Dépannage de la couche de données commune (CDL)
Options de téléchargement
-
ePub (313.8 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (289.1 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Table des matières
1. Introduction
Cet article traite des bases du dépannage de la couche de données commune (CDL) dans un environnement SMF. Documentation que vous pouvez trouver sur ce lien.
2. Vue d'ensemble
La couche CDL (Common Data Layer) de Cisco est une couche de stockage de données KV (Key-value) nouvelle génération hautes performances pour toutes les applications cloud natives.
CDL est actuellement utilisé comme composant de gestion d'état avec des fonctions HA (haute disponibilité) et Geo HA.
La CDL offre :
- Une couche de stockage de données commune sur différentes fonctions réseau (NF).
- Lecture et écriture à faible latence (dans le stockage de session mémoire)
- Notifier les NF de bloquer l'abonné lorsqu'une attaque DoS (Denial of Service) sur la même session est signalée.
- Haute disponibilité - Redondance locale avec au moins 2 réplicas.
- Redondance géographique avec 2 sites.
- Aucun concept primaire/secondaire n'inclut tous les emplacements disponibles pour les opérations d'écriture. Améliore le temps de basculement car aucune sélection principale n'a lieu.
3. Composants
- Point d'extrémité : (cdl-ep-session-c1-d0-7c79c87d65-xpm5v)
- Le terminal CDL est un POD Kubernetes (K8s). Il est déployé pour exposer l'interface gRPC sur HTTP2 vers le client NF qui traite les demandes de service de base de données et agit comme point d'entrée pour les applications en direction nord.
- Emplacement : (cdl-slot-session-c1-m1-0)
- Le terminal CDL prend en charge plusieurs microservices Slot. Ces microservices sont des POD K8 déployés pour exposer l'interface gRPC interne vers Cisco Data Store
- Chaque Slot POD contient un nombre fini de sessions. Ces sessions représentent les données de session réelles au format tableau d'octets
- Index : (cdl-index-session-c1-m1-0)
- Le microservice Index contient les données relatives à l'indexation
- Ces données d'indexation sont ensuite utilisées pour récupérer les données de session réelles à partir des microservices de logement
- ETCD : (etcd-smf-etcd-cluster-0)
- CDL utilise l'ETCD (un magasin de valeurs de clés open source) comme découverte de service de base de données. Lorsque l'EP Cisco Data Store est démarré, arrêté ou arrêté, il entraîne l'ajout d'un événement par l'état de publication. Par conséquent, des notifications sont envoyées à chacun des POD abonnés à ces événements. De plus, lorsqu'un événement clé est ajouté ou supprimé, il actualise la carte locale.
- Kafka : (kafka-0)
- Le POD Kafka réplique les données entre les réplicas locaux et entre les sites pour l'indexation. Pour la réplication sur plusieurs sites, Kafak utilise MirrorMaker.
- Mirror Maker : (mirror-maker-0)
- Le POD Mirror Maker réplique les données d'indexation sur les sites CDL distants. Il prend les données des sites distants et les publie sur le site Kafka local pour que les instances d'indexation appropriées puissent les récupérer.
Exemple :
master-1:~$ kubectl get pods -n smf-smf -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES cdl-ep-session-c1-d0-7889db4d87-5mln5 1/1 Running 0 80d 192.168.16.247 smf-data-worker-5 <none> <none> cdl-ep-session-c1-d0-7889db4d87-8q7hg 1/1 Running 0 80d 192.168.18.108 smf-data-worker-1 <none> <none> cdl-ep-session-c1-d0-7889db4d87-fj2nf 1/1 Running 0 80d 192.168.24.206 smf-data-worker-3 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z6c2z 1/1 Running 0 34d 192.168.4.164 smf-data-worker-2 <none> <none> cdl-ep-session-c1-d0-7889db4d87-z7c89 1/1 Running 0 80d 192.168.7.161 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-0 1/1 Running 0 80d 192.168.7.172 smf-data-worker-4 <none> <none> cdl-index-session-c1-m1-1 1/1 Running 0 80d 192.168.24.241 smf-data-worker-3 <none> <none> cdl-index-session-c1-m2-0 1/1 Running 0 49d 192.168.18.116 smf-data-worker-1 <none> <none> cdl-index-session-c1-m2-1 1/1 Running 0 80d 192.168.7.173 smf-data-worker-4 <none> <none> cdl-index-session-c1-m3-0 1/1 Running 0 80d 192.168.24.197 smf-data-worker-3 <none> <none> cdl-index-session-c1-m3-1 1/1 Running 0 80d 192.168.18.107 smf-data-worker-1 <none> <none> cdl-index-session-c1-m4-0 1/1 Running 0 80d 192.168.7.158 smf-data-worker-4 <none> <none> cdl-index-session-c1-m4-1 1/1 Running 0 49d 192.168.16.251 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m1-0 1/1 Running 0 80d 192.168.18.117 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m1-1 1/1 Running 0 80d 192.168.24.201 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m2-0 1/1 Running 0 80d 192.168.16.245 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m2-1 1/1 Running 0 80d 192.168.18.123 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m3-0 1/1 Running 0 34d 192.168.4.156 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m3-1 1/1 Running 0 80d 192.168.18.78 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m4-0 1/1 Running 0 34d 192.168.4.170 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m4-1 1/1 Running 0 80d 192.168.7.177 smf-data-worker-4 <none> <none> cdl-slot-session-c1-m5-0 1/1 Running 0 80d 192.168.24.246 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m5-1 1/1 Running 0 34d 192.168.4.163 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m6-0 1/1 Running 0 80d 192.168.18.119 smf-data-worker-1 <none> <none> cdl-slot-session-c1-m6-1 1/1 Running 0 80d 192.168.16.228 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-0 1/1 Running 0 80d 192.168.16.215 smf-data-worker-5 <none> <none> cdl-slot-session-c1-m7-1 1/1 Running 0 49d 192.168.4.167 smf-data-worker-2 <none> <none> cdl-slot-session-c1-m8-0 1/1 Running 0 49d 192.168.24.213 smf-data-worker-3 <none> <none> cdl-slot-session-c1-m8-1 1/1 Running 0 80d 192.168.16.253 smf-data-worker-5 <none> <none> etcd-smf-smf-etcd-cluster-0 2/2 Running 0 80d 192.168.11.176 smf-data-master-1 <none> <none> etcd-smf-smf-etcd-cluster-1 2/2 Running 0 48d 192.168.7.59 smf-data-master-2 <none> <none> etcd-smf-smf-etcd-cluster-2 2/2 Running 1 34d 192.168.11.66 smf-data-master-3 <none> <none> georeplication-pod-0 1/1 Running 0 80d 10.10.1.22 smf-data-master-1 <none> <none> georeplication-pod-1 1/1 Running 0 48d 10.10.1.23 smf-data-master-2 <none> <none> grafana-dashboard-cdl-smf-smf-77bd69cff7-qbvmv 1/1 Running 0 34d 192.168.7.41 smf-data-master-2 <none> <none> kafka-0 2/2 Running 0 80d 192.168.24.245 smf-data-worker-3 <none> <none> kafka-1 2/2 Running 0 49d 192.168.16.200 smf-data-worker-5 <none> <none> mirror-maker-0 1/1 Running 1 80d 192.168.18.74 smf-data-worker-1 <none> <none> zookeeper-0 1/1 Running 0 34d 192.168.11.73 smf-data-master-3 <none> <none> zookeeper-1 1/1 Running 0 48d 192.168.7.47 smf-data-master-2 <none> <none> zookeeper-2
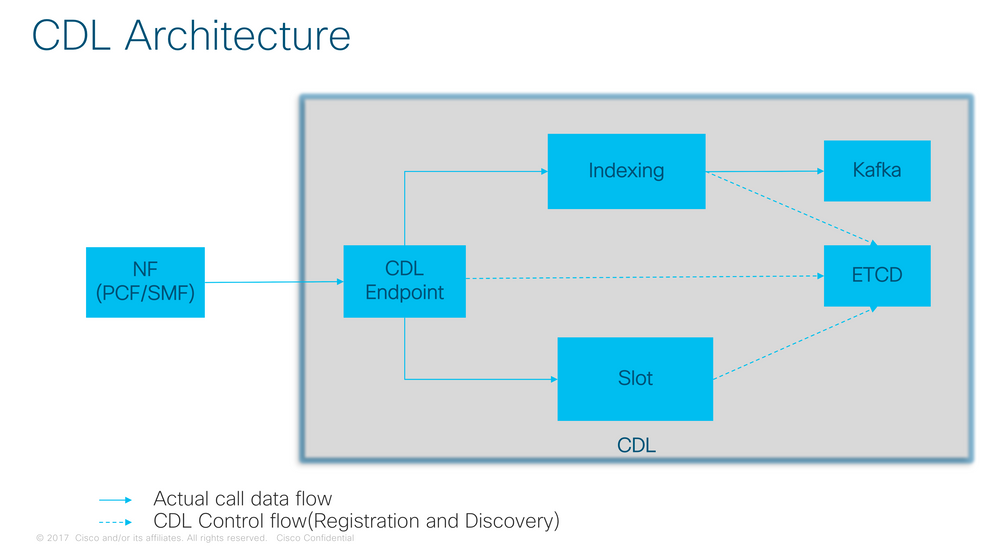 Architecture CDL
Architecture CDL
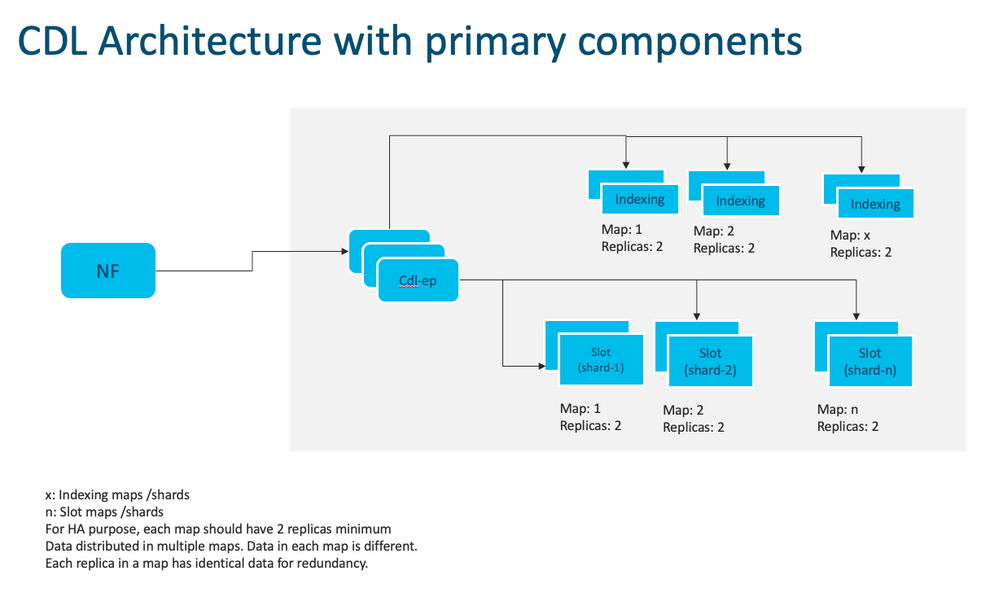
Remarque : aucun concept primaire/secondaire n'est disponible pour toutes les opérations d'écriture. Améliore le temps de basculement car aucune sélection principale n'a lieu.
Remarque : par défaut, CDL est déployé avec 2 réplicas pour db-ep, 1 mappage de logement (2 réplicas par mappage) et 1 mappage d'index (2 réplicas par mappage).
4. Procédure pas à pas de configuration
smf# show running-config cdl cdl system-id 1 /// unique across the site, system-id 1 is the primary site ID for sliceNames SMF1 SMF2 in HA GR CDL deploy cdl node-type db-data /// node label to configure the node affinity cdl enable-geo-replication true /// CDL GR Deployment with 2 RACKS cdl remote-site 2 db-endpoint host x.x.x.x /// Remote site cdl-ep configuration on site-1 db-endpoint port 8882 kafka-server x.x.x.x 10061 /// Remote site kafka configuration on site-1 exit kafka-server x.x.x.x 10061 exit exit cdl label-config session /// Configures the list of label for CDL pods endpoint key smi.cisco.com/node-type-3 endpoint value session slot map 1 key smi.cisco.com/node-type-3 value session exit slot map 2 key smi.cisco.com/node-type-3 value session exit slot map 3 key smi.cisco.com/node-type-3 value session exit slot map 4 key smi.cisco.com/node-type-3 value session exit slot map 5 key smi.cisco.com/node-type-3 value session exit slot map 6 key smi.cisco.com/node-type-3 value session exit slot map 7 key smi.cisco.com/node-type-3 value session exit slot map 8 key smi.cisco.com/node-type-3 value session exit index map 1 key smi.cisco.com/node-type-3 value session exit index map 2 key smi.cisco.com/node-type-3 value session exit index map 3 key smi.cisco.com/node-type-3 value session exit index map 4 key smi.cisco.com/node-type-3 value session exit exit cdl datastore session /// unique with in the site label-config session geo-remote-site [ 2 ] slice-names [ SMF1 SMF2 ] endpoint cpu-request 2000 endpoint go-max-procs 16 endpoint replica 5 /// number of cdl-ep pods endpoint external-ip x.x.x.x endpoint external-port 8882 index cpu-request 2000 index go-max-procs 8 index replica 2 /// number of replicas per mop for cdl-index, can not be changed after CDL deployement.
NOTE: If you need to change number of index replica, set the system mode to shutdown from respective ops-center CLI, change the replica and set the system mode to running index map 4 /// number of mops for cdl-index index write-factor 1 /// number of copies to be written before a successful response slot cpu-request 2000 slot go-max-procs 8 slot replica 2 /// number of replicas per mop for cdl-slot slot map 8 /// number of mops for cdl-slot slot write-factor 1 slot metrics report-idle-session-type true features instance-aware-notification enable true /// This enables GR failover notification features instance-aware-notification system-id 1 slice-names [ SMF1 ] exit features instance-aware-notification system-id 2 slice-names [ SMF2 ] exit exit cdl kafka replica 2 cdl kafka label-config key smi.cisco.com/node-type-3 cdl kafka label-config value session cdl kafka external-ip x.x.x.x 10061 exit cdl kafka external-ip x.x.x.x 10061 exit
5. Dépannage
5.1 Pannes de pod
Le fonctionnement de CDL est simple Clé > Valeur db.
- Toutes les requêtes parviennent aux pods cdl-endpoint.
- Dans les pods cdl-index, nous stockons les clés, round robin.
- Dans cdl-slot, nous stockons la valeur (informations de session), round robin.
- Nous définissons la sauvegarde (nombre de réplicas) pour chaque pod map (type).
- La nacelle Kafka est utilisée comme bus de transport.
- miroir maker est utilisé comme bus de transport vers différents racks (redondance géographique).
L'échec de chaque peut être traduit par, c'est-à-dire si tous les pods de ce type/mappage sont tombés en panne en même temps :
- cdl-endpoint : erreurs de communication avec CDL
- cdl-index - perte des clés pour les données de session
- cdl-slot - perte de données de session
- Kafka - perte de l'option de synchronisation entre les cartes de type pod
- miroirs : perte de synchronisation avec d'autres noeuds geo redudand
Nous pouvons toujours collecter des journaux à partir des pods appropriés, car les journaux de pod cdl ne se propagent pas aussi rapidement, il y a donc une valeur supplémentaire pour les collecter.
Rappelez-vous que tac-debug collecte l'instantané à temps pendant que les journaux impriment toutes les données depuis qu'il est stocké.
Description des modules
kubectl describe pod cdl-ep-session-c1-d0-7889db4d87-5mln5 -n smf-rcdn
Collecter les journaux pod
kubectl logs cdl-ep-session-c1-d0-7c79c87d65-xpm5v -n smf-rcdn
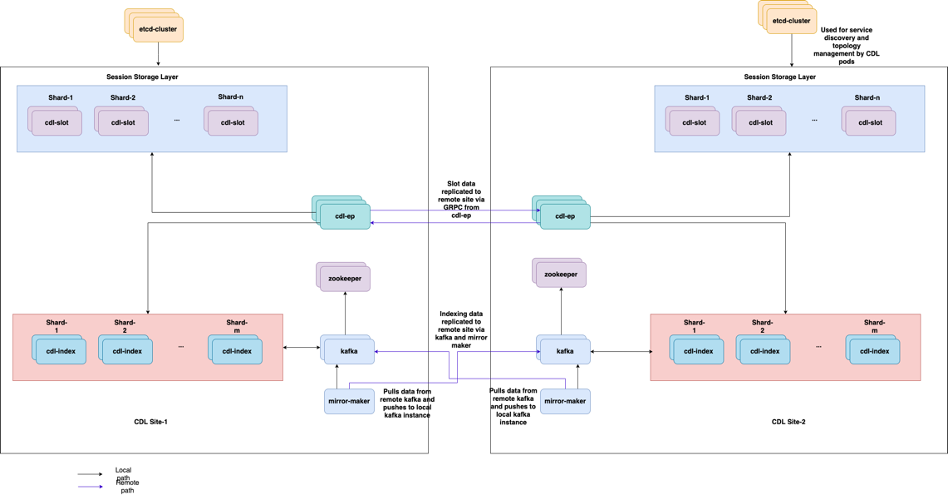
5.2 CDL Comment obtenir des informations de session à partir des clés de session
Dans la CDL, chaque session comporte un champ appelé clés uniques qui identifie cette session.
Si nous comparons l'impression de session de show subscriber supi et cdl show sessions summary nom_tranche tranche1 nom_base filtre de session
- adresse de session ipv4 associée à supi = "1#/#imsi-123969789012404:10.0.0.3"
- ddn + adresse ip4 = "1#/#lab:10.0.0.3"
- adresse de session ipv6 associée à supi = "1#/#imsi-123969789012404:2001:db0:0:2::"
- ddn + adresse ipv6 de la session = "1#/#lab:2001:db0:0:2::"
- smfTeid also N4 Session Key = "1#/#293601283" (Clé de session N4 = "1#/") Cette option est très utile lors du dépannage d'erreurs sur UPF. Vous pouvez effectuer une recherche dans les journaux de session et trouver des informations relatives à la session.
- supi + ebi = "1#/#imsi-123969789012404 : ebi-5"
- supi + ddn= "1#/#imsi-123969789012404:lab"
[smf/data] smf# cdl show sessions summary slice-name slice1 db-name session filter { condition match key 1#/#293601283 }
Sun Mar 19 20:17:41.914 UTC+00:00
message params: {session-summary cli session {0 100 1#/#293601283 0 [{0 1#/#293601283}] [] 0 0 false 4096 [] [] 0} slice1}
session {
primary-key 1#/#imsi-123969789012404:1
unique-keys [ "1#/#imsi-123969789012404:10.0.0.3" "1#/#lab:10.0.0.3" "1#/#imsi-123969789012404:2001:db0:0:2::" "1#/#lab:2001:db0:0:2::" "1#/#293601283" "1#/#imsi-123969789012404:ebi-5" "1#/#imsi-123969789012404:lab" ]
non-unique-keys [ "1#/#roaming-status:visitor-lbo" "1#/#ue-type:nr-capable" "1#/#supi:imsi-123969789012404" "1#/#gpsi:msisdn-22331010101010" "1#/#pei:imei-123456789012381" "1#/#psid:1" "1#/#snssai:001000003" "1#/#dnn:lab" "1#/#emergency:false" "1#/#rat:nr" "1#/#access:3gpp" access "1#/#connectivity:5g" "1#/#udm-uecm:10.10.10.215" "1#/#udm-sdm:10.10.10.215" "1#/#auth-status:unauthenticated" "1#/#pcfGroupId:PCF-dnn=lab;" "1#/#policy:2" "1#/#pcf:10.10.10.216" "1#/#upf:10.10.10.150" "1#/#upfEpKey:10.10.10.150:10.10.10.202" "1#/#ipv4-addr:pool1/10.0.0.3" "1#/#ipv4-pool:pool1" "1#/#ipv4-range:pool1/10.0.0.1" "1#/#ipv4-startrange:pool1/10.0.0.1" "1#/#ipv6-pfx:pool1/2001:db0:0:2::" "1#/#ipv6-pool:pool1" "1#/#ipv6-range:pool1/2001:db0::" "1#/#ipv6-startrange:pool1/2001:db0::" "1#/#id-index:1:0:32768" "1#/#id-value:2/3" "1#/#chfGroupId:CHF-dnn=lab;" "1#/#chf:10.10.10.218" "1#/#amf:10.10.10.217" "1#/#peerGtpuEpKey:10.10.10.150:20.0.0.1" "1#/#namespace:smf" ]
flags [ flag3:peerGtpuEpKey:10.10.10.150:20.0.0.1 session-state-flag:smf_active ]
map-id 2
instance-id 1
app-instance-id 1
version 1
create-time 2023-03-19 20:14:14.381940117 +0000 UTC
last-updated-time 2023-03-19 20:14:14.943366502 +0000 UTC
purge-on-eval false
next-eval-time 2023-03-26 20:14:14 +0000 UTC
session-types [ rat_type:NR wps:non_wps emergency_call:false pdu_type:ipv4v6 dnn:lab qos_5qi_1_rat_type:NR ssc_mode:ssc_mode_1 always_on:disable fourg_only_ue:false up_state:active qos_5qi_5_rat_type:NR dcnr:disable smf_roaming_status:visitor-lbo dnn:lab:rat_type:NR ]
data-size 2866
}
[smf/data] smf#
Si nous le comparons à l'impression du SMF :
[smf/data] smf# show subscriber supi imsi-123969789012404 gr-instance 1 namespace smf
Sun Mar 19 20:25:47.816 UTC+00:00
subscriber-details
{
"subResponses": [
[
"roaming-status:visitor-lbo",
"ue-type:nr-capable",
"supi:imsi-123969789012404",
"gpsi:msisdn-22331010101010",
"pei:imei-123456789012381",
"psid:1",
"snssai:001000003",
"dnn:lab",
"emergency:false",
"rat:nr",
"access:3gpp access",
"connectivity:5g",
"udm-uecm:10.10.10.215",
"udm-sdm:10.10.10.215",
"auth-status:unauthenticated",
"pcfGroupId:PCF-dnn=lab;",
"policy:2",
"pcf:10.10.10.216",
"upf:10.10.10.150",
"upfEpKey:10.10.10.150:10.10.10.202",
"ipv4-addr:pool1/10.0.0.3",
"ipv4-pool:pool1",
"ipv4-range:pool1/10.0.0.1",
"ipv4-startrange:pool1/10.0.0.1",
"ipv6-pfx:pool1/2001:db0:0:2::",
"ipv6-pool:pool1",
"ipv6-range:pool1/2001:db0::",
"ipv6-startrange:pool1/2001:db0::",
"id-index:1:0:32768",
"id-value:2/3",
"chfGroupId:CHF-dnn=lab;",
"chf:10.10.10.218",
"amf:10.10.10.217",
"peerGtpuEpKey:10.10.10.150:20.0.0.1",
"namespace:smf",
"nf-service:smf"
]
]
}
Vérifiez l'état CDL sur SMF :
cdl show status
cdl show sessions summary slice-name <slice name> | more
5.3 Les modules CDL ne fonctionnent pas
Comment identifier les
Vérifiez la sortie de description des pods (conteneurs/membre/État/Raison, événements).
kubectl describe pods -n <namespace> <failed pod name>
Comment réparer
- Les pods sont en état d'attente Vérifiez si un noeud k8s avec les valeurs d'étiquette égales à la valeur de cdl/type de noeud nombre de réplicas sont inférieurs ou égaux au nombre de noeuds k8s avec les valeurs d'étiquette égales à la valeur de cdl/type de noeud
kubectl get nodes -l smi.cisco.com/node-type=<value of cdl/node-type, default value is 'session' in multi node setup)
- Les pods sont dans l'état d'échec CrashLoopBackOff. Vérifiez l'état des pods etcd. Si les pods etcd ne sont pas en cours d'exécution, corrigez les problèmes etcd.
kubectl describe pods -n <namespace> <etcd pod name>
- Les pods sont à l'état d'échec ImagePullBack Vérifiez si le référentiel de barre et le registre d'images sont accessibles. Vérifiez si les serveurs proxy et dns requis sont configurés.
5.4 Les modules Mirror Maker sont à l'état init
Vérifiez la sortie et les journaux de description des pods
kubectl describe pods -n <namespace> <failed pod name> kubectl logs -n <namespace> <failed pod name> [-c <container name>]
Comment réparer
- Vérifiez si les adresses IP externes configurées pour Kafka sont correctes
- Vérifier la disponibilité du site distant kafka via des adresses IP externes
5.5 Les index CDL ne sont pas répliqués correctement
Comment identifier les
Les données ajoutées sur un site ne sont pas accessibles à partir d'un autre site.
Comment réparer
- Vérifiez la configuration de l'ID système local et la configuration du site distant.
- Vérifiez l'accessibilité des terminaux CDL et kafka entre chaque site.
- Vérifiez la carte, la réplique de l'index et le logement sur chaque site. Il peut être identique sur tous les sites.
5.6 Les opérations CDL échouent, mais la connexion réussit
Comment réparer
- Vérifiez que tous les pods sont prêts et en cours d'exécution.
- Les pods d'index sont à l'état Prêt uniquement s'ils sont synchronisés avec le réplica homologue (local ou distant si disponible)
- Les pods de logement sont à l'état Prêt uniquement s'ils sont synchronisés avec le réplica homologue (local ou distant si disponible)
- Les terminaux NE sont PAS à l'état prêt si au moins un logement et un pod d'index ne sont pas disponibles. Même s'il n'est pas prêt, la connexion grpc sera acceptée du client.
5.7 La notification de purge de l'enregistrement a été envoyée en avance ou en retard par CDL
Comment réparer
- Dans un cluster k8s, tous les noeuds peuvent être synchronisés dans le temps
- Vérifiez l'état de synchronisation NTP sur tous les noeuds k8. Si vous rencontrez des problèmes, corrigez-les.
chronyc tracking chronyc sources -v chronyc sourcestats -v
6. Alertes
| ALARME |
severity (gravité) |
résumé |
|---|---|---|
| CdlLocalRequestFailure |
critical (critique) |
Si le taux de réussite des requêtes locales est inférieur à 90 % pendant plus de 5 minutes, déclenche l'alarme |
| CdlRemoteConnectionFailure |
critical (critique) |
Si les connexions actives entre le pod de point d'extrémité et le site distant ont atteint 0 pendant plus de 5 minutes , l'alarme est déclenchée (uniquement pour le système compatible GR) |
| CdlRemoteRequestFailure |
critical (critique) |
Si le taux de réussite des requêtes distantes entrantes est inférieur à 90 % pendant plus de 5 minutes, déclenche l'alarme (uniquement pour le système GR) |
| cdlReplicationError |
critical (critique) |
Si le rapport entre les demandes de réplication sortantes et les demandes locales dans l'espace de noms cdl-global est passé sous la barre des 90 % pendant plus de 5 minutes (uniquement pour le système activé par GR). Ces alertes sont attendues pendant l'activité de mise à niveau et vous pouvez donc les ignorer. |
| cdlKafkaRemoteReplicationDelay |
critical (critique) |
Si le délai de réplication kafka vers le site distant dépasse 10 secondes pendant plus de 5 minutes, l'alarme est déclenchée (uniquement pour le système GR) |
| cdlOverloaded - majeur |
major (important) |
Si le système CDL atteint le pourcentage configuré (80 % par défaut) de sa capacité, le système déclenche l'alarme (uniquement si la fonction de protection contre les surcharges est activée) |
| cdlOverloaded - critique |
critical (critique) |
Si le système CDL atteint le pourcentage configuré (90 % par défaut) de sa capacité, le système déclenche l'alarme (uniquement si la fonction de protection contre les surcharges est activée) |
| CdlKafkaÉchecConnexion |
critical (critique) |
Si les pods d'index CDL sont déconnectés de kafka pendant plus de 5 minutes |
7. Problèmes les plus courants
7.1 cdlReplicationError
Cette alerte se produit généralement lors de l'activation du centre d'opérations ou de la mise à niveau du système, essayez de trouver CR pour elle, essayez de vérifier l'occurrence CEE de l'alerte et si elle a déjà été effacée.
7.2 cdlRemoteConnectionFailure et GRPC_Connections_Remote_Site
Cette explication s'applique à toutes les alertes « cdlRemoteConnectionFailure » et « GRPC_Connections_Remote_Site ».
Pour les alertes cdlRemoteConnectionFailure :
Dans les journaux des terminaux CDL, nous voyons que la connexion à l'hôte distant à partir du pod de terminal CDL a été perdue :
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
Le pod du point d'extrémité CDL tente de se connecter au serveur distant, mais il est refusé par l'hôte distant :
2022/01/20 01:37:08.730 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.732 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.742 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 8, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.752 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 2 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
2022/01/20 01:37:08.754 [WARN] [checksum.go:836] [datastore.checksum.session] Could not get checksum from remote for systemID: 2, clot: 7, Instance: 1 : rpc error: code = Unavailable desc = connection error: desc = "transport: Error while dialing dial tcp 10.10.10.141:8882: connect: connection refused"
Comme l'hôte distant est resté inaccessible pendant 5 minutes, l'alerte a été déclenchée comme suit :
alerts history detail cdlRemoteConnectionFailure f5237c750de6
severity critical
type "Processing Error Alarm"
startsAt 2025-01-21T01:41:26.857Z
endsAt 2025-01-21T02:10:46.857Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes"
labels [ "alertname: cdlRemoteConnectionFailure" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" ]
annotations [ "summary: CDL endpoint connections from pod cdl-ep-session-c1-d0-6d86f55945-pxfx9 and namespace smf-rcdn to remote site reached 0 for longer than 5 minutes" "type: Processing Error Alarm" ]
La connexion à l'hôte distant a réussi à 02:10:32:
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
Configuration présente dans SMF pour le site distant CDL :
cdl remote-site 2
db-endpoint host 10.10.10.141
db-endpoint port 8882
kafka-server 10.10.19.139 10061
exit
kafka-server 10.10.10.140 10061
exit
exit
Pour l'alerte GRPC_Connections_Remote_Site :
La même explication s'applique également à « GRPC_Connections_Remote_Site », car il s'agit également du même pod de point d'extrémité CDL.
alerts history detail GRPC_Connections_Remote_Site f083cb9d9b8d
severity critical
type "Communications Alarm"
startsAt 2025-01-21T01:37:35.160Z
endsAt 2025-01-21T02:11:35.160Z
source cdl-ep-session-c1-d0-6d86f55945-pxfx9
summary "GRPC connections to remote site are not equal to 4"
labels [ "alertname: GRPC_Connections_Remote_Site" "cluster: smf-data-rcdn_cee" "monitor: prometheus" "namespace: smf-rcdn" "pod: cdl-ep-session-c1-d0-6d86f55945-pxfx9" "replica: smf-data-rcdn_cee" "severity: critical" "systemId: 2" ]
À partir des journaux de pod de point d'extrémité CDL, l'alerte a démarré lorsque la connexion à l'hôte distant a été refusée :
2022/01/20 01:36:18.852 [ERROR] [RemoteEndointConnection.go:572] [datastore.ep.session] Connection to remote systemID 2 has been lost
L'alerte a été effacée lorsque la connexion au site distant a réussi :
2022/01/20 02:10:32.702 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.923 [WARN] [RemoteEndointConnection.go:563] [datastore.ep.session] Cdl status changed - new version 283eb1e86aa9561c653083e6b691c919, old version f81478148c9e1ccb28f3ec0d90ca04e1. Reloading connections
2022/01/20 02:10:38.927 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.934 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
2022/01/20 02:10:38.935 [WARN] [RemoteEndointConnection.go:437] [datastore.ep.session] Stream to remote site successful
8. Grafana
Le tableau de bord CDL fait partie de chaque déploiement SMF.
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
1.0 |
04-Oct-2023 |
Première publication |
Contribution d’experts de Cisco
- Nebojsa KosanovicResponsable technique
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)