Element Manager après la version Ultra 6.3 : modifications architecturales et résolution des problèmes liés à la solution EM
Options de téléchargement
-
ePub (137.2 KB)
Consulter à l’aide de différentes applications sur iPhone, iPad, Android ou Windows Phone -
Mobi (Kindle) (140.7 KB)
Consulter sur un appareil Kindle ou à l’aide d’une application Kindle sur plusieurs appareils
Langage exempt de préjugés
Dans le cadre de la documentation associée à ce produit, nous nous efforçons d’utiliser un langage exempt de préjugés. Dans cet ensemble de documents, le langage exempt de discrimination renvoie à une langue qui exclut la discrimination en fonction de l’âge, des handicaps, du genre, de l’appartenance raciale de l’identité ethnique, de l’orientation sexuelle, de la situation socio-économique et de l’intersectionnalité. Des exceptions peuvent s’appliquer dans les documents si le langage est codé en dur dans les interfaces utilisateurs du produit logiciel, si le langage utilisé est basé sur la documentation RFP ou si le langage utilisé provient d’un produit tiers référencé. Découvrez comment Cisco utilise le langage inclusif.
À propos de cette traduction
Cisco a traduit ce document en traduction automatisée vérifiée par une personne dans le cadre d’un service mondial permettant à nos utilisateurs d’obtenir le contenu d’assistance dans leur propre langue. Il convient cependant de noter que même la meilleure traduction automatisée ne sera pas aussi précise que celle fournie par un traducteur professionnel.
Contenu
Introduction
Ce document décrit les modifications apportées à l'architecture Element Manager (EM) dans le cadre de la version 6.3 d'UltraM.
Conditions préalables
Conditions requises
Cisco vous recommande de prendre connaissance des rubriques suivantes :
- STARO
- Architecture de base Ultra-M
Components Used
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Informations générales
Avant la version Ultra 6.3, pour que Ultra Element Manager fonctionne, il fallait créer 3 machines virtuelles UEM. La troisième n'était pas utilisée et était là pour aider à former le cluster ZooKeeper. Depuis la version 6.3, cette conception a changé.
Abréviations
Abréviations utilisées dans cet article :
| VNF | Fonction de réseau virtuel |
| FC | Fonction de contrôle |
| SF | Fonction de service |
| Échap | Contrôleur de service flexible |
| VIM | Gestionnaire d'infrastructure virtuelle |
| VM | Machine virtuelle |
| EM | Gestionnaire d'éléments |
| UAS | Services d’automatisation ultra |
| UUID | Identificateur unique |
| ZK | Zoo |
Ultra Element Manager après la version Ultra 6.3 - Modifications architecturales
Ce document décrit les 5 modifications introduites dans la version 6.3 UltraM :
Nombre d'instances de VM UEM configurables à partir de la version 6.3
Avant la version 6.3, 3 UEM VM étaient obligatoires. Vous pouvez voir qu'avec la liste nova après la source du fichier locataire principal :
[root@POD]# openstack server list --all
+--------------------------------------+-----------------------+--------+--------------------------------------------------------------------+---------------+
| ID | Name | Status | Networks | Image Name |
+--------------------------------------+-----------------------+--------+---------------------------------....
| fae2d54a-96c7-4199-a412-155e6c029082 | vpc-LAASmme-em-3 | ACTIVE | orch=192.168.12.53; mgmt=192.168.11.53 | ultra-em |
| c89a3716-9028-4835-9237-759166b5b7fb | vpc-LAASmme-em-2 | ACTIVE | orch=192.168.12.52; mgmt=192.168.11.52 | ultra-em |
| 5f8cda2c-657a-4ba1-850c-805518e4bc18 | vpc-LAASmme-em-1 | ACTIVE | orch=192.168.12.51; mgmt=192.168.11.51 | ultra-em |
Cet instantané de configuration (à partir du fichier vnf.conf) a été utilisé :
vnfc em
health-check enabled
health-check probe-frequency 10
health-check probe-max-miss 6
health-check retry-count 6
health-check recovery-type restart-then-redeploy
health-check boot-time 300
vdu vdu-id em
number-of-instances 1 --> HERE, this value was previously ignored in pre 6.3 releases
connection-point eth0
...
Quel que soit le nombre d'instances spécifié dans cette commande, le nombre de machines virtuelles filées est toujours égal à 3. En d'autres termes, la valeur nombre d'instances a été ignorée.
À partir de la version 6.3, cette valeur est modifiée - la valeur configurée peut être 2 ou 3.
Lorsque vous configurez 2, les 2 machines virtuelles UEM sont créées.
Lorsque vous configurez 3, les 3 machines virtuelles UEM sont créées.
vnfc em
health-check enabled
health-check probe-frequency 10
health-check probe-max-miss 6
health-check retry-count 3
health-check recovery-type restart
health-check boot-time 300
vdu vdu-id vdu-em
vdu image ultra-em
vdu flavor em-flavor
number-of-instances 2 --> HERE
connection-point eth0
....
Cette configuration aboutirait à 2 machines virtuelles, comme le montre la liste nova.
[root@POD]# openstack server list --all
+--------------------------------------+-----------------------+--------+--------------------------------------------------------------------+---------------+
| ID | Name | Status | Networks | Image Name |
+--------------------------------------+-----------------------+--------+---------------------------------....
| fae2d54a-96c7-4199-a412-155e6c029082 | vpc-LAASmme-em-3 | ACTIVE | orch=192.168.12.53; mgmt=192.168.11.53 | ultra-em |
| c89a3716-9028-4835-9237-759166b5b7fb | vpc-LAASmme-em-2 | ACTIVE | orch=192.168.12.52; mgmt=192.168.11.52 | ultra-em |
Notez cependant que 3 adresses IP sont restées identiques. Autrement dit, dans la partie EM de la configuration (fichier vnf.conf), les 3 adresses IP sont toujours obligatoires :
vnfc em
health-check enabled
health-check probe-frequency 10
health-check probe-max-miss 6
health-check retry-count 3
health-check recovery-type restart
health-check boot-time 300
vdu vdu-id vdu-em
vdu image ultra-em
vdu flavor em-flavor
number-of-instances 2 ---> NOTE NUMBER OF INSTANCES is 2
connection-point eth0
virtual-link service-vl orch
virtual-link fixed-ip 172.x.y.51 --> IP #1
!
virtual-link fixed-ip 172.x.y.52 --> IP #2
!
virtual-link fixed-ip 172.x.y.53 --> IP #3
!
Ceci est nécessaire pour que ZK fonctionne 3 instances de ZK sont requises. Chaque instance nécessite une adresse IP. Même si la 3ème instance n'est pas utilisée efficacement, la 3ème IP est attribuée à la 3ème instance ZK Arbiter (voir Diff.2 pour plus d'explications).
Quel effet cela a-t-il sur le réseau d'orchestration ?
Il y aura toujours 3 ports créés dans le réseau d'orchestration (pour lier les 3 adresses IP mentionnées).
[root@POD# neutron port-list | grep -em_
| 02d6f499-b060-469a-b691-ef51ed047d8c | vpc-LAASmme-em_vpc-LA_0_70de6820-9a86-4569-b069-46f89b9e2856 | fa:16:3e:a4:9a:49 | {"subnet_id": "bf5dea3d-cd2f-4503-a32d-5345486d66dc", "ip_address": "192.168.12.52"} |
| 0edcb464-cd7a-44bb-b6d6-07688a6c130d | vpc-LAASmme-em_vpc-LA_0_2694b73a-412b-4103-aac2-4be2c284932c | fa:16:3e:80:eb:2f | {"subnet_id": "bf5dea3d-cd2f-4503-a32d-5345486d66dc", "ip_address": "192.168.12.51"} |
| 9123f1a8-b3ea-4198-9ea3-1f89f45dfe74 | vpc-LAASmme-em_vpc-LA_0_49ada683-a5ce-4166-aeb5-3316fe1427ea | fa:16:3e:5c:17:d6 | {"subnet_id": "bf5dea3d-cd2f-4503-a32d-5345486d66dc", "ip_address": "192.168.12.53"} |
Distribution ZooKeeper
Avant la version 6.3, ZK était utilisé pour former le cluster. Cette condition est donc requise pour la troisième machine virtuelle.
Cette exigence n'a pas changé. Cependant, pour les configurations où deux machines virtuelles UEM sont utilisées, une troisième instance ZK est hébergée sur le même ensemble de machines virtuelles :
Avant 6.3 et après 6.3 dans une configuration avec 3 machines virtuelles UEM :
UEM VM1 : hébergement de l'instance ZK 1
UEM VM2 : hébergement de l'instance ZK 2
UEM VM3 : hébergement de l'instance ZK 3
Dans la version 6.3 et ultérieure où 2 machines virtuelles uniquement :
UEM VM1 : hébergement des instances Zk 1 et Zk 3
UEM VM2 : hébergement de l'instance ZK 2
UEM VM3 : inexistant
Voir l'image 1. au bas de cet article pour une représentation graphique détaillée.
Useful Zk commands:
To see Zk mode (leader/follower):
/opt/cisco/usp/packages/zookeeper/current/bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/cisco/usp/packages/zookeeper/current/bin/../conf/zoo.cfg
Mode: leader
To check if Zk is running:
echo stat | nc IP_ADDRESS 2181
How to find the Ip address of Zk instance:
Run 'ip addr' from EM
In the /opt/cisco/em/config/ip.txt there are all the 3IP's
From vnf.conf file
From 'nova list' look for orchestration IP
For 2 EM's the arbiter IP can be found also in /opt/cisco/em/config/proxy-params.txt
How to check status of the Zk instance:
echo stat | nc 192.168.12.51 2181 | grep Mode
Mode: follower
You can run this command from one Zk for all other Zk instances (even they are on different VM)!
To connect to the Zk cli - now must use the IP (rather then localhost earlier):
/opt/cisco/usp/packages/zookeeper/current/bin/zkCli.sh -server:2181 Some useful command you can run once you connect to ZkCli:
You can use same command to connect to other Zk instances (even they are on different VM)!
ls /config/vdus/control-function
ls /config/element-manager
ls /
ls /log
ls /stat
get /config/vdus/session-function/BOOTxx
Introduction de Keepalived pour HA
Avec les versions précédentes, le cadre de sélection du leader ZK a été utilisé pour déterminer le maître EM. Ce n'est plus le cas depuis que Cisco a adopté la structure de gestion.
Qu'est-ce qui est conservé et comment cela fonctionne ?
Keeplaived est un logiciel basé sur Linux utilisé pour l'équilibrage de charge et la haute disponibilité du système Linux et de l'infrastructure basée sur Linux.
Il est déjà utilisé dans ESC pour HA.
Dans EM, Keepalived est utilisé pour découpler le NCS de l'état du cluster Zk.
Le processus conservé ne s'exécute que sur les deux premières instances du module EM et déterminerait l'état principal du processus NCS.
To check if the keepalived process is running:
ps -aef | grep keepalived
(must return the process ID)
Pourquoi changer ?
Lors d'une implémentation antérieure, la sélection du noeud maître (NCS/SCM) était étroitement intégrée à l'état du cluster Zk (la première instance à verrouiller la base de données /em dans Zk a été élue maître). Cela crée des problèmes lorsque Zk perd la connectivité avec le cluster.
Keepalived est utilisé pour gérer le cluster UEM actif/veille sur la base des machines virtuelles.
NCS gère les données de configuration.
Zookeeper conserve les données opérationnelles.
Découper SCM du processus NCS
Dans les versions antérieures à la version 6.3, le composant SCM a été intégré à NCS. Cela signifie que lorsque le NCS a démarré, le SCM a également démarré (en conséquence). Dans cette version, il s'agit maintenant d'un processus découplé et SCM est un processus distinct pour lui-même.
Commands to check the NCS and SCM services & processes.
To be executed from the ubuntu command line
ps -aef | grep ncs
ps -aef | grep scm
sudo service show ncs
sudo service scm status
Le service EM s'exécute sur le noeud maître uniquement
Avant la version 6.3, les services UEM s'exécutent à la fois sur Master/Slave. À partir de la version 6.3, les services s'exécutent uniquement sur le noeud maître. Cela aurait un impact sur le résultat affiché dans show ems. À partir de la version 6.3, un seul noeud (maître) devrait apparaître avec cette commande, une fois connecté à l'interface de ligne de commande UEM :
root@vpc-em-2:/var/log# sudo -i
root@vpc-em-2:~# ncs_cli -u admin -C
admin connected from 127.0.0.1 using console on vpc-LAASmme-em-2
admin@scm# show ems
EM VNFM
ID SLA SCM PROXY VERSION
------------------------------
52 UP UP UP 6.3.0 ===> HERE Only one EM instance is seen. In previous releases you were able to see 2 instances.
En fait, tous les services s'exécutent sur le noeud maître, à l'exception du NCS, et cela est dû aux exigences de NCS.
Cette image présente le résumé des services possibles et de la distribution des machines virtuelles pour Ultra Element Manager
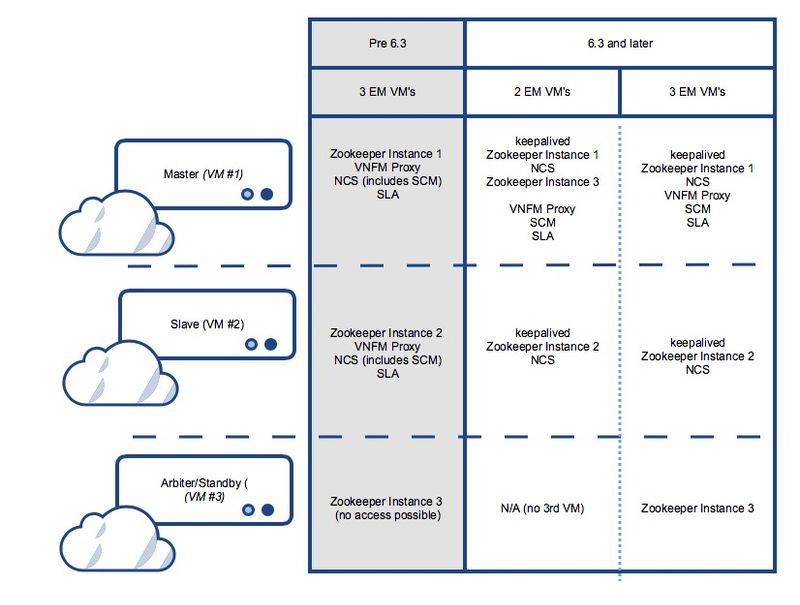
Étapes de dépannage des problèmes liés à Element Manager
Au démarrage, il s'agit de la séquence de démarrage :
Configuration UEM avec 2 machines virtuelles - Séquence de démarrage du processus et emplacement du journal
UEM maître :
- conservé
- Zookeeper
- NCS
- Arbiter (3rd) instance de Zookeeper
- VNFM-Proxy
- SCM
- SLA
UEM esclave :
- conservé
- Zookeeper
- NCS
Configuration UEM avec 3 machines virtuelles - Séquence de démarrage du processus et emplacement du journal
UEM maître :
- conservé
- Zookeeper
- NCS
- VNFM-Proxy
- SCM
- SLA
UEM esclave :
- conservé
- Zookeeper
- NCS
3e UEM :
- Zookeeper
Résumé des processus UEM
Il s'agit du résumé des processus UEM que vous devez exécuter.
Vous vérifiez l'état avec ps -aef | grep xx
| conservé |
| arbiter |
| scm |
| sla |
| zoo.cfg |
| ncs |
Vous pouvez vérifier l'état avec l'état du service xx, où xx :
| zookeeper-arbiter |
| proxy |
| scm |
| sla |
| zk |
| ncs |
Contribution d’experts de Cisco
- Snezana MitrovicCIsco TAC Engineer
- Sourav Jyoti DasCIsco TAC Engineer
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)