Causes courantes de connexions IntraVLAN et InterVLAN lentes dans les réseaux campus commutés
Contenu
Introduction
Ce document aborde la plupart des problèmes courants qui peuvent contribuer à la lenteur de réseau. Le document classifie les symptômes communs de lenteur de réseau, et aborde les approches au diagnostic et à la résolution de problème.
Conditions préalables
Conditions requises
Aucune spécification déterminée n'est requise pour ce document.
Components Used
Ce document n'est pas limité à des versions de matériel et de logiciel spécifiques.
Conventions
Pour plus d'informations sur les conventions des documents, référez-vous aux Conventions utilisées pour les conseils techniques de Cisco.
Causes courantes de lenteur de la connectivité intra-VLAN et inter-VLAN
Les symptômes d’une connectivité lente sur un VLAN peuvent être causés par plusieurs facteurs sur différentes couches du réseau. Généralement, le problème de vitesse du réseau peut se produire à un niveau inférieur, mais les symptômes peuvent être observés à un niveau supérieur car le problème se masque sous le terme « VLAN lent ». Pour clarifier les choses, ce document définit les nouveaux termes suivants : « domaine de collision lente », « domaine de diffusion lente » (en d'autres termes, VLAN lent) et « transfert interVLAN lent ». Ces causes sont définies dans la section Trois catégories de causes, ci-dessous.
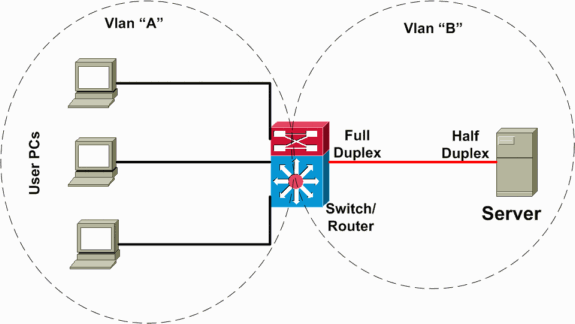
Dans le scénario suivant (illustré dans le schéma de réseau ci-dessous), un commutateur de couche 3 (L3) effectue le routage interVLAN entre les VLAN serveur et client. Dans ce scénario d'échec, un serveur est connecté à un commutateur et le mode duplex du port est configuré en mode bidirectionnel non simultané côté serveur et en mode bidirectionnel simultané côté commutateur. Cette erreur de configuration entraîne une perte et une lenteur de paquets, avec une perte de paquets accrue lorsque des débits de trafic plus élevés se produisent sur la liaison sur laquelle le serveur est connecté. Pour les clients qui communiquent avec ce serveur, le problème ressemble à un transfert interVLAN lent car ils n'ont pas de problème de communication avec d'autres périphériques ou clients sur le même VLAN. Le problème se produit uniquement lors de la communication avec le serveur sur un autre VLAN. Par conséquent, le problème s’est produit sur un seul domaine de collision, mais il est considéré comme un transfert interVLAN lent.
Trois catégories de causes
Les causes de la lenteur peuvent être divisées en trois catégories :
Connectivité de domaine de collision lente
Le domaine de collision est défini comme les périphériques connectés configurés dans une configuration de port semi-duplex, connectés entre eux ou à un concentrateur. Si un périphérique est connecté à un port de commutateur et que le mode bidirectionnel simultané est configuré, une telle connexion point à point est sans collision. La lenteur d'un tel segment peut encore se produire pour différentes raisons.
Connectivité de domaine de diffusion lente (VLAN lent)
La connectivité lente du domaine de diffusion se produit lorsque l’ensemble du VLAN (c’est-à-dire tous les périphériques du même VLAN) connaît une lenteur.
Connectivité inter-VLAN lente (transfert lent entre VLAN)
La connectivité inter-VLAN lente (transmission lente entre VLAN) se produit lorsqu’il n’y a pas de lenteur sur le VLAN local, mais le trafic doit être transféré à un VLAN alternatif, et il n’est pas transféré à la vitesse prévue.
Causes de lenteur du réseau
La perte de paquets
Dans la plupart des cas, un réseau est considéré comme lent lorsque les protocoles de couche supérieure (applications) nécessitent un délai plus long pour mener à bien une opération généralement plus rapide. Cette lenteur est causée par la perte de certains paquets sur le réseau, ce qui provoque l'expiration des protocoles de niveau supérieur tels que TCP ou les applications et le déclenchement de la retransmission.
Problèmes de transfert de matériel
Avec un autre type de lenteur, causée par l’équipement réseau, le transfert (que ce soit la couche 2 [L2] ou la couche 3) est effectué lentement. Ceci est dû à un écart par rapport au fonctionnement normal (conçu) et à une commutation vers un transfert de chemin lent. Par exemple, lorsque la commutation multicouche (MLS) sur le commutateur transfère des paquets de couche 3 entre des VLAN dans le matériel, mais en raison d’une mauvaise configuration, MLS ne fonctionne pas correctement et que le transfert est effectué par le routeur dans le logiciel (ce qui supprime de manière significative le taux de transfert interVLAN).
Dépannage de la cause
Dépannage des problèmes de domaine de collision
Ainsi, si votre VLAN semble lent, commencez par isoler les problèmes de domaine de collision. Vous devez déterminer si seuls les utilisateurs du même domaine de collision rencontrent des problèmes de connectivité ou si cela se produit sur plusieurs domaines. Pour ce faire, effectuez un transfert de données entre des PC utilisateur sur le même domaine de collision, et comparez ces performances aux performances d'un autre domaine de collision, ou à ses performances attendues.
Si des problèmes ne surviennent que sur ce domaine de collision et que les performances des autres domaines de collision dans le même VLAN sont normales, examinez les compteurs de port sur le commutateur pour déterminer les problèmes que ce segment peut rencontrer. Il est probable que la cause est simple, comme une non-correspondance de mode duplex. Une autre cause, moins fréquente, est un segment surchargé ou surabonné. Pour plus d'informations sur le dépannage d'un problème de segment unique, référez-vous au document Configuration et dépannage de la négociation automatique semi-duplex/duplex intégral Ethernet 10/100/1000Mb.
Si les utilisateurs de différents domaines de collision (mais dans le même VLAN) ont les mêmes problèmes de performances, il se peut qu'ils soient toujours dus à une non-correspondance de duplex sur un ou plusieurs segments Ethernet entre la source et la destination. Le scénario suivant se produit souvent : un commutateur est configuré manuellement pour avoir un mode bidirectionnel simultané sur tous les ports du VLAN (le paramètre par défaut est auto), tandis que les utilisateurs (cartes d'interface réseau [NIC]) connectés aux ports effectuent une procédure de négociation automatique. Cela entraîne une non-correspondance du mode duplex sur tous les ports et, par conséquent, de mauvaises performances sur chaque port (domaine de collision). Ainsi, bien qu'il semble que l'ensemble du VLAN (domaine de diffusion) ait un problème de performances, il est toujours classé comme non-correspondance de duplex, pour le domaine de collision de chaque port.
Un autre cas à prendre en compte est un problème particulier de performances de la carte réseau. Si une carte réseau présentant un problème de performances est connectée à un segment partagé, il peut sembler qu'un segment entier connaît une lenteur, en particulier si la carte réseau appartient à un serveur qui dessert également d'autres segments ou VLAN. Gardez ce cas à l'esprit car il peut vous induire en erreur lors du dépannage. Encore une fois, la meilleure façon de réduire ce problème est d'effectuer un transfert de données entre deux hôtes sur le même segment (où la carte réseau avec le problème supposé est connectée), ou si seule la carte réseau est sur ce port, l'isolement n'est pas facile, alors essayez une autre carte réseau dans cet hôte, ou essayez de connecter l'hôte suspect sur un port distinct, en assurant la configuration correcte du port et de la carte réseau.
Si le problème persiste, essayez de dépanner le port du commutateur. Reportez-vous au document Dépannage des problèmes de port et d'interface du commutateur.
Le cas le plus grave est celui où une partie ou la totalité des cartes réseau incompatibles sont connectées à un commutateur Cisco. Dans ce cas, il semble que le commutateur rencontre des problèmes de performances. Pour vérifier la compatibilité des cartes réseau avec les commutateurs Cisco, reportez-vous au document Dépannage des problèmes de compatibilité des commutateurs Cisco Catalyst avec les cartes réseau.
Vous devez faire la distinction entre les deux premiers cas (dépannage de la lenteur du domaine de collision et de VLAN), car ces deux causes impliquent des domaines différents. Avec la lenteur du domaine de collision, le problème se situe à l'extérieur du commutateur (ou sur le bord du commutateur, sur un port de commutateur) ou à l'extérieur du commutateur. Il se peut que le segment seul ait des problèmes (par exemple, un segment surabonné, dépassant la longueur du segment, des problèmes physiques sur le segment ou des problèmes de concentrateur/répéteur). Dans le cas de la lenteur du VLAN, le problème se situe probablement à l’intérieur du commutateur (ou de plusieurs commutateurs). Si vous diagnostiquez le problème de manière incorrecte, vous risquez de perdre du temps à chercher le problème au mauvais endroit.
Donc, après avoir diagnostiqué un cas, vérifiez les éléments ci-dessous.
Dans le cas d'un segment partagé :
-
Déterminer si le segment est surchargé ou sursouscrit
-
déterminer si le segment est sain (y compris si la longueur du câble est correcte, si l’atténuation est conforme à la norme et s’il y a des dommages physiques au support) ;
-
Déterminer si le port réseau et toutes les cartes réseau connectées à un segment ont des paramètres compatibles
-
Déterminer si la carte réseau fonctionne correctement (et exécute le dernier pilote)
-
Déterminer si le port réseau continue à afficher des erreurs croissantes
-
Déterminer si le port réseau est surchargé (en particulier s'il s'agit d'un port serveur)
Dans le cas d'un segment partagé point à point ou d'un segment sans collision (duplex intégral) :
-
Déterminer la configuration du port et de la carte réseau
-
Déterminer l’état du segment
-
Déterminer l’état de la carte réseau
-
rechercher les erreurs de port réseau ou la sursouscription
Dépannage de lenteur IntraVLAN (domaine de diffusion)
Après avoir vérifié qu'il n'y a pas d'incompatibilité de mode duplex ou de problèmes de domaine de collision comme expliqué dans la section ci-dessus, vous pouvez maintenant dépanner la lenteur IntraVLAN. L’étape suivante pour isoler l’emplacement de la lenteur consiste à effectuer un transfert de données entre les hôtes sur le même VLAN (mais sur des ports différents). c’est-à-dire, sur différents domaines de collision), et comparez les performances aux mêmes tests dans d’autres VLAN.
Les VLAN suivants peuvent être lents :
1 Ces trois causes de lenteur de la connectivité intraVLAN ne sont pas couvertes par ce document et peuvent nécessiter un dépannage par un ingénieur du support technique Cisco. Après avoir exclu les cinq premières causes possibles énumérées ci-dessus, vous devrez peut-être ouvrir une demande de service auprès de l'assistance technique Cisco.
Boucle de trafic
Une boucle de trafic est la cause la plus courante d’un VLAN lent. En plus d'une boucle, vous devriez voir d'autres symptômes qui indiquent que vous avez une boucle. Pour le dépannage des boucles STP (Spanning Tree Protocol), référez-vous au document Problèmes de protocole Spanning Tree et considérations de conception associées. Bien que les commutateurs puissants (tels que les commutateurs Cisco Catalyst 6500/6000) avec des fonds de panier compatibles Gigabit puissent gérer certaines boucles (STP) sans compromettre les performances du processeur de gestion, les paquets en boucle peuvent entraîner un débordement des tampons d'entrée sur les cartes réseau et des tampons de réception/transmission (Rx/Tx) sur les commutateurs, ce qui ralentit les performances lors de la connexion à d'autres périphériques.
Un autre exemple de boucle est un EtherChannel configuré de manière asymétrique, comme illustré dans le scénario suivant :
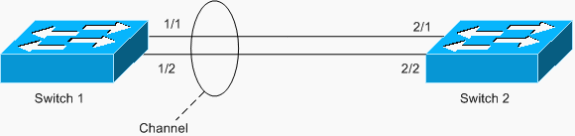
Dans cet exemple, les ports 1/1 et 1/2 sont dans le canal, mais les ports 2/1 et 2/2 ne le sont pas.
Le commutateur 1 a un canal configuré (canal forcé) et le commutateur 2 n'a aucune configuration de canal pour les ports correspondants. Si le trafic inondé (mcast/bcast/unicast inconnu) circule du commutateur 1 vers le commutateur 2, le commutateur 2 le réachemine vers le canal. Il ne s'agit pas d'une boucle complète, car le trafic n'est pas bouclé en continu, mais ne se reflète qu'une seule fois. C'est la moitié de la boucle totale. Le fait d'avoir deux erreurs de configuration peut créer une boucle complète, comme illustré dans l'exemple ci-dessous.
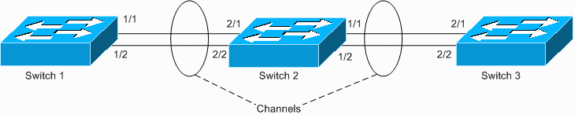
Le risque d'une telle mauvaise configuration est que les adresses MAC sont apprises sur des ports incorrects car le trafic est commuté de manière incorrecte, ce qui entraîne la perte de paquets. Prenons l’exemple d’un routeur avec le protocole HSRP (Hot Standby Router Protocol) actif connecté au commutateur Switch1 (comme illustré dans le schéma ci-dessus). Une fois que le routeur diffuse des paquets, son adresse MAC est bouclée par le commutateur 2 et apprise du canal par le commutateur 1, jusqu’à ce qu’un paquet de monodiffusion soit envoyé de nouveau par le routeur.
VLAN surchargé ou surabonné
Notez que des goulots d'étranglement (segments surabonnés) se trouvent sur vos VLAN et localisez-les. Le premier signe que votre VLAN est surchargé est si les tampons Rx ou Tx sur un port sont surabonnés. Si vous voyez des sorties ou des absences sur certains ports, vérifiez si ces ports sont surchargés. (Une augmentation des caractères indiscard ne signifie pas seulement une mémoire tampon Rx complète.) Dans Catalyst OS (CatOS), les commandes utiles à émettre sont show mac mod/port ou show top [N]. Dans le logiciel Cisco IOS® (natif), vous pouvez exécuter la commande show interfaces slot#/port# counters errors pour afficher les rejets. Le scénario VLAN surchargé ou surabonné et le scénario de boucle de trafic s'accompagnent souvent, mais ils peuvent également exister séparément.
Le plus souvent, la surcharge se produit sur les ports de backbone lorsque la bande passante agrégée du trafic est sous-estimée. La meilleure façon de contourner ce problème est de configurer un EtherChannel entre les périphériques pour lesquels les ports sont bloqués. Si le segment de réseau est déjà un canal, ajoutez d'autres ports dans un groupe de canaux pour augmenter la capacité du canal.
Sachez également que le problème de polarisation de Cisco Express Forwarding (CEF) se pose. Ce problème se produit sur les réseaux dans lesquels le trafic est équilibré en charge par les routeurs, mais en raison de l'uniformité des algorithmes de Cisco Express Forwarding, tout le trafic est polarisé et, au prochain saut, il n'est pas équilibré en charge. Cependant, ce problème ne se produit pas souvent, car il nécessite une certaine topologie avec des liaisons L3 équilibrées par la charge. Pour plus d'informations sur Cisco Express Forwarding et l'équilibrage de charge, consultez Dépannage du routage IP de monodiffusion impliquant CEF sur les commutateurs de la gamme Catalyst 6500/6000 avec un Supervisor Engine 2 et exécutant le logiciel système CatOS.
Un autre problème de routage asymétrique est une cause de surcharge du VLAN. Ce type de configuration peut également entraîner une quantité de trafic excessivement élevée inondant vos VLAN. Pour plus d'informations, reportez-vous à la section Cause 1 : Section Routage asymétrique du document Inondation de monodiffusion dans les réseaux de campus commutés.
Parfois, un goulot d'étranglement peut être un périphérique réseau lui-même. Si vous essayez, par exemple, de pomper du trafic de 4 gigabits via le commutateur avec un fond de panier de 3 gigabits, vous finissez par perdre énormément de trafic. La compréhension de l'architecture des commutateurs réseau n'entre pas dans le champ d'application de ce document ; cependant, lorsque vous examinez la capacité d’un commutateur réseau, tenez compte des aspects suivants :
-
capacité du fond de panier
-
problèmes de blocage en tête de ligne
-
architecture de port/commutateur bloquante et non bloquante
Congestion sur le chemin d'accès intrabande du commutateur
L’encombrement sur le chemin intrabande du commutateur peut entraîner une boucle Spanning Tree ou d’autres types d’instabilité sur le réseau. Le port intrabande de tout commutateur Cisco est un port virtuel qui fournit une interface pour le trafic de gestion (trafic tel que Cisco Discovery Protocol et PAgP [Port Aggregation Protocol]) au processeur de gestion. Le port intrabande est considéré comme virtuel car, dans certaines architectures, l'utilisateur ne peut pas le voir et les fonctions intrabande sont combinées avec le fonctionnement normal du port. Par exemple, l'interface SC0 sur les commutateurs de la gamme Catalyst 4000, Catalyst 5000 et Catalyst 6500/6000 (exécutant CatOS) est un sous-ensemble du port intrabande. L'interface SC0 fournit uniquement une pile IP pour le processeur de gestion au sein du VLAN configuré, tandis que le port intrabande fournit l'accès au processeur de gestion pour les unités de données de protocole de pont (BPDU) dans n'importe quel VLAN configuré et pour de nombreux autres protocoles de gestion (tels que Cisco Discovery Protocol, Internet Group Management Protocol [IGMP], Cisco Group Management Protocol et Dynamic Trunking Protocol [DTP]).
Si le port intrabande est surchargé (en raison d'une mauvaise configuration de l'application ou du trafic utilisateur), cela peut entraîner l'instabilité de tous les protocoles pour lesquels la stabilité de l'état du protocole est basée sur des messages réguliers ou « hellos » reçus. Cet état peut entraîner des boucles temporaires, des interruptions et d'autres problèmes, provoquant ce type de lenteur.
Il est difficile de provoquer l'encombrement du port intrabande sur le commutateur, bien que des attaques par déni de service (DoS) malveillantes puissent aboutir. Il n'y a aucun moyen de limiter ou de réduire le trafic sur le port intrabande. Une solution nécessite une intervention et une enquête de la part de l’administrateur du commutateur. En règle générale, les ports intrabande présentent une tolérance élevée en cas de congestion. Il est rare que le port intrabande ne fonctionne pas ou qu'il soit coincé dans la direction Rx ou Tx. Cela impliquerait une panne matérielle grave et affecterait l'ensemble du commutateur. Cette condition est difficile à reconnaître et est généralement diagnostiquée par les ingénieurs du support technique Cisco. Les symptômes sont qu'un commutateur devient soudainement « sourd » et cesse de voir le trafic de contrôle tel que les mises à jour des voisins du protocole CDP. Ceci indique un problème d'inbande Rx. (Toutefois, si un seul voisin du Cisco Discovery Protocol est visible, vous pouvez être certain que l'intrabande fonctionne.) Par conséquent, si tous les commutateurs connectés perdent le protocole Cisco Discovery Protocol d'un seul commutateur (ainsi que tous les autres protocoles de gestion), cela indique des problèmes Tx de l'interface intrabande de ce commutateur.
Utilisation élevée du processeur de gestion des commutateurs
Si un chemin d'accès intrabande est surchargé, il peut entraîner des conditions de CPU élevées pour un commutateur ; et, alors que le processeur traite tout ce trafic inutile, la situation s'aggrave. Si l'utilisation élevée du CPU est causée par un chemin d'accès intrabande surchargé ou un autre problème, elle peut affecter les protocoles de gestion comme décrit dans la section Congestion sur le chemin d'accès intrabande du commutateur, ci-dessus.
En général, considérez le processeur de gestion comme un point vulnérable de tout commutateur. Un commutateur correctement configuré réduit le risque de problèmes causés par une utilisation élevée du CPU.
L'architecture des Supervisor Engine I et II des commutateurs de la gamme Catalyst 4000 est conçue de manière à ce que le processeur de gestion soit impliqué dans la surcharge de commutation. Gardez à l'esprit les points suivants :
-
Le processeur programme une matrice de commutation chaque fois qu'un nouveau chemin (les Supervisor Engine I et II sont basés sur le chemin) entre dans le commutateur. Si un port intrabande est surchargé, tout nouveau chemin est abandonné. Cela entraîne la perte de paquets (suppression silencieuse) et la lenteur des protocoles de couche supérieure lorsque le trafic est commuté entre les ports. (Reportez-vous à la section Congestion sur le chemin d'accès intrabande du commutateur, ci-dessus.)
-
Puisque le processeur effectue partiellement la commutation dans les Supervisor Engine I et II, les conditions élevées du processeur peuvent affecter les capacités de commutation du Catalyst 4000. L'utilisation élevée du CPU sur les Supervisor Engine I et II peut être causée par la surcharge de commutation elle-même.
Les modules Supervisor Engine II+, III et IV de la gamme Catalyst 4500/4000 sont assez tolérants au trafic, mais l'apprentissage des adresses MAC dans le Supervisor Engine basé sur le logiciel Cisco IOS est toujours effectué entièrement dans le logiciel (par le processeur de gestion); il est possible qu'une utilisation élevée du processeur affecte ce processus et entraîne une lenteur. Comme avec Supervisor Engine I et II, l'apprentissage ou le réapprentissage massif des adresses MAC peut entraîner une utilisation élevée du CPU sur Supervisor Engine II+, III et IV.
Le processeur est également impliqué dans l'apprentissage MAC dans les commutateurs des gammes Catalyst 3500XL et 2900XL, de sorte qu'un processus qui entraîne un réapprentissage rapide des adresses affecte les performances du processeur.
En outre, le processus d’apprentissage des adresses MAC (même s’il est entièrement implémenté dans le matériel) est relativement lent, comparé à un processus de commutation. Si le taux de réapprentissage des adresses MAC est élevé en permanence, la cause doit être trouvée et éliminée. Une boucle Spanning Tree sur le réseau peut entraîner le réapprentissage de ce type d’adresse MAC. Le réapprentissage d'adresses MAC (ou le battement d'adresses MAC) peut également être causé par des commutateurs tiers qui implémentent des VLAN basés sur des ports, ce qui signifie que les adresses MAC ne sont pas associées à une balise VLAN. Ce type de commutateur, lorsqu'il est connecté aux commutateurs Cisco dans certaines configurations, peut entraîner une fuite MAC entre les VLAN. À son tour, cela peut entraîner un taux élevé de réapprentissage des adresses MAC et peut affecter les performances.
Erreurs en entrée sur un commutateur cut-through
La propagation des paquets d'erreur d'entrée coupée est liée à la connectivité du domaine de collision lente, mais comme les paquets d'erreur sont transférés à un autre segment, le problème semble être la commutation entre les segments. Les commutateurs cut-through (tels que les routeurs de commutation de campus de la gamme Catalyst 8500 et le module de commutation Catalyst 2948G-L3 ou L3 pour la gamme Catalyst 4000) commencent la commutation de paquets/trames dès que le commutateur dispose des informations nécessaires pour lire l’en-tête L2/L3 du paquet pour transférer le paquet à son port de destination ports. Ainsi, pendant que le paquet est commuté entre les ports d'entrée et de sortie, le début du paquet est déjà transféré hors du port de sortie, tandis que le reste du paquet est toujours reçu par le port d'entrée. Que se passe-t-il si le segment d'entrée n'est pas sain et génère une erreur CRC (Cyclique Redundancy Check) ou une panne ? Le commutateur le reconnaît uniquement lorsqu’il reçoit la fin de la trame et, à ce moment-là, la majeure partie de la trame est transférée hors du port de sortie. Comme il n'est pas logique de transférer le reste de la trame erronée, le reste est abandonné, le port de sortie incrémente l'erreur de « sous-exécution » et le port d'entrée incrémente le compteur d'erreurs correspondant. Si plusieurs ports d'entrée ne sont pas sains et que leur serveur réside sur le port de sortie, il apparaît que le segment de serveur rencontre le problème, même s'il ne l'est pas.
Pour les commutateurs L3 cut-through, vérifiez les sous-exécutions et, lorsque vous les voyez, vérifiez que tous les ports d'entrée contiennent des erreurs.
Erreur de configuration logicielle ou matérielle
Une mauvaise configuration peut entraîner une lenteur d’un VLAN. Ces effets négatifs peuvent résulter d’un VLAN surabonné ou surchargé, mais le plus souvent, ils résultent d’une conception incorrecte ou de configurations négligées. Par exemple, un segment (VLAN) peut être facilement submergé par le trafic de multidiffusion (par exemple, le flux vidéo ou audio) si les techniques de limitation du trafic de multidiffusion ne sont pas correctement configurées sur ce VLAN. Un tel trafic de multidiffusion peut affecter le transfert de données, entraînant une perte de paquets sur un VLAN entier pour tous les utilisateurs (et inondant les segments des utilisateurs qui n'avaient pas l'intention de recevoir les flux de multidiffusion).
Bogues logiciels et problèmes matériels
Les bogues logiciels et les problèmes matériels sont difficiles à identifier car ils provoquent des déviations, ce qui est difficile à dépanner. Si vous pensez que le problème est causé par un bogue logiciel ou un problème matériel, contactez les ingénieurs du support technique Cisco pour qu'ils examinent le problème.
Dépannage de la lenteur de la connectivité interVLAN
Avant de dépanner une connectivité interVLAN lente (entre VLAN), examinez et éliminez les problèmes abordés dans les sections Dépannage des problèmes de domaine de collision et Dépannage de lenteur intraVLAN (domaine de diffusion) de ce document.
La plupart du temps, la lenteur de la connectivité interVLAN est due à une mauvaise configuration de l'utilisateur. Par exemple, si vous avez mal configuré MLS ou MMLS (Multicast Multilayer Switching), le transfert de paquets est effectué par le processeur du routeur, qui est un chemin lent. Pour éviter les erreurs de configuration et résoudre efficacement les problèmes si nécessaire, vous devez comprendre le mécanisme utilisé par votre périphérique de transfert L3. Dans la plupart des cas, le mécanisme de transfert de couche 3 est basé sur une compilation des tables de routage et ARP (Address Resolution Protocol) et la programmation extrait les informations de transfert de paquets dans le matériel (raccourcis). Toute défaillance du processus de programmation des raccourcis entraîne soit le transfert de paquets logiciels (chemin lent), le transfert incorrect (transfert vers un port incorrect), soit le blocage noir du trafic.
Généralement, une défaillance de programmation de raccourcis ou la création de raccourcis incomplets (qui peuvent également conduire à la transmission de paquets logiciels, à la transmission erronée ou à la rétention de trafic noir) est le résultat d'un bogue logiciel. Si vous pensez que c'est le cas, demandez aux ingénieurs du support technique de Cisco d'enquêter. Parmi les autres raisons de la lenteur du transfert interVLAN figurent les dysfonctionnements matériels, mais ces causes ne sont pas comprises dans ce document. Les dysfonctionnements matériels empêchent simplement la création de raccourcis dans le matériel et, par conséquent, le trafic peut prendre un chemin lent (logiciel) ou être creusé en noir. Les dysfonctionnements matériels doivent également être gérés par les ingénieurs du support technique Cisco.
Si vous êtes sûr que l'équipement est correctement configuré, mais que la commutation matérielle n'a pas lieu, un bogue logiciel ou un dysfonctionnement matériel peut être la cause. Cependant, soyez conscient des capacités des périphériques avant de tirer cette conclusion.
Voici les deux situations les plus fréquentes dans lesquelles le transfert de matériel peut cesser ou ne pas avoir lieu :
-
La mémoire qui stocke les raccourcis est épuisée. Une fois la mémoire saturée, le logiciel cesse généralement la création de raccourcis supplémentaires. (Par exemple, MLS, qu'il s'agisse de NetFlow ou de Cisco Express Forwarding, devient inactif une fois qu'il n'y a plus de place pour de nouveaux raccourcis et qu'il passe au logiciel [chemin lent].)
-
L'équipement n'est pas conçu pour effectuer la commutation matérielle, mais ce n'est pas évident. Par exemple, les Supervisor Engine III et les versions ultérieures de la gamme Catalyst 4000 sont conçus pour transmettre uniquement le trafic IP matériel ; tous les autres types de trafic sont des logiciels traités par le processeur. Un autre exemple est la configuration d'une liste de contrôle d'accès (ACL) qui nécessite une intervention de l'UC (par exemple, avec l'option « log »). Le trafic qui s'applique à cette règle est traité par le processeur dans le logiciel.
Les erreurs d'entrée sur un commutateur cut-through peuvent également contribuer à la lenteur du routage entre VLAN. Les commutateurs Cut-through utilisent les mêmes principes architecturaux pour transférer le trafic de couche 3 et de couche 2, de sorte que les méthodes de dépannage fournies dans la section Dépannage de lenteur IntraVLAN (domaine de diffusion), ci-dessus, peuvent également être appliquées au trafic de couche 2.
Un autre type de configuration erronée qui affecte le routage entre réseaux locaux virtuels est une mauvaise configuration sur les périphériques des utilisateurs finaux (tels que le PC et les imprimantes). Une situation courante est un PC mal configuré ; par exemple, une passerelle par défaut n'est pas configurée correctement, la table ARP du PC n'est pas valide ou le client IGMP n'est pas fonctionnel. Un cas courant est lorsqu’il existe plusieurs routeurs ou périphériques compatibles avec le routage, et que certains ou tous les PC de l’utilisateur final sont mal configurés pour utiliser la mauvaise passerelle par défaut. Ceci peut être le cas le plus problématique, car tous les périphériques réseau sont configurés et fonctionnent correctement, mais les périphériques de l'utilisateur final ne les utilisent pas en raison de cette mauvaise configuration.
Si un périphérique du réseau est un routeur normal qui ne possède aucun type d'accélération matérielle (et ne participe pas à NetFlow MLS), le taux de transfert du trafic dépend entièrement de la vitesse du processeur et de l'occupation de celui-ci. Une utilisation élevée du CPU affecte définitivement le taux de transfert. Sur les commutateurs de couche 3, cependant, les conditions de CPU élevées n'affectent pas nécessairement le débit de transfert ; une utilisation élevée du CPU affecte la capacité du CPU à créer (programmer) un raccourci matériel. Si le raccourci est déjà installé dans le matériel, alors même si le CPU est fortement utilisé, le trafic (pour le raccourci programmé) est commuté dans le matériel jusqu'à ce que le raccourci soit dépassé (s'il y a un compteur d'expiration) ou supprimé par le CPU. Cependant, si un routeur est configuré pour n'importe quel type d'accélération logicielle (comme la commutation rapide ou la commutation Cisco Express Forwarding), le transfert de paquets peut être affecté par des raccourcis logiciels ; si un raccourci est rompu ou si le mécanisme lui-même est défaillant, alors au lieu d'accélérer le débit de transfert, le trafic est acheminé vers le processeur, ce qui ralentit le débit de transfert des données.
Informations connexes
- Dépannage de la commutation multicouche IP
- Dépannage de routage IP monodiffusion impliquant CEF sur commutateur Catalyst 6500/6000 sous CatOS avec un Supervisor Engine 2
- Configuration du routage entre réseaux locaux virtuels (InterVLAN) avec les commutateurs de la gamme Catalyst 3550
- Support pour commutateurs
- Prise en charge de la technologie de commutation LAN
- Support et documentation techniques - Cisco Systems
 Commentaires
Commentaires