Introduction
Ce document décrit les étapes impliquées pour restaurer vManage par l'utilisation d'une sauvegarde configuration-db.
Informations générales
Ce document suppose qu'une sauvegarde de la base de données de configuration a été effectuée régulièrement et que, pour une raison quelconque, le vManage autonome est irrécupérable et nécessite une réinitialisation logicielle ou une nouvelle installation.
Ce document vous aide à récupérer toutes les stratégies, les modèles, les configurations et les certificats de périphériques Edge.
Backup Configuration-db
vManage_rcdn01# request nms configuration-db backup path 05_08_20_configdb
Starting backup of configuration-db
config-db backup logs are available in /var/log/nm/neo4j-backup.log file
Successfully saved database to /opt/data/backup/05_08_20_configdb.tar.gz
passez à un serveur externe.
vManage_rcdn01# vshell
vManage_rcdn01:~$ scp /opt/data/backup/05_08_20_configdb.tar.gz user@10.2.3.1://home/ftpuser/ftp/amaugust/
amaugust@10.2.3.1's password:
05_08_20_configdb.tar.gz 100% 484KB 76.6MB/s 00:00
Récupérer vManage
Simulez un sinistre en réinitialisant le vManage à l'aide de la commande suivante :
vManage_rcdn01# request software reset
Maintenant que vous disposez d'un nouveau vManage ressemblant à celui illustré, il est conseillé de suivre le processus de récupération dans l'ordre correct avant de restaurer la sauvegarde.
Étape 1. Configuration minimale sur vManage
system
host-name vManage_rcdn01
system-ip xx.xx.xx.xx
site-id 100
organization-name ****.cisco
vbond vbond.list
!
!
vpn 0
host vbond.list ip 10.2.3.4 10.2.3.5
interface eth0
ip address 10.1.3.8/24
tunnel-interface
no shutdown
!
ip route 0.0.0.0/0 10.1.3.1
!
vpn 512
interface eth1
ip address 10.11.3.8/24
no shutdown
!
ip route 0.0.0.0/0 10.1.3.1
!
Étape 2. Copie de la configuration de sauvegarde et du certificat racine
vManage_rcdn01:~$ scp am****@xx.xx.xx.xx://home/ftpuser/ftp/am****/05_08_20_configdb.tar.gz .
am****@xx.xx.xx.xx's password:
05_08_20_configdb.tar.gz 100% 484KB 76.6MB/s 00:00
Verify
vManage_rcdn01:~$ ls -lh
total 492K
-rw-r--r-- 1 admin admin 394 May 8 15:20 archive_id_rsa.pub
-rwxr-xr-x 1 admin admin 485K May 8 15:3905_08_20_configdb.tar.gz
Copy root certificate from other controller:
vManage_rcdn01:~$ scp admin@vbond://home/admin/root.crt .
viptela 18.4.4
admin@vbond's password:
root.crt 100% 1380 2.8MB/s 00:00
Étape 3. Installation du certificat racine
vManage_rcdn01# request root-cert-chain install /home/admin/root.crt
Uploading root-ca-cert-chain via VPN 0
Copying ... /home/admin/root.crt via VPN 0
Updating the root certificate chain..
Successfully installed the root certificate chain
Étape 4. Mise à jour des informations de base
Accédez aux informations de base relatives à l'IP vBond, au nom de l'organisation et au certificat et configurez-lesAdministration > Settings.
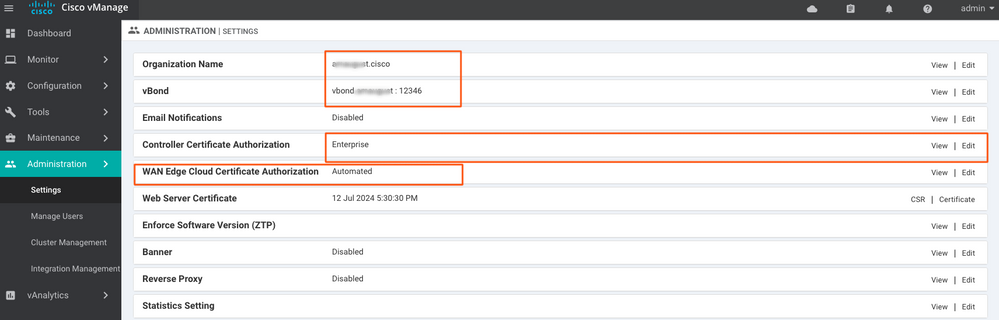
Étape 5. Installation du certificat vManage
Utilisez le root.crt
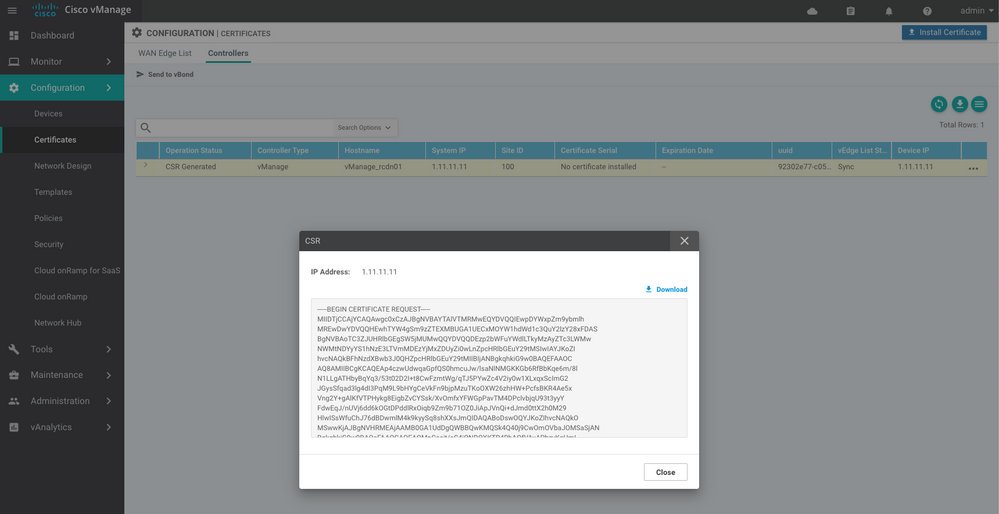
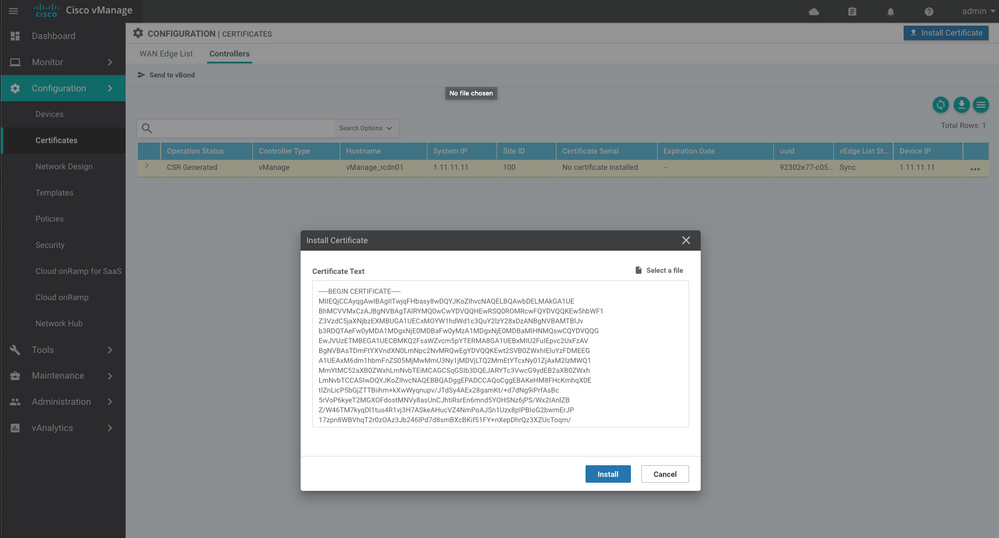
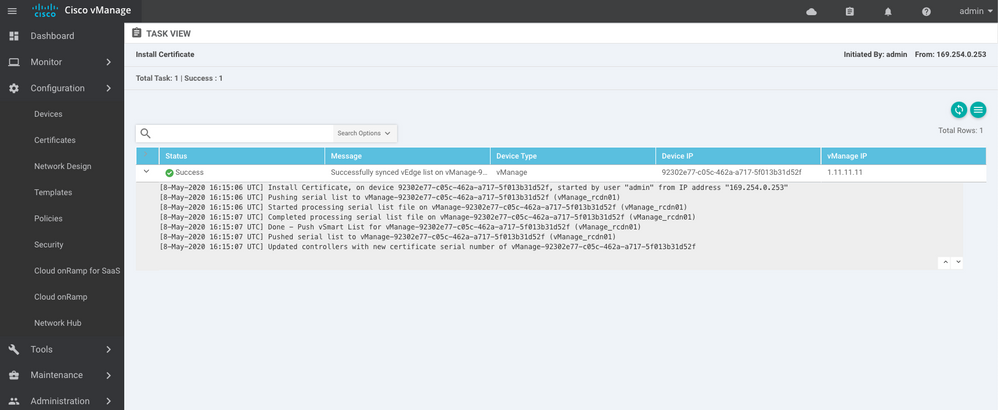
Étape 6. Restauration De La Base De Données
vManage_rcdn01# request nms configuration-db restore path /home/admin/05_08_20_configdb.tar.gz
Configuration database is running in a standalone mode
0 [main] INFO com.viptela.vmanage.server.deployment.cluster.ClusterConfigurationFileHandler - Trying to update existing working copy of server_configs.json file
4 [main] INFO com.viptela.vmanage.server.deployment.cluster.ClusterConfigurationFileHandler - Working copy of server_configs.json NOT updated due to unmodified configs
Successfully saved cluster configuration for localhost
Starting DB backup from: localhost
Creating directory: local
cmd to backup db: sh /usr/bin/vconfd_script_nms_neo4jwrapper.sh backup localhost /opt/data/backup/local 8g
Finished DB backup from: localhost
Stopping NMS application server on localhost
Stopping NMS configuration database on localhost
Reseting NMS configuration database on localhost
Restoring from DB backup: /opt/data/backup/staging/graph.db-backup
cmd to restore db: sh /usr/bin/vconfd_script_nms_neo4jwrapper.sh restore /opt/data/backup/staging/graph.db-backup
Successfully restored DB backup: /opt/data/backup/staging/graph.db-backup
Starting NMS configuration database on localhost
Waiting for 10s before starting other instances...
Polling neo4j at: localhost
NMS configuration database on localhost has started.
Updating DB with the saved cluster configuration data
Successfully reinserted cluster meta information
Starting NMS application-server on localhost
Waiting for 120s for the instance to start...
Removed old database directory: /opt/data/backup/local/graph.db-backup
Successfully restored database
Cette étape prend plus de temps et dépend de la sauvegarde.
Vous pouvez vérifier le processus à l'aidetailingdes journaux sur vShell.
vManage_rcdn01:~$ tail -fq /var/log/nms/vmanage-server.log /var/log/nms/neo4j-out.log
Étape 7. Vérification des services
vManage_rcdn01# request nms all status
Étape 8. Réauthentifier les contrôleurs
Actuellement, vous pouvez constater que toutes les stratégies, modèles et configurations ont été chargés sur vManage, mais que tous les contrôleurs sont hors service.
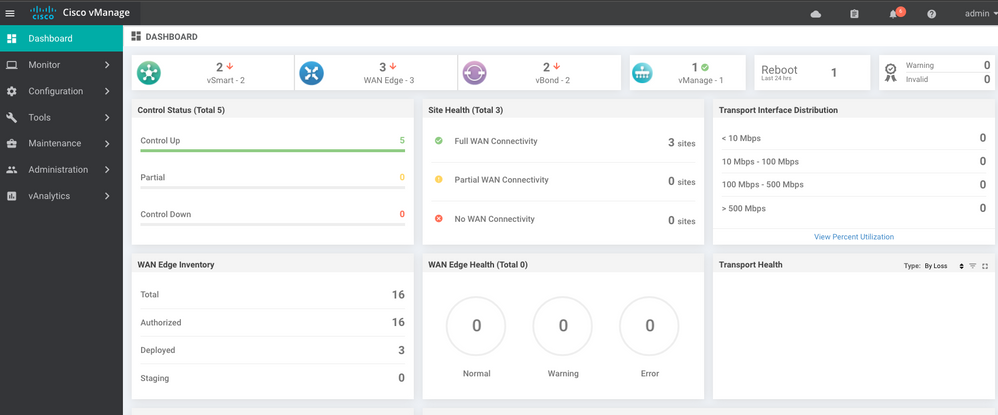
Vous devez authentifier à nouveau tous les contrôleurs.
Accédez àConfiguration > Devices. Modifiez chaque contrôleur et indiquez l'adresse IP de gestion (l'adresse IP de gestion se trouve dans la configuration locale), le nom d'utilisateur et le mot de passe.
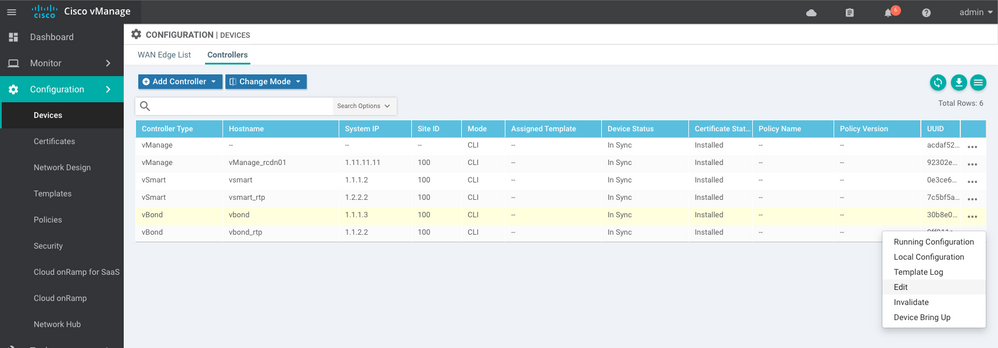
Étape 9. Envoyer les mises à jour aux contrôleurs
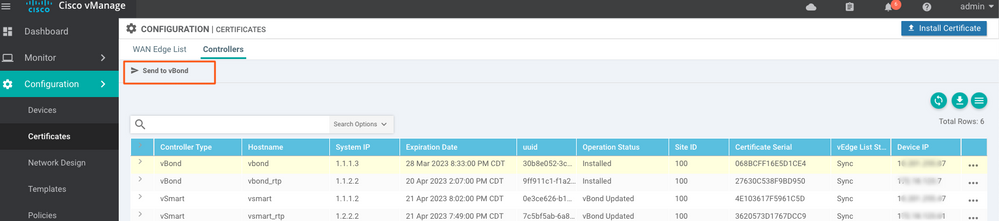
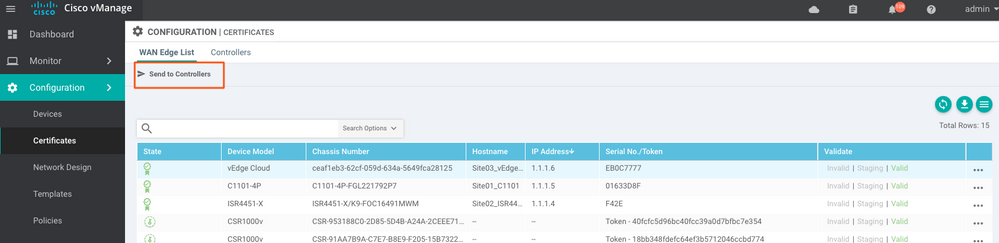
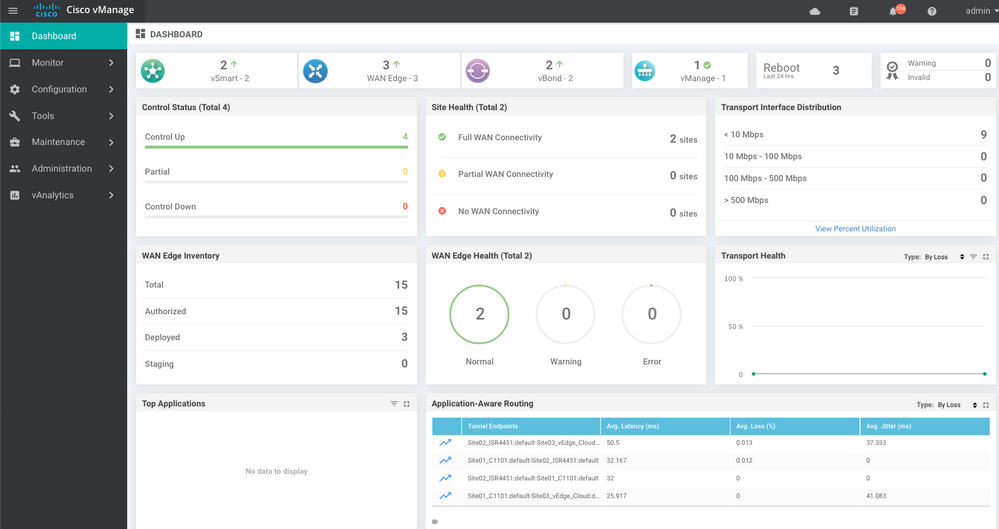
Vous voyez maintenant que tous les périphériques peuvent être gérés par vManage.
 Commentaires
Commentaires