Risoluzione dei problemi ACI Fault Code F199144, F93337, F381328, F93241, F450296 : TCA
Opzioni per il download
Linguaggio senza pregiudizi
La documentazione per questo prodotto è stata redatta cercando di utilizzare un linguaggio senza pregiudizi. Ai fini di questa documentazione, per linguaggio senza di pregiudizi si intende un linguaggio che non implica discriminazioni basate su età, disabilità, genere, identità razziale, identità etnica, orientamento sessuale, status socioeconomico e intersezionalità. Le eventuali eccezioni possono dipendere dal linguaggio codificato nelle interfacce utente del software del prodotto, dal linguaggio utilizzato nella documentazione RFP o dal linguaggio utilizzato in prodotti di terze parti a cui si fa riferimento. Scopri di più sul modo in cui Cisco utilizza il linguaggio inclusivo.
Informazioni su questa traduzione
Cisco ha tradotto questo documento utilizzando una combinazione di tecnologie automatiche e umane per offrire ai nostri utenti in tutto il mondo contenuti di supporto nella propria lingua. Si noti che anche la migliore traduzione automatica non sarà mai accurata come quella fornita da un traduttore professionista. Cisco Systems, Inc. non si assume alcuna responsabilità per l’accuratezza di queste traduzioni e consiglia di consultare sempre il documento originale in inglese (disponibile al link fornito).
Sommario
Introduzione
Questo documento descrive le fasi di correzione per i codici di errore ACI: F199144, F93337, F381328, F93241, F450296
Introduzione
Se si dispone di un'infrastruttura ACI connessa a Intersight, è stata generata una richiesta di assistenza per conto dell'utente per indicare che l'istanza di questo errore è stata trovata nell'infrastruttura ACI connessa a Intersight.
Questo processo viene monitorato attivamente nell'ambito degli impegni ACI proattivi.
In questo documento vengono descritte le fasi successive per la risoluzione del seguente errore:
Errore: F199144
"Code" : "F199144",
"Description" : "TCA: External Subnet (v4 and v6) prefix entries usage current value(eqptcapacityPrefixEntries5min:extNormalizedLast) value 91% raised above threshold 90%",
"Dn" : "topology/pod-1/node-132/sys/eqptcapacity/fault-F199144"
Questo errore specifico viene generato quando l'utilizzo corrente del prefisso della subnet esterna supera il 99%. Ciò suggerisce una limitazione hardware in termini di percorsi gestiti da questi switch.
Avvio rapido per risolvere il problema: F199144
1. Comando "show platform internal hal l3 routingthreshold"
module-1# show platform internal hal l3 routingthresholds
Executing Custom Handler function
OBJECT 0:
trie debug threshold : 0
tcam debug threshold : 3072
Supported UC lpm entries : 14848
Supported UC lpm Tcam entries : 5632
Current v4 UC lpm Routes : 19526
Current v6 UC lpm Routes : 0
Current v4 UC lpm Tcam Routes : 404
Current v6 UC lpm Tcam Routes : 115
Current v6 wide UC lpm Tcam Routes : 24
Maximum HW Resources for LPM : 20480 < ------- Maximum hardware resources
Current LPM Usage in Hardware : 20390 < ------------Current usage in Hw
Number of times limit crossed : 5198 < -------------- Number of times that limit was crossed
Last time limit crossed : 2020-07-07 12:34:15.947 < ------ Last occurrence, today at 12:34 pm2. Comando "show platform internal hal health-stats"
module-1# show platform internal hal health-stats
No sandboxes exist
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 249
...
l2_total_host_entries_norm : 4
L3 stats:
=========
l3_v4_local_ep_entries : 40
max_l3_v4_local_ep_entries : 12288
l3_v4_local_ep_entries_norm : 0
l3_v6_local_ep_entries : 0
max_l3_v6_local_ep_entries : 8192
l3_v6_local_ep_entries_norm : 0
l3_v4_total_ep_entries : 221
max_l3_v4_total_ep_entries : 24576
l3_v4_total_ep_entries_norm : 0
l3_v6_total_ep_entries : 0
max_l3_v6_total_ep_entries : 12288
l3_v6_total_ep_entries_norm : 0
max_l3_v4_32_entries : 49152
total_l3_v4_32_entries : 6294
l3_v4_total_ep_entries : 221
l3_v4_host_uc_entries : 6073
l3_v4_host_mc_entries : 0
total_l3_v4_32_entries_norm : 12
max_l3_v6_128_entries : 12288
total_l3_v6_128_entries : 17
l3_v6_total_ep_entries : 0
l3_v6_host_uc_entries : 17
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 0
max_l3_lpm_entries : 20480 < ----------- Maximum
l3_lpm_entries : 19528 < ------------- Current L3 LPM entries
l3_v4_lpm_entries : 19528
l3_v6_lpm_entries : 0
l3_lpm_entries_norm : 99
max_l3_lpm_tcam_entries : 5632
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 864
l3_v4_lpm_tcam_entries : 404
l3_v6_lpm_tcam_entries : 460
l3_v6_wide_lpm_tcam_entries : 24
l3_lpm_tcam_entries_norm : 15
l3_v6_lpm_tcam_entries_norm : 2
l3_host_uc_entries : 6090
l3_v4_host_uc_entries : 6073
l3_v6_host_uc_entries : 17
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 250
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 261
uc_adj_entries_norm : 3
vrfs : 150
infra_vrfs : 0
tenant_vrfs : 148
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 185
Errore Fasi Successive : F199144
1. Ridurre il numero di percorsi che ogni switch deve gestire in modo da garantire la conformità alla scalabilità definita per il modello hardware. Consultare la guida alla scalabilità https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/verified-scalability/Cisco-ACI-Verified-Scalability-Guide-412.html
2. Valutare la possibilità di modificare il profilo della scala di inoltro in base alla scala. https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-overview-and-guidelines.html
3. Rimozione della subnet 0.0.0.0/0 in L3Out e configurazione delle sole subnet richieste
4. Se si utilizza la generazione 1, aggiornare l'hardware dalla generazione 1 alla generazione 2, in quanto gli switch della generazione 2 consentono oltre 20.000 route v4 esterne.
Errore: F93337
"Code" : "F93337",
"Description" : "TCA: memory usage current value(compHostStats15min:memUsageLast) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93337"Questo errore specifico viene generato quando l'host VM utilizza una quantità di memoria superiore alla soglia. L'APIC monitora questi host tramite VCenter. Comp:HostStats15min è una classe che rappresenta le statistiche più recenti per l'host in un intervallo di campionamento di 15 minuti. Questo corso viene aggiornato ogni 5 minuti.
Avvio rapido per risolvere il problema: F93337
1. Comando "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<VM id dal DN dell'errore>'"
Questo comando fornisce informazioni sulla VM interessata
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Comando "moquery -c compRsHv | grep 'vm-1071'"
Questo comando fornisce informazioni sull'host in cui è ospitata la VM. In questo esempio, la VM si trova sull'host 347
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Comando "moquery -c compHv -f 'comp.Hv.oid="host-1068"'"
Questo comando fornisce dettagli sull'host
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Errore nella fase successiva: F93337
1. Modificare la memoria allocata per la macchina virtuale sull'host.
2. Se è prevista la memoria, è possibile eliminare l'errore creando un criterio di raccolta delle statistiche per modificare il valore di soglia.
a. Sotto il tenant della VM, creare un nuovo criterio di monitoraggio.

b. In Criterio di monitoraggio, selezionare Criterio di raccolta statistiche.
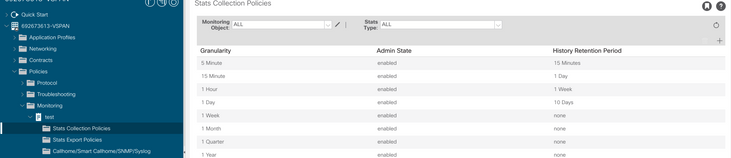
c. Fare clic sull'icona Modifica accanto all'elenco a discesa Oggetto di monitoraggio e controllare la macchina virtuale (comp.Vm) come oggetto di monitoraggio. Dopo l'invio, selezionare l'oggetto compVm dall'elenco a discesa Oggetto di monitoraggio.

d. Fare clic sull'icona Modifica accanto a Tipo di stato, quindi controllare Utilizzo CPU.
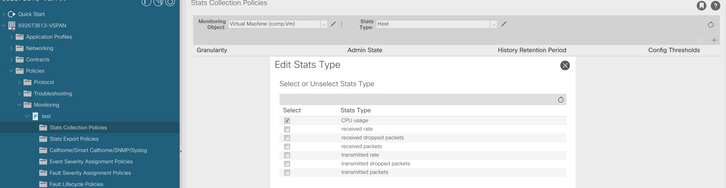
e. Dall'elenco a discesa del tipo di stato, fare clic su select host, fare clic sul segno + e immettere il proprio Granularity, Admin state e History Rentention Period, quindi fare clic su update.

f. Fare clic sul segno + sotto la soglia di configurazione e aggiungere "valore massimo di utilizzo della memoria" come proprietà.
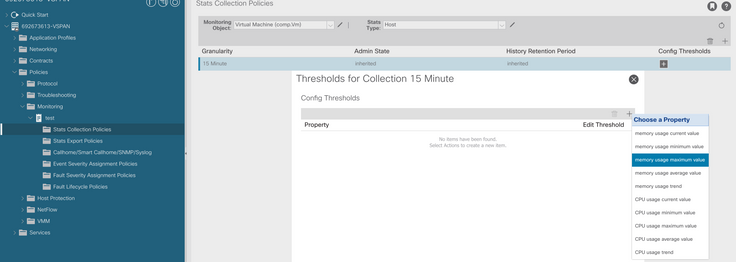
g. Sostituire il valore normale con il valore di soglia desiderato.
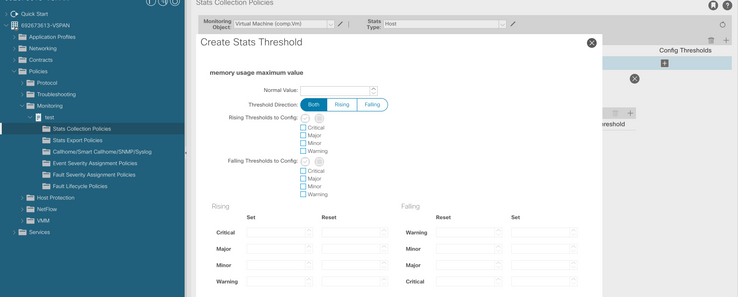
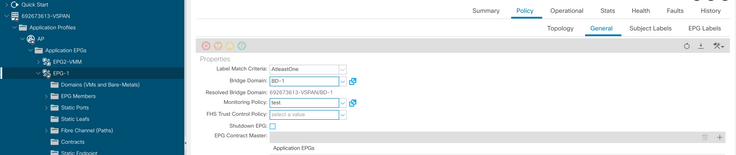
h. Applicare la politica di monitoraggio sull'EPG
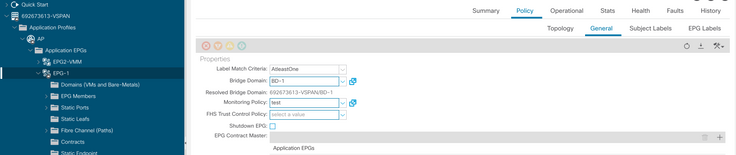
I. Per verificare se il criterio è applicato alla macchina virtuale eseguire "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>"'"
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been applied
Errore: F93241
"Code" : "F93241",
"Description" : "TCA: CPU usage average value(compHostStats15min:cpuUsageAvg) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93241"Questo errore specifico viene generato quando l'host VM utilizza una CPU superiore alla soglia. L'APIC monitora questi host tramite VCenter. Comp:HostStats15min è una classe che rappresenta le statistiche più recenti per l'host in un intervallo di campionamento di 15 minuti. Questo corso viene aggiornato ogni 5 minuti.
Avvio rapido per risolvere il problema: F93241
1. Comando "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<VM id dal DN dell'errore>'"
Questo comando fornisce informazioni sulla VM interessata
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Comando "moquery -c compRsHv | grep 'vm-1071'"
Questo comando fornisce informazioni sull'host in cui è ospitata la VM. In questo esempio, la VM si trova sull'host 347
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Comando "moquery -c compHv -f 'comp.Hv.oid="host-1068"'"
Questo comando fornisce dettagli sull'host
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Errore nella fase successiva: F93241
1. Aggiornare la CPU allocata per la macchina virtuale sull'host.
2. Se è prevista la CPU, è possibile eliminare l'errore creando un criterio di raccolta delle statistiche per modificare il valore di soglia.
a. Sotto il tenant della VM, creare un nuovo criterio di monitoraggio.

b. In Criterio di monitoraggio, selezionare Criterio di raccolta statistiche.
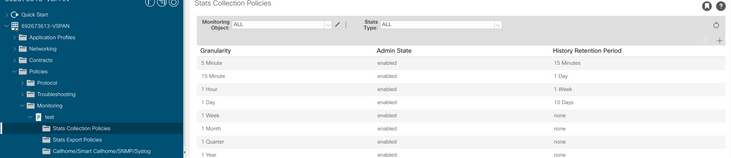
c. Fare clic sull'icona Modifica accanto all'elenco a discesa Oggetto di monitoraggio e controllare la macchina virtuale (comp.Vm) come oggetto di monitoraggio. Dopo l'invio, selezionare l'oggetto compVm dall'elenco a discesa Oggetto di monitoraggio.

d. Fare clic sull'icona Modifica accanto a Tipo di stato, quindi controllare Utilizzo CPU.
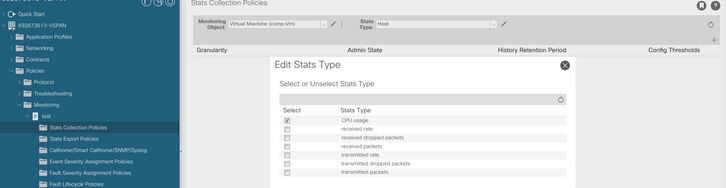
e. Dall'elenco a discesa del tipo di stato, fare clic su select host, fare clic sul segno + e immettere il proprio Granularity, Admin state e History Rentention Period, quindi fare clic su update.

f. Fare clic sul segno + sotto la soglia di configurazione e aggiungere "valore massimo di utilizzo CPU" come proprietà.
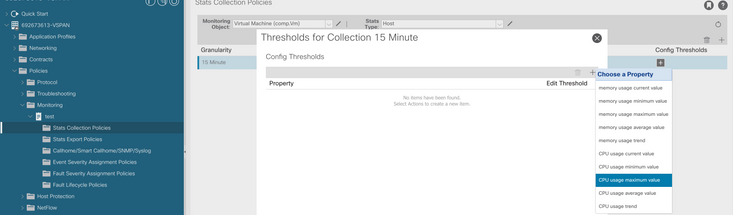
g. Sostituire il valore normale con il valore di soglia desiderato.
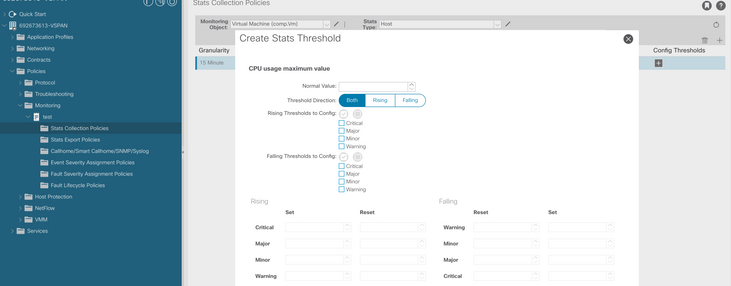
h. Applicare la politica di monitoraggio sull'EPG
I. Per verificare se il criterio è applicato alla macchina virtuale eseguire "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>"'"
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been appliedErrore: F381328
"Code" : "F381328",
"Description" : "TCA: CRC Align Errors current value(eqptIngrErrPkts5min:crcLast) value 50% raised above threshold 25%",
"Dn" : "topology/<pod>/<node>/sys/phys-<[interface]>/fault-F381328"Questo errore specifico viene generato quando gli errori CRC su un'interfaccia superano la soglia. Sono disponibili due tipi comuni di errori CRC: gli errori FCS e gli errori CRC Stomped. Gli errori CRC vengono propagati a causa di un percorso a commutazione di tipo cut-through e sono il risultato di errori FCS iniziali. Poiché ACI segue lo switching cut-through questi frame finiscono per attraversare il fabric ACI e vediamo errori CRC stomp lungo il percorso, questo non significa che tutte le interfacce con errori CRC sono difetti. Si consiglia di identificare l'origine del CRC e risolvere il problema relativo a SFP/porta/fibra.
Avvio rapido per risolvere l'errore: F381328
1. Scaricare il numero più alto di interfacce con CRC nella struttura
moquery -c rmonEtherStats -f 'rmon.EtherStats.cRCAlignErrors>="1"' | egrep "dn|cRCAlignErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/([[:digit:]]+)\s/\n\1 /g' | awk '{printf "%-65s %-15s\n", $2,$1}' | sort -rnk 2
topology/pod-1/node-103/sys/phys-[eth1/50]/dbgEtherStats 399158
topology/pod-1/node-101/sys/phys-[eth1/51]/dbgEtherStats 399158
topology/pod-1/node-1001/sys/phys-[eth2/24]/dbgEtherStats 3991582. Scaricare il numero più alto di FCS nell'infrastruttura
moquery -c rmonDot3Stats -f 'rmon.Dot3Stats.fCSErrors>="1"' | egrep "dn|fCSErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/topology/\ntopology/g' | awk '{printf "%-65s %-15s\n", $1,$2}' | sort -rnk 2Errore nella fase successiva: F381328
1. Gli eventuali errori FCS nell'infrastruttura vengono corretti. Questi errori in genere indicano problemi di livello 1.
2. Se sulla porta del pannello anteriore sono presenti errori di stomp CRC, controllare il dispositivo collegato sulla porta e individuare il motivo per cui lo stomps proviene da tale dispositivo.
Script Python per errore : F381328
L'intero processo può anche essere automatizzato utilizzando lo script Python. Fare riferimento a https://www.cisco.com/c/en/us/support/docs/cloud-systems-management/application-policy-infrastructure-controller-apic/217577-how-to-use-fcs-and-crc-troubleshooting-s.html
Errore : F450296
"Code" : "F450296",
"Description" : "TCA: Multicast usage current value(eqptcapacityMcastEntry5min:perLast) value 91% raised above threshold 90%",
"Dn" : "sys/eqptcapacity/fault-F450296"Questo errore specifico viene generato quando il numero di voci multicast supera la soglia.
Avvio rapido per risolvere il problema: F450296
1. Comando "show platform internal hal health-stats asic-unit all"
module-1# show platform internal hal health-stats asic-unit all
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 1979
max_bds: : 3500
external_bds: : 0
vsan_bds: : 0
legacy_bds: : 0
regular_bds: : 0
control_bds: : 0
fds : 1976
max_fds : 3500
fd_vlans : 0
fd_vxlans : 0
vlans : 3955
max vlans : 3960
vlan_xlates : 6739
max vlan_xlates : 32768
ports : 52
pcs : 47
hifs : 0
nif_pcs : 0
l2_local_host_entries : 1979
max_l2_local_host_entries : 32768
l2_local_host_entries_norm : 6
l2_total_host_entries : 1979
max_l2_total_host_entries : 65536
l2_total_host_entries_norm : 3
L3 stats:
=========
l3_v4_local_ep_entries : 3953
max_l3_v4_local_ep_entries : 32768
l3_v4_local_ep_entries_norm : 12
l3_v6_local_ep_entries : 1976
max_l3_v6_local_ep_entries : 24576
l3_v6_local_ep_entries_norm : 8
l3_v4_total_ep_entries : 3953
max_l3_v4_total_ep_entries : 65536
l3_v4_total_ep_entries_norm : 6
l3_v6_total_ep_entries : 1976
max_l3_v6_total_ep_entries : 49152
l3_v6_total_ep_entries_norm : 4
max_l3_v4_32_entries : 98304
total_l3_v4_32_entries : 35590
l3_v4_total_ep_entries : 3953
l3_v4_host_uc_entries : 37
l3_v4_host_mc_entries : 31600
total_l3_v4_32_entries_norm : 36
max_l3_v6_128_entries : 49152
total_l3_v6_128_entries : 3952
l3_v6_total_ep_entries : 1976
l3_v6_host_uc_entries : 1976
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 8
max_l3_lpm_entries : 38912
l3_lpm_entries : 9384
l3_v4_lpm_entries : 3940
l3_v6_lpm_entries : 5444
l3_lpm_entries_norm : 31
max_l3_lpm_tcam_entries : 4096
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 2689
l3_v4_lpm_tcam_entries : 2557
l3_v6_lpm_tcam_entries : 132
l3_v6_wide_lpm_tcam_entries : 0
l3_lpm_tcam_entries_norm : 65
l3_v6_lpm_tcam_entries_norm : 0
l3_host_uc_entries : 2013
l3_v4_host_uc_entries : 37
l3_v6_host_uc_entries : 1976
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 1
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 1033
uc_adj_entries_norm : 12
vrfs : 1806
infra_vrfs : 0
tenant_vrfs : 1804
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 1978
Mcast stats:
============
mcast_count : 31616 <<<<<<<
max_mcast_count : 32768
Policy stats:
=============
policy_count : 127116
max_policy_count : 131072
policy_otcam_count : 2920
max_policy_otcam_count : 8192
policy_label_count : 0
max_policy_label_count : 0
Dci Stats:
=============
vlan_xlate_entries : 0
vlan_xlate_entries_tcam : 0
max_vlan_xlate_entries : 0
sclass_xlate_entries : 0
sclass_xlate_entries_tcam : 0
max_sclass_xlate_entries : 0Errore nella fase successiva: F450296
1. Valuta la possibilità di spostare parte del traffico multicast in altri fogli.
2. Esplora vari profili di scala di inoltro per aumentare la scala multicast. Fai riferimento al collegamento https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-forwarding-scale-profiles-523.html
Cronologia delle revisioni
| Revisione | Data di pubblicazione | Commenti |
|---|---|---|
1.0 |
11-Jul-2023 |
Versione iniziale |
Contributo dei tecnici Cisco
- Savinder SinghTAC
 Feedback
Feedback