Problemas comunes de rendimiento de FlexPod
Contenido
Introducción
Este documento describe los problemas de rendimiento comunes en los entornos de FlexPod, proporciona a un método para resolver problemas los problemas, y proporciona a los pasos de la mitigación. Se piensa como punto de partida para los clientes que miran para resolver problemas el funcionamiento en un entorno de FlexPod. Este documento fue escrito como resultado de los problemas considerados por el equipo del Centro de Asistencia Técnica (TAC) de las soluciones del centro de datos estos últimos meses.
Introducción general de FlexPod
Un FlexPod consiste en un ordenador del sistema de la Computación unificada (UCS) conectado vía un conmutador del nexo con el almacenamiento de NetApp y las redes IP.

El FlexPod más común consiste en un chasis de las B-series de Cisco UCS conectado vía la tela interconecta (FIs) a los 5500 Switch del nexo a los limadores de NetApp. Otra solución, llamada el FlexPod expreso, utiliza un chasis de la serie C UCS conectado con los 3000 Switch del nexo. Este documento discute el FlexPod más común.
Consideraciones de rendimiento
En los entornos complejos con los partidos responsables del múltiplo según lo visto típicamente en un FlexPod, usted necesita considerar los aspectos múltiples para resolver problemas el problema. Los problemas de rendimiento típicos en la capa 2 y las redes IP provendrían:
- Paquete o pérdida de trama - la pérdida de bits de los datos causa un efecto adverso en el funcionamiento de las aplicaciones.
- Protegiendo - si un paquete o un marco pasa demasiada hora en una cola/un almacenador intermediario que ciertas implicaciones en el rendimiento se pudieron considerar por las aplicaciones, especialmente en caso de las Redes de almacenamiento. El tiempo de espera, el reordenar, y los problemas del normalizador bajan bajo esta categoría.
- Problemas de falta de coincidencia y fragmentación MTU - un problema común cuando usted alcanza el mayor rendimiento. Problemas que se relacionan con la caída de la fragmentación y de la inconsistencia MTU en esta categoría.
Entorno
Es importante conocer el entorno para el cual se mide el funcionamiento. Las preguntas sobre el tipo y protocolo del almacenamiento, así como el sistema operativo del servidor afectado (OS) y la ubicación, se deben aumentar para estrechar correctamente el problema abajo. Un Diagrama de topología que resume la Conectividad es el mínimo.
Medida
Usted necesita conocer se mide qué y se mide cómo él. Ciertas aplicaciones, así como la mayoría de los vendedores del almacenamiento y del hipervisor, proporcionan a las medidas de una cierta clase que indican el funcionamiento/la salud del sistema. Estas medidas son una buena punta a comenzar en pues no son un substituto para la mayoría de las metodologías del troubleshooting.
Como un ejemplo, una medida del tiempo de espera del almacenamiento del Network File System (NFS) en el hipervisor pudo indicar que va el funcionamiento abajo, no obstante en sus los propio no implica la red. En el caso de un NFS, un ping simple del host a la red IP del almacenamiento NFS pudo indicar si la red es culpar.
Línea de base
Esta punta no se puede subrayar bastantes, especialmente cuando usted abre un caso de TAC. Para indicar que el funcionamiento es insatisfactorio, el parámetro medido necesita ser indicado. Esto incluye el valor previsto y probado. Idealmente, usted debe mostrar los datos anteriores y la metodología de prueba usada para alcanzar esos datos.
Como un ejemplo; el tiempo de espera 10ms alcanzado cuando estaba probado, con una escritura-solamente de un solo iniciador a un solo número de unidad lógica (LUN), no pudo ser indicativo de lo que se supone el tiempo de espera para estar para completamente un sistema cargado.
Problemas de rendimiento en un FlexPod
Puesto que este documento se piensa como referencia para la mayoría de los entornos de FlexPod, resume solamente la mayoría de los problemas frecuentes como considerado por el Equipo del TAC responsable de las soluciones del centro de datos.
Problemas Comunes
Los problemas comunes al almacenamiento y las redes IP/Layer 2 se discuten en esta sección.
Marco y pérdida del paquete
El capítulo y la pérdida del paquete es el factor más frecuente ese funcionamiento de los impactos. Uno de los lugares comunes para buscar las indicaciones de un problema está en el nivel de la interfaz. Del nexo 5000 o del sistema operativo del nexo UCS (NX-OS) CLI, ingrese el interfaz de la demostración | el sec “está encima de” | ^ del egrep (Eth|fc)|deseche|descenso|Comando crc. Para los interfaces que están para arriba, enumera el nombre y desecha los contadores y los descensos. Semejantemente, se visualiza una gran descripción cuando usted ingresa el comando error de los contadores de la interfaz de la demostración que muestra las estadísticas del error para todos los interfaces.
Mundo de los Ethernetes
Es importante saber que los contadores en non-0 no pudieron indicar un problema. En ciertos decorados esos contadores se pudieron haber aumentado en la disposición inicial o en los cambios operativos anteriores. Un aumento de los contadores debe ser vigilado.
Uno puede también recolectar los contadores de ASIC llano, que pudieron ser más indicativa. Específicamente, para el error del control de la redundancia cíclica (CRC) en los interfaces, un comando preferido TAC de ingresar es el carmel interno crc de la dotación física de la demostración. Carmel es el nombre de ASIC responsable de la expedición del puerto-nivel.
La salida similar se puede tomar de las 6100 Series FIs o de los 5600 Switch del nexo en una basada en cada puerto. Para el FI 6100, los gatos ASIC, ingresan este comando:
show hardware internal gatos port ethernet X/Y | grep
"OVERSIZE|TOOLONG|DISCARD|UNDERSIZE|FRAGMENT|T_CRC|ERR|JABBER|PAUSE"
Para el nexo 5600, del bigsur ASIC, ingrese este comando:
show hardware internal bigsur port eth x/y | egrep
"OVERSIZE|TOOLONG|DISCARD|UNDERSIZE|FRAGMENT|T_CRC|ERR|JABBER|PAUSE"
El comando para el carmel ASIC muestra donde se han recibido los paquetes CRC y al donde se han remitido, y lo que es más importante si se han pisado fuerte o no.
Puesto que el nexo 5000 y la operación UCS NX-OS está corte-por, los marcos del modo que cambian con la Secuencia de verificación de tramas (FCS) incorrecta se pisan fuerte solamente antes de remitir. Es importante descubrir de adónde los marcos corrompidos vienen.
bdsol-6248-06-A(nxos)# show hardware internal carmel crc
+----------+------------+------------+------------+------------+------------+------------+------------+
| Port | MM rx CRC | MM Rx Stomp| FI rx CRC | FI Rx Stomp| FI tx CRC | FI tx Stomp| MM tx CRC |
+----------+------------+------------+------------+------------+------------+------------+------------+
(....)
| Eth 1/17 | --- | --- | --- | 908100 | --- | --- | --- |
| Eth 1/18 | --- | --- | --- | 298658 | --- | --- | --- |
(....)
| Eth 1/34 | --- | --- | --- | --- | --- | 1206758 | 1206758 |
Este ejemplo muestra los paquetes pisados fuerte que vienen de Eth 1/17 y Eth 1/18, que es uplink al nexo 5000. Uno puede asumir que esos marcos fueron enviados después abajo a Eth 1/34, tal como Eth 1/17 + Eth que pisa fuerte 1/18 rx = Eth pisa fuerte 1/34 tx.
Una mirada similar en el nexo 5000 muestra:
bdsol-n5548-05# show hardware internal carmel crc
+----------+------------+------------+------------+------------+------------+------------+------------+
| Port | MM rx CRC | MM Rx Stomp| FI rx CRC | FI Rx Stomp| FI tx CRC | FI tx Stomp| MM tx CRC |
+----------+------------+------------+------------+------------+------------+------------+------------+
(....)
| Eth 1/14 | 13 | --- | --- | 13 | --- | --- | --- |
(.....)
| Eth 1/19 | 7578 | --- | --- | 7463 | --- | --- | --- |
Esta salida muestra que los CRCs recibidos en dos links y marcados como pisa fuerte antes de remitir. Para más información, vea el guía de Troubleshooting del nexo 5000.
Mundo del canal de la fibra
Un método simple de buscar los descensos (discrds, error, los CRCs, agotamiento del crédito de B2B) está vía el comando del fc de los contadores de la interfaz de la demostración.
Este comando, disponibles en los nexos 5000 y la interconexión de la tela, da una buena indicación de qué sucede en el mundo del canal de la fibra.
Por ejemplo:
bdsol-n5548-05# show interface counters fc | i fc|disc|error|B2B|rate|put
fc2/16
1 minute input rate 72648 bits/sec, 9081 bytes/sec, 6 frames/sec
1 minute output rate 74624 bits/sec, 9328 bytes/sec, 5 frames/sec
96879643 frames input, 155712103332 bytes
0 discards, 0 errors, 0 CRC
113265534 frames output, 201553309480 bytes
0 discards, 0 errors
0 input OLS, 1 LRR, 0 NOS, 0 loop inits
1 output OLS, 2 LRR, 0 NOS, 0 loop inits
0 transmit B2B credit transitions from zero
0 receive B2B credit transitions from zero
16 receive B2B credit remaining
32 transmit B2B credit remaining
0 low priority transmit B2B credit remaining
(...)
Este interfaz no está ocupado, y la salida muestra que sucedieron ningunos descartes o error.
Además, las transiciones del crédito de B2B a partir de la 0 fueron destacadas; debido a los ID de bug CSCue80063 y CSCut08353 de Cisco, esos contadores no pueden ser confiados en. Trabajan muy bien en Cisco MDS, pero no en el UCS de las Plataformas Nexus5k. También usted puede verificar el ID de bug CSCsz95889 de Cisco.
Semejantemente al carmel en el mundo de los Ethernetes para el canal de la fibra (FC) el recurso del fc-mac puede ser utilizado. Como un ejemplo, para el puerto fc2/1, ingresa el comando statistics interno del puerto 1 del fc-mac 2 de la dotación física de la demostración. Los contadores presentados están en el formato hexadecimal.
bdsol-6248-06-A(nxos)# show interface fc1/32 | i disc
15 discards, 0 errors
0 discards, 0 errors
bdsol-6248-06-A(nxos)# show hardware internal fc-mac 1 port 32 statistics
ADDRESS STAT COUNT
__________ ________ __________________
0x0000003d FCP_CNTR_MAC_RX_BAD_WORDS_FROM_DECODER 0x70
0x00000042 FCP_CNTR_MAC_CREDIT_IG_XG_MUX_SEND_RRDY_REQ 0x1e4f1026
0x00000043 FCP_CNTR_MAC_CREDIT_EG_DEC_RRDY 0x66cafd1
0x00000061 FCP_CNTR_MAC_DATA_RX_CLASS3_FRAMES 0x1e4f1026
0x00000069 FCP_CNTR_MAC_DATA_RX_CLASS3_WORDS 0xe80946c708
0x000d834c FCP_CNTR_PIF_RX_DROP 0xf
0x00000065 FCP_CNTR_MAC_DATA_TX_CLASS3_FRAMES 0x66cafd1
0x0000006d FCP_CNTR_MAC_DATA_TX_CLASS3_WORDS 0x2b0fae9588
0xffffffff FCP_CNTR_OLS_IN 0x1
0xffffffff FCP_CNTR_LRR_IN 0x1
0xffffffff FCP_CNTR_OLS_OUT 0x1
La salida muestra 15 descartes en la entrada. Esto se puede corresponder con a FCP_CNTR_PIF_RX_DROP que contó a 0xf (15 en el decimal). Esta información se puede correlacionar otra vez a la información FWM (encargado de la expedición).
bdsol-6248-06-A(nxos)# show platform fwm info pif fc 1/32 verbose | i drop|discard|asic
fc1/32 pd: slot 0 logical port num 31 slot_asic_num 3 global_asic_num 3 fwm_inst 7
fc 0
fc1/32 pd: tx stats: bytes 191196731188 frames 107908990 discard 0 drop 0
fc1/32 pd: rx stats: bytes 998251154572 frames 509332733 discard 0 drop 15
fc1/32 pd fcoe: tx stats: bytes 191196731188 frames 107908990 discard 0 drop 0
fc1/32 pd fcoe: rx stats: bytes 998251154572 frames 509332733 discard 0 drop 15
Sin embargo, este tellls el administrador la cantidad de descensos y que es el número correspondiente de ASIC. La información del conseguir sobre la razón de eso cayó las necesidades de ASIC de ser preguntado.
bdsol-6248-06-A(nxos)# show platform fwm info asic-errors 3
Printing non zero Carmel error registers:
DROP_SHOULD_HAVE_INT_MULTICAST: res0 = 25 res1 = 0 [36]
DROP_INGRESS_ACL: res0 = 15 res1 = 0 [46]
En este caso, el tráfico fue caído por la lista de control de acceso (ACL) del ingreso, típicamente en el mundo FC - Establecimiento de zonas.
Discordancía MTU
En los entornos de FlexPod es importante acomodar la configuración máxima de punta a punta de la unidad de la transición (MTU) para las aplicaciones y los protocolos donde se requiere. En el caso de la mayoría de los entornos, éste es canal de la fibra sobre los Ethernetes (FCoE) y las Tramas gigantes.
, Ocurre la fragmentación, el rendimiento disminuido debe además ser esperado. En caso de los protocolos tales como Network File System (NFS) y Interfaz de sistema informático reducida de Internet (iSCSI), es importante probar y probar el tamaño de punta a punta del Maximum Transmission Unit IP (MTU) y del segmento máxima TCP (MSS).
Si usted resuelve problemas las Tramas gigantes o FCoE, es importante recordar que ambos ésos necesitan la configuración constante y el Clase de Servicio (CoS) que marcan a través del entorno para actuar correctamente.
En el caso del UCS y del nexo, un comando que es útil para validar el por-interfaz, por la configuración de MTU del QoS-grupo es interfaz de Datos en espera de la demostración | i que hace cola|qos-grupo|MTU.
El MTU visualiza en el nexo 5000 y las Plataformas UCS
Un aspecto sabido del UCS y del nexo es la visualización de MTUs en el interfaz. Esta salida demuestra un interfaz configurado para hacer cola las Tramas gigantes y FCoE:
bdsol-6248-06-A(nxos)# show queuing interface e1/1 | i MTU
q-size: 360640, HW MTU: 9126 (9126 configured)
q-size: 79360, HW MTU: 2158 (2158 configured)
Al mismo tiempo, el comando show interface visualiza 1500 bytes:
bdsol-6248-06-A(nxos)# show int e1/1 | i MTU
MTU 1500 bytes, BW 10000000 Kbit, DLY 10 usec
Si está comparado a ASIC del carmel la información, ASIC muestra la capacidad MTU de un puerto dado.
show hardware internal carmel port ethernet 1/1 | egrep -i MTU
mtu : 9260
Esta discordancía MTU en la visualización se espera en las Plataformas ya mencionadas, y podría potencialmente engañar a los neófitos.
Configuración integral de extremo a extremo
La configuración constante de punta a punta es la única forma de garantizar el funcionamiento apropiado. Las Tramas gigantes configuración y pasos para el lado de Cisco, así como VMware ESXi, se describen en el UCS con el ejemplo de punta a punta de la configuración MTU del jumbo de VMware ESXi.
El UCS FCoE Uplink el ejemplo de la configuración muestra una configuración UCS y del nexo 5000. Vea el Apéndice A en el documento referido para un esquema de una configuración básica del nexo 5000.
Ponga la Conectividad de FCoE para los focos de una cuchilla de Cisco UCS en la configuración UCS para FCoE. El nexo 5000 NPIV FCoE con FCoE NPV asoció los focos del ejemplo de la configuración UCS en la configuración del nexo.
Pruebe las Tramas gigantes de punta a punta
La mayoría de los sistemas operativos de los modernos ofrecen la capacidad de probar una configuración apropiada de las Tramas gigantes con una prueba simple del Internet Control Message Protocol (ICMP).
Cálculo
9000 bytes - Encabezado IP sin las opciones (20 bytes) - encabezado ICMP (8 bytes) = 8972 bytes de dato
Comandos en los sistemas operativos populares
Linux
ping a.b.c.d -M do -s 8972
Microsoft Windows
ping -f -l 8972 a.b.c.d
ESXi
vmkping -d -s 8972 a.b.c.d
Problemas relacionados del almacenador intermediario
Problemas relacionados del tiempo de espera que protegen y los otros están entre las causas comunes de la degradación del rendimiento en el entorno de FlexPod. No todos los problemas señalados como tiempo de espera provienen los problemas reales del buffering, muy algunas medidas pudieron indicar el tiempo de espera de punta a punta. Por ejemplo, en el caso de NFS, el período del tiempo informado pudo ser con éxito read/write necesario al almacenamiento y no al tiempo de espera de red real.
La congestión es la mayoría de la causa común para proteger. En el mundo de la capa 2, la congestión puede causar el buffering e incluso ata los descensos de los bastidores. Para evitar los descensos durante los períodos de congestión, las tramas de pausa de IEEE 802.3x y el control de flujo de la prioridad (PFC) fueron introducidos. Ambos confían en pedir la punto final para llevar a cabo las transmisiones por un período corto mientras que la congestión dura. Esto se puede causar por la congestión de red (abrume recibido con el periodo de los datos) o porque un marco prioritario necesita pasar, como en el caso para FCoE.
Control de flujo - 802.3x
Para verificar qué interfaces tienen control de flujo activado, ingrese el comando flowcontrol del interfaz de la demostración. Es importante seguir la recomendación del vendedor del almacenamiento con respecto al control de flujo que es activado.
Un ejemplo que muestra cómo los trabajos del control de flujo 802.3x se muestran aquí.

PFC - 802.1Qbb
PFC no se requiere para todas las disposiciones, sino se recomienda para la mayoría. Para verificar qué interfaces tienen PFC activado, el prioridad-flujo-control de interfaz de la demostración | i en el comando puede ser ejecutado en el NX-OS y el nexo 5000 UCS.
Los interfaces entre FIs y el nexo 5000 deben ser visibles en esa lista. Si no, la configuración de QoS necesita ser verificada. QoS necesita ser de punta a punta constante para aprovecharse de PFC. Para controlar porqué el PFC no sube en una interfaz particular, ingrese el comando interno de las interfaces Ethernet x/y del registro del dcbx del sistema de la demostración para obtener el centro de datos que puentea el registro del Exchange Protocol de las capacidades (DCBX).
Un ejemplo que muestra cómo las tramas de pausa funcionan con PFC se muestra aquí.

El comando de prioridad-flujo-control del interfaz de la demostración permite que el administrador observe por-QoS el comportamiento de la clase de las tramas de pausa de la prioridad.
Aquí tiene un ejemplo:
bdsol-6120-05-A(nxos)# show queuing interface ethernet 1/1 | i prio
Per-priority-pause status : Rx (Inactive), Tx (Inactive)
Per-priority-pause status : Rx (Inactive), Tx (Active)
Esta salida muestra que, en la segunda clase, el dispositivo acaba de transmitir (TX) un marco PPP.
En este caso, el Ethernet 1/1 es puerto que hace frente a IOM y mientras que el puerto total no tendrá PFC activado, puede ser que procese los marcos PPP para los puertos FEX.
bdsol-6120-05-A(nxos)# show interface e1/1 priority-flow-control
============================================================
Port Mode Oper(VL bmap) RxPPP TxPPP
============================================================
Ethernet1/1 Auto Off 4885 3709920
En este caso, los interfaces FEX están implicados.
bdsol-6120-05-A(nxos)# show interface priority-flow-control | egrep .*\/.*\/
Ethernet1/1/1 Auto Off 0 0
Ethernet1/1/2 Auto Off 0 0
Ethernet1/1/3 Auto Off 0 0
Ethernet1/1/4 Auto Off 0 0
Ethernet1/1/5 Auto On (8) 8202210 15038419
Ethernet1/1/6 Auto On (8) 0 1073455
Ethernet1/1/7 Auto Off 0 0
Ethernet1/1/8 Auto On (8) 0 3956077
Ethernet1/1/9 Auto Off 0 0
Los puertos FEX que están implicados se pueden también controlar vía el detalle del fex X de la demostración donde está el número X de chasis.
bdsol-6120-05-A(nxos)# show fex 1 detail | section "Fex Port"
Fex Port State Fabric Port
Eth1/1/1 Down Eth1/1
Eth1/1/2 Down Eth1/2
Eth1/1/3 Down None
Eth1/1/4 Down None
Eth1/1/5 Up Eth1/1
Eth1/1/6 Up Eth1/2
Eth1/1/7 Down None
Eth1/1/8 Up Eth1/2
Eth1/1/9 Up Eth1/2
Vea estos documentos para más información sobre los mecanismos de la pausa.
- Canal de la fibra sobre las operaciones de los Ethernetes
- Canal blanco unificado de la Papel-fibra de la tela sobre los Ethernetes (FCoE)
Descartes de espera
Los nexos 5000 y el UCS NX-OS no pierden de vista los descartes del ingreso debido a la espera en a por la base del QOS-grupo. Por ejemplo:
bdsol-6120-05-A(nxos)# show queuing interface
Ethernet1/1 queuing information:
TX Queuing
qos-group sched-type oper-bandwidth
0 WRR 50
1 WRR 50
RX Queuing
qos-group 0
q-size: 243200, HW MTU: 9280 (9216 configured)
drop-type: drop, xon: 0, xoff: 243200
Statistics:
Pkts received over the port : 31051574
Ucast pkts sent to the cross-bar : 30272680
Mcast pkts sent to the cross-bar : 778894
Ucast pkts received from the cross-bar : 27988565
Pkts sent to the port : 34600961
Pkts discarded on ingress : 0
Per-priority-pause status : Rx (Inactive), Tx (Active)
El descarte del ingreso debe suceder solamente en las colas de administración del tráfico que se configuran para permitir los descensos.
Los descartes de espera del ingreso pueden suceder debido a estas razones:
- Sesión del Switched Port Analyzer (SPAN) /Monitoring activada en algunos de los interfaces (véase el ID de bug CSCur25521 de Cisco)
- La presión posterior de otro interfaz, las tramas de pausa se considera típicamente cuando está activada
- Tráfico llevado en batea a la CPU
Problema del driver
Cisco proporciona a dos drivers del sistema operativo para el UCS, enic y fnic. Enic es responsable de la Conectividad de Ethernet y fnic es responsable de la Conectividad del canal y de FCoE de la fibra. Es muy importante que los drivers enic y fnic están exactamente como se especifica en la Matriz de interoperabilidad UCS. Los problemas introducidos por los drivers incorrectos se extienden de la pérdida del paquete y del tiempo de espera agregado a un proceso de cargador del programa inicial más largo o completan la falta de Conectividad.
Información del adaptador
Cisco-proporcionó al adaptador puede proporcionar a una buena medida sobre el tráfico se pasa que, así como cae. Este ejemplo muestra cómo conectar con el chasis X, el servidor Y, y el adaptador Z.
bdsol-6248-06-A# connect adapter X/Y/Z
adapter X/Y/Z # connect
No entry for terminal type "dumb";
using dumb terminal settings.
De aquí, el administrador puede abrirse una sesión al centro de la supervisión para el recurso del funcionamiento (MCP).
adapter 1/2/1 (top):1# attach-mcp
No entry for terminal type "dumb";
using dumb terminal settings
El recurso MCP permite que usted vigile el uso del tráfico por la interfaz lógica (LIF).
adapter 1/2/1 (mcp):1# vnic
(...)
---------------------------------------- --------- --------------------------
v n i c l i f v i f
id name type bb:dd.f state lif state uif ucsm idx vlan state
--- -------------- ------- ------- ----- --- ----- --- ----- ----- ---- -----
13 vnic_1 enet 06:00.0 UP 2 UP =>0 834 20 3709 UP
14 vnic_2 fc 07:00.0 UP 3 UP =>0 836 17 970 UP
Los chasis 1, separan 1, y el adaptador 1 tiene dos indicadores luminosos LED amarillo de la placa muestra gravedad menor de interfaz de red virtual (VNICs) asociados las interfaces virtuales (los Ethernetes virtuales o canal virtual de la fibra) a 834 y a 836. Ésos tienen números 2 y 3. Las estadísticas para LIF 2 y 3 se pueden controlar como se muestra aquí:
adapter 1/2/1 (mcp):3# lifstats 2
DELTA TOTAL DESCRIPTION
4 4 Tx unicast frames without error
53999 53999 Tx multicast frames without error
69489 69489 Tx broadcast frames without error
500 500 Tx unicast bytes without error
8361780 8361780 Tx multicast bytes without error
22309578 22309578 Tx broadcast bytes without error
2 2 Rx unicast frames without error
2791371 2791371 Rx multicast frames without error
4595548 4595548 Rx broadcast frames without error
188 188 Rx unicast bytes without error
260068999 260068999 Rx multicast bytes without error
514082967 514082967 Rx broadcast bytes without error
3668331 3668331 Rx frames len == 64
2485417 2485417 Rx frames 64 < len <= 127
655185 655185 Rx frames 128 <= len <= 255
434424 434424 Rx frames 256 <= len <= 511
143564 143564 Rx frames 512 <= len <= 1023
94.599bps Tx rate
2.631kbps Rx rate
Es importante observar que proporcionan el administrador del UCS las columnas del total y del delta (entre dos ejecuciones subsiguientes de los lifstats) así como la carga de tráfico actual por-LIF y la información sobre cualquier error que pudieran haber ocurrido.
El ejemplo anterior muestra los interfaces sin ningunos errores con una carga muy pequeña. Este ejemplo muestra un diverso servidor.
adapter 4/4/1 (mcp):2# lifstats 2
DELTA TOTAL DESCRIPTION
127927993 127927993 Tx unicast frames without error
273955 273955 Tx multicast frames without error
122540 122540 Tx broadcast frames without error
50648286058 50648286058 Tx unicast bytes without error
40207322 40207322 Tx multicast bytes without error
13984837 13984837 Tx broadcast bytes without error
28008032 28008032 Tx TSO frames
262357491 262357491 Rx unicast frames without error
55256866 55256866 Rx multicast frames without error
51088959 51088959 Rx broadcast frames without error
286578757623 286578757623 Rx unicast bytes without error
4998435976 4998435976 Rx multicast bytes without error
7657961343 7657961343 Rx broadcast bytes without error
96 96 Rx rq drop pkts (no bufs or rq disabled)
136256 136256 Rx rq drop bytes (no bufs or rq disabled)
5245223 5245223 Rx frames len == 64
136998234 136998234 Rx frames 64 < len <= 127
9787080 9787080 Rx frames 128 <= len <= 255
14176908 14176908 Rx frames 256 <= len <= 511
11318174 11318174 Rx frames 512 <= len <= 1023
61181991 61181991 Rx frames 1024 <= len <= 1518
129995706 129995706 Rx frames len > 1518
136.241kbps Tx rate
784.185kbps Rx rate
Dos bits interesantes de información muestran que 96 marcos fueron caídos por el adaptador debido faltar del almacenador intermediario o el buffering inhabilitaron y además los segmentos de descarga del segmento TCP (TSO) que eran procesados.
Flujo de paquetes lógico
El diagrama mostrado aquí resume el flujo de paquetes lógico en un entorno de FlexPod.

Se significa este diagrama como un desglose de los componentes que un marco pasó a través en la manera vía el entorno de FlexPod. No refleja la complejidad de los bloques uces de los y es simplemente una manera memorizar donde las funciones particulares deben ser configuradas y ser verificadas.
Módulo de entrada-salida
Tal y como se muestra en del diagrama lógico del flujo de paquetes, el módulo de entrada-salida (IOM) es un componente en el medio de toda la comunicación que pase con el UCS. Para conectar con el IOM en los chasis X, ingrese el comando x del iom de la conexión.
Aquí están varios otros comandos útiles:
- Información de topología - el software de plataforma de la demostración [woodside|el comando sts de la secoya] muestra la información topológica desde el punto de vista IOM.

Muestra los interfaces de red (NIs) que lleve a FIs, en este caso allí es ocho de ellos, con cuatro de ellos para arriba. Además, muestra los interfaces del host (el suyo) que lleve, dentro del chasis, a las cuchillas determinadas.
- Relaciones del tráfico - el software de plataforma de la demostración [woodside|utilizan al comando rate de la secoya] de controlar el índice de tráfico que pase a través de los interfaces HI una vez la topología e interfaz se sabe HI a la asignación de la cuchilla.
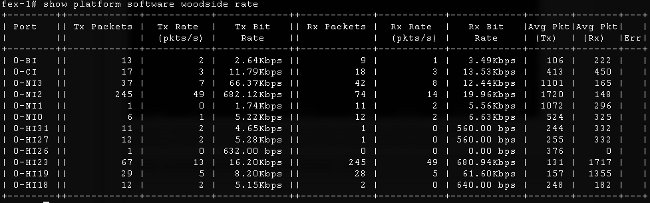
- Pérdida de tráfico - ingrese el software de plataforma de la demostración [woodside|comando de la pérdida de la secoya]. La ejecución de los ceros de este comando que la pérdida contradice. Permite que usted vea las tramas de pausa y los descensos sobre una base del por-interfaz.
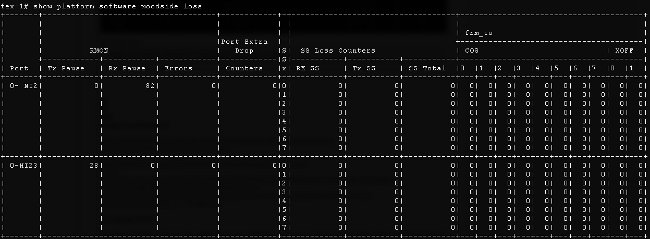
Debido a la manera que la infraestructura subyacente trabaja, los contadores se muestran solamente para los interfaces cuáles han experimentado cualquier ejecución media de la pérdida de los dos comandos. En este ejemplo, usted ve que el interfaz NI2 recibió 82 tramas de pausa y que 28 tramas de pausa fueron transmitidas para interconectar HI23, que usted conoce se asocia a la cuchilla 3.
Aspectos del diseño
Un FlexPod permite una configuración flexible y una disposición del almacenamiento y de la red de datos. Con la flexibilidad también vienen los desafíos adicionales. Es vital seguir los documentos y un diseño validado Cisco (CVD) de las mejores prácticas:
- CVD - Guía de despliegue de FlexPod
- Mejores prácticas del almacenamiento de NetApp (no específicas a Flexpod) - opciones de conectividad y mejores prácticas del almacenamiento del Cisco Unified Computing System (UCS) con el almacenamiento de NetApp
Consideraciones de la selección y del Canal de puerto de la velocidad de puerto
Un problema común considerado por los ingenieros de TAC es sobreutilización de los links debido a la selección de 1 Ethernet de Gbit en vez de 10 Ethernetes de Gbit referidos a los documentos de la mejor práctica. Como ejemplo acentuado, el funcionamiento del flujo único no será mejor en diez links de 1 Gbit comparados a un link de 10 Gbit. En el Canal de puerto un flujo único puede pasar un solo link.
Para descubrir qué método del Equilibrio de carga se utiliza en NX-OS del nexo y/o FI, ingrese el comando port-channel load-balance de la demostración. El administrador puede también descubrir que interconectan en un Canal de puerto será elegido como la interfaz saliente para un paquete o un marco. Un ejemplo simple de un bastidor en VLAN49 entre dos host se muestra aquí:
show port-channel load-balance forwarding-path interface port-channel 928 vlan 49
src-mac 70ca.9bce.ee24 dst-mac 8478.ac55.2fc2
Missing params will be substituted by 0's.
Load-balance Algorithm on switch: source-dest-ip
crc8_hash: 2 Outgoing port id: Ethernet1/27
Param(s) used to calculate load-balance:
dst-mac: 8478.ac55.2fc2
src-mac: 70ca.9bce.ee24
Problemas del específico del almacenamiento
Los problemas discutidos previamente son comunes a los datos y a las Redes de almacenamiento. Por lo completo, los problemas de rendimiento específicos a la Red de área de almacenamiento (SAN) también se mencionan. Los protocolos de almacenamiento fueron construidos con la elasticidad y la mutli-dirección todavía se aumenta. Con la llegada de las Tecnologías tales como asignación asimétrica de la unidad lógica (ALUA) e IO de trayectoria múltiple (MPIO), más flexibilidad y opciones se presentan a los administradores.
Colocación del almacenamiento
Otra consideración es colocación del almacenamiento. Un diseño de FlexPod dicta que el almacenamiento debe ser asociado en el Switches del nexo. El almacenamiento directamente asociado no se ajusta al CVD. Los diseños con el almacenamiento directamente asociado se utilizan, si se siguen las mejores prácticas. Al mismo tiempo, esos diseños no son estrictamente FlexPod.
Selección de trayecto óptimo
Esto no es técnico un problema de Cisco, pues la mayor parte de esas opciones son transparentes a los dispositivos de Cisco. Es un problema común a escoger y a pegarse a un trayecto óptimo. Un módulo específico del dispositivo moderno (el DSM) se puede presentar con los trayectos múltiples y las necesidades de escoger óptimo un uno Este tiro de pantalla muestra cuatro trayectorias disponibles para NetApp DSM para Microsoft Windows y las opciones del Equilibrio de carga.

Las configuraciones recomendadas se deben escoger sobre la base de una discusión con el vendedor del almacenamiento. Esas configuraciones pudieron afectar a los problemas de rendimiento. Una prueba típica que TAC pudo pedirle que se realice es una prueba de lectura/grabación a través solamente de la tela A o de la tela B. Esto permite típicamente que usted estreche abajo los problemas de rendimiento a las situaciones discutidas en la sección de los “problemas comunes” de este documento.
Tráfico compartido VM y del hipervisor
Esta punta es específica al componente del cálculo, sin importar el vendedor. Una forma sencilla de poner una red de almacenamiento para los hipervisores desde el punto de vista del cálculo es crear dos adaptadores del bus del host (HBA), uno para cada fibra, y ejecuta el tráfico del tráfico del cargador del programa inicial LUN y del almacenamiento de la máquina virtual (VM) sobre esos dos interfaces. Se recomienda siempre para partir el tráfico del tráfico del cargador del programa inicial LUN y del almacenamiento VM. Esto permite el mejor rendimiento y permite además una fractura lógica entre las dos clases de tráfico. Vea la sección de los “problemas conocidos” para un ejemplo.
Consejos para Troubleshooting
Estreche abajo el problema
Como en el caso de cualquier troubleshooting rápido, es muy importante estrechar abajo el problema y hacer las preguntas de la derecha.
- ¿Qué dispositivos/applications/VM son (/not) afectados?
- ¿Qué controlador de almacenamiento es (/not) afectado?
- ¿Qué trayectorias son (/not) afectadas?
- ¿Cuantas veces el problema (/not) aparece?
Cisco
Limitaciones contrarias
En este interfaz del documento, ASIC que hace cola los contadores se discute. Los contadores también dan una visión en una punta a tiempo, así que es importante vigilar el aumento de los contadores. Ciertos contadores no se pueden borrar por el diseño. Por ejemplo, el carmel ASIC mencionado previamente.
Para dar un ejemplo acentuado, la presencia de CRC o los descartes en un interfaz no pudo ser ideales, sino que puede ser que se espere que sus valores sean no-cero. Los contadores habrían podido subir en algún momento, posiblemente durante la transición o la disposición inicial. Por lo tanto es importante observar el aumento de los contadores y cuando era la última vez ellos fue borrado.
Controle las consideraciones planas
Mientras que es útil revisar los contadores, es importante saber que ciertos problemas del avión de los datos no pudieron encontrar una reflexión fácil para controlar los contadores y las herramientas planos. Como ejemplo acentuado, el ethanalyzer es mismo una herramienta útil que está disponible en UCS y el nexo 5000. Sin embargo, puede capturar solamente el tráfico del plano del control. Una captura del tráfico es lo que pide TAC a menudo, especialmente cuando no está claro donde miente el incidente.
Tráfico de la captura
Una captura confiable del tráfico adquirida los host de extremo puede verter la luz en un problema de rendimiento y estrecharla abajo muy rápidamente. El nexo 5000 y SPAN del tráfico de la oferta UCS. Específicamente, las opciones UCS de SPANing HBA determinados y los lados de la tela son útiles. Para aprender más sobre las capacidades de la captura del tráfico cuando usted vigila una sesión sobre el UCS, vea estas referencias:
- Análisis del tráfico UCS para la comprobación y los adaptadores virtuales (vídeo)
- Guía de Configuración del GUI del Cisco UCS Manager - Vigilar el tráfico
NetApp
NetApp ofrece a un conjunto completo de utilidades para resolver problemas sus controladores de almacenamiento, entre ellos es:
- perfstat - una utilidad muy útil, se ejecuta típicamente para el personal de servicio técnico de NetApp
- systat - proporciona a la información sobre cómo está ocupado es el limador y lo que está haciendo el limador - biblioteca de la ayuda de NetApp
Hay entre los comandos mas comunes:
sysstat -x 2
sysstat -M 2
Aquí están algunas cosas a buscar en el sysstat - x 2 hecho salir que pudo indicar el arsenal sobrecargado o los discos de NetApp:
- Columna ty continua CP con las porciones de: o F
- Columna continua uso HDD sobre el 20%
Este artículo describe cómo configurar NetApp: Mejores prácticas del almacenamiento de los Ethernetes de NetApp.
- El marcar con etiqueta del VLA N
- Enlace del VLA N
- MTU enorme
- Picado IP
- Control de flujos de la neutralización
VMware
ESXi proporciona al acceso del Secure Shell (SSH), con el cual usted puede resolver problemas. Entre la mayoría de las herramientas útiles proporcionadas a los administradores son el esxtop y el perfmon.
- esxtop - como el top Linux/BSD, permite que los usuarios vigilen los parámetros relacionados con el funcionamiento en tiempo real
Usando el esxtop para identificar los problemas de rendimiento del almacenamiento para ESX/ESXi - perfmon - permite que los usuarios resuelvan problemas las máquinas virtuales de Microsoft Windows (la VM)
Recogida de los datos de registro de Windows Perfmon para diagnosticar los problemas de rendimiento de la máquina virtuales - Recoja el manojo de diagnóstico en ESXi - Recogiendo la información de diagnóstico para VMware ESX/ESXi usando el cliente del vSphere (653)
- Requisito del Equilibrio de carga del vSwitch de VMware para los servidores de las B-series de Cisco - la ruta basada en el hash IP no se utiliza con los servidores de la cuchilla de Cisco UCS B200 M1/M2 que utilizan las 6100 Series UCS que la tela interconecta
Problemas conocidos y mejoras
- ID de bug CSCuj86736 de Cisco - con los errores pasivos CRC de los cables del twinax puede aumentar. Se causa esto cuando el nexo 5000 no optimiza DFE. Ingrese el comando interno del ojo del carmel de la dotación física de la demostración para verificar que “el parámetro de la altura del ojo” está sobre 100 milivoltio. Esto fue fijada en las versiones 5.2(1)N1(7) y 7.0(4)N1(1).
- El ID de bug CSCuo76425 de Cisco - similar al bug anterior y también existe en la tela UCS interconecta. Esto se fija en la versión 2.2(3a).
- ID de bug CSCuo76425 de Cisco - lo mismo que introducen errores de funcionamiento CSCuj86736 a excepción de la interconexión de la tela UCS.
- El ID de bug CSCup40056 de Cisco - problema de sincronización causado compartiendo del tráfico del cargador del programa inicial con el tráfico VM descrito en la migración viva de la máquina virtual del sistema de la Computación unificada falla con los adaptadores de canal virtuales de la fibra.
- Detección y evitación lentas del dren - muy a menudo FC y FCoE son afectados por el dren lento. La versión NX-OS 7.0(0)N1(1) introduce los medios de detectarlo y de evitar. Aprenda más sobre la característica en la guía de configuración de los interfaces de las 5500 Series NX-OS del nexo de Cisco y reduzca la detección del dispositivo del dren y la evitación de la congestión.
- ID de bug CSCuj81245 de Cisco - una limitación existe en los indicadores luminosos LED amarillo de la placa muestra gravedad menor basados PALO (VIC1240 y otros) ese los abortos de las causas FC.
- ID de bug CSCuh61202 de Cisco - después de que la mejora para release/versión 2.1(3), los firmwares FC UCS aborta y el múltiplo otros problemas puede ser considerado.
- ID de bug CSCtw91018 de Cisco - una mezcla de configuraciones de MTU para VNICs en un adaptador solo, PALO-basado puede causar el hambre para algunas de las clases de tráfico.
- El ID de bug CSCuq40256 de Cisco - hará PFC ser inhabilitado en los links de la interconexión de la tela abajo a los adaptadores del servidor. Esto causará la variedad de problemas que comienza con los abortos del canal de la fibra y echan a un lado los marcos fuera de servicio señalados sobre el almacenamiento. Las desconexiones del almacenamiento y otros problemas de rendimiento pudieron ser señalados.
Casos TAC
En muchos de los casos, el ingeniero de TAC pedirá que usted recoja una cierta información básica antes de que una investigación pueda ser comenzada.
- Diagrama de topología - que incluye los números del puerto y las velocidades de línea, absolutamente necesario.
- Soporte técnico UCSM - Guía visual para recoger los ficheros del soporte técnico (B y serie C).
- Soporte técnico del chasis UCS para un chasis que experimente los problemas - vea el link anterior.
- Ambos Soporte técnico del nexo 5000 y cualquier otros dispositivos de red entre el UCS y el NetApp - reorientando la salida de los detalles de la tecnología-ayuda de la demostración ordene.
- Salida del comando show queueing interface en ambos FIs.
connect nxos A|B
show queuing interface | no-more
show interface priority-flow-control | no-more
show interface flowcontrol | no-more. - Las versiones del driver del host en el ESXi se realizan - ingrese estos comandos:
- vmkload_mod - s enic
- vmkload_mod - s fnic
- Linux -
dmesg | egrep -i 'enic|fnic'
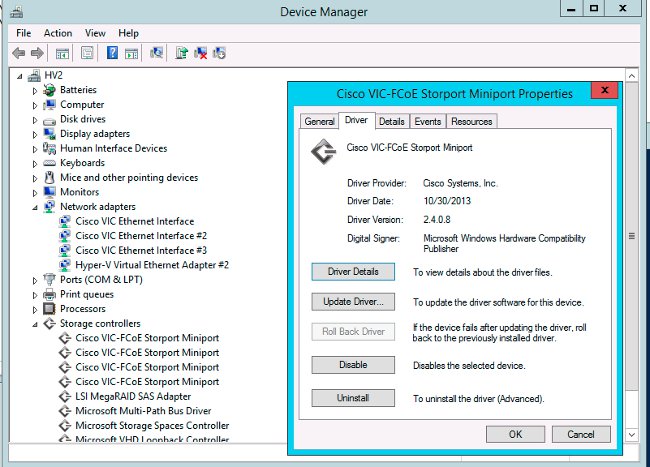
- Windows - controle la versión del driver en el “administrador de dispositivos”. Un ejemplo de las demostraciones R2 de la ventana 2012 tres interfaces de los Ethernetes de Cisco VIC y cuatro interfaces del miniport de VIC FCoE (responsables también del canal de la fibra, no sólo FCoE) y versión 2.4.0.8 del driver fnic.
Comentarios
Utilice el botón Feedback Button para proporcionar al feedback sobre este documento o sus experiencias. Pondremos al día continuamente este documento como ocurren los progresos y después del feedback nos recibimos.
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
1.0 |
20-Feb-2015 |
Versión inicial |
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)