Conception de réseaux de stub à grande échelle avec ODR
Contenu
Introduction
Le routage à la demande (ODR) est une amélioration du protocole CDP (Cisco Discovery Protocol), un protocole utilisé pour détecter d'autres périphériques Cisco sur des supports de diffusion ou non. À l’aide du protocole CDP, il est possible de trouver le type de périphérique, l’adresse IP, la version Cisco IOS® exécutée sur le périphérique Cisco voisin, les fonctionnalités du périphérique voisin, etc. Dans la version 11.2 du logiciel Cisco IOS, ODR a été ajouté au protocole CDP pour annoncer le préfixe IP connecté d’un routeur d’extrémité via le protocole CDP. Cette fonctionnalité prend cinq octets supplémentaires pour chaque réseau ou sous-réseau, quatre octets pour l'adresse IP et un octet pour annoncer le masque de sous-réseau avec l'adresse IP. Le routeur ODR peut transporter des informations VLSM (Variable Length Subnet Mask).
Le routeur ODR a été conçu pour les clients de détail d'entreprise qui ne veulent pas utiliser la bande passante de leur réseau pour les mises à jour de protocole de routage. Dans un environnement X.25, par exemple, il est souvent très coûteux d’exécuter un protocole de routage sur cette liaison. Le routage statique est un bon choix, mais il y a trop de surcharge pour gérer manuellement les routes statiques. Le routage ODR n'est pas gourmand en CPU et il est utilisé pour propager les routes IP dynamiquement sur la couche 2.
Le routeur ODR n'est pas un protocole de routage et ne doit pas être traité comme tel lors de sa configuration. Les configurations traditionnelles pour différents protocoles de routage IP ne fonctionneront pas dans l'ODR, car l'ODR utilise le protocole CDP sur la couche 2. Pour configurer le routeur désigné de sauvegarde, utilisez la commande router odr sur le routeur concentrateur. La conception, la mise en oeuvre et l'interaction du routage en ligne avec d'autres protocoles de routage IP peuvent être difficiles.
Le routage ODR ne s'exécute pas sur les routeurs de la gamme Cisco 700 ni sur les liaisons ATM, à l'exception de l'émulation LAN (LANE).
Réseaux d'extrémité et réseaux de transit
Lorsqu’aucune information ne transite par le réseau, il s’agit d’un réseau d’extrémité. La topologie en étoile est un bon exemple de réseau d’extrémité. Les grandes entreprises disposant de nombreux sites connectés à un data center utilisent ce type de topologie.
Les routeurs bas de gamme tels que les routeurs Cisco 2500, 1600 et 1000 sont utilisés côté rayon. Si des informations passent par des routeurs en étoile pour accéder à un autre réseau, ce routeur d’extrémité devient un routeur de transit. Cette configuration se produit lorsqu'un rayon est connecté à un autre routeur en dehors du routeur concentrateur.
Une préoccupation commune est de savoir quelle taille d'une mise à jour ODR un rayon peut envoyer. Normalement, les rayons sont connectés uniquement à un concentrateur. Si les rayons sont connectés à d’autres routeurs, ils ne sont plus des stubs et deviennent un réseau de transit. Les boîtiers bas de gamme ont généralement une ou deux interfaces LAN. Par exemple, le Cisco 2500 peut prendre en charge deux interfaces LAN. Dans des situations normales, un paquet de 10 octets est envoyé (dans le cas où il y a deux réseaux locaux du côté satellite) dans le cadre du protocole CDP. Le protocole CDP est activé par défaut, il n'y a donc aucun problème de surcharge supplémentaire. Il n'y aura jamais de situation dans laquelle il y a une mise à jour importante de l'ODR. La taille des mises à jour ODR ne sera pas un problème dans un véritable environnement en étoile.
Réseaux Hub and Spoke et ODR
Un réseau en étoile est un réseau classique où un concentrateur (routeur haut de gamme) dessert de nombreux rayons (routeurs bas de gamme). Dans certains cas, il peut y avoir plusieurs concentrateurs, soit à des fins de redondance, soit pour prendre en charge des rayons supplémentaires via un concentrateur distinct. Dans ce cas, activez le routage en attente sur les deux concentrateurs. Il est également nécessaire d’avoir un protocole de routage pour échanger des informations de routage ODR entre les deux concentrateurs.
Figure 1 : Topologie Hub and Spoke 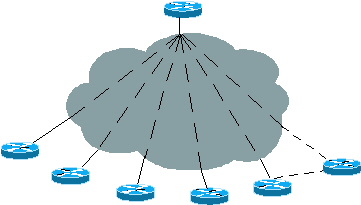
Rayons avec un point de sortie unique
Dans la Figure 1 ci-dessus, les rayons sont connectés à un concentrateur afin de pouvoir compter sur la passerelle par défaut au lieu de recevoir toutes les informations de routage du concentrateur avec un point de sortie. Il n'est pas nécessaire de transmettre toutes les informations aux rayons, car un rayon n'aura pas à prendre de décision de routage intelligente. Un rayon envoie toujours le trafic au concentrateur, de sorte que les rayons n'ont besoin que d'une route par défaut pointant vers un concentrateur.
Il doit y avoir un moyen pour que les informations de sous-réseau du rayon soient envoyées au concentrateur. Avant Cisco IOS 11.2, la seule façon d'y parvenir était d'activer un protocole de routage en étoile. Cependant, avec l’ODR, les protocoles de routage n’ont pas besoin d’être activés du côté satellite. Avec l'ODR, seul Cisco IOS 11.2 et une route statique par défaut pointant vers un concentrateur sont nécessaires sur le rayon.
Rayons avec plusieurs points de sortie
Un rayon peut avoir plusieurs connexions au concentrateur à des fins de redondance ou de sauvegarde en cas de défaillance de la liaison principale. Un concentrateur distinct est souvent requis pour cette redondance. Dans ce cas, les rayons ont plusieurs points de sortie. Le routage ODR fonctionne également bien dans ce réseau.
Les rayons doivent être point à point, sinon la route statique flottante par défaut ne fonctionnera pas. Dans une configuration multipoint, il n’y a aucun moyen de détecter une défaillance du tronçon suivant, tout comme dans un média de diffusion.
Équilibrage de charge ou sauvegarde avec un seul concentrateur
Pour réaliser l'équilibrage de charge, définissez deux routes statiques par défaut sur les rayons ayant la même distance et le rayon effectue l'équilibrage de charge entre ces deux chemins. S'il existe deux chemins vers la destination, le routeur de secours conserve les deux routes dans la table de routage et effectue l'équilibrage de charge sur le concentrateur.
Pour les sauvegardes, définissez deux routes statiques par défaut avec une distance supérieure à l'une de l'autre. Le rayon utilise la liaison principale et, lorsque la liaison principale tombe en panne, la route statique flottante fonctionne. Dans le routeur concentrateur, utilisez la commande distance pour chaque adresse de voisin CDP et améliorez une distance par rapport à l’autre. Avec cette configuration, les routes ODR apprises via une liaison seront préférées à l'autre. Cette configuration est utile dans un environnement où il existe des liaisons principales rapides et des liaisons de sauvegarde lentes (faible bande passante) et où l'équilibrage de charge n'est pas souhaité.
Remarque : Aujourd'hui, il n'existe aucune autre méthode du côté satellite pour préférer une liaison à l'autre dans une situation de concentrateur unique, sauf comme décrit ci-dessus. Si vous utilisez IOS 12.0.5T ou version ultérieure, le concentrateur envoie automatiquement la route par défaut via les deux liaisons et le rayon ne peut pas distinguer les deux chemins et va les installer dans sa table de routage. La seule façon de préférer une route par défaut à une autre est d'utiliser une route statique par défaut sur le rayon qui a un chemin avec une distance d'administration inférieure pour laquelle vous voulez préférer. Ceci remplace automatiquement les routes par défaut qui arrivent sur les rayons via ODR. Actuellement, l'idée de fournir au rayon un bouton, où il peut préférer un lien par rapport à l'autre, est à l'étude.
Figure 2 : Rayons avec plusieurs points de sortie et un seul concentrateur 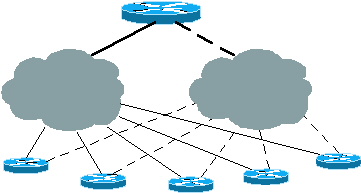
Équilibrage de charge ou sauvegarde avec plusieurs concentrateurs
Ces configurations peuvent également être utilisées pour l'équilibrage de charge ou les sauvegardes lorsqu'il existe plusieurs concentrateurs. Tous les concentrateurs doivent être entièrement maillés de sorte que si l’une des liaisons des rayons échoue, la destination puisse toujours être atteinte via un second concentrateur. Consultez la section Comparaison des protocoles de routage ODR et autres de ce document pour une explication plus détaillée. De même, dans le cas de plusieurs concentrateurs, si IOS 12.0.5T ou version ultérieure est utilisé, les concentrateurs envoient les routes ODR par défaut aux rayons et aux rayons installés à la fois dans la table de routage. Une amélioration future permettra à un rayon de préférer un concentrateur à l'autre. Actuellement, ceci peut être fait par une route statique par défaut définie sur le routeur du rayon et l'utilisation de la distance admin dans la commande static route pour préférer un concentrateur à l'autre. Cela n'affecte pas les situations d'équilibrage de charge.
Figure 3 : Rayons avec plusieurs points de sortie et plusieurs concentrateurs 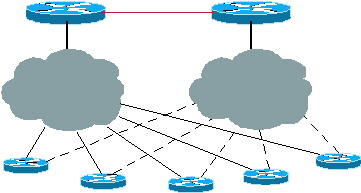
Comparaison entre le routeur désigné de sauvegarde et les autres protocoles de routage
Le principal avantage du routage ODR sur IP est que le routeur concentrateur apprendra les préfixes IP sans activer les protocoles de routage sur la couche 3. Les mises à jour ODR font partie du protocole CDP sur la couche 2.
ODR et EIGRP
Dans un véritable environnement en étoile, il est inutile de transmettre toutes les informations de routage à tous les rayons. Les rayons de liaison lente gaspillent de la bande passante dans les mises à jour de routage et la maintenance des relations de voisinage. En activant le protocole EIGRP (Enhanced Interior Gateway Routing Protocol) sur les rayons, les mises à jour de routage sont envoyées aux rayons. Dans les grands réseaux, ces mises à jour deviennent énormes, gaspillent la bande passante du processeur et peuvent nécessiter plus de mémoire sur les routeurs en étoile.
Une meilleure approche avec le protocole EIGRP consiste à appliquer des filtres au niveau du concentrateur. Les informations de routage sont contrôlées de sorte que les concentrateurs envoient uniquement une route par défaut de manière dynamique aux rayons. Ces filtres permettent de réduire la taille de la table de routage côté satellite, mais si le concentrateur perd un voisin, il envoie des requêtes à tous les autres voisins. Ces requêtes sont inutiles car le concentrateur n'obtiendra jamais de réponse d'un voisin.
La meilleure approche consiste à éliminer la surcharge des requêtes EIGRP et de la maintenance des voisins à l'aide de l'ODR. En ajustant les temporisateurs ODR, le temps de convergence peut être augmenté.
Aujourd'hui, nous avons une nouvelle fonctionnalité dans le protocole EIGRP qui permet une meilleure évolutivité du protocole EIGRP dans une situation de réseau en étoile. Référez-vous à Routage de stub IGRP amélioré pour plus d'informations sur la fonctionnalité de stub EIGRP.
ODR et OSPF
Le protocole OSPF (Open Shortest Path First) offre plusieurs options pour les environnements en étoile, et l'option stub no-summary a la surcharge la plus faible.
Vous pouvez rencontrer des problèmes lors de l'exécution du protocole OSPF sur des réseaux en étoile à grande échelle. Les exemples de cette section utilisent Frame Relay car il s’agit de la topologie en étoile la plus courante.
Réseaux de stub point à point OSPF
Dans cet exemple, OSPF est activé sur 100 rayons connectés par une configuration point à point. Premièrement, il y a beaucoup d'adresses IP gaspillées, même si nous subdivisons avec un masque de réseau /30. Deuxièmement, si nous incluons ces 100 rayons dans une zone et qu'un rayon est bloqué, l'algorithme SPF (Shortest Path First) s'exécute et peut devenir gourmand en CPU. Cette situation est particulièrement vraie pour les routeurs en étoile si la liaison est en effervescence constante. D’autres volets voisins peuvent causer des problèmes en ce qui concerne les routeurs en étoile.
Dans OSPF, la zone est stub et non l'interface. Si un réseau d’extrémité comporte 100 routeurs, il faut plus de mémoire sur les rayons pour conserver la grande base de données. Ce problème peut être résolu en divisant une grande zone de stub en une petite zone. Cependant, un rabat dans une zone de stub déclenchera toujours l'exécution de SPF sur les rayons, de sorte que cette surcharge ne peut pas être guérie en créant une petite zone de stub sans résumé et sans externe.
Une autre option consiste à inclure chaque liaison dans une zone. Avec cette option, le routeur concentrateur devra exécuter un algorithme SPF distinct pour chaque zone et créer une LSA (Link-State Advertisement) récapitulative pour les routes de la zone. Cette option peut nuire aux performances du routeur concentrateur.
La mise à niveau vers une meilleure plate-forme n'est pas une solution permanente ; cependant, le routage en ligne offre une solution. Les routes apprises via l’ODR peuvent être redistribuées dans OSPF pour informer les autres routeurs concentrateurs de ces routes.
Réseaux de stub point à multipoint OSPF
Dans les réseaux point à multipoint, l’espace d’adressage IP est enregistré en plaçant chaque rayon sur le même sous-réseau. En outre, la taille du concentrateur LSA du routeur qui est généré sera réduite de moitié car il ne générera qu’une seule liaison d’extrémité pour toutes les liaisons point à point. Un réseau point à multipoint force l’inclusion de l’ensemble du sous-réseau dans une zone. En cas de battement de liaison, le rayon exécute SPF, qui peut être gourmand en CPU.
La tempête Hello
Les paquets Hello OSPF sont petits, mais s'il y a trop de voisins, leur taille peut devenir importante. Puisque les HELLO sont de la multidiffusion, le routeur traite les paquets. Le concentrateur OSPF envoie et reçoit des paquets Hello composés de 20 octets d'en-tête IP, 24 octets d'en-tête OSPF, 20 octets de paramètres Hello et 4 octets pour chaque voisin vu. Un paquet Hello OSPF provenant d’un concentrateur d’un réseau point à multipoint avec 100 voisins peut devenir long de 464 octets et sera diffusé à tous les rayons toutes les 30 secondes.
Tableau 1 : Paquet Hello OSPF pour 100 voisins| En-tête IP de 20 octets |
| En-tête OSPF de 24 octets |
| Paramètres Hello de 20 octets |
| 4 octets par ID de routeur voisin (RID) |
| . . . |
| . . . |
| . . . |
| . . . |
| . . . |
La surcharge est résolue en mode ODR, car aucune information supplémentaire n'est envoyée du concentrateur aux rayons. Les rayons envoient le préfixe IP de 5 octets par sous-réseau au routeur concentrateur. En considérant la taille du paquet Hello, comparez les 5 octets en ODR (le rayon envoyant les informations d'un sous-réseau connecté) aux 68 octets du protocole OSPF (la plus petite taille de paquet Hello incluant un en-tête IP envoyé du rayon au concentrateur) plus 68 octets (le plus petit paquet Hello envoyé du concentrateur au rayon) au cours d'un intervalle de 30 secondes. En outre, les HELLO OSPF se produisent sur la couche 3 tandis que les mises à jour ODR se produisent sur la couche 2. Avec l'ODR, beaucoup moins d'informations sont envoyées, de sorte que la bande passante de liaison peut être utilisée pour les données importantes.
ODR et RIPv2
Le protocole RIPv2 (Routing Information Protocol version 2) est également un bon choix pour les environnements en étoile. Pour concevoir RIPv2, envoyez la route par défaut du concentrateur aux rayons. Les rayons annoncent ensuite leur interface connectée via le protocole RIP. RIPv2 peut être utilisé lorsque des adresses secondaires sur les rayons doivent être annoncées ou si plusieurs routeurs de fournisseurs sont utilisés ou si la situation n’est pas vraiment un concentrateur et un rayon.
Circuit à demande RIPv2
La version 2 a quelques modifications, mais elle ne change pas le protocole de manière drastique. Cette section décrit quelques améliorations apportées au protocole RIP pour les circuits de demande.
Aujourd'hui, les interréseaux évoluent vers des réseaux commutés ou des sauvegardes de sites principaux pour fournir des connexions à un grand nombre de sites distants. De tels types de connexions peuvent traverser un trafic de données très faible ou nul pendant un fonctionnement normal.
Le comportement périodique du protocole RIP entraîne des problèmes sur ces circuits. Le protocole RIP rencontre des problèmes avec les interfaces point à point à faible bande passante. Les mises à jour sont envoyées toutes les 30 secondes avec de grandes tables de routage qui utilisent une bande passante élevée. Dans ce cas, il est préférable d’utiliser le protocole RIP déclenché.
RIP déclenché
Le protocole RIP déclenché est conçu pour les routeurs qui échangent toutes les informations de routage avec leur voisin. Si des modifications sont apportées au routage, seules les modifications sont propagées au voisin. Le routeur récepteur applique immédiatement les modifications.
Les mises à jour RIP déclenchées sont envoyées uniquement lorsque :
-
Une demande de mise à jour de routage est reçue.
-
De nouvelles informations sont reçues.
-
La destination est passée du circuit descendant au circuit ascendant.
-
Le routeur est d'abord sous tension.
Voici un exemple de configuration pour le protocole RIP déclenché :
Spoke# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
Spoke(config)# int s0.1
Spoke(config-if)# ip rip triggered
Spoke(config)# int s0.2
Spoke(config-if)# ip rip triggered
interface serial 0
encapsulation frame-relay
interface serial 0.1 point /* Primary PVC */
ip address 10.x.x.x 255.255.255.0
ip rip triggered
frame-relay interface-dlci XX
interface serial 0.2 point /* Secondary PVC */
ip address 10.y.y.y 255.255.255.0
ip rip triggered
frame-relay interface-dlci XX
router rip
network 10.0.0.0
Spoke# show ip protocol
Routing Protocol is "rip"
Sending updates every 30 seconds, next due in 23 seconds
Invalid after 180 seconds, hold down 180, flushed after 240
Outgoing update filter list for all interfaces is not set
Incoming update filter list for all interfaces is not set
Redistributing: rip
Default version control: send version 1, receive any version
Interface Send Recv Triggered RIP Key-chain
Ethernet0 1 1 2
Serial0.1 1 1 2 Yes
Serial0.2 1 1 2 Yes
Routing for Networks:
10.0.0.0
Routing Information Sources:
Gateway Distance Last Update
Distance: (default is 120)
La commande ip rip trigger doit être configurée sur l'interface du routeur concentrateur se connectant aux rayons.
Lorsque vous comparez RIPv2 à ODR, l'ODR est un meilleur choix car RIPv2 fonctionne sur la couche 3 et l'ODR se produit sur la couche 2. Lorsque le concentrateur envoie des mises à jour RIPv2 à plus de 1 000 rayons, il doit répliquer le paquet sur la couche 3 pour chaque rayon. Le routeur ODR n'envoie rien depuis le concentrateur, à l'exception de la mise à jour CDP habituelle toutes les minutes sur la couche 2, qui n'est pas du tout gourmande en CPU. L’envoi d’informations de sous-réseau dans la couche 2 à partir du rayon est beaucoup moins gourmand en CPU que l’envoi de RIPv2 sur la couche 3.
Conception de réseau à grande échelle avec ODR
Le routage ODR fonctionne mieux dans un réseau à grande échelle que tout autre protocole de routage. Le principal avantage du routage en ligne est que les protocoles de routage n’ont pas besoin d’être activés sur les liaisons série connectées. Actuellement, aucun protocole de routage ne peut envoyer d’informations de routage sans les activer sur l’interface connectée.
ODR avec EIGRP exécuté sur les concentrateurs
Lors de l'exécution du protocole EIGRP, établissez une connexion d'interface passive au réseau en étoile afin qu'il n'envoie pas les paquets Hello EIGRP inutiles sur la liaison. Dans la mesure du possible, il est préférable de ne pas mettre d’instructions réseau pour les réseaux entre le concentrateur et les rayons, car si la liaison tombe en panne, le protocole EIGRP n’enverra pas de requêtes inutiles aux voisins principaux. Choisissez toujours un faux réseau entre le concentrateur et les rayons afin que ces liaisons ne soient pas incluses dans le domaine EIGRP, car vous ne mettrez pas d'instructions réseau dans les configurations.
Redondance et récapitulation
Dans une situation de concentrateur unique, aucun paramètre supplémentaire n'est requis. Récapitulez les sous-réseaux spécifiques et connectés des rayons et laissez-les s'infiltrer dans le coeur. Cependant, les frais généraux des requêtes seront toujours là. Si des routes spécifiques sont perdues à partir d’un des rayons, envoyez les requêtes à tous les voisins des routeurs principaux.
Dans le cas de plusieurs concentrateurs, il est très important que les deux concentrateurs soient connectés et que le protocole EIGRP fonctionne entre les concentrateurs. Si possible, cette liaison doit être un réseau majeur unique afin qu'il n'interfère pas avec d'autres liaisons allant aux rayons. Cette configuration est nécessaire car le protocole EIGRP ne peut pas être activé sur une interface spécifique. Par conséquent, même si nous rendons l’interface passive, elle sera toujours annoncée via le protocole EIGRP. Si l'interface est résumée, les requêtes sont toujours envoyées en cas de perte d'un rayon. Tant que la liaison entre les deux concentrateurs n’est pas dans le même réseau principal que les rayons, la configuration doit fonctionner correctement.
Figure 4 : Redondance et récapitulation : Le coeur reçoit des routes récapitulatives 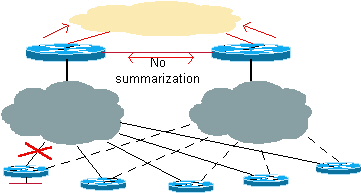
L’un des avantages du protocole EIGRP est qu’il peut résumer au niveau de l’interface, de sorte que la route résumée des sous-réseaux en étoile sera envoyée au coeur et qu’elle enverra une route plus spécifique à l’autre concentrateur. Si la liaison entre un concentrateur et un rayon tombe en panne, il est possible d'atteindre la destination via le second concentrateur.
ODR avec OSPF exécuté sur les concentrateurs
Dans ce scénario, OSPF n’a pas besoin d’être activé sur la liaison reliant les rayons. Dans un scénario normal, si le protocole OSPF est activé sur la liaison, et qu’une liaison spécifique est constamment instable, il peut provoquer plusieurs problèmes, notamment l’exécution du SPF, la régénération de la LSA du routeur, la régénération de la LSA récapitulative, etc. Lors de l'exécution de l'ODR, n'incluez pas la liaison série connectée dans le domaine OSPF. La principale préoccupation est de recevoir les informations du segment LAN des rayons. Ces informations peuvent être obtenues par l'intermédiaire de l'ODR. Si une liaison est constamment instable, elle n’interférera pas avec le protocole de routage du routeur concentrateur.
Redondance et récapitulation
Toutes les liaisons spécifiques peuvent être résumées avant de s'infiltrer dans le coeur de réseau pour éviter le calcul de route si l'une des interfaces connectées d'un rayon tombe en panne. Il ne peut pas être détecté si les informations du routeur principal sont résumées.
Figure 5 : Redondance et récapitulation : Le routeur principal reçoit des routes résumées 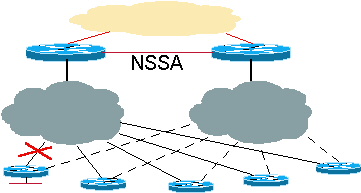
Dans cet exemple, il est très important que les concentrateurs soient connectés entre eux à des fins de redondance. Cette connexion récapitule également les sous-réseaux connectés en étoile avant de s’infiltrer dans le coeur du protocole OSPF.
NSSA avec amélioration future
Il y aura éventuellement une fonctionnalité OSPF Not-So-Stubby Areas (NSSA) qui permettra non seulement de résumer dans le coeur de réseau, mais également des informations plus spécifiques sur le concentrateur via la liaison NSSA. L'avantage de l'exécution de NSSA est que les routes résumées peuvent être envoyées dans le coeur de réseau. Ensuite, le coeur peut envoyer le trafic à l'un ou l'autre des concentrateurs pour atteindre la destination du rayon. Si la liaison entre un concentrateur et un rayon tombe en panne, il y aura une LSA de type 7 plus spécifique dans les deux concentrateurs pour atteindre la destination via un autre concentrateur.
Voici un exemple de configuration utilisant NSSA :
N2507: Hub 1
router odr
timers basic 8 24 0 1
!
router ospf 1
redistribute odr subnets
network 1.0.0.0 0.255.255.255 area 1
area 1 nssa
N2504: Hub 2
router odr
timers basic 8 24 0 1
!
router ospf 1
redistribute odr subnets
network 1.0.0.0 0.255.255.255 area 1
area 1 nssa
N2507# show ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, * - candidate default
U - per-user static route, o - ODR
Gateway of last resort is not set
C 1.0.0.0/8 is directly connected, Serial0
C 2.0.0.0/8 is directly connected, Serial1
3.0.0.0/24 is subnetted, 1 subnets
C 3.3.3.0 is directly connected, Ethernet0
o 150.0.0.0/16 [160/1] via 3.3.3.2, 00:00:23, Ethernet0
o 200.1.1.0/24 [160/1] via 3.3.3.2, 00:00:23, Ethernet0
o 200.1.2.0/24 [160/1] via 3.3.3.2, 00:00:23, Ethernet0
N2504# show ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, * - candidate default
U - per-user static route, o - ODR
Gateway of last resort is not set
C 1.0.0.0/8 is directly connected, Serial0
C 2.0.0.0/8 is directly connected, Serial1
3.0.0.0/24 is subnetted, 1 subnets
C 3.3.4.0 is directly connected, TokenRing0
C 5.0.0.0/8 is directly connected, Loopback0
C 6.0.0.0/8 is directly connected, Loopback1
O N2 150.0.0.0/16 [110/20] via 1.0.0.1, 00:12:06, Serial0
O N2 200.1.1.0/24 [110/20] via 1.0.0.1, 00:12:06, Serial0
O N2 200.1.2.0/24 [110/20] via 1.0.0.1, 00:12:06, Serial0
Récapitulation et amélioration future avec NSSA
Attribuez un bloc contigu de sous-réseaux aux rayons afin que ces sous-réseaux puissent être correctement résumés dans le coeur OSPF, comme indiqué dans l'exemple suivant. Si les sous-réseaux ne sont pas résumés et qu’un sous-réseau connecté tombe en panne, le coeur de réseau entier le détecte et recalcule les routes. En envoyant la route récapitulative pour un bloc contigu, si le sous-réseau en étoile clignote, le coeur ne la détecte pas.
N2504# configure terminal
Enter configuration commands, one per line. End with CNTL/Z.
N2504(config)# router ospf 1
N2504(config-router)# summary-address 200.1.0.0 255.255.0.0
N2504# show ip ospf database external
OSPF Router with ID (6.0.0.1) (Process ID 1)
Type-5 AS External Link States
LS age: 1111
Options: (No TOS-capability, DC)
LS Type: AS External Link
Link State ID: 200.1.0.0 (External Network Number )
Advertising Router: 6.0.0.1
LS Seq Number: 80000001
Checksum: 0x2143
Length: 36
Network Mask: /16
Metric Type: 2 (Larger than any link state path)
TOS: 127
Metric: 16777215
Forward Address: 0.0.0.0
External Route Tag: 0
Problème de distance
Dans cet exemple, des informations plus spécifiques sont reçues des deux concentrateurs. Puisque la distance OSPF est 110 et la distance ODR est 160, les informations interféreront avec ODR lorsqu'elles seront reçues de l'autre concentrateur à propos du même sous-réseau. L’autre concentrateur sera toujours préféré pour atteindre la destination en étoile, ce qui entraînera un routage sous-optimal. Pour remédier à cette situation, diminuez la distance de routage en ligne à moins de 110 avec la commande distance, de sorte que la route de routage en ligne soit toujours préférée à la route OSPF. Si la route ODR échoue, la route externe OSPF sera installée dans la table de routage à partir de la base de données.
N2504(config)# router odr
N2504(config-router)# distance 100
N2504(config-router)# end
N2504# show ip route
Codes: C - connected, S - static, I - IGRP, R - RIP, M - mobile, B - BGP
D - EIGRP, EX - EIGRP external, O - OSPF, IA - OSPF inter area
N1 - OSPF NSSA external type 1, N2 - OSPF NSSA external type 2
E1 - OSPF external type 1, E2 - OSPF external type 2, E - EGP
i - IS-IS, L1 - IS-IS level-1, L2 - IS-IS level-2, * - candidate default
U - per-user static route, o - ODR
Gateway of last resort is not set
C 1.0.0.0/8 is directly connected, Serial0
C 2.0.0.0/8 is directly connected, Serial1
3.0.0.0/24 is subnetted, 1 subnets
C 3.3.4.0 is directly connected, TokenRing0
C 5.0.0.0/8 is directly connected, Loopback0
C 6.0.0.0/8 is directly connected, Loopback1
o 150.0.0.0/16 [100/1] via 3.3.4.1, 00:00:39, TokenRing0
o 200.1.1.0/24 [100/1] via 3.3.4.1, 00:00:39, TokenRing0
o 200.1.2.0/24 [100/1] via 3.3.4.1, 00:00:39, TokenRing0
O 200.1.0.0/16 is a summary, 00:04:38, Null0
Les routes N2 sont toujours dans la base de données et deviendront actives si la liaison principale du concentrateur au rayon tombe en panne.
N2504# show ip ospf database nssa
OSPF Router with ID (6.0.0.1) (Process ID 1)
Type-7 AS External Link States (Area 1)
LS age: 7
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 150.0.0.0 (External Network Number )
Advertising Router: 6.0.0.1
LS Seq Number: 80000002
Checksum: 0x965E
Length: 36
Network Mask: /16
Metric Type: 2 (Larger than any link state path)
TOS: 0
Metric: 20
Forward Address: 1.0.0.2
External Route Tag: 0
Avec l'amélioration de NSSA, la LSA de type 7 plus spécifique sera dans la base de données NSSA. Au lieu d’une route récapitulative, la sortie de la base de données NSSA apparaît comme suit :
LS age: 868
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 200.1.1.0 (External Network Number)
Advertising Router: 3.3.3.1
LS Seq Number: 80000001
Checksum: 0xDFE0
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
TOS: 0
Metric: 20
Forward Address: 1.0.0.1
External Route Tag: 0
LS age: 9
Options: (No TOS-capability, Type 7/5 translation, DC)
LS Type: AS External Link
Link State ID: 200.1.2.0 (External Network Number)
Advertising Router: 3.3.3.1
LS Seq Number: 80000002
Checksum: 0xFDC3
Length: 36
Network Mask: /24
Metric Type: 2 (Larger than any link state path)
TOS: 0
Metric: 20
Forward Address: 1.0.0.2
External Route Tag: 0
Circuit de demande
Le circuit de demande est une fonctionnalité de Cisco IOS 11.2 qui peut également être utilisée dans les réseaux en étoile. Cette fonctionnalité est généralement utile dans les scénarios de sauvegarde commutée et dans les environnements de circuits virtuels commutés X.25 ou Frame Relay. Voici un exemple de configuration d'un circuit de demande :
router ospf 1
network 1.1.1.0 0.0.0.255 area 1
area 1 stub no-summary
interface Serial0 /* Link to the hub router */
ip address 1.1.1.1 255.255.255.0
ip ospf demand-circuit
clockrate 56000
Spoke#show ip o int s0
Serial0 is up, line protocol is up
Internet Address 1.1.1.1/24, Area 1
Process ID 1, Router ID 141.108.4.2, Network Type POINT_TO_POINT, Cost: 64
Configured as demand circuit.
Run as demand circuit.
DoNotAge LSA not allowed (Number of DCbitless LSA is 1).
Transmit Delay is 1 sec, State POINT_TO_POINT,
Timer intervals configured, Hello 10, Dead 40, Wait 40, Retransmit 5
Hello due in 00:00:06
Neighbor Count is 1, Adjacent neighbor count is 1
Adjacent with neighbor 130.2.4.2
Suppress hello for 0 neighbor(s)
L’utilisation de la fonction de circuit de demande dans un réseau en étoile permet d’activer le circuit et de former une nouvelle contiguïté en cas de modification de la topologie. Par exemple, s'il y a un sous-réseau dans un rayon qui clignote, le circuit de demande affiche la contiguïté et diffuse ces informations. Dans un environnement de zone de stub, ces informations seront diffusées dans toute la zone de stub. L'ODR résout ce problème en ne divulguant pas ces informations aux autres rayons. Référez-vous à Fonctionnalité de circuit de demande OSPF pour plus d'informations.
ODR avec réseaux point à point
L'état actuel de Cisco IOS 12.0 sur les limites du bloc de descripteurs d'interface (IDB) est le suivant :
| Routeur | Limite |
|---|---|
| 1000 | 300 |
| 2600 | 300 |
| 3600 | 800 |
| 4 x 00 | 300 |
| 5200 | 300 |
| 5300 | 700 |
| 5800 | 3000 |
| 7200 | 3000 |
| RSP | 1000 |
Avant IOS 12.0, le nombre maximal de rayons qu'un concentrateur pouvait prendre en charge était de 300 en raison des limites de l'IDB. Si un réseau nécessitait plus de 300 rayons, la configuration point à point n'était pas un bon choix. En outre, un paquet CDP distinct a été généré pour chaque liaison. La complexité du temps d’envoi des mises à jour CDP sur les liaisons point à point est n2. Le tableau ci-dessus nous donne les limites de la BID pour différentes plates-formes. Le nombre maximal de rayons pris en charge sur chaque plate-forme varie, mais la surcharge liée à la création d’un paquet CDP distinct pour chaque liaison reste un problème. Par conséquent, dans une situation de réseau en étoile, la configuration d’une interface point à multipoint est une meilleure solution qu’une interface point à point.
ODR avec réseaux point à multipoint
Dans un réseau point à multipoint où un concentrateur prend en charge plusieurs rayons, trois problèmes majeurs se posent :
-
Le concentrateur peut facilement prendre en charge plus de 300 rayons. Par exemple, un réseau 10.10.0.0/22 pourrait prendre en charge 1024-2 rayons avec une interface multipoint.
-
Dans un environnement multipoint, un paquet CDP est généré pour tous les voisins et répliqué sur la couche 2. La complexité de la mise à jour CDP est réduite à n.
-
Dans une configuration point à multipoint, vous ne pouvez affecter qu'un seul sous-réseau à tous les rayons.
ODR et plusieurs fournisseurs
L'une des idées fausses les plus répandues est que l'ODR ne fonctionnera pas si plusieurs fournisseurs sont utilisés. Le routage ODR fonctionne tant que le réseau est un véritable réseau en étoile. Par exemple, s'il y a 100 rayons et deux rayons sont des routeurs d'un autre fournisseur, il est alors possible d'activer un protocole de routage sur ces liaisons se connectant aux différents routeurs et d'exécuter ODR sur les 98 rayons Cisco restants.
Figure 6 : ODR avec plusieurs fournisseurs 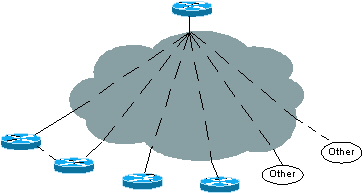
Le routeur concentrateur connecté aux 98 routeurs Cisco reçoit les mises à jour de sous-réseau via le routeur de secours (ODR) et les mises à jour de protocole de routage des deux autres routeurs. Les liaisons connectées aux différents routeurs doivent se trouver sur des sous-réseaux point à point ou point à multipoint distincts.
Problèmes de croissance futurs
Si une organisation exécute ODR sur 100 rayons, elle peut éventuellement vouloir modifier sa topologie à partir d'un réseau en étoile. Par exemple, ils peuvent décider de mettre à niveau un rayon vers une plate-forme plus grande, faisant de ce rayon un concentrateur pour 20 autres rayons.
Figure 7 : Croissance future 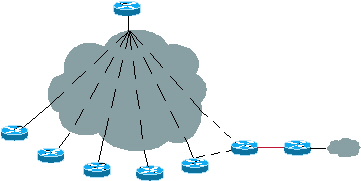
Il est possible d'exécuter un protocole de routage sur le nouveau concentrateur tout en conservant la conception ODR telle quelle. Si le nouveau concentrateur prend en charge au moins 20 nouveaux rayons, le routeur de secours peut s'exécuter sur le nouveau concentrateur. Le nouveau concentrateur peut en apprendre davantage sur ces nouveaux sous-réseaux en étoile par l'intermédiaire du routeur de secours (ODR) et redistribuer ces informations au concentrateur d'origine par l'intermédiaire d'un autre protocole de routage.
Cette situation est similaire lorsque l'ODR commence par deux concentrateurs. Il n'y a pas de surcharge pour changer de protocole. En fait, le routage ODR peut s'exécuter tant que le routeur est un stub.
Performances
Plusieurs paramètres peuvent être ajustés pour une convergence plus rapide et de meilleures performances lors de l'exécution de l'ODR.
Ajustement des compteurs pour une convergence plus rapide
Dans un environnement ODR de grande taille, réglez les compteurs ODR pour une convergence plus rapide et augmentez les compteurs de la mise à jour CDP du concentrateur au rayon afin de minimiser les performances du processeur du concentrateur.
Routeur concentrateur
Le minuteur de mise à jour CDP doit être défini par défaut sur 60 secondes pour réduire la quantité de trafic du concentrateur vers les rayons. La durée de conservation doit être augmentée au maximum (255 secondes). Comme le routeur concentrateur doit gérer trop de tables de contiguïté CDP et, en cas de panne de quelques voisins, ne supprimez pas les entrées CDP de la mémoire pendant 255 secondes (durée de retenue maximale autorisée). Cette configuration donnera de la flexibilité au routeur concentrateur car si le voisin se réactive dans les quatre minutes, il n’est pas nécessaire de recréer la contiguïté CDP. L'ancienne entrée de table peut être utilisée et le compteur de retenue peut être mis à jour.
Voici un exemple de modèle de configuration IP pour un routeur central :
cdp holdtime 255
router odr
timers basic 8 24 0 1 /* odr timer's are update, invalid, hold down, flush
router eigrp 1
network 10.0.0.0
redistribute odr
default-metric 1 1 1 1 1
Il existe trois circuits virtuels permanents (PVC) à partir de chaque site distant (entrepôt, région et dépôt). Deux des circuits virtuels permanents sont reliés à deux routeurs centraux distincts. Le troisième circuit virtuel permanent est acheminé vers un routeur PayPoint. Il est obligatoire que le circuit virtuel permanent vers la route PayPoint soit utilisé pour le trafic destiné au réseau PayPoint. Les deux autres PVC servent de fonctions principales et de sauvegarde pour tout autre trafic. En fonction de ces exigences, reportez-vous au modèle de configuration ci-dessous pour chaque routeur distant.
Il est très important d'ajuster les temporisateurs ODR tels que non valide, mise hors service et vidage pour une convergence plus rapide. Même si CDP n'envoie pas de préfixe IP une fois que le routeur odr est configuré, le compteur de mise à jour ODR doit correspondre au compteur de mise à jour CDP voisin, car le compteur de convergence ne peut être défini que s'il existe un compteur de mise à jour. Ce compteur est différent du compteur CDP et ne peut être utilisé que pour une convergence plus rapide.
Routeur satellite
Puisque les rayons envoient des mises à jour ODR dans des paquets CDP, le compteur des mises à jour CDP doit être maintenu très petit pour une convergence plus rapide. Dans un environnement en étoile réel, il n'y a aucune restriction pour le temps de mise hors service du voisin CDP, car il n'y a que quelques entrées que le rayon doit conserver dans sa table CDP. La durée de retenue maximale de 255 secondes est recommandée, de sorte que si le circuit virtuel permanent du concentrateur tombe en panne et revient dans les quatre minutes, aucune nouvelle contiguïté CDP n'est nécessaire, car l'ancienne entrée de table peut être utilisée.
Voici un exemple de modèle de configuration IP pour un site distant :
cdp timer 8
cdp holdtime 255
interface serial 0
encapsulation frame-relay
cdp enable
interface serial 0.1 point /* Primary PVC */
ip address 10.x.x.x 255.255.255.0
frame-relay interface-dlci XX
interface serial 0.2 point /* Secondary PVC */
ip address 10.y.y.y 255.255.255.0
frame-relay interface-dlci XX
interface bri 0
interface BRI0
description Backup ISDN for frame-relay
ip address 10.c.d.e 255.255.255.0
encapsulation PPP
dialer idle-timeout 240
dialer wait-for-carrier-time 60
dialer map IP 10.x.x.x name ROUTER2 broadcast xxxxxxxxx
ppp authentication chap
dialer-group 1
isdn spid1 xxxxxxx
isdn spid2 xxxxxxx
access-list 101 permit ip 0.0.0.0 255.255.255.255 0.0.0.0 255.255.255.255
dialer-list 1 LIST 101
/* following are the static routes that need to be configured on the remote routers
ip route 0.0.0.0 0.0.0.0 10.x.x.x
ip route 0.0.0.0 0.0.0.0 10.y.y.y
ip route 0.0.0.0 0.0.0.0 bri 0 100
ip classless
Les routes statiques par défaut ne sont pas obligatoires si vous utilisez IOS 12.0.5T ou version ultérieure, car le routeur concentrateur envoie automatiquement la route par défaut vers tous les rayons.
Filtrage et récapitulation des routes ODR
Les routes ODR peuvent être filtrées avant qu'elles ne fuient dans le coeur. Utilisez la commande distribute-list in. Tous les sous-réseaux connectés des rayons doivent être récapitulés lors de fuites dans le coeur. Si le résumé n’est pas possible, les routes inutiles peuvent être filtrées au niveau du routeur concentrateur. Dans plusieurs réseaux concentrateurs, les rayons peuvent annoncer l’interface connectée qui est la liaison vers un autre concentrateur.
Dans ce cas, la commande distribute-list doit être appliquée de sorte que le concentrateur ne place pas ces routes dans la table de routage. Lorsque l'ODR est redistribué dans le concentrateur, ces informations ne sont pas divulguées dans le coeur.
Réglage du temporisateur Telco
Il est important d'ajuster le minuteur de l'opérateur téléphonique pour augmenter le temps de convergence des rayons. Si le circuit virtuel permanent du côté concentrateur tombe en panne, les rayons doivent être en mesure de le détecter rapidement pour passer au second concentrateur.
Performances du processeur
Le processus ODR ne prend pas beaucoup d'utilisation du CPU. L'ODR a été testé pour environ 1 000 voisins avec une utilisation du CPU de 3 à 4 %. Le paramètre de minuteur agressif de l'ODR sur le concentrateur permet une convergence plus rapide. Si les paramètres par défaut sont utilisés, l'utilisation du CPU reste de zéro à un pour cent.
Même avec des temporisateurs ODR et CDP agressifs, le résultat ci-dessous montre qu'il n'y a pas eu d'utilisation élevée du CPU. Ce test a été effectué avec un processeur 150 MHz sur un Cisco 7206.
Hub# show proc cpu
CPU utilization for five seconds: 4%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588036 15783316 734 0.73% 1.74% 1.95% 0 CDP Protocol
.
.
48 3864 5736 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 3%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588484 15783850 734 2.21% 1.83% 1.96% 0 CDP Protocol
.
.
48 3864 5736 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 2%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588676 15784090 734 1.31% 1.79% 1.95% 0 CDP Protocol
.
.
48 3864 5736 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 1%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11588824 15784283 734 0.65% 1.76% 1.94% 0 CDP Protocol
.
.
48 3864 5737 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 3%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11589004 15784473 734 1.96% 1.85% 1.95% 0 CDP Protocol
.
.
48 3864 5737 673 0.00% 0.00% 0.00% 0 ODR Router
Hub# show proc cpu
CPU utilization for five seconds: 3%/0%; one minute: 3%; five minutes: 3%
PID Runtime(ms) Invoked uSecs 5Sec 1Min 5Min TTY Process
.
.
18 11589188 15784661 734 1.63% 1.83% 1.94% 0 CDP Protocol
.
.
48 3864 5737 673 0.00% 0.00% 0.00% 0 ODR Router
Améliorations
La version de l'ODR antérieure à Cisco IOS 12.0.5T présentait quelques limites. Voici la liste des améliorations apportées à Cisco IOS 12.0.5T et versions ultérieures :
-
Avant CSCdy48736, les sous-réseaux secondaires sont annoncés en tant que /32 dans une mise à jour CDP. Ceci est corrigé dans 12.2.13T et versions ultérieures.
-
Les concentrateurs CDP propagent maintenant les routes par défaut aux rayons, de sorte qu'il n'est pas nécessaire d'ajouter des routes statiques par défaut dans les rayons. Le temps de convergence augmente considérablement. Lorsque le saut suivant tombe en panne, le rayon le détecte rapidement via l'ODR et converge. Cette fonctionnalité est ajoutée dans 12.0.5T par le bogue CSCdk91586.
-
Si la liaison entre le concentrateur et le rayon n'est pas numérotée IP, la route par défaut envoyée par le concentrateur peut ne pas être vue au niveau des rayons. Ce bogue, CSCdx66917, est corrigé dans IOS 12.2.14, 12.2.14T et versions ultérieures.
-
Pour augmenter/diminuer la distance de ROD sur les rayons afin qu'ils puissent préférer un concentrateur à l'autre, une suggestion a été faite qui est suivie via CSCdr35460. Le code a déjà été testé et sera bientôt disponible pour les clients.
 Commentaires
Commentaires