Resolución de problemas de código de fallo de ACI F199144, F93337, F381328, F93241, F450296: TCA
Opciones de descarga
-
ePub (694.0 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (495.4 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos de remediación para los códigos de fallo de ACI: F199144, F93337, F381328, F93241, F450296
Background
Si tiene un fabric ACI conectado a Intersight, se generó una solicitud de servicio en su nombre para indicar que se encontró una instancia de este fallo en el fabric ACI conectado a Intersight.
Esto se supervisa activamente como parte de los compromisos proactivos de ACI.
Este documento describe los siguientes pasos para la remediación del siguiente fallo:
Error: F199144
"Code" : "F199144",
"Description" : "TCA: External Subnet (v4 and v6) prefix entries usage current value(eqptcapacityPrefixEntries5min:extNormalizedLast) value 91% raised above threshold 90%",
"Dn" : "topology/pod-1/node-132/sys/eqptcapacity/fault-F199144"
Este error específico se produce cuando el uso actual del prefijo de subred externa supera el 99%. Esto sugiere una limitación de hardware en términos de rutas manejadas por estos switches.
Inicio rápido para solucionar los errores: F199144
1. Comando "show platform internal hal l3 routingthreshold"
module-1# show platform internal hal l3 routingthresholds
Executing Custom Handler function
OBJECT 0:
trie debug threshold : 0
tcam debug threshold : 3072
Supported UC lpm entries : 14848
Supported UC lpm Tcam entries : 5632
Current v4 UC lpm Routes : 19526
Current v6 UC lpm Routes : 0
Current v4 UC lpm Tcam Routes : 404
Current v6 UC lpm Tcam Routes : 115
Current v6 wide UC lpm Tcam Routes : 24
Maximum HW Resources for LPM : 20480 < ------- Maximum hardware resources
Current LPM Usage in Hardware : 20390 < ------------Current usage in Hw
Number of times limit crossed : 5198 < -------------- Number of times that limit was crossed
Last time limit crossed : 2020-07-07 12:34:15.947 < ------ Last occurrence, today at 12:34 pm2. Comando "show platform internal hal health-stats"
module-1# show platform internal hal health-stats
No sandboxes exist
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 249
...
l2_total_host_entries_norm : 4
L3 stats:
=========
l3_v4_local_ep_entries : 40
max_l3_v4_local_ep_entries : 12288
l3_v4_local_ep_entries_norm : 0
l3_v6_local_ep_entries : 0
max_l3_v6_local_ep_entries : 8192
l3_v6_local_ep_entries_norm : 0
l3_v4_total_ep_entries : 221
max_l3_v4_total_ep_entries : 24576
l3_v4_total_ep_entries_norm : 0
l3_v6_total_ep_entries : 0
max_l3_v6_total_ep_entries : 12288
l3_v6_total_ep_entries_norm : 0
max_l3_v4_32_entries : 49152
total_l3_v4_32_entries : 6294
l3_v4_total_ep_entries : 221
l3_v4_host_uc_entries : 6073
l3_v4_host_mc_entries : 0
total_l3_v4_32_entries_norm : 12
max_l3_v6_128_entries : 12288
total_l3_v6_128_entries : 17
l3_v6_total_ep_entries : 0
l3_v6_host_uc_entries : 17
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 0
max_l3_lpm_entries : 20480 < ----------- Maximum
l3_lpm_entries : 19528 < ------------- Current L3 LPM entries
l3_v4_lpm_entries : 19528
l3_v6_lpm_entries : 0
l3_lpm_entries_norm : 99
max_l3_lpm_tcam_entries : 5632
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 864
l3_v4_lpm_tcam_entries : 404
l3_v6_lpm_tcam_entries : 460
l3_v6_wide_lpm_tcam_entries : 24
l3_lpm_tcam_entries_norm : 15
l3_v6_lpm_tcam_entries_norm : 2
l3_host_uc_entries : 6090
l3_v4_host_uc_entries : 6073
l3_v6_host_uc_entries : 17
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 250
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 261
uc_adj_entries_norm : 3
vrfs : 150
infra_vrfs : 0
tenant_vrfs : 148
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 185
Falla de los siguientes pasos: F199144
1. Reduzca el número de rutas que debe gestionar cada switch para cumplir con la escalabilidad definida para el modelo de hardware. Consulte la guía de escalabilidad aquí https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/4-x/verified-scalability/Cisco-ACI-Verified-Scalability-Guide-412.html
2. Considere cambiar el perfil de la escala de reenvío según la escala. https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-overview-and-guidelines.html
3. Quitando la subred 0.0.0.0/0 en L3Out y solo configure las subredes requeridas
4. Si utiliza la Gen 1, actualice su hardware de la Gen 1 a la Gen 2, ya que los switches de la Gen 2 permiten más de 20 000 rutas v4 externas.
Error: F93337
"Code" : "F93337",
"Description" : "TCA: memory usage current value(compHostStats15min:memUsageLast) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93337"Este fallo específico se produce cuando el host de VM consume más memoria que el umbral. El APIC supervisa estos hosts a través de VCenter. Comp:HostStats15min es una clase que representa las estadísticas más actuales para el host en un intervalo de muestreo de 15 minutos. Esta clase se actualiza cada 5 minutos.
Inicio rápido para solucionar errores: F93337
1. Comando "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<ID de VM del DN del fallo>"
Este comando brinda información sobre la VM afectada
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Comando "moquery -c compRsHv | grep 'vm-1071'"
Este comando brinda información sobre el host donde se aloja la VM. En este ejemplo, la VM se encuentra en el host-347
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Comando "moquery -c compHv -f 'comp.Hv.oid=="host-1068"'"
Este comando proporciona detalles sobre el host
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Falla de los siguientes pasos: F93337
1. Cambie la memoria asignada para la máquina virtual en el host.
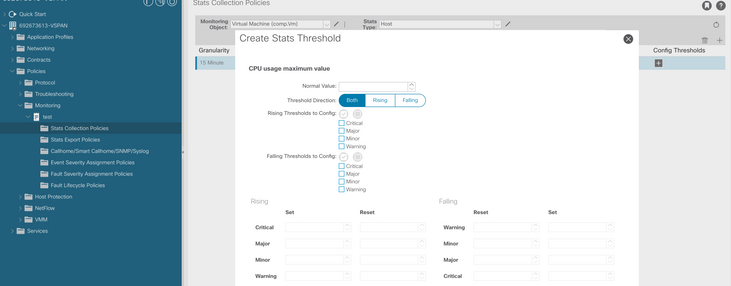
2. Si se espera que haya memoria, puede suprimir el fallo creando una política de recopilación de estadísticas para cambiar el valor de umbral.
a. Bajo el arrendatario de la VM, cree una nueva política de monitoreo.

b. En la directiva de supervisión, seleccione la directiva de recopilación de estadísticas.
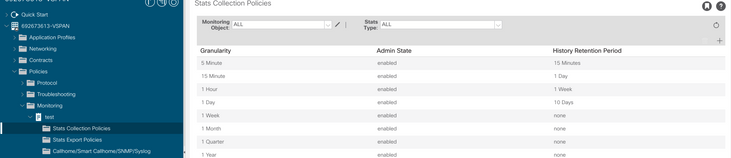
c. Haga clic en el icono de edición junto al menú desplegable Objeto de supervisión y active la máquina virtual (comp.Vm) como objeto de supervisión. Después de enviar, seleccione el objeto compVm en el menú desplegable Objeto de supervisión.

d. Haga clic en el icono de edición junto a Tipo de estadísticas y, a continuación, active Uso de CPU.
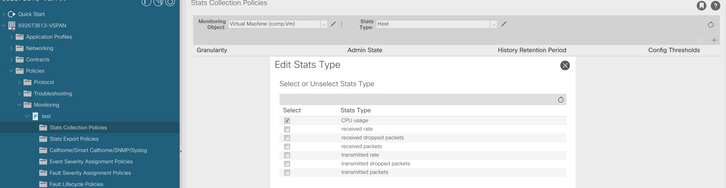
e. En el menú desplegable de estadísticas, haga clic en seleccionar host, haga clic en el signo + e introduzca su granularidad, el estado de administrador y el período de retención de historial y, a continuación, haga clic en actualizar.

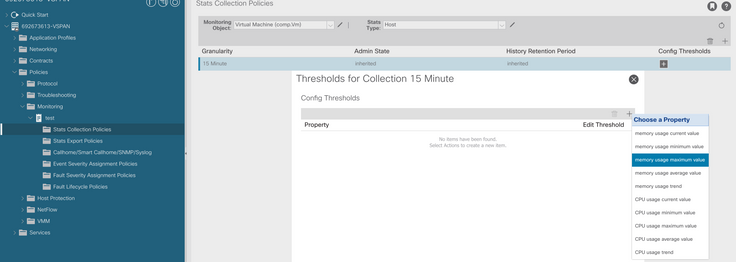
f. Haga clic en el signo + bajo el umbral de configuración y agregue "valor máximo de uso de memoria" como propiedad.
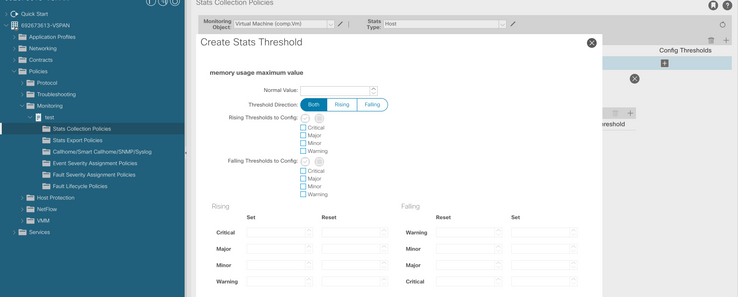
g. Cambie el valor normal al umbral que prefiera.
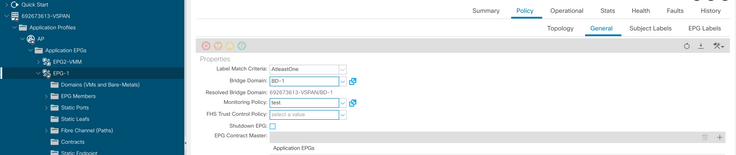
h. Aplicar la política de supervisión en el EPG
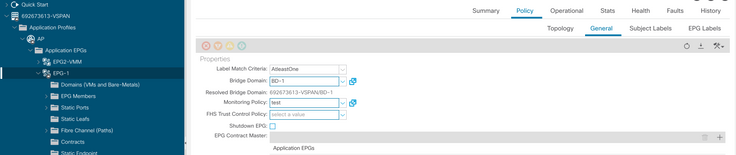
I. Para confirmar si la política se aplica en la máquina virtual, ejecute "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>"'"
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been applied
Error: F93241
"Code" : "F93241",
"Description" : "TCA: CPU usage average value(compHostStats15min:cpuUsageAvg) value 100% raised above threshold 99%",
"Dn" : "comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/fault-F93241"Este fallo específico se produce cuando el host de VM consume CPU más que el umbral. El APIC supervisa estos hosts a través de VCenter. Comp:HostStats15min es una clase que representa las estadísticas más actuales para el host en un intervalo de muestreo de 15 minutos. Esta clase se actualiza cada 5 minutos.
Inicio rápido para solucionar errores: F93241
1. Comando "moquery -d 'comp/prov-VMware/ctrlr-[<DVS>]-<VCenter>/vm-vm-<ID de VM del DN del fallo>"
Este comando brinda información sobre la VM afectada
# comp.Vm
oid : vm-1071
cfgdOs : Ubuntu Linux (64-bit)
childAction :
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071
ftRole : unset
guid : 501030b8-028a-be5c-6794-0b7bee827557
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T17:16:06.572+05:30
monPolDn : uni/tn-692673613-VSPAN/monepg-test
name : VM3
nameAlias :
os :
rn : vm-vm-1071
state : poweredOn
status :
template : no
type : virt
uuid : 4210b04b-32f3-b4e3-25b4-fe73cd3be0ca2. Comando "moquery -c compRsHv | grep 'vm-1071'"
Este comando brinda información sobre el host donde se aloja la VM. En este ejemplo, la VM se encuentra en el host-347
apic2# moquery -c compRsHv | grep vm-1071
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/vm-vm-1071/rshv-[comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068]3. Comando "moquery -c compHv -f 'comp.Hv.oid=="host-1068"'"
Este comando proporciona detalles sobre el host
apic2# moquery -c compHv -f 'comp.Hv.oid=="host-1068"'
Total Objects shown: 1
# comp.Hv
oid : host-1068
availAdminSt : gray
availOperSt : gray
childAction :
countUplink : 0
descr :
dn : comp/prov-VMware/ctrlr-[FAB4-AVE]-vcenter/hv-host-1068
enteringMaintenance : no
guid : b1e21bc1-9070-3846-b41f-c7a8c1212b35
id : 0
issues :
lcOwn : local
modTs : 2022-04-21T14:23:26.654+05:30
monPolDn : uni/infra/moninfra-default
name : myhost
nameAlias :
operIssues :
os :
rn : hv-host-1068
state : poweredOn
status :
type : hv
uuid :Falla de los siguientes pasos: F93241
1. Actualice la CPU asignada para la máquina virtual en el host.
2. Si se espera que la CPU suprima el fallo creando una política de recopilación de estadísticas para cambiar el valor de umbral.
a. Bajo el arrendatario de la VM, cree una nueva política de monitoreo.

b. En la directiva de supervisión, seleccione la directiva de recopilación de estadísticas.
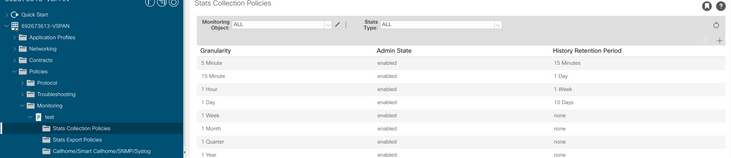
c. Haga clic en el icono de edición junto al menú desplegable Objeto de supervisión y active la máquina virtual (comp.Vm) como objeto de supervisión. Después de enviar, seleccione el objeto compVm en el menú desplegable Objeto de supervisión.

d. Haga clic en el icono de edición junto a Tipo de estadísticas y, a continuación, active Uso de CPU.
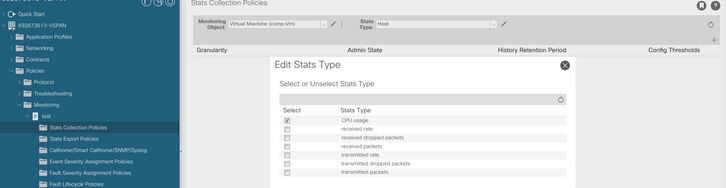
e. En el menú desplegable de estadísticas, haga clic en seleccionar host, haga clic en el signo + e introduzca su granularidad, el estado de administrador y el período de retención de historial y, a continuación, haga clic en actualizar.

f. Haga clic en el signo + bajo el umbral de configuración y agregue "valor máximo de uso de CPU" como propiedad.
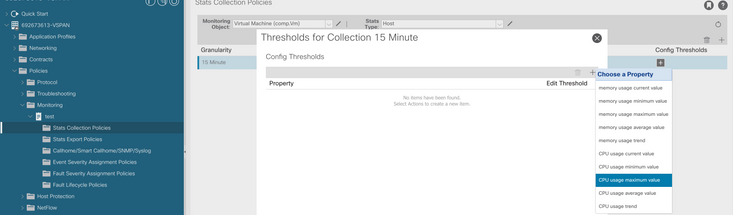
g. Cambie el valor normal al umbral que prefiera.
h. Aplicar la política de supervisión en el EPG
I. Para confirmar si la política se aplica en la máquina virtual, ejecute "moquery -c compVm -f 'comp.Vm.oid = "vm-<vm-id>"'"
apic1# moquery -c compVm -f 'comp.Vm.oid == "vm-1071"' | grep monPolDn
monPolDn : uni/tn-692673613-VSPAN/monepg-test <== Monitoring Policy test has been appliedError: F381328
"Code" : "F381328",
"Description" : "TCA: CRC Align Errors current value(eqptIngrErrPkts5min:crcLast) value 50% raised above threshold 25%",
"Dn" : "topology/<pod>/<node>/sys/phys-<[interface]>/fault-F381328"Este error específico se genera cuando los errores CRC en una interfaz exceden el umbral. Existen dos tipos comunes de errores CRC observados: errores FCS y errores CRC Stomped. Los errores de CRC se propagan debido a una trayectoria conmutada de conexión directa y son el resultado de errores FCS iniciales. Dado que la ACI sigue el switching por conexión directa, estas tramas terminan atravesando el fabric de ACI y vemos errores CRC de stomp a lo largo del trayecto, esto no significa que todas las interfaces con errores CRC sean fallas. Se recomienda identificar el origen de CRC y solucionar el problema de SFP/puerto/fibra.
Inicio rápido para solucionar errores: F381328
1. Volcar el número más alto de interfaces con CRC en el fabric
moquery -c rmonEtherStats -f 'rmon.EtherStats.cRCAlignErrors>="1"' | egrep "dn|cRCAlignErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/([[:digit:]]+)\s/\n\1 /g' | awk '{printf "%-65s %-15s\n", $2,$1}' | sort -rnk 2
topology/pod-1/node-103/sys/phys-[eth1/50]/dbgEtherStats 399158
topology/pod-1/node-101/sys/phys-[eth1/51]/dbgEtherStats 399158
topology/pod-1/node-1001/sys/phys-[eth2/24]/dbgEtherStats 3991582. Volcar el mayor número de FCS en el fabric
moquery -c rmonDot3Stats -f 'rmon.Dot3Stats.fCSErrors>="1"' | egrep "dn|fCSErrors" | egrep -o "\S+$" | tr '\r\n' ' ' | sed -re 's/topology/\ntopology/g' | awk '{printf "%-65s %-15s\n", $1,$2}' | sort -rnk 2Falla de los siguientes pasos: F381328
1. Si hay errores FCS en el fabric, estos se solucionan. Estos errores suelen indicar problemas de nivel 1.
2. Si hay errores CRC stomp en el puerto del panel frontal, verifique el dispositivo conectado en el puerto e identifique por qué los stomp provienen de ese dispositivo.
Guión Python para fallo: F381328
Todo este proceso también se puede automatizar mediante el script python. Consulte https://www.cisco.com/c/en/us/support/docs/cloud-systems-management/application-policy-infrastructure-controller-apic/217577-how-to-use-fcs-and-crc-troubleshooting-s.html
Error: F450296
"Code" : "F450296",
"Description" : "TCA: Multicast usage current value(eqptcapacityMcastEntry5min:perLast) value 91% raised above threshold 90%",
"Dn" : "sys/eqptcapacity/fault-F450296"Este fallo específico se produce cuando el número de entradas de multidifusión supera el umbral.
Inicio rápido para solucionar errores: F450296
1. Comando "show platform internal hal health-stats asic-unit all"
module-1# show platform internal hal health-stats asic-unit all
|Sandbox_ID: 0 Asic Bitmap: 0x0
|-------------------------------------
L2 stats:
=========
bds: : 1979
max_bds: : 3500
external_bds: : 0
vsan_bds: : 0
legacy_bds: : 0
regular_bds: : 0
control_bds: : 0
fds : 1976
max_fds : 3500
fd_vlans : 0
fd_vxlans : 0
vlans : 3955
max vlans : 3960
vlan_xlates : 6739
max vlan_xlates : 32768
ports : 52
pcs : 47
hifs : 0
nif_pcs : 0
l2_local_host_entries : 1979
max_l2_local_host_entries : 32768
l2_local_host_entries_norm : 6
l2_total_host_entries : 1979
max_l2_total_host_entries : 65536
l2_total_host_entries_norm : 3
L3 stats:
=========
l3_v4_local_ep_entries : 3953
max_l3_v4_local_ep_entries : 32768
l3_v4_local_ep_entries_norm : 12
l3_v6_local_ep_entries : 1976
max_l3_v6_local_ep_entries : 24576
l3_v6_local_ep_entries_norm : 8
l3_v4_total_ep_entries : 3953
max_l3_v4_total_ep_entries : 65536
l3_v4_total_ep_entries_norm : 6
l3_v6_total_ep_entries : 1976
max_l3_v6_total_ep_entries : 49152
l3_v6_total_ep_entries_norm : 4
max_l3_v4_32_entries : 98304
total_l3_v4_32_entries : 35590
l3_v4_total_ep_entries : 3953
l3_v4_host_uc_entries : 37
l3_v4_host_mc_entries : 31600
total_l3_v4_32_entries_norm : 36
max_l3_v6_128_entries : 49152
total_l3_v6_128_entries : 3952
l3_v6_total_ep_entries : 1976
l3_v6_host_uc_entries : 1976
l3_v6_host_mc_entries : 0
total_l3_v6_128_entries_norm : 8
max_l3_lpm_entries : 38912
l3_lpm_entries : 9384
l3_v4_lpm_entries : 3940
l3_v6_lpm_entries : 5444
l3_lpm_entries_norm : 31
max_l3_lpm_tcam_entries : 4096
max_l3_v6_wide_lpm_tcam_entries: 1000
l3_lpm_tcam_entries : 2689
l3_v4_lpm_tcam_entries : 2557
l3_v6_lpm_tcam_entries : 132
l3_v6_wide_lpm_tcam_entries : 0
l3_lpm_tcam_entries_norm : 65
l3_v6_lpm_tcam_entries_norm : 0
l3_host_uc_entries : 2013
l3_v4_host_uc_entries : 37
l3_v6_host_uc_entries : 1976
max_uc_ecmp_entries : 32768
uc_ecmp_entries : 1
uc_ecmp_entries_norm : 0
max_uc_adj_entries : 8192
uc_adj_entries : 1033
uc_adj_entries_norm : 12
vrfs : 1806
infra_vrfs : 0
tenant_vrfs : 1804
rtd_ifs : 2
sub_ifs : 2
svi_ifs : 1978
Mcast stats:
============
mcast_count : 31616 <<<<<<<
max_mcast_count : 32768
Policy stats:
=============
policy_count : 127116
max_policy_count : 131072
policy_otcam_count : 2920
max_policy_otcam_count : 8192
policy_label_count : 0
max_policy_label_count : 0
Dci Stats:
=============
vlan_xlate_entries : 0
vlan_xlate_entries_tcam : 0
max_vlan_xlate_entries : 0
sclass_xlate_entries : 0
sclass_xlate_entries_tcam : 0
max_sclass_xlate_entries : 0Falla de los siguientes pasos: F450296
1. Considere la posibilidad de trasladar parte del tráfico de multidifusión a otras hojas.
2. Explore diversos perfiles de escala de reenvío para aumentar la escala de multidifusión. consulte el enlace https://www.cisco.com/c/en/us/td/docs/switches/datacenter/aci/apic/sw/all/forwarding-scale-profiles/cisco-apic-forwarding-scale-profiles/m-forwarding-scale-profiles-523.html
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
11-Jul-2023 |
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Savinder SinghTAC
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)