Solución de problemas de detección de blade de UCS
Opciones de descarga
-
ePub (1.5 MB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (806.9 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
En este documento se describen los pasos para solucionar un problema en el que el blade no puede detectar debido a un error de estado de alimentación del servidor MC.
Prerequisites
Requirements
Cisco recomienda que tenga conocimientos prácticos sobre estos temas:
- Cisco Unified Computing System (UCS)
- Fabric Interconnect (FI) de Cisco
Componentes Utilizados
La información que contiene este documento se basa en las siguientes versiones de software y hardware.
- UCS B420-M3
- UCS B440-M3
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
- Actualización del firmware del blade, el servidor se desactivó tras el reinicio de la política de tiempo de actividad.
- Algún evento de alimentación en el Data Center.
Lo anterior podría ser el posible desencadenante de la cuestión.
Problema
Este mensaje de error aparece al reiniciar o durante la detección.
"No se puede cambiar el estado de alimentación del blade"
UCSM informa de esta alerta en el caso de un blade que no se enciende
El blade se ha reiniciado como parte de la actualización del firmware o cualquier otro mantenimiento no puede detectar/activar con el siguiente mensaje en FSM:
"No se puede cambiar el estado de alimentación del servidor: error de MC (-20): el controlador de administración no puede procesar la solicitud o no pudo hacerlo (sam:dme:ComputePhysicalTurnup:Execute)"
Los registros de SEL muestran entradas de error como se muestra a continuación:
CIMC | Alerta de plataforma POWER_ON_FAIL #0xde | Falla predictiva no confirmada | No Declarado
CIMC | Alerta de plataforma POWER_ON_FAIL #0xde | Fallo predictivo afirmado | Afirmativo
Troubleshoot
Desde el shell de UCSM CLI, conéctese a cimc del blade y verifique el estado de la alimentación del blade mediante el comando power.
- ssh FI-IP-ADDR
- connect cimc X
- energía
Failure Scenario # 1 OP:[ status ] Power-State: [ on ] VDD-Power-Good: [ inactive ] Power-On-Fail: [ active ] Power-Ctrl-Lock: [ unlocked ] Power-System-Status: [ Good ] Front-Panel Power Button: [ Enabled ] Front-Panel Reset Button: [ Enabled ] OP-CCODE:[ Success ]
Failure Scenario #2 OP:[ status ] Power-State: [ off ] VDD-Power-Good: [ inactive ] Power-On-Fail: [ inactive ] Power-Ctrl-Lock: [ permanent lock ] <<<---------------- Power-System-Status: [ Bad ] <<<--------------- Front-Panel Power Button: [ Disabled ] Front-Panel Reset Button: [ Disabled ] OP-CCODE:[ Success ]
Resultado del escenario de trabajo #
[ help ]# power OP:[ status ] Power-State: [ on ] VDD-Power-Good: [ active ] Power-On-Fail: [ inactive ] Power-Ctrl-Lock: [ unlocked ] Power-System-Status: [ Good ] Front-Panel Power Button: [ Enabled ] Front-Panel Reset Button: [ Enabled ] OP-CCODE:[ Success ] [ power ]#
Verifique el valor del sensor #
POWER_ON_FAIL | disk -> | discreto | 0x0200 | na | na | na | na | na | na | >>> No funciona
Valor del sensor#
POWER_ON_FAIL | disk -> | discreto | 0x0100 | na | na | na | na | na | na | >>> Trabajando
Ejecute el comando sensores y verifique los valores de los sensores de potencia y voltaje. Compare la salida con el mismo modelo de estado de encendido del blade.
Si las columnas Lectura o Estado son No Aplicable para ciertos sensores, es posible que no se trate del fallo de hardware en todo momento.
Logs snippet#
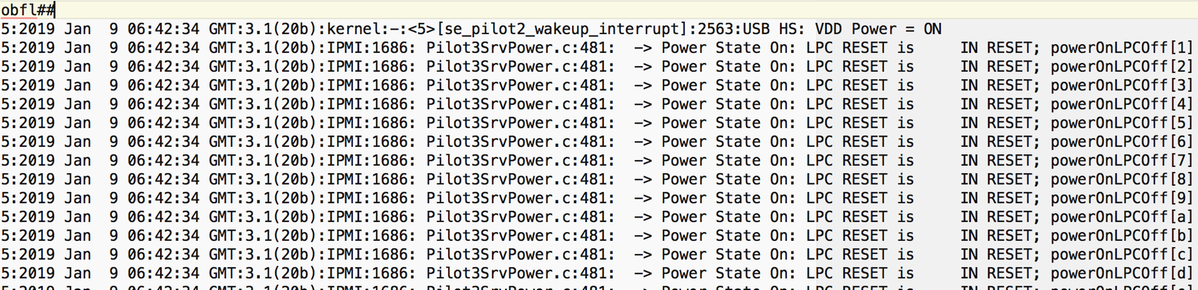
Sel.log#
CIMC | Alerta de plataforma POWER_ON_FAIL #0xde | Fallo predictivo afirmado | Afirmativo
power-on-fail.hist dentro de tmp/techsupport_pidXXXX/CIMCX_TechSupport-nvram.tar.gz)
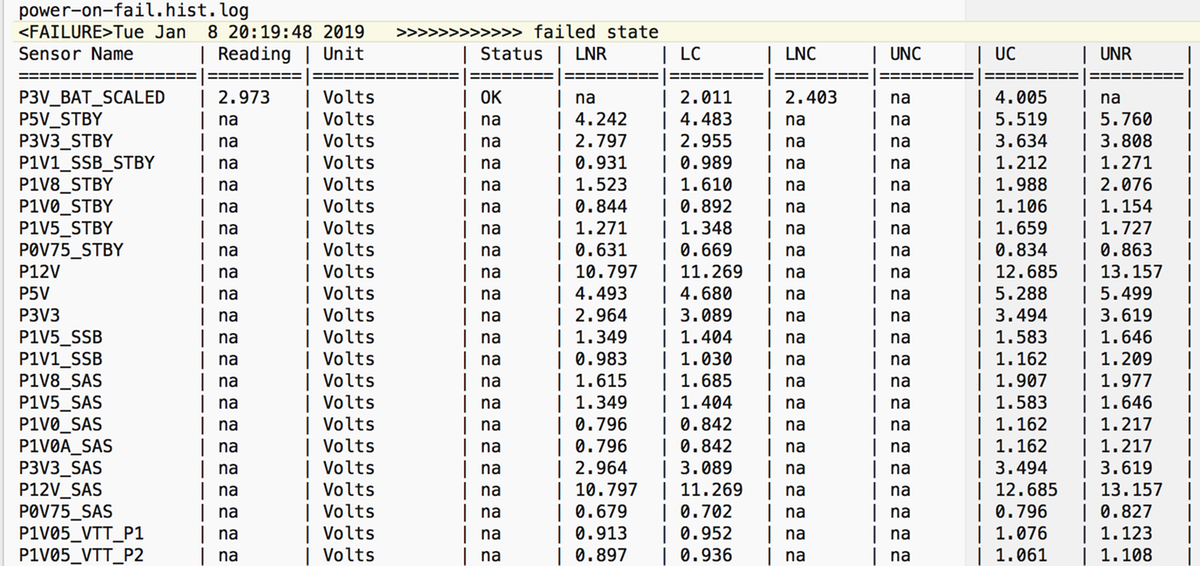
Si lo anterior no ayuda y, como paso siguiente, recopile el paquete de registro de soporte técnico de UCSM y chasis.
Ayuda a investigar más a fondo el problema.
Con los síntomas mencionados anteriormente, intente estos pasos para recuperar el problema.
Paso 1: compruebe que el estado del FSM del blade es "Error" con la descripción "state-MC Error(-20)".
Vaya a Equipo > Chasis X > Servidor Y > FSM

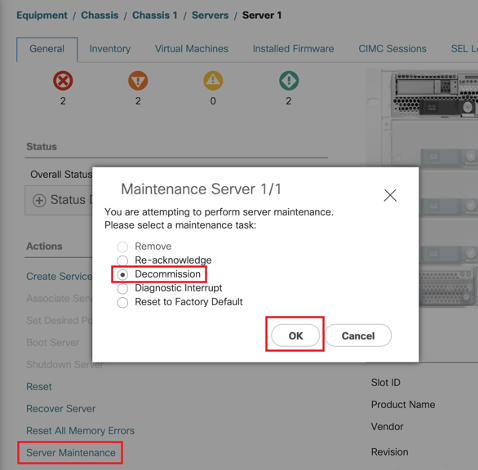
Paso 2: anote el número de serie del blade afectado y retire el blade.
<<< IMP: Anote el número de serie del blade problemático en la ficha General antes de retirarlo. Será necesario más adelante en el paso 4 >>>
Vaya a Equipo > Chasis X > Servidor Y > General > Mantenimiento del servidor > Retirada > Aceptar.
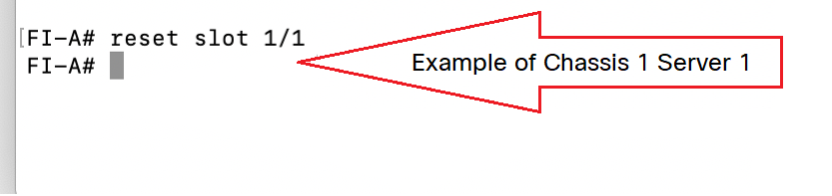
Paso 3. FI-A/B# reset slot x/y
Por ejemplo, #Chassis2-Server 1 se verá afectado.
FI-A# reset slot 2/1
Espere de 30 a 40 segundos después de ejecutar el comando anterior
Paso 4: Recomiende el Blade que se ha retirado.
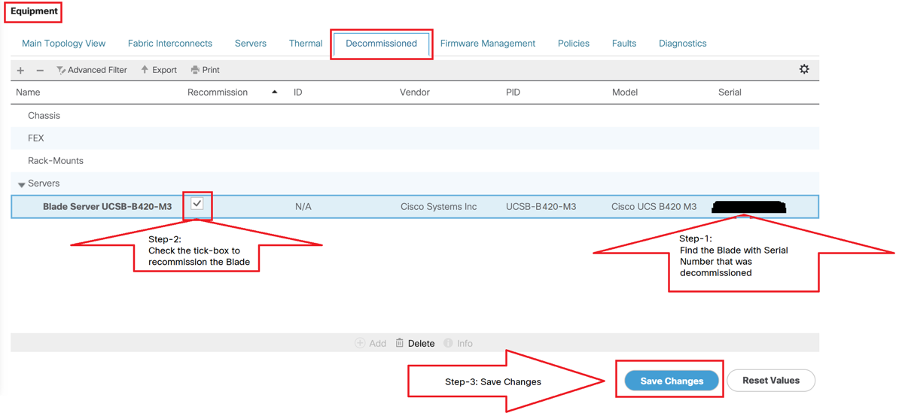
Navegue hasta Equipo > Retirado > Servidores > Busque el servidor que retiró (Encuentre el blade correcto con el número de serie indicado en el paso 2 antes de la retirada) > Marque la casilla de verificación de reconexión con el blade correcto (Valide con el número de serie) > Guardar cambios.
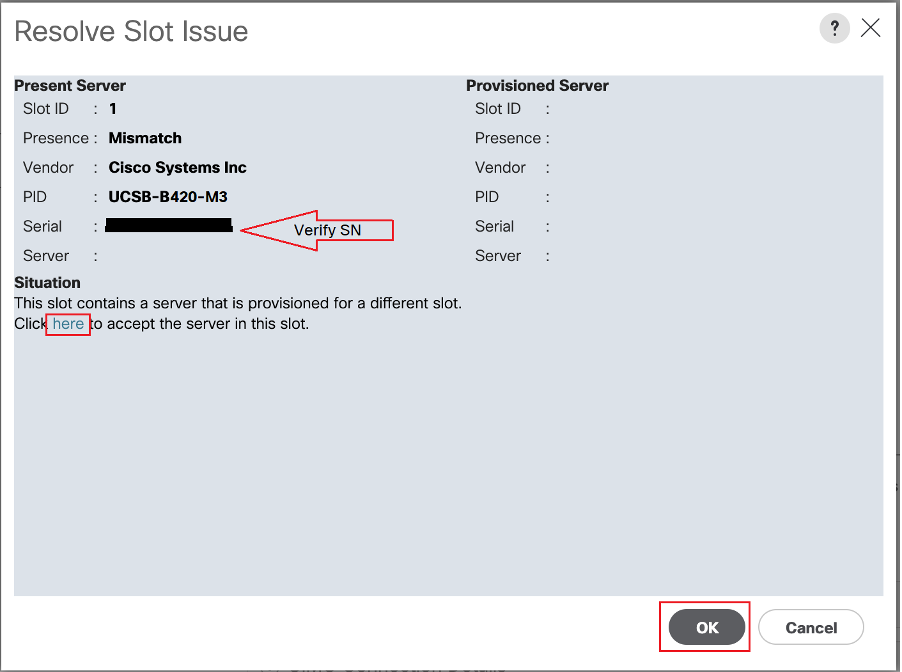
Paso-5: Resuelva la ranura, si se observa.
Vaya a Equipo > Chasis X > Servidor Y.
Si aparece el mensaje emergente "Resolve Slot Issues" (Resolver problema de ranura) para el servidor blade que ha reiniciado, verifique su número de serie y haga clic en "here" para aceptar el servidor en la ranura.
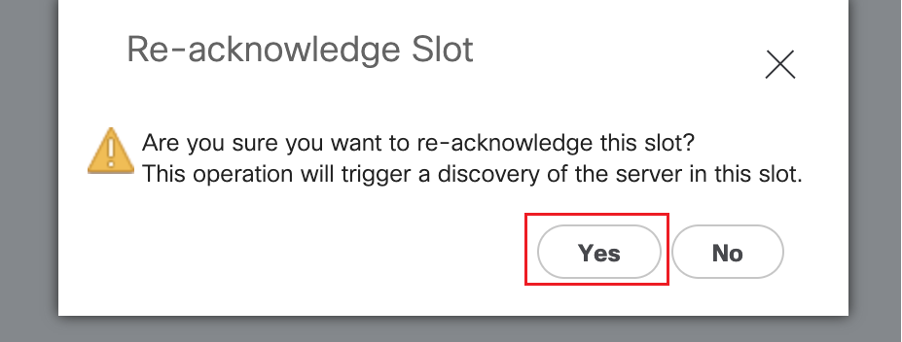
La detección de servidores blade debe comenzar ahora.
Espere a que se complete la detección de servidores. Supervise el progreso en la ficha Server FSM (Servidor FSM).
Paso 6. Si los pasos uno a cinco no sirven de ayuda y FSM falla de nuevo, retire el blade e intente VOLVER A INSTALARLO físicamente.
Si el servidor sigue sin poder detectar, póngase en contacto con Cisco TAC si se trata de un problema de hardware.
NOTE: If you have B200 M4 blade and notice failure scenario #2 , please refer following bug and Contact TAC
CSCuv90289
B200 M4 fails to power on due to POWER_SYS_FLT
Información Relacionada
Con la colaboración de ingenieros de Cisco
- Richita GajjarCisco TAC
- Afroj AhmadCisco TAC
- Sivakumar SukumarCisco TAC
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)