Cause comuni della connettività lenta tra VLAN e tra VLAN nelle reti di switch del campus
Sommario
Introduzione
Questo documento affronta i problemi più comuni che possono contribuire alla lentezza della rete. Il documento classifica i sintomi comuni di lentezza della rete e delinea gli approcci per la diagnosi e la risoluzione dei problemi.
Prerequisiti
Requisiti
Nessun requisito specifico previsto per questo documento.
Componenti usati
Il documento può essere consultato per tutte le versioni software o hardware.
Convenzioni
Per ulteriori informazioni sulle convenzioni usate, consultare il documento Cisco sulle convenzioni nei suggerimenti tecnici.
Cause comuni della connettività lenta tra VLAN e tra VLAN
I sintomi di una connettività lenta su una VLAN possono essere causati da più fattori su diversi livelli della rete. In genere, il problema di velocità della rete può verificarsi a un livello inferiore, ma i sintomi possono essere osservati a un livello superiore, in quanto il problema si maschera con il termine "VLAN lenta". Per maggiore chiarezza, il presente documento definisce i seguenti nuovi termini: "slow collision domain", "slow broadcast domain" (in altre parole, slow VLAN) e "slow interVLAN forwarding". Tali cause sono definite nella sezione Tre categorie di cause riportata di seguito.
Nello scenario seguente (illustrato nel diagramma di rete seguente), è presente uno switch di layer 3 (L3) che esegue il routing tra VLAN tra le VLAN server e client. In questo scenario di errore, un server è collegato a uno switch e la modalità duplex della porta è configurata in modalità half-duplex sul lato server e in modalità full-duplex sul lato switch. Questa configurazione errata comporta una perdita e un rallentamento dei pacchetti, con conseguente aumento della perdita dei pacchetti in caso di velocità di traffico più elevate sul collegamento a cui è connesso il server. Per i client che comunicano con il server, il problema sembra essere l'inoltro tra VLAN lento perché non si verificano problemi di comunicazione con altri dispositivi o client sulla stessa VLAN. Il problema si verifica solo quando si comunica con il server su una VLAN diversa. Di conseguenza, il problema si è verificato su un singolo dominio di collisione, ma viene considerato come un lento inoltro tra VLAN.
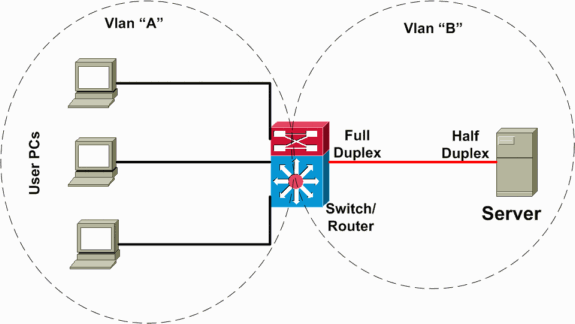
Tre categorie di cause
Le cause della lentezza possono essere suddivise in tre categorie, come segue:
Connettività dominio a collisione lenta
Il dominio di collisione è definito come dispositivo connesso configurato in una configurazione di porta half-duplex, connesso l'uno all'altro o a un hub. Se un dispositivo è collegato a una porta dello switch e è configurata la modalità full-duplex, una connessione point-to-point di questo tipo non ha collisioni. La lentezza su un segmento di questo tipo può ancora verificarsi per diversi motivi.
Connettività con dominio di trasmissione lento (VLAN lenta)
La connettività al dominio di broadcast è lenta quando l'intera VLAN (ossia, tutti i dispositivi sulla stessa VLAN) mostra una lentezza.
Connettività tra VLAN lenta (inoltro lento tra VLAN)
La connettività tra VLAN lenta (inoltro lento tra VLAN) si verifica quando non c'è lentezza sulla VLAN locale, ma il traffico deve essere inoltrato a una VLAN alternativa e non viene inoltrato alla velocità prevista.
Cause del rallentamento della rete
Perdita di pacchetti
Nella maggior parte dei casi, una rete viene considerata lenta quando i protocolli (applicazioni) di livello superiore richiedono un tempo maggiore per completare un'operazione che in genere viene eseguita più rapidamente. Questa lentezza è causata dalla perdita di alcuni pacchetti sulla rete, che causa il timeout di protocolli di livello superiore come TCP o applicazioni e avvia la ritrasmissione.
Problemi di inoltro hardware
Con un altro tipo di lentezza, causata dalle apparecchiature di rete, l'inoltro (sia sul layer 2 [L2] che L3) viene eseguito lentamente. Ciò è dovuto a una deviazione dal normale funzionamento (progettato) e al passaggio all'inoltro del percorso lento. Ad esempio, quando lo switch MLS (Multilayer Switching) sullo switch inoltra i pacchetti L3 tra le VLAN nell'hardware, ma a causa di una configurazione errata, il protocollo MLS non funziona correttamente e l'inoltro viene eseguito dal router nel software (la velocità di inoltro tra VLAN viene ridotta in modo significativo).
Risoluzione dei problemi
Risoluzione dei problemi relativi ai domini di collisione
Se la VLAN è lenta, occorre prima isolare i problemi del dominio di collisione. È necessario stabilire se solo gli utenti dello stesso dominio di collisione hanno problemi di connettività o se questa situazione si verifica su più domini. A tale scopo, eseguire un trasferimento di dati tra PC utente sullo stesso dominio di collisione e confrontare queste prestazioni con quelle di un altro dominio di collisione o con le prestazioni previste.
Se i problemi si verificano solo su quel dominio di collisione e le prestazioni di altri domini di collisione nella stessa VLAN sono normali, esaminare i contatori delle porte sullo switch per determinare i problemi che potrebbe verificare questo segmento. Molto probabilmente la causa è semplice, ad esempio una mancata corrispondenza del duplex. Un'altra causa, meno frequente, è il sovraccarico o la sovrascrittura di un segmento. Per ulteriori informazioni sulla risoluzione dei problemi relativi a un singolo segmento, consultare il documento sulla configurazione e la risoluzione dei problemi di negoziazione automatica Ethernet 10/100/1000Mb half/full duplex.
Se gli utenti su domini di collisione diversi (ma nella stessa VLAN) hanno gli stessi problemi di prestazioni, potrebbe essere ancora possibile che il duplex non corrisponda su uno o più segmenti Ethernet tra l'origine e la destinazione. Si verifica spesso lo scenario seguente: uno switch è configurato manualmente in modo da avere la modalità full-duplex su tutte le porte della VLAN (l'impostazione predefinita è "auto"), mentre gli utenti (schede di interfaccia di rete [NIC]) connessi alle porte stanno eseguendo una procedura di negoziazione automatica. Il risultato è una mancata corrispondenza del duplex su tutte le porte e, di conseguenza, prestazioni non valide su ciascuna porta (dominio di collisione). Quindi, anche se sembra che l'intera VLAN (dominio di broadcast) abbia un problema di prestazioni, viene ancora classificata come mancata corrispondenza duplex, per il dominio di collisione di ciascuna porta.
Un altro caso da considerare è un particolare problema di prestazioni della scheda NIC. Se una scheda NIC con un problema di prestazioni è collegata a un segmento condiviso, è possibile che l'intero segmento stia registrando un rallentamento, soprattutto se la scheda NIC appartiene a un server che serve anche altri segmenti o VLAN. Ricordare questo caso perché potrebbe fuorviarvi durante la risoluzione dei problemi. Anche in questo caso, il modo migliore per risolvere il problema è eseguire un trasferimento di dati tra due host sullo stesso segmento (dove è connessa la scheda NIC con il problema presunto), oppure se solo la scheda NIC si trova su quella porta, l'isolamento non è facile, quindi provare a utilizzare una scheda NIC diversa su questo host o provare a connettere l'host sospetto su una porta separata, assicurando la corretta configurazione della porta e della scheda NIC.
Se il problema persiste, provare a risolvere il problema relativo alla porta dello switch. Fare riferimento al documento sulla risoluzione dei problemi relativi alle porte e alle interfacce dello switch.
Il caso più grave si verifica quando alcune o tutte le NIC incompatibili sono collegate a uno switch Cisco. In questo caso, sembra che lo switch abbia problemi di prestazioni. Per verificare la compatibilità delle schede NIC con gli switch Cisco, consultare il documento sulla risoluzione dei problemi di compatibilità NIC degli switch Cisco Catalyst.
È necessario distinguere tra i primi due casi (risoluzione dei problemi di lentezza dei domini di collisione e di VLAN) perché queste due cause coinvolgono domini diversi. Con la lentezza del dominio di collisione, il problema si trova all'esterno dello switch (o sul bordo dello switch, su una porta dello switch) o all'esterno dello switch. È possibile che il solo segmento abbia dei problemi (ad esempio, un segmento sovrascritto, che supera la lunghezza del segmento, problemi fisici sul segmento o problemi di hub/ripetitori). In caso di lentezza della VLAN, il problema più probabile è che si trovi all'interno dello switch (o di più switch). Se si diagnostica il problema in modo errato, è possibile che si perda tempo cercando il problema nel posto sbagliato.
Quindi, dopo aver diagnosticato un caso, controllare le voci elencate di seguito.
Nel caso di un segmento condiviso:
-
determinare se il segmento è sovraccarico o sovrascritto
-
determinare se il segmento è sano (anche se la lunghezza del cavo è corretta, se l'attenuazione rientra nella norma e se il mezzo presenta danni fisici)
-
determinare se la porta di rete e tutte le schede NIC collegate a un segmento dispongono di impostazioni compatibili
-
determinare se la scheda NIC sta funzionando correttamente (ed eseguire il driver più recente)
-
determinare se la porta di rete continua a mostrare errori in aumento
-
determinare se la porta di rete è sovraccarica (in particolare se si tratta di una porta server)
Nel caso di un segmento condiviso point-to-point o di un segmento senza collisioni (full-duplex):
-
determinare la configurazione della porta e della scheda NIC compatibile
-
determinare lo stato del segmento
-
determinare lo stato della scheda NIC
-
cerca errori delle porte di rete o sovrassegnazione
Risoluzione dei problemi relativi a IntraVLAN lente (dominio di broadcast)
Dopo aver verificato che non vi siano problemi di mancata corrispondenza duplex o di dominio di collisione, come spiegato nella sezione precedente, è possibile risolvere i problemi di lentezza della IntraVLAN. Per isolare la posizione della lentezza, il passaggio successivo è eseguire un trasferimento di dati tra gli host sulla stessa VLAN (ma su porte diverse; su domini di collisione diversi) e confrontare le prestazioni con gli stessi test nelle VLAN alternative.
Le seguenti condizioni possono rallentare le VLAN:
1Queste tre cause di connettività intraVLAN lenta esulano dall'ambito di questo documento e possono richiedere la risoluzione dei problemi da parte di un tecnico dell'assistenza Cisco. Dopo aver escluso le prime cinque possibili cause elencate sopra, potrebbe essere necessario aprire una richiesta di servizio con il supporto tecnico Cisco.
Traffic Loop
Un loop di traffico è la causa più comune di una VLAN lenta. Insieme a un ciclo, si dovrebbero vedere altri sintomi che indicano che si sta sperimentando un ciclo. Per la risoluzione dei problemi relativi ai loop dello Spanning Tree Protocol (STP), consultare il documento Spanning Tree Protocol Problems and Related Design Considerations (Problemi del protocollo Spanning Tree e considerazioni correlate sulla progettazione). Sebbene switch potenti (come Cisco Catalyst 6500/6000) con backplane Gigabit compatibili possano gestire alcuni loop (STP) senza compromettere le prestazioni della CPU di gestione, i pacchetti con loop possono causare l'overflow dei buffer di input sulle schede NIC e i buffer di ricezione/trasmissione (Rx/Tx) sugli switch, causando prestazioni lente durante la connessione ad altri dispositivi.
Un altro esempio di loop è EtherChannel con configurazione asimmetrica, come mostrato nello scenario seguente:
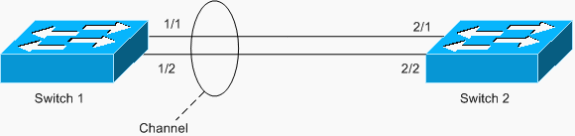
nell'esempio, le porte 1/1 e 1/2 sono nel canale, a differenza delle porte 2/1 e 2/2.
Lo switch 1 ha un canale configurato (canale forzato) e lo switch 2 non ha una configurazione del canale per le porte corrispondenti. Se il traffico esteso (mcast/bcast/unicast sconosciuto) scorre dallo switch 1 allo switch 2, lo switch 2 lo ricollega nuovamente al canale. Non si tratta di un loop completo, in quanto il traffico non viene ripetuto in modo continuo, ma viene riflesso solo una volta. È la metà del ciclo totale. La presenza di due configurazioni errate può creare un loop completo, come illustrato nell'esempio seguente.
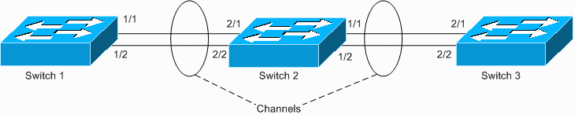
Il rischio di una configurazione errata è che gli indirizzi MAC vengono appresi su porte errate, in quanto il traffico viene commutato in modo errato, causando la perdita dei pacchetti. Si consideri, ad esempio, un router con il protocollo HSRP (Hot Standby Router Protocol) attivo collegato allo switch 1 (come mostrato nel diagramma precedente). Dopo che il router ha trasmesso i pacchetti, il relativo MAC viene rimandato indietro dallo switch 2 e appreso dal canale dallo switch 1, fino a quando un pacchetto unicast non viene inviato di nuovo dal router.
VLAN sovraccarica o con sottoscrizione eccessiva
Notare se sulle VLAN vi sono colli di bottiglia (segmenti con sovrascrittura) e individuarli. Il primo segnale di sovraccarico della VLAN è se i buffer Rx o Tx su una porta hanno una sottoscrizione eccessiva. Se su alcune porte vengono rilevati scarti o scarti non consentiti, verificare se le porte sono sovraccariche. (Un aumento di indiscard non indica solo un buffer Rx completo.) Nel sistema operativo Catalyst (CatOS), è possibile usare i comandi show mac mod/porta o show top [N]. Nel software Cisco IOS® (nativo), è possibile usare il comando show interfaces slot#/port# counters errors per verificare gli errori. Lo scenario VLAN con sovraccarico o sovrascrittura e lo scenario del loop di traffico spesso si accompagnano, ma possono anche esistere separatamente.
Molto spesso, il sovraccarico si verifica sulle porte della backbone quando la larghezza di banda aggregata del traffico è sottostimata. Il modo migliore per risolvere questo problema è configurare EtherChannel tra i dispositivi su cui le porte sono bloccate. Se il segmento di rete è già un canale, aggiungere altre porte in un gruppo di canali per aumentare la capacità del canale.
Prestare attenzione anche al problema di polarizzazione Cisco Express Forwarding (CEF). Questo problema si verifica sulle reti in cui il traffico viene bilanciato dal carico dai router, ma a causa dell'uniformità dell'algoritmo di Cisco Express Forwarding, tutto il traffico viene polarizzato e, sull'hop successivo, non viene bilanciato dal carico. Questo problema tuttavia non si verifica spesso, in quanto richiede una determinata topologia con collegamenti L3 con carico bilanciato. Per ulteriori informazioni sull'inoltro e il bilanciamento del carico Cisco Express, vedere Risoluzione dei problemi di routing IP unicast con CEF sugli switch Catalyst serie 6500/6000 con Supervisor Engine 2 e software CatOS.
Un'altra causa del sovraccarico della VLAN è un problema di routing asimmetrico. Questo tipo di configurazione può anche causare un sovraccarico del traffico sulle VLAN. Per ulteriori informazioni, consultare il documento sulla Causa 1: Sezione Asymmetric Routing del documento Unicast Flooding in Switched Campus Networks.
A volte un collo di bottiglia può essere un dispositivo di rete stesso. Se, ad esempio, si tenta di pompare il traffico di 4 gigabit attraverso lo switch con un backplane di 3 gigabit, si ottiene una notevole perdita di traffico. La comprensione dell'architettura dello switch di rete non rientra nell'ambito del presente documento; tuttavia, quando si considera la capacità di uno switch di rete, prestare attenzione ai seguenti aspetti:
-
capacità backplane
-
problemi di blocco head-of-line
-
architettura switch/porte bloccante e non bloccante
Congestione su percorso in banda switch
La congestione sul percorso in banda dello switch può causare un loop nello spanning tree o altri tipi di instabilità sulla rete. La porta in banda su qualsiasi switch Cisco è una porta virtuale che fornisce l'interfaccia per il traffico di gestione (ad esempio, il protocollo Cisco Discovery e il protocollo PAgP [Port Aggregation Protocol]) al processore di gestione. La porta in banda è considerata virtuale perché, in alcune architetture, non è visibile all'utente e le funzioni in banda vengono combinate con il normale funzionamento della porta. Ad esempio, l'interfaccia SC0 sugli switch Catalyst serie 4000, Catalyst 5000 e Catalyst serie 6500/6000 (con CatOS) è un sottoinsieme della porta in banda. L'interfaccia SC0 fornisce solo uno stack IP per il processore di gestione all'interno della VLAN configurata, mentre la porta in banda fornisce l'accesso al processore di gestione per le BDPU (Bridge Protocol Data Unit) in una delle VLAN configurate e per molti altri protocolli di gestione (ad esempio Cisco Discovery Protocol, Internet Group Management Protocol [IGMP], Cisco Group Management Protocol e Dynamic Trunking Protocol [DTP]).
Se la porta in banda viene sovraccaricata (a causa di un traffico utente o di un'applicazione non configurata correttamente), potrebbe causare l'instabilità di qualsiasi protocollo per il quale la stabilità dello stato del protocollo si basa sui messaggi regolari o sui messaggi "hellos" ricevuti. Questo stato può causare loop temporanei, interfacce sfarfalliate e altri problemi, causando questo tipo di lentezza.
È difficile causare congestione della porta in banda sullo switch, anche se attacchi Denial of Service (DoS) formati in modo dannoso potrebbero avere esito positivo. Non è possibile limitare la velocità o ridurre il traffico sulla porta in banda. Una soluzione richiede l'intervento dell'amministratore dello switch e l'analisi del problema. Le porte in banda in genere presentano una tolleranza elevata alla congestione. Raramente la porta in banda non funziona correttamente o rimane bloccata nella direzione Rx o Tx. Ciò comporterebbe gravi interruzioni dell'hardware e influirebbe sull'intero switch. Questa condizione è difficile da riconoscere e viene generalmente diagnosticata dai tecnici del supporto tecnico Cisco. I sintomi sono che uno switch diventa improvvisamente "sordo" e smette di visualizzare il traffico di controllo, ad esempio gli aggiornamenti dei router adiacenti del Cisco Discovery Protocol. Ciò indica un problema Rx in banda. Se tuttavia viene visualizzato un solo router adiacente al protocollo di rilevamento Cisco, il protocollo in banda è attivo. Analogamente, se tutti gli switch collegati perdono il protocollo Cisco Discovery Protocol da un singolo switch (e da tutti gli altri protocolli di gestione), vengono segnalati problemi di trasmissione dall'interfaccia in banda dello switch.
Utilizzo elevato della CPU del processore di gestione dello switch
Se un percorso in banda è sovraccarico, lo switch può sperimentare condizioni CPU elevate; e, mentre la CPU elabora tutto quel traffico non necessario, la situazione peggiora. Se un utilizzo elevato della CPU è causato da un percorso in banda sovraccarico o da un problema alternativo, può influire sui protocolli di gestione come descritto nella sezione Congestione sul percorso in banda dello switch, sopra.
In generale, considerare la CPU di gestione come un punto vulnerabile di uno switch. Uno switch configurato correttamente riduce il rischio di problemi causati da un elevato utilizzo della CPU.
L'architettura del Supervisor Engine I e II degli switch Catalyst serie 4000 è progettata in modo che la CPU di gestione sia coinvolta nel sovraccarico di switching. Tenete presente quanto segue:
-
La CPU programma una struttura dello switch ogni volta che un nuovo percorso (basato sul percorso del Supervisor Engine I e II) entra nello switch. Se una porta in banda è sovraccarica, tutti i nuovi percorsi vengono eliminati. Ciò comporta la perdita dei pacchetti (eliminazione invisibile all'utente) e la lentezza dei protocolli di livello superiore quando il traffico viene commutato tra le porte. Fare riferimento alla sezione Congestione su percorso in banda switch, sopra.
-
Poiché la CPU esegue parzialmente la commutazione nel Supervisor Engine I e II, condizioni elevate della CPU possono influire sulle funzionalità di commutazione di Catalyst 4000. L'elevato utilizzo della CPU sul Supervisor Engine I e II può essere causato dal sovraccarico di commutazione stesso.
i Supervisor Engine II+, III e IV della serie Catalyst 4500/4000 sono abbastanza tolleranti al traffico, ma l'apprendimento dell'indirizzo MAC nel Supervisor Engine basato sul software Cisco IOS viene ancora eseguito completamente nel software (dalla CPU di gestione); è possibile che un utilizzo elevato della CPU possa influire sul processo e causare lentezza. Come con Supervisor Engine I e II, l'apprendimento o il riapprendimento massiccio degli indirizzi MAC può causare un elevato utilizzo della CPU sui Supervisor Engine II+, III e IV.
La CPU è coinvolta nell'apprendimento degli indirizzi MAC anche negli switch Catalyst serie 3500XL e 2900XL, quindi un processo che produce un riapprendimento rapido degli indirizzi influisce sulle prestazioni della CPU.
Inoltre, il processo di apprendimento dell'indirizzo MAC (anche se è completamente implementato nell'hardware) è relativamente lento rispetto a un processo di commutazione. Se la frequenza di riapprendimento degli indirizzi MAC è costantemente elevata, la causa deve essere individuata ed eliminata. Un loop nello spanning tree sulla rete può causare il riapprendimento di questo tipo di indirizzo MAC. Il relearning degli indirizzi MAC (o il flapping degli indirizzi MAC) può essere causato anche da switch di terze parti che implementano VLAN basate sulle porte, ossia gli indirizzi MAC non vengono associati a un tag VLAN. Questo tipo di switch, quando collegato a switch Cisco in alcune configurazioni, può causare perdite di dati MAC tra le VLAN. A sua volta, ciò può portare a una frequenza elevata di riapprendimento degli indirizzi MAC e può ridurre le prestazioni.
Errori in entrata su uno switch cut-through
La propagazione dei pacchetti di errore in entrata cut-through è correlata alla connettività del dominio a collisione lenta, ma poiché i pacchetti di errore vengono trasferiti a un altro segmento, il problema sembra dipendere dal passaggio da un segmento all'altro. Gli switch cut-through (ad esempio i CSR Catalyst serie 8500 e il modulo di switching Catalyst 2948G-L3 o L3 per la serie Catalyst 4000) iniziano la commutazione di pacchetto/frame non appena lo switch ha informazioni sufficienti dalla lettura dell'intestazione L2/L3 del pacchetto per inoltrare il pacchetto alla porta o alle porte di destinazione. Quindi, mentre il pacchetto viene scambiato tra le porte in entrata e in uscita, l'inizio del pacchetto viene già inoltrato fuori dalla porta in uscita, mentre il resto del pacchetto viene ancora ricevuto dalla porta in entrata. Cosa succede se il segmento in entrata non è integro e genera un errore CRC (Cyclic Redundancy Check) o un runt? Lo switch riconosce questa condizione solo quando riceve la fine del frame e, a quel punto, la maggior parte del frame viene trasferito fuori dalla porta di uscita. Poiché non ha senso trasferire il resto del fotogramma errato, il resto viene scartato, la porta in uscita incrementa l'errore di sottocarico e la porta in entrata incrementa il contatore di errori corrispondente. Se più porte in entrata non sono integre e il relativo server risiede sulla porta di uscita, il problema è presente anche nel segmento del server.
Per gli switch L3 cut-through, verificare la presenza di eventuali errori e, quando vengono visualizzati, controllare la presenza di errori in tutte le porte in entrata.
Configurazione errata di software o hardware
Una configurazione errata può causare un rallentamento della VLAN. Questi effetti negativi possono essere dovuti a una VLAN con sovrascrittura o sovraccarico, ma nella maggior parte dei casi sono dovuti a un design errato o a configurazioni ignorate. Ad esempio, un segmento (VLAN) può essere facilmente sopraffatto dal traffico multicast (ad esempio, un flusso video o audio) se le tecniche di limitazione del traffico multicast non sono configurate correttamente su tale VLAN. Tale traffico multicast può influire sul trasferimento dei dati, causando la perdita dei pacchetti su un'intera VLAN per tutti gli utenti (e inondando i segmenti di utenti che non intendevano ricevere i flussi multicast).
Bug software e problemi hardware
I bug software e i problemi hardware sono difficili da identificare perché causano deviazioni, che sono difficili da risolvere. Se si ritiene che il problema sia causato da un bug software o da un problema hardware, contattare i tecnici del supporto tecnico Cisco per richiedere loro di esaminare il problema.
Risoluzione dei problemi di connettività tra VLAN lenta
Prima di risolvere i problemi relativi alla lentezza della connettività tra VLAN (tra VLAN), esaminare e risolvere i problemi descritti nelle sezioni Risoluzione dei problemi di collisione dei domini e Risoluzione dei problemi di lentezza delle IntraVLAN (dominio di broadcast) di questo documento.
Nella maggior parte dei casi, la connettività tra VLAN è lenta a causa di una configurazione errata dell'utente. Ad esempio, se si è configurato in modo errato MLS o Multicast Multilayer Switching (MLS), l'inoltro dei pacchetti viene eseguito dalla CPU del router, che ha un percorso lento. Per evitare errori di configurazione e risolvere i problemi in modo efficiente quando necessario, è necessario comprendere il meccanismo utilizzato dal dispositivo di inoltro L3. Nella maggior parte dei casi, il meccanismo di inoltro L3 si basa su una compilazione di tabelle ARP (Routing and Address Resolution Protocol) e sulla programmazione di informazioni estratte per l'inoltro dei pacchetti nell'hardware (collegamenti). Qualsiasi errore nel processo di programmazione dei collegamenti porta all'inoltro di pacchetti software (percorso lento), all'inoltro errato (inoltro a una porta errata) o al blocco del traffico.
Di solito un errore di programmazione dei collegamenti o la creazione di collegamenti incompleti (che possono anche portare all'inoltro di pacchetti software, all'inoltro errato o al blocco del traffico) è il risultato di un bug del software. Se si sospetta che ciò sia vero, chiedere ai tecnici del supporto tecnico Cisco di indagare. Altri motivi della lentezza nell'inoltro tra VLAN sono i malfunzionamenti hardware, che non rientrano tuttavia nell'ambito di questo documento. I malfunzionamenti hardware impediscono semplicemente la creazione di collegamenti nell'hardware e, pertanto, il traffico può seguire un percorso lento (software) o essere bucato. I malfunzionamenti hardware devono essere gestiti anche dai tecnici del supporto tecnico Cisco.
Se si è certi che l'apparecchiatura sia configurata correttamente, ma che la commutazione hardware non sia in corso, è possibile che si sia verificato un bug del software o un malfunzionamento dell'hardware. Prima di formulare questa conclusione, tuttavia, è necessario conoscere le funzionalità del dispositivo.
Di seguito sono riportate le due situazioni più frequenti in cui l'inoltro hardware potrebbe cessare o non avere luogo:
-
La memoria in cui sono memorizzati i collegamenti è esaurita. Una volta che la memoria è piena, il software in genere cessa di creare ulteriori collegamenti. Ad esempio, MLS, basato su NetFlow o Cisco Express Forwarding, diventa inattivo quando non c'è spazio per nuovi collegamenti e passa al software [slow path].
-
L'apparecchiatura non è progettata per eseguire la commutazione hardware, ma non è ovvia. Ad esempio, Catalyst serie 4000 Supervisor Engine III e versioni successive sono progettati per inoltrare solo il traffico IP; tutti gli altri tipi di traffico sono software elaborati dalla CPU. Un altro esempio è la configurazione di un elenco di controllo di accesso (ACL) che richiede l'intervento della CPU (ad esempio, con l'opzione "log"). Il traffico che si applica a questa regola viene elaborato dalla CPU nel software.
Gli errori di ingresso su uno switch cut-through possono inoltre contribuire alla lentezza del routing tra VLAN. Gli switch cut-through utilizzano gli stessi principi architetturali per inoltrare il traffico L3 e L2, quindi i metodi di risoluzione dei problemi descritti nella sezione Risoluzione dei problemi di una IntraVLAN (dominio di broadcast) lenta, sopra, possono essere applicati anche al traffico L2.
Un altro tipo di configurazione errata che influisce sul routing tra VLAN è la configurazione errata sui dispositivi dell'utente finale (ad esempio, il PC e le stampanti). Una situazione comune è un PC configurato in modo errato; ad esempio, un gateway predefinito non è configurato correttamente, la tabella ARP PC non è valida o il client IGMP non funziona correttamente. Un caso comune è quello di più router o dispositivi con funzionalità di routing e di alcuni o tutti i PC degli utenti finali non configurati correttamente per l'utilizzo del gateway predefinito errato. Questo potrebbe essere il caso più problematico, poiché tutti i dispositivi di rete sono configurati e funzionano correttamente, tuttavia, i dispositivi dell'utente finale non li utilizzano a causa di questa configurazione errata.
Se un dispositivo nella rete è un router normale che non ha alcun tipo di accelerazione hardware (e non partecipa al protocollo MLS NetFlow), la velocità di inoltro del traffico dipende completamente dalla velocità della CPU e dalla sua quantità di spazio occupato. Un utilizzo elevato della CPU influisce in modo decisivo sulla velocità di inoltro. Sugli switch L3, tuttavia, condizioni elevate della CPU non influiscono necessariamente sulla velocità di inoltro; un utilizzo elevato della CPU influisce sulla capacità della CPU di creare (programmare) un collegamento hardware. Se il collegamento è già installato nell'hardware, anche se la CPU è molto utilizzata, il traffico (per il collegamento programmato) viene invertito nell'hardware fino a quando il collegamento non è obsoleto (se è presente un timer di scadenza) o rimosso dalla CPU. Tuttavia, se un router è configurato per un qualsiasi tipo di accelerazione software (come la commutazione veloce o la commutazione Cisco Express Forwarding), l'inoltro dei pacchetti potrebbe essere influenzato dai collegamenti software; se un collegamento viene interrotto o il meccanismo stesso non funziona, invece di accelerare la velocità di inoltro, il traffico viene indirizzato alla CPU, rallentando la velocità di inoltro dei dati.
Informazioni correlate
- Risoluzione dei problemi di switching IP multilivello
- Risoluzione dei problemi di routing IP unicast con CEF sugli switch Catalyst serie 6500/6000 con Supervisor Engine 2 e software di sistema CatOS
- Configurazione del routing tra VLAN sugli switch Catalyst serie 3550
- Switch - Supporto dei prodotti
- Supporto della tecnologia di switching LAN
- Documentazione e supporto tecnico – Cisco Systems
 Feedback
Feedback