Procedure di backup e ripristino per vari componenti Ultra-M - CPS
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Introduzione
In questo documento vengono descritti i passaggi necessari per eseguire il backup e il ripristino di una macchina virtuale in un'installazione Ultra-M che ospita le chiamate alle funzioni di rete virtuale di CPS.
Premesse
Ultra-M è una soluzione mobile packet core preconfezionata e convalidata, progettata per semplificare l'installazione delle funzioni di rete virtuale (VNF). La soluzione Ultra-M è costituita dai seguenti tipi di macchine virtuali (VM):
- Elastic Services Controller (ESC)
- Cisco Policy Suite (CPS)
L'architettura di alto livello di Ultra-M e i componenti coinvolti sono illustrati in questa immagine.
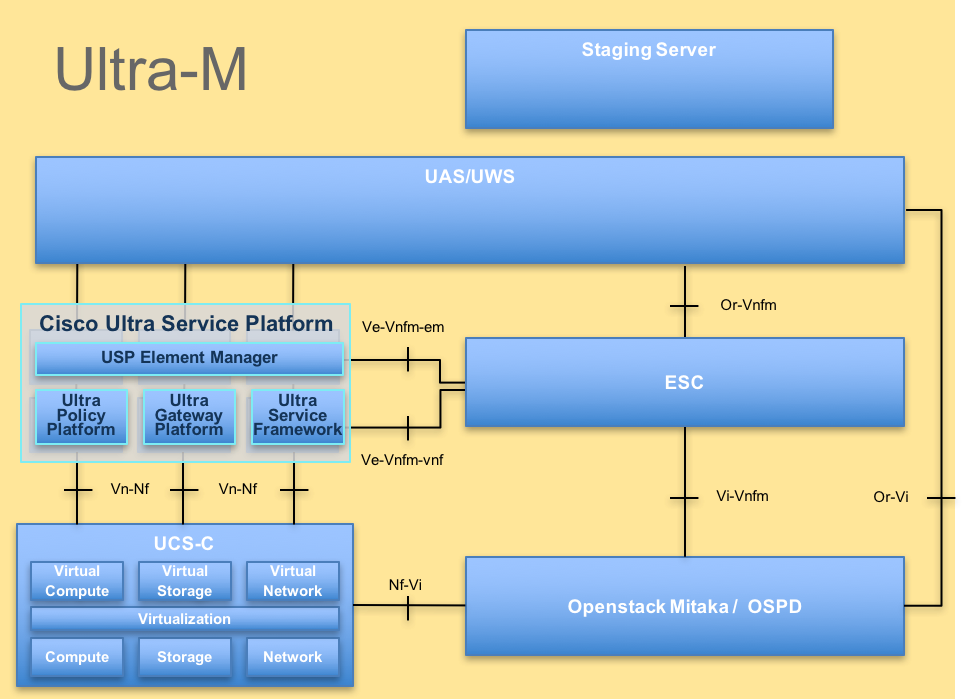

Nota: la release di Ultra M 5.1.x è stata presa in considerazione per definire le procedure descritte in questo documento. Questo documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M.
Abbreviazioni
| VNF | Funzione di rete virtuale |
| ESC | Elastic Service Controller |
| MOP | Metodo di procedura |
| OSD | Dischi Object Storage |
| HDD | Unità hard disk |
| SSD | Unità a stato solido |
| VIM | Virtual Infrastructure Manager |
| VM | Macchina virtuale |
| UUID | Identificatore univoco universale |
Procedura di backup
Backup OSPD
1. Controllare lo stato dello stack OpenStack e l'elenco dei nodi.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
2. Verificare se tutti i servizi undercloud sono in stato caricato, attivo e in esecuzione dal nodo OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, for example, generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
3. Verificare di disporre di spazio su disco sufficiente prima di eseguire il processo di backup. Si prevede che questa scheda sia di almeno 3,5 GB.
[stack@director ~]$df -h
4. Eseguire questi comandi come utente root per eseguire il backup dei dati dal nodo undercloud in un file denominato undercloud-backup-[timestamp].tar.gz e trasferirlo al server di backup.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Backup ESC
1. ESC, a sua volta, richiama la funzione di rete virtuale (VNF) interagendo con VIM.
2. La ridondanza 1:1 di ESC nella soluzione Ultra-M. In Ultra-M sono distribuite 2 VM ESC che supportano un singolo errore. Ad esempio, ripristinare il sistema in caso di un singolo errore.
Nota: se si verifica più di un errore, non è supportato e può essere necessario ridistribuire il sistema.
Dettagli backup ESC:
- Configurazione in esecuzione
- DB CDB ConfD
- Registri ESC
- Configurazione Syslog
3. La frequenza del backup del database ESC è complessa e deve essere gestita con attenzione durante il monitoraggio e la manutenzione da parte di ESC delle varie macchine di stato per le diverse VM VNF installate. Si consiglia di eseguire questi backup dopo queste attività in un determinato VNF/POD/sito.
4. Verificare che lo stato di ESC sia corretto utilizzando lo script health.sh.
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Primary Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (Primary) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
5. Eseguire il backup della configurazione corrente e trasferire il file sul server di backup.
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
Backup database ESC
1. Accedere alla VM ESC ed eseguire questo comando prima di eseguire il backup.
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
2. Controllare la modalità ESC e assicurarsi che si trovi in modalità di manutenzione.
[root@esc esc-scripts]# escadm op_mode show
3. Eseguire il backup del database utilizzando lo strumento di ripristino del backup del database disponibile in ESC.
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://<username>:<password>@<backup_vm_ip>:<filename>
4. Ripristinare la modalità di funzionamento di ESC e confermare la modalità.
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
5. Passare alla directory scripts e raccogliere i log.
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
6. Per creare un'istantanea dell'ESC, chiudere prima l'ESC.
shutdown -r now
7. Da OSPD, creare una copia istantanea dell'immagine.
nova image-create --poll esc1 esc_snapshot_27aug2018
8. Verificare che lo snapshot sia stato creato.
openstack image list | grep esc_snapshot_27aug2018
9. Avviare l'ESC da OSPD.
nova start esc1
10. Ripetere la stessa procedura sulla VM ESC in standby e trasferire i registri sul server di backup.
11. Raccogliere il backup della configurazione syslog su entrambe le VM ESC e trasferirle sul server di backup.
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
Backup CPS
Passaggio 1. Creare un backup di CPS Cluster-Manager.
Utilizzare questo comando per visualizzare le istanze nova e annotare il nome dell'istanza della macchina virtuale di Gestione cluster:
nova list
Ferma la Cluman da ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP <vm-name>
Passaggio 2. Verificare che Gestione cluster sia in stato SHUTOFF.
admin@esc1 ~]$ /opt/cisco/esc/confd/bin/confd_cli admin@esc1> show esc_datamodel opdata tenants tenant Core deployments * state_machine
Passaggio 3. Creare un'immagine snapshot nuova come illustrato in questo comando:
nova image-create --poll <cluman-vm-name> <snapshot-name>
Nota: assicurarsi di disporre di spazio su disco sufficiente per la copia istantanea.
.Importante - Nel caso in cui la VM diventi irraggiungibile dopo la creazione dell'istantanea, controllare lo stato della VM utilizzando il comando nova list. Se si trova nello stato SHUTOFF, è necessario avviare la VM manualmente.
Passaggio 4. Visualizzare l'elenco delle immagini con questo comando: nova image-list
Immagine 1: Output di esempio

Passaggio 5. Quando viene creata una copia istantanea, l'immagine della copia istantanea viene archiviata in OpenStack Glance. Per archiviare la copia istantanea in un archivio dati remoto, scaricarla e trasferire il file in OSPD in (/home/stack/CPS_BACKUP).
Per scaricare l'immagine, usare questo comando in OpenStack:
glance image-download –-file For example: glance image-download –-file snapshot.raw 2bbfb51c-cd05-4b7c-ad77-8362d76578db
Passaggio 6. Elencare le immagini scaricate come mostrato in questo comando:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
Passaggio 7. Archiviare lo snapshot della macchina virtuale di Gestione cluster da ripristinare in futuro.
2. Eseguire il backup della configurazione e del database.
1. config_br.py -a export --all /var/tmp/backup/ATP1_backup_all_$(date +\%Y-\%m-\%d).tar.gz OR 2. config_br.py -a export --mongo-all /var/tmp/backup/ATP1_backup_mongoall$(date +\%Y-\%m-\%d).tar.gz 3. config_br.py -a export --svn --etc --grafanadb --auth-htpasswd --haproxy /var/tmp/backup/ATP1_backup_svn_etc_grafanadb_haproxy_$(date +\%Y-\%m-\%d).tar.gz 4. mongodump - /var/qps/bin/support/env/env_export.sh --mongo /var/tmp/env_export_$date.tgz 5. patches - cat /etc/broadhop/repositories, check which patches are installed and copy those patches to the backup directory /home/stack/CPS_BACKUP on OSPD 6. backup the cronjobs by taking backup of the cron directory: /var/spool/cron/ from the Pcrfclient01/Cluman. Then move the file to CPS_BACKUP on the OSPD.
Verificare dal crontab-l se sono necessari altri backup.
Trasferire tutti i backup in OSPD /home/stack/CPS_BACKUP.
3. Eseguire il backup del file yaml da ESC primario.
/opt/cisco/esc/confd/bin/netconf-console --host 127.0.0.1 --port 830 -u <admin-user> -p <admin-password> --get-config > /home/admin/ESC_config.xml
Trasferire il file in OSPD /home/stack/CPS_BACKUP.
4. Eseguire il backup delle voci crontab -l.
Creare un file di testo con crontab -l e ftp in una posizione remota (in OSPD /home/stack/CPS_BACKUP).
5. Eseguire un backup dei file di route dal client LB e PCRF.
Collect and scp the configurations from both LBs and Pcrfclients route -n /etc/sysconfig/network-script/route-*
Procedura di ripristino
Ripristino OSPD
La procedura di ripristino OSPD viene eseguita in base a questi presupposti.
1. Il backup OSPD è disponibile dal vecchio server OSPD.
2. Il ripristino OSPD può essere eseguito sul nuovo server che sostituisce il vecchio server OSPD nel sistema. .
Ripristino ESC
1. La VM ESC è ripristinabile se la VM è in stato di errore o di arresto eseguire un riavvio a freddo per attivare la VM interessata. Eseguire questi passaggi per ripristinare ESC.
2. Identificare la VM in stato ERROR o Shutdown, una volta identificato il riavvio a freddo della VM ESC. In questo esempio, si sta riavviando auto-test-vnfm1-ESC-0.
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.11; auto-testautovnf1-uas-management=172.31.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.15; auto-testautovnf1-uas-management=172.31.11.15 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
3. Se la VM ESC viene eliminata e deve essere riattivata. Utilizzare la sequenza di passaggi seguente.
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.16.11.14; vnf1-UAS-uas-management=172.16.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
4. Se la VM ESC è irrecuperabile e richiede il ripristino del database, ripristinare il database dal backup precedentemente eseguito.
5. Per il ripristino del database ESC, è necessario assicurarsi che il servizio esc venga arrestato prima di ripristinare il database; per ESC HA, eseguire prima la VM secondaria, quindi la VM primaria.
# service keepalived stop
6. Controllare lo stato del servizio ESC e verificare che tutto sia stato arrestato nelle VM principali e secondarie per HA.
# escadm status
7. Eseguire lo script per ripristinare il database. Come parte del ripristino del database nella nuova istanza ESC creata, lo strumento può anche promuovere una delle istanze come ESC primario, montare la sua cartella DB sul dispositivo drbd e può avviare il database PostgreSQL.
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://<username>:<password>@<backup_vm_ip>:<filename>
8. Riavviare il servizio ESC per completare il ripristino del database. Per l'esecuzione di HA in entrambe le VM, riavviare il servizio keepalive.
# service keepalived start
9. Una volta che la VM è stata ripristinata e in esecuzione; accertarsi che tutta la configurazione specifica del syslog sia ripristinata dal precedente backup noto. accertarsi che sia ripristinata in tutte le VM ESC.
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
10. Se è necessario ricreare la protezione avanzata da uno snapshot OSPD, utilizzare questo comando con lo snapshot creato durante il backup.
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
11. Controllare lo stato del controllo di sicurezza dopo il completamento della ricostruzione.
nova list --fileds name,host,status,networks | grep esc
12. Controllare l'integrità ESC con questo comando.
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
Quando ESC non riesce ad avviare la macchina virtuale
- In alcuni casi, ESC può non riuscire ad avviare la macchina virtuale a causa di uno stato imprevisto. Per risolvere il problema, è possibile eseguire il passaggio a un ESC riavviando l'ESC principale. Il passaggio al formato ESC può richiedere circa un minuto. Eseguire health.sh sul nuovo ESC primario per verificare che sia attivo. Quando ESC diventa Primario, ESC può correggere lo stato della VM e avviare la VM. Poiché l'operazione è pianificata, è necessario attendere 5-7 minuti per il completamento.
- È possibile monitorare /var/log/esc/yangesc.log e /var/log/esc/escmanager.log. Se NON si vede che la VM viene ripristinata dopo 5-7 minuti, l'utente deve eseguire il ripristino manuale delle VM interessate.
- Una volta che la VM è stata ripristinata ed eseguita correttamente; assicurarsi che tutta la configurazione specifica del syslog sia ripristinata dal precedente backup noto riuscito. Garantire il ripristino in tutte le VM ESC
root@abautotestvnfm1em-0:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@abautotestvnfm1em-0:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
Ripristino CPS
Ripristinare la macchina virtuale di Cluster Manager in OpenStack.
Passaggio 1. Copiare lo snapshot della macchina virtuale di Gestione cluster nel blade del controller, come mostrato in questo comando:
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
Passaggio 2. Caricare l'immagine della copia istantanea in OpenStack dall'archivio dati:
glance image-create --name --file --disk-format qcow2 --container-format bare
Passaggio 3. Verificare se la copia istantanea è stata caricata con un comando Nova, come mostrato nell'esempio:
nova image-list
Immagine 2: Output di esempio

Passaggio 4. A seconda che la VM di Gestione cluster esista o meno, è possibile scegliere di creare la cluman o di ricrearla:
· Se l'istanza della VM di Cluster Manager non esiste, creare la VM cluman con un comando Heat o Nova, come mostrato nell'esempio seguente:
Creare la VM cluman con ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli edit-config /opt/cisco/esc/cisco-cps/config/gr/tmo/gen/<original_xml_filename>
Il cluster PCRF può essere generato con l'aiuto del comando precedente e quindi ripristinare le configurazioni di Gestione cluster dai backup eseguiti con il comando config_br.py restore, mongorestore dal dump eseguito nel backup.
delete - nova boot --config-drive true --image "" --flavor "" --nic net-id=",v4-fixed-ip=" --nic net-id="network_id,v4-fixed-ip=ip_address" --block-device-mapping "/dev/vdb=2edbac5e-55de-4d4c-a427-ab24ebe66181:::0" --availability-zone "az-2:megh-os2-compute2.cisco.com" --security-groups cps_secgrp "cluman"
· Se l'istanza VM di Cluster Manager esiste, utilizzare un comando nova rebuild per ricreare l'istanza VM di Cluster con lo snapshot caricato, come mostrato di seguito:
nova rebuild <instance_name> <snapshot_image_name>
Ad esempio:
nova rebuild cps-cluman-5f3tujqvbi67 cluman_snapshot
Passaggio 5. Elencare tutte le istanze come illustrato e verificare che la nuova istanza di Gestione cluster sia stata creata e in esecuzione:
nova list
Immagine 3. Output di esempio

Ripristinare le patch più recenti nel sistema.
1. Copy the patch files to cluster manager which were backed up in OSPD /home/stack/CPS_BACKUP 2. Login to the Cluster Manager as a root user. 3. Untar the patch by executing this command: tar -xvzf [patch name].tar.gz 4. Edit /etc/broadhop/repositories and add this entry: file:///$path_to_the plugin/[component name] 5. Run build_all.sh script to create updated QPS packages: /var/qps/install/current/scripts/build_all.sh 6. Shutdown all software components on the target VMs: runonall.sh sudo monit stop all 7. Make sure all software components are shutdown on target VMs: statusall.sh
Nota: lo stato corrente di tutti i componenti software deve essere Non monitorato.
8. Update the qns VMs with the new software using reinit.sh script: /var/qps/install/current/scripts/upgrade/reinit.sh 9. Restart all software components on the target VMs: runonall.sh sudo monit start all 10. Verify that the component is updated, run: about.sh
Ripristinare i Cronjobs.
1. Spostare il file di backup da OSPD a Cluman/Pcrfclient01.
2. Eseguire il comando per attivare il cronjob dal backup.
#crontab Cron-backup
3. Verificare se i cronjob sono stati attivati da questo comando.
#crontab -l
Ripristinare le singole VM nel cluster.
Per ridistribuire la VM pcrfclient01:
Passaggio 1. Accedere alla macchina virtuale di Cluster Manager come utente root.
Passaggio 2. Memorizzare l'UUID dell'archivio SVN utilizzando questo comando:
svn info http://pcrfclient02/repos | grep UUID
Il comando può generare l'UUID del repository.
Ad esempio: UUID repository: ea50bbd2-5726-46b8-b807-10f4a7424f0e
Passaggio 3. Importare i dati di configurazione di Generatore criteri di backup in Gestione cluster, come illustrato nell'esempio seguente:
config_br.py -a import --etc-oam --svn --stats --grafanadb --auth-htpasswd --users /mnt/backup/oam_backup_27102016.tar.gz
Nota: molte distribuzioni eseguono un processo cron che esegue regolarmente il backup dei dati di configurazione. Per ulteriori informazioni, vedere Backup del repository di Subversion.
Passaggio 4. Per generare i file di archivio VM in Gestione cluster utilizzando le configurazioni più recenti, eseguire questo comando:
/var/qps/install/current/scripts/build/build_svn.sh
Passaggio 5. Per distribuire la VM pcrfclient01, eseguire una delle operazioni seguenti:
In OpenStack, utilizzare il modello HEAT o il comando Nova per ricreare la VM. Per ulteriori informazioni, vedere la Guida all'installazione di CPS per OpenStack.
Passaggio 6. Ristabilire la sincronizzazione primaria/secondaria SVN tra pcrfclient01 e pcrfclient02 con pcrfclient01 come principale eseguendo queste serie di comandi.
Se SVN è già sincronizzato, non utilizzare questi comandi.
Per verificare se SVN è sincronizzato, eseguire questo comando da pcrfclient02.
Se viene restituito un valore, SVN è già sincronizzato:
/usr/bin/svn propget svn:sync-from-url --revprop -r0 http://pcrfclient01/repos
Eseguire i seguenti comandi da pcrfclient01:
/bin/rm -fr /var/www/svn/repos /usr/bin/svnadmin create /var/www/svn/repos /usr/bin/svn propset --revprop -r0 svn:sync-last-merged-rev 0 http://pcrfclient02/repos-proxy-sync /usr/bin/svnadmin setuuid /var/www/svn/repos/ "Enter the UUID captured in step 2" /etc/init.d/vm-init-client / var/qps/bin/support/recover_svn_sync.sh
Passaggio 7. Se pcrfclient01 è anche la VM arbitro, eseguire i seguenti passaggi:
a) Creare le scritture di avvio/arresto mongodb in base alla configurazione del sistema. Non tutte le distribuzioni dispongono di tutti questi database configurati.
Nota: fare riferimento a /etc/broadhop/mongoConfig.cfg per determinare i database da configurare.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
b) Avviare la procedura mongo:
/usr/bin/systemctl start sessionmgr-XXXXX
c) Attendere l'avvio dell'arbitro, quindi eseguire diagnostics.sh —get_replica_status per verificare lo stato del set di repliche.
Per ridistribuire la VM pcrfclient02:
Passaggio 1. Accedere alla macchina virtuale di Cluster Manager come utente root.
Passaggio 2. Per generare i file di archivio VM in Gestione cluster utilizzando le configurazioni più recenti, eseguire questo comando:
/var/qps/install/current/scripts/build/build_svn.sh
Passaggio 3. Per distribuire la VM pcrfclient02, eseguire una delle operazioni seguenti:
In OpenStack, utilizzare il modello HEAT o il comando Nova per ricreare la VM. Per ulteriori informazioni, vedere la Guida all'installazione di CPS per OpenStack.
Passaggio 4. Proteggere la shell in pcrfclient01:
ssh pcrfclient01
Passaggio 5. Eseguire questo script per recuperare i repository SVN da pcrfclient01:
/var/qps/bin/support/recover_svn_sync.sh
Per ridistribuire una VM sessionmgr:
Passaggio 1. Accedere alla macchina virtuale di Cluster Manager come utente root.
Passaggio 2. Per distribuire la macchina virtuale sessionmgr e sostituire la macchina virtuale danneggiata o non riuscita, eseguire una delle operazioni seguenti:
In OpenStack, utilizzare il modello HEAT o il comando Nova per ricreare la VM. Per ulteriori informazioni, vedere la Guida all'installazione di CPS per OpenStack.
Passaggio 3. Creare gli script di avvio/arresto mongodb in base alla configurazione del sistema.
Non tutte le distribuzioni dispongono di tutti questi database configurati. Fare riferimento a /etc/broadhop/mongoConfig.cfg per determinare i database da configurare.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
Passaggio 4. Proteggere la shell nella macchina virtuale sessionmgr e avviare il processo mongo:
ssh sessionmgrXX /usr/bin/systemctl start sessionmgr-XXXXX
Passaggio 5. Attendere l'avvio dei membri e la sincronizzazione dei membri secondari, quindi eseguire diagnostics.sh —get_replica_status per verificare lo stato del database.
Passaggio 6. Per ripristinare il database di Session Manager, utilizzare uno dei seguenti comandi di esempio a seconda che il backup sia stato eseguito con l'opzione —mongo-all o —mongo:
• config_br.py -a import --mongo-all --users /mnt/backup/Name of backup or • config_br.py -a import --mongo --users /mnt/backup/Name of backup
Per ridistribuire la macchina virtuale di Policy Director (servizio di bilanciamento del carico):
Passaggio 1. Accedere alla macchina virtuale di Cluster Manager come utente root.
Passaggio 2. Per importare i dati di configurazione di Generatore criteri di backup in Gestione cluster, eseguire questo comando:
config_br.py -a import --network --haproxy --users /mnt/backup/lb_backup_27102016.tar.gz
Passaggio 3. Per generare i file di archivio VM in Gestione cluster utilizzando le configurazioni più recenti, eseguire questo comando:
/var/qps/install/current/scripts/build/build_svn.sh
Passaggio 4. Per distribuire la VM lb01, eseguire una delle operazioni seguenti:
In OpenStack, utilizzare il modello HEAT o il comando Nova per ricreare la VM. Per ulteriori informazioni, vedere la Guida all'installazione di CPS per OpenStack.
Per ridistribuire la macchina virtuale di Policy Server (QNS):
Passaggio 1. Accedere alla macchina virtuale di Cluster Manager come utente root.
Passaggio 2. Importare i dati di configurazione di Generatore criteri di backup in Gestione cluster, come illustrato nell'esempio seguente:
config_br.py -a import --users /mnt/backup/qns_backup_27102016.tar.gz
Passaggio 3. Per generare i file di archivio VM in Gestione cluster utilizzando le configurazioni più recenti, eseguire questo comando:
/var/qps/install/current/scripts/build/build_svn.sh
Passaggio 4. Per distribuire la VM qns, eseguire una delle operazioni seguenti:
In OpenStack, utilizzare il modello HEAT o il comando Nova per ricreare la VM. Per ulteriori informazioni, vedere la Guida all'installazione di CPS per OpenStack.
Procedura generale per il ripristino del database.
Passaggio 1. Eseguire questo comando per ripristinare il database:
config_br.py –a import --mongo-all /mnt/backup/backup_$date.tar.gz where $date is the timestamp when the export was made.
Ad esempio,
config_br.py –a import --mongo-all /mnt/backup/backup_27092016.tgz
Passaggio 2. Accedere al database e verificare se è in esecuzione e se è accessibile:
1. Accedere al gestore della sessione:
mongo --host sessionmgr01 --port $port
dove $port è il numero di porta del database da controllare. Ad esempio, 27718 è la porta predefinita Bilanciamento.
2. Visualizzare il database eseguendo questo comando:
show dbs
3. Passare la shell mongo al database eseguendo questo comando:
use $db
dove $db è il nome di un database visualizzato nel comando precedente.
Il comando use passa la shell mongo a quel database.
Ad esempio,
use balance_mgmt
4. Per visualizzare le raccolte, eseguire questo comando:
show collections
5. Per visualizzare il numero di record nella raccolta, eseguire questo comando:
db.$collection.count() For example, db.account.count()
L'esempio precedente può mostrare il numero di record nel conto di collection nel database Balance (balance_mgmt).
Ripristino del repository di Subversion.
Per ripristinare i dati di configurazione di Generatore criteri da un backup, eseguire questo comando:
config_br.py –a import --svn /mnt/backup/backup_$date.tgz where, $date is the date when the cron created the backup file.
Ripristinare Grafana Dashboard.
È possibile ripristinare il dashboard Grafana utilizzando questo comando:
config_br.py -a import --grafanadb /mnt/backup/
Convalida del ripristino.
Dopo aver ripristinato i dati, verificare il sistema funzionante eseguendo questo comando:
/var/qps/bin/diag/diagnostics.sh
Cronologia delle revisioni
| Revisione | Data di pubblicazione | Commenti |
|---|---|---|
2.0 |
20-Mar-2024 |
Titolo, introduzione, testo alternativo, traduzione automatica, requisiti di stile e formattazione aggiornati. |
1.0 |
21-Sep-2018 |
Versione iniziale |
Contributo dei tecnici Cisco
- Aaditya DeodharCisco Advanced Services
 Feedback
Feedback