Introducción
Este documento describe el sistema RMA proactivo. Al aprovechar la telemetría de los productos conectados, Cisco puede ofrecer una experiencia al cliente casi sin esfuerzo cuando los productos experimentan ciertos fallos. Sin interacción humana, se autorizarán de forma proactiva una solicitud de servicio (SR) y una autorización de devolución de mercancía (RMA) para reducir significativamente el tiempo que transcurre entre el fallo y la sustitución. Este documento cubre información sobre este programa, qué acciones deben realizar los clientes, los dispositivos/problemas cubiertos por este programa y las configuraciones disponibles (opt-out, configuración de contacto).
Requirements
- El dispositivo afectado debe estar conectado y reclamarse a Intersight Cloud directamente o a través de un dispositivo virtual conectado (el dispositivo es compatible desde julio de 2021). Consulte la guía de inicio de Intersight para obtener información sobre cómo conectar y solicitar un dispositivo. No se admiten dispositivos virtuales privados. Lea la sección específica de Nutanix para conocer las advertencias y los requisitos de dichos dispositivos.
- En el caso de los dispositivos virtuales conectados, debe activarse la RMA proactiva. Consulte aquí para obtener más información sobre cómo activarla.
- El dispositivo afectado debe estar cubierto por un contrato de soporte válido (por ejemplo: Smart Net Total Care (SNTC), que autoriza la sustitución de hardware.
- No se necesita ninguna licencia para Intersight SaaS (sin nivel de licencia); se requiere un mínimo de Essentials en el dispositivo virtual conectado (CVA).
Alcance
Todos los clientes y dispositivos que cumplan con los requisitos establecidos están dentro del alcance. Este programa funciona con la opción de no participar, aunque para funcionar en appliances virtuales conectados debe activarse la función RMA proactiva. Aparte de los tipos de fallos mencionados en este documento, se tienen en cuenta otros escenarios o fallos de hardware para la cobertura de este programa.
Errores de memoria
Fallos de memoria de UCS (fallo no operativo de DIMM F0185, código de fallo de IMM MemoryUnitUncorrectableError). Estos representan errores incorregibles, así como DIMM en el mismo canal para DIMM que han experimentado un error incorregible (UECC). Aunque los DIMM que se encuentran en el mismo canal experimentarán un fallo F0185 anterior a la versión 4.2(2a), no han fallado realmente y no serán reemplazados. Consulte Cisco bug ID CSCvt29521 para obtener más información sobre este comportamiento. Nota: Todos los modos de gestión (autónomo, UMM - Modo gestionado UCSM, IMM - Modo gestionado de intersección) son compatibles con este tipo de fallo.
Advertencias:
- Los servidores que experimenten más de un fallo DIMM degradado/no operativo no están cubiertos. Los clientes tendrán que abrir manualmente casos para estos problemas.
- Se excluirán los casos de ID de error de Cisco CSCvo48003 ("M4 Blade - Patrol Scrubber registra la dirección DIMM con límite de 4k") o de ID de error de Cisco CSCvo48006 ("M4 Rack - Patrol Scrubber registra la dirección DIMM con límite de 4k"). Los clientes pueden abrir un caso TAC para estos y evaluar el impacto del error en su entorno.
Fallos de unidad de UCS
Esta característica cubre los errores de disco de UCS (códigos de error de UCS F1732, F0181, F0996 y códigos de error de IMM StoragePhysicalDiskFailed, StoragePhysicalDiskOffline, StoragePhysicalDiskPredictiveFailure, StoragePhysicalDiskSelfTestFail y StoragePhysicalDiskUnConfiguredBad). Las unidades en estado Fallo predictivo o Fallo generan estos fallos y están cubiertas.
Advertencias:
- Discos con fallos pero en un estado aparente sin fallos (ejemplo : configuración externa, copia, reconstrucción, etc.).
- Los discos que utilizan un controlador de almacenamiento HBA de paso a través o no RAID o los discos en modo JBOD rara vez tendrán suficiente evidencia de registro en los archivos de soporte técnico para determinar si un disco ha fallado y no será reemplazado si no se puede encontrar evidencia. Un subconjunto de fallos de disco en un HBA no RAID crea un fallo adecuado y tiene suficiente evidencia de registro para ser incluida. Consulte las secciones Falla de la unidad Hyperflex y Fallas de la unidad Nutanix para conocer las situaciones en las que se admitirán unidades de paso HBA.
Fallas de unidad Hyperflex
Error permanente de almacenamiento en caché y discos persistentes en Hyperflex (a veces llamado: Lista negra / Fallo permanentemente / Retirado) están cubiertos por esta función.
Nota: El clúster se recuperará automáticamente y estará en buen estado poco después de que el disco falle; en estos casos, aún debe reemplazarse un disco.
Advertencias:
- Los clústeres con más de una falla de unidad no se operarán en.
- Las unidades que coincidan con FN70234 se excluirán.
- Se excluirán las unidades que coincidan con los modelos afectados por el Id. de bug Cisco CSCvo58565.
Fallos del ventilador de la serie C
Se admiten los errores de ventilador en un servidor de la serie C que se encuentre en modo independiente, UMM (UCSM Managed Mode) o IMM (Intersight Managed Mode). Códigos de fallo: F0484, F0397, F0794 están dentro del alcance.
Advertencias:
- Es probable que varios fallos de ventilador al mismo tiempo no sean fallos de hardware de ventilador y no se admitan en este momento
- Los fallos transitorios del ventilador no generarán un caso de RMA proactivo
Fallos del ventilador de Fabric Interconnect
Se admiten los fallos de ventilador en Fabric Interconnect que se encuentra en UMM (UCSM Manged Mode). Códigos de fallo: F0484, F0397 están dentro del alcance.
Advertencias:
- Aún no se admiten los FI administrados de IMM
- Es probable que varios fallos de ventilador al mismo tiempo no sean fallos de hardware de ventilador y no se admitan en este momento
Fallos de unidad Nutanix
Se admiten las unidades que hayan fallado en clústeres de Nutanix en hardware de Cisco.
Advertencias:
- Nutanix clúster debe estar conectado a Nutanix nube
- El correo electrónico de Nutanix BreakFixContact se debe configurar o el hardware se debe conectar a Intersight.
- El usuario de BreakFixContact o de Intersight debe tener derecho a abrir casos para el contrato que cubre el servidor en cuestión.
Qué esperar
Cuando se produce un evento de fallo cubierto, se genera una SR y una RMA. Puntos de interés:
- Los correos electrónicos serán enviados desde sherholm@cisco.com.
- El caso se creará con el correo electrónico configurado (consulte la sección de configuración avanzada a continuación) o con el último usuario autorizado que haya iniciado sesión en Intersight.
- Los demás usuarios de la cuenta Intersight autorizados en virtud del contrato se copian en el correo electrónico. Si los usuarios se configuran explícitamente (mediante etiquetas, consulte la sección Configuración avanzada (opcional)), solo los usuarios configurados recibirán el correo electrónico.
- Cualquier usuario autorizado puede tomar posesión de la RMA y rellenar los datos necesarios. En la herramienta RMA hay una opción de transferencia de propiedad.
- La herramienta RMA de Cisco (Product Returns and Replacement - PRR) enviará recordatorios para completar el borrador de RMA al usuario con el que se abrió el caso.
Después de crear la solicitud de servicio, los clientes recibirán un correo electrónico que describe el problema y proporciona pasos procesables. A continuación se incluye un ejemplo:
From: sherholm@cisco.com
To: bob@example.com
Subject: [Action Required] SR: 600000000 - Proactive Replacement of Memory Module [Connected via Intersight]
Hello Bob,
I am writing to let you know that Cisco has received a fault message from your Cisco UCS server connected by Cisco Intersight.
The fault indicates that a memory DIMM module has failed and needs replacing. I have automatically created a TAC Case for
you (SR 600000000) and have created the RMA to ship you the replacement DIMM. I just need you to click the RMA link and
verify your shipping address so the replacement part can be shipped out to you: https://ibpm.cisco.com/rma/home/?RMANumber=800000000
Note: If you have difficulty loading the link above, please contact LSC at one of the following manners:
https://www.cisco.com/c/en/us/buy/logistics-support-center.html
Here is some more information about the failed DIMM and the server it's installed in:
Domain Name: ucs-domain
Domain IP Address: 192.0.2.1
Server Serial Number: SERIAL
Server Name: HOSTNAME
Server Service Profile: org-root/SERVICEPROFILENAME
Server User Label: USER_LABEL
Fault Description: DIMM DIMM_H1 on server 1/1 operability: inoperable
Link to server in Intersight: https://intersight.com/an/compute/physical-summaries/moid/server/
Link to Fault in Intersight: https://intersight.com/an/cond/alarms/?Moid=moid
Hardware replacement guide available here:
<link to replacement guide for the specific server type>
For more information on this feature of Intersight see:
<link to this document>
Please let me know if you have further questions,
Sincerely,
Sherlock
Technical Consulting Engineer, Virtual
Cisco Customer Experience
Email: sherholm@cisco.com
Beneficios
- Reducción significativa del esfuerzo necesario para recibir una pieza de repuesto.
- Creación automática de SR: tiempo de reacción al evento más rápido.
- Autorización previa de RMA.
- Posibilidad de cumplimentar los datos de la RMA inmediatamente después del contacto.
- Recopilación automática de datos de diagnóstico objetivo.
- Exclusión de defectos de software: los fallos de software que aparecen como fallos de hardware no generarán RMA innecesarios.
Detalles adicionales
Detalles del flujo de trabajo
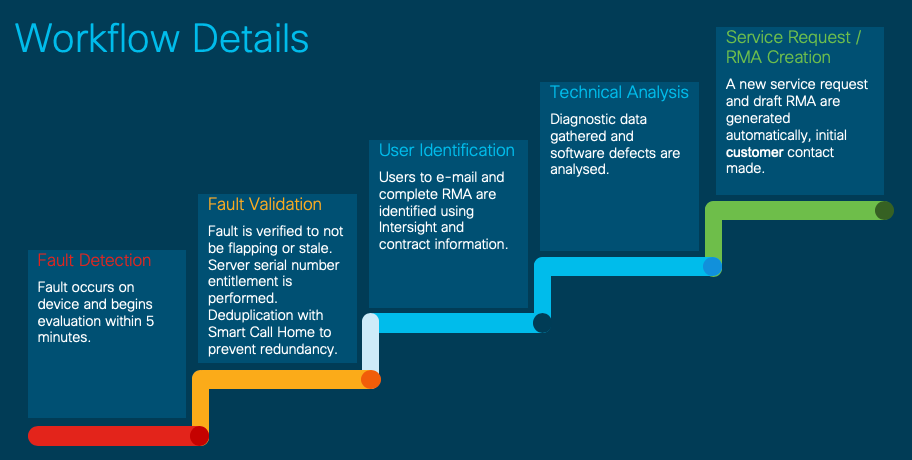
Configuración avanzada (opcional)
En este momento se admiten dos opciones de configuración avanzada. Las opciones de configuración se establecen mediante etiquetas dentro de Intersight.
Las etiquetas descritas en esta sección se pueden configurar en cualquiera de los objetos de la lista en Intersight:
- Cuenta (mediante GUI)
- Organización (mediante API)
- Dispositivo de destino/registrado (mediante API)
Para los clientes con el dispositivo virtual conectado, las etiquetas se pueden configurar en el propio dispositivo o en Intersight Cloud.
Para obtener más información sobre las etiquetas de configuración, consulte el documento Etiquetas de configuración en Intersight.
Configuración explícita de un contacto
Los clientes pueden configurar explícitamente las direcciones de correo electrónico que desean asociar tanto con el SR como con la RMA. El nombre/clave de la etiqueta es "AutoRAMmail" y el valor es una lista CSV de correos electrónicos a los que desea notificar y a los que desea otorgar derechos para el caso. La RMA proactiva utilizará una primera base de coincidencia y analizará los correos electrónicos de izquierda a derecha. Por ejemplo, si utiliza "user@example.com,user2@example.com", user@example.com se intentará en primer lugar, aunque se copiarán todos los correos electrónicos.

Nota: Advertencia: Para que se abra un caso, al menos un correo electrónico de la lista CSV debe estar correlacionado con una cuenta CCO válida asociada al contrato que cubre el número de serie del dispositivo.
En otras palabras, si ninguna de las direcciones de AutoRMAEmail está en el contrato que cubre el dispositivo, entonces las direcciones de AutoRMAEmail serán ignoradas.
La RMA proactiva volverá al comportamiento predeterminado de enviar por correo electrónico a todos los usuarios que tengan una cuenta Intersight y estén en el contrato que cubre el dispositivo.
Tenga en cuenta que Intersight tiene un límite de caracteres para etiquetas de 255 caracteres. Debido a esto, RMA proactiva admite cualquier etiqueta que comience con AutoRMAmail (por ejemplo: AutoRMAEmail1, AutoRMAEmail2) y concatenará todos los valores juntos.
Si utiliza la API para configurar etiquetas, la etiqueta debe tener un aspecto similar a:
{"Key":"AutoRMAEmail","Value":"email1@example.com,email2@example.com"}
Consulte el documento Configuración de etiquetas en Intersight para obtener información detallada sobre las etiquetas.
Cancelación de RMA proactivos
Para no participar,
Si utiliza la API, la etiqueta debe ser como se muestra a continuación.
{"Key":"AutoRMA","Value":"False"}
Para volver a suscribirse a RMA proactivos (si se ha excluido), los usuarios pueden eliminar la etiqueta por completo o cambiarla por:
{"Key":"AutoRMA","Value":"True"}
Tenga en cuenta que los usuarios NO tienen que suscribirse mediante etiquetas si no lo han hecho, sino que se activan automáticamente a menos que lo hayan hecho.
Preguntas frecuentes
A: ¿Qué información recopilará Cisco para estos fallos?
R: Detalles del fallo (tiempo/dispositivo/etc.), información del inventario (modelo/serie/firmware), datos de diagnóstico aplicables (p. ej.: CIMC/UCSM/HX (Asistencia técnica).
A: ¿Cuál es el tiempo de reacción?
R: Normalmente, los casos se abren y la RMA se crea en el plazo de una hora tras producirse el fallo. Esto incluye todo el tiempo necesario para generar y procesar los datos de diagnóstico adecuados.
A: ¿Quién puede enviar la RMA?
R: Cualquier usuario autorizado en el contrato al que esté cubierto el dispositivo puede enviar la RMA, no es necesario que sea la misma persona que es el contacto en la solicitud de servicio del TAC. La RMA se asocia inicialmente a una cuenta CCO específica. Los usuarios que deseen cumplimentar la RMA pueden hacer clic en el botón "Acciones" situado en la esquina superior derecha de la RMA y seleccionar "Transferir asignación". En la siguiente pantalla, deje su CCO rellenado en el cuadro de entrada y haga clic en "Enviar".
A: Aparece un error al cargar el RMA. ¿Cómo puedo enviarlo?
R: Ocasionalmente, las cookies obsoletas o la caché del navegador pueden causar problemas al cargar el RMA. Intente primero cargar el RMA en una ventana de navegación privada o en un navegador diferente. Si el problema continúa, por favor, envíenos un correo electrónico pidiéndonos ayuda.
 Comentarios
Comentarios