Introduction
Ce document décrit comment dépanner sessmgr ou aamgr qui sont dans l'état "warn" ou "over".
Aperçu
Gestionnaire de session (Sessmgr) : système de traitement des abonnés qui prend en charge plusieurs types de session et qui est chargé de gérer les transactions des abonnés. Sessmgr est généralement associé à AAAManagers.
Gestionnaire d'autorisations, d'authentification et de comptabilité (Aamgr) : est responsable de l'exécution de toutes les opérations et fonctions du protocole AAA pour les abonnés et les utilisateurs administratifs du système.
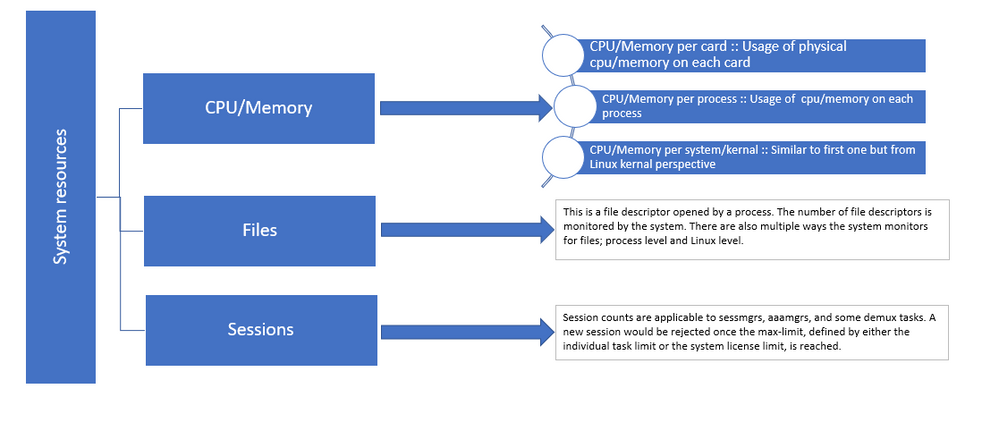 Figure 1 : Distribution des ressources Staros
Figure 1 : Distribution des ressources Staros
Journaux/vérifications de base
Contrôles de base
Pour obtenir plus de détails sur le problème, vous devez vérifier ces informations avec l'utilisateur :
- Depuis combien de temps le sessmgr/aamgr est-il à l'état « warn » ou « over » ?
- Combien de sessmgrs/aamgrs sont concernés par ce problème ?
- Vous devez confirmer si sessmgr/aamgr est dans l'état "warn" ou "over" en raison de la mémoire ou du CPU.
- Vous devez également vérifier s'il y a eu une augmentation soudaine du trafic, qui peut être évaluée en examinant le nombre de sessions par sessmgr.
En obtenant ces renseignements, vous pourrez mieux comprendre et régler le problème en question.
Journaux
-
Procurez-vous Show Support Details (SSD) et syslogs pour capturer l'horodatage problématique. Il est recommandé de collecter ces journaux au moins 2 heures avant l'apparition du problème afin d'identifier le point de déclenchement.
-
Capturez les fichiers de base pour les sessmgr/aamgr problématiques et non problématiques. Vous trouverez plus d'informations à ce sujet dans la section Analyse.
Analyse
Étape 1. Pour vérifier l'état des commandes sessmgr/aamgr affectées.
show task resources -
--------- to check detail of sessmgr/aamgr into warn/over state and from the same you also get to know current memory/cpu utlization
Output ::
******** show task resources *******
Monday May 29 08:30:54 IST 2023
task cputime memory files sessions
cpu facility inst used alloc used alloc used allc used allc S status
----------------------- ----------- ------------- --------- ------------- ------
2/0 sessmgr 297 6.48% 100% 604.8M 900.0M 210 500 1651 12000 I good
2/0 sessmgr 300 5.66% 100% 603.0M 900.0M 224 500 1652 12000 I good
2/1 aaamgr 155 0.90% 95% 96.39M 260.0M 21 500 -- -- - good
2/1 aaamgr 170 0.89% 95% 96.46M 260.0M 21 500 -- -- - good

Remarque : le nombre de sessions par sessmgr peut être vérifié par cette commande comme indiqué dans le résultat de la commande.
Ces deux commandes aident à vérifier l'utilisation maximale de la mémoire depuis le rechargement du noeud :
show task resources max
show task memory max
******** show task memory max *******
Monday May 29 08:30:53 IST 2023
task heap physical virtual
cpu facility inst max max alloc max alloc status
----------------------- ------ ------------------ ------------------ ------
2/0 sessmgr 902 548.6M 66% 602.6M 900.0M 29% 1.19G 4.00G good
2/0 aaamgr 913 68.06M 38% 99.11M 260.0M 17% 713.0M 4.00G good
Remarque : la commande memory max indique la mémoire maximale utilisée depuis le rechargement du noeud. Cette commande nous aide à identifier les modèles liés au problème, par exemple si le problème a commencé après un rechargement récent ou s'il y a eu un rechargement récent qui nous permet de vérifier la valeur de mémoire maximale. D'un autre côté, « show task resources » et « show task resources max » fournissent des résultats similaires, à la différence que la commande max affiche les valeurs maximales de mémoire, de CPU et de sessions utilisées par un sessmgr/aamgr spécifique depuis le rechargement.
show subscriber summary apn <apn name> smgr-instance <instance ID> | grep Total
-------------- to check no of subscribers for that particular APN in sessmg
plan d'action
Scénario 1. Utilisation élevée de la mémoire
1. Collectez SSD avant de redémarrer/tuer l'instance sessmgr.
2. Collectez le vidage de mémoire pour l'un des sessmgr affectés.
task core facility sessmgr instance <instance-value>
3. Collectez la sortie du tas à l'aide de ces commandes en mode masqué pour les mêmes sessmgr et aamgr affectés.
show session subsystem facility sessmgr instance <instance-value> debug-info verbose
show task resources facility sessmgr instance <instance-value>
Heap outputs:
show messenger proclet facility sessmgr instance <instance-value> heap depth 9
show messenger proclet facility sessmgr instance <instance-value> system heap depth 9
show messenger proclet facility sessmgr instance <instance-value> heap
show messenger proclet facility sessmgr instance <instance-value> system
show snx sessmgr instance <instance-value> memory ldbuf
show snx sessmgr instance <instance-value> memory mblk
4. Redémarrez la tâche sessmgr à l'aide de la commande suivante :
task kill facility sessmgr instance <instance-value>

Attention : si plusieurs sessmgrs sont à l'état « avertir » ou « sur », il est recommandé de les redémarrer avec un intervalle de 2 à 5 minutes. Commencez par redémarrer seulement 2 à 3 sessmgrs, puis attendez jusqu'à 10 à 15 minutes pour voir si ces sessmgrs reviennent à l'état normal. Cette étape permet d'évaluer l'impact du redémarrage et de surveiller la progression de la restauration.
5. Vérifiez l'état du sessmgr.
show task resources facility sessmgr instance <instance-value> -------- to check if sessmgr is back in good state
6. Collectez un autre SSD.
7. Collectez le résultat de toutes les commandes CLI mentionnées à l’étape 3.
8. Collectez le vidage de mémoire pour toutes les instances sessmgr saines à l'aide de la commande mentionnée à l'étape 2.
Remarque : Pour obtenir des fichiers de base pour les installations problématiques et non problématiques, vous avez deux options. Premièrement, vous pouvez collecter le fichier de base du même sessmgr après son retour à la normale après un redémarrage. Vous pouvez également capturer le fichier de base à partir d'un autre sessmgr sain. Ces deux approches fournissent des informations précieuses pour l'analyse et le dépannage.
Une fois que vous avez collecté les sorties de tas, veuillez contacter le TAC Cisco pour trouver le tableau exact de consommation de tas.
À partir de ces sorties de tas, vous devez vérifier la fonction qui utilise plus de mémoire. Sur cette base, le TAC étudie le but prévu de l'utilisation des fonctions et détermine si son utilisation correspond à l'augmentation du trafic/volume de transactions ou à toute autre raison problématique.
Les sorties de tas peuvent être triées en utilisant un outil accessible par le lien donné comme Memory-CPU-data-sorting-tool.
Remarque : cet outil propose plusieurs options pour les différentes installations. Cependant, vous devez sélectionner "Table de consommation de tas" où vous téléchargez des sorties de tas et exécutez l'outil pour obtenir la sortie dans un format trié.
Scénario 2. En raison d'une utilisation CPU élevée
1. Collectez SSD avant de redémarrer ou de tuer l'instance sessmgr.
2. Collectez le vidage de mémoire pour l'un des sessmgr affectés.
task core facility sessmgr instance <instance-value>
3. Collectez la sortie de tas de ces commandes en mode masqué pour le même sessmgr/aamgr affecté.
show session subsystem facility sessmgr instance <instance-value> debug-info verbose
show task resources facility sessmgr instance <instance-value>
show cpu table
show cpu utilization
show cpu info ------ Display detailed info of CPU.
show cpu info verbose ------ More detailed version of the above
Profiler output for CPU
This is the background cpu profiler. This command allows checking which functions consume
the most CPU time. This command requires CLI test command password.
show profile facility <facility instance> instance <instance ID> depth 4
show profile facility <facility instance> active facility <facility instance> depth 8
4. Redémarrez la tâche sessmgr avec cette commande :
task kill facility sessmgr instance <instance-value>
5. Vérifiez l'état du sessmgr.
show task resources facility sessmgr instance <instance-value> -------- to check if sessmgr is back in good state
6. Collectez un autre SSD.
7. Collectez le résultat de toutes les commandes CLI mentionnées à l’étape 3.
8. Collectez le vidage de mémoire pour toutes les instances sessmgr saines à l'aide de la commande mentionnée à l'étape 2.
Pour analyser les scénarios de mémoire élevée et de CPU, examinez les statistiques groupées afin de déterminer s'il y a une augmentation légitime des tendances de trafic.
En outre, vérifiez les statistiques de volume pour les statistiques de niveau carte/processeur.
 Commentaires
Commentaires