Présentation et dépannage des délais Astro/Lemans/NiceR sur les commutateurs des gammes Catalyst 4000/4500
Contenu
Introduction
La gamme de commutateurs Catalyst 4000/4500 utilise une conception ASIC d'extrémité dans l'architecture du commutateur. Le commutateur gère ces circuits ASIC de stub de carte de ligne (Astro/Leman/NiceR) via le protocole de contrôle de gestion interne. Lorsque ces requêtes et réponses de gestion interne sont perdues ou retardées, des messages de console et Syslog sont générés. Étant donné que les raisons de ces pertes de communication varient, la cause première n'est pas évidente avec ces messages d'erreur.
L'objectif de ce document est d'aider à comprendre le message Astro/Leman/Nicer Timeout généré sur la plate-forme Cat4000 et de les résoudre avec l'aide du TAC Cisco. Les versions futures de CatOS et de Cisco IOS® offriront des messages d'erreur améliorés et, si possible, identifieront la cause première du problème.
Lorsque le délai d'attente ASIC de stub (Astro/Lemans/Nicer) se produit, les messages similaires à ceux suivants sont signalés sur un commutateur Catalyst 4000/4500 basé sur CatOS :
%SYS-4-P2_WARN: 1/Astro(4/3) - timeout occurred %SYS-4-P2_WARN: 1/Astro(4/3) - timeout is persisting
Veuillez noter que selon les versions du logiciel, le libellé du message d'erreur peut varier. Astro, Lemans et Nicer font référence à différents types de stub ASIC. Plus de détails sont décrits dans la section Théorie générale de ce document.
Pour les superviseurs Cisco IOS (Supervisor II+, III et IV), le message d'erreur apparaît comme suit :
%C4K_LINECARDMGMTPROTOCOL-4-INITIALTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - management request timed out. %C4K_LINECARDMGMTPROTOCOL-4-ONGOINGTIMEOUTWARNING: Astro 5-2(Fa5/9-16) - consecutive management requests timed out.
Remarque : Ce document traite principalement du dépannage sur les superviseurs ou commutateurs basés sur CatOS. Certaines informations s'appliquent au superviseur basé sur Cisco IOS lorsqu'elles sont indiquées.
Note : Ce document traite également de l'ASIC de stub Astro, mais la plupart des sections s'appliquent à d'autres types de cartes de ligne ASIC de stub (Lemans et Nicer) et, à ce titre, seront indiquées dans les sections appropriées.
Après avoir lu ce document, le lecteur comprendra ce qui suit :
-
Fonction des circuits ASIC de stub dans le Catalyst 4000/4500.
-
Les conditions qui peuvent conduire aux messages d'expiration des paquets de gestion interne.
-
Les étapes à suivre et les commandes à collecter pour le TAC Cisco lors du dépannage de cette condition.
Les sections Délai d’attente et dépannage d’Astro fournissent un arrière-plan et des explications détaillées sur chaque problème. Vous pouvez également accéder directement à la section Simple Ways to Troubleshoot de ce document.
Avant de commencer
Conventions
Pour plus d'informations sur les conventions des documents, référez-vous aux Conventions utilisées pour les conseils techniques de Cisco.
Conditions préalables
Aucune condition préalable spécifique n'est requise pour ce document.
Components Used
Ce document est spécifique au superviseur ou aux cartes de ligne Catalyst 4000/4500 à l'aide de circuits ASIC stub.
Théorie générale
L'ASIC de stub d'astronomie fait référence aux ASIC de stub 10/100 contrôlent un groupe de huit ports 10/100 adjacents communiquant au superviseur via une connexion de bande passante Gigabit au fond de panier, comme illustré ci-dessous.
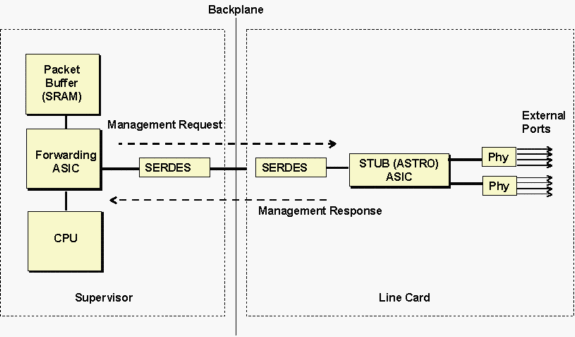
Les superviseurs communiquent avec l'ASIC d'extrémité de carte de ligne via le composant SERDES (SERealizer-DESerializer). Un composant SERDES se connecte au fond de panier du côté superviseur et un autre SERDES se connecte à la carte de ligne pour chaque ASIC d'extrémité pour se connecter au fond de panier.
Le schéma ci-dessus peut être utilisé en général pour dépanner différents types de cartes de ligne. L'ASIC de stub mentionné dans les messages d'expiration sera différent selon le type de carte de ligne. Voir le tableau ci-dessous pour une liste des noms ASIC et leur description.
| ASIC stub | Description | Exemple |
|---|---|---|
| Astro | ASIC de stub contrôleur 8 ports 10/100 | WS-X4148-RJ45V |
| NiceR | ASIC de stub contrôleur 1000 4 ports | WS-X4418-GB(ports 3-18) |
| Citron | ASIC de stub contrôleur 8 ports 10/100/1000 | WS-X4448-GB-RJ |
Le trafic de gestion interne transite à la fois par le composant SERDES et par le trafic de données normal. Le trafic de gestion interne est utilisé pour lire/écrire les registres ASIC et Phy stub. Les opérations les plus courantes incluent la lecture de l'état et des statistiques des liaisons.
Dépannage simple
Les sections suivantes expliquent la signification et les causes possibles de %SYS-4-P2_WARN : 1/(Stub)(module_number/) Stub_reference - message d'erreur de délai d'attente sur le Catalyst 4000/4500.
Les messages de délai d'attente Astro (stub) ont été ajoutés à la version du logiciel à partir des versions 6.2.3 et 6.3.1 et ultérieures, améliorés dans la version 6.4.4 (CSCea73908) pour indiquer que Supervisor a perdu des paquets de contrôle de gestion interne lors de la communication au stub Astro ASIC sur une carte de ligne 10/1000. Cette perte de communication est due à plusieurs causes, comme expliqué en détail dans la section Dépannage ci-dessous.
L'organigramme de dépannage suivant présente un moyen simple et rapide d'isoler le problème entre les causes possibles :
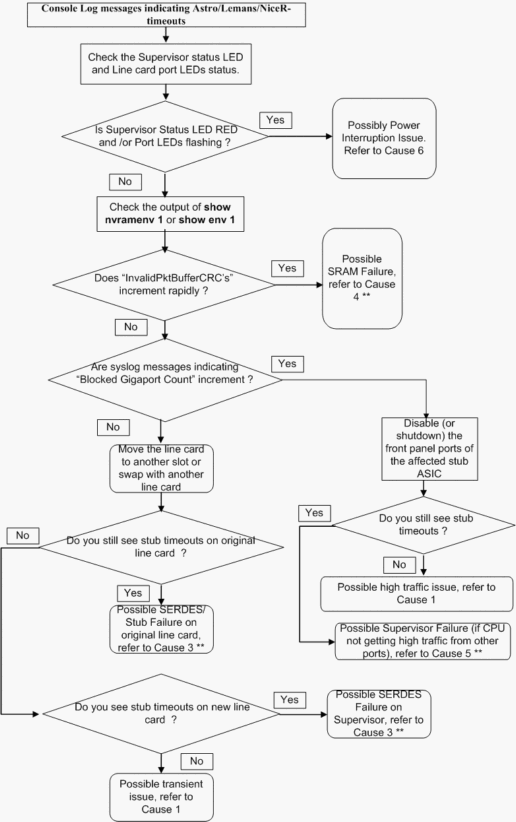
** Diverses causes premières peuvent présenter des symptômes similaires. Contactez le TAC pour obtenir de plus amples informations sur le dépannage.
Délais ASIC du stub (Astro/Lemans/NiceR)
Les délais d'attente Astro/Lemans/Nicer sont signalés lorsque le logiciel Supervisor ne reçoit pas plusieurs réponses de gestion interne de l'ASIC de stub de carte de ligne. Cela peut se produire si :
-
Demande de gestion perdue ou retardée
-
Réponse de la direction perdue ou retardée
Un délai d'attente “ s'est produit.. ” message est imprimé lorsque le logiciel a expiré 10 fois de suite en attendant la réponse du paquet de gestion. Les délais d'attente qui en résultent se traduisent par l'impression “ gestion consécutive ... ” ou “..délai persistant.. ” , selon la version du logiciel.
Ce message de journal est limité à une fois toutes les 10 minutes. Le transfert de paquets vers les circuits ASIC de stub affectés se poursuit lorsque les délais d'attente se produisent. Cependant, les modifications apportées à la liaison / vitesse automatique / duplex ne sont pas vues car le logiciel ne reçoit pas les réponses de paquets de gestion. En outre, le processus de mise à jour des statistiques de trafic pour le groupe d'interfaces est affecté en cas de dépassement de délai.
Dépannage
Les messages de temporisation Astro/Lemans/Nicer apparaissent pour différentes raisons. Chacune est décrite ci-dessous.
Cause 1 : Charge de trafic élevée, boucle de couche 2 ou trafic réseau excessif vers CPU
Les éléments suivants peuvent entraîner des conditions de délai d'attente d'extrémité :
-
Problèmes de réseau
-
Problèmes de configuration
-
Éléments voisins
-
Autres facteurs en dehors d'un commutateur Catalyst
Une boucle ou une tempête de diffusion de couche 2 qui entraîne une charge de trafic élevée peut entraîner la perte de paquets de contrôle de gestion interne. Cela se produit généralement parce que le processeur est occupé (bogue CPU) et ne peut pas traiter ses files d'attente.
Le trafic de contrôle de gestion interne emprunte le même chemin de données vers le superviseur que le trafic de données normal provenant de l'Astro (ou de toute autre puce Stub). Ainsi, les paquets de contrôle peuvent être perdus en raison d'un encombrement.
Avec le correctif pour l'ID de bogue Cisco CSCea73908 (clients enregistrés uniquement) , le délai d'expiration des demandes de gestion interne est mieux géré dans CatOS version 6.4(4) et versions ultérieures. Cette amélioration peut empêcher de nombreux délais d'attente de paquets de contrôle transitoires dus à la charge du processeur.
Action : dépannage de la boucle de couche 2 ; ou modifiez la configuration pour résoudre les modèles de trafic.
Solution de contournement: Déplacez l'interface de gestion du commutateur (sc0) vers le VLAN de trafic non utilisateur sur les commutateurs basés sur CatOS. Utilisez la commande set interface sc0 <vlan-id> pour déplacer le vlan de l’interface sc0.
Remarque : À partir de Cisco IOS 12.1(20)EW, les superviseurs basés sur Cisco IOS améliorent la gestion du mécanisme de gestion interne des paquets par le processeur. Cette amélioration permettra d'éviter la perte de paquets de contrôle de gestion interne en raison d'un trafic de faible priorité inopiné qui monopolise le processeur.
Solution : Voir la solution de contournement ci-dessus.
Cause 2 : Câblage semi-duplex/type 1A
Les ports utilisateur du panneau avant sont configurés en mode bidirectionnel non simultané. Les collisions du trafic sortant avec le trafic entrant au niveau de l'ASIC d'extrémité peuvent entraîner une fuite très lente de la mémoire tampon d'extrémité. Cela peut entraîner le remplissage des files d'attente tx sur le superviseur et l'abandon de nouvelles demandes de gestion interne, ce qui entraînerait des messages d'erreur de délai d'attente.
Un réseau avec un câblage de type 1A peut également causer ce problème. Lorsqu'une station de travail connectée à un commutateur Type1A avec un correctif RJ-45 est déconnectée, le commutateur fait une boucle interne et provoque le retour du trafic sortant. Cette situation simule la connexion d'un bouclage externe sur le port de la façade. Avant que le port ne passe à l'état de blocage, le trafic sortant est bouclé dans le commutateur. Cela peut entraîner un débordement des tampons de stub, selon le débit du trafic.
Action : Voir contournement.
Solution de contournement: Évitez la configuration en mode bidirectionnel non simultané. Dans le cas d’un câblage de type 1A, évitez de brancher le cordon de raccordement RJ-45 du module de secours de type 1A pour éviter de former un bouclage interne dans le module de secours.
Solution : Voir contournement.
Cause 3 : Échec du composant SERDES
Si les erreurs ne sont vues que sur un Astro (ou un autre ASIC de stub) sur un module et qu'aucune boucle de couche 2 n'est détectée, le problème est probablement un composant SERDES défectueux sur le Supervisor ou la carte de ligne. Par exemple, si le message d'erreur se trouve toujours sur Astro 4 sur le module 3 comme indiqué ci-dessous, le composant SERDES sur le module 3 ou le composant SERDES sur le superviseur est défectueux.
%SYS-4-P2_WARN: 1/Astro(3/4) – timeout occurred
Dans le message d'erreur ci-dessus, le numéro « 4 » entre parenthèses fait référence au numéro d'Astro, et non au port réel 3/4. Ce numéro fait référence à un groupe de huit ports (3/33-3/40), car il s’agit du quatrième Astro sur le module 3.
Un composant SERDES défectueux peut provoquer une connectivité intermittente pour le trafic de contrôle et de données vers Astro/Lemans/NiceR, ce qui entraîne des délais d'attente. En règle générale, cependant, le message d'erreur s'affiche en permanence si le SERDES est défectueux.
Action : Afin de déterminer quel SERDES (superviseur ou carte de ligne) est incorrect, procédez comme suit :
-
Déplacez la carte de ligne vers un emplacement de rechange dans le châssis ou un autre châssis. Si un emplacement libre est disponible, remplacez les emplacements par un module de travail connu.
-
Si vous continuez à obtenir des délais d'attente Astro/Lemans/Nicer sur le même Astro/Lemans/Nicer dans le nouveau logement, alors très probablement le SERDES ou l'Astro/Lemans/Nicer sur la carte de ligne a échoué et la carte de ligne doit être remplacée
Remarque : en réinsérant le module dans un logement de rechange, les diagnostics en ligne sont effectués sur la carte de ligne. Si un SERDES ou Astro/Lemans/Nicer défectueux est détecté, le commutateur marquera le port comme défectueux.
-
Si les délais d'attente ne continuent pas à se produire sur la carte de ligne d'origine Astro/Lemans/Nicer, il est possible que le Supervisor SERDES soit défectueux. Pour vérifier cela, insérez un module de travail dont le fonctionnement a été vérifié dans le logement d'origine et vérifiez si les délais d'attente se produisent avec le nouveau module.
Si cela fonctionne, il est possible qu'un SERDES soit sur le superviseur. Reportez-vous à l'avis de champ Perte partielle de connectivité du superviseur Catalyst WS-X4013 pour obtenir la liste des numéros de série affectés avec le composant SERDES défaillant.
Solution de contournement: Aucune
Solution : Contactez le centre d'assistance technique pour plus de dépannage.
Cause 4 : Défaillance de la mémoire SRAM temporaire/matérielle
Les périphériques connectés à un Catalyst 4000 avec un Supervisor I, II ou III ou IV Engine ou Catalyst 2948G, Cat2980G peuvent subir une perte totale ou partielle de connectivité réseau. Certains ou tous les ports peuvent être affectés. Ces symptômes s'accompagneront d'une augmentation rapide des paquets abandonnés CRC non valides sur le superviseur basé sur CatOS et des messages d'erreur de délai d'attente ASIC de stub.
Le problème est dû à une défaillance de la mémoire tampon de paquets (SRAM), qui est un type dur ou transitoire.
Action : Sélectionnez la procédure à suivre en fonction des deux signatures de défaillance de mémoire tampon de paquets transitoires ci-dessous :
-
Signature d'échec de mémoire tampon de paquets transitoire pour SUP I, SUP II, 2948G, 2980G
Voici les symptômes de ce problème :
-
InvalidPktBufferCRC s'incrémente rapidement avec un message similaire à ce qui suit :
%SYS-4-P2_WARN: 1/Invalid crc, dropped packet, count = xxxx
-
Une réinitialisation logicielle à l'aide de la commande reset provoquerait l'échec du POST du superviseur.
-
Si une réinitialisation matérielle (cycle d'alimentation) est effectuée, le superviseur passe l'autotest à la mise sous tension (POST) et ne connaîtra plus de défaillance.
Remarque : En cas de défaillance de la mémoire tampon de paquets pour Supervisor I, II, 2948G, 2980G, une réinitialisation matérielle ne résoudrait pas le problème et le superviseur ou le commutateur échouerait toujours lors de l'autotest à la mise sous tension.
Pour plus d'informations sur ce problème, référez-vous à ID de bogue Cisco CSCdy46288 (clients enregistrés uniquement) pour Supervisor II, ID de bogue Cisco CSCeb56266 (clients enregistrés uniquement) pour Supervisor I/2948G/29880G et ID de80 ID de bogues Cisco CSCeb56325 (clients enregistrés uniquement) pour le WS-C2980G-A.
-
-
Signature de défaillance de mémoire tampon de paquets transitoire pour SUP III, SUP IV
Voici les symptômes de ce problème :
-
Le compteur VlanZeroBadCrc s'incrémente rapidement et s'affiche dans la sortie de commande des éléments suivants :
show platform cpuport all (prior to 12.1(11b)EW1 ) or show platform cpu packet statistics all (Since 12.1(11b)EW1) depending upon the software version. Starting from 12.1(19)EW, you should also see the following error message rapidly incrementing errors: %C4K_SWITCHINGENGINEMAN-2-PACKETMEMORYERROR3: Persistent Errors in Packet Memory xxxx
-
Une réinitialisation logicielle entraîne l'échec du POST du superviseur. Utilisez la commande show diagnostics power-on pour vérifier la défaillance.
-
Une réinitialisation matérielle (cycle d'alimentation) récupère le superviseur et passe l'autotest à la mise sous tension.
Remarque : En cas de défaillance de la mémoire vive dynamique du Supervisor III / IV, une réinitialisation matérielle ne récupérerait pas le Supervisor et échouerait toujours à l'autotest de mise sous tension.
Pour plus d'informations sur ce problème sur Supervisor III/IV, référez-vous à l'ID de bogue Cisco CSCdz57255 (clients enregistrés uniquement)
-
Solution de contournement: Cycle d'alimentation ou réinitialisation matérielle du commutateur en cas de problème SRAM temporaire. Le problème de mémoire SRAM dure n'a pas de solution de contournement.
Solution : Contactez le centre d'assistance technique pour plus de dépannage.
Cause 5 : Échec de l'horloge du superviseur
Si des messages d'erreur de délai d'attente Astro/Lemans/NiceR font référence à plusieurs numéros de module ou à plusieurs Astro/Lemans/Nicer, cela peut indiquer une éventuelle défaillance de l'horloge sur le superviseur. En règle générale, une panne d'horloge est accompagnée du message d'erreur Astro/Lemans/Nicer timeout et des messages d'erreur BlockTXQueue et BlockedGigaport, comme indiqué ci-dessous :
%SYS-4-P2_WARN: 1/Blocked queue on gigaport ...
Action : Contactez le centre d'assistance technique pour obtenir des informations de dépannage supplémentaires concernant l'ID de bogue Cisco CSCdp89537 (clients enregistrés uniquement) et CSCdp93187 (clients enregistrés uniquement).
Solution de contournement: Aucune
Solution : Contactez le centre d'assistance technique pour plus de dépannage.
Cause 6 : Interruption courte de l'alimentation
Un commutateur de la gamme Catalyst 4000 avec un Supervisor II (WS-X4013) peut entrer dans un état dans lequel le Supervisor et les cartes de ligne ne peuvent pas communiquer correctement entre eux. Lorsque le commutateur entre dans cet état, les voyants d'état du module sont rouges (non clignotants) et/ou les voyants du port clignotent dans l'ordre, comme pour un module ou un commutateur réinitialisé. Ce message sera accompagné des messages d'expiration Astro/Lemans/NiceR.
Ce problème est dû à une interruption temporaire de l'alimentation du commutateur (moins de 500 ms). L'interruption temporaire de l'alimentation peut être due à des alimentations instables dans un environnement de production.
Action : Voir la solution de contournement ci-dessous.
Solution de contournement: Réinitialisez (soft ou hard (power-cycle)) le commutateur.
Solution : Passez à l'image logicielle avec le correctif pour l'ID de bogue Cisco CSCea14710 (clients enregistrés uniquement) ou versions ultérieures.
Informations connexes
- Messages d'erreur CatOS courants sur les commutateurs de la gamme Catalyst 4000
- Dépannage matériel des commutateurs Catalyst 4000/4912G/2980G/2948G
- Dépannage du matériel et des problèmes connexes sur Catalyst 4000 et 4500 Supervisor III et IV
- Pages de support des commutateurs de la gamme Catalyst 4000/4500
- Prise en charge de la technologie de commutation LAN
- Support produit pour commutateurs ATM et LAN Catalyst
- Support et documentation techniques - Cisco Systems
 Commentaires
CommentairesContacter Cisco
- Ouvrir un dossier d’assistance

- (Un contrat de service de Cisco est requis)