コンピューティングサーバUCS C240 M4の交換 – CPAR
ダウンロード オプション
偏向のない言語
この製品のドキュメントセットは、偏向のない言語を使用するように配慮されています。このドキュメントセットでの偏向のない言語とは、年齢、障害、性別、人種的アイデンティティ、民族的アイデンティティ、性的指向、社会経済的地位、およびインターセクショナリティに基づく差別を意味しない言語として定義されています。製品ソフトウェアのユーザインターフェイスにハードコードされている言語、RFP のドキュメントに基づいて使用されている言語、または参照されているサードパーティ製品で使用されている言語によりドキュメントに例外が存在する場合があります。シスコのインクルーシブ ランゲージの取り組みの詳細は、こちらをご覧ください。
翻訳について
シスコは世界中のユーザにそれぞれの言語でサポート コンテンツを提供するために、機械と人による翻訳を組み合わせて、本ドキュメントを翻訳しています。ただし、最高度の機械翻訳であっても、専門家による翻訳のような正確性は確保されません。シスコは、これら翻訳の正確性について法的責任を負いません。原典である英語版(リンクからアクセス可能)もあわせて参照することを推奨します。
内容
概要
このドキュメントでは、Ultra-Mセットアップで故障したコンピューティングサーバを交換するために必要な手順について説明します。
この手順は、Elastic Services Controller(ESC)がCisco Prime Access Registrar(CPAR)を管理せず、CPARがOpenstackに導入されたVMに直接インストールされているNEWTONバージョンを使用するOpenstack環境に適用されます。
背景説明
Ultra-Mは、VNFの導入を簡素化するために設計された、パッケージ化および検証済みの仮想化モバイルパケットコアソリューションです。OpenStackは、Ultra-M向けの仮想化インフラストラクチャマネージャ(VIM)で、次のノードタイプで構成されています。
- 計算
- オブジェクトストレージディスク – コンピューティング(OSD – コンピューティング)
- コントローラ
- OpenStackプラットフォーム – Director(OSPD)
Ultra-Mのアーキテクチャと関連するコンポーネントを次の図に示します。
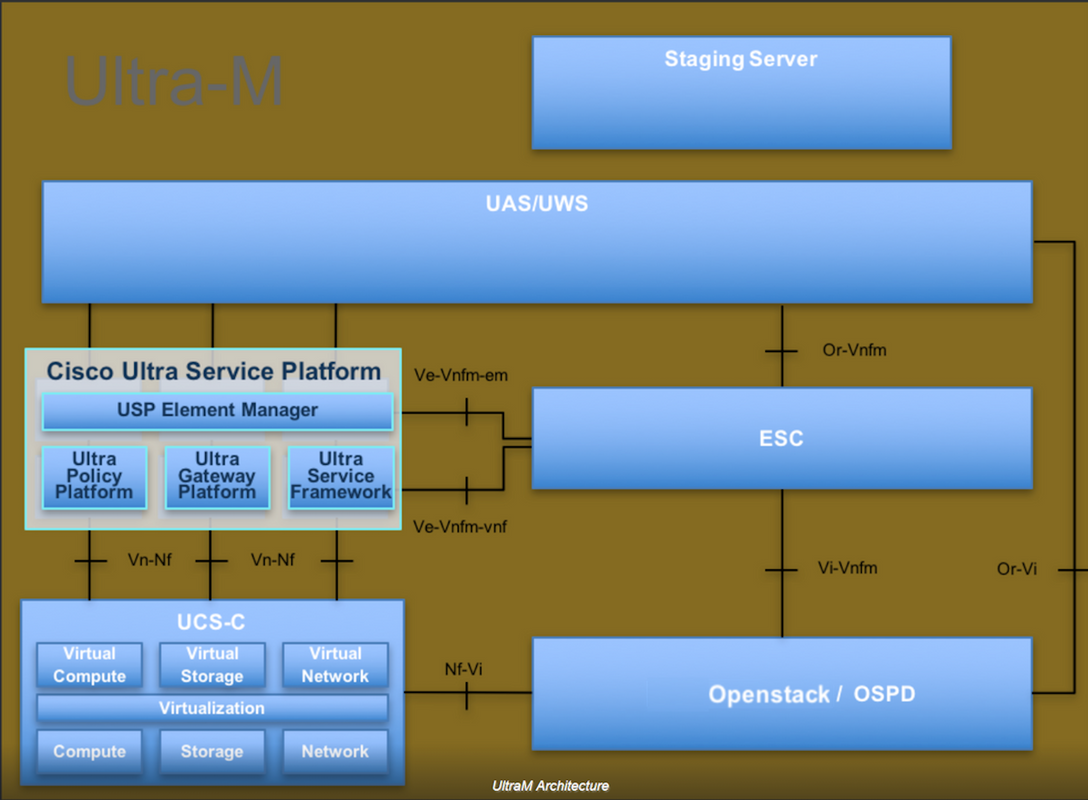
このドキュメントは、Cisco Ultra-Mプラットフォームに精通しているシスコ担当者を対象としており、OpenStackおよびRedhat OSで実行する必要がある手順の詳細を説明しています。
注:このドキュメントの手順を定義するために、Ultra M 5.1.xリリースが検討されています。
省略形
| MOP | 手続きの方法 |
| OSD | オブジェクトストレージディスク |
| OSPD | OpenStack Platform Director |
| HDD | ハードディスクドライブ |
| SSD | ソリッドステートドライブ |
| VIM | 仮想インフラストラクチャマネージャ |
| VM | 仮想マシン |
| EM | エレメント マネージャ |
| UAS | Ultra Automation Services |
| UUID | ユニバーサル一意IDentifier |
MoPのワークフロー
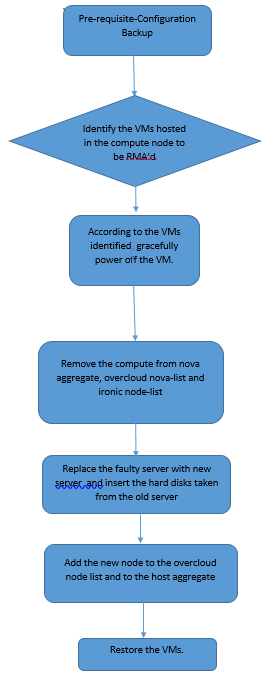
前提条件
バックアップ
コンピュートノードを置き換える前に、Red Hat OpenStackプラットフォーム環境の現在の状態を確認することが重要です。コンピューティングの交換プロセスがオンの場合は、複雑さを避けるために現在の状態を確認することをお勧めします。この交換フローによって実現できます。
リカバリの場合は、次の手順を使用してOSPDデータベースのバックアップを取ることを推奨します。
[root@ al03-pod2-ospd ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@ al03-pod2-ospd ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
このプロセスにより、インスタンスの可用性に影響を与えることなく、ノードを確実に交換できます。
注:必要に応じてVMをリストアできるように、インスタンスのスナップショットがあることを確認します。VMのスナップショットを作成する手順は、次のとおりです。
コンピューティングノードでホストされるVMの特定
コンピューティングサーバでホストされているVMを特定します。
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
注:ここに示す出力では、最初の列が汎用一意識別子(UUID)に対応し、2番目の列がVM名、3番目の列がVMが存在するホスト名です。この出力のパラメータは、以降のセクションで使用します。
スナップショットプロセス
CPARアプリケーションのシャットダウン
ステップ1:ネットワークに接続されているすべてのSSHクライアントを開き、CPARインスタンスに接続します。
1つのサイト内のすべての4つのAAAインスタンスを同時にシャットダウンしないようにし、1つずつ実行することが重要です。
ステップ2:次のコマンドを使用して、CPARアプリケーションをシャットダウンします。
/opt/CSCOar/bin/arserver stop
「Cisco Prime Access Registrar Server Agent shutdown complete」というメッセージが表示されます。 表示されます。
注:ユーザがCLIセッションを開いたままにすると、arserver stopコマンドが動作せず、次のメッセージが表示されます。
ERROR: You can not shut down Cisco Prime Access Registrar while the
CLI is being used. Current list of running
CLI with process id is:
2903 /opt/CSCOar/bin/aregcmd –s
この例では、CPARを停止する前に、強調表示されたプロセスID 2903を終了する必要があります。このような場合は、次のコマンドを使用してプロセスを終了します。
kill -9 *process_id*
次に、手順1を繰り返します。
ステップ3:次のコマンドで、CPARアプリケーションが実際にシャットダウンされたことを確認します。
/opt/CSCOar/bin/arstatus
次のメッセージが表示されます。
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
VMスナップショットタスク
ステップ1:現在作業中のサイト(都市)に対応するHorizon GUI Webサイトを入力します。Horizonにアクセスすると、図に示す画面が表示されます。
ステップ2:図に示すように、[プロジェクト] > [インスタンス]に移動します。
ユーザがcparの場合、このメニューには4つのAAAインスタンスだけが表示されます。
ステップ3:一度に1つのインスタンスだけをシャットダウンし、このドキュメントのプロセス全体を繰り返します。VMをシャットダウンするには、[Actions] > [Shut Off Instance]に移動し、選択を確定します。

ステップ4インスタンスが実際にシャットダウンされたことを、ステータス=シャットオフおよび電源状態=シャットダウンで確認します。
この手順により、CPARシャットダウンプロセスが終了します。
VMスナップショット
CPAR VMがダウンすると、スナップショットは独立した計算に属するため、並行して取得できます。
4つのQCOW2ファイルが並行して作成されます。
各AAAインスタンスのスナップショット(25分~1時間)(ソースとしてqcowイメージを使用したインスタンスは25分、ソースとしてrawイメージを使用するインスタンスは1時間)を取得します。
ステップ1:PODのOpenstackのHorizon GUIにログインします。
ステップ2:ログインしたら、トップメニューの[Project] > [Compute] > [Instances]セクションに進み、AAAインスタンスを探します。
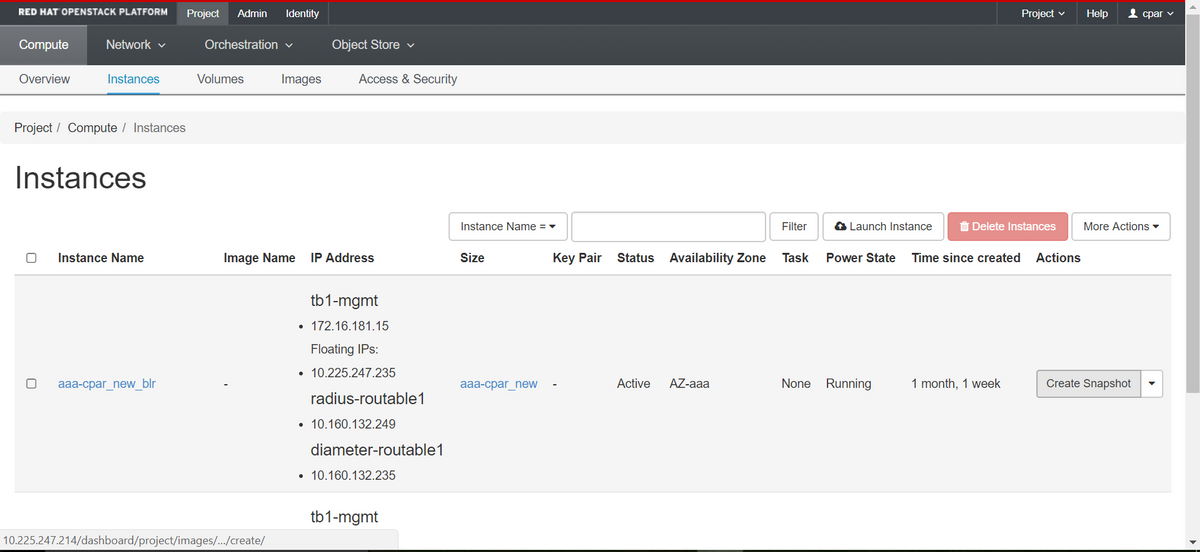
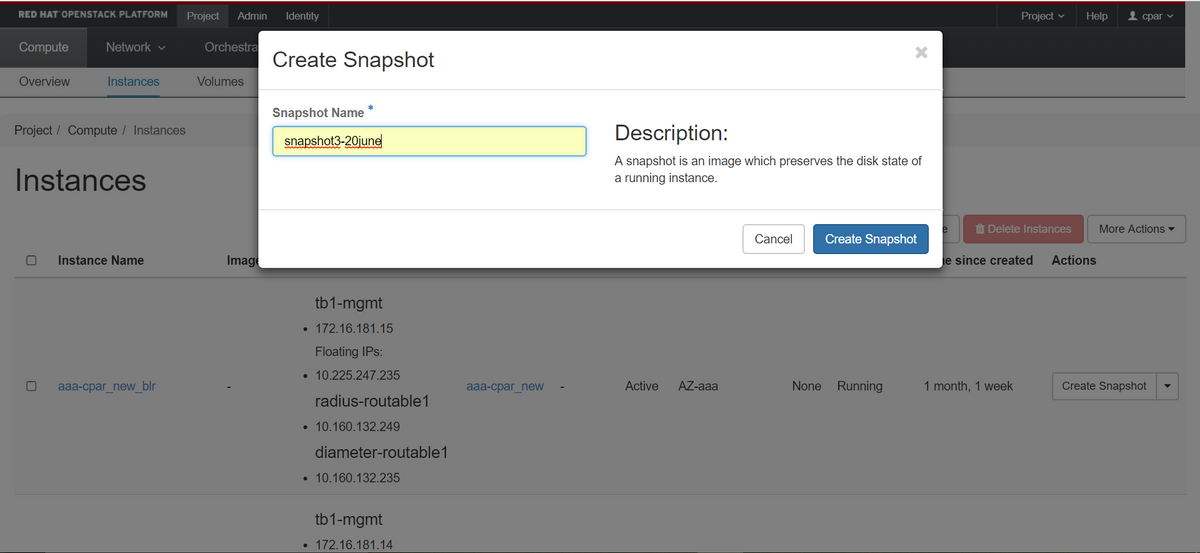
ステップ3:[Create Snapshot]をクリックして、スナップショットの作成を続行します(これは、対応するAAAインスタンスで実行する必要があります)。
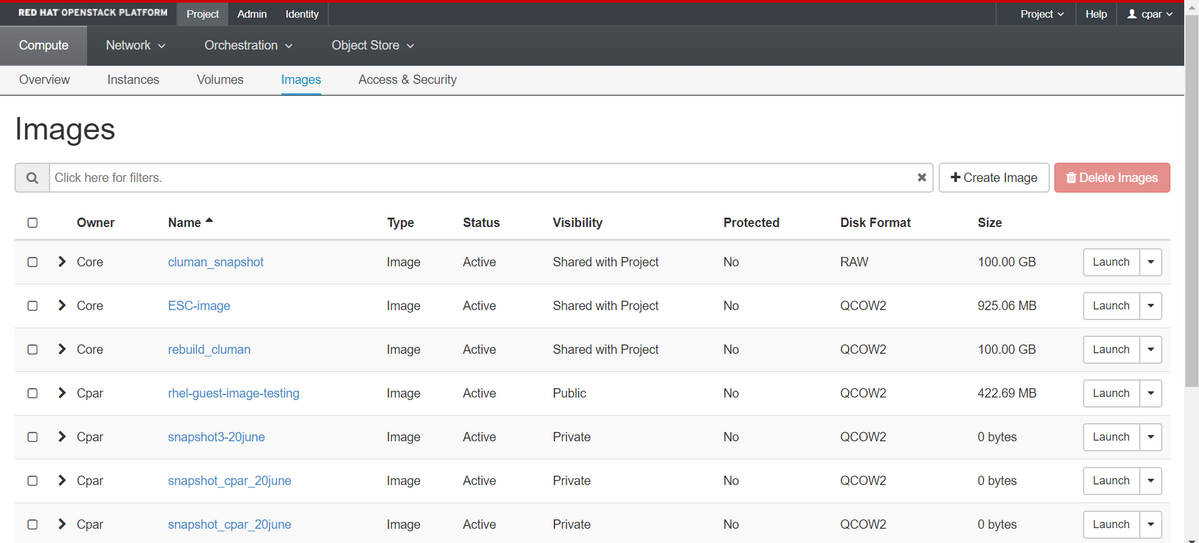
ステップ4:スナップショットが実行されたら、[イメージ]メニューに移動し、完了し、問題が報告されていないことを確認します。
ステップ5:次のステップは、QCOW2形式でスナップショットをダウンロードし、このプロセス中にOSPDが失われた場合に備えてリモートエンティティに転送することです。これを行うには、次のコマンドglance image-listを使用してスナップショットをOSPDレベルで識別してください
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
ステップ6:ダウンロードするスナップショット(この場合は上の緑色で示すスナップショット)を特定したら、次のコマンドglance image-downloadを使用してQCOW2形式でダウンロードします。
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- 「&」は、プロセスをバックグラウンドに送信します。この操作を完了するには時間がかかります。完了すると、イメージは/tmpディレクトリに置かれます。
- プロセスがバックグラウンドに送信されると、接続が失われると、プロセスも停止します。
- disown -hコマンドを実行し、セキュアシェル(SSH)接続が失われた場合でも、プロセスがOSPDで実行され、終了します。
ステップ7:ダウンロード処理が終了したら、圧縮プロセスを実行する必要があります。これは、オペレーティングシステムによって処理されるプロセス、タスク、一時ファイルが原因で、スナップショットにゼロが埋まる可能性があるためです。ファイル圧縮に使用するコマンドはvirt-sparsifyです。
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
このプロセスには時間がかかります(約10 ~ 15分)。 完了すると、次の手順で指定した外部エンティティに転送する必要があるファイルが生成されます。
ファイルの整合性を確認する必要があります。これを行うには、次のコマンドを実行し、出力の最後に破損した属性を探します。
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
OSPDが失われる問題を回避するには、QCOW2形式で最近作成したスナップショットを外部エンティティに転送する必要があります。ファイル転送を開始する前に、宛先に十分な空きディスク領域があるかどうかを確認するには、コマンドdf -khを使用して、メモリ領域を確認します。SFTP sftp root@x.x.x.x(x.x.x.xはリモートOSPDののです)。転送を高速化するために、宛先を複数のOSPDに送信できます。同様に、このコマンドをscp *name_of_the_file*.qcow2 root@ x.x.x.x.x:/tmp(x.x.x.xはリモートOSPDのIP)を使用して、ファイルを別のOSPDに転送できます。
グレースフルパワーオフ
ノードの電源オフ
- インスタンスの電源をオフにするには:nova stop <INSTANCE_NAME>
- これで、インスタンス名とステータスシャットオフが表示されます。
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
コンピューティングノードの削除
このセクションで説明する手順は、コンピューティングノードでホストされるVMに関係なく共通できます。
サービスリストからのコンピューティングノードの削除
サービスリストからコンピュートサービスを削除します。
[stack@director ~]$ openstack compute service list |grep compute-3 | 138 | nova-compute | pod2-stack-compute-3.localdomain | AZ-aaa | enabled | up | 2018-06-21T15:05:37.000000 |
openstack 計算 service delete <ID>
[stack@director ~]$ openstack compute service delete 138
Neutronエージェントの削除
古い関連付けられたNeutronエージェントを削除し、コンピューティングサーバのvswitchエージェントを開きます。
[stack@director ~]$ openstack network agent list | grep compute-3 | 3b37fa1d-01d4-404a-886f-ff68cec1ccb9 | Open vSwitch agent | pod2-stack-compute-3.localdomain | None | True | UP | neutron-openvswitch-agent |
openstack network agent delete <ID>
[stack@director ~]$ openstack network agent delete 3b37fa1d-01d4-404a-886f-ff68cec1ccb9
Ironicデータベースから削除
皮肉なデータベースからノードを削除し、確認します。
nova show <計算-node> | grep hypervisor
[root@director ~]# source stackrc [root@director ~]# nova show pod2-stack-compute-4 | grep hypervisor | OS-EXT-SRV-ATTR:hypervisor_hostname | 7439ea6c-3a88-47c2-9ff5-0a4f24647444
ironic node-delete <ID>
[stack@director ~]$ ironic node-delete 7439ea6c-3a88-47c2-9ff5-0a4f24647444 [stack@director ~]$ ironic node-list
削除されたノードを皮肉なノードリストにリストすることはできません。
オーバークラウドから削除
ステップ1:次に示す内容のdelete_node.shという名前のスクリプトファイルを作成します。記載されているテンプレートが、スタック配置に使用されるdeploy.shスクリプトと同じであることを確認します。
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack <stack-name> <UUID>
[stack@director ~]$ source stackrc [stack@director ~]$ /bin/sh delete_node.sh + openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod2-stack 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Deleting the following nodes from stack pod2-stack: - 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae real 0m52.078s user 0m0.383s sys 0m0.086s
ステップ2:OpenStackスタックの動作がCOMPLETE状態になるまで待ちます。
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod2-stack | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
新しいコンピューティングノードのインストール
新しいUCS C240 M4サーバのインストール手順と初期セットアップ手順については、『Cisco UCS C240 M4サーバインストールおよびサービスガイド』を参照してください
ステップ1:サーバのインストール後、ハードディスクを古いサーバとしてそれぞれのスロットに挿入します。
ステップ2:CIMC IPを使用してサーバにログインします。
ステップ3:ファームウェアが以前に使用した推奨バージョンと異なる場合は、BIOSアップグレードを実行します。BIOSアップグレードの手順は次のとおりです。Cisco UCS CシリーズラックマウントサーバBIOSアップグレードガイド
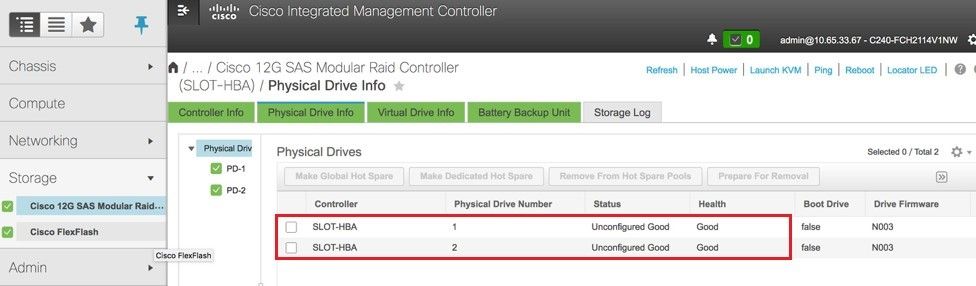
ステップ4:[Unconfigured Good]の物理ドライブのステータスを確認するには、[Storage] > [Cisco 12G SAS Modular Raid Controller (SLOT-HBA)] > [Physical Drive Info]に移動します。
ステップ5:RAIDレベル1の物理ドライブから仮想ドライブを作成するには、[Storage] > [Cisco 12G SAS Modular Raid Controller (SLOT-HBA)] > [Controller Info] > [Create Virtual Drive from Unused Physical Drives]に移動します。
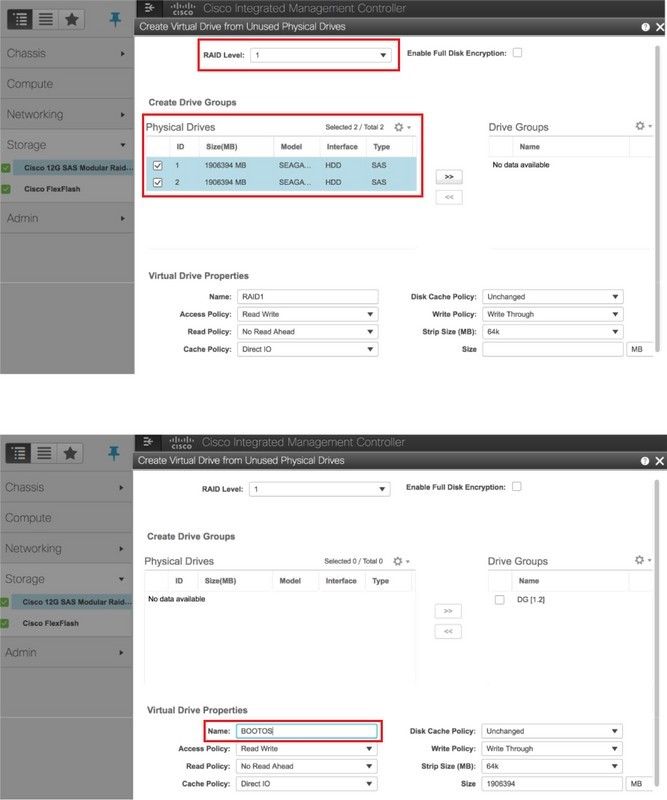
ステップ6:VDを選択し、図に示すように[Set as Boot Drive]を設定します。

ステップ7:IPMI over LANを有効にするには、図に示すように、[Admin] > [Communication Services] > [Communication Services]に移動します。

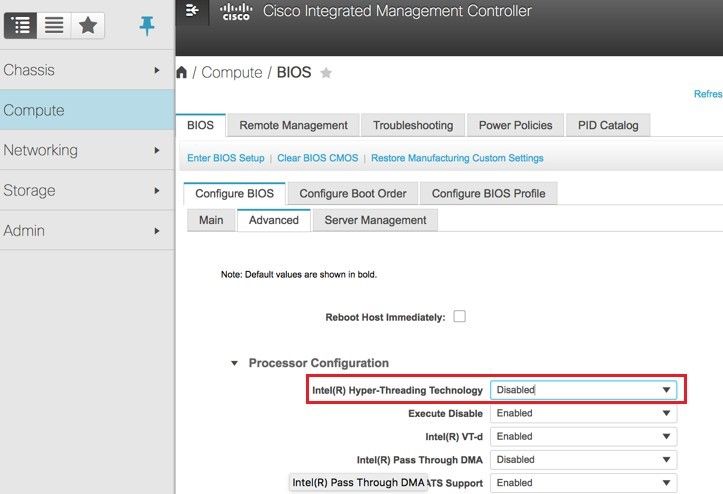
ステップ8:ハイパースレッディングをディセーブルにするには、[Compute] > [BIOS] > [Configure BIOS] > [Advanced] > [Processor Configuration]に移動します。
注:このセクションで説明するイメージと設定手順は、ファームウェアバージョン3.0(3e)を参照するもので、他のバージョンで作業する場合は、若干の違いがあります。
新しいコンピューティングノードをオーバークラウドに追加する
このセクションで説明する手順は、コンピューティングノードによってホストされるVMに関係なく共通しています。
ステップ1:異なるインデックスを持つコンピュートサーバを追加する
追加する新しいコンピュートサーバの詳細のみを含むadd_node.jsonファイルを作成します。新しいコンピュートサーバのインデックス番号が以前に使用されていないことを確認します。通常は、次に高い計算値を増やします。
例:最も前はcompute-17なので、2-vnfシステムの場合、compute-18が作成されました。
注:json形式に注意してください。
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
ステップ2: jsonファイルをインポートします。
[stack@director ~]$ openstack baremetal import --json add_node.json Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e Successfully set all nodes to available.
ステップ3:前のステップでメモしたUUIDを使用して、ノードのイントロスペクションを実行します。
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e [stack@director ~]$ ironic node-list |grep 7eddfa87 | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False | [stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c Waiting for introspection to finish... Successfully introspected all nodes. Introspection completed. Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9 Successfully set all nodes to available. [stack@director ~]$ ironic node-list |grep available | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
ステップ4:新しいコンピュータノードをオーバークラウドスタックに追加するために、スタックの展開に以前に使用したdeploy.shスクリプトを実行します。
[stack@director ~]$ ./deploy.sh ++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180 … Starting new HTTP connection (1): 192.200.0.1 "POST /v2/action_executions HTTP/1.1" 201 1695 HTTP POST http://192.200.0.1:8989/v2/action_executions 201 Overcloud Endpoint: http://10.1.2.5:5000/v2.0 Overcloud Deployed clean_up DeployOvercloud: END return value: 0 real 38m38.971s user 0m3.605s sys 0m0.466s
ステップ5:openstackスタックのステータスが[Complete]になるまで待ちます。
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
ステップ6:新しいコンピュートノードがアクティブ状態であることを確認します。
[root@director ~]# nova list | grep pod2-stack-compute-4 | 5dbac94d-19b9-493e-a366-1e2e2e5e34c5 | pod2-stack-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.116 |
VMのリストア
スナップショットによるインスタンスのリカバリ
リカバリプロセス:
前のステップで実行したスナップショットを使用して、前のインスタンスを再展開できます。
ステップ1 [オプション]使用可能な以前のVMsnapshotがない場合、バックアップが送信されたOSPDノードに接続し、バックアップを元のOSPDノードにsftpします。sftp root@x.x.x.xを介して、x.x.x.xは元のOSPDののIPです。スナップショットファイルを/tmpディレクトリに保存します。
ステップ2:インスタンスが再展開されるOSPDノードに接続します。

次のコマンドを使用して、環境変数をソース化します。
# source /home/stack/pod1-stackrc-Core-CPAR
ステップ3:イメージとしてスナップショットを使用するには、スナップショットを地平線にアップロードする必要があります。次のコマンドを使用して実行します。
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
このプロセスは水平線で確認できます。

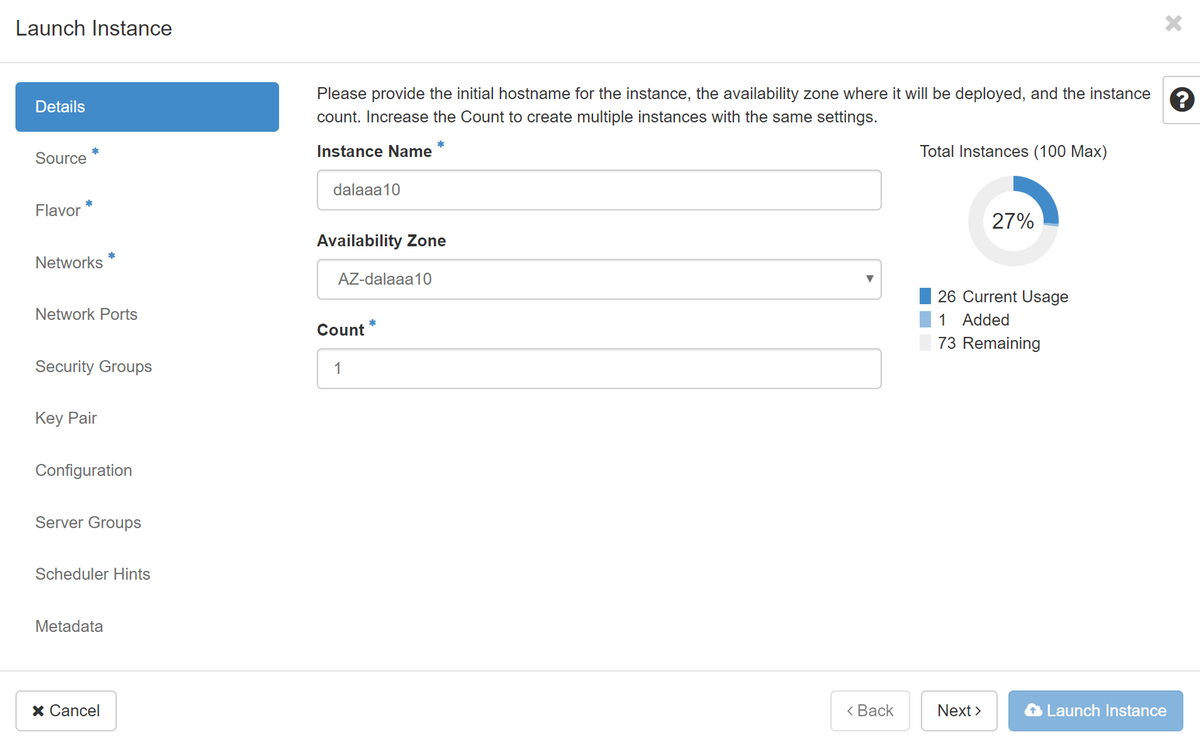
ステップ4:ホライズンで、[プロジェクト] > [インスタンス]に移動し、図に示すように[インスタンスの起動]をクリックします。

ステップ5:図に示すように、インスタンス名を入力し、[Availability Zone]を選択します。
ステップ6:[Source]タブで、インスタンスを作成するイメージを選択します。[Select Boot Source]メニューで[image]を選択しますが、ここに画像のリストが表示されて、+記号をクリックしてアップロードした画像を選択します。
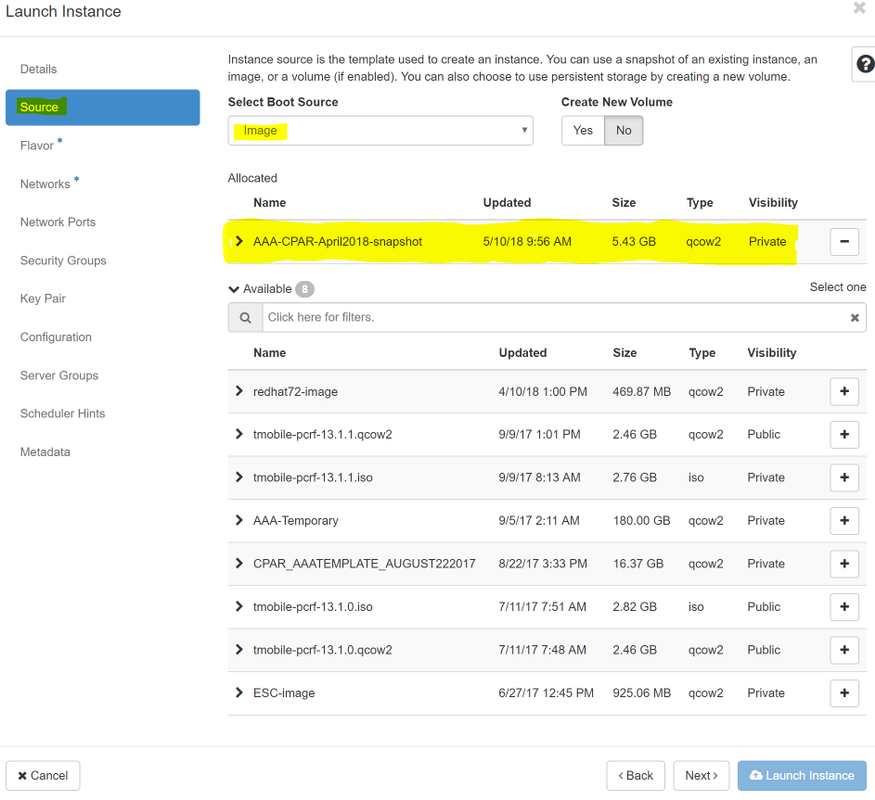
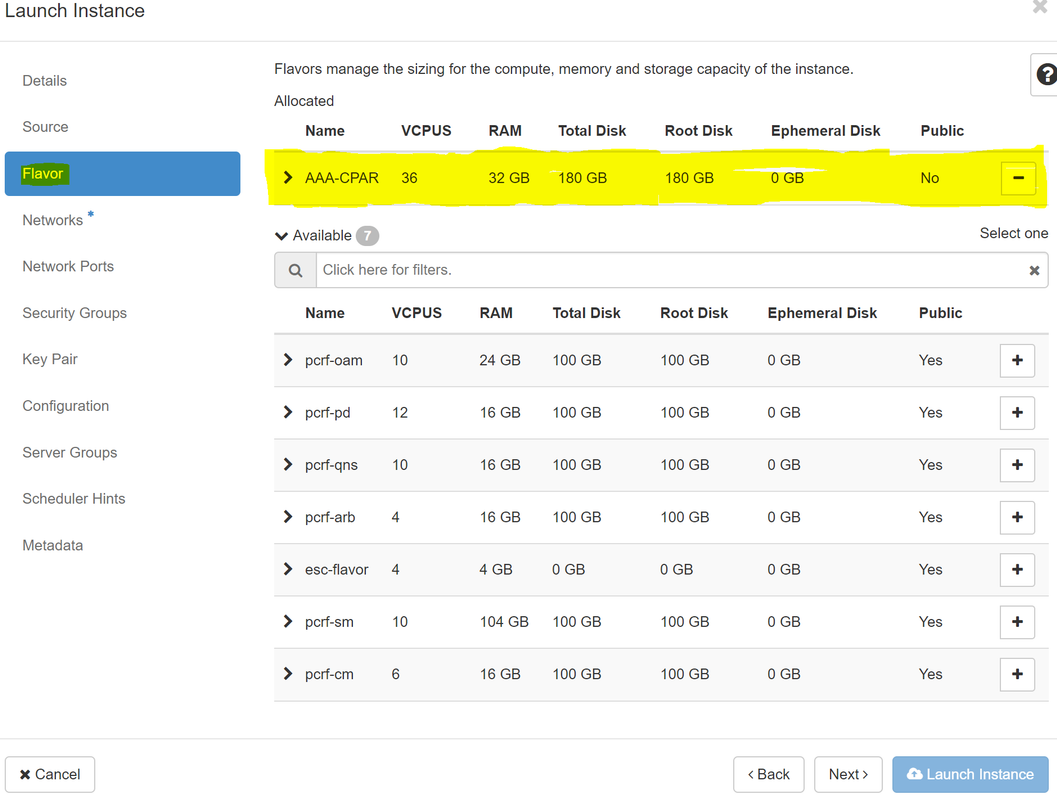
ステップ7:[Flavor]タブで、図に示すように、+記号をクリックしてAAAフレーバーを選択します。
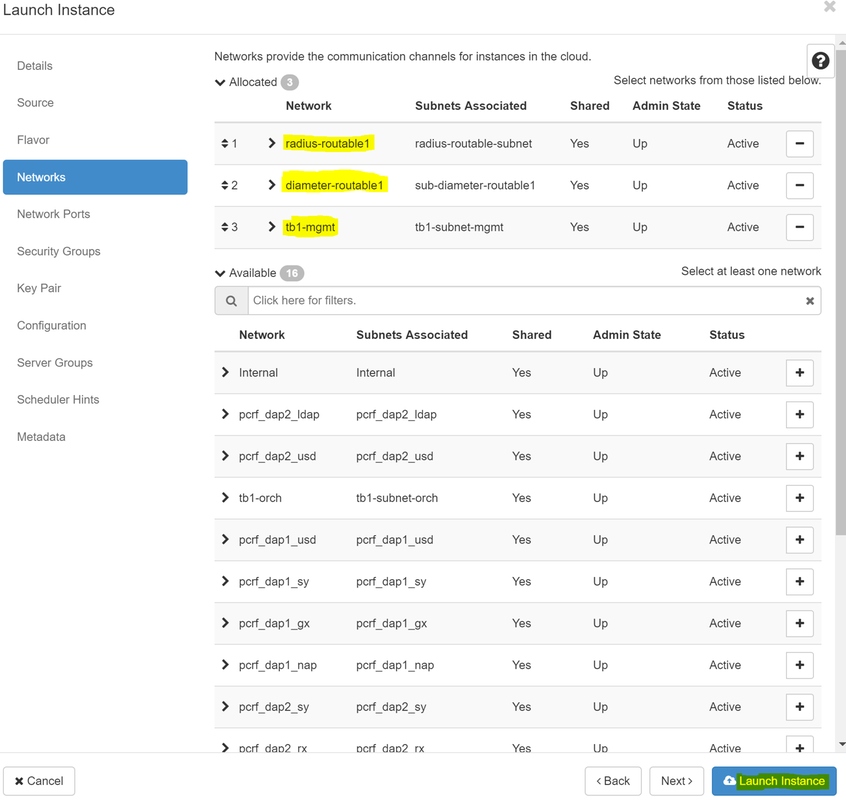
ステップ8:[Networks]タブに移動し、+記号をクリックして、インスタンスに必要なネットワークを選択します。この場合、図に示すように、diameter-soutable1、radius-routable1、およびtb1-mgmtを選択します。
ステップ9:[Launch instance]をクリックして作成します。進行状況は、次のHorizonで監視できます。
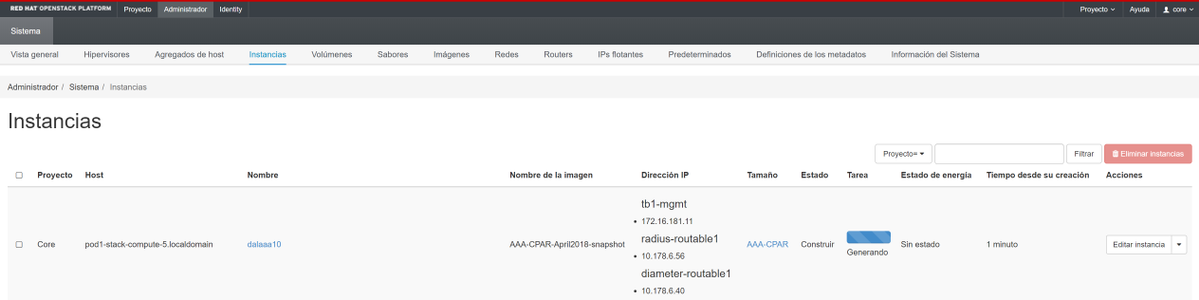
数分後に、インスタンスが完全に導入され、使用可能な状態になります。

フローティングIPアドレスの作成と割り当て
フローティングIPアドレスは、ルーティング可能なアドレスです。つまり、Ultra M/Openstackアーキテクチャの外部から到達可能であり、ネットワークの他のノードと通信できます。
ステップ1:[Horizon]トップメニューで、[Admin] > [Floating IPs]に移動します。
ステップ2:[プロジェクトにIPを割り当て]ボタンをクリックします。
ステップ3:[Allocate Floating IP]ウィンドウで、新しいフローティングIPが属するプール、割り当て先のプロジェクト、新しいフローティングIPアドレスを選択します。
以下に、いくつかの例を示します。
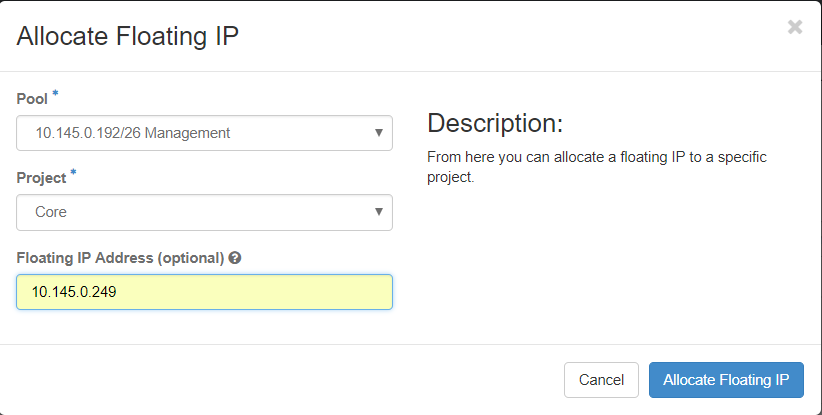
ステップ4:[Allocate Floating IP]ボタンをクリックします。
ステップ5:[Horizon]トップメニューで、[Project] > [インスタンス]に移動します。
ステップ6:[アクション]列で、[スナップショットの作成]ボタンを下に向く矢印をクリックすると、メニューが表示されます。[Associate Floating IP]オプションを選択します。
ステップ7:[IP Address]フィールドで使用する対応するフローティングIPアドレスを選択し、関連付けるポートでこのフローティングIPが割り当てられる新しいインスタンスから対応する管理インターフェイス(eth0)を選択します。この手順の例として、次の図を参照してください。
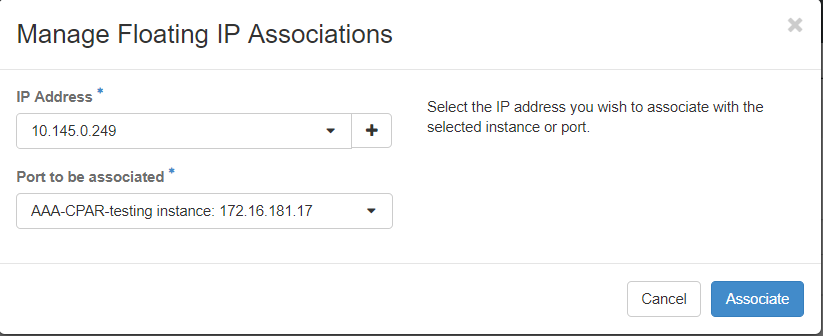
ステップ8:[Associate]をクリックします。
SSH の有効化
ステップ1:[Horizon]トップメニューで、[Project] > [インスタンス]に移動します。
ステップ2:セクション「新規インスタンスのランチインプ」で作成したインスタンス/VMの名前をクリックします。
ステップ3:[Console]タブをクリックします。VMのCLIが表示されます。
ステップ4:CLIが表示されたら、適切なログインクレデンシャルを入力します。
ユーザ名:root
パスワード:Cisco123
ステップ5:CLIでコマンドvi /etc/ssh/sshd_configを入力し、ssh設定を編集します。
ステップ6: ssh設定ファイルが開いたら、Iを押してファイルを編集します。次に、次に示すセクションを探し、最初の行をPasswordAuthentication noからPasswordAuthentication yesに変更します。

ステップ7: Escキーを押して:wq!sshd_configファイルの変更を保存します。
ステップ8:service sshd restartコマンドを実行します。
ステップ9:SSH設定の変更が正しく適用されたことをテストするために、任意のSSHクライアントを開き、インスタンスに割り当てられたフローティングIP(10.145.0.249)とユーザrootを使用してリモートセキュア接続を確立します。
SSHセッションの確立
アプリケーションがインストールされている対応するVM/サーバのIPアドレスでSSHセッションを開きます。

CPARインスタンス開始
アクティビティが完了し、シャットダウンされたサイトでCPARサービスを再確立できたら、次の手順に従ってください。
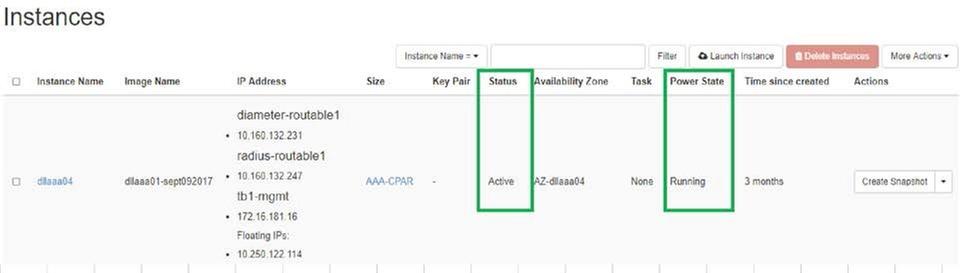
- Horizonにログインし直すには、[Project] > [Instance] > [Start Instance] に移動します。
- インスタンスのステータスがアクティブで、電源状態が実行中であることを確認します。
アクティビティ後のヘルスチェック
ステップ1:OSレベルでコマンド/opt/CSCOar/bin/arstatusを実行します。
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
ステップ2:OSレベルでコマンド/opt/CSCOar/bin/aregcmdを実行し、管理者クレデンシャルを入力します。CPAR Healthが10のうち10であることを確認し、CPAR CLIを終了します。
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd
Cisco Prime Access Registrar 7.3.0.1 Configuration Utility
Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved.
Cluster:
User: admin
Passphrase:
Logging in to localhost
[ //localhost ]
LicenseInfo = PAR-NG-TPS 7.2(100TPS:)
PAR-ADD-TPS 7.2(2000TPS:)
PAR-RDDR-TRX 7.2()
PAR-HSS 7.2()
Radius/
Administrators/
Server 'Radius' is Running, its health is 10 out of 10
--> exit
ステップ3:コマンドnetstatを実行する | grep diameterとして、すべてのDRA接続が確立されていることを確認します。
次に示す出力は、Diameterリンクが想定される環境を対象としています。表示されるリンク数が少ない場合は、分析が必要なDRAからの切断を表します。
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
ステップ4:TPSログに、CPARによって処理されている要求が表示されることを確認します。強調表示されている値はTPSを表し、これらは注意が必要な値です。
TPSの値は1500を超えることはできません。
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
ステップ5:name_radius_1_logで「error」または「alarm」メッセージを探します
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
ステップ6:次のコマンドを使用して、CPARプロセスのメモリ量を確認します。
top | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
この強調表示された値は、次より小さい値である必要があります。7 Gb(アプリケーションレベルで許可される最大サイズ)。
シスコ エンジニア提供
- Karthikeyan DachanamoorthyCisco Advance Services
- Harshita BhardwajCisco Advance Services
 フィードバック
フィードバックシスコに問い合わせ
- サポート ケースをオープン

- (シスコ サービス契約が必要です。)