Sostituzione PCRF di Compute Server UCS C240 M4
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
In questo documento viene descritto come sostituire un server di elaborazione difettoso in una configurazione Ultra-M che ospita funzioni di rete virtuale (VNF) di Cisco Policy Suite (CPS).
Premesse
Questo documento è destinato al personale Cisco che ha familiarità con la piattaforma Cisco Ultra-M e descrive i passaggi richiesti da eseguire a livello di OpenStack e CPS VNF al momento della sostituzione del server di elaborazione.
Nota: Per definire le procedure descritte in questo documento, viene presa in considerazione la release di Ultra M 5.1.x.
Controllo dello stato
Prima di sostituire un nodo di calcolo, è importante verificare lo stato di integrità corrente dell'ambiente della piattaforma Red Hat OpenStack. Si consiglia di controllare lo stato corrente per evitare complicazioni quando il processo di calcolo sostitutivo è attivo.
Passaggio 1. Da OpenStack Deployment (OSPD).
[root@director ~]$ su - stack
[stack@director ~]$ cd ansible
[stack@director ansible]$ ansible-playbook -i inventory-new openstack_verify.yml -e platform=pcrf
Passaggio 2. Verificare lo stato del sistema da un rapporto di ultrasuoni che viene generato ogni quindici minuti.
[stack@director ~]# cd /var/log/cisco/ultram-health
Passaggio 3. Controllare il file ultram_health_os.report.Gli unici servizi visualizzati come stato XXX sono neutron-sriov-nic-agent.service.
Passaggio 4. Per verificare se rabbitmq viene eseguito per tutti i controller eseguiti da OSPD.
[stack@director ~]# for i in $(nova list| grep controller | awk '{print $12}'| sed 's/ctlplane=//g') ; do (ssh -o StrictHostKeyChecking=no heat-admin@$i "hostname;sudo rabbitmqctl eval 'rabbit_diagnostics:maybe_stuck().'" ) & done
Passaggio 5. Verificare che la pietra sia abilitata
[stack@director ~]# sudo pcs property show stonith-enabled
Passaggio 6. Verifica dello stato del PCS per tutti i controller.
- Tutti i nodi controller sono avviati in haproxy-clone.
- Tutti i nodi controller sono attivi sotto galera.
- Tutti i nodi controller sono avviati in Rabbitmq.
- 1 nodo controller è attivo e 2 standby sotto redis.
Passaggio 7. Da OSPD.
[stack@director ~]$ for i in $(nova list| grep controller | awk '{print $12}'| sed 's/ctlplane=//g') ; do (ssh -o StrictHostKeyChecking=no heat-admin@$i "hostname;sudo pcs status" ) ;done
Passaggio 8. Verificare che tutti i servizi openstack siano attivi. Da OSPD eseguire questo comando.
[stack@director ~]# sudo systemctl list-units "openstack*" "neutron*" "openvswitch*"
Passaggio 9. Verificare che lo stato del CEPH sia HEALTH_OK per i controller.
[stack@director ~]# for i in $(nova list| grep controller | awk '{print $12}'| sed 's/ctlplane=//g') ; do (ssh -o StrictHostKeyChecking=no heat-admin@$i "hostname;sudo ceph -s" ) ;done
Passaggio 10. Verificare i log del componente OpenStack. Cercare eventuali errori:
Neutron:
[stack@director ~]# sudo tail -n 20 /var/log/neutron/{dhcp-agent,l3-agent,metadata-agent,openvswitch-agent,server}.log
Cinder:
[stack@director ~]# sudo tail -n 20 /var/log/cinder/{api,scheduler,volume}.log
Glance:
[stack@director ~]# sudo tail -n 20 /var/log/glance/{api,registry}.log
Passaggio 11. Da OSPD eseguire queste verifiche per API.
[stack@director ~]$ source
[stack@director ~]$ nova list
[stack@director ~]$ glance image-list
[stack@director ~]$ cinder list
[stack@director ~]$ neutron net-list
Passaggio 12. Verificare lo stato dei servizi.
Every service status should be “up”:
[stack@director ~]$ nova service-list
Every service status should be “ :-)”:
[stack@director ~]$ neutron agent-list
Every service status should be “up”:
[stack@director ~]$ cinder service-list
Backup
In caso di ripristino, Cisco consiglia di eseguire un backup del database OSPD attenendosi alla seguente procedura:
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Questo processo assicura che un nodo possa essere sostituito senza influire sulla disponibilità di alcuna istanza. È inoltre consigliabile eseguire il backup della configurazione CPS.
Per eseguire il backup delle VM CPS, dalla VM di Cluster Manager:
[root@CM ~]# config_br.py -a export --all /mnt/backup/CPS_backup_$(date +\%Y-\%m-\%d).tar.gz
or
[root@CM ~]# config_br.py -a export --mongo-all --svn --etc --grafanadb --auth-htpasswd --haproxy /mnt/backup/$(hostname)_backup_all_$(date +\%Y-\%m-\%d).tar.gz
Identificare le VM ospitate nel nodo di calcolo
Identificare le VM ospitate nel server di elaborazione:
[stack@director ~]$ nova list --field name,host,networks | grep compute-10
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d | pod1-compute-10.localdomain | Replication=10.160.137.161; Internal=192.168.1.131; Management=10.225.247.229; tb1-orch=172.16.180.129
Nota: Nell'output mostrato di seguito, la prima colonna corrisponde all'UUID (Universal Unique Identifier), la seconda colonna al nome della VM e la terza colonna al nome host in cui la VM è presente. I parametri di questo output vengono utilizzati nelle sezioni successive.
Disabilitare i servizi PCRF residenti sulla VM da arrestare
Passaggio 1. Accedere all'IP di gestione della macchina virtuale:
[stack@XX-ospd ~]$ ssh root@
Passaggio 2. Se la macchina virtuale è un SM, OAM o arbitro, arrestare inoltre i servizi sessionmgr:
[root@XXXSM03 ~]# cd /etc/init.d [root@XXXSM03 init.d]# ls -l sessionmgr* -rwxr-xr-x 1 root root 4544 Nov 29 23:47 sessionmgr-27717 -rwxr-xr-x 1 root root 4399 Nov 28 22:45 sessionmgr-27721 -rwxr-xr-x 1 root root 4544 Nov 29 23:47 sessionmgr-27727
Passaggio 3. Per ogni file denominato sessionmgr-xxxxx, eseguire il servizio sessionmgr-xxxxx stop:
[root@XXXSM03 init.d]# service sessionmgr-27717 stop
Rimozione del nodo di calcolo dall'elenco aggregato Nova
Passaggio 1. Elencare gli aggregati nova e identificare l'aggregato corrispondente al server di elaborazione basato sul VNF ospitato. In genere, il formato è <VNFNAME>-SERVICE<X>:
[stack@director ~]$ nova aggregate-list
+----+-------------------+-------------------+
| Id | Name | Availability Zone |
+----+-------------------+-------------------+
| 29 | POD1-AUTOIT | mgmt |
| 57 | VNF1-SERVICE1 | - |
| 60 | VNF1-EM-MGMT1 | - |
| 63 | VNF1-CF-MGMT1 | - |
| 66 | VNF2-CF-MGMT2 | - |
| 69 | VNF2-EM-MGMT2 | - |
| 72 | VNF2-SERVICE2 | - |
| 75 | VNF3-CF-MGMT3 | - |
| 78 | VNF3-EM-MGMT3 | - |
| 81 | VNF3-SERVICE3 | - |
+----+-------------------+-------------------+
In questo caso, il server di elaborazione da sostituire appartiene a VNF2. Pertanto, l'elenco di aggregazione corrispondente è VNF2-SERVICE2.
Passaggio 2. Rimuovere il nodo di calcolo dall'aggregazione identificata (rimuovere per nome host indicato nella sezione Identificare le VM ospitate nel nodo di calcolo😞
nova aggregate-remove-host
[stack@director ~]$ nova aggregate-remove-host VNF2-SERVICE2 pod1-compute-10.localdomain
Passaggio 3. Verificare se il nodo di calcolo viene rimosso dagli aggregati. A questo punto, l'host non deve essere elencato nell'aggregato:
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-SERVICE2
Calcola eliminazione nodo
I passaggi descritti in questa sezione sono comuni indipendentemente dalle VM ospitate nel nodo di calcolo.
Elimina da overcloud
Passaggio 1. Creare un file di script denominato delete_node.sh con il contenuto, come mostrato di seguito. Verificare che i modelli indicati siano gli stessi utilizzati nello script deploy.sh utilizzato per la distribuzione dello stack.
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack
[stack@director ~]$ source stackrc
[stack@director ~]$ /bin/sh delete_node.sh
+ openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod1 49ac5f22-469e-4b84-badc-031083db0533
Deleting the following nodes from stack pod1:
- 49ac5f22-469e-4b84-badc-031083db0533
Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae
real 0m52.078s
user 0m0.383s
sys 0m0.086s
Passaggio 2. Attendere che l'operazione dello stack OpenStack passi allo stato COMPLETE.
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod1 | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
Elimina nodo di calcolo dall'elenco dei servizi
Eliminare il servizio di elaborazione dall'elenco dei servizi:
[stack@director ~]$ source corerc
[stack@director ~]$ openstack compute service list | grep compute-8
| 404 | nova-compute | pod1-compute-8.localdomain | nova | enabled | up | 2018-05-08T18:40:56.000000 |
openstack compute service delete
[stack@director ~]$ openstack compute service delete 404
Elimina agenti neutroni
Eliminare il vecchio agente neutronico associato e l'agente vswitch aperto per il server di elaborazione:
[stack@director ~]$ openstack network agent list | grep compute-8
| c3ee92ba-aa23-480c-ac81-d3d8d01dcc03 | Open vSwitch agent | pod1-compute-8.localdomain | None | False | UP | neutron-openvswitch-agent |
| ec19cb01-abbb-4773-8397-8739d9b0a349 | NIC Switch agent | pod1-compute-8.localdomain | None | False | UP | neutron-sriov-nic-agent |
openstack network agent delete
[stack@director ~]$ openstack network agent delete c3ee92ba-aa23-480c-ac81-d3d8d01dcc03
[stack@director ~]$ openstack network agent delete ec19cb01-abbb-4773-8397-8739d9b0a349
Elimina dal database Ironic
Eliminare un nodo dal database Ironic e verificarlo.
[stack@director ~]$ source stackrc
nova show| grep hypervisor
[stack@director ~]$ nova show pod1-compute-10 | grep hypervisor
| OS-EXT-SRV-ATTR:hypervisor_hostname | 4ab21917-32fa-43a6-9260-02538b5c7a5a
ironic node-delete
[stack@director ~]$ ironic node-delete 4ab21917-32fa-43a6-9260-02538b5c7a5a
[stack@director ~]$ ironic node-list (node delete must not be listed now)
Installare il nuovo nodo di calcolo
I passaggi per installare un nuovo server UCS C240 M4 e le fasi di configurazione iniziali sono disponibili all'indirizzo: Guida all'installazione e all'assistenza del server Cisco UCS C240 M4
Passaggio 1. Dopo l'installazione del server, inserire i dischi rigidi nei rispettivi slot come server precedente.
Passaggio 2. Accedere al server utilizzando l'indirizzo IP CIMC.
Passaggio 3. Eseguire l'aggiornamento del BIOS se il firmware non corrisponde alla versione consigliata utilizzata in precedenza. Le fasi per l'aggiornamento del BIOS sono riportate di seguito: Guida all'aggiornamento del BIOS dei server con montaggio in rack Cisco UCS serie C
Passaggio 4. Per verificare lo stato delle unità fisiche, selezionare Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info (Informazioni sull'unità fisica). Deve essere non configurato correttamente
Lo storage mostrato qui può essere un'unità SSD.

Passaggio 5. Per creare un'unità virtuale dalle unità fisiche con RAID di livello 1, selezionare Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Informazioni sul controller > Crea unità virtuale da unità fisiche inutilizzate
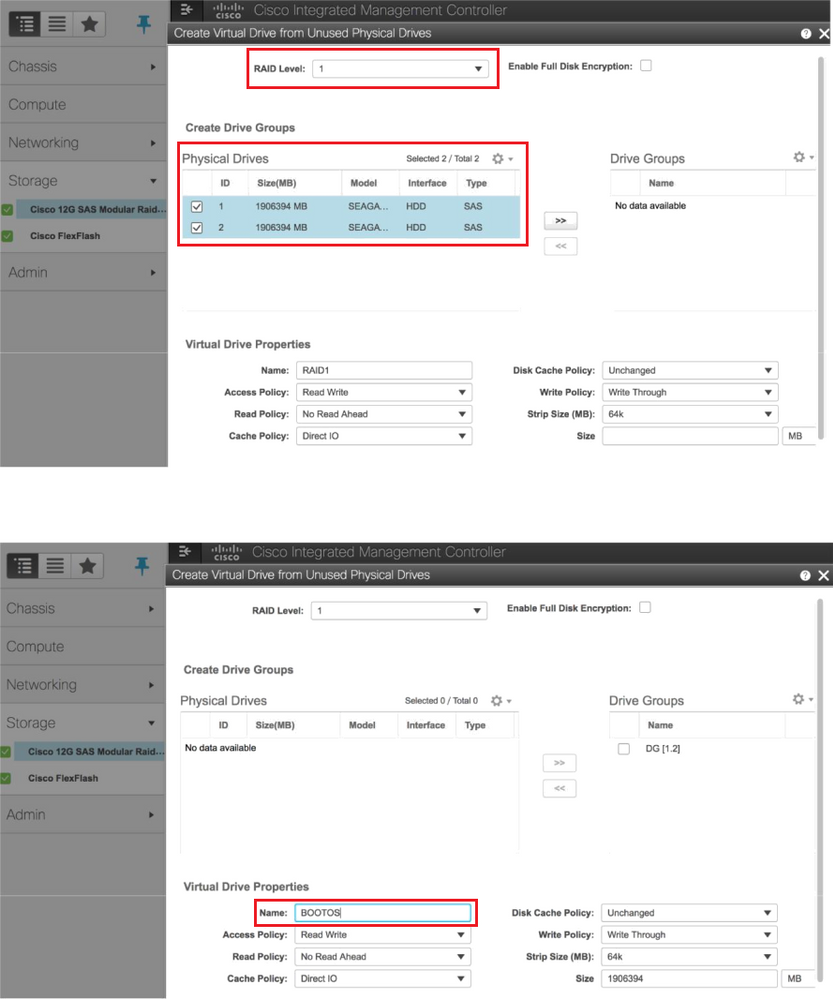
Passaggio 6. Selezionare il DVD e configurare Set as Boot Drive, come mostrato nell'immagine.

Passaggio 7. Per abilitare IPMI su LAN, selezionare Admin > Communication Services > Communication Services, come mostrato nell'immagine.

Passaggio 8. Per disabilitare l'HyperThreading, come mostrato nell'immagine, selezionare Compute > BIOS > Configure BIOS > Advanced > Processor Configuration (Calcola > BIOS > Configura BIOS > Avanzate > Configurazione processore).

Nota: L'immagine qui illustrata e le procedure di configurazione descritte in questa sezione fanno riferimento alla versione del firmware 3.0(3e). Se si utilizzano altre versioni, potrebbero verificarsi lievi variazioni
Aggiungi nuovo nodo di calcolo all'overcloud
I passaggi menzionati in questa sezione sono comuni indipendentemente dalla VM ospitata dal nodo di calcolo.
Passaggio 1. Aggiungere un server di elaborazione con un indice diverso.
Creare un file add_node.json contenente solo i dettagli del nuovo server di elaborazione da aggiungere. Verificare che il numero di indice per il nuovo server di elaborazione non sia già stato utilizzato. In genere, incrementa il valore di calcolo successivo più alto.
Esempio: La versione precedente più alta era compute-17, quindi creò compute-18 nel caso del sistema 2-vnf.
Nota: Prestare attenzione al formato json.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
""
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
Passaggio 2. Importare il file json.
[stack@director ~]$ openstack baremetal import --json add_node.json
Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d
Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e
Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e
Successfully set all nodes to available.
Passaggio 3. Eseguire l'introspezione del nodo utilizzando l'UUID indicato nel passaggio precedente.
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e
[stack@director ~]$ ironic node-list |grep 7eddfa87
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False |
[stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide
Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c
Waiting for introspection to finish...
Successfully introspected all nodes.
Introspection completed.
Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9
Successfully set all nodes to available.
[stack@director ~]$ ironic node-list |grep available
| 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
Passaggio 4. Aggiungere gli indirizzi IP in custom-templates/layout.yml sotto ComputeIPs. Aggiungere l'indirizzo alla fine dell'elenco per ogni tipo, ad esempio compute-0.
ComputeIPs:
internal_api:
- 11.120.0.43
- 11.120.0.44
- 11.120.0.45
- 11.120.0.43 <<< take compute-0 .43 and add here
tenant:
- 11.117.0.43
- 11.117.0.44
- 11.117.0.45
- 11.117.0.43 << and here
storage:
- 11.118.0.43
- 11.118.0.44
- 11.118.0.45
- 11.118.0.43 << and here
Passaggio 5. Eseguire lo script deploy.sh precedentemente utilizzato per distribuire lo stack, in modo da aggiungere il nuovo nodo di calcolo allo stack dell'overcloud.
[stack@director ~]$ ./deploy.sh
++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180
…
Starting new HTTP connection (1): 192.200.0.1
"POST /v2/action_executions HTTP/1.1" 201 1695
HTTP POST http://192.200.0.1:8989/v2/action_executions 201
Overcloud Endpoint: http://10.1.2.5:5000/v2.0
Overcloud Deployed
clean_up DeployOvercloud:
END return value: 0
real 38m38.971s
user 0m3.605s
sys 0m0.466s
Passaggio 6. Attendere che lo stato dello stack di apertura sia Completo.
[stack@director ~]$ openstack stack list
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| ID | Stack Name | Stack Status | Creation Time | Updated Time |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
| 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z |
+--------------------------------------+------------+-----------------+----------------------+----------------------+
Passaggio 7. Verificare che il nuovo nodo di calcolo sia nello stato Attivo.
[stack@director ~]$ source stackrc
[stack@director ~]$ nova list |grep compute-18
| 0f2d88cd-d2b9-4f28-b2ca-13e305ad49ea | pod1-compute-18 | ACTIVE | - | Running | ctlplane=192.200.0.117 |
[stack@director ~]$ source corerc
[stack@director ~]$ openstack hypervisor list |grep compute-18
| 63 | pod1-compute-18.localdomain |
Ripristino delle VM
Aggiunta all'elenco aggregato Nova
Aggiungere il nodo di calcolo all'host aggregato e verificare se l'host è stato aggiunto.
nova aggregate-add-host
[stack@director ~]$ nova aggregate-add-host VNF2-SERVICE2 pod1-compute-18.localdomain
nova aggregate-show
[stack@director ~]$ nova aggregate-show VNF2-SERVICE2
Ripristino VM da Elastic Services Controller (ESC)
Passaggio 1. La macchina virtuale è in stato di errore nell'elenco delle macchine virtuali.
[stack@director ~]$ nova list |grep VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
| 49ac5f22-469e-4b84-badc-031083db0533 | VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d | ERROR | - | NOSTATE |
Passaggio 2. Ripristinare la VM dalla ESC.
[admin@VNF2-esc-esc-0 ~]$ sudo /opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli recovery-vm-action DO VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d
[sudo] password for admin:
Recovery VM Action
/opt/cisco/esc/confd/bin/netconf-console --port=830 --host=127.0.0.1 --user=admin --privKeyFile=/root/.ssh/confd_id_dsa --privKeyType=dsa --rpc=/tmp/esc_nc_cli.ZpRCGiieuW
Passaggio 3. Controllare il file yangesc.log.
admin@VNF2-esc-esc-0 ~]$ tail -f /var/log/esc/yangesc.log
…
14:59:50,112 07-Nov-2017 WARN Type: VM_RECOVERY_COMPLETE
14:59:50,112 07-Nov-2017 WARN Status: SUCCESS
14:59:50,112 07-Nov-2017 WARN Status Code: 200
14:59:50,112 07-Nov-2017 WARN Status Msg: Recovery: Successfully recovered VM [VNF2-DEPLOYM_s9_0_8bc6cc60-15d6-4ead-8b6a-10e75d0e134d].
Controllare i servizi PCRF (Cisco Policy and Charging Rules Function) che risiedono sulla VM
Nota: Se la VM è nello stato di arresto, accenderla utilizzando esc_nc_cli da ESC.
Controllare il file diagnostics.sh dalla macchina virtuale di Gestione cluster e verificare se sono stati rilevati errori per le macchine virtuali ripristinate
Passaggio 1. Accedere alla VM corrispondente.
[stack@XX-ospd ~]$ ssh root@
Passaggio 2. Se la macchina virtuale è un SM, un OAM o un arbitro, oltre ad essa, avviare i servizi sessionmgr arrestati in precedenza:
Per ogni file denominato sessionmgr-xxxxx, eseguire il servizio sessionmgr-xxxxx start:
[root@XXXSM03 init.d]# service sessionmgr-27717 start
Se la diagnostica non è ancora chiara, eseguire build_all.sh dalla macchina virtuale di Cluster Manager, quindi eseguire VM-init sulla macchina virtuale corrispondente.
/var/qps/install/current/scripts/build_all.sh
ssh VM e.g. ssh pcrfclient01
/etc/init.d/vm-init
Eliminazione e reinstallazione di una o più VM in caso di mancato ripristino ESC
Se il comando ESC recovery (sopra) non funziona (VM_RECOVERY_FAILED), eliminare e leggere le singole VM.
Ottenere l'ultimo modello ESC per il sito
Dal portale ESC:
Passaggio 1. Posizionare il cursore sul pulsante blu Action (Azione), viene visualizzata una finestra popup, quindi fare clic su Export Template (Esporta modello), come mostrato nell'immagine.

Passaggio 2. Viene visualizzata un'opzione per scaricare il modello sul computer locale. Selezionare Salva file, come mostrato nell'immagine.
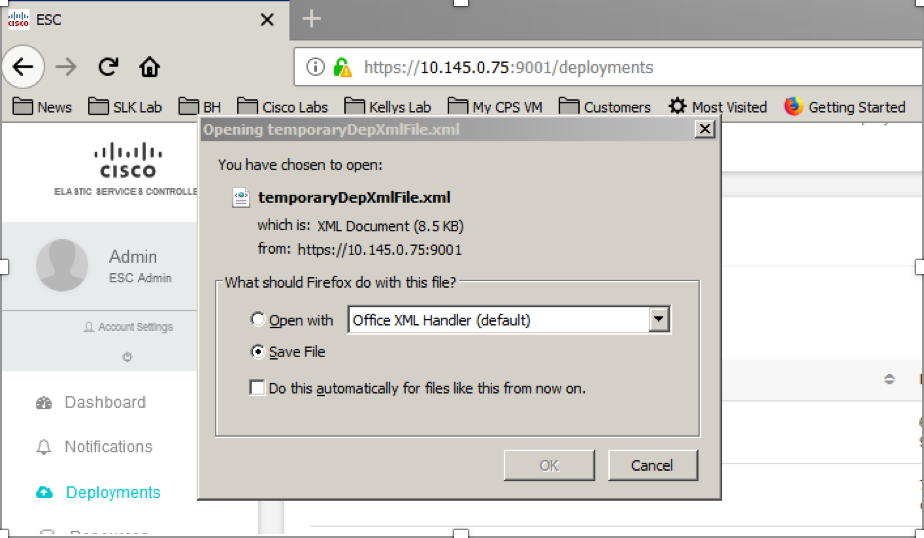
Passaggio 3. Come mostrato nell'immagine, selezionare una posizione e salvare il file per un utilizzo successivo.

Passaggio 4. Accedere alla Protezione avanzata del sito da eliminare e copiare il file precedentemente salvato nella Protezione avanzata del sito in questa directory.
/opt/cisco/esc/cisco-cps/config/gr/tmo/gen
Passaggio 5. Cambiare la directory in /opt/cisco/esc/cisco-cps/config/gr/tmo/gen:
cd /opt/cisco/esc/cisco-cps/config/gr/tmo/gen
Procedura per la modifica del file
Passaggio 1. Modificare il file del modello di esportazione.
In questo passaggio si modifica il file modello di esportazione per eliminare il gruppo o i gruppi di macchine virtuali associati alle macchine virtuali da ripristinare.
Il file modello di esportazione è per un cluster specifico.
All'interno di tale cluster sono presenti più vm_groups. Esistono uno o più vm_groups per ciascun tipo di VM (PD, PS, SM, OM).
Nota: Alcuni vm_groups hanno più di una VM. Tutte le VM all'interno del gruppo verranno eliminate e riaggiunte.
All'interno di tale distribuzione, è necessario contrassegnare uno o più vm_groups per l'eliminazione.
Esempio:
<gruppo_macchine virtuali>
<name>cm</name>
Modificare il <vm_group>in <vm_group nc:operation="delete"> e salvare le modifiche.
Passaggio 2. Eseguire il file del modello di esportazione modificato.
Dal CES eseguire:
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli edit-config /opt/cisco/esc/cisco-cps/config/gr/tmo/gen/
Dal portale ESC dovrebbe essere possibile visualizzare una o più VM che passano allo stato di annullamento della distribuzione per poi scomparire completamente.
I progressi possono essere registrati nel /var/log/esc/yangesc.log
Esempio:
09:09:12,608 29-Jan-2018 INFO ===== UPDATE SERVICE REQUEST RECEIVED(UNDER TENANT) ===== 09:09:12,608 29-Jan-2018 INFO Tenant name: Pcrf 09:09:12,609 29-Jan-2018 INFO Deployment name: WSP1-tmo 09:09:29,794 29-Jan-2018 INFO 09:09:29,794 29-Jan-2018 INFO ===== CONFD TRANSACTION ACCEPTED ===== 09:10:19,459 29-Jan-2018 INFO 09:10:19,459 29-Jan-2018 INFO ===== SEND NOTIFICATION STARTS ===== 09:10:19,459 29-Jan-2018 INFO Type: VM_UNDEPLOYED 09:10:19,459 29-Jan-2018 INFO Status: SUCCESS 09:10:19,459 29-Jan-2018 INFO Status Code: 200 | | | 09:10:22,292 29-Jan-2018 INFO ===== SEND NOTIFICATION STARTS ===== 09:10:22,292 29-Jan-2018 INFO Type: SERVICE_UPDATED 09:10:22,292 29-Jan-2018 INFO Status: SUCCESS 09:10:22,292 29-Jan-2018 INFO Status Code: 200
Passaggio 3. Modificare il file del modello di esportazione per aggiungere le VM.
In questo passaggio si modifica il file modello di esportazione per aggiungere nuovamente il gruppo o i gruppi di macchine virtuali associati alle macchine virtuali da ripristinare.
Il file modello di esportazione è suddiviso nelle due distribuzioni (cluster1 / cluster2).
All'interno di ogni cluster è presente un vm_group. Esistono uno o più vm_groups per ciascun tipo di VM (PD, PS, SM, OM).
Nota: Alcuni vm_groups hanno più di una VM. Tutte le VM all'interno del gruppo verranno riaggiunte.
Esempio:
<vm_group nc:operation="delete">
<name>cm</name>
Sostituire <vm_group nc:operation="delete"> con <vm_group>.
Nota: Se le VM devono essere ricostruite perché l'host è stato sostituito, è possibile che il nome host dell'host sia stato modificato. Se il nome host dell'HOST è stato modificato, il nome host all'interno della sezione placement del gruppo_vm dovrà essere aggiornato.
<posizionamento>
<type>zone_host</type>
<enforcement>rigoroso</enforcement>
<host>wsstackover-compute-4.localdomain</host>
</posizionamento>
Aggiornare il nome dell'host mostrato nella sezione precedente con il nuovo nome host fornito dal team Ultra-M prima dell'esecuzione di questo MOP. Dopo l'installazione del nuovo host, salvare le modifiche.
Passaggio 4. Eseguire il file del modello di esportazione modificato.
Dal CES eseguire:
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli edit-config /opt/cisco/esc/cisco-cps/config/gr/tmo/gen/
Dal portale ESC dovrebbe essere possibile visualizzare nuovamente una o più VM, quindi passare allo stato Attivo.
I progressi possono essere registrati nel /var/log/esc/yangesc.log
Esempio:
09:14:00,906 29-Jan-2018 INFO ===== UPDATE SERVICE REQUESTRECEIVED (UNDER TENANT) ===== 09:14:00,906 29-Jan-2018 INFO Tenant name: Pcrf 09:14:00,906 29-Jan-2018 INFO Deployment name: WSP1-tmo 09:14:01,542 29-Jan-2018 INFO 09:14:01,542 29-Jan-2018 INFO ===== CONFD TRANSACTION ACCEPTED ===== 09:16:33,947 29-Jan-2018 INFO 09:16:33,947 29-Jan-2018 INFO ===== SEND NOTIFICATION STARTS ===== 09:16:33,947 29-Jan-2018 INFO Type: VM_DEPLOYED 09:16:33,947 29-Jan-2018 INFO Status: SUCCESS 09:16:33,947 29-Jan-2018 INFO Status Code: 200 | | | 09:19:00,148 29-Jan-2018 INFO ===== SEND NOTIFICATION STARTS ===== 09:19:00,148 29-Jan-2018 INFO Type: VM_ALIVE 09:19:00,148 29-Jan-2018 INFO Status: SUCCESS 09:19:00,148 29-Jan-2018 INFO Status Code: 200 | | | 09:19:00,275 29-Jan-2018 INFO ===== SEND NOTIFICATION STARTS ===== 09:19:00,275 29-Jan-2018 INFO Type: SERVICE_UPDATED 09:19:00,275 29-Jan-2018 INFO Status: SUCCESS 09:19:00,275 29-Jan-2018 INFO Status Code: 200
Passaggio 5. Verificare i servizi PCRF residenti nella macchina virtuale.
Verificare se i servizi PCRF sono inattivi e avviarli.
[stack@XX-ospd ~]$ ssh root@
[root@XXXSM03 ~]# monit start all
Se la VM è SM, OAM o arbitro, avviare anche i servizi sessionmgr arrestati in precedenza:
Per ogni file denominato sessionmgr-xxxxx eseguire il servizio sessionmgr-xxxxx start:
[root@XXXSM03 init.d]# service sessionmgr-27717 start
Se la diagnostica non è ancora chiara, eseguire build_all.sh dalla macchina virtuale di Cluster Manager, quindi eseguire VM-init sulla macchina virtuale corrispondente.
/var/qps/install/current/scripts/build_all.sh
ssh VM e.g. ssh pcrfclient01
/etc/init.d/vm-init
Passaggio 6. Eseguire Diagnostica per controllare lo stato del sistema.
[root@XXXSM03 init.d]# diagnostics.sh
Informazioni correlate
Contributo dei tecnici Cisco
- Vaibhav BandekarCisco Advanced Services
- Aaditya DeodharCisco Advanced Services
 Feedback
Feedback