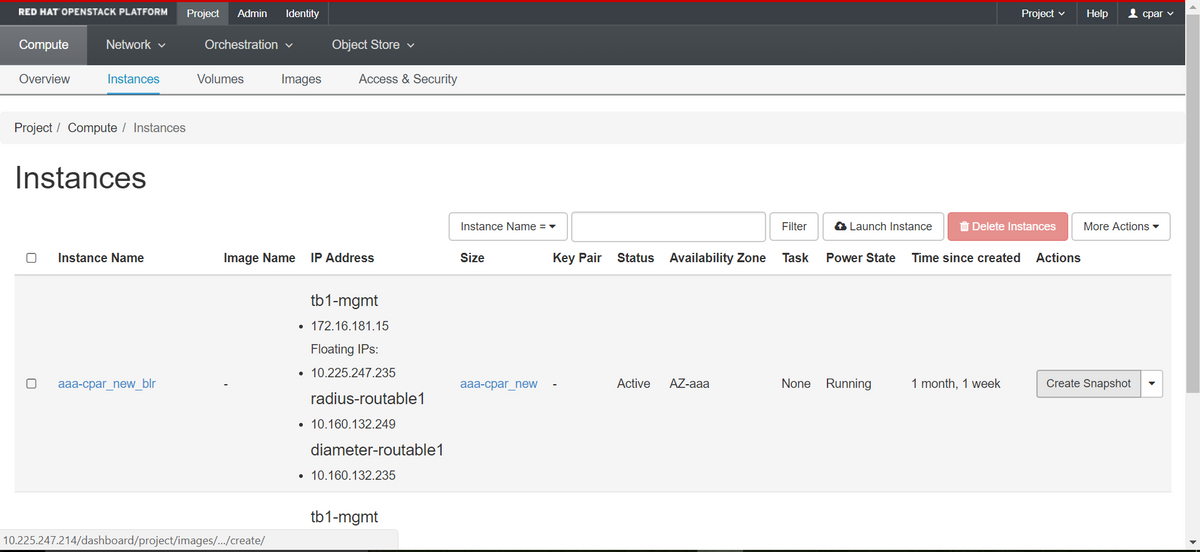
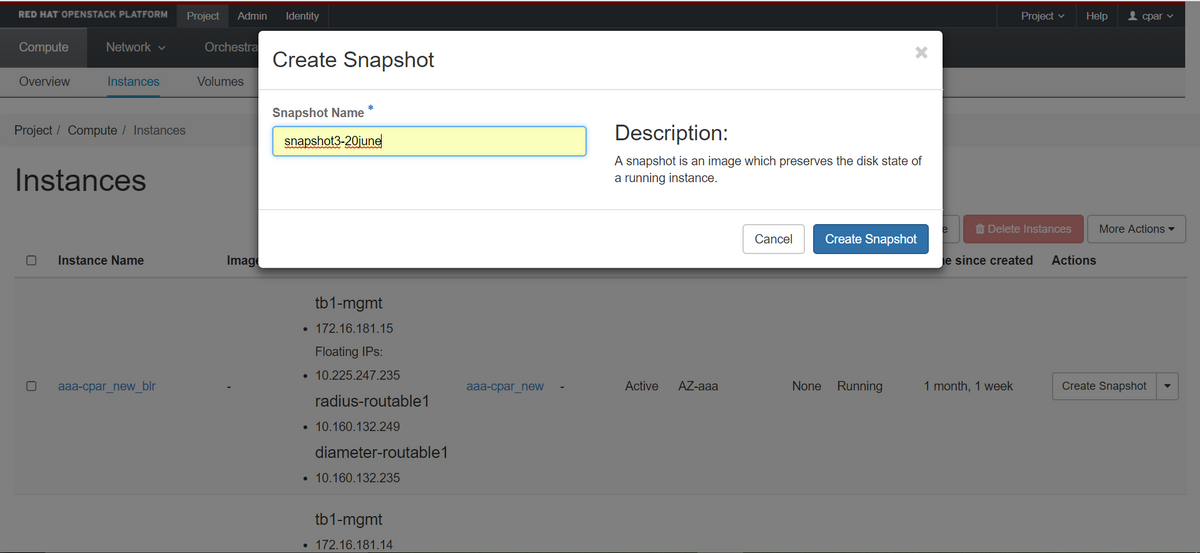
ステップ3:[Create Snapshot]ボタンをクリックして、スナップショットの作成を続行します(これは、対応するAAAインスタンスで実行する必要があります)。
ステップ4:スナップショットが実行されたら、[IMAGES(イメージ)]メニューに移動し、すべてが終了して問題が報告されていないことを確認します。
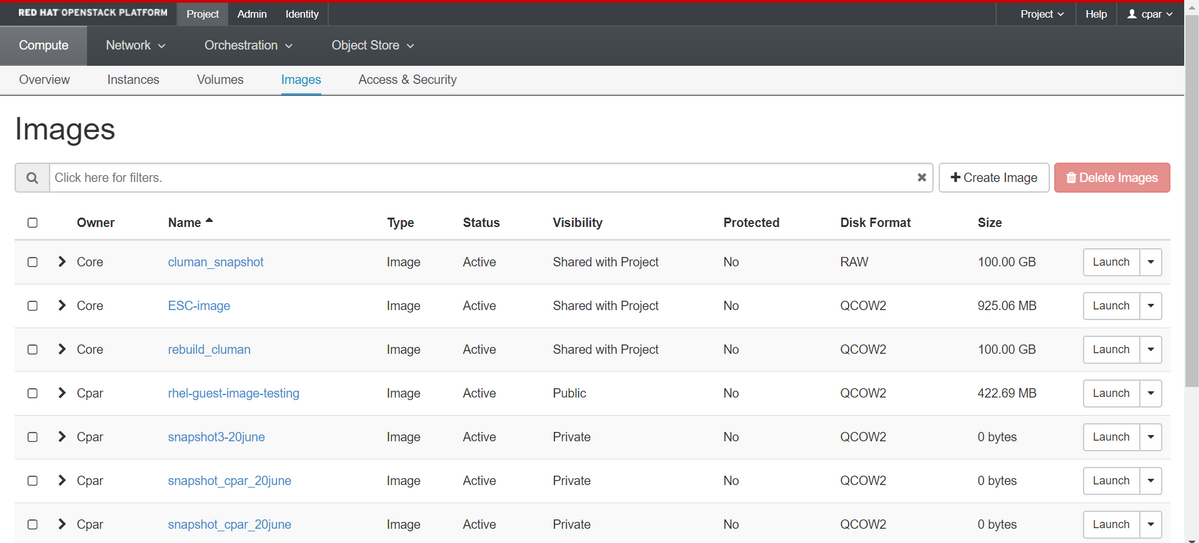
ステップ5:次のステップは、QCOW2形式でスナップショットをダウンロードし、このプロセス中にOSPDが失われた場合に備えてリモートエンティティに転送することです。これを行うには、次のコマンドglance image-listを使用してスナップショットをOSPDレベルで識別してください。
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
ステップ6:ダウンロードするスナップショットを特定したら(この場合は緑色で上に示すスナップショット)、コマンドglance image-downloadを使用してQCOW2形式でダウンロードします。
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- 「&」は、プロセスをバックグラウンドに送信します。この操作を完了するには時間がかかります。完了すると、イメージは/tmpディレクトリに置かれます。
- プロセスをバックグラウンドに送信すると、接続が失われると、プロセスも停止します。
- コマンド「disown -h」を実行して、SSH接続が失われた場合でもプロセスが実行され、OSPDで終了するようにします。
ステップ7:ダウンロード処理が終了したら、圧縮プロセスを実行する必要があります。これは、オペレーティングシステムによって処理されるプロセス、タスク、一時ファイルが原因で、スナップショットにゼロが埋まる可能性があるためです。ファイル圧縮に使用するコマンドはvirt-sparsifyです。
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
このプロセスには時間がかかります(約10 ~ 15分)。 完了すると、次の手順で指定した外部エンティティに転送する必要があるファイルが生成されます。
ファイルの整合性を確認する必要があります。これを行うには、次のコマンドを実行し、出力の最後に「corrupt」属性を探します。
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
OSPDが失われる問題を回避するには、QCOW2形式で最近作成したスナップショットを外部エンティティに転送する必要があります。ファイル転送を開始する前に、宛先に十分な空きディスク領域があるかどうかを確認する必要があります。メモリ領域を確認するには、コマンド「df -kh」を使用します。私たちのアドバイスは、SFTP「sftproot@x.x.x.x」(x.x.x.xはリモートOSPDのIP)を使用して、それを一時的に別のサイトのOSPDに転送することです。転送を高速化するために、宛先を複数のOSPDに送信できます。同様に、scp *name_of_the_file*.qcow2 root@ x.x.x.x.x:/tmp (x.x.x.xはリモートOSPDのIP)コマンドを使用して、ファイルを別のOSPDに転送できます。
グレースフルパワーオフ
ノードの電源オフ
- インスタンスの電源をオフにするには:nova stop <INSTANCE_NAME>
- 次に、インスタンス名とステータスシャットオフが表示されます。
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
マザーボードの交換
UCS C240 M4サーバのマザーボードを交換する手順については、『Cisco UCS C240 M4サーバインストレーションおよびサービスガイド』を参照してください
- CIMC IPを使用してサーバにログインします。
- ファームウェアが以前に使用した推奨バージョンと異なる場合は、BIOSアップグレードを実行します。BIOSアップグレードの手順は次のとおりです。Cisco UCS CシリーズラックマウントサーバBIOSアップグレードガイド
VMのリストア
スナップショットによるインスタンスのリカバリ
リカバリプロセス
前のステップで実行したスナップショットを使用して、前のインスタンスを再展開できます。
ステップ1 [オプション]使用可能な以前のVMsnapshotがない場合は、バックアップが送信されたOSPDノードに接続し、バックアップを元のOSPDノードにsftpして戻します。「sftproot@x.x.x.x」を使用します。x.x.x.xは元のOSPDのIPです。スナップショットファイルを/tmpディレクトリに保存します。
ステップ 2:インスタンスが再展開されるOSPDノードに接続します。
 次のコマンドを使用して、環境変数をソース化します。
次のコマンドを使用して、環境変数をソース化します。
# source /home/stack/pod1-stackrc-Core-CPAR
ステップ 3:スナップショットをイメージとして使用するには、スナップショットを地平線にアップロードする必要があります。次のコマンドを使用して実行します。
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
プロセスは水平線で確認できます。

ステップ 4:Horizonで、[プロジェクト] > [インスタンス]に移動し、[インスタンスの起動]をクリックします。

ステップ 5:インスタンス名を入力し、可用性ゾーンを選択します。
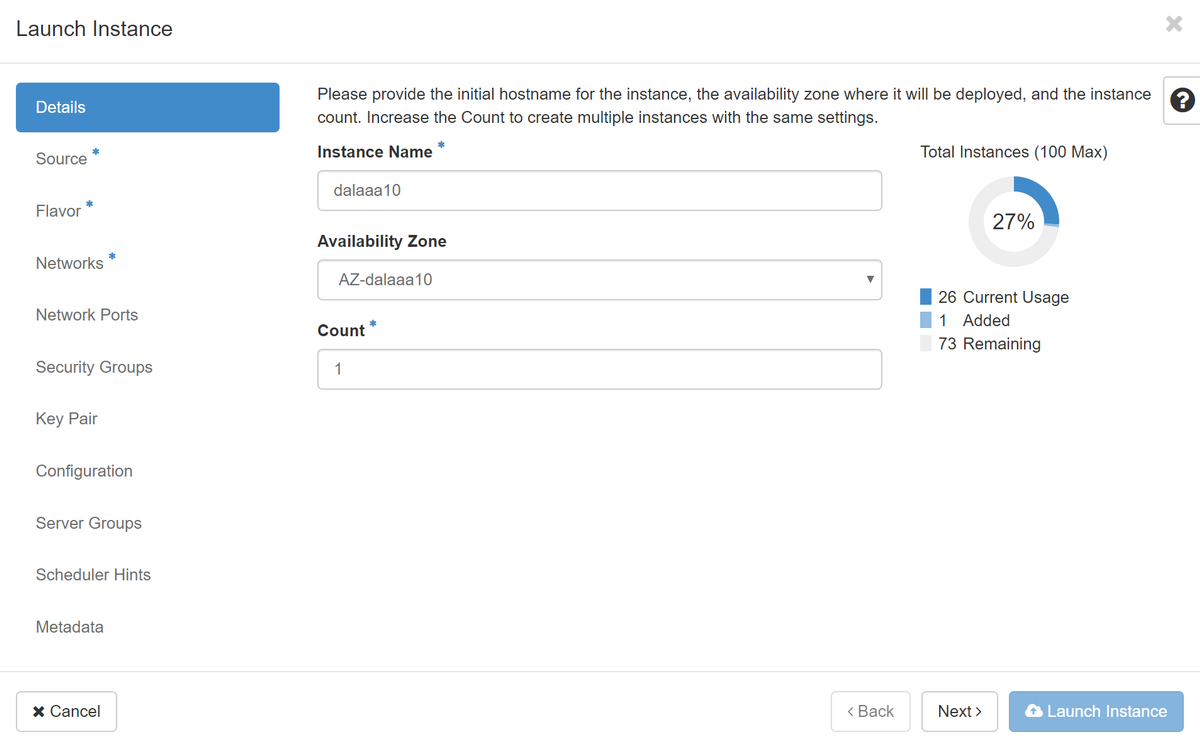
手順 6:[ソース]タブで、インスタンスを作成するイメージを選択します。[Select Boot Source]メニューでイメージを選択して、ここにイメージのリストが表示されます。+記号をクリックすると、以前にアップロードしたイメージを選択します。
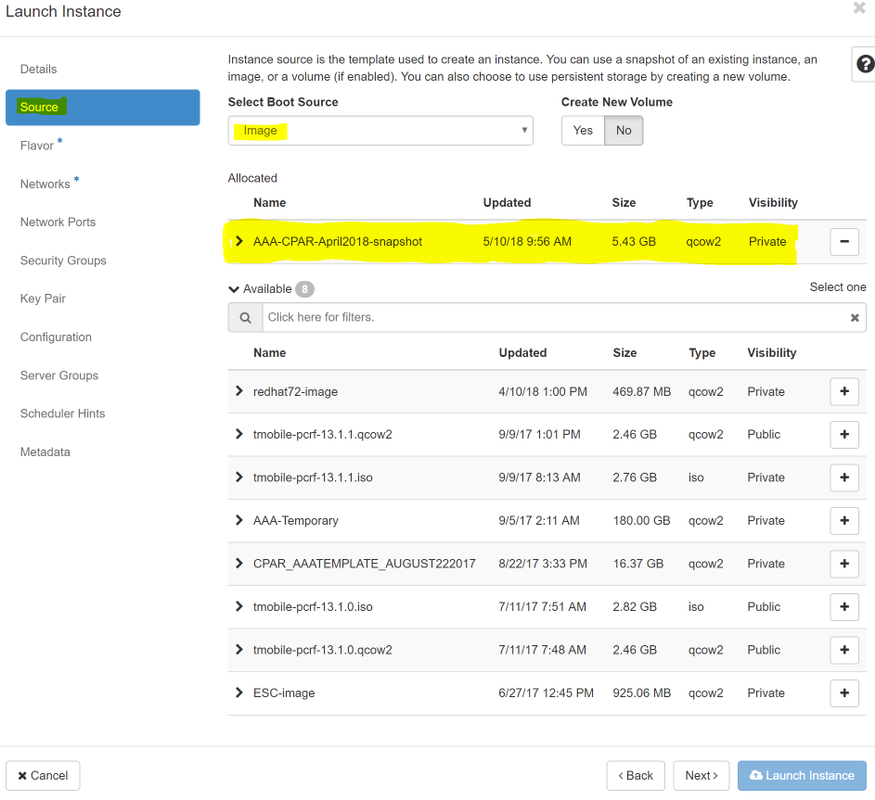
手順 7:[フレーバー]タブで、+記号をクリックしながらAAAフレーバーを選択します。
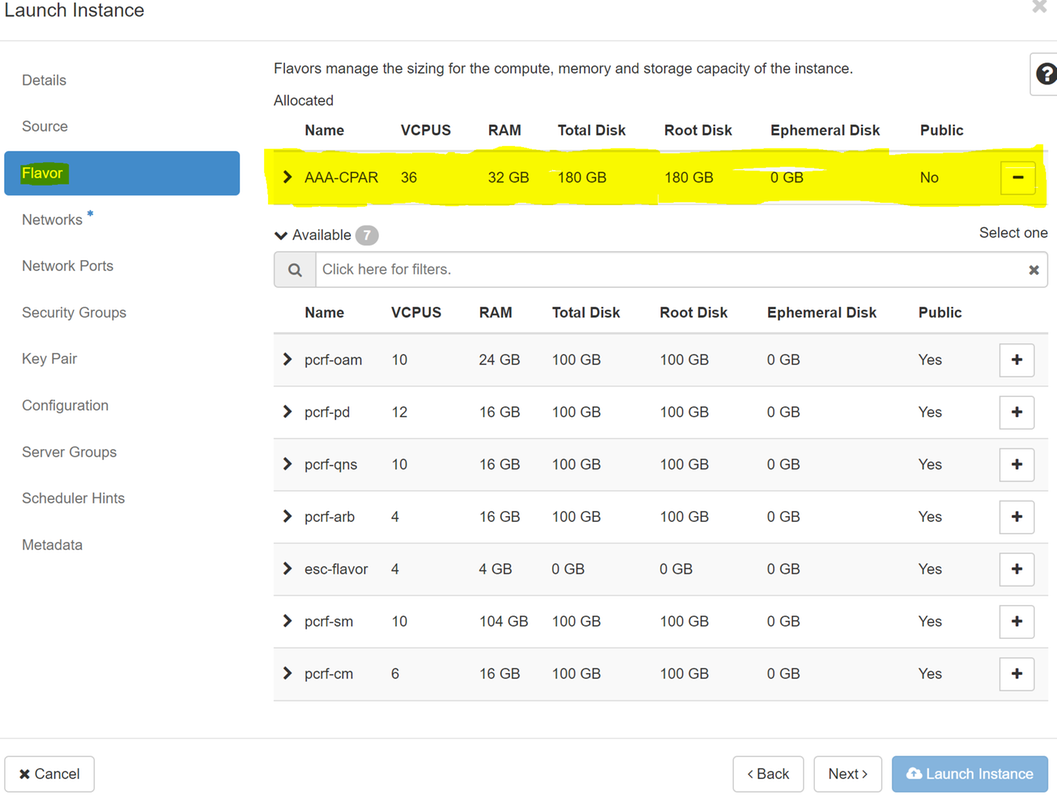
ステップ8:最後に、[network]タブに移動し、+記号をクリックしてインスタンスに必要なネットワークを選択します。この場合は、diameter-soutable1、radius-routable1、tb1-mgmtを選択します。
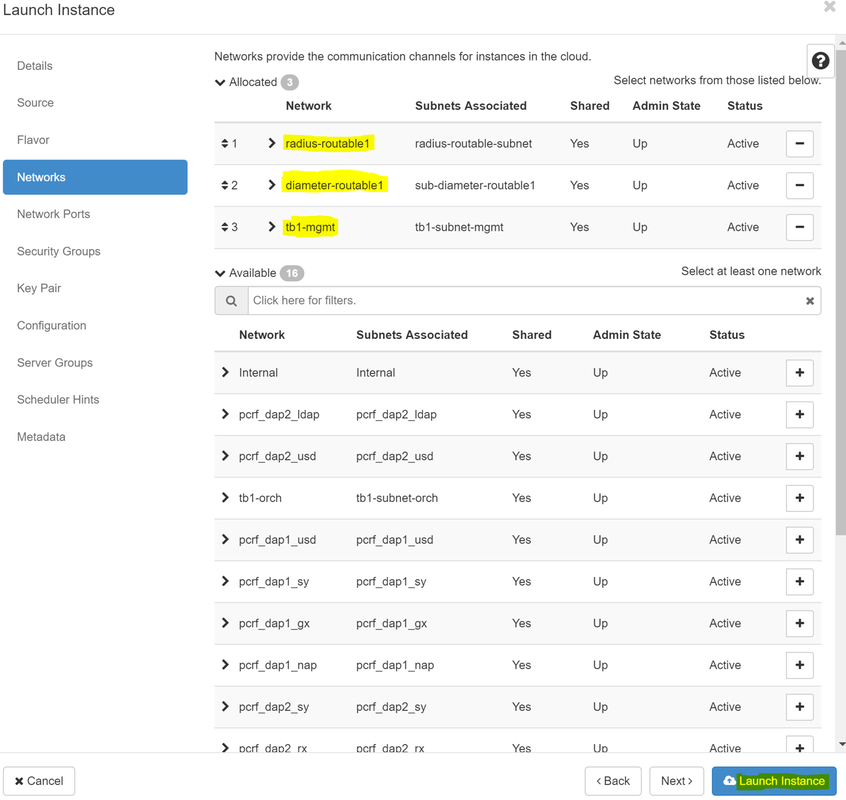
ステップ9:最後に、[Launch instance]をクリックして作成します。進行状況は、次のHorizonで監視できます。
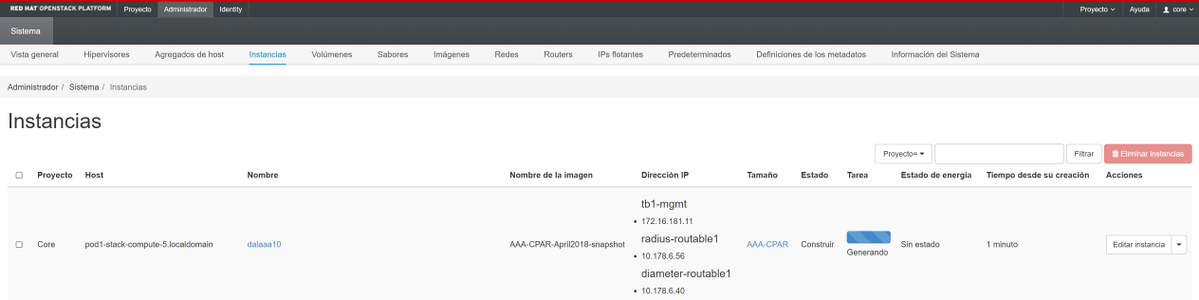
数分後、インスタンスは完全に導入され、使用可能な状態になります。

フローティングIPアドレスの作成と割り当て
フローティングIPアドレスは、ルーティング可能なアドレスです。つまり、Ultra M/Openstackアーキテクチャの外部から到達可能であり、ネットワークの他のノードと通信できます。
ステップ1:[Horizon]トップメニューで、[Admin] > [Floating IPs]に移動します。
ステップ2:ボタン[AllocateIP to Project]をクリックします。
ステップ3:[Allocate Floating IP]ウィンドウで、新しいフローティングIPが属するプール、割り当て先のプロジェクト、および新しいフローティングIPアドレス自体を選択します。
以下に、いくつかの例を示します。
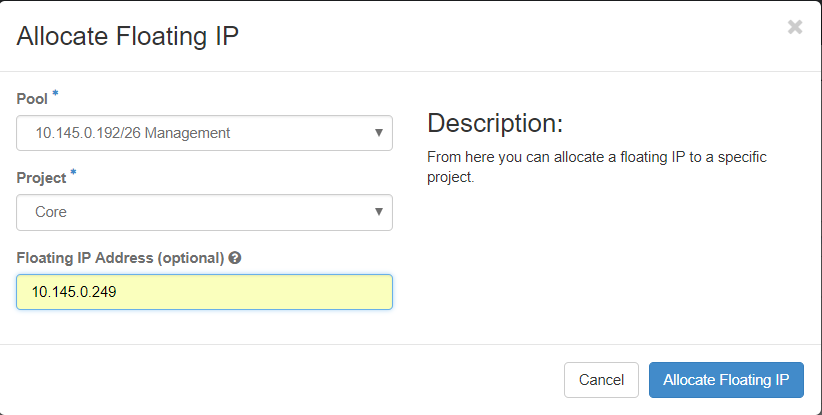
ステップ4:[AllocateFloating IPbutton]をクリックします。
ステップ5:[Horizon]トップメニューで、[Project] > [Instances]に移動します。
手順 6:[アクション]列の[スナップショットの作成]ボタンの下を指定する矢印をクリックすると、メニューが表示されます。Associate Floating IPoptionを選択します。
ステップ7:[IP Address]フィールドで使用する対応するフローティングIPアドレスを選択し、このフローティングIPが関連付けられるポートで割り当てられる新しいインスタンスから対応する管理インターフェイス(eth0)を選択します。この手順の例として、次の図を参照してください。
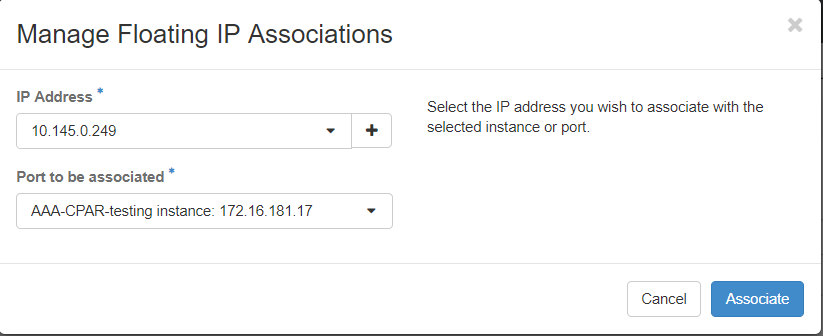
ステップ8:最後に、[Associate]ボタンをクリックします。
SSHの有効化
ステップ 1:水平線のトップメニューで、「プロジェクト」>「インスタンス」に移動します。
ステップ 2:「新規インスタンスのランチインチ」セクションで作成したインスタンス/VMの名前をクリックします。
ステップ3:[コンソール]タブをクリックします。これにより、VMのコマンドラインインターフェイスが表示されます。
ステップ 4:CLIが表示されたら、適切なログインクレデンシャルを入力します。
ユーザ名:root
パスワード:cisco123
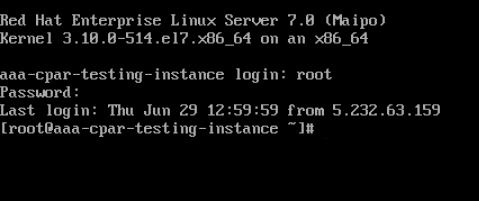
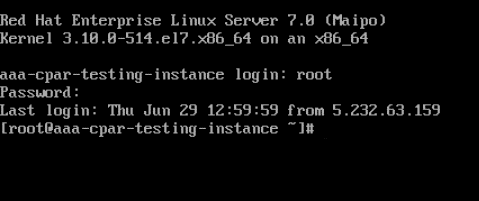
ステップ 5:CLIでvi /etc/ssh/sshd_configationコマンドを入力し、ssh設定を編集します。
ステップ6: ssh設定ファイルが開いたら、Itoキーを押してファイルを編集します。次に、以下に示すセクションを探し、最初の行をPasswordAuthenticationnotoPasswordAuthentication yesから変更します。

手順 7:sshd_configファイルの変更を保存するには、Escキーを押し、:wq!と入力します。
ステップ8:service sshd restartコマンドを実行します。
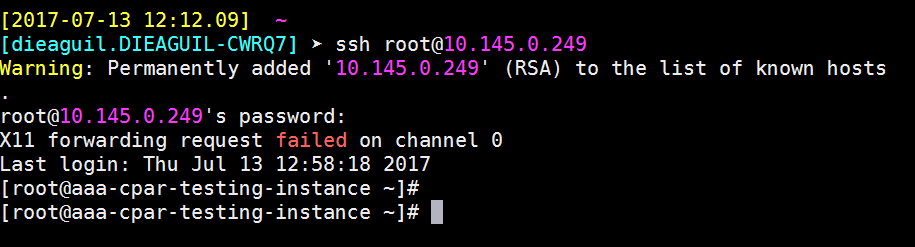
ステップ9:SSH設定の変更が正しく適用されたことをテストするために、任意のSSHクライアントを開き、インスタンスに割り当てられたフローティングIP(10.145.0.249)とuserrootを使用してリモートのセキュア接続を確立してみます。
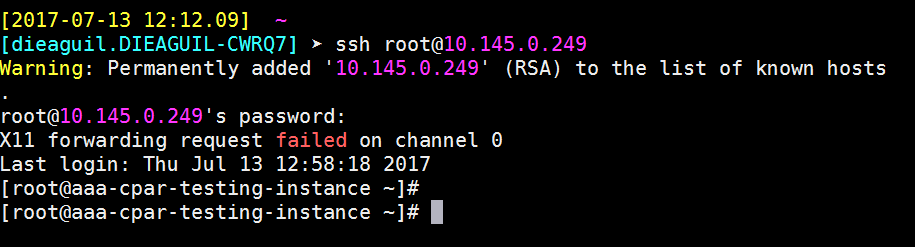
SSHセッションの確立
アプリケーションがインストールされている対応するVM/サーバのIPアドレスを使用して、SSHセッションを開きます。

CPARインスタンス開始
アクティビティが完了し、シャットダウンされたサイトでCPARサービスを再確立できたら、次の手順に従ってください。
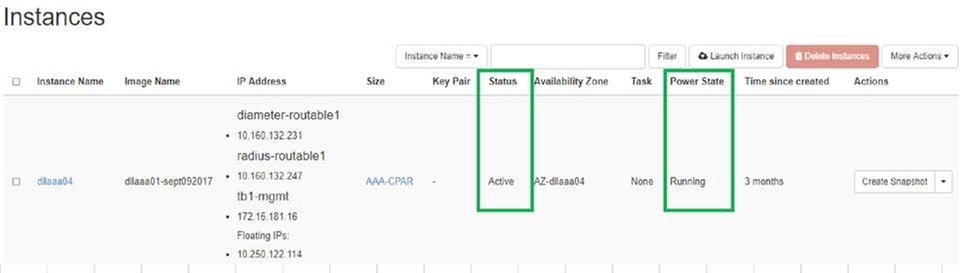
- Horizonに再度ログインするには、[Project] > [Instance] > [Start Instance]に移動します。
- インスタンスのステータスがアクティブで、電源状態が実行中であることを確認します。
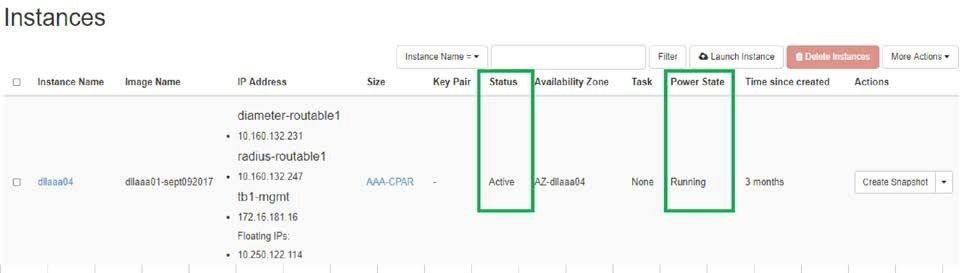
アクティビティ後のヘルスチェック
ステップ1:OSレベルでコマンド/opt/CSCOar/bin/arstatusを実行します。
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
ステップ2:OSレベルでコマンド/opt/CSCOar/bin/aregcmdを実行し、管理者クレデンシャルを入力します。CPAR Healthが10のうち10であることを確認し、CPAR CLIを終了します。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
ステップ 3:コマンドnetstatを実行します | grep diameterとして、すべてのDRA接続が確立されていることを確認します。
次に示す出力は、Diameterリンクが想定される環境を対象としています。表示されるリンク数が少ない場合は、分析が必要なDRAからの切断を表します。
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
ステップ4:TPSログに、CPARによって処理されている要求が表示されることを確認します。強調表示されている値はTPSを表し、これらは注意が必要な値です。
TPSの値は1500を超えることはできません。
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
ステップ 5:name_radius_1_logで「error」または「alarm」メッセージを探します
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
ステップ 6。次のコマンドを発行して、CPARプロセスで使用されているメモリ量を確認します。
top | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
この強調表示された値は、次より小さい値である必要があります。7 Gb(アプリケーションレベルで許可される最大サイズ)。
OSDコンピュートノードでのマザーボードの交換
アクティビティの前に、コンピューティングノードでホストされているVMは正常にシャットオフされ、CEPHはメンテナンスモードになります。マザーボードを交換すると、VMが復元され、CEPHがメンテナンスモードから外れます。
Osd-ComputeノードでホストされるVMの特定
OSDコンピューティングサーバでホストされているVMを特定します。
[stack@director ~]$ nova list --field name,host | grep osd-compute-0 | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain |
バックアップ:スナップショットプロセス
CPARアプリケーションのシャットダウン
ステップ1:ネットワークに接続されているすべてのsshクライアントを開き、CPARインスタンスに接続します。
1つのサイト内のすべての4つのAAAインスタンスを同時にシャットダウンしないようにし、1つずつ実行することが重要です。
ステップ 2:次のコマンドを使用して、CPARアプリケーションをシャットダウンします。
/opt/CSCOar/bin/arserver stop A Message stating “Cisco Prime Access Registrar Server Agent shutdown complete.” Should show up
注:ユーザがCLIセッションを開いたままにすると、arserver stopコマンドが動作せず、次のメッセージが表示されます。
ERROR: You can not shut down Cisco Prime Access Registrar while the CLI is being used. Current list of running CLI with process id is: 2903 /opt/CSCOar/bin/aregcmd –s
この例では、CPARを停止する前に、強調表示されたプロセスID 2903を終了する必要があります。このような場合は、次のコマンドを使用してこのプロセスを終了してください。
kill -9 *process_id*
次に、手順1を繰り返します。
ステップ 3:次のコマンドを使用して、CPARアプリケーションが実際にシャットダウンされたことを確認します。
/opt/CSCOar/bin/arstatus
次のメッセージが表示されます。
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VMスナップショットタスク
ステップ 1:現在作業中のサイト(都市)に対応するHorizon GUI Webサイトを入力します。
Horizonにアクセスすると、次の図が表示されます。
ステップ2:図に示すように、[プロジェクト] > [インスタンス]に移動します。
ユーザがCPARの場合、このメニューには4つのAAAインスタンスだけが表示されます。
ステップ 3:一度に1つのインスタンスだけをシャットダウンします。このドキュメントのプロセス全体を繰り返してください。
VMをシャットダウンするには、[Actions] > [Shut Off Instance]に移動し、選択を確定します。

ステップ 4:ステータス=シャットオフおよび電力状態=シャットダウンをチェックして、インスタンスが実際にシャットダウンされたことを確認します。
この手順により、CPARシャットダウンプロセスが終了します。
VMスナップショット
CPAR VMがダウンすると、スナップショットは独立した計算に属するため、並行して取得できます。
4つのQCOW2ファイルが並行して作成されます。
各AAAインスタンスのスナップショット(25分~1時間)(ソースとしてqcowイメージを使用したインスタンスの場合は25分、ソースとしてrawイメージを使用するインスタンスの場合は1時間)
ステップ1:PODのOpenstackのHorizonGUIにログインします。
ステップ2:ログインしたら、トップメニューの[Project] > [Compute] > [Instances]セクションに進み、AAAインスタンスを探します。
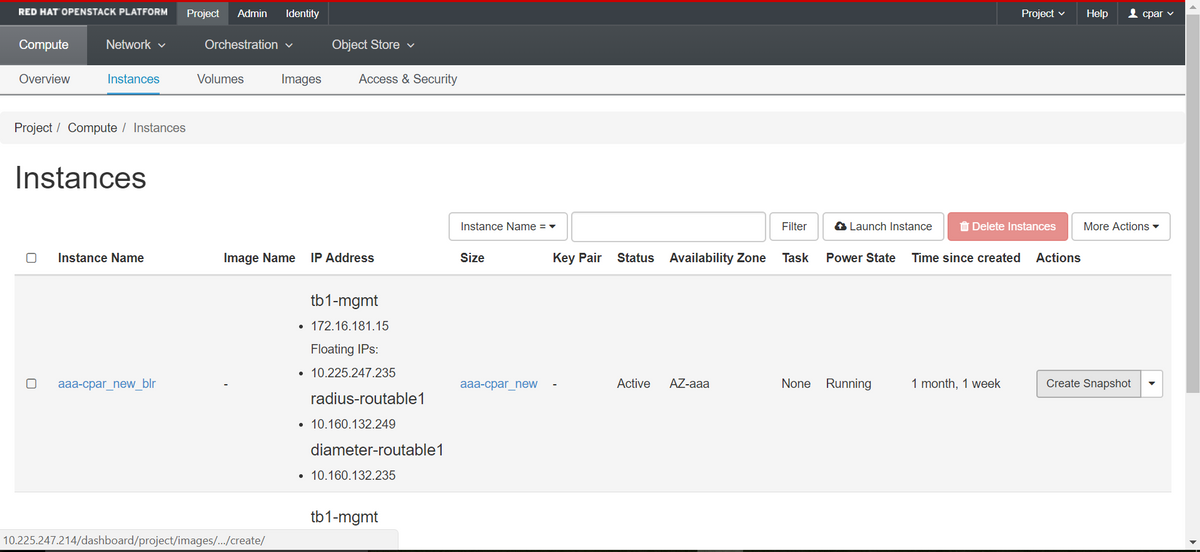
ステップ3:[Create Snapshot]ボタンをクリックして、スナップショットの作成を続行します(これは、対応するAAAインスタンスで実行する必要があります)。
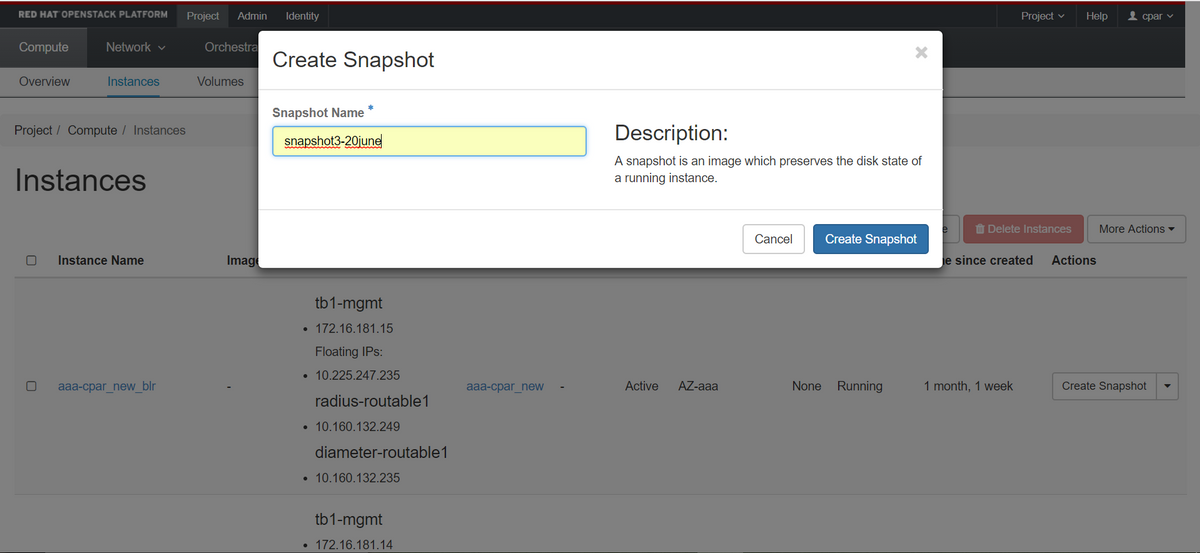
ステップ4:スナップショットが実行されたら、[IMAGES(イメージ)]メニューに移動し、すべてが終了して問題が報告されていないことを確認します。
ステップ5:次のステップは、QCOW2形式でスナップショットをダウンロードし、このプロセス中にOSPDが失われた場合に備えてリモートエンティティに転送することです。これを行うには、次のコマンドglance image-listを使用してスナップショットをOSPDレベルで識別してください。
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
ステップ6:スナップショットをダウンロードする予定であることを確認したら(この場合は緑色で上に示す予定)、次に示すようにglance image-downloadコマンドを使用してQCOW2形式でダウンロードします。
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- 「&」は、プロセスをバックグラウンドに送信します。この操作を完了するには時間がかかります。完了すると、イメージは/tmpディレクトリに置かれます。
- プロセスをバックグラウンドに送信すると、接続が失われると、プロセスも停止します。
- コマンド「disown -h」を実行して、SSH接続が失われた場合でもプロセスが実行され、OSPDで終了するようにします。
7.ダウンロードプロセスが終了したら、圧縮プロセスを実行する必要があります。これは、オペレーティングシステムによって処理されるプロセス、タスク、一時ファイルが原因で、スナップショットにゼロが埋まる可能性があるためです。ファイル圧縮に使用するコマンドはvirt-sparsifyです。
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
このプロセスには時間がかかります(約10 ~ 15分)。 完了すると、次の手順で指定した外部エンティティに転送する必要があるファイルが生成されます。
ファイルの整合性を確認する必要があります。これを行うには、次のコマンドを実行し、出力の最後に「corrupt」属性を探します。
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
OSPDが失われる問題を回避するには、QCOW2形式で最近作成したスナップショットを外部エンティティに転送する必要があります。ファイル転送を開始する前に、宛先に十分な空きディスク領域があるかどうかを確認する必要があります。メモリ領域を確認するには、コマンド「df -kh」を使用します。私たちのアドバイスは、SFTP「sftproot@x.x.x.x」(x.x.x.xはリモートOSPDのIP)を使用して、それを一時的に別のサイトのOSPDに転送することです。転送を高速化するために、宛先を複数のOSPDに送信できます。同様に、scp *name_of_the_file*.qcow2 root@ x.x.x.x.x:/tmp (x.x.x.xはリモートOSPDのIP)コマンドを使用して、ファイルを別のOSPDに転送できます。
CEPHをメンテナンスモードにする
ステップ1:サーバでceph osdツリーのステータスがupであることを確認します
[heat-admin@pod2-stack-osd-compute-0 ~]$ sudo ceph osd tree
ID WEIGHT TYPE NAME UP/DOWN REWEIGHT PRIMARY-AFFINITY
-1 13.07996 root default
-2 4.35999 host pod2-stack-osd-compute-0
0 1.09000 osd.0 up 1.00000 1.00000
3 1.09000 osd.3 up 1.00000 1.00000
6 1.09000 osd.6 up 1.00000 1.00000
9 1.09000 osd.9 up 1.00000 1.00000
-3 4.35999 host pod2-stack-osd-compute-1
1 1.09000 osd.1 up 1.00000 1.00000
4 1.09000 osd.4 up 1.00000 1.00000
7 1.09000 osd.7 up 1.00000 1.00000
10 1.09000 osd.10 up 1.00000 1.00000
-4 4.35999 host pod2-stack-osd-compute-2
2 1.09000 osd.2 up 1.00000 1.00000
5 1.09000 osd.5 up 1.00000 1.00000
8 1.09000 osd.8 up 1.00000 1.00000
11 1.09000 osd.11 up 1.00000 1.00000
ステップ2:OSDコンピュートノードにログインし、CEPHをメンテナンスモードにします。
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd set noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_WARN
noout,norebalance,sortbitwise,require_jewel_osds flag(s) set
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e79: 12 osds: 12 up, 12 in
flags noout,norebalance,sortbitwise,require_jewel_osds
pgmap v22844323: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3858 kB/s wr, 0 op/s rd, 546 op/s wr
注:CEPHが削除されると、VNF HD RAIDはDegraded状態になりますが、hdディスクにアクセスできる必要があります
グレースフルパワーオフ
ノードの電源オフ
- インスタンスの電源をオフにするには:nova stop <INSTANCE_NAME>
- インスタンス名がステータスシャットオフとともに表示されます。
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
マザーボードの交換
UCS C240 M4サーバのマザーボードを交換する手順については、『Cisco UCS C240 M4サーバインストレーションおよびサービスガイド』を参照してください
- CIMC IPを使用してサーバにログインします。
- ファームウェアが以前に使用した推奨バージョンと異なる場合は、BIOSアップグレードを実行します。BIOSアップグレードの手順は次のとおりです。Cisco UCS CシリーズラックマウントサーバBIOSアップグレードガイド
メンテナンスモードからCEPHを移動
OSDコンピュートノードにログインし、CEPHをメンテナンスモードから外します。
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset norebalance
[root@pod2-stack-osd-compute-0 ~]# sudo ceph osd unset noout
[root@pod2-stack-osd-compute-0 ~]# sudo ceph status
cluster eb2bb192-b1c9-11e6-9205-525400330666
health HEALTH_OK
monmap e1: 3 mons at {pod2-stack-controller-0=11.118.0.10:6789/0,pod2-stack-controller-1=11.118.0.11:6789/0,pod2-stack-controller-2=11.118.0.12:6789/0}
election epoch 10, quorum 0,1,2 pod2-stack-controller-0,pod2-stack-controller-1,pod2-stack-controller-2
osdmap e81: 12 osds: 12 up, 12 in
flags sortbitwise,require_jewel_osds
pgmap v22844355: 704 pgs, 6 pools, 804 GB data, 423 kobjects
2404 GB used, 10989 GB / 13393 GB avail
704 active+clean
client io 3658 kB/s wr, 0 op/s rd, 502 op/s wr
VMのリストア
スナップショットによるインスタンスのリカバリ
リカバリプロセス:
前のステップで実行したスナップショットを使用して、前のインスタンスを再展開できます。
ステップ1 [オプション]使用可能な以前のVMsnapshotがない場合は、バックアップが送信されたOSPDノードに接続し、バックアップを元のOSPDノードにsftpして戻します。「sftproot@x.x.x.x」を使用します。x.x.x.xは元のOSPDのIPです。スナップショットファイルを/tmpディレクトリに保存します。
ステップ 2:インスタンスが再展開されるOSPDノードに接続します。

次のコマンドを使用して、環境変数をソース化します。
# source /home/stack/pod1-stackrc-Core-CPAR
ステップ 3:スナップショットをイメージとして使用するには、スナップショットを地平線にアップロードする必要があります。次のコマンドを使用して実行します。
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
プロセスは水平線で確認できます。

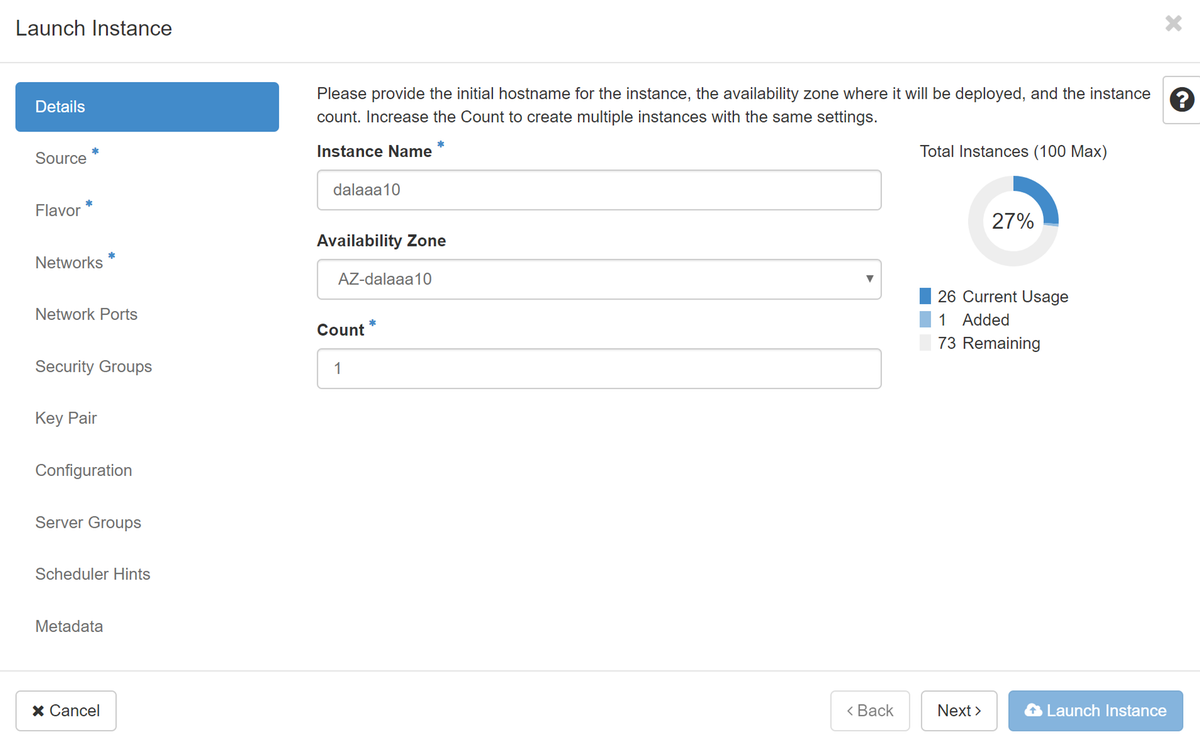
ステップ 4:Horizonで、[プロジェクト] > [インスタンス]に移動し、[インスタンスの起動]をクリックします。

ステップ 5:インスタンス名を入力し、可用性ゾーンを選択します。
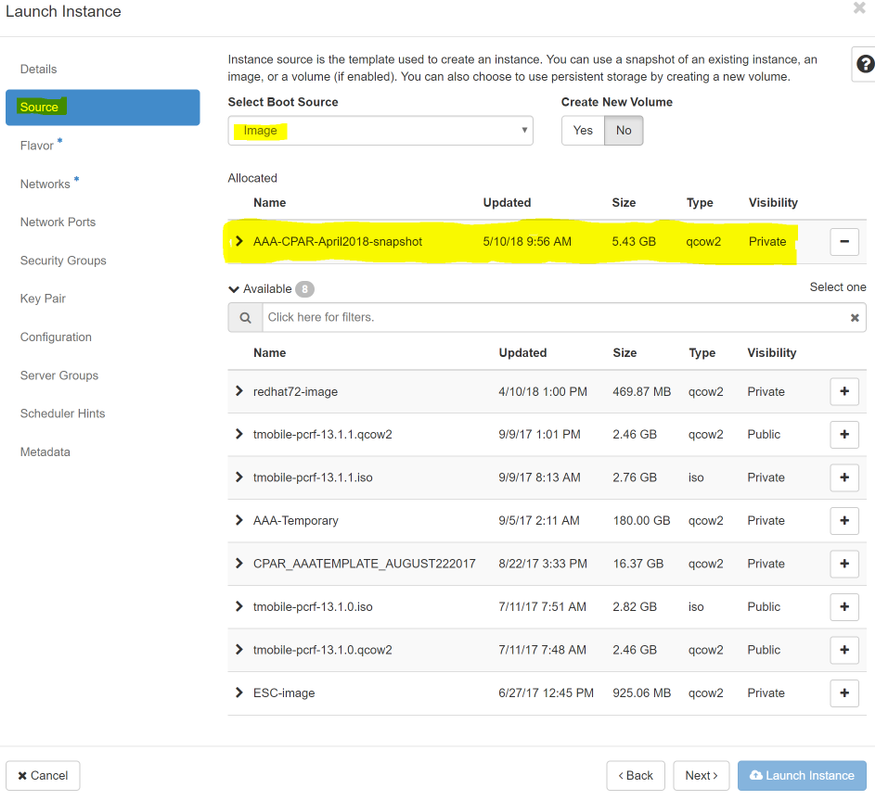
手順 6:[ソース]タブで、インスタンスを作成するイメージを選択します。[Select Boot Source]メニューでイメージを選択して、ここにイメージのリストが表示されます。+記号をクリックすると、以前にアップロードしたイメージを選択します。
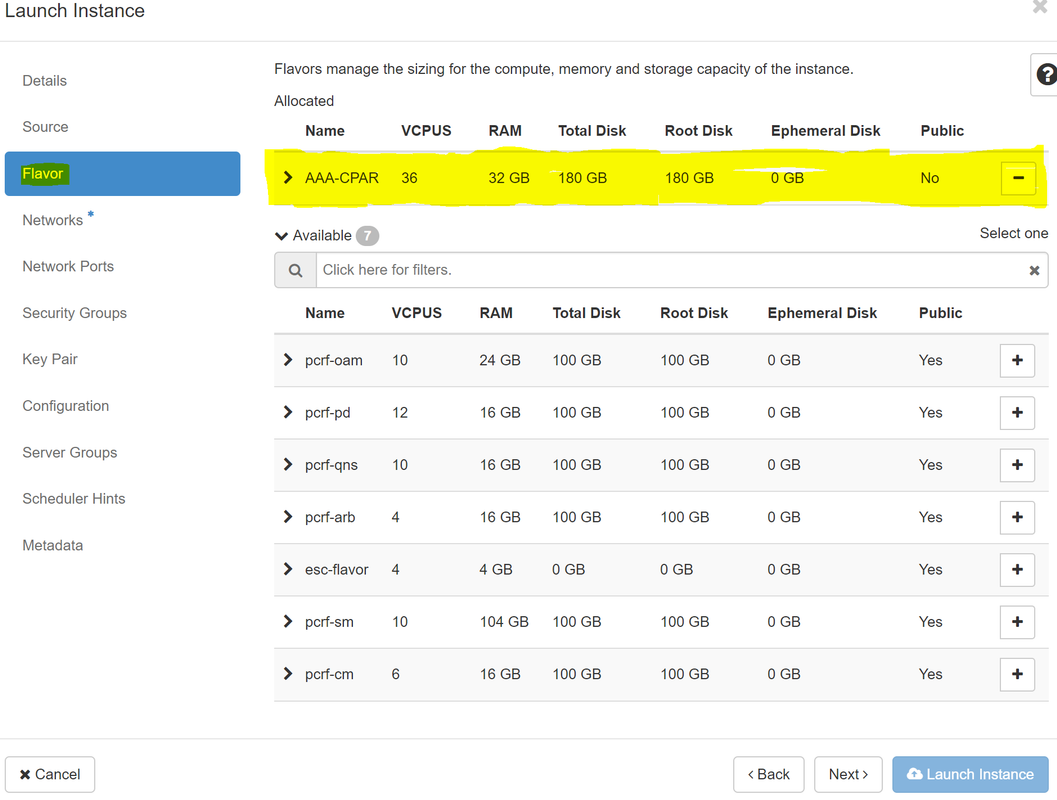
手順 7:[フレーバー]タブで、+記号をクリックしながらAAAフレーバーを選択します。
ステップ8:最後に、[network]タブに移動し、+記号をクリックしてインスタンスに必要なネットワークを選択します。この場合は、diameter-soutable1、radius-routable1、tb1-mgmtを選択します。
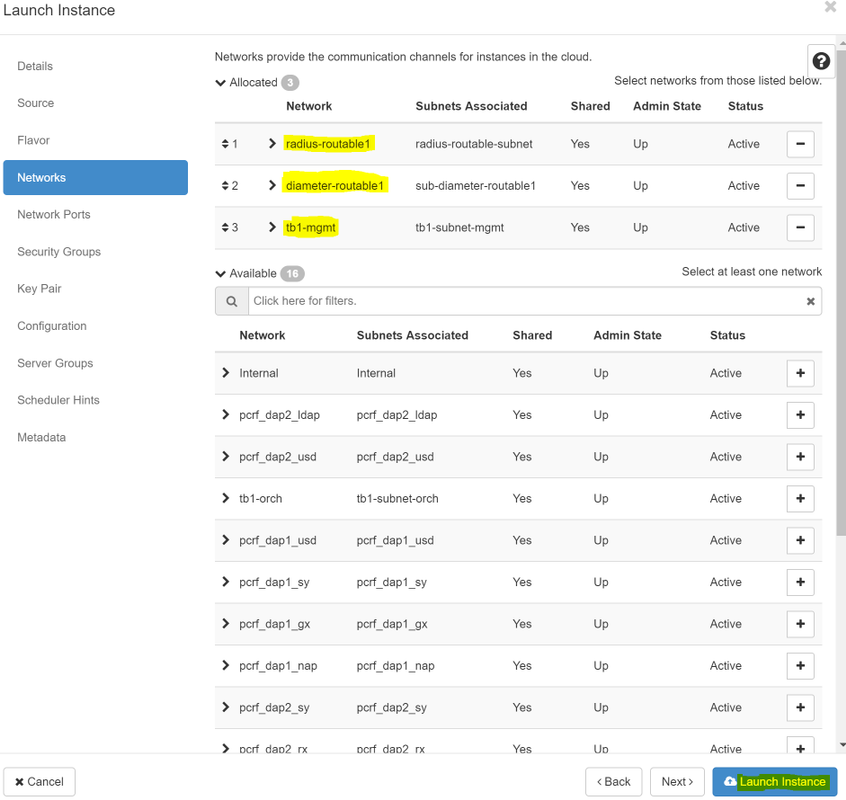
ステップ9:最後に、[Launch instance]をクリックして作成します。進行状況は、次のHorizonで監視できます。
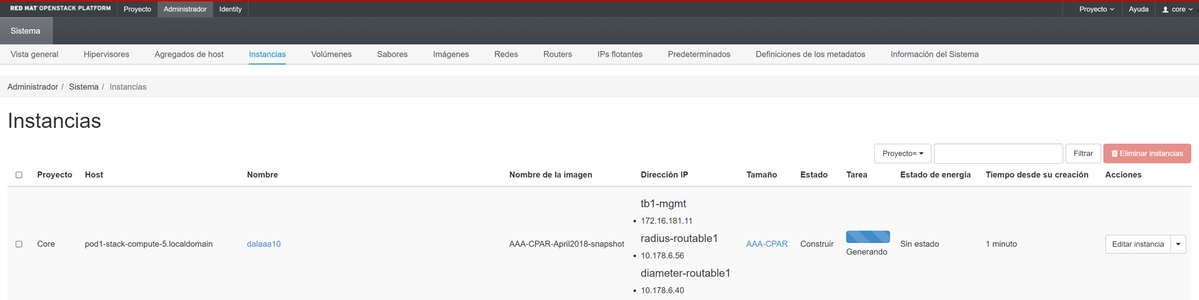
数分後、インスタンスは完全に導入され、使用可能な状態になります。

フローティングIPアドレスの作成と割り当て
フローティングIPアドレスは、ルーティング可能なアドレスです。つまり、Ultra M/Openstackアーキテクチャの外部から到達可能であり、ネットワークの他のノードと通信できます。
ステップ1:[Horizon]トップメニューで、[Admin] > [Floating IPs]に移動します。
ステップ 2:ボタン[AllocateIP to Project]をクリックします。
ステップ3:[Allocate Floating IP]ウィンドウで、新しいフローティングIPが属するプール、割り当て先のプロジェクト、および新しいフローティングIPアドレス自体を選択します。
以下に、いくつかの例を示します。
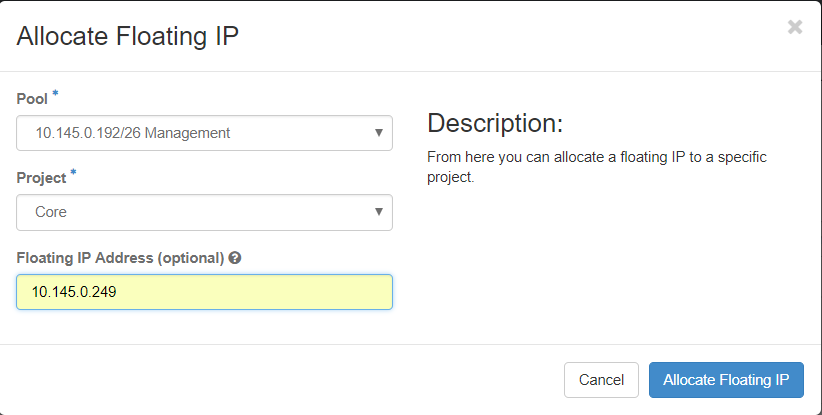
ステップ4:[AllocateFloating IPbutton]をクリックします。
ステップ5:[Horizon]トップメニューで、[Project] > [Instances]に移動します。
ステップ6:[Actioncolumn]で、[Create Snapshot]ボタンの下向きの矢印をクリックすると、メニューが表示されます。Associate Floating IPoptionを選択します。
ステップ7:[IP Address]フィールドで使用する対応するフローティングIPアドレスを選択し、このフローティングIPが関連付けられるポートで割り当てられる新しいインスタンスから対応する管理インターフェイス(eth0)を選択します。この手順の例として、次の図を参照してください。
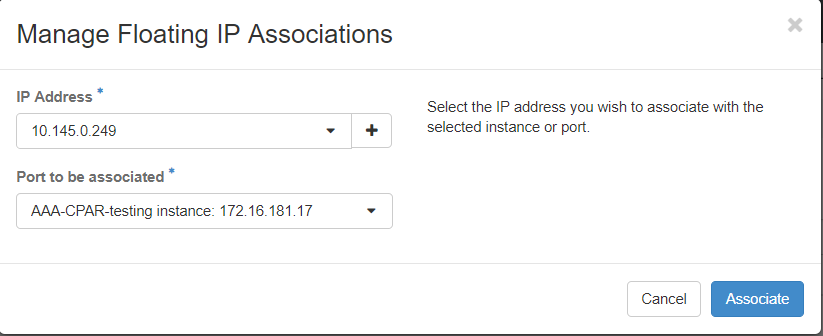
ステップ8:最後に、[関連付け]ボタンをクリックします。
SSHの有効化
ステップ 1:水平線のトップメニューで、「プロジェクト」>「インスタンス」に移動します。
ステップ 2:「新規インスタンスのランチインチ」セクションで作成したインスタンス/VMの名前をクリックします。
ステップ 3:[コンソール]タブをクリックします。VMのCLIが表示されます。
ステップ4:CLIが表示されたら、適切なログインクレデンシャルを入力します。
ユーザ名:root
パスワード:cisco123
ステップ 5:CLIでvi /etc/ssh/sshd_configationコマンドを入力し、ssh設定を編集します。
ステップ6: ssh設定ファイルが開いたら、Itoキーを押してファイルを編集します。次に、ここに示すセクションを探し、最初の行をPasswordAuthenticationnotoPasswordAuthentication yesから変更します。

手順 7:sshd_configファイルの変更を保存するには、Escキーを押し、:wq!と入力します。
ステップ8:コマンドservice sshd restartを実行します。
ステップ9:SSH設定の変更が正しく適用されたことをテストするために、任意のSSHクライアントを開き、インスタンスに割り当てられたフローティングIP(10.145.0.249)とuserrootを使用してリモートのセキュア接続を確立してみます。
SSHセッションの確立
アプリケーションがインストールされている対応するVM/サーバのIPアドレスを使用して、SSHセッションを開きます。

CPARインスタンス開始
アクティビティが完了し、シャットダウンされたサイトでCPARサービスを再確立できたら、次の手順に従ってください。
- Horizonにログインし、[プロジェクト] > [インスタンス] > [インスタンスの開始]に移動します。
- インスタンスのステータスがアクティブで、電源状態が実行中であることを確認します。
アクティビティ後のヘルスチェック
ステップ1:コマンド/opt/CSCOar/bin/arstatusをOSレベルで実行します。
[root@aaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
ステップ2:コマンド/opt/CSCOar/bin/aregcmdをOSレベルで実行し、管理者クレデンシャルを入力します。CPAR Healthが10のうち10であることを確認し、CPAR CLIを終了します。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is Running, its health is 10 out of 10 --> exit
ステップ 3:コマンドnetstatを実行します | grep diameterとして、すべてのDRA接続が確立されていることを確認します。
ここで説明する出力は、Diameterリンクが必要な環境を対象としています。表示されるリンク数が少ない場合は、分析が必要なDRAからの切断を表します。
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
ステップ4:TPSログに、CPARによって処理されている要求が表示されることを確認します。強調表示されている値はTPSを表し、これらは注意が必要な値です。
TPSの値は1500を超えることはできません。
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
ステップ 5:name_radius_1_logで「error」または「alarm」メッセージを探します
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
ステップ 6。次のコマンドを使用して、CPARプロセスが使用するメモリ量を確認します。
top | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
この強調表示された値は、次より小さい値である必要があります。7 Gb(アプリケーションレベルで許可される最大サイズ)。
コントローラノードでのマザーボードの交換
コントローラのステータスを確認し、クラスタをメンテナンスモードにします
OSPDからコントローラにログインし、pcが正常な状態であることを確認します。3つすべてのコントローラOnlineとgaleraは、3つすべてのコントローラをマスターとして表示します。
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:02:52 2018Last change: Mon Jul 2 12:49:52 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
クラスタをメンテナンスモードにする
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster standby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:10 2018Last change: Fri Jul 6 09:03:06 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Node pod2-stack-controller-0: standby
Online: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-1 ]
Stopped: [ pod2-stack-controller-0 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
マザーボードの交換
UCS C240 M4サーバのマザーボードを交換する手順については、『Cisco UCS C240 M4サーバインストールおよびサービスガイド』を参照してください
- CIMC IPを使用してサーバにログインします。
- ファームウェアが以前に使用した推奨バージョンと異なる場合は、BIOSアップグレードを実行します。BIOSアップグレードの手順は次のとおりです。
Cisco UCS CシリーズラックマウントサーバBIOSアップグレードガイド
クラスタステータスの復元
影響を受けるコントローラにログインし、unstandbyを設定してスタンバイモードを削除します。 コントローラがクラスタでオンラインになり、galeraは3つのコントローラすべてをマスターとして表示することを確認します。 これには数分かかることがあります。
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs cluster unstandby
[heat-admin@pod2-stack-controller-0 ~]$ sudo pcs status
Cluster name: tripleo_cluster
Stack: corosync
Current DC: pod2-stack-controller-2 (version 1.1.15-11.el7_3.4-e174ec8) - partition with quorum
Last updated: Fri Jul 6 09:03:37 2018Last change: Fri Jul 6 09:03:35 2018 by root via crm_attribute on pod2-stack-controller-0
3 nodes and 19 resources configured
Online: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Full list of resources:
ip-11.120.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Clone Set: haproxy-clone [haproxy]
Started: [ pod2-stack-controller-0 pod2-stack-controller-1 pod2-stack-controller-2 ]
Master/Slave Set: galera-master [galera]
Masters: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 ]
ip-192.200.0.110(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
ip-11.120.0.44(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
ip-11.118.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
Clone Set: rabbitmq-clone [rabbitmq]
Started: [ pod2-stack-controller-1 pod2-stack-controller-2 ]
Stopped: [ pod2-stack-controller-0 ]
ip-10.225.247.214(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-1
Master/Slave Set: redis-master [redis]
Masters: [ pod2-stack-controller-2 ]
Slaves: [ pod2-stack-controller-0 pod2-stack-controller-1 ]
ip-11.119.0.49(ocf::heartbeat:IPaddr2):Started pod2-stack-controller-2
openstack-cinder-volume(systemd:openstack-cinder-volume):Started pod2-stack-controller-1
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
シスコ エンジニア提供
- Karthikeyan DachanamoorthyCisco Advance Services
- Harshita BhardwajCisco Advance Services
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)