Introduction
Ce document décrit Cisco Express Forwarding (CEF) switching et comment elle est mise en oeuvre dans le routeur Internet de la gamme Cisco 12000.
Conditions préalables
Exigences
Aucune exigence spécifique n'est associée à ce document.
Composants utilisés
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. Si votre réseau est en ligne, assurez-vous de bien comprendre l’incidence possible des commandes.
Conventions
Pour plus d'informations sur les conventions utilisées dans ce document, consultez Conventions relatives aux conseils techniques Cisco.
Aperçu
La commutation CEF (Cisco Express Forwarding) est une forme propriétaire de commutation évolutive destinée à résoudre les problèmes associés à la mise en cache de la demande. Avec la commutation CEF, les informations classiquement stockées dans un cache de route sont réparties sur plusieurs structures de données. Le code CEF est capable de gérer ces structures de données dans le processeur de routage Gigabit (GRP), ainsi que dans les processeurs secondaires tels que les cartes de ligne des routeurs 12000. Les structures de données qui permettent une recherche optimisée pour un transfert efficace des paquets sont les suivantes :
-
La table FIB (Forwarding Information Base) - CEF utilise une FIB pour prendre des décisions de commutation basées sur le préfixe de destination IP. La base de données FIB est conceptuellement similaire à une table de routage ou à une base d’informations. Il conserve une image miroir des informations de transfert contenues dans la table de routage IP. Lorsque des modifications de routage ou de topologie se produisent sur le réseau, la table de routage IP est mise à jour et ces modifications sont reflétées dans la base de données FIB. La table FIB conserve les informations d'adresse de prochain saut selon les informations contenues dans la table de routage IP. Comme il existe une corrélation biunivoque entre les entrées FIB et les entrées de la table de routage, la table FIB contient toutes les routes connues et élimine le besoin de maintenance du cache de route associé aux chemins de commutation tels que la commutation rapide et la commutation optimale.
-
Table de contiguïté : les noeuds du réseau sont dits contigus s’ils peuvent se joindre entre eux par un seul saut sur une couche liaison. Outre la FIB, CEF utilise des tables de contiguïté pour ajouter des informations d’adressage de couche 2. La table de contiguïté conserve les adresses de prochain saut de couche 2 pour toutes les entrées de la table FIB.
CEF peut être activé dans l'un des deux modes suivants :
-
Mode CEF central : lorsque le mode CEF est activé, la FIB CEF et les tables de contiguïté résident sur le processeur de routage, et le processeur de routage effectue le transfert express. Vous pouvez utiliser le mode CEF lorsque les cartes de ligne ne sont pas disponibles pour la commutation CEF ou lorsque vous devez utiliser des fonctionnalités non compatibles avec la commutation CEF distribuée.
-
Mode CEF distribué (dCEF) : lorsque dCEF est activé, les cartes de ligne conservent des copies identiques des tables FIB et de contiguïté. Les cartes de ligne peuvent effectuer le transfert express par elles-mêmes, ce qui évite au processeur principal, le processeur de routage Gigabit (GRP), d'être impliqué dans l'opération de commutation. Il s'agit de la seule méthode de commutation disponible sur les routeurs de la gamme Cisco 12000.
dCEF utilise un mécanisme IPC (Inter-Process Communication) pour assurer la synchronisation des FIB et des tables de contiguïté sur le processeur de routage et les cartes de ligne.
Pour plus d'informations sur la commutation CEF, consultez le livre blanc Cisco Express Forwarding (CEF).
Opérations CEF
Mise à jour des tables de routage GRP
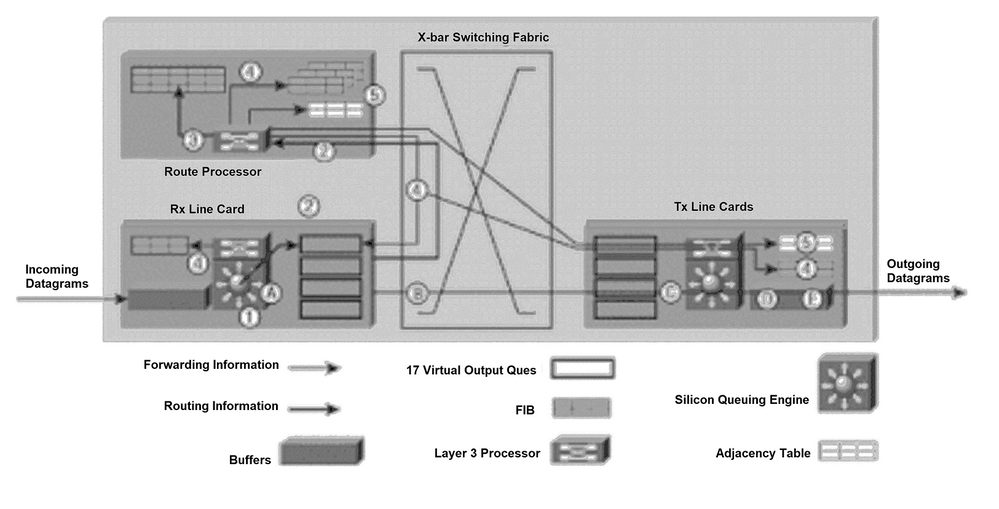
La Figure 1 illustre le processus par lequel un paquet de mise à jour de routage est envoyé au processeur de routage Gigabit (GRP) et les messages de mise à jour de transfert qui en résultent sont envoyés aux tables FIB sur les cartes de ligne.
Par souci de clarté, la numérotation des paragraphes suivants correspond à celle de la figure 1.
Le processus suivant se produit lors de l’initialisation de la table de routage ou à chaque modification de la topologie du réseau (lorsque des routes sont ajoutées, supprimées ou modifiées). Le processus illustré à la Figure 1 comprend cinq étapes principales :
-
Un datagramme IP est placé dans les tampons d'entrée sur la carte de ligne réceptrice (carte de ligne d'entrée), et le moteur de transfert L2/L3 accède aux informations de couche 2 et de couche 3 dans le paquet et les envoie au processeur de transfert. Le processeur de transfert détermine que le paquet contient des informations de routage. Le processeur de transfert envoie le pointeur à la file d'attente de sortie virtuelle (VOQ) du protocole GRP et indique que le paquet dans la mémoire tampon doit être envoyé au protocole GRP.
-
La carte de ligne envoie une requête à la carte d'horloge et d'ordonnancement (CSC). La carte d'ordonnancement émet une autorisation et le paquet est envoyé à travers le fabric de commutation au protocole GRP.
-
Il traite les informations de routage. Le routeur R5000 (processeur) du protocole GRP met à jour la table de routage du réseau. En fonction des informations de routage contenues dans le paquet, le processeur de couche 3 peut être amené à diffuser des informations d’état de liens vers des routeurs adjacents (si le protocole de routage interne est Open Shortest Path First [OSPF]). Le processeur génère les paquets IP qui transportent les informations d'état de liens et la mise à jour interne des tables FIB. En outre, le protocole GRP calcule toutes les routes récursives qui se produisent lorsque la prise en charge est assurée à la fois pour un protocole interne et pour des protocoles de passerelle externe (par exemple, le protocole BGP [Border Gateway Protocol]).
Les informations de route récursive calculées sont envoyées aux FIB sur chaque carte de ligne. Cela accélère considérablement le processus de transfert, car le processeur de couche 3 de la carte de ligne peut se concentrer sur le transfert du paquet et ne calcule pas la route récursive.
-
Le protocole GRP envoie des mises à jour internes aux tables FIB sur toutes les cartes de ligne et inclut celles situées sur le protocole GRP. Les mises à jour FIB des cartes de ligne sont surveillées et limitées si nécessaire. Le protocole GRP dispose d'une copie de chaque table FIB de carte de ligne. Ainsi, si une nouvelle carte de ligne est insérée dans le châssis, le protocole GRP télécharge les dernières informations de transfert vers la nouvelle carte une fois que celle-ci est active.
-
Le protocole GRP est averti, à partir des cartes de ligne, chaque fois qu’un nouveau routeur voisin est connecté au routeur 12000. Le processeur de la carte de ligne envoie un paquet au protocole GRP qui contient les nouvelles informations de couche 2 (généralement les informations d’en-tête PPP). Le protocole GRP utilise ces informations de couche 2 pour mettre à jour la table de contiguïté située sur le protocole GRP et sur les cartes de ligne. Chaque carte de ligne ajoute ces informations de couche 2 à chaque paquet au fur et à mesure qu’il est envoyé à partir du routeur 12000. Une copie de la table de contiguïté est conservée sur le protocole GRP à des fins d'initialisation.
Figure 1 : Détermination du chemin et schéma de commutation de couche 3
 Détermination du chemin et schéma de commutation de couche 3
Détermination du chemin et schéma de commutation de couche 3
Transfert de paquets pour toutes les cartes de ligne sauf OC48 et QOC12
Une fois que les cartes de ligne disposent de suffisamment d’informations de transfert pour déterminer le chemin à travers la matrice de commutation (par exemple, la destination du saut suivant), le routeur 12000 est prêt à transférer des paquets. Les étapes suivantes décrivent la technique de transfert simple et rapide utilisée par le routeur 12000 (voir Figure 1). Par souci de clarté, le lettrage des paragraphes correspond au lettrage de la figure 1.
-
R. Un datagramme IP est placé dans les tampons d’entrée sur la carte de ligne réceptrice (carte de ligne Rx), et le moteur de transfert L2/L3 accède aux informations de couche 2 et de couche 3 dans le paquet et les envoie au processeur de transfert. Le processeur de transfert détermine que le paquet contient des données et n'est pas une mise à jour de routage. Sur la base des informations de couche 2 et de couche 3 dans la table FIB, le processeur de transfert envoie le pointeur à la carte de ligne appropriée VOQ indiquant que le paquet dans la mémoire tampon doit être envoyé à cette carte de ligne.
-
B. Le planificateur d'interfaces de ligne émet une requête vers le planificateur. L'ordonnanceur émet une autorisation et le paquet est envoyé de la mémoire tampon à travers le fabric de commutation à la carte de ligne (carte de ligne Tx).
-
C.La carte de ligne Tx met en mémoire tampon les paquets entrants.
-
D.Le processeur de couche 3 et les circuits ASIC (Application-Specific Integrated Circuit) associés sur la carte de ligne Tx relient les informations de couche 2 (une adresse PPP) à chaque paquet transmis. Le paquet est dupliqué pour chaque port de la carte de ligne (si nécessaire).
-
E.Les émetteurs de la carte de ligne Tx envoient le paquet via l'interface à fibre optique.
L'avantage de ce processus de transfert simple est que la plupart des tâches de transmission de données peuvent être effectuées dans des circuits ASIC et permettent au 12000 de fonctionner à des débits de plusieurs gigabits. En outre, les paquets de données ne sont jamais envoyés au protocole GRP.
Transfert de paquets pour les cartes de ligne OC48 et QOC12
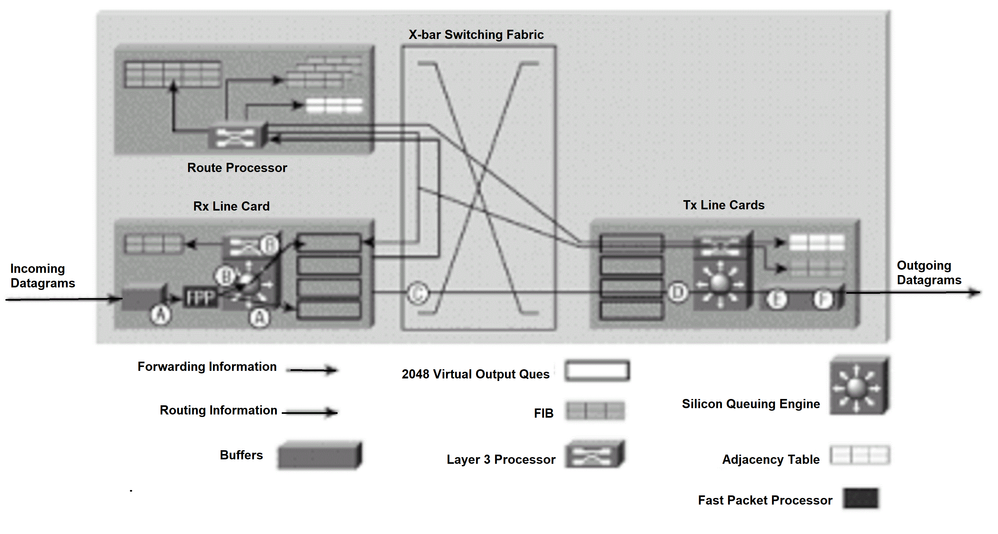
Lorsque les cartes de ligne disposent de suffisamment d’informations de transfert pour déterminer le chemin à travers la matrice de commutation (par exemple, la destination du saut suivant), le routeur 12000 est prêt à transférer des paquets. Les étapes suivantes constituent la technique de transfert simple et ultra-rapide utilisée par le 12000 (voir Figure 2). Par souci de clarté, le lettrage des paragraphes correspond au lettrage de la figure 2.
-
R. Un datagramme IP (pas une mise à jour de routage, le protocole ICMP (Internet Control Message Protocol) et les paquets IP avec options) est reçu dans la carte de ligne et passe par le traitement de couche 2. En fonction des informations de couche 2 et de couche 3 de la table FIB locale, le processeur de paquets rapides détermine la destination du paquet et modifie l’en-tête du paquet. En fonction de la destination, le paquet est ensuite placé dans la carte de ligne VOQ appropriée.
-
B. Dans les rares cas où le processeur de paquets rapides ne peut pas transférer correctement le paquet, le paquet est traité par le processeur de transfert. Le processeur de transfert, en fonction des informations de couche 2 et de couche 3 de sa table FIB locale, envoie le pointeur à la carte de ligne VOQ appropriée, qui indique que le paquet en mémoire tampon doit être envoyé à cette carte de ligne.
-
C. Une fois que le paquet est dans la VOQ appropriée, le planificateur de carte de ligne émet une requête au planificateur. L'ordonnanceur émet une autorisation et le paquet est envoyé de la mémoire tampon à travers le fabric de commutation à la carte de ligne (carte de ligne Tx).
-
D. La carte de ligne Tx met en mémoire tampon les paquets entrants.
-
E. Le processeur de couche 3 et les circuits ASIC associés sur la carte de ligne Tx associent les informations de couche 2 (une adresse PPP) à chaque paquet transmis. Le paquet est dupliqué pour chaque port de la carte de ligne (si nécessaire).
-
F. Les émetteurs de la carte de ligne Tx envoient le paquet sur l’interface à fibre optique.
L'avantage du nouveau processus de transfert est qu'il optimise la carte spécifiquement pour des vitesses plus rapides, comme l'OC48/STM16.
Figure 2 : Commutation de paquets pour des cartes de ligne plus rapides
 Commutation de paquets pour des cartes de ligne plus rapides
Commutation de paquets pour des cartes de ligne plus rapides
Informations connexes
 Commentaires
Commentaires