サービス レベル管理:ベスト プラクティス ホワイト ペーパー
内容
概要
この文書は、ハイアベイラビリティ ネットワークのサービス レベル管理と Service-Level Agreement(SLA; サービス レベル契約)について説明しています。これには、成功の評価を行うためのサービス レベル管理に関する重要な成功要因とパフォーマンス インジケータが含まれています。さらに、ハイアベイラビリティ サービス チームによって明らかにされた最適な方法のガイドラインに基づき、SLA について詳細に説明します。
サービス レベル管理の概要
従来、ネットワーク組織は、堅牢なネットワーク インフラストラクチャを構築し、個々のサービスの問題に事後処理的に対処することで、拡大するネットワーク要件を満たしてきました。ネットワークが停止すると、同じ原因による停止が二度と発生しないように、新しいプロセス、管理能力、またはインフラストラクチャを構築します。しかし、変化速度が大きく、アベイラビリティの要求が増え続けているため、計画外のダウンタイムを事前に防止し、すぐにネットワークを修復する必要が生じています。多くのサービス プロバイダーや企業組織は、企業目標の達成に必要なサービス レベルの定義を向上させようとしました。
重要な成功要因
SLA の重要な成功要因は、取得できるサービス レベルを正常に構築して SLA を維持する重要な要素を定義するために使用されます。重要な成功要因として認められるには、プロセスまたはプロセスのステップが SLA の品質を向上させ、ネットワーク アベイラビリティ全般に対してプラスの効果を与えることが必要条件となります。また、重要な成功要因は測定できる必要があり、これによって組織では、その成功要因が、定義された手順に対してどの程度成果をあげているかを判断できます。
詳細については、「サービス レベル管理の実装」を参照してください。
パフォーマンス指標
パフォーマンス指標は、重要な成功要因を測定するための仕組みを提供します。通常はパフォーマンス指標を月に 1 回検討することで、サービス レベル定義または SLA がうまく機能しているかどうかを確認します。ネットワーク運用グループおよび必須ツール グループでは次の規準を実行できます。
注:SLAが適用されていない組織では、メトリックに加えて、サービスレベル定義とサービスレベルのレビューを実行することをお勧めします。
パフォーマンス指標には、次のようなものがあります。
-
文書化されたサービス レベル定義または SLA。アベイラビリティ、パフォーマンス、事後処理的なサービス応答時間、問題解決の目標と問題の報告などが含まれます。
-
月に 1 度行うネットワークのサービス レベルのレビュー ミーティング。サービス レベルのコンプライアンスを確認し、改善点を実装するために行います。
-
パフォーマンス指標の規準。アベイラビリティ、パフォーマンス、優先順位別のサービス応答時間、優先順位別の解決時間、その他の測定可能な SLA パラメータなどが含まれます。
詳細については、「サービス レベル管理の実装」を参照してください。
サービス レベル管理のプロセス フロー
サービス レベル管理の高レベル プロセス フローには 2 つの主要なグループがあります。
次の図のオブジェクトをクリックすると、その手順の詳細が表示されます。
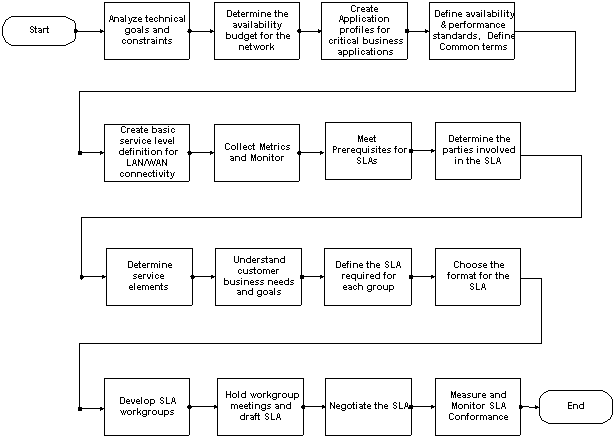
サービス レベル管理の実装
サービス レベル管理の実装は、次の 2 つの主なカテゴリに分けられる 16 の手順から構成されます。
ネットワーク サービス レベルの定義
ネットワーク マネージャは、ネットワークをサポート、管理、および測定する主なルールを定義する必要があります。サービス レベルはすべてのネットワーク利用者のための目標を定めるもので、サービス全体の品質の規準として使用できます。サービス レベル定義は、ネットワーク リソース計画を作成するためのツールや、より高度な QoS への資金投入を要求するための証拠としても使用できます。また、ベンダーおよび通信事業者のパフォーマンスを評価するための手段にもなります。
サービス レベルの定義と測定を行わなければ、組織は明確な目標を設定できません。サービスの満足度を決めるのはユーザであり、この満足度はアプリケーション、サーバ/クライアント処理、またはネットワーク サポートの間で多少違いがあります。最終結果が組織にとって明確ではなく、最終的にネットワーク組織がネットワークとサポート モデルの改善について、予防的に行うのではなく事後処理的になる傾向があることが原因で、概算がより難しくなる可能性があります。
サービス レベルのモデルを構築し、それをサポートするためには、次のステップに従うことを推奨します。
ステップ 1:技術目標と制約の分析
技術的な目標と制約の分析に取りかかる際の最もよい方法は、技術的な目標と要件に関するブレーンストーミングまたは調査を行うことです。この討論には、他の IT 技術担当者を招くのがよい場合があります。これは、各担当者がそれぞれ自身の担当するサービスについて個別の目標を定めているためです。技術的な目標には、アベイラビリティ レベル、スループット、ジッタ、遅延、応答時間、スケーラビリティに関する要件、新機能の導入、新規アプリケーションの導入、セキュリティ、管理性、コストの安定化などが含まれます。続いて、使用可能なリソースが与えられたという仮定のもとに、これらの目標を達成するための制約を調査します。それぞれの目標と、それに対する制約の説明を記述したワークシートを作成します。まず、目標のほとんどが達成できないように思える場合があります。この場合は目標に優先順位を設定するか、ビジネス要件から外れない範囲で期待を下方修正します。
たとえば、アベイラビリティ レベルを 99.999 %、つまり 1 年当たりのダウンタイムを 5 分にしている場合があります。この目標を達成するには数多くの制約があります。たとえば、ハードウェアのシングル ポイント障害、リモート ロケーションで故障したハードウェアの Mean Time To Repair(MTTR; 平均修理時間)、通信事業者の信頼性、予防的な障害検出機能、変更率の高さ、現在のネットワーク キャパシティの制限などが制約として挙げられます。その結果、より実現可能なレベルに目標を調整することができます。次の項で説明するアベイラビリティ モデルは、現実的な目標の設定に役立ちます。
また、ネットワーク内の制約の少ない領域に高いアベイラビリティを提供する案も検討する余地があります。ネットワーキング組織がアベイラビリティのサービス標準を公開したときに、同じ組織内のビジネス グループの中から、そのレベルは許容できないという声があがる場合があります。この場合、ここから、SLA に関する議論や、ビジネス要件を満たす引き当てモデルや概算モデルの作成を始めることができます。
技術的な目標の達成に関係する制約またはリスクをすべて明らかにします。制約には、所期の目標に対する最も大きなリスクまたは影響という観点から優先順位を設定します。これは、ネットワーク改善イニシアチブに優先順位を設定するときや、制約に対処する際の難易度を判断するときに役立ちます。制約には次の 3 つの種類があります。
-
ネットワーク テクノロジー、復元力と設定
-
計画、設計、実装、運用を含むライフサイクルの実施
-
現在のトラフィック負荷やアプリケーションの動作
ネットワーク テクノロジー、復元力と設定の制約は、現在のテクノロジー、ハードウェア、リンク、設計、設定に関する制約またはリスクです。テクノロジーの制限には、テクノロジー自体によって課される制約も含まれます。たとえば、現在のテクノロジーでは冗長ネットワーク環境で 1 秒未満のコンバージェンス時間は達成できないものの、これがネットワークを通過する音声接続の維持には重要である場合があります。別の例として、データが 1 ミリ秒当たり約 100 マイルで地上回線を伝送できる理論速度である場合があります。
ネットワーク ハードウェアの復元力のリスクの調査は、ネットワークの定義済みのパスに沿って、ハードウェア トポロジ、階層、モジュール方式、冗長性および MTBF に注目する必要があります。ネットワーク リンクの制約は企業組織のネットワーク リンクと通信事業者の接続に重点を置く必要があります。リンク制約には、リンクの冗長性と多様性、メディアの制約、配線のインフラストラクチャ、ローカル ループ接続、および長距離接続が含まれる可能性があります。設計上の制約は、ネットワークの物理的または論理的な設計に関連し、機器が使用可能なスペースから、ルーティング プロトコルの実装のスケーラビリティなど、あらゆるものが含まれます。すべてのプロトコルとメディアの設計は、設定、アベイラビリティ、スケーラビリティ、パフォーマンス、およびキャパシティに関連して検討する必要があります。Dynamic Host Configuration Protocol(DHCP)、ドメイン ネーム システム(DNS)、ファイアウォール、プロトコル変換、ネットワーク アドレス変換などのネットワーク サービスの制約も考慮する必要があります。
ライフサイクルの実施は、ソリューションの一貫した導入、問題の検出と修復、キャパシティやパフォーマンスの問題の防止、一貫性があるモジュール型のネットワークの構成のために使用されるネットワークのプロセスと管理を定義します。この領域の検討が必要となるのは、非アベイラビリティの最大の要因が一般に専門知識とプロセスであるためです。ネットワーク ライフ サイクルとは、計画、設計、実装、運用のサイクルを指します。これらの各領域内で、パフォーマンス管理、構成管理、障害管理、セキュリティなどのネットワーク管理機能について理解する必要があります。ネットワーク ライフサイクル アセスメントは、ネットワーク ライフサイクルの実施に関連する現在のネットワーク アベイラビリティの制約を示す、Cisco NSA ハイ アベイラビリティ サービス(HAS)サービスから利用できます。
現在のトラフィック負荷やアプリケーション制約は、現在のトラフィックとアプリケーションの影響を示します。
困ったことに、多くのアプリケーションには注意深い管理を必要とする重要な制約があります。現在のアプリケーションのジッタ、遅延、スループット、帯域幅の要件には、通常多くの制約があります。また、アプリケーションの記述方法によって制約が生じることもあります。アプリケーションのプロファイリングにより、これらの問題を詳しく理解できます。次の項で、この機能を説明します。現在のアベイラビリティ、トラフィック、キャパシティやパフォーマンスの全体的な調査も、ネットワーク マネージャが現在のサービス レベルの予想とリスクを理解するのに役立ちます。この調査を行うには通常、ネットワーク ベースラインと呼ばれるプロセスを使用します。このプロセスを利用すれば、一定の期間(通常はおよそ 1 か月)におけるネットワークのパフォーマンス、アベイラビリティ、またはキャパシティの平均を明確にすることができます。この情報は一般にキャパシティの計画やトレンド分析に使用されますが、サービス レベルの問題を把握するために使用することもできます。
次のワークシートでは、セキュリティ攻撃または Denial-of-Service(DoS; サービス拒否)攻撃を防ぐという目標例に対して、上記の目標/制約手法を使用しています。このワークシートは、セキュリティ攻撃を最小限に抑えるためのサービス範囲を決定する際にも利用できます。
| リスクまたは制約 | 制約のタイプ | 予想される影響 |
|---|---|---|
| 使用できる DoS 検出ツールが、すべての種類の DoS 攻撃を検出できるわけではない。 | テクノロジー/復元力 | 高 |
| アラートの対処に必要なスタッフとプロセスがない。 | ライフサイクルの実施 | 高 |
| 現在のネットワーク アクセス ポリシーが設定されていない。 | ライフサイクルの実施 | 中 |
| 現在の低帯域幅のインターネット接続は、帯域幅の輻輳が攻撃に使用される要因になる可能性がある。 | ネットワークの容量 | 中 |
| 攻撃の防止に役立つ現在のセキュリティ設定が、完全でない可能性がある。 | テクノロジー/復元力 | 中 |
ステップ 2:アベイラビリティの概算の決定
アベイラビリティの概算は、定義された 2 つの地点間のネットワークに対して期待される、理論的なアベイラビリティです。正確な論理情報は、いくつかの点で役に立ちます。
-
組織における内部アベイラビリティの目標としてアベイラビリティの概算を使用し、ずれを迅速に定義、修正できる。
-
ネットワーク設計担当者がビジネス要件に合わせてシステムのアベイラビリティを決定する際に、この情報を使用できる。
非アベイラビリティまたは停止時間を引き起こす要因には、ハードウェア障害、ソフトウェア障害、電源や環境の問題、リンクまたは通信事業者の障害、ネットワーク設計、人的エラー、またはプロセスの欠如などがあります。ネットワークの全体的なアベイラビリティの概算を評価する際は、これらのパラメータをそれぞれ詳細に評価する必要があります。
組織が現在アベイラビリティを測定している場合は、アベイラビリティの概算を必要としない可能性があります。この場合は、ベースラインとしてアベイラビリティの測定値を使用して、サービス レベル定義で使用する現在のサービス レベルを推定します。ただし、実際の測定結果と比べて潜在的な理論上のアベイラビリティを理解するために、2 つを比較することに関心がある場合があります。
アベイラビリティとは、必要に応じて製品やサービスが稼働する確率です。次の定義を参照してください。
-
アベイラビリティ
-
1 -(接続障害の総時間数)/(接続の総供用時間数)
-
1 - [Σ(i の停止に影響される接続数 X i の停止の継続時間)] /(サービスの接続数 X 稼働時間)
-
-
非アベイラビリティ
1 - アベイラビリティ。つまり、ハードウェア障害、ソフトウェア障害、環境および電源の問題、リンクまたは通信事業者の障害、ネットワーク設計、ユーザ エラーとプロセス障害を原因とする接続停止時間の合計。
-
ハードウェアのアベイラビリティ
調査すべき最初の領域はハードウェア障害の可能性と非アベイラビリティへの影響です。これを判断するには、全ネットワーク コンポーネントの MTBF と、2 地点間のパス上にある全デバイスのハードウェア問題の MTTR を把握する必要があります。ネットワークがモジュール式で階層型であれば、ハードウェアのアベイラビリティはほとんどすべての 2 地点間で同じです。MTBF 情報は、すべての Cisco コンポーネントで利用でき、ローカル アカウント マネージャへの要求に応じて提供されます。Cisco NSA HAS プログラムでも、ツールを使用してネットワーク パスに基づくハードウェア アベイラビリティを計算します。これは、システムにモジュールの冗長性、シャーシの冗長性、およびパスの冗長性が存在する場合でも可能です。MTTR はハードウェアの信頼性を構成する主な要素の 1 つです。組織では、故障したハードウェアをどれだけ迅速に修理できるかを評価する必要があります。組織に予備の計画がなく、Cisco SMARTnet™ の標準契約のみに依存している場合は、潜在的な平均交換時間は約 24 時間です。コア冗長性があり、アクセス冗長性がない一般的な LAN 環境では、おおよそのアベイラビリティは 4 時間の MTTR で 99.99 % です。
-
ソフトウェアのアベイラビリティ
次に調査する領域はソフトウェア障害です。測定の目的で、シスコはソフトウェア障害をソフトウェア エラーによるデバイスのコールド スタートとして定義します。シスコは、ソフトウェアのアベイラビリティの理解に向けて大きな進歩を遂げています。ただし、新しいリリースは測定に時間がかかり、General Deployment ソフトウェアよりもアベイラビリティが低いと見なされます。IOS バージョン 11.2(18) などの General Deployment ソフトウェアは、99.9999 % 以上のアベイラビリティで測定されています。これは、修復時間を 6 分(ルータがリロードに要する時間)とし、Cisco ルータでの実際のコールドスタートに基づいて計算されたものです。 複数のバージョンを使用している組織では、アベイラビリティは若干低くなると予想されます。これは、複雑度が増し、相互運用性を考慮する必要があるほか、トラブルシューティング時間が増えるためです。最新のソフトウェア バージョンを使用している組織では、非アベイラビリティが高くなると予想されます。また、非アベイラビリティはかなり広範に分散されます。このため、カスタマーのサイトにおいて、非アベイラビリティが著しく増加するか、アベイラビリティが General Deployment リリースのレベルに近づきます。
-
環境および電源のアベイラビリティ
アベイラビリティにおける環境と電源の問題についても考慮する必要があります。環境の問題は、機器を指定動作温度に維持するために必要な冷却システムの故障に関連しています。多くのシスコ デバイスは、仕様外であると見なされたとき、すべてのハードウェアに障害を与えるリスクを取らずにシャットダウンします。アベイラビリティの概算の目的で電源が使用されるのは、それがこの領域の非アベイラビリティの主要な原因になるからです。
電源障害はネットワーク アベイラビリティ決定の重要な側面ですが、これは電源の理論的な分析が正確にできないため、制限されます。したがって、地域での過去の事例、電源バックアップ機能、およびすべてのデバイスに一定品質の電源を確実に供給するためのプロセスに基づいておおまかに測定された、各デバイスの電源のアベイラビリティを評価する必要があります。
控え目に評価しても、補助発電機、無停電電源装置(UPS)システム、および電源実装の品質プロセスを持つ組織では、シックスナインつまり 99.9999 % のアベイラビリティが実現すると言えますが、こうしたシステムを持たない組織では、99.99 % のアベイラビリティ、つまり年間 36 分のダウンタイムが発生する可能性があります。もちろん、組織の認識または実際のデータに基づいて、これらの値をより現実的な値に調整できます。
-
リンクまたは通信事業者の障害
リンクおよび通信事業者の障害は、WAN 環境のアベイラビリティに関する主要な要因です。WAN 環境は、ハードウェア障害、ソフトウェア障害、ユーザ エラー、電源障害など、組織のネットワークと同じアベイラビリティの問題が発生する可能性があるネットワークにすぎないことに注意してください。
多くの通信事業者のネットワークは、すでにシステムのアベイラビリティの概算を実行していますが、この情報を取得することは難しいことがあります。また、通信事業者のアベイラビリティの保証レベルが、実際のアベイラビリティの概算にほとんど、またはまったく基づかない場合が多いことにも注意してください。これらの保証レベルは、単に通信事業者のマーケティングおよび販売の戦略に過ぎないことがあります。場合によっては、これらのネットワークが公開するアベイラビリティの統計情報が、非常に優れているように見えることがあります。これらの統計は、完全冗長コア ネットワークにのみ該当し、WAN ネットワークの非アベイラビリティの主要な要因であるローカル ループ アクセスによる非アベイラビリティは考慮していないことに注意してください。
WAN 環境のアベイラビリティの概算は、実際の通信事業者の情報や WAN 接続の冗長性のレベルに基づいて作成する必要があります。組織が建物の複数の入り口機能、冗長ローカル ループ プロバイダー、同期光ネットワーク(SONET)ローカル アクセス、および地理的に分散した冗長性を持つ長距離通信事業者を利用している場合、WAN アベイラビリティは大幅に向上します。
電話サービスは WAN 環境での非冗長ネットワーク接続に関するかなり正確なアベイラビリティの概算です。電話のエンドツーエンド接続は、この項の説明と同様のアベイラビリティの概算方式を使用すると、アベイラビリティの概算が約 99.94 % となります。この方法論はこれまでわずかな変動しかないデータ環境で使用されていましたが、現在はサービス プロバイダー ケーブル ネットワークのパケット ケーブル仕様における対象として使用されています。完全冗長システムにこの値を適用する場合、WAN アベイラビリティは 99.9999 % のアベイラビリティに近いと想定できます。もちろん、コスト削減とアベイラビリティが原因で、地理的に分散した完全冗長 WAN システムを持つ組織はごく少数であるため、この機能について適切に判断してください。
LAN 環境のリンク障害は、可能性が低くなります。ただし、プランナーはコネクタの破損や緩みに応じて、短時間のダウンタイムを想定することもできます。LAN ネットワークでは、控えめに見積もって、99.9999 %、つまり 1 年当たり約 30 秒のアベイラビリティです。
-
ネットワーク設計
ネットワーク設計は、アベイラビリティに対して大きな影響を与えるもう 1 つの主な要因です。非スケーラブルな設計、設計エラー、およびネットワーク収束時間は、すべてアベイラビリティにマイナスの影響を与えます。
注:このドキュメントでは、拡張性のない設計や設計のエラーを次のセクションに示します。
ネットワーク設計は、トラフィックの再ルーティングを引き起こすネットワーク上のソフトウェアとハードウェアの不具合に基づいて測定可能な値に制限されます。この値は一般に「システム切り替え時間」と呼ばれ、システム内部でのプロトコルのセルフヒーリング機能の要因です。
システムの計算で同じ方法を使用して、アベイラビリティを計算します。ただし、ネットワークの切り替え時間は、ネットワーク アプリケーション要件を満たさない限り無効です。切り替え時間が許容される場合は、計算から削除します。切り替え時間が許容されない場合は、計算に追加する必要があります。例として、概算または実際の切り替え時間が 30 秒の環境における Voice over IP(VoIP)があります。この例では、ユーザは電話を切ってからもう一度やり直す可能性があります。ユーザはこの時間を間違いなく非アベイラビリティと認識しますが、アベイラビリティの概算ではこれは評価されません。
理論的なソフトウェアおよびハードウェアのアベイラビリティと冗長パスを調べることで、システム切り替え時間による非アベイラビリティを計算します。これは、切り替えがこの領域で発生していることによります。故障によって冗長パス内での切り替えを引き起こす可能性があるデバイスの数、それらのデバイスの MTBF、および切り替え時間を調べる必要があります。簡単な例では、2 つの同じ冗長デバイスのそれぞれで 35,433 時間の MTBF、および 30 秒の切り替え時間になります。35,433 を 8766(うるう年を含む 1 年の平均時間)で除算すると、4 年に一度装置が故障することがわかります。切り替え時間を 30 秒に設定すると、各デバイスで、1 年当たり平均 7.5 秒の切り替えによる非アベイラビリティが発生すると考えられます。ユーザはどちらのパスも通過できるため、7.5 秒を 2 倍すると、1 年当たりの非アベイラビリティは 15 秒になります。1 年当たりの秒数の観点で計算すると、この単純なシステムでの切り替えによるアベイラビリティは 99.99999785 % になります。切り替えを引き起こす可能性があるネットワーク内の冗長デバイスの数によっては、この値は他の環境よりも大きくなることがあります。
-
ユーザ エラーとプロセス
ユーザ エラーとプロセスに関するアベイラビリティの問題は、企業ネットワークと通信事業者ネットワークにおける非アベイラビリティの主な要因です。非アベイラビリティの約 80 % は、エラーの未検出、変更障害やパフォーマンスの問題などによって発生します。
アベイラビリティの概算を決定する際に、その他すべての理論的な非アベイラビリティを 4 倍する必要は決してありませんが、これが多くの環境に当てはまることは事実です。次の項では、非アベイラビリティのこの側面について、詳しく説明します。
ユーザ エラーとプロセスを原因とする非アベイラビリティの量を理論的に計算することはできないため、これはアベイラビリティの概算から除外し、組織が完璧を目指して努力することを推奨します。注意すべき点は、組織が持つ固有のプロセスと専門知識のレベルが現在アベイラビリティにどの程度のリスクをもたらしているのかを理解する必要があることです。これらのリスクや阻害要因を十分に理解していれば、ネットワーク計画担当者はこれらの問題を原因とする非アベイラビリティをある程度考慮に入れても構いません。Cisco NSA HAS プログラムはこれらの問題について調査を行うため、プロセス、ユーザ エラー、または専門知識の問題によって起こりうる非アベイラビリティについて理解する際に役立つ場合があります。
-
最終的なアベイラビリティの概算の決定
全体的なアベイラビリティの概算は、これまでに定義された領域の各アベイラビリティを掛け合わせて計算します。これは一般に、任意の 2 地点間の接続性がほぼ同じである均質な環境(階層的なモジュール方式の LAN 環境や階層的な標準の WAN 環境)の場合に行います。
この例では、アベイラビリティの概算は、階層的なモジュラ LAN 環境に対して行われます。この環境では補助発電機を使用し、すべてのネットワーク コンポーネントに対して UPS システムを備えており、電源を適切に管理しています。VoIP は使用しておらず、ソフトウェア切り替え時間を考慮する必要はありません。個々の見積もりは次のとおりです。
-
2 つのエンド ポイント間のハードウェアのパスのアベイラビリティ = 99.99 %
-
GD ソフトウェアの信頼性を基準として使用したソフトウェア アベイラビリティ = 99.9999 %
-
バックアップ システムがある環境と電源のアベイラビリティ = 99.999 %
-
LAN 環境のリンク障害 = 99.9999 %
-
システム切り替え時間は考慮しない = 100 %
-
ユーザ エラーとプロセスのアベイラビリティ(完璧と想定)= 100 %
組織が確保すべき最終的なアベイラビリティの概算は 0.9999 x 0.999999 x 0.999999 x 0.999999 = 0.999896、つまり 99.9896 % になります。潜在的な非アベイラビリティの要因を、ユーザ エラーまたはプロセス エラーによるものであると判断し、非アベイラビリティが技術的な要因によって 4 倍のアベイラビリティであると想定する場合、アベイラビリティの概算は 99.95 % になると想定できます。
この分析例は、LAN アベイラビリティが 99.95 % と 99.989 % の平均になることを示しています。これらの数値はネットワーキング組織のサービス レベルの目標として使用できます。システムのアベイラビリティを測定し、非アベイラビリティの何パーセントが上記の 6 つの領域に起因するかを決定することによって、別の値を計算することも可能です。この方法を使用すれば、ベンダー、通信事業者、プロセス、およびスタッフを適切に評価できます。計算された数値は、そのビジネスにおける期待の設定にも使用できます。この数値を許容できない場合、追加のリソースの概算を行って必要なレベルを取得します。
ネットワーク マネージャが特定のアベイラビリティ レベルでダウンタイムの量を理解すると役に立つことがあります。任意のアベイラビリティ レベルにおける 1 年間のダウンタイムの長さ(分)は次のようにして計算できます。
1 年のダウンタイムの分数 = 525600 -(アベイラビリティ レベル X 5256)
99.95 % のアベイラビリティ レベルを使用する場合、これは 525600 -(99.95 X 5256)、つまり 262.8 分のダウンタイムと等しく機能します。上記のアベイラビリティの定義では、これはネットワーク内のサービスのすべての接続に対するダウンタイムの平均量に相当します。
-
ステップ 3:アプリケーション プロファイルの作成
アプリケーション プロファイルは、ネットワーキング組織が個別のアプリケーションのネットワーク サービス レベルの要件を理解して定義するのに役立ちます。これを利用すれば、ネットワークに対する個々のアプリケーションの要件とネットワーク サービス全体を確実にサポートできます。また、アプリケーション プロファイルは、アプリケーションまたはサーバ グループが問題になっているネットワークを指すときに、ネットワーク サービス サポートの文書化されたベースラインとしても機能できます。最終的にアプリケーション プロファイルは、パフォーマンスやアベイラビリティなどのアプリケーションの要件を実際のネットワーク サービスの目標または現在の制限と比較することによって、ネットワーク サービスの目標をアプリケーションまたはビジネスの要件に合わせます。これはサービス レベル管理のためだけでなく、全体的なトップダウン ネットワーク設計のためにも重要です。
ネットワークに新しいアプリケーションを導入するときには必ずアプリケーション プロファイルを作成します。新規サービスまたは既存サービスに対するアプリケーション プロファイルの作成を徹底させるために、場合によっては、IT アプリケーション グループ、サーバ管理グループ、およびネットワーキング グループの間で取り決めを行う必要があります。ビジネス アプリケーションおよびシステム アプリケーションのアプリケーション プロファイルを完成させます。ビジネス アプリケーションには、電子メール、ファイル転送、Web ブラウズ、画像診断、製造などが含まれます。システム アプリケーションには、ソフトウェア配布、ユーザ認証、ネットワークのバックアップ、ネットワーク管理などが含まれます。
ネットワーク アナリストと、アプリケーションやサーバをサポートするアプリケーションが、アプリケーション プロファイルを作成する必要があります。新しいアプリケーションでは、プロトコル アナライザと遅延のエミュレーション機能を持つ WAN エミュレータを使用して、アプリケーションの要件を適切に特徴づける必要がある場合があります。これは、必要な帯域幅、アプリケーションの操作性を損なわない最大の遅延、およびジッタ要件を決定する際に役立ちます。必要なサーバがありさえすれば、ラボ環境でこれを実行しても構いません。VoIP など、その他の場合では、ジッタ、遅延、帯域幅などのネットワーク要件が公開されていて、ラボ テストは必要ではありません。アプリケーション プロファイルには、次の項目を含める必要があります。
-
アプリケーション名
-
アプリケーションのタイプ
-
新しいアプリケーションかどうか
-
ビジネスでの重要性
-
可用性要件
-
使用するプロトコルとポート
-
ユーザの帯域幅の見積もり(kbps)
-
ユーザの数および場所
-
ファイル転送の要件(時間、量、エンドポイントなど)
-
ネットワーク停止の影響
-
遅延、ジッタ、アベイラビリティの要件
アプリケーション プロファイルの目標は、アプリケーションのビジネス要件、ビジネス上の重要性、およびネットワークの要件(帯域幅、遅延、ジッタなど)を把握することです。また、ネットワーキング組織は、ネットワーク停止時間の影響を理解する必要があります。状況によっては、全体的なアプリケーションのダウンタイムを大幅に増やすアプリケーションやサーバの再起動が必要になります。詳細なアプリケーション プロファイルを作成すれば、ネットワーク能力全般を比較し、ネットワーク サービス レベルをビジネスおよびアプリケーションの要件に合わせることができます。
ステップ 4:アベイラビリティおよびパフォーマンスの標準の定義
アベイラビリティおよびパフォーマンスの標準は、組織のサービス目標を設定します。これらはネットワークまたは個別アプリケーションの各種領域別に定義できます。パフォーマンスは、往復の遅延、ジッタ、最大スループット、帯域幅保証、および全体的なスケーラビリティの観点から定義することもできます。サービス期待値の設定に加えて、組織は注意して各サービス標準を定義し、ユーザやネットワーキングを処理する IT グループが、サービス標準を完全に理解し、アプリケーションやサービスの管理要件にどのように関連するのか理解する必要があります。また、ユーザ グループと IT グループにも、サービス標準の測定方法を理解してもらうことが望まれます。
標準の作成には、前のサービス レベル定義ステップの結果が役立ちます。この時点で、ネットワーキング組織はネットワークの現在のリスクや制約を明確に理解し、アプリケーションの動作や、論理的なアベイラビリティ分析やアベイラビリティのベースラインも理解する必要があります。
-
サービス標準が適用される地理的領域またはアプリケーション領域を定義します。
これには、キャンパス LAN、国内 WAN、エクストラネット、パートナーとの接続などの領域が含まれることがあります。状況によっては、1 つの領域内に複数の異なるサービス レベル目標を設定する場合もあります。これは企業やサービス プロバイダー組織では珍しいことではありません。このような場合では、個々のサービス要件に応じて異なるサービス レベルの標準を作成することは珍しくありません。それらの標準が、1 つの地理的領域またはサービス領域で、ゴールド、シルバー、およびブロンズ サービス標準として分類されるケースもあります。
-
サービス標準のパラメータを定義します。
アベイラビリティと往復の遅延は、最も一般的なネットワーク サービス標準です。最大スループット、最小帯域幅の保証、ジッタ、許容されるエラー率とスケーラビリティ機能も、必要に応じて含めることができます。測定方法のサービス パラメータについて検討するときは注意してください。パラメータが SLA に含まれるかどうかにかかわらず、どのようにしてサービス パラメータを測定し、問題またはサービスの不適合が生じたときにどのようにしてその正当性を示すかについて検討しておくことが望まれます。
サービス エリアおよびサービス パラメータを定義した後で、前の手順の情報を使用してサービス標準マトリックスを作成します。ユーザや IT グループに混乱を招くおそれのある領域を定義することも必要です。たとえば、特定のアプリケーションに対して遠隔地で Enter キーを打つ場合とラウンドトリップ ping では、最大応答時間が大きく異なります。次の表は、米国内でのパフォーマンス ターゲットをまとめたものです。
| [ネットワーク(Network)] 領域 | アベイラビリティのターゲット | 計測方法 | ネットワークの平均応答時間のターゲット | 許容できる最大応答時間 | 応答時間の測定方法 |
|---|---|---|---|---|---|
| LAN | 99.99 % | 影響を受けるユーザ分 | 5 ミリ秒以下 | 10 ms | ラウンドトリップ ping の応答 |
| WAN | 99.99 % | 影響を受けるユーザ分 | 100 ミリ秒以下(ラウンドトリップ ping) | 150 ミリ秒 | ラウンドトリップ ping の応答 |
| 重要な WAN およびエクストラネット | 99.99 % | 影響を受けるユーザ分 | 100 ミリ秒以下(ラウンドトリップ ping) | 150 ミリ秒 | ラウンドトリップ ping の応答 |
ステップ 5:ネットワーク サービスの定義
これは、基本的なサービス レベル管理の最後の手順です。サービス レベルの目標を達成するために、事後処理的および予防的なプロセス、実装するネットワーク管理機能を定義します。最終的な文書は一般に「運用サポート プラン」と呼ばれます。ほとんどのアプリケーション サポート プランには、事後処理的なサポート要件のみが含まれます。ハイ アベイラビリティ環境では、組織は、ユーザのサービス コールの開始前にネットワーク問題の特定と解決に使用される、予防的な管理プロセスも検討する必要があります。最終的な文書には概して次のことを記載します。
-
サービス レベルの目標を達成するための事後処理的および予防的なプロセスの説明
-
サービス プロセスの管理方法
-
サービス目標とサービス プロセスの測定方法
この項では、多くのサービス プロバイダーおよび企業組織で検討すべき事後対処的サービス定義と予防的サービス定義の例を示しています。サービス レベル定義を作成する際の目標は、アベイラビリティとパフォーマンスの目標を満たすサービスを作成することです。これを実現するには、現在の技術的な制約、アベイラビリティの概算、およびアプリケーション プロファイルを念頭に置きながらサービスを構築する必要があります。具体的に言えば、常に迅速に問題を特定し、アベイラビリティ モデルによって割り当てられた時間内に問題を解決できるサービスを定義、構築することが望まれます。また、無視すればアベイラビリティとパフォーマンスに影響を及ぼす可能性のあるサービス問題を迅速に特定し、解決できるサービスを定義することも必要です。
所期のサービス レベルは一朝一夕で達成されるものではありません。すでにサービス分析ステップを完了していたとしても、専門知識の不足、プロセスに関する現在の制限、スタッフのレベルが十分でないなどの欠点によって、所期の標準または目標の達成が妨げられることがあります。必要なサービス レベルを所期の目標に正確に一致させる方法はありません。これに対処するには、サービス標準を測定し、さらにサービス標準のサポートに使用するサービス パラメータを測定します。サービス目標が満たされていない場合は、問題を把握するためにサービス規準に目を向けます。多くの場合、サポート サービスを改善し、希望のサービス目標の達成に必要な改善を行うために、概算を増やせます。時間が経つにつれてネットワーク サービスとビジネス要件の間に齟齬が生じ、それらを合わせるために、サービス目標またはサービス定義に修正を加えることもあります。
たとえば、企業が 99 % のアベイラビリティを達成したときに、それよりずっと高い 99.9 % のアベイラビリティを目標にしていることがあります。サービスおよびサポートの規準を見ていた組織の担当者は、ハードウェア交換におよそ 24 時間かかっていることに気付きました。当初の見積もりでは、ハードウェア交換の時間配分は 4 時間であり、実際の作業時間はこの見積もりを大幅に超えています。また、組織は予防的な管理機能が無視され、ダウン状態の冗長ネットワーク デバイスが修復されていないことを発見しました。さらに、責任を持って改善を行う担当者も定められていませんでした。その結果、現在のサービス目標を下げることを検討した後で、組織は必要なサービス レベルを達成するために必要な追加のリソースについて概算を決定しました。
サービス定義には、事後対処的なサポート定義と予防的なサポート定義をどちらも含める必要があります。事後対処的定義では、ユーザからの苦情またはネットワーク管理能力を起点として問題を特定し、その問題に対処する方法を定義します。予防的定義では、故障した「スタンバイ」ネットワーク コンポーネントの修理、エラーの検出、キャパシティのしきい値とアップグレードなど、発生する可能性のあるネットワークの問題を特定し、解決する方法について記述します。次の項に、事後対処的サービス レベル定義と予防的サービス レベル定義の例を示します。
事後対処的サービス レベル定義
次のサービス レベル領域は一般に、ヘルプデスク データベースの統計情報と定期的な監査を使用して測定します。この表は組織にとっての問題の重大度を具体的に示しています。チャートには、新しいサービスの要求を処理する方法が含まれていないことに注意してください。これは、SLA または追加のアプリケーションのプロファイリングとパフォーマンスの what-if 分析によって処理することができます。同じサポート プロセスによって対処する場合は、一般に重大度 5 が新規サービスの要求になります。
| 重大度 1 | 重大度 2 | 重大度 3 | 重大度 4 |
|---|---|---|---|
| 重大なビジネス インパクト:LAN ユーザまたはサーバ セグメントのダウン、重要な WAN サイトのダウン | 損失または品質低下による大きなビジネス インパクト、実施されている可能性がある回避策:キャンパス LAN のダウン5 ~ 99 人のユーザへの影響、国内 WAN サイトのダウン、海外 WAN サイトのダウン、重要なパフォーマンスへの影響 | 冗長性の喪失など、特定のネットワーク機能の損失または品質低下:キャンパス LAN のパフォーマンスへの影響、LAN の冗長性の喪失 | 組織のビジネスに影響しない機能のクエリまたは障害 |
問題の重大度を定義したら、サービス応答定義を作成するためのサポート プロセスを定義または調査します。一般に、サービス応答定義は、多層サポート構造とヘルプ デスクのソフトウェア サポート システムを組み合わせて、トラブル チケットによって問題を追跡する必要があります。メトリックは、優先順位ごとの応答時間と解決時間、優先順位別のコール数、および応答/解決の品質で利用できる必要があります。サポート プロセスを定義するには、組織内での各サポート層の目標を設定し、それぞれの役割と責任を明確化すると便利です。組織ではこの作業を通じて、各サポート レベルのリソース要件と専門知識のレベルを把握できます。次の表は、階層化されたサポート構造と問題解決のガイドラインの例を示しています。
| サポート層 | 責任 | 目標 |
|---|---|---|
| 第 1 層サポート | フルタイムのヘルプ デスク サポート。サポート コールへの応答、トラブル チケットの発行、最長 15 分での問題の対応、チケットの記述、適切な第 2 層サポートへの報告 | 着信コールの解決率:40 % |
| 第 2 層サポート | キューのモニタリング、ネットワーク管理、ステーションのモニタリング。ソフトウェアが特定した問題へのトラブル チケットの発行。実装。第 1 層、ベンダー、第 3 層報告からのコールの対応。解決までのコールに対する責任を担う | 第 2 層レベルでのコールの解決率:100 % |
| 第 3 層サポート | すべての優先順位 1 の問題に対して第 2 層サポートを即座に提供する必要がある。SLA の解決期間内に第 2 層によって解決されていないすべての問題のサポートに応じる | 問題の直接の所有権なし |
次に、サービス応答とサービス解決に関するサービス定義のマトリックスを作成します。ここでは、問題をどれだけ迅速に解決するかについての目標を設定します(ハードウェア交換を含む)。この領域では、目標を設定することが重要です。これは、サービス応答時間と回復時間が、ネットワーク アベイラビリティに直接影響を与えるためです。問題解決時間も、アベイラビリティの概算に基づいて設定します。多くの重大度の高い問題がアベイラビリティの概算で考慮されていない場合、組織はこれらの問題の原因と考えられる解決策を把握するための作業を行うとよいでしょう。次の表を参照してください。
| 問題の重大度 | ヘルプ デスクの応答 | 第 2 層の応答 | オンサイトの第 2 層 | ハードウェアの交換 | 問題解決 |
|---|---|---|---|---|---|
| 1 | 第 2 層のネットワーク運用マネージャへの即座の報告 | 5 分 | 2 時間 | 2 時間 | 4 時間 |
| 0 | 第 2 層のネットワーク運用マネージャへの即座の報告 | 5 分 | 4 時間 | 4 時間 | 8 時間 |
| 3 | 15 minutes | 2 時間 | 12 時間 | 24 時間 | 36 時間 |
| 4 | 15 minutes | 4 時間 | 3 日 | 3 日 | 6 日 |
サービス応答とサービス解決に加えて、報告マトリックスを作成します。報告マトリックスは、使用可能なリソースを、サービスに重大な影響を及ぼす問題に確実に集中させるために役立ちます。一般に、アナリストが問題の修正に注力しているときに、問題に追加リソースを持ち込むことに注力することはまれです。追加リソースを通知すべきタイミングを定義すると、管理での問題認識を促進し、一般的に将来の事前または予防措置につながる可能性があります。次の表を参照してください。
| Elapsed Time | 重大度 1 | 重大度 2 | 重大度 3 | 重大度 4 |
|---|---|---|---|---|
| 5 分 | ネットワーク運用管理者、第 3 層サポート、ネットワーキング担当役員 | |||
| 1 時間 | ネットワーク運用管理者、第 3 層サポート、ネットワーキング担当役員への情報の更新 | ネットワーク運用管理者、第 3 層サポート、ネットワーキング担当役員への情報の更新 | ||
| 2 時間 | VP への報告、ディレクタ、運用マネージャへの更新 | |||
| 4 時間 | VP、役員、運用管理者、第 3 層サポートへの根本原因分析の報告、未解決時は CEO への報告が必要 | VP への報告、ディレクタ、運用マネージャへの更新 | ||
| 24 時間 | ネットワーク運用マネージャ | |||
| 5 日 | ネットワーク運用マネージャ |
これまでに説明したサービス レベル定義では、運用サポート組織が問題を特定した後、その問題にどのようにして対処するかという点を中心としていました。運用組織では、上記とほぼ同じ情報を含む運用サポート プランを何年も前から作成しています。ただし、このような状況では、組織が問題をどのように特定し、どの問題を特定するかという点が欠けています。より高度なネットワーク組織は、ユーザによる問題の報告や苦情によって問題を事後処理的に特定するのではなく、予防的に特定される問題のパーセンテージについて目標を作成することで、この問題を解決しようとします。
次の表は、予防的サポート能力と予防的サポート全般をどの程度見積もってよいかを示しています。
| [ネットワーク(Network)] 領域 | 予防的な問題検出の比率 | 予防的な問題検出の比率 |
|---|---|---|
| LAN | 80 % | 20 % |
| WAN | 80 % | 20 % |
より予防的なサポート定義を作成する際に、この方法から始めることをお勧めします。特に予防的ツールによって自動的にトラブル チケットが生成される場合は測定が単純で、非常に簡単だからです。これはまた、ネットワーク管理ツール/情報を、根本的な原因を特定するための支援ではなく、予防的な問題の解決に集中させる点でも役立ちます。ただし、この方法の主な問題は、予防的なサポートの要件を定義していないことです。これは一般に、予防的サポート管理能力における格差を生み出し、結果的に新たなアベイラビリティ リスクをもたらします。
予防的サービス レベル定義
サービス レベル定義を作成するより包括的な方法には、ネットワークをモニタする方法、および運営組織が定義されたネットワーク管理ステーション(NMS)のしきい値に 7 x 24 ベースで対応する方法の詳細が含まれています。これは、Management Information Base(MIB; 管理情報ベース)変数の数の多さや、ネットワークの健全性に関係するネットワーク管理情報の量を見れば、まったく不可能な作業のように思われるかもしれません。また、非常に高価で、大量のリソースが消費される可能性があります。残念なことに、このような理由から多くの組織が予防的サービス定義の実装を避けていますが、予防的サービス定義は、本質的に単純で、非常に簡単に従うことができ、ネットワーク内の最大のアベイラビリティ リスクまたはパフォーマンス リスクのみに適用できます。組織が基本的な予防的サービスの定義に価値を見出すようになると、段階的なアプローチを実装する限り、重大な影響を与えずに、時間の経過とともにより多くの変数を追加できます。
すべての運用サポート計画に、予防的サービス定義の最初の領域を含めます。サービス定義では単に、運用グループがネットワークのさまざまな領域で、どのようにしてネットワークまたはリンクのダウン状態を事前に検出し、それに対処するのかを規定するだけです。この定義(または管理サポート)がなければ、一定していない多様なサポート、非現実的なユーザの期待、および最終的なネットワーク アベイラビリティの低下を余儀なくされるおそれがあります。
次の表は、リンク/デバイスダウン状態に対するサービス定義の作成方法を示しています。この例では、企業組織が時間帯やネットワークの領域に基づいて異なる通知要件と応答要件を持つ場合を示しています。
| ネットワーク デバイスまたはリンクのダウン | 検出方法 | 5 x 8 通知 | 7 x 24 通知 | 5 x 8 解決 | 7 x 24 解決 |
|---|---|---|---|---|---|
| コア LAN | SNMP デバイスとリンクのポーリング、トラップ | NOC はトラブル チケットを作成し、LAN 担当のポケットベルに発信 | LAN 担当のポケットベルに自動発信し、LAN 担当者がコア LAN キューのトラブル チケットを作成 | NOC によって 15 分以内に割り当てられた LAN アナリストが、サービス応答定義に従って修復 | 優先順位 1 および 2 は即時に調査および解決、優先順位 3 および 4 は早期解決のためにキューイング |
| 国内 WAN | SNMP デバイスとリンクのポーリング、トラップ | NOC はトラブル チケットを作成し、WAN 担当のポケットベルに発信 | WAN 担当のポケットベルに自動発信し、WAN 担当者が WAN キューのトラブル チケットを作成 | NOC によって 15 分以内に割り当てられた WAN アナリストがサービス応答定義に従って修復 | 優先順位 1 および 2 は即時に調査および解決、優先順位 3 および 4 は早期解決のためにキューイング |
| エクストラネット | SNMP デバイスとリンクのポーリング、トラップ | NOC はトラブル チケットを作成し、パートナー担当のポケットベルに発信 | パートナー担当のポケットベルに自動発信し、パートナー担当者がパートナー キューのトラブル チケットを作成 | NOC によって 15 分以内に割り当てられたパートナー アナリストがサービス応答定義に従って修復 | 優先順位 1 および 2 の場合は即時に調査および解決優先順位 3 および 4 は早期解決のためにキューイング |
残りの予防的サービス レベル定義は 2 つのカテゴリ、つまりネットワーク エラー、およびキャパシティとパフォーマンスの問題に分類できます。これらの領域のサービス レベル定義を作成しているネットワーク組織はほんの数パーセントに過ぎません。その結果、これらの問題は無視されるか、散発的に処理されます。それでも構わないネットワーク環境もありますが、ハイアベイラビリティ環境では一般に、一貫した予防的サービス管理が必要です。
ネットワーキング組織はいくつかの理由で、予防的サービス定義に苦労する傾向があります。これは主に、アベイラビリティ リスク、アベイラビリティの概算、およびアプリケーションの問題に基づいて予防的サービス定義の要件分析を行ったことがないためです。そのため、特に状況に応じて追加のリソースが必要になるという点で、予防的サービス定義の要件を明確にすることができず、利点もあいまいになります。
2 つめの理由は、既存のリソースまたは新しく定義されたリソースと、処理可能な予防的管理の量とのバランスに関係します。これについては、アベイラビリティまたはパフォーマンスに重大な影響を及ぼす可能性のあるアラートのみを生成するようにします。また、同じ問題に対して複数の予防的トラブル チケットが生成されないようにするため、イベント相関管理またはプロセスについても検討が必要です。組織が苦労する最後の理由は、新しい予防的アラートのセットを作成すると、多くの場合、それまで検出されなかったメッセージの初期フラッドが生成されることです。運用グループでは、この初期フラッドの問題に対応できるよう準備するとともに、それまで検出されなかったこれらの条件を修正または解決するために短期的に追加のリソースを割り当てる必要があります。
予防的サービス レベル定義の最初のカテゴリはネットワーク エラーです。ネットワーク エラーは、ソフトウェア エラーまたはハードウェア エラー、プロトコル エラー、メディア制御エラー、精度のエラー、環境の警告などのシステム エラーに細分類できます。サービス レベル定義の作成は、まずこれらの問題の条件をどのように検出し、だれが確認して、発生したときに何が起こるのかを周知させることから開始します。必要に応じて、サービス レベル定義に特定のメッセージや問題を追加します。正しい対処を行うために、次の分野でさらに作業を行う必要がある場合があります。
-
第 1 層、第 2 層、第 3 層サポートの責務
-
ネットワーク管理情報の優先順位と、運用グループが実際に処理可能な予防作業の量とのバランス
-
サポート スタッフが定義済みのアラートに効果的に対処できるようにするためのトレーニング要件
-
根本原因が同じ問題に対して複数のトラブル チケットが生成されないようにするためのイベント相関方法
-
第 1 層サポート レベルでイベントを特定できるようにする、特定のメッセージまたはアラートのドキュメンテーション
次の表は、ネットワーク エラーに関するサービス レベル定義の例を示したものです。これを見れば、予防的ネットワーク エラー アラートの担当者はだれで、問題をどのようにして特定し、問題が発生したときに何が起こるかを明確に理解できます。また、組織では、正しい対処を行うために、上記で定義した努力をする必要がある場合があります。
プロトコル間の再配送には、デフォルトのメトリックを使用するのが常に最適の方法とされます。
| エラー カテゴリ | 検出方法 | しきい値 | アクション実施済み |
|---|---|---|---|
| ソフトウェア エラー(ソフトウェアによる強制クラッシュ) | syslog ビューアを使用した syslog メッセージの毎日の確認、第 2 層サポートによって実行 | 優先順位 0、1、および 2 の頻度、レベル 3 以上の頻度が 100 以上 | 新しい事項が発生したか、注意を要する問題の場合は、問題のレビュー、トラブル チケットの作成とディスパッチ |
| ハードウェア エラー(ハードウェアによる強制クラッシュ) | syslog ビューアを使用した syslog メッセージの毎日の確認、第 2 層サポートによって実行 | 優先順位 0、1、および 2 の頻度、レベル 3 以上の頻度が 100 以上 | 新しい事項が発生したか、注意を要する問題の場合は、問題のレビュー、トラブル チケットの作成とディスパッチ |
| プロトコル エラー(IP ルーティング プロトコルだけ) | syslog ビューアを使用した syslog メッセージの毎日の確認、第 2 層サポートによって実行 | 優先順位 0、1、および 2 の 1 日当たりのメッセージが 10 件、レベル 3 以上の頻度が 100 以上 | 新しい事項が発生したか、注意を要する問題の場合は、問題のレビュー、トラブル チケットの作成とディスパッチ |
| メディア制御エラー(FDDI、POS およびファスト イーサネットのみ) | syslog ビューアを使用した syslog メッセージの毎日の確認、第 2 層サポートによって実行 | 優先順位 0、1、および 2 の 1 日当たりのメッセージが 10 件、レベル 3 以上の頻度が 100 以上 | 新しい事項が発生したか、注意を要する問題の場合は、問題のレビュー、トラブル チケットの作成とディスパッチ |
| 環境メッセージ(電力および温度) | syslog ビューアを使用した syslog メッセージの毎日の確認、第 2 層サポートによって実行 | 任意のメッセージ | 新しい問題に関するトラブル チケットを作成してディスパッチ |
| 精度のエラー(リンク入力エラー) | 5 分間隔の SNMP ポーリング、NOC により受信されるしきい値イベント | 入力または出力エラー、任意のリンクでの任意の 5 分間隔内で 1 つのエラー | 新しい問題に関するトラブル チケットを作成して第 2 層サポートにディスパッチ |
予防的サービス レベル定義のもう 1 つのカテゴリはパフォーマンスとキャパシティに適用されます。真のパフォーマンスおよびキャパシティ管理には、例外管理、ベースラインとトレンディング、および what-if 分析が含まれます。サービス レベル定義では単に、調査またはアップグレードのきっかけとなるパフォーマンスおよびキャパシティの例外しきい値と平均しきい値を規定するだけです。これらのしきい値は 3 つのパフォーマンスおよびキャパシティ管理プロセスすべてになんらかの方法で適用されます。
キャパシティとパフォーマンスのサービス レベル定義は、ネットワーク リンク、ネットワーク デバイス、エンドツーエンド パフォーマンス、アプリケーションのパフォーマンスなど、複数のカテゴリに分けることができます。これらの領域でサービス レベル定義を開発するには、デバイス キャパシティ、メディアのキャパシティ、QoS 特性、アプリケーション要件の特定の側面に関する深い技術的知識が必要です。したがって、ネットワーク アーキテクトはベンダーの情報を利用してパフォーマンスとキャパシティに関するサービス レベル定義を作成することを推奨します。
ネットワーク エラーと同様に、キャパシティとパフォーマンスに関するサービス レベル定義の作成は、まずこれらの問題の条件をどのように検出し、だれが確認して、発生したときに何が起こるのかを周知させることから開始します。必要に応じて、サービス レベル定義に特定のイベント定義を追加できます。正しい対処を行うために、次の分野でさらに作業を行う必要がある場合があります。
-
アプリケーション パフォーマンスの要件を明確に理解する
-
ビジネス要件や全体的なコストに基づき、組織にとって妥当なしきい値について詳細な技術調査を行う
-
概算サイクルおよびサイクル外のアップグレード要件
-
第 1 層、第 2 層、第 3 層サポートの責務
-
ネットワーク管理情報の優先順位および重要性と、運用グループが実際に処理可能な予防作業の量とのバランス
-
サポート スタッフがメッセージまたはアラートを理解し、定義済みの条件に効果的に対処できるようにするためのトレーニング要件
-
根本原因が同じ問題に対して複数のトラブル チケットが生成されないようにするためのイベント相関の方法またはプロセス
-
第 1 層サポート レベルでイベントを特定できるようにする、特定のメッセージまたはアラートのドキュメンテーション
次の表は、リンクの使用率に関するサービス レベル定義の例を示したものです。これを見れば、予防的ネットワーク エラー アラートの担当者はだれで、問題をどのようにして特定し、問題が発生したときに何が起こるかを明確に理解できます。また、組織では、正しい対処を行うために、上記で定義した努力を行う必要がある場合があります。
| ネットワーク領域/メディア | 検出方法 | しきい値 | アクション実施済み |
|---|---|---|---|
| キャンパス LAN のバックボーンとディストリビューション リンク | 5 分間隔の SNMP ポーリング、コア リンクおよびディストリビューション リンクでの RMON 例外トラップ | 5 分間隔での使用率 50 %、例外トラップによる使用率 90 % | 再発する問題に関する QoS 要件の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
| 国内 WAN リンク | 5 分間隔での SNMP ポーリング | 5 分間隔での使用率が 75 % | 再発する問題に関する QoS 要件の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
| エクストラネット WAN リンク | 5 分間隔での SNMP ポーリング | 5 分間隔での使用率が 60% | 再発する問題に関する QoS 要件の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
次の表は、デバイス キャパシティおよびパフォーマンスのしきい値に関するサービス レベル定義を示しています。ネットワークの問題やアベイラビリティの問題を防ぐために、意味のある有用なしきい値を作成していることを確認します。チェックされていないデバイス コントロール プレーン リソースの問題によってネットワークへの重大な影響が生じるおそれがあるため、この領域は非常に重要です。
| Cisco 7500 | CPU メモリ、バッファ | 5 分間隔の SNMP ポーリング、CPU の RMON 通知 | 5 分間隔での CPU 75 %、RMON 通知で 99 %、5 分間隔でのメモリ 50 %、バッファ使用率 99 % | 99 % の RMON CPU の問題の解決またはアップグレード計画のためのパフォーマンスとキャパシティ電子メール エイリアス グループへの電子メール通知、トラブル チケットの発行、第 2 層サポートのポケットベルへの発信 |
| Cisco 2600 | CPU メモリ | 5 分間隔での SNMP ポーリング | 5 分間隔での CPU 75 %、5 分間隔でのメモリ 50 % | 問題の解決またはアップグレード計画のためのパフォーマンスとキャパシティ電子メール エイリアス グループへの電子メール通知 |
| Catalyst 5000 | バックプレーン使用率、メモリ | 5 分間隔での SNMP ポーリング | バックプレーン使用率 50 %、メモリ使用率 75 % | 問題の解決またはアップグレード計画のためのパフォーマンスとキャパシティ電子メール エイリアス グループへの電子メール通知 |
| LightStream® 1010 ATM スイッチ | CPU メモリ | 5 分間隔での SNMP ポーリング | CPU 使用率 65 %、メモリ使用率 50 % | 問題の解決またはアップグレード計画のためのパフォーマンスとキャパシティ電子メール エイリアス グループへの電子メール通知 |
次の表は、エンドツーエンド パフォーマンスおよびキャパシティに関するサービス レベル定義を示しています。これらのしきい値は一般にアプリケーションの要件に基づきますが、なんらかのタイプのネットワーク パフォーマンスまたはキャパシティの問題を示すために使用することもできます。ネットワークの任意の場所から他のすべてのポイントへのパフォーマンスの測定には大量のリソースを必要とし、多量のネットワーク オーバーヘッドが生み出されるため、パフォーマンスに関するサービス レベル定義を持つほとんどの組織は、いくつかのパフォーマンス定義だけを作成します。これらのエンドツーエンド パフォーマンスの問題はリンクまたはデバイス キャパシティのしきい値によって捕捉されることもあります。地理的領域別に全般的な定義を作成することを推奨します。必要であれば、いくつかの重要なサイトまたはリンクを追加しても構いません。
| ネットワーク領域/メディア | 計測方法 | しきい値 | アクション実施済み |
|---|---|---|---|
| キャンパス LAN | なし、想定される問題なし、LAN インフラストラクチャ全体の測定は困難 | 往復応答時間が常に 10 ミリ秒以下 | 問題の解決またはアップグレード計画のためのパフォーマンスとキャパシティ電子メール エイリアス グループへの電子メール通知 |
| 国内 WAN リンク | Internet Performance Monitor(IPM)ICMP エコーのみを使用した SF から NY、および SF からシカゴの現在の測定 | 往復応答時間の 5 分間の平均が 75 ミリ秒 | 再発する問題に関する QoS 要件の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
| サンフランシスコから東京 | IPM および ICMP エコーを使用したサンフランシスコからブリュッセルの現在の測定 | 往復応答時間の 5 分間の平均が 250 ミリ秒 | 再発する問題に関する QoS 要件の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
| サンフランシスコからブリュッセル | IPM および ICMP エコーを使用したサンフランシスコからブリュッセルの現在の測定 | 往復応答時間の 5 分間の平均が 175 ミリ秒 | 再発する問題に関する QoS 要件の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
サービス レベル定義の最後の領域はアプリケーションのパフォーマンスに関するものです。アプリケーション パフォーマンスのサービス レベル定義は、通常はアプリケーションやサーバの管理者グループによって作成されます。これは、サーバ自体のパフォーマンスとキャパシティが、アプリケーション パフォーマンスの最大の要因である可能性があることが理由です。ネットワーキング組織は、ネットワーク アプリケーションのパフォーマンスに関するサービス レベル定義を作成することで、大きなメリットを認識できます。その理由は次のとおりです。
-
サービス レベルの定義および測定によってグループ間の競合が解消される可能性がある。
-
キー アプリケーションに対して QoS が設定されていて、その他のトラフィックがオプションと見なされている場合は、個々のアプリケーションのサービス レベル定義が重要になる。
アプリケーションのパフォーマンスを作成および測定することを選択した場合、おそらくサーバ自体のパフォーマンスを測定しないことが最もよいでしょう。そうすると、ネットワークの問題とアプリケーションまたはサーバの問題を区別する際に役立ちます。Cisco ルータで動作するプローブまたはシステム アベイラビリティ エージェント ソフトウェアと、パケットのタイプおよび測定頻度を制御する Cisco IPM を使用してください。
次の表は、アプリケーションのパフォーマンスに関する単純なサービス レベル定義を示しています。
| アプリケーション | 計測方法 | しきい値 | アクション実施済み |
|---|---|---|---|
| エンタープライズ リソース プランニング(ERP)アプリケーション、TCP ポート 1529、ブリュッセルから SF | IPM、ポート 1529 を使用して、ブリュッセルからサンフランシスコへの往復のパフォーマンスを測定、ブリュッセルのゲートウェイから SFO のゲートウェイ 2 | 往復応答時間の 5 分間の平均が 175 ミリ秒 | 再発する問題に関する問題の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
| ERP アプリケーション、TCP ポート 1529、東京から SF | IPM、ポート 1529 を使用して、ブリュッセルからサンフランシスコへの往復のパフォーマンスを測定、ブリュッセルのゲートウェイから SFO のゲートウェイ 2 | 往復応答時間の 5 分間の平均が 200 ミリ秒 | 再発する問題に関する問題の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
| カスタマー サポート アプリケーション TCP ポート 1702 シドニーから SF | IPM、ポート 1702 を使用して、シドニーからサンフランシスコへの往復のパフォーマンスを測定、シドニーのゲートウェイから SFO のゲートウェイ 1 | 往復応答時間の 5 分間の平均が 250 ミリ秒 | 再発する問題に関する問題の評価またはアップグレードの計画を行うための、パフォーマンス電子メール エイリアス グループへの電子メール通知 |
ステップ 6:メトリックの収集とモニタリング
規準を収集して成果を監視しなければ、サービス レベル定義だけがあっても役に立ちません。重要なサービス レベル定義の作成で、サービス レベルが測定および報告される方法を定義します。サービス レベルの測定は、組織が目標を達成しているかどうかを決定し、アベイラビリティやパフォーマンスの問題の根本原因を特定します。また、サービス レベル定義を測定する方法を選択する際に、目標を考慮します。詳細については、「SLA の作成と保守」を参照してください。
サービス レベルのモニタは、定期的なサービスについて話し合うために、定期的な確認のミーティングを(通常は毎月)行うことが含まれます。すべてのメトリック、および目標に適合しているかどうかを話し合います。これらが適合していない場合、問題の根本原因を特定し、改善点を実装します。個々の状況について改善を実施しているときは、現在のイニシアチブと進捗状況も議題に取り上げます。
SLA の作成と保守
サービス レベル定義は、組織全体にわたる一貫した QoS の作成とアベイラビリティの改善に寄与するという点で優れたビルディング ブロックです。次のステップでは SLA を取り扱います。SLA によってビジネス目標とコスト要件が直接サービス品質に反映されるため、SLA は一種の改善手段といえます。適切に構成された SLA は、ネットワークの問題に関する明確なプロセスまたは手順を維持することにより、効率、品質、およびユーザ コミュニティとサポート グループ間の相乗効果のモデルとして機能します。
SLA には次のような利点があります。
-
SLA はサービスに関する双方向の責任を確立します。つまり、ユーザやアプリケーション グループにもネットワーク サービスについての責任が生じます。特定のサービスに対する SLA を作成せず、ネットワーク グループにビジネス インパクトを伝えない場合、実際に問題に責任を負う可能性があります。
-
SLA は、ビジネス要件を満たすために必要な標準ツールとリソースを決定する際に役立ちます。SLA なしで利用する人数とツールを決定すると、概算が推測になることがあります。サービスの設計が過剰であれば支出超過につながり、逆に条件に満たない場合はビジネス目標が達成されません。SLA を調整することでバランスのとれた最適なレベルを実現できます。
-
文書化された SLA はサービス レベルの期待を設定するための明確な手段となります。
サービス レベルの定義を行った後、次の手順に従って SLA を構築することを推奨します。サービス レベルの定義を行った後、次の手順に従って SLA を構築することを推奨します。
7. SLAの前提条件を満たす。
9.サービス要素を決定する。
10.お客様のビジネスニーズと目標の理解
11.各グループに必要なSLAを定義します。
12. SLAの形式を選択します
13.SLAワークグループの作成
14.ワークグループ会議を開催し、SLAを作成する。
15. SLAをネゴシエートします。
16. SLA準拠を測定および監視する。
手順 7:SLA の前提条件を満たす
IT SLA の開発の専門家は、SLA の成功のための 3 つの前提条件を特定しました。残念ながら、これらの目標に達していない組織は SLA プロセスに関して問題が生じるおそれがあるため、SLA プロセスに関連して起こりうる問題について検討する必要があります。ネットワーキング組織が一般的なビジネス要件を満たすサービス レベル定義を構築できる場合、SLA の導入に失敗しても有害ではありません。SLA プロセスの前提条件を次に示します。
-
会社全体にサービス重視の体制が形成されていなければならない。
組織では、カスタマーのニーズを何よりも優先させる必要があります。サービスに対してはトップダウンによる最優先事項としての取り組みが必要であり、これがカスタマーのニーズと意識の全面的な理解につながります。顧客満足度調査および顧客主導型サービス制御を行います。
別のサービス インジケータとして、組織が企業目標としてサービスまたはサポートの満足度を提示する場合があります。IT 組織は今や組織全体の成果にクリティカルにリンクしているため、このようなことは珍しくありません。
サービス体制が重要なのは、SLA プロセスが本質的にカスタマーのニーズとビジネス要件に基づいて改善されるためです。組織がこれを過去に行っていない場合、SLA プロセスは困難に思われます。
-
カスタマー/ビジネス イニシアチブによって、すべての IT 活動を推進する必要があります。
企業のビジョンまたはミッションの声明は、SLA などの IT 活動すべてを推進するカスタマーおよびビジネス イニシアチブと整合がとれている必要があります。ネットワークを活用して特定の目標を達成しようとすることが多くありますが、目標とそれに続くビジネス要件をネットワーキング グループが認識していない場合があります。このような状況で、設定した概算がネットワークに割り当てられますが、現在のニーズに過剰反応したり、要件を過小評価したりする結果、失敗する可能性があります。
カスタマー/ビジネス イニチアチブが IT 活動と整合がとれていると、ネットワーキング組織は新規アプリケーションの水平展開、新規サービス、またはその他のビジネス要件に容易に同調することができます。このつながりによって、企業目標の達成へと向かう共通した全体意識が生まれるため、すべてのグループが 1 つのチームとして機能します。
-
SLA プロセスと契約に従う必要がある。
第 1 に、SLA プロセスを習得して、効率的な契約を作成する必要があります。第 2 に、契約のサービス要件を遵守する必要があります。関連するすべてのユーザからの重要な情報と提供なしで、強力な SLA を作成できると考えないでください。これは、管理者層および SLA プロセスに関係のあるすべての個人が取り組む必要があります。
ステップ 8:SLA に関連があるユーザを特定する
エンタープライズレベル ネットワーク SLA は、ネットワーク要素、サーバ管理者の要素、ヘルプ デスク サポート、アプリケーション要素、ビジネスやユーザの要求に大きく左右されます。通常、各領域からの管理は、SLA プロセスに含まれます。このシナリオは組織が基本的な事後対処的サポート SLA を構築しているときに有効です。ハイ アベイラビリティ要件を持つ企業組織は、SLA プロセスに、アベイラビリティの概算、パフォーマンスの制限、アプリケーション プロファイリング、予防的な管理機能などの問題に役立つ技術サポートが必要になることがあります。より予防的な管理 SLA の側面については、ネットワーク アーキテクトとアプリケーション アーキテクトのテクニカル チームが推奨されます。技術サポート員であれば、ネットワークのアベイラビリティとパフォーマンス能力、および特定の目標を達成するために必要な事柄をかなり厳密に見積もることができます。
サービス プロバイダーの SLA には通常、ユーザの意見は取り込まれません。これは、サービス プロバイダーが SLA を作成する目的が「他のサービス プロバイダーに対する競争上の優位性を獲得すること」に尽きるからです。状況によっては、サービスの促進や社内従業員の内部目標を提供のために、経営陣がこれらの SLA をより高いアベイラビリティや高いパフォーマンス レベルで作成します。その他に、内部的に測定および管理された強力なサービス レベル定義を作成することでアベイラビリティを改善するという技術的側面に専心しているサービス プロバイダーもあります。また、両方の努力が同時に行われることがありますが、必ず同時に行われるわけではなく、同じ目的を持っているわけでもありません。
SLA に関連するユーザの選択は、SLA の目標に基づく必要があります。目標には次のようなものが考えられます。
-
事後対応型サポート ビジネス目標の達成
-
予防的 SLA の定義による、最高レベルのアベイラビリティの提供
-
サービスの普及促進または販売
手順 9:サービス要素の決定
主要なサービス/サポート SLA は通常、サポートのレベル、測定方法、SLA 調整のための報告経路、概算に関する全体的な考慮事項など、多くの要素から構成されます。ハイアベイラビリティ環境のサービス要素には、事後対処的な目標だけでなく、予防的なサービス定義も含めるようにしてください。次のような詳細もあります。
-
オンサイト サポート時間と時間外サポート用の手順
-
優先順位の定義(問題のタイプ、問題についての作業を開始するまでの最大時間、問題解決までの最大時間、報告手順など)
-
ビジネス上の重要性の順にランク付けされた、サポート対象製品またはサービス
-
専門知識への期待、パフォーマンス レベルの期待、ステータス レポート、および問題解決に対するユーザ責任のサポート
-
地理的または事業部門単位のサポート レベルの問題や要件
-
問題管理方法と手順(コール追跡システム)
-
ヘルプ デスクの目標
-
ネットワーク エラーの検出とサービスの応答
-
ネットワーク アベイラビリティの測定およびレポート
-
ネットワークのキャパシティとパフォーマンスの測定およびレポート
-
競合の解決手順
-
実装された SLA の資金
ネットワーク アプリケーションまたはサービスの SLA には、ユーザ グループの要件とビジネスの重要度に基づく追加のニーズがある場合があります。ネットワーク組織はこれらのビジネス要件に真摯に耳を傾け、サポート構造全体に合わせた特別なソリューションを展開する必要があります。一部の個人またはグループに専用のプレミア サービスを作成しないことが重要であるため、全体的なサポート体制に合わせることが非常に重要です。多くの場合、次の追加要件を「ソリューション」のカテゴリに分けることができます。例として、ビジネス ニーズに基づいたプラチナ、ゴールド、およびシルバー ソリューションなどがあります。個別のビジネス ニーズについては、次の SLA 要件の例を参照してください。
注:サポート構造、エスカレーションパス、ヘルプデスクの手順、測定、優先順位の定義は、一貫性のあるサービスカルチャーを維持および改善するために、ほとんど同じままにする必要があります。
-
バーストの帯域幅要件および機能
-
パフォーマンス要件
-
QoS の要件と定義
-
ソリューション マトリックスを作成するためのアベイラビリティの要件と冗長性
-
モニタリングおよびレポートの要件、方法、手順
-
アプリケーション/サービス要素のアップグレード基準
-
概算範囲外の要件の資金、または相互課金の方法
たとえば、WAN サイトの接続用のソリューション カテゴリを作成できます。プラチナ ソリューションの場合は、サイトに 1 対の T1 サービスが提供されます。キャリアごとにそれぞれ T1 回線を提供します。サイトには 2 台のルータがあり、いずれかの T1 またはルータで障害が発生したときにサイトが停止しないように設定されます。ゴールド サービスでも 2 台のルータがありますが、バックアップ フレームリレーが使用されます。このソリューションでは、停止が起こると帯域幅が制限される可能性があります。シルバー ソリューションではルータは 1 台のみで、通信事業者も 1 つです。これらの任意のソリューションが、問題チケットの異なる優先順位の対象となります。停止に対して優先順位 1 または 2 のチケットが必要な組織では、プラチナまたはゴールド ソリューションが必要になります。顧客の組織は、必要とするサービスのレベルに資金を投入できます。次の表は、エクストラネット接続のビジネス ニーズに応じて 3 つのレベルのサービスを提供する組織の例を示しています。
| 解決方法 | Platinum | ゴールド | シルバー |
|---|---|---|---|
| Devices | WAN 接続用の冗長ルータ | コア サイトでのバックアップ用の冗長ルータ | デバイスの冗長性なし |
| WAN | 冗長化された T1 接続、複数の通信事業者 | フレームリレー バックアップ付きの T1 接続 | WAN の冗長性なし |
| 帯域幅の要件とバースト | バースト時のロード シェアリング機能を持つ冗長化された T1 | 非ロード シェアリング、重要なアプリケーションのみのフレーム リレーのバックアップ、フレーム リレー CIR 64K のみ | 最大で T1 まで |
| パフォーマンス | 一貫した 100 ミリ秒以下の往復応答時間 | 応答時間:99.9% の期待値で 100 ミリ秒以下 | 応答時間:99% の期待値で 100 ミリ秒以下 |
| アベイラビリティの要件 | 99.99 % | 99.95 % | 99.9 % |
| ダウン時のヘルプ デスクの優先順位 | 優先度 1:ビジネスに不可欠なサービスのダウン | 優先度 2:ビジネスに影響を及ぼすサービスのダウン | 優先度 3:ビジネスに関する接続のダウン |
手順 10:カスタマーのビジネス ニーズと目的を理解する
このステップは SLA 作成者に大きな信頼感を与えます。さまざまなビジネス グループのニーズを理解すると、最初の SLA のドキュメントがビジネス要件と目的の結果に近づきます。カスタマーのサービスがダウンしたときに失われるコストの把握に努めてください。生産性、収益、顧客の信用の喪失の観点から見積もります。少人数でシンプルな接続でも、収益に大きく影響する可能性があることに留意してください。この場合、組織が必要なサービス レベルを理解できるように、発生する可能性があるアベイラビリティとパフォーマンスのリスクを顧客に理解してもらいます。この手順が欠落していると、100 % のアベイラビリティを要求する顧客が多くなります。
SLA 作成者は、ネットワークのアップグレード、ワークロード、および概算を考慮するために、組織のビジネス目標と発展についても理解することが求められます。使用されるアプリケーションを理解することも有効です。組織が各アプリケーションのアプリケーション プロファイルを持っていることが望ましいですが、持っていない場合は、ネットワーク関連の問題を特定するためにアプリケーションの技術的評価を行うことを検討します。
ステップ 11:各グループに必要な SLA の定義
主要なサポート SLA には、ネットワーク運用グループ、サーバ運用グループ、アプリケーション サポート グループなどの重要なビジネス単位や機能グループの代表を含める必要があります。これらのグループは、サポート プロセスにおける役割だけでなく、ビジネス ニーズにも基づいて選出するようにします。多くのグループからの代表が含まれていると、個々のグループの好みや優先順位なしで、公正で全体的なサポート ソリューションを作成できます。こうしなければ、サポート組織が個々のグループにプレミア サービスを提供するという、組織のサービス体制全体が埋もれるシナリオにつながる可能性があります。たとえば、顧客が自分のアプリケーションが最も重要だと主張する場合でも、実際には、そのアプリケーションのダウンタイムのコストが、収益の損失、生産性の損失、顧客の信用喪失の点から判断して、あまり重要でない可能性があります。
組織内の部門が異なると、要件も異なります。ネットワーク SLA の目標の中に、異なるサービス レベルに対応するただ 1 つの総合的なフォーマットについて合意を得ることがあります。ここでの要件とは通常、アベイラビリティ、QoS、パフォーマンス、および MTTR です。ネットワーク SLA では、これらの変数は、潜在的な QoS の調整のためのビジネス アプリケーションの優先順位付け、ネットワークに影響を与えるさまざまな問題の MTTR に対するヘルプ デスクの優先順位の定義、およびさまざまなアベイラビリティとパフォーマンス要件に対応できるソリューション マトリックスの開発によって処理されます。企業メーカーのシンプルなソリューション マトリックスの例として、次の表に示すようなものがあります。この表に、アベイラビリティ、QoS、およびパフォーマンスの情報を追加しても構いません。
| 事業部門 | アプリケーション | ダウンタイムにかかるコスト | ダウン時の問題の優先順位 | サーバ/ネットワーク要件 |
|---|---|---|---|---|
| 製造 | ERP | 高 | 1 | 最大の冗長性 |
| カスタマー サポート | カスタマー サポート | 高 | 1 | 最大の冗長性 |
| エンジニアリング | ファイル サーバ、ASIC 設計 | 中 | 0 | LAN コア冗長性 |
| Marketing | ファイル サーバ | 中 | 0 | LAN コア冗長性 |
ステップ 12:SLA の形式を選択する
SLA のフォーマットはグループの要望や組織の要件によって異なります。ネットワーク SLA のアウトラインの推奨される例を次に示します。
-
契約の目的
-
契約に関与する関係者
-
契約の目的と目標
-
-
提供されるサービスとサポート対象製品
-
ヘルプ デスク サービスとコール トラッキング
-
MTTR 定義に対するビジネス上の影響を基準とした問題重要度定義
-
QoS 定義に対するビジネスに不可欠なサービスの優先順位
-
アベイラビリティおよびパフォーマンスの要件に基づいて定義されたソリューションのカテゴリ
-
トレーニング要件
-
キャパシティ プランニングの要件
-
報告の要件
-
レポート作成
-
提供されるネットワーク ソリューション
-
新しいソリューションの要求
-
サポート対象外の製品またはアプリケーション
-
-
ビジネス ポリシー
-
業務時間内のサポート
-
業務時間外サポートの定義
-
祝日のカバレッジ
-
連絡先電話番号
-
ワークロードの予測
-
不服の解決
-
サービス適格基準
-
ユーザおよびグループのセキュリティ責任
-
-
問題管理手順
-
コールの開始(ユーザと自動化)
-
第 1 レベルの応答とコールの解決率
-
コール トラッキングと録音の保持
-
発信者の責任
-
問題の診断とコール クローズ要件
-
ネットワーク管理の問題検出とサービスの応答
-
問題解決カテゴリまたは定義
-
慢性的な問題の処理
-
重要な問題と例外のコール処理
-
-
サービス品質の目標
-
品質の定義
-
測定の定義
-
品質の目標
-
問題の優先順位別の問題解決開始の平均時間
-
問題の優先順位別の問題解決の平均時間
-
問題の優先順位別のハードウェア交換の平均時間
-
ネットワークのアベイラビリティとパフォーマンス
-
キャパシティの管理
-
成長の管理
-
品質レポート
-
-
要員計画と概算
-
要員計画モデル
-
運用の概算
-
-
契約のメンテナンス
-
準拠確認のスケジュール
-
パフォーマンス レポートの作成と検討
-
レポート規準の調整
-
定期的な SLA の更新
-
-
承認
-
添付ファイル
-
コール フロー図
-
報告マトリックス
-
ネットワーク ソリューション マトリックス
-
レポートの例
-
ステップ 13:SLA のワークグループを作成する
次のステップは SLA ワーキング グループの参加者(グループ リーダーなど)を決めることです。ワークグループには、ビジネス単位または機能グループからのユーザや管理者、または地域的拠点からの代表者が参加しても構いません。参加者はそれぞれのワークグループで SLA の問題について意見を交換します。SLA の重要な要素に同意する管理者や意思決定者が参加する必要があります。このような参加者には、SLA に関連する技術的な問題を定義する能力があり、なおかつ IT レベルの意思決定の権限を持つ、管理者であり技術者でもある人々(つまり、ヘルプデスク管理者、サービス運用管理者、アプリケーション管理者、ネットワーク運用管理者など)が含まれていても構いません。
ネットワーク SLA ワークグループは、多くのアプリケーションとサービスに対応するただ 1 つのネットワーク SLA について合意を得るために、幅広いアプリケーションおよびビジネスの代表から構成される必要があります。ワークグループには、ネットワーク対応のビジネス クリティカルなプロセスとサービス、および個々のサービスのアベイラビリティ要件とパフォーマンス要件をランク付けする権限が必要です。この情報は、ビジネスに影響する問題のタイプ別の優先順位付けに使用されるほか、ネットワーク上のビジネス クリティカルなトラフィックへの優先順位付けや、ビジネス要件に基づく将来的な標準ネットワーキング ソリューションの作成時にも使用されます。
ステップ 14:ワークグループのミーティングを開き、SLA のドラフトを作成する
ワークグループでは最初にワークグループ憲章を作成します。この憲章では、SLA の目標、イニシアチブ、およびタイム フレームについて明示します。次に、グループは具体的な作業計画を作成し、SLA を開発、実装するスケジュールおよびタイムテーブルを決定する必要があります。また、サポート基準に照らし合わせてサポート レベルを測定するためのレポート作成プロセスも開発します。最後に SLA 契約のドラフトを作成します。
ネットワーク SLA ワークグループは、最初のうちは SLA を作成するために週に 1 回会合を開きます。SLA が作成され、承認された後、グループは SLA の更新について毎月または 3 カ月ごとに集まるとよいでしょう。
ステップ 15:SLA のネゴシエート
SLA 作成の最後のステップは最終的な交渉と承認です。このステップには次のような作業があります。
-
ドラフトの検討
-
コンテンツのネゴシエーション
-
ドキュメントの編集と改訂
-
最終承認の取得
ドラフトの検討、内容の交渉、改訂というサイクルは、承認を得るために最終版を経営陣に提出するまで何度も繰り返される場合があります。
ネットワーク マネージャの観点から、測定可能で達成可能な結果をネゴシエートすることが重要です。パフォーマンスとアベイラビリティの契約を他の関連組織の契約と比較して詳しく説明してください。これは、品質の定義、測定の定義、および品質の目標を対象とします。追加サービスは費用の追加に相当する点に注意してください。追加のサービス レベルは費用がさらにかかることをユーザ グループが理解していることを確認し、重要なビジネス要件の場合は、ユーザ グループに意思決定を任せます。コスト分析は SLA のさまざまな角度(ハードウェア交換時間など)から容易に実行できます。
ステップ 16:SLA への準拠を測定してモニタする
SLA 順守の測定と結果の報告は、長期にわたって一貫性と結果を保証する SLA プロセスの重要な要素です。通常は、SLA の主要コンポーネントをすべて測定可能なものとし、SLA の実装に先立って測定方法を導入することを推奨します。さらに、ユーザ グループとサポート グループの間で月次ミーティングを開催し、測定結果の検討、問題の根本原因の特定、サービス レベル要件を満たす、またはそれを越えるようなソリューションの提案などを行います。これにより、SLA プロセスが最新の品質改善プログラムとほぼ同じようなものとなります。
次の項では、組織の管理者層が自組織の SLA と全体的なサービス レベル管理をどのようにして評価できるかについて、さらに詳しく説明します。
サービス レベル管理のパフォーマンス指標
サービス レベル管理のパフォーマンス指標は、成果の尺度としてサービス レベルを監視し、改善するための仕組みを提供します。これにより、組織はサービスの問題に迅速に対処し、その環境内のサービスまたはダウンタイム コストに影響を与える問題を容易に把握できます。また、サービス レベルも定義を測定しないと、組織が事後処理的なスタンスを取らざるを得ないため、積極的で予防的な作業ができなくなります。どのユーザもサービスがうまく機能していると言うことはなく、多くのユーザがサービスは要件を満たしていないと言うようになります。
サービス レベル管理のパフォーマンス指標は既存のサービス レベルを十分に把握し、現在の問題に基づいて調整を行うための手段を提供するため、サービス レベル管理の最も重要な要件になります。これは予防的サポートを提供し、品質改善を行うための基盤です。組織が問題について根本原因を分析し、品質改善を行う場合、サービス レベル管理のパフォーマンス指標は、アベイラビリティ、パフォーマンス、およびサービス品質を改善するための最良の方法論になりえます。
たとえば、次の実際のシナリオについて考えてみてください。X 社には、多数のユーザからネットワークが頻繁にダウンするという苦情が長期間寄せられていました。アベイラビリティを測定すると、いくつかの WAN サイトで問題が見つかりました。これらのサイトを詳しく調査し、問題のほとんどが、いくつかの WAN サイトにあることが判明しました。根本原因がわかり、X 社は問題を解決しました。X 社では次にアベイラビリティのサービス レベル目標を設定し、ユーザ グループとの間で契約を作成しました。詳しく測定すると、SLA への不適合があるために問題が発生していたことが迅速に特定されました。そのため、ネットワーキング グループはプロ意識と専門知識を備えた、組織にとって貴重な存在と見なされるようになりました。ネットワーク グループは本質的に事後対処的サポートから予防的サポートに移行し、会社の収益に貢献しました。
残念ながら、今日の大部分のネットワーキング組織は限られたサービス レベル定義しか持たず、パフォーマンス指標はまったく使用していません。その結果、根本原因を予防的に特定し、ビジネス要件を満たすネットワーク サービスを構築する代わりに、ユーザからの苦情や問題に対処するために多くの時間を費やしています。
サービス レベル管理プロセスの成果を確認するには、次の SLA パフォーマンス指標を使用します。
-
文書化されたサービス レベル定義または SLA。アベイラビリティ、パフォーマンス、事後処理的なサービス応答時間、問題解決の目標と問題の報告などが含まれます。
-
パフォーマンス指標の規準。アベイラビリティ、パフォーマンス、優先順位別のサービス応答時間、優先順位別の解決時間、その他の測定可能な SLA パラメータなどが含まれます。
-
月に 1 度行うネットワークのサービス レベル管理のミーティング。サービス レベルのコンプライアンスを確認し、改善点を実装するために行います。
文書化されたサービス レベル契約またはサービス レベル定義
最初のパフォーマンス指標は、SLA またはサービス レベル定義について詳述した文書です。サービス レベル定義の第 1 の目標はアベイラビリティとパフォーマンスにするのが普通です。これは、アベイラビリティとパフォーマンスが最も重要なユーザ要件であるためです。
第 2 の目標の重要性は、アベイラビリティまたはパフォーマンス レベルの達成方法を定義する際に利用できる点にあります。たとえば、組織に積極的なアベイラビリティとパフォーマンスの目標があれば、問題の発生を防止し、発生した場合は迅速に修正することが重要です。第 2 の目標は所期のアベイラビリティとパフォーマンスのレベルの達成に必要なプロセスを定義する際に役立ちます。
事後対処的な第 2 の目標には次のようなものがあります。
-
コール優先順位による事後対処的なサービス応答時間
-
問題解決の目標または MTTR
-
問題の報告手順
予防的な第 2 の目標には次のようなものがあります。
-
デバイス ダウンまたはリンク ダウンの検出
-
ネットワーク エラーの検出
-
キャパシティまたはパフォーマンスの問題検出
第 1 の目標であるアベイラビリティとパフォーマンスのサービス レベル定義には次のものを含める必要があります。
目標
-
目標の測定方法
-
アベイラビリティとパフォーマンスの測定を担当する関係者
-
アベイラビリティとパフォーマンスのターゲットを担当する関係者
-
不適合プロセス
可能であれば、利益相反を防ぐために、測定を担当する関係者と結果の担当者を別にすることを推奨します。時々、追加/移動/変更のエラー、未検出のエラー、アベイラビリティの測定の問題により、アベイラビリティの数の調整が必要になることもあります。サービス レベル定義には、精度を改善するため、および誤った調整を避けるために結果を変更するプロセスを含めても構いません。アベイラビリティとパフォーマンスを測定する方法については、次の項を参照してください。
事後対処的な第 2 の目標のサービス レベル定義では、ネットワークまたは IT 全般にわたる問題を検出した後、組織がどのようにしてその問題に対処するかを規定します。次に例を示します。
-
問題の優先順位の定義
-
コール優先順位による事後対処的なサービス応答時間
-
問題解決の目標、または MTTR
-
問題の報告手順
一般に、これらの目標は、特定の時間にだれが問題を担当し、どの程度現在の仕事を中断して定義された問題に対処するかを定義します。他のサービス レベル定義と同様に、サービス レベル文書は、目標の測定方法、測定を担当する関係者、および非適合プロセスを詳しく説明する必要があります。
予防的な第 2 の目標のサービス定義では、組織がどのようにして予防的サポートを提供するか(たとえば、ネットワーク ダウン、リンクダウン、またはデバイスダウン状態の検出、ネットワーク エラー状態、ネットワーク キャパシティのしきい値など)を規定します。品質の予防的管理は問題の解消と迅速な解決に効果があるため、予防的管理を推進するような目標を設定します。これを実現するには通常、ユーザから連絡を受ける前に検出および解決した予防的なケースの数を目標として設定します。多くの組織はこの目的のため、予防的なケースと事後処理的なケースを特定するために、ヘルプ デスク ソフトウェアでフラグを設定します。サービス レベル文書にも、目標の測定方法、測定を担当する関係者、および非適合プロセスについて詳しく記載する必要があります。
パフォーマンス指標のメトリック
定義されたサービス レベルの目標はすべて測定可能であることが常に推奨されます。これにより、組織でサービス レベルを測定し、アベイラビリティとパフォーマンスという第 1 の目標の達成を阻害するサービス問題の根本原因を特定できるほか、特定のターゲットに向けた改善を実施できます。全体的に見ると、規準とは単に、ネットワーク管理者がサービス レベルの一貫性を管理し、ビジネス要件に従って改善を実施するためのツールに過ぎません。
残念ながら、アベイラビリティ、パフォーマンス、およびその他の規準を収集している組織はそれほど多くありません。組織ではその理由として、完璧な精度、コスト、ネットワークのオーバーヘッド、および使用可能なリソースを提供できないことを挙げています。これらの要素はサービス レベルの測定能力に影響を与える可能性がありますが、サービス レベルは全体的な目標に照準を合わせて管理し、改善すべきです。多くの組織は、低コストで低オーバーヘッドであり、完全な正確性は提供しないかもしれないが、これらの主な目標を満たすメトリックを作成できています。
アベイラビリティとパフォーマンスの測定は、サービス レベル メトリックで無視されることが多い領域の 1 つです。これらの規準をうまく利用している組織では、非常に単純な 2 通りの方法を使用しています。1 つめの方法は、ネットワークのコア部分からエッジに対して Internet Control Message Protocol(ICMP; インターネット制御メッセージ プロトコル)ping パケットを送信することです。この方法によってパフォーマンスに関する情報を取得することもできます。また、この方法を活用している組織では、同類のデバイスを LAN デバイスや国内のフィールド オフィスなどの「アベイラビリティ グループ」に分類しています。通常はネットワークの地理的領域やビジネス クリティカルな領域が違えばサービス レベルの目標も異なるため、この方法も魅力的です。この方法を使用すれば、規準グループ別に特定のアベイラビリティ グループに属するすべてのデバイスの平均をとることができるため、適正な結果が得られます。
アベイラビリティを計算するためのもう 1 つの有用な方法は、トラブル チケットと、Impacted User Minutes(IUM)と呼ばれる測定値を使用することです。 この方法では停止によって影響を受けたユーザの数を表にまとめ、ユーザの数と停止時間(分)を掛け合わせます。その時間帯における合計時間(分)のパーセンテージとして表すと、これはアベイラビリティに容易に換算できます。いずれにしても、ダウンタイムの根本原因を特定し、測定することもでき、改善の対象をさらに容易に決定できます。根本原因カテゴリには、ハードウェアの問題、ソフトウェアの問題、リンクまたは通信事業者の問題、電源または環境の問題、変更障害、ユーザ エラーなどが含まれます。
測定可能な事後対処的サポート目標は、次のとおりです。
-
コール優先順位による事後対処的なサービス応答時間
-
問題解決の目標、または MTTR
-
問題の報告時間
次のフィールドを含むヘルプ デスク データベースからのレポートを生成することで、事後処理的なサポートの目標を測定します。
-
コールが最初に報告された(またはデータベースに入力された)時間
-
問題に対処する担当者によってコールが受け入れられた時間
-
問題が報告された時間
-
問題がクローズされた時間
これらの規準には、データベースに一貫して問題を入力し、リアルタイムで問題を更新するために管理者のインフルエンス(影響力)が必要となる場合があります。場合によっては、組織はネットワーク イベントまたは電子メール要求に関するトラブル チケットを自動的に生成できます。この方法を使用すれば、問題の開始時間を正確に特定できます。この種の規準から生成されたレポートでは通常、問題はプライオリティ別、ワークグループ別、および担当者別にソートされており、起こりうる問題の特定に役立ちます。
予防的サポート プロセスの測定は、予防的な作業をモニタして、その効果の測定のくつかを計算する必要があるため、より困難です。この領域では、作業はあまり行われていませんでした。ただし、ヘルプ デスクにネットワークの問題を実際に報告するユーザの割合が非常に少なく、問題を報告する際に、問題を説明したり、問題がネットワークに関連していると特定したりすることに時間がかかることは明らかです。冗長デバイスまたはリンクの障害は、エンドユーザに対する影響が少ないため、すべての予防的なケースが、アベイラビリティやパフォーマンスにすぐに影響を与えるわけではありません。
予防的サービス レベル定義または契約を実装している組織がそれを行っているのは、ビジネス要件とアベイラビリティ リスクの可能性のためです。測定は、ユーザによって生成された事後処理的なケースとは異なり、予防的なケース数またはパーセンテージの点から実行されます。各領域の予防的なケースの量も測定することをお勧めします。そのカテゴリとして、ダウン デバイス、ダウン リンク、ネットワーク エラー、キャパシティ違反などがあります。アベイラビリティ モデリングと予防的ケースを使用してさらに作業を進めると、予防的サービス定義を実装することで達成されるアベイラビリティの効果を判断できる場合もあります。
サービス レベル管理のレビュー
サービス レベル管理の成功のもう 1 つの基準は、サービス レベル管理のレビューです。これは SLA を作成しているかどうかにかかわらず実施することが望まれます。サービス レベル管理の検討は、定義されたサービス レベルの測定担当者やサービス レベルの定義に関与した関係者との月次ミーティング時に実施します。SLA が関係しているときには、ユーザ グループが出席しても構いません。ミーティングの目的は、測定されたサービス レベル定義のパフォーマンスを検討し、改善を実施することです。
ミーティングには、それぞれ次を含む定義されたアジェンダが必要です。
-
ある一定期間にわたって測定されたサービス レベルの検討
-
個々の領域で定義された改善イニチアチブの検討
-
現在のサービス レベル メトリック
-
現在のメトリックのセットに基づく、どのような改善が必要なのかの話し合い。
ある程度の期間が経過すると、組織ではグループの有効性を判断するために、サービス レベルの適合状況のトレンド分析を実施できます。このプロセスは品質管理サークルまたは品質改善プロセスと同じです。ミーティングは個々の問題をターゲットとして設定したり、根本原因に基づいてソリューションを決定したりする際に役立ちます。
サービス レベル管理の要約
要約すると、サービス レベル管理では、組織が最新の問題ではなく、ビジネス要件によってネットワークのアベイラビリティとパフォーマンスのレベルが決定される、予防的なサポート モデルに事後処理的なサポート モデルから移行できます。このプロセスを利用すれば、サービス レベルの継続的な改善を可能にする環境が構築され、ビジネス上の競争力が向上します。サービス レベル管理は予防的ネットワーク管理の最も重要な管理要素でもあります。したがって、サービス レベル管理はネットワーク計画および設計フェーズで強く推奨され、新しく定義されたネットワーク アーキテクチャから開始する必要があります。これによって組織では最初からソリューションを適切に実装できるようになり、ダウンタイムや手直しの量を最小限に抑えることができます。
 フィードバック
フィードバック