Introduzione
In questo documento viene descritto come risolvere i problemi di riduzione del livello degli indicatori di prestazioni chiave (KPI) S11.
Panoramica
S11 è l'interfaccia che connette Mobility Management Entity (MME) e Serving Gateway (SGW) in una rete LTE (Long Term Evolution). L'interfaccia utilizza GTP-C (Gn Tunneling Protocol-Control) o GPRS.
Messaggi nell'interfaccia S11
- Crea richiesta/risposta sessione
- Modifica richiesta/risposta sessione
- Elimina richiesta/risposta sessione
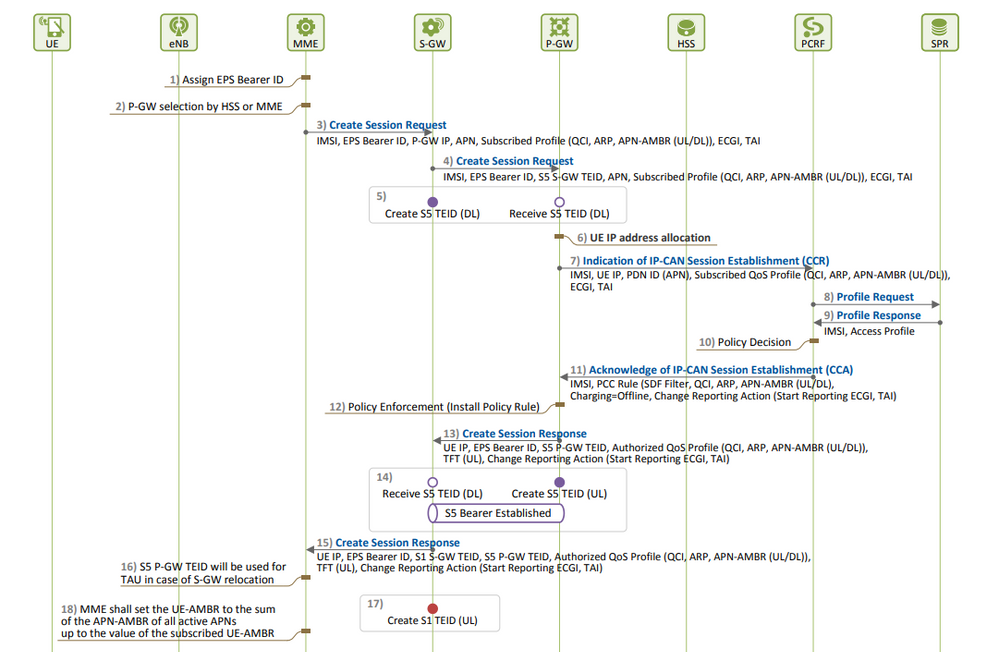
Definizione sessione EPS:
- Il peggioramento dell'indicatore KPI S11 si verifica quando viene visualizzato un numero maggiore di rifiuti della creazione di richieste di sessione (CSR) rispetto ai relativi tentativi CSR, che devono essere la causa principale.
È possibile conoscere la formula utilizzata per misurare l'indicatore KPI, prendere nota di tutti i contatori inclusi nella formula e determinare il contatore esatto responsabile della degradazione.
S11 ASR (SPGW) = ((tun-sent-cresessrespaccept+ggsn_tun-sent-cresessrespdeniedUserAuthFailed+tun-sent-cresessrespdeniedPrefPdnTypeUnsupported+tun-sent-cresessrespdeniedCtxtNotFound)/EGTPC-ggsn_tun-recv-cresess)*100
PDN Connectivity Success Rate (MME) : ((%esmevent-pdncon-success%) + (%esm-msgtx-pdncon-rej%))*) / (%esmevent-pdncon-attempt%) *100)

Nota: la formula può variare in base al modo in cui viene misurata.
Registri richiesti al livello iniziale:
- Tendenza degli indicatori KPI che illustra la degradazione.
- Formula KPI utilizzata.
-
Contatori di bulkstat non elaborati e causare le tendenze del codice dall'inizio del problema.
- Acquisire due istanze di Mostra dettagli supporto (SSD) dal nodo a un intervallo di 30 minuti durante i periodi in cui si sono verificati problemi.
- I syslog variavano da due ore prima che si verificasse la degradazione fino all'ora corrente.
mon sub/pro traces e logging monitor msid <imsi> .
Sequenza di risoluzione dei problemi
-
Valutare l'andamento degli indicatori KPI di ogni contatore coinvolto nella formula degli indicatori KPI S11 analizzando i dati di dettaglio.
-
Confrontare la tendenza degli indicatori KPI durante le sequenze temporali problematiche con sequenze temporali non problematiche.
-
Esaminare come il contatore di bulkstat problematico identificato è definito in base al flusso e stabilire eventuali modelli.
-
Raccogliere i motivi di disconnessione dal nodo tramite più iterazioni a intervalli di 3-5 minuti.
È possibile analizzare il delta dei motivi di disconnessione tra due unità SSD raccolte con timestamp diversi. Il motivo di disconnessione che indica un aumento significativo del valore delta può essere considerato la causa del degrado degli indicatori KPI. Per descrizioni dettagliate di tutti i motivi di disconnessione, fare riferimento alla Guida di riferimento alle statistiche e ai contatori Cisco: https://www.cisco.com/c/en/us/td/docs/wireless/asr_5000/21-23/Stat-Count-Reference/21-23-show-comman...
show session disconnect-reasons verbose
5. Controllare le statistiche egtp in base al tipo di nodo su cui è assunto:
--- SGW end -----
show egtpc statistics interface sgw-ingress path-failure-reasons
show egtpc statistics interface sgw-ingress summary
show egtpc statistics interface sgw-ingress verbose
show egtpc statistics interface sgw-ingress sessmgr-only
show egtpc statistics interface sgw-egress path-failure-reasons
show egtpc statistics interface sgw-egress summary
show egtpc statistics interface sgw-egress verbose
show egtpc statistics interface sgw-egress sessmgr-only
---- PGW end -----
show egtpc statistics interface pgw-ingress path-failure-reasons
show egtpc statistics interface sgw-ingress summary
show egtpc statistics interface sgw-ingress verbose
show egtpc statistics interface sgw-ingress sessmgr-only
--- MME end -----
show egtpc statistics interface mme path-failure-reasons
show egtpc statistics interface mme summary
show egtpc statistics interface mme verbose
show egtpc statistics interface mme sessmgr-only
6. Dopo aver identificato il contatore specifico che causa il problema, è necessario acquisire le tracce delle chiamate mon-sub/mon-pro per analizzare ulteriormente e identificare il flusso di chiamate specifico che causa il degrado dell'indicatore KPI. Inoltre, potete utilizzare strumenti esterni per ottenere tracce di Wireshark per un'analisi più dettagliata.
Di seguito sono riportati i comandi per acquisire le sottotracce Mon:
monitor subscriber with options 19, 26,33, 34, 35, 49,A,S, X, Y, verbosity +5 during the issue.
mon-pro with options 19, 26,33, 34, 35, 49,A,S, X, Y, verbosity +5 during the issue if no mon-sub is present.
More options can be enabled depending on the protocol or call flow we need to capture specifically
Nei casi in cui non è possibile acquisire tracce come mon-sub a causa di una percentuale minima di riduzione dei valori KPI, è necessario acquisire i log di debug a livello di sistema. Questa operazione comporta l'acquisizione dei log di debug per sessmgr ed egptc e, se necessario, l'acquisizione dei flussi specifici del gateway.
logging filter active facility sessmgr level debug
logging filter active facility egtpc level debug
logging filter active facility sgw level debug
logging filter active facility pgw level debug
logging active ----------------- to enable
no logging active ------------- to disable
Note :: Debugging logs can increase CPU utilization so need to keep a watch while executing debugging logs
7. Dopo aver analizzato i log di debug, se si determina la causa del problema, è possibile procedere all'acquisizione del file di base per l'evento specifico in cui si osservano i log degli errori.
logging enable-debug facility sessmgr instance <instance-ID> eventid 11176 line-number 3219 collect-cores 1
For example :: consider we are getting below error log in debug logs which we suspect can be a cause of issue
and we don;t have any call trace
[egtpc 141027 info] [15/0/6045 <sessmgr:93> _handler_func.c:10068] [context: INLAND_PTL_MME01, contextID: 6] [software internal user syslog] [mme-egress] Sending reject response for the message EGTP_MSG_UPDATE_BEARER_REQUEST with cause EGTP_CAUSE_NO_RESOURCES_AVAILABLE to <Host:x.x.x.x, Port:31456, seq_num:82011>
So in this error event
facility :: sessmgr
event ID = 141027
line number = 10068

Avviso: quando si richiede la raccolta di log come debug logs, logging monitor, mon-sub o mon-pro, è importante assicurarsi che questi log vengano raccolti durante un intervento di manutenzione. Inoltre, è fondamentale monitorare il carico della CPU durante questo periodo.
Analisi e identificazione dei sintomi
- Verificare innanzitutto se nel sistema si verificano frequenti arresti anomali da SSD.
show crash list
- Verificare se sono stati rilevati problemi di licenza. In alcuni casi, quando la licenza di SPGW (Serving Packet Data Gateway) è scaduta, non può più accettare nuove chiamate, che non sono riuscite e causano il peggioramento o la riduzione del livello di servizio di S11.
show resource info
- Verificare se sono presenti più istanze di sessmgr in uno stato di avviso o sovrascrittura a causa di un utilizzo elevato della memoria o della CPU. Se vengono rilevate tali istanze, verificare se le nuove chiamate vengono rifiutate a causa di queste condizioni.
- Dai log di debug, è possibile controllare l'interfaccia su cui si verificano gli errori di rifiuto delle chiamate.
Se si verifica un numero significativo di errori di rifiuto della chiamata per un determinato sottoscrittore nel contesto "sgw-egress", seguito dal rifiuto dello stesso sottoscrittore nel contesto "sgw-ingress", si può dedurre che i rifiuti dal Packet Data Gateway (PGW) vengano inviati a SGW-> MME nel contesto S11. Per confermare e risolvere i problemi più lontano dall'estremità PGW, è ora possibile utilizzare un mon-sub per questo IMSI.
2022-Nov-26+00:20:51.763 [egtpc 141018 unusual] [7/0/16871 <sessmgr:579> _handler_func.c:3227] [context: gwctx, contextID: 2] [software internal user syslog] [sgw-egress] For IMSI: 427021600263284, create session request is rejected by the peer with cause EGTP_CAUSE_NO_RESOURCES_AVAILABLE
2022-Nov-26+00:20:51.763 [egtpc 141018 unusual] [7/0/16871 <sessmgr:579> _handler_func.c:2505] [context: gwctx, contextID: 2] [software internal user syslog] [sgw-ingress] For IMSI: 427021600263284, create session request is rejected by the SAP user with cause EGTPC_REASON_UNKNOWN
- A volte possono esistere più motivi di rifiuto per il calo dell'indicatore KPI, pertanto è necessario controllare separatamente ogni motivo e procedere di conseguenza.
Ad esempio, è possibile che no_resource_available/user_auth_failuresi verifichi un aumento di errori per alcune serie IMSI (International Mobile Subscriber Identity), che è riservata agli abbonati in roaming, quindi è necessario controllare questi dati da PGW. remote peer not responding È possibile che si verifichi un timeout in SGW per una richiesta di sessione e la creazione di una richiesta di sessione possa causare una riduzione del valore dell'indicatore KPI S11. Questa sessione potrebbe essere rifiutata come No_resource_available da SGW verso MME. Questi codici di causa di rifiuto possono essere osservati dai registri del protocollo di monitoraggio ed è possibile controllare le caselle Crea richiesta sessione e Crea risposte sessione per identificare gli indirizzi IP specifici da cui vengono inviati i codici di causa di rifiuto.
 Feedback
Feedback