Element Manager dopo la release Ultra 6.3 - Modifiche dell'architettura e risoluzione dei problemi EM
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
Questo documento descrive le modifiche all'architettura di Element Manager (EM) introdotte come parte della release 6.3 UltraM.
Prerequisiti
Requisiti
Cisco raccomanda la conoscenza dei seguenti argomenti:
- STARO
- Architettura di base Ultra-M
Componenti usati
Le informazioni discusse in questo documento fanno riferimento a dispositivi usati in uno specifico ambiente di emulazione. Su tutti i dispositivi menzionati nel documento la configurazione è stata ripristinata ai valori predefiniti. Se la rete è operativa, valutare attentamente eventuali conseguenze derivanti dall'uso dei comandi.
Premesse
Prima della versione Ultra 6.3, per il funzionamento di Ultra Element Manager era necessario creare 3 VM UEM. Il terzo non era in uso ed era lì per aiutare a formare il cluster ZooKeeper. A partire dalla versione 6.3, questo design è stato modificato.
Abbreviazioni
Abbreviazioni utilizzate in questo articolo:
| VNF | Funzione di rete virtuale |
| CF | Funzione di controllo |
| SF | Funzione di servizio |
| ESC | Elastic Service Controller |
| VIM | Virtual Infrastructure Manager |
| VM | Macchina virtuale |
| EM | Gestione elementi |
| UAS | Ultra Automation Services |
| UUID | Identificatore univoco universale |
| ZK | Custode zoo |
Ultra Element Manager dopo Ultra 6.3 Release - Modifiche all'architettura
Questo documento descrive le 5 modifiche introdotte come parte della release 6.3 UltraM:
Il numero di istanze di VM UEM è configurabile alla versione 6.3
Prima della release 6.3, 3 VM UEM erano obbligatorie. Si potrebbe vedere che con nova elenco dopo l'origine del file tenant core:
[root@POD]# openstack server list --all
+--------------------------------------+-----------------------+--------+--------------------------------------------------------------------+---------------+
| ID | Name | Status | Networks | Image Name |
+--------------------------------------+-----------------------+--------+---------------------------------....
| fae2d54a-96c7-4199-a412-155e6c029082 | vpc-LAASmme-em-3 | ACTIVE | orch=192.168.12.53; mgmt=192.168.11.53 | ultra-em |
| c89a3716-9028-4835-9237-759166b5b7fb | vpc-LAASmme-em-2 | ACTIVE | orch=192.168.12.52; mgmt=192.168.11.52 | ultra-em |
| 5f8cda2c-657a-4ba1-850c-805518e4bc18 | vpc-LAASmme-em-1 | ACTIVE | orch=192.168.12.51; mgmt=192.168.11.51 | ultra-em |
Questo snapshot di configurazione (dal file vnf.conf) è stato utilizzato:
vnfc em
health-check enabled
health-check probe-frequency 10
health-check probe-max-miss 6
health-check retry-count 6
health-check recovery-type restart-then-redeploy
health-check boot-time 300
vdu vdu-id em
number-of-instances 1 --> HERE, this value was previously ignored in pre 6.3 releases
connection-point eth0
...
Indipendentemente dal numero di istanze specificato in questo comando, il numero di macchine virtuali ruotate è sempre 3. In altre parole, il valore del numero di istanze è stato ignorato.
A partire dalla versione 6.3, questa viene modificata - il valore configurato può essere 2 o 3.
Quando si configura 2, vengono create le 2 VM UEM.
Quando si configura 3, vengono create le 3 VM UEM.
vnfc em
health-check enabled
health-check probe-frequency 10
health-check probe-max-miss 6
health-check retry-count 3
health-check recovery-type restart
health-check boot-time 300
vdu vdu-id vdu-em
vdu image ultra-em
vdu flavor em-flavor
number-of-instances 2 --> HERE
connection-point eth0
....
Questa configurazione darebbe come risultato 2 VM come mostrato nell'elenco nova.
[root@POD]# openstack server list --all
+--------------------------------------+-----------------------+--------+--------------------------------------------------------------------+---------------+
| ID | Name | Status | Networks | Image Name |
+--------------------------------------+-----------------------+--------+---------------------------------....
| fae2d54a-96c7-4199-a412-155e6c029082 | vpc-LAASmme-em-3 | ACTIVE | orch=192.168.12.53; mgmt=192.168.11.53 | ultra-em |
| c89a3716-9028-4835-9237-759166b5b7fb | vpc-LAASmme-em-2 | ACTIVE | orch=192.168.12.52; mgmt=192.168.11.52 | ultra-em |
Si noti, tuttavia, che il requisito di 3 indirizzi IP rimane lo stesso. Ciò significa che nella parte EM della configurazione (file vnf.conf) l'indirizzo IP 3 è ancora obbligatorio:
vnfc em
health-check enabled
health-check probe-frequency 10
health-check probe-max-miss 6
health-check retry-count 3
health-check recovery-type restart
health-check boot-time 300
vdu vdu-id vdu-em
vdu image ultra-em
vdu flavor em-flavor
number-of-instances 2 ---> NOTE NUMBER OF INSTANCES is 2
connection-point eth0
virtual-link service-vl orch
virtual-link fixed-ip 172.x.y.51 --> IP #1
!
virtual-link fixed-ip 172.x.y.52 --> IP #2
!
virtual-link fixed-ip 172.x.y.53 --> IP #3
!
Questa operazione è necessaria affinché ZK funzioni. Sono necessarie 3 istanze di ZK. Ogni istanza richiede un indirizzo IP. Anche se la terza istanza non viene effettivamente utilizzata, la terza IP viene assegnata alla terza istanza, la cosiddetta Arbiter ZK (vedere Diff.2 per ulteriori informazioni).
Che effetto ha questo sulla rete di orchestrazione?
Nella rete di orchestrazione verranno sempre create 3 porte (per collegare i 3 indirizzi IP menzionati).
[root@POD# neutron port-list | grep -em_
| 02d6f499-b060-469a-b691-ef51ed047d8c | vpc-LAASmme-em_vpc-LA_0_70de6820-9a86-4569-b069-46f89b9e2856 | fa:16:3e:a4:9a:49 | {"subnet_id": "bf5dea3d-cd2f-4503-a32d-5345486d66dc", "ip_address": "192.168.12.52"} |
| 0edcb464-cd7a-44bb-b6d6-07688a6c130d | vpc-LAASmme-em_vpc-LA_0_2694b73a-412b-4103-aac2-4be2c284932c | fa:16:3e:80:eb:2f | {"subnet_id": "bf5dea3d-cd2f-4503-a32d-5345486d66dc", "ip_address": "192.168.12.51"} |
| 9123f1a8-b3ea-4198-9ea3-1f89f45dfe74 | vpc-LAASmme-em_vpc-LA_0_49ada683-a5ce-4166-aeb5-3316fe1427ea | fa:16:3e:5c:17:d6 | {"subnet_id": "bf5dea3d-cd2f-4503-a32d-5345486d66dc", "ip_address": "192.168.12.53"} |
Distribuzione ZooKeeper
Prima della 6.3 ZK era stato utilizzato per formare il cluster, quindi questo requisito è per la terza VM.
Questo requisito non è cambiato. Tuttavia, per le impostazioni in cui vengono utilizzate 2 VM UEM, una terza istanza ZK è ospitata sullo stesso set di VM:
Prima della 6.3 e dopo la 6.3 in una configurazione con 3 VM UEM:
UEM VM1: hosting istanza Zk 1
UEM VM2: hosting istanza Zk 2
UEM VM3: hosting istanza Zk 3
Nella versione 6.3 e successive, dove solo 2 VM:
UEM VM1: hosting istanza Zk 1 e istanza Zk 3
UEM VM2: hosting istanza Zk 2
UEM VM3: non esiste
Vedere la figura 1. in fondo a questo articolo per una rappresentazione grafica dettagliata.
Useful Zk commands:
To see Zk mode (leader/follower):
/opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
To check if Zk is running:
echo stat | nc IP_ADDRESS 2181
How to find the Ip address of Zk instance:
Run 'ip addr' from EM
In the /opt/cisco/em/config/ip.txt there are all the 3IP's
From vnf.conf file
From 'nova list' look for orchestration IP
For 2 EM's the arbiter IP can be found also in /opt/cisco/em/config/proxy-params.txt
How to check status of the Zk instance:
echo stat | nc 192.168.12.51 2181 | grep Mode
Mode: follower
You can run this command from one Zk for all other Zk instances (even they are on different VM)!
To connect to the Zk cli - now must use the IP (rather then localhost earlier):
/opt/cisco/usp/packages/zookeeper/current/bin/zkCli.sh -server:2181 Some useful command you can run once you connect to ZkCli:
You can use same command to connect to other Zk instances (even they are on different VM)!
ls /config/vdus/control-function
ls /config/element-manager
ls /
ls /log
ls /stat
get /config/vdus/session-function/BOOTxx
Introduzione di Mantenuti attivi per HA
Con le release precedenti, il framework per l'elezione dei leader ZK veniva utilizzato per determinare i master EM. Questo non è più il caso, in quanto Cisco è passata al framework keepalive.
Cosa viene mantenuto e come funziona?
Keepalive è un software basato su Linux utilizzato per il bilanciamento del carico e l'elevata disponibilità del sistema Linux e delle infrastrutture basate su Linux.
È già utilizzato in ESC per HA.
In EM, l'opzione Mantenuto viene utilizzata per separare NCS dallo stato del cluster Zk.
Il processo Mantenuto attivo viene eseguito solo sulle prime due istanze di Enterprise Manager e determina lo stato principale del processo NCS.
To check if the keepalived process is running:
ps -aef | grep keepalived
(must return the process ID)
Perché cambiare?
In un'implementazione precedente, la selezione del nodo master (NCS/SCM) era strettamente integrata con lo stato del cluster Zk (la prima istanza a bloccare /em nel database Zk è stata scelta come master). Questo crea problemi quando Zk perde la connettività con il cluster.
Mantenuto attivo viene utilizzato per mantenere il cluster UEM attivo/standby sulla base di VM.
NCS gestisce i dati di configurazione.
Zookeeper conserva i dati operativi.
Separazione di SCM dal processo NCS
Nelle versioni precedenti alla 6.3, il componente SCM era fornito con NCS. Ciò significa che all'avvio dell'NCS anche l'SCM ha avuto inizio (di conseguenza). In questa release, l'operazione è ora disaccoppiata e SCM è un processo separato per se stesso.
Commands to check the NCS and SCM services & processes.
To be executed from the ubuntu command line
ps -aef | grep ncs
ps -aef | grep scm
sudo service show ncs
sudo service scm status
Il servizio EM viene eseguito solo sul nodo principale
Nelle versioni precedenti alla 6.3, i servizi UEM vengono eseguiti sia su Master che su Slave. A partire dalla versione 6.3, i servizi vengono eseguiti solo sul nodo master. Questo influirebbe sull'output visualizzato in show ems. A partire dalla versione 6.3, si prevede di vedere solo un nodo (master) con questo comando, una volta eseguito il login alla CLI UEM:
root@vpc-em-2:/var/log# sudo -i
root@vpc-em-2:~# ncs_cli -u admin -C
admin connected from 127.0.0.1 using console on vpc-LAASmme-em-2
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY VERSION
------------------------------
52 UP UP UP 6.3.0 ===> HERE Only one EM instance is seen. In previous releases you were able to see 2 instances.
Tutti i servizi verrebbero effettivamente eseguiti sul nodo principale, ad eccezione di NCS, e ciò è dovuto ai requisiti NCS.
Questa immagine mostra il riepilogo dei possibili servizi e distribuzione VM per Ultra Element Manager
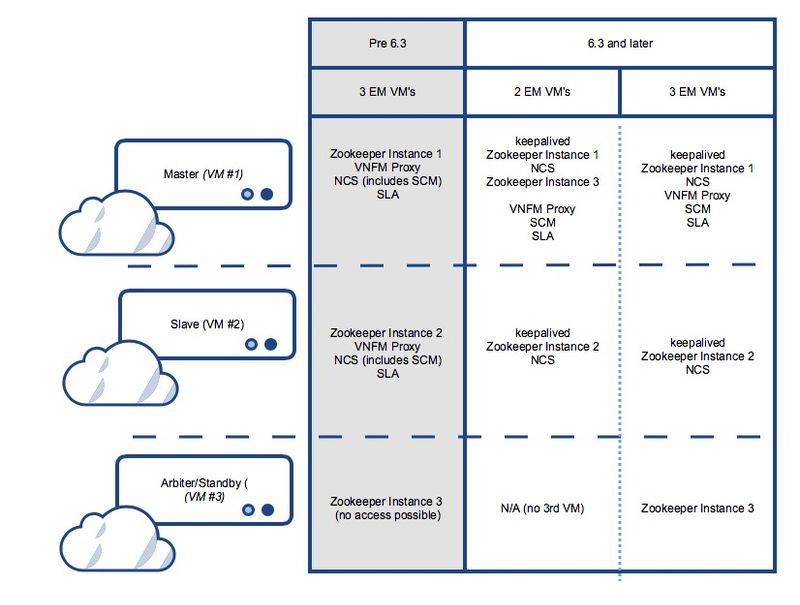
Passi per la risoluzione dei problemi correlati a Element Manager
Durante l'avvio, questa è la sequenza di avvio:
Configurazione UEM con 2 VM - Sequenza di avvio del processo e posizione del log
UEM master:
- conservato
- Zookeeper
- NCS
- Arbitro (3a) istanza di Zookeeper
- VNFM-Proxy
- SCM
- SLA
UEM slave:
- conservato
- Zookeeper
- NCS
Configurazione UEM con 3 VM - Sequenza di avvio del processo e posizione del log
UEM master:
- conservato
- Zookeeper
- NCS
- VNFM-Proxy
- SCM
- SLA
UEM slave:
- conservato
- Zookeeper
- NCS
Terza UEM:
- Zookeeper
Riepilogo dei processi UEM
Riepilogo dei processi UEM da eseguire.
Lo stato viene verificato con ps -aef | grep xx
| conservato |
| arbitro |
| scm |
| sla |
| zoo.cfg |
| ncs |
È possibile controllare lo stato con lo stato del servizio xx, dove xx:
| zookeeper-arbitro |
| proxy |
| scm |
| sla |
| zk |
| ncs |
Contributo dei tecnici Cisco
- Snezana MitrovicCisco TAC Engineer
- Sourav Jyoti DasCisco TAC Engineer
 Feedback
Feedback