Procédures de sauvegarde et de restauration pour divers composants Ultra-M - CPS
Options de téléchargement
-
ePub (346.2 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (313.8 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Introduction
Ce document décrit les étapes requises pour sauvegarder et restaurer une machine virtuelle dans une configuration Ultra-M qui héberge des fonctions de réseau virtuel CPS.
Informations générales
Ultra-M est une solution de coeur de réseau mobile prépackagée et validée, virtualisée et conçue pour simplifier le déploiement des fonctions de réseau virtuel (VNF). La solution Ultra-M se compose des types de machines virtuelles suivants :
- Contrôleur de services élastiques (ESC)
- Cisco Policy Suite (CPS)
L'architecture de haut niveau d'Ultra-M et les composants impliqués sont tels qu'illustrés dans cette image.
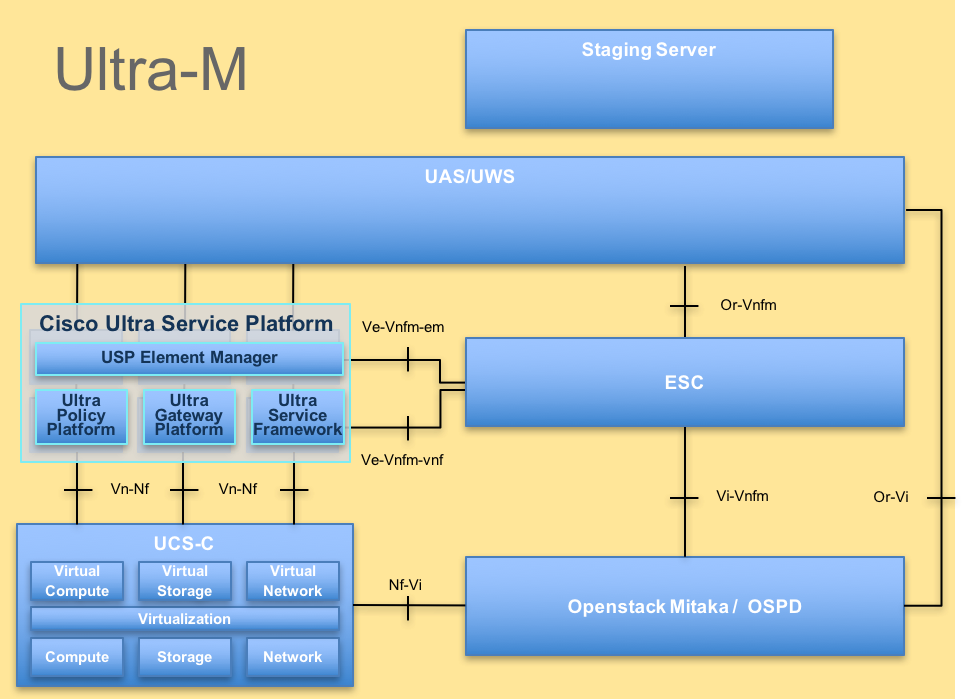

Remarque : la version Ultra M 5.1.x est prise en compte pour définir les procédures de ce document. Ce document est destiné au personnel Cisco qui connaît bien la plate-forme Cisco Ultra-M.
Abréviations
| VNF | Fonction de réseau virtuel |
| ESC | Contrôleur de service élastique |
| SERPILLIÈRE | Méthode de procédure |
| OSD | Disques de stockage d'objets |
| HDD | Disque dur |
| SSD | Disque dur SSD |
| VIM | Gestionnaire d'infrastructure virtuelle |
| VM | Machine virtuelle |
| UUID | Identificateur Universally Unique |
Procédure de sauvegarde
Sauvegarde OSPD
1. Vérifiez l'état de la pile OpenStack et la liste des noeuds.
[stack@director ~]$ source stackrc
[stack@director ~]$ openstack stack list --nested
[stack@director ~]$ ironic node-list
[stack@director ~]$ nova list
2. Vérifiez si tous les services sous-cloud sont à l'état chargé, actif et en cours d'exécution à partir du noeud OSP-D.
[stack@director ~]$ systemctl list-units "openstack*" "neutron*" "openvswitch*"
UNIT LOAD ACTIVE SUB DESCRIPTION
neutron-dhcp-agent.service loaded active running OpenStack Neutron DHCP Agent
neutron-openvswitch-agent.service loaded active running OpenStack Neutron Open vSwitch Agent
neutron-ovs-cleanup.service loaded active exited OpenStack Neutron Open vSwitch Cleanup Utility
neutron-server.service loaded active running OpenStack Neutron Server
openstack-aodh-evaluator.service loaded active running OpenStack Alarm evaluator service
openstack-aodh-listener.service loaded active running OpenStack Alarm listener service
openstack-aodh-notifier.service loaded active running OpenStack Alarm notifier service
openstack-ceilometer-central.service loaded active running OpenStack ceilometer central agent
openstack-ceilometer-collector.service loaded active running OpenStack ceilometer collection service
openstack-ceilometer-notification.service loaded active running OpenStack ceilometer notification agent
openstack-glance-api.service loaded active running OpenStack Image Service (code-named Glance) API server
openstack-glance-registry.service loaded active running OpenStack Image Service (code-named Glance) Registry server
openstack-heat-api-cfn.service loaded active running Openstack Heat CFN-compatible API Service
openstack-heat-api.service loaded active running OpenStack Heat API Service
openstack-heat-engine.service loaded active running Openstack Heat Engine Service
openstack-ironic-api.service loaded active running OpenStack Ironic API service
openstack-ironic-conductor.service loaded active running OpenStack Ironic Conductor service
openstack-ironic-inspector-dnsmasq.service loaded active running PXE boot dnsmasq service for Ironic Inspector
openstack-ironic-inspector.service loaded active running Hardware introspection service for OpenStack Ironic
openstack-mistral-api.service loaded active running Mistral API Server
openstack-mistral-engine.service loaded active running Mistral Engine Server
openstack-mistral-executor.service loaded active running Mistral Executor Server
openstack-nova-api.service loaded active running OpenStack Nova API Server
openstack-nova-cert.service loaded active running OpenStack Nova Cert Server
openstack-nova-compute.service loaded active running OpenStack Nova Compute Server
openstack-nova-conductor.service loaded active running OpenStack Nova Conductor Server
openstack-nova-scheduler.service loaded active running OpenStack Nova Scheduler Server
openstack-swift-account-reaper.service loaded active running OpenStack Object Storage (swift) - Account Reaper
openstack-swift-account.service loaded active running OpenStack Object Storage (swift) - Account Server
openstack-swift-container-updater.service loaded active running OpenStack Object Storage (swift) - Container Updater
openstack-swift-container.service loaded active running OpenStack Object Storage (swift) - Container Server
openstack-swift-object-updater.service loaded active running OpenStack Object Storage (swift) - Object Updater
openstack-swift-object.service loaded active running OpenStack Object Storage (swift) - Object Server
openstack-swift-proxy.service loaded active running OpenStack Object Storage (swift) - Proxy Server
openstack-zaqar.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server
openstack-zaqar@1.service loaded active running OpenStack Message Queuing Service (code-named Zaqar) Server Instance 1
openvswitch.service loaded active exited Open vSwitch
LOAD = Reflects whether the unit definition was properly loaded.
ACTIVE = The high-level unit activation state, for example, generalization of SUB.
SUB = The low-level unit activation state, values depend on unit type.
37 loaded units listed. Pass --all to see loaded but inactive units, too.
To show all installed unit files use 'systemctl list-unit-files'.
3. Vérifiez que vous disposez d'un espace disque suffisant avant d'effectuer la sauvegarde. Cette archive tar devrait être d'au moins 3,5 Go.
[stack@director ~]$df -h
4. Exécutez ces commandes en tant qu'utilisateur racine pour sauvegarder les données du noeud sous-cloud dans un fichier nommé undercloud-backup-[timestamp].tar.gz et transférez-le au serveur de sauvegarde.
[root@director ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql
[root@director ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql
/etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack
tar: Removing leading `/' from member names
Sauvegarde ESC
1. L’ESC, à son tour, active la fonction VNF (Virtual Network Function) en interagissant avec VIM.
2. La redondance 1:1 de l'ESC est assurée dans la solution Ultra-M. Deux VM ESC sont déployées et prennent en charge une seule défaillance dans Ultra-M. Par exemple, restaurez le système en cas de défaillance unique.
Remarque : en cas de défaillance multiple, elle n'est pas prise en charge et peut nécessiter le redéploiement du système.
Détails de la sauvegarde ESC :
- La configuration d'exécution
- ConfD CDB DB
- Journaux ESC
- Configuration Syslog
3. La fréquence de la sauvegarde de la base de données ESC est délicate et doit être gérée avec soin car l'ESC surveille et maintient les différentes machines d'état pour les différentes VM VNF déployées. Il est conseillé d'effectuer ces sauvegardes après ces activités dans un VNF/POD/site donné.
4. Vérifiez l'intégrité de l'ESC à l'aide du script health.sh.
[root@auto-test-vnfm1-esc-0 admin]# escadm status
0 ESC status=0 ESC Primary Healthy
[root@auto-test-vnfm1-esc-0 admin]# health.sh
esc ui is disabled -- skipping status check
esc_monitor start/running, process 836
esc_mona is up and running ...
vimmanager start/running, process 2741
vimmanager start/running, process 2741
esc_confd is started
tomcat6 (pid 2907) is running... [ OK ]
postgresql-9.4 (pid 2660) is running...
ESC service is running...
Active VIM = OPENSTACK
ESC Operation Mode=OPERATION
/opt/cisco/esc/esc_database is a mountpoint
============== ESC HA (Primary) with DRBD =================
DRBD_ROLE_CHECK=0
MNT_ESC_DATABSE_CHECK=0
VIMMANAGER_RET=0
ESC_CHECK=0
STORAGE_CHECK=0
ESC_SERVICE_RET=0
MONA_RET=0
ESC_MONITOR_RET=0
=======================================
ESC HEALTH PASSED
5. Effectuez la sauvegarde de la configuration en cours et transférez le fichier sur le serveur de sauvegarde.
[root@auto-test-vnfm1-esc-0 admin]# /opt/cisco/esc/confd/bin/confd_cli -u admin -C
admin connected from 127.0.0.1 using console on auto-test-vnfm1-esc-0.novalocal
auto-test-vnfm1-esc-0# show running-config | save /tmp/running-esc-12202017.cfg
auto-test-vnfm1-esc-0#exit
[root@auto-test-vnfm1-esc-0 admin]# ll /tmp/running-esc-12202017.cfg
-rw-------. 1 tomcat tomcat 25569 Dec 20 21:37 /tmp/running-esc-12202017.cfg
Sauvegarder la base de données ESC
1. Connectez-vous à la machine virtuelle ESC et exécutez cette commande avant d'effectuer la sauvegarde.
[admin@esc ~]# sudo bash
[root@esc ~]# cp /opt/cisco/esc/esc-scripts/esc_dbtool.py /opt/cisco/esc/esc-scripts/esc_dbtool.py.bkup
[root@esc esc-scripts]# sudo sed -i "s,'pg_dump,'/usr/pgsql-9.4/bin/pg_dump," /opt/cisco/esc/esc-scripts/esc_dbtool.py
#Set ESC to mainenance mode
[root@esc esc-scripts]# escadm op_mode set --mode=maintenance
2. Vérifiez le mode ESC et assurez-vous qu'il est en mode maintenance.
[root@esc esc-scripts]# escadm op_mode show
3. Sauvegardez la base de données à l'aide de l'outil de sauvegarde de base de données disponible dans ESC.
[root@esc scripts]# sudo /opt/cisco/esc/esc-scripts/esc_dbtool.py backup --file scp://<username>:<password>@<backup_vm_ip>:<filename>
4. Réglez ESC sur Operation Mode (Mode de fonctionnement) et confirmez le mode.
[root@esc scripts]# escadm op_mode set --mode=operation
[root@esc scripts]# escadm op_mode show
5. Accédez au répertoire des scripts et collectez les journaux.
[root@esc scripts]# /opt/cisco/esc/esc-scripts
sudo ./collect_esc_log.sh
6. Pour créer un instantané de l'ESC, arrêtez-le.
shutdown -r now
7. À partir d'OSPD, créez un instantané d'image.
nova image-create --poll esc1 esc_snapshot_27aug2018
8. Vérifiez que la capture instantanée est créée.
openstack image list | grep esc_snapshot_27aug2018
9. Démarrez l'ESC à partir de l'OSPD.
nova start esc1
10. Répétez la même procédure sur la machine virtuelle ESC en veille et transférez les journaux vers le serveur de sauvegarde.
11. Collectez la sauvegarde de la configuration Syslog sur le VMS ESC et transférez-les sur le serveur de sauvegarde.
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
Sauvegarde CPS
Étape 1. Créez une sauvegarde de CPS Cluster-Manager.
Utilisez cette commande afin d'afficher les instances nova et de noter le nom de l'instance VM du gestionnaire de cluster :
nova list
Arrêtez Cluman à partir de l'ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli vm-action STOP <vm-name>
Étape 2. Vérifiez que Cluster Manager est à l'état SHUTOFF.
admin@esc1 ~]$ /opt/cisco/esc/confd/bin/confd_cli admin@esc1> show esc_datamodel opdata tenants tenant Core deployments * state_machine
Étape 3. Créez une image de snapshot nova comme indiqué dans la commande suivante :
nova image-create --poll <cluman-vm-name> <snapshot-name>
Remarque : assurez-vous que vous disposez de suffisamment d'espace disque pour le snapshot.
.Important : si la machine virtuelle devient inaccessible après la création du snapshot, vérifiez l'état de la machine virtuelle à l'aide de la commande nova list. S'il est à l'état SHUTOFF (ARRÊT), vous devez démarrer la VM manuellement.
Étape 4. Affichez la liste d'images avec cette commande : nova image-list
Image 1 : Exemple de résultat

Étape 5. Lors de la création d'un snapshot, l'image du snapshot est stockée dans OpenStack Glance. Pour stocker le snapshot dans un data store distant, téléchargez le snapshot et transférez le fichier dans OSPD vers (/home/stack/CPS_BACKUP).
Pour télécharger l'image, utilisez cette commande dans OpenStack :
glance image-download –-file For example: glance image-download –-file snapshot.raw 2bbfb51c-cd05-4b7c-ad77-8362d76578db
Étape 6. Répertoriez les images téléchargées comme indiqué dans cette commande :
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
Étape 7. Stocker le snapshot de la machine virtuelle Cluster Manager à restaurer ultérieurement.
2. Sauvegardez la configuration et la base de données.
1. config_br.py -a export --all /var/tmp/backup/ATP1_backup_all_$(date +\%Y-\%m-\%d).tar.gz OR 2. config_br.py -a export --mongo-all /var/tmp/backup/ATP1_backup_mongoall$(date +\%Y-\%m-\%d).tar.gz 3. config_br.py -a export --svn --etc --grafanadb --auth-htpasswd --haproxy /var/tmp/backup/ATP1_backup_svn_etc_grafanadb_haproxy_$(date +\%Y-\%m-\%d).tar.gz 4. mongodump - /var/qps/bin/support/env/env_export.sh --mongo /var/tmp/env_export_$date.tgz 5. patches - cat /etc/broadhop/repositories, check which patches are installed and copy those patches to the backup directory /home/stack/CPS_BACKUP on OSPD 6. backup the cronjobs by taking backup of the cron directory: /var/spool/cron/ from the Pcrfclient01/Cluman. Then move the file to CPS_BACKUP on the OSPD.
Vérifiez à partir de crontab-l si une autre sauvegarde est nécessaire.
Transférez toutes les sauvegardes vers OSPD /home/stack/CPS_BACKUP.
3. Sauvegardez le fichier Yaml à partir de l'ESC Primary.
/opt/cisco/esc/confd/bin/netconf-console --host 127.0.0.1 --port 830 -u <admin-user> -p <admin-password> --get-config > /home/admin/ESC_config.xml
Transférez le fichier dans OSPD /home/stack/CPS_BACKUP.
4. Sauvegardez les entrées crontab -l.
Créez un fichier texte avec crontab -l et envoyez-le par FTP à un emplacement distant (dans OSPD /home/stack/CPS_BACKUP).
5. Effectuez une sauvegarde des fichiers de routage à partir des clients LB et PCRF.
Collect and scp the configurations from both LBs and Pcrfclients route -n /etc/sysconfig/network-script/route-*
Procédure de restauration
Récupération OSPD
La procédure de récupération OSPD est effectuée sur la base de ces hypothèses.
1. La sauvegarde OSPD est disponible à partir de l’ancien serveur OSPD.
2. La récupération OSPD peut être effectuée sur le nouveau serveur qui remplace l’ancien serveur OSPD dans le système. .
Récupération ESC
1. La VM ESC peut être restaurée si la VM est en état d'erreur ou d'arrêt. Redémarrez-la pour activer la VM affectée. Exécutez ces étapes pour récupérer ESC.
2. Identifiez la machine virtuelle qui est en état ERREUR ou Arrêt, une fois identifié dur-redémarrer la machine virtuelle ESC. Dans cet exemple, vous redémarrez auto-test-vnfm1-ESC-0.
[root@tb1-baremetal scripts]# nova list | grep auto-test-vnfm1-ESC-
| f03e3cac-a78a-439f-952b-045aea5b0d2c | auto-test-vnfm1-ESC-0 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.11; auto-testautovnf1-uas-management=172.31.11.3 |
| 79498e0d-0569-4854-a902-012276740bce | auto-test-vnfm1-ESC-1 | ACTIVE | - | running | auto-testautovnf1-uas-orchestration=172.31.12.15; auto-testautovnf1-uas-management=172.31.11.15 |
[root@tb1-baremetal scripts]# [root@tb1-baremetal scripts]# nova reboot --hard f03e3cac-a78a-439f-952b-045aea5b0d2c\
Request to reboot server <Server: auto-test-vnfm1-ESC-0> has been accepted.
[root@tb1-baremetal scripts]#
3. Si la VM ESC est supprimée et doit être réactivée. Utilisez la séquence d'étapes suivante.
[stack@pod1-ospd scripts]$ nova list |grep ESC-1
| c566efbf-1274-4588-a2d8-0682e17b0d41 | vnf1-ESC-ESC-1 | ACTIVE | - | running | vnf1-UAS-uas-orchestration=172.16.11.14; vnf1-UAS-uas-management=172.16.10.4 |
[stack@pod1-ospd scripts]$ nova delete vnf1-ESC-ESC-1
Request to delete server vnf1-ESC-ESC-1 has been accepted.
4. Si la VM ESC est irrécupérable et nécessite la restauration de la base de données, restaurez la base de données à partir de la sauvegarde précédemment effectuée.
5. Pour la restauration de la base de données ESC, vous devez vous assurer que le service ESC est arrêté avant de restaurer la base de données ; pour la HA ESC, exécutez d'abord la VM secondaire, puis la VM principale.
# service keepalived stop
6. Vérifiez l'état du service ESC et assurez-vous que tout est arrêté sur les machines virtuelles principale et secondaire pour la haute disponibilité.
# escadm status
7. Exécutez le script pour restaurer la base de données. Dans le cadre de la restauration de la base de données sur l'instance ESC nouvellement créée, l'outil peut également promouvoir l'une des instances en tant qu'ESC primaire, monter son dossier DB sur le périphérique drbd et démarrer la base de données PostgreSQL.
# /opt/cisco/esc/esc-scripts/esc_dbtool.py restore --file scp://<username>:<password>@<backup_vm_ip>:<filename>
8. Redémarrez le service ESC pour terminer la restauration de la base de données. Pour que la haute disponibilité s'exécute sur les deux machines virtuelles, redémarrez le service keepalived.
# service keepalived start
9. Une fois que la machine virtuelle est correctement restaurée et en cours d'exécution, assurez-vous que toute la configuration spécifique de Syslog est restaurée à partir de la sauvegarde connue précédente. assurez-vous qu'elle est restaurée dans toutes les machines virtuelles ESC.
[admin@auto-test-vnfm2-esc-1 ~]$
[admin@auto-test-vnfm2-esc-1 ~]$ cd /etc/rsyslog.d
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/00-escmanager.conf
00-escmanager.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/01-messages.conf
01-messages.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.d/02-mona.conf
02-mona.conf
[admin@auto-test-vnfm2-esc-1 rsyslog.d]$ls /etc/rsyslog.conf
rsyslog.conf
10. Si l'ESC doit être reconstruit à partir d'un snapshot OSPD, utilisez cette commande avec l'utilisation d'un snapshot pris pendant la sauvegarde.
nova rebuild --poll --name esc_snapshot_27aug2018 esc1
11. Vérifiez l’état de l’ESC une fois la reconstruction terminée.
nova list --fileds name,host,status,networks | grep esc
12. Vérifiez l'état de l'ESC avec cette commande.
health.sh
Copy Datamodel to a backup file
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli get esc_datamodel/opdata > /tmp/esc_opdata_`date +%Y%m%d%H%M%S`.txt
Échec du démarrage de la VM par ESC
- Dans certains cas, ESC peut ne pas démarrer la machine virtuelle en raison d'un état inattendu. Une solution de contournement consiste à effectuer une commutation ESC en redémarrant l'ESC principal. Le basculement de l'ESC peut prendre environ une minute. Exécutez le fichier health.sh sur la nouvelle ESC principale pour vérifier qu'elle est active. Lorsque l'ESC devient Primary, l'ESC peut corriger l'état de la VM et démarrer la VM. Comme cette opération est planifiée, vous devez attendre 5 à 7 minutes pour qu'elle se termine.
- Vous pouvez surveiller /var/log/esc/yangesc.log et /var/log/esc/escmanager.log. Si vous ne voyez PAS de VM récupérée après 5 à 7 minutes, l'utilisateur devrait aller et faire la récupération manuelle de la ou des VM affectées.
- Une fois que la machine virtuelle a été correctement restaurée et exécutée, assurez-vous que la configuration spécifique au Syslog a été restaurée à partir de la sauvegarde connue précédente. Assurez-vous qu'il est restauré dans toutes les VM ESC
root@abautotestvnfm1em-0:/etc/rsyslog.d# pwd
/etc/rsyslog.d
root@abautotestvnfm1em-0:/etc/rsyslog.d# ll
total 28
drwxr-xr-x 2 root root 4096 Jun 7 18:38 ./
drwxr-xr-x 86 root root 4096 Jun 6 20:33 ../]
-rw-r--r-- 1 root root 319 Jun 7 18:36 00-vnmf-proxy.conf
-rw-r--r-- 1 root root 317 Jun 7 18:38 01-ncs-java.conf
-rw-r--r-- 1 root root 311 Mar 17 2012 20-ufw.conf
-rw-r--r-- 1 root root 252 Nov 23 2015 21-cloudinit.conf
-rw-r--r-- 1 root root 1655 Apr 18 2013 50-default.conf
root@abautotestvnfm1em-0:/etc/rsyslog.d# ls /etc/rsyslog.conf
rsyslog.conf
Récupération CPS
Restaurer la machine virtuelle Cluster Manager dans OpenStack
Étape 1. Copiez le snapshot de VM du gestionnaire de cluster sur la lame du contrôleur comme indiqué dans cette commande :
ls —ltr *snapshot*
Example output: -rw-r--r--. 1 root root 10429595648 Aug 16 02:39 snapshot.raw
Étape 2. Téléchargez l'image de snapshot vers OpenStack à partir du data store :
glance image-create --name --file --disk-format qcow2 --container-format bare
Étape 3. Vérifiez si le snapshot est téléchargé à l'aide d'une commande Nova, comme indiqué dans cet exemple :
nova image-list
Image 2 : Exemple de résultat

Étape 4. Selon que la machine virtuelle du gestionnaire de cluster existe ou non, vous pouvez choisir de créer la colonne ou de la reconstruire :
· Si l'instance de VM Cluster Manager n'existe pas, créez la VM Cluman à l'aide d'une commande Heat ou Nova, comme indiqué dans cet exemple :
Créez la machine virtuelle Cluman à l'aide de la commande ESC.
/opt/cisco/esc/esc-confd/esc-cli/esc_nc_cli edit-config /opt/cisco/esc/cisco-cps/config/gr/tmo/gen/<original_xml_filename>
Le cluster PCRF peut être généré à l'aide de la commande précédente, puis restaurer les configurations du gestionnaire de cluster à partir des sauvegardes effectuées avec config_br.py restore, mongorestore à partir de dump pris en sauvegarde.
delete - nova boot --config-drive true --image "" --flavor "" --nic net-id=",v4-fixed-ip=" --nic net-id="network_id,v4-fixed-ip=ip_address" --block-device-mapping "/dev/vdb=2edbac5e-55de-4d4c-a427-ab24ebe66181:::0" --availability-zone "az-2:megh-os2-compute2.cisco.com" --security-groups cps_secgrp "cluman"
· Si l'instance de VM Cluster Manager existe, utilisez une commande nova rebuild pour reconstruire l'instance de VM Cluster avec le snapshot téléchargé comme indiqué :
nova rebuild <instance_name> <snapshot_image_name>
Exemple :
nova rebuild cps-cluman-5f3tujqvbi67 cluman_snapshot
Étape 5. Répertoriez toutes les instances comme indiqué et vérifiez que la nouvelle instance du gestionnaire de cluster est créée et en cours d'exécution :
nova list
Image 3. Exemple de rapport

Restaurez les derniers correctifs sur le système.
1. Copy the patch files to cluster manager which were backed up in OSPD /home/stack/CPS_BACKUP 2. Login to the Cluster Manager as a root user. 3. Untar the patch by executing this command: tar -xvzf [patch name].tar.gz 4. Edit /etc/broadhop/repositories and add this entry: file:///$path_to_the plugin/[component name] 5. Run build_all.sh script to create updated QPS packages: /var/qps/install/current/scripts/build_all.sh 6. Shutdown all software components on the target VMs: runonall.sh sudo monit stop all 7. Make sure all software components are shutdown on target VMs: statusall.sh
Remarque : les composants logiciels doivent tous afficher l'état Non surveillé comme état actuel.
8. Update the qns VMs with the new software using reinit.sh script: /var/qps/install/current/scripts/upgrade/reinit.sh 9. Restart all software components on the target VMs: runonall.sh sudo monit start all 10. Verify that the component is updated, run: about.sh
Restaurer les Cronjobs.
1. Déplacez le fichier sauvegardé de OSPD vers Cluman/Pcrfclient01.
2. Exécutez la commande pour activer la tâche cron à partir de la sauvegarde.
#crontab Cron-backup
3. Vérifiez si les tâches cron ont été activées par cette commande.
#crontab -l
Restaurer des machines virtuelles individuelles dans le cluster.
Pour redéployer la machine virtuelle pcrfclient01 :
Étape 1. Connectez-vous à la machine virtuelle Cluster Manager en tant qu'utilisateur racine.
Étape 2. Mémorisez l'UUID du référentiel SVN à l'aide de cette commande :
svn info http://pcrfclient02/repos | grep UUID
La commande peut afficher l'UUID du référentiel.
Par exemple : UUID du référentiel : ea50bbd2-5726-46b8-b807-10f4a7424f0e
Étape 3. Importez les données de configuration du générateur de stratégies de sauvegarde sur le Gestionnaire de clusters, comme indiqué dans cet exemple :
config_br.py -a import --etc-oam --svn --stats --grafanadb --auth-htpasswd --users /mnt/backup/oam_backup_27102016.tar.gz
Remarque : de nombreux déploiements exécutent une tâche cron qui sauvegarde régulièrement les données de configuration. Voir Subversion Repository Backup pour plus de détails.
Étape 4. Pour générer les fichiers d'archive de VM sur Cluster Manager à l'aide des configurations les plus récentes, exécutez cette commande :
/var/qps/install/current/scripts/build/build_svn.sh
Étape 5. Pour déployer la machine virtuelle pcrfclient01, effectuez l'une des opérations suivantes :
Dans OpenStack, utilisez le modèle HEAT ou la commande Nova pour recréer la machine virtuelle. Pour plus d'informations, consultez le Guide d'installation de CPS pour OpenStack.
Étape 6. Rétablissez la synchronisation SVN primaire/secondaire entre pcrfclient01 et pcrfclient02 avec pcrfclient01 comme principal en exécutant ces séries de commandes.
Si SVN est déjà synchronisé, n'émettez pas ces commandes.
Pour vérifier si SVN est synchronisé, exécutez cette commande à partir de pcrfclient02.
Si une valeur est retournée, alors SVN est déjà synchronisé :
/usr/bin/svn propget svn:sync-from-url --revprop -r0 http://pcrfclient01/repos
Exécutez ces commandes à partir de pcrfclient01 :
/bin/rm -fr /var/www/svn/repos /usr/bin/svnadmin create /var/www/svn/repos /usr/bin/svn propset --revprop -r0 svn:sync-last-merged-rev 0 http://pcrfclient02/repos-proxy-sync /usr/bin/svnadmin setuuid /var/www/svn/repos/ "Enter the UUID captured in step 2" /etc/init.d/vm-init-client / var/qps/bin/support/recover_svn_sync.sh
Étape 7. Si pcrfclient01 est également la machine virtuelle arbitre, exécutez les étapes suivantes :
a) Créez les scripts de démarrage/arrêt mongodb en fonction de la configuration du système. Toutes ces bases de données ne sont pas configurées pour tous les déploiements.
Remarque : consultez le site /etc/broadhop/mongoConfig.cfg pour déterminer les bases de données à configurer.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
b) Commencez le processus mongo :
/usr/bin/systemctl start sessionmgr-XXXXX
c) Attendez que l'arbitre démarre, puis exécutez diagnostics.sh —get_replica_status pour vérifier l'intégrité du jeu de réplicas.
Pour redéployer la machine virtuelle pcrfclient02 :
Étape 1. Connectez-vous à la machine virtuelle Cluster Manager en tant qu'utilisateur racine.
Étape 2. Pour générer les fichiers d'archive de VM sur Cluster Manager à l'aide des configurations les plus récentes, exécutez cette commande :
/var/qps/install/current/scripts/build/build_svn.sh
Étape 3. Pour déployer la machine virtuelle pcrfclient02, effectuez l'une des opérations suivantes :
Dans OpenStack, utilisez le modèle HEAT ou la commande Nova pour recréer la machine virtuelle. Pour plus d'informations, consultez le Guide d'installation de CPS pour OpenStack.
Étape 4. Sécurisez l'interpréteur de commandes sur pcrfclient01 :
ssh pcrfclient01
Étape 5. Exécutez ce script pour récupérer les repos SVN de pcrfclient01 :
/var/qps/bin/support/recover_svn_sync.sh
Pour redéployer une VM SessionManager :
Étape 1. Connectez-vous à la machine virtuelle Cluster Manager en tant qu'utilisateur racine.
Étape 2. Pour déployer la machine virtuelle sessionmgr et remplacer la machine virtuelle défaillante ou endommagée, effectuez l'une des opérations suivantes :
Dans OpenStack, utilisez le modèle HEAT ou la commande Nova pour recréer la machine virtuelle. Pour plus d'informations, consultez le Guide d'installation de CPS pour OpenStack.
Étape 3. Créez les scripts de démarrage/arrêt mongodb en fonction de la configuration du système.
Toutes ces bases de données ne sont pas configurées pour tous les déploiements. Reportez-vous au site /etc/broadhop/mongoConfig.cfg pour déterminer les bases de données à configurer.
cd /var/qps/bin/support/mongo build_set.sh --session --create-scripts build_set.sh --admin --create-scripts build_set.sh --spr --create-scripts build_set.sh --balance --create-scripts build_set.sh --audit --create-scripts build_set.sh --report --create-scripts
Étape 4. Sécurisez l'interpréteur de commandes sur la machine virtuelle sessionmgr et démarrez le processus mongo :
ssh sessionmgrXX /usr/bin/systemctl start sessionmgr-XXXXX
Étape 5. Attendez que les membres démarrent et que les membres secondaires se synchronisent, puis exécutez diagnostics.sh —get_replica_status pour vérifier l'intégrité de la base de données.
Étape 6. Pour restaurer la base de données Session Manager, utilisez l'une des commandes suivantes, selon que la sauvegarde a été effectuée avec l'option —mongo-all ou —mongo :
• config_br.py -a import --mongo-all --users /mnt/backup/Name of backup or • config_br.py -a import --mongo --users /mnt/backup/Name of backup
Pour redéployer la machine virtuelle Policy Director (Load Balancer) :
Étape 1. Connectez-vous à la machine virtuelle Cluster Manager en tant qu'utilisateur racine.
Étape 2. Pour importer les données de configuration du générateur de politiques de sauvegarde sur le Gestionnaire de cluster, exécutez la commande suivante :
config_br.py -a import --network --haproxy --users /mnt/backup/lb_backup_27102016.tar.gz
Étape 3. Pour générer les fichiers d'archive de VM sur Cluster Manager à l'aide des configurations les plus récentes, exécutez cette commande :
/var/qps/install/current/scripts/build/build_svn.sh
Étape 4. Pour déployer la machine virtuelle lb01, effectuez l'une des opérations suivantes :
Dans OpenStack, utilisez le modèle HEAT ou la commande Nova pour recréer la machine virtuelle. Pour plus d'informations, consultez le Guide d'installation de CPS pour OpenStack.
Pour redéployer la machine virtuelle Policy Server (QNS) :
Étape 1. Connectez-vous à la machine virtuelle Cluster Manager en tant qu'utilisateur racine.
Étape 2. Importez les données de configuration du générateur de stratégies de sauvegarde sur le Gestionnaire de clusters, comme indiqué dans cet exemple :
config_br.py -a import --users /mnt/backup/qns_backup_27102016.tar.gz
Étape 3. Pour générer les fichiers d'archive de VM sur Cluster Manager à l'aide des configurations les plus récentes, exécutez cette commande :
/var/qps/install/current/scripts/build/build_svn.sh
Étape 4. Pour déployer la machine virtuelle qns, effectuez l'une des opérations suivantes :
Dans OpenStack, utilisez le modèle HEAT ou la commande Nova pour recréer la machine virtuelle. Pour plus d'informations, consultez le Guide d'installation de CPS pour OpenStack.
Procédure générale de restauration de base de données.
Étape 1. Exécutez cette commande pour restaurer la base de données :
config_br.py –a import --mongo-all /mnt/backup/backup_$date.tar.gz where $date is the timestamp when the export was made.
Exemple :
config_br.py –a import --mongo-all /mnt/backup/backup_27092016.tgz
Étape 2. Connectez-vous à la base de données et vérifiez qu'elle est en cours d'exécution et accessible :
1. Connectez-vous au gestionnaire de session :
mongo --host sessionmgr01 --port $port
où $port est le numéro de port de la base de données à vérifier. Par exemple, 27718 est le port Balance par défaut.
2. Affichez la base de données en exécutant la commande suivante :
show dbs
3. Basculez le shell mongo vers la base de données en exécutant cette commande :
use $db
où $db est un nom de base de données affiché dans la commande précédente.
La commande use commute le shell mongo vers cette base de données.
Exemple :
use balance_mgmt
4. Pour afficher les collections, exécutez la commande suivante :
show collections
5. Pour afficher le nombre d'enregistrements de la collection, exécutez cette commande :
db.$collection.count() For example, db.account.count()
L'exemple précédent peut afficher le nombre d'enregistrements du compte de collecte dans la base de données Balance (balance_mgmt).
Restauration du référentiel Subversion.
Pour restaurer les données de configuration de Policy Builder à partir d'une sauvegarde, exécutez la commande suivante :
config_br.py –a import --svn /mnt/backup/backup_$date.tgz where, $date is the date when the cron created the backup file.
Restaurer Grafana Dashboard.
Vous pouvez restaurer le tableau de bord Grafana en utilisant cette commande :
config_br.py -a import --grafanadb /mnt/backup/
Validation de la restauration.
Après avoir restauré les données, vérifiez le système en exécutant la commande suivante :
/var/qps/bin/diag/diagnostics.sh
Historique de révision
| Révision | Date de publication | Commentaires |
|---|---|---|
2.0 |
20-Mar-2024 |
Titre, introduction, texte de remplacement, traduction automatique, exigences de style et mise en forme mis à jour. |
1.0 |
21-Sep-2018 |
Première publication |
Contribution d’experts de Cisco
- Aaditya DeodharServices avancés Cisco
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)