Resolución de problemas de fallas de verificación de estado de intersección para clústeres HX
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Introducción
Este documento describe cómo resolver problemas comunes de fallas de Intersight Health Check para clústeres Hyperflex.
Prerequisites
Requirements
Cisco recomienda que tenga conocimiento sobre estos temas:
- Comprensión básica del protocolo de tiempo de red (NTP) y del sistema de nombres de dominio (DNS).
- Comprensión básica de la línea de comandos de Linux.
- Conocimientos básicos de VMware ESXi.
- Comprensión básica del editor de texto VI.
- Operaciones de clúster de hiperflex.
Componentes Utilizados
La información de este documento se basa en:
Hyperflex Data Platform (HXDP) 5.0.(2a) y superior
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
Cisco Intersight ofrece la capacidad de ejecutar una serie de pruebas en un clúster Hyperflex para garantizar que el estado del clúster se encuentre en condiciones óptimas para las operaciones diarias y las tareas de mantenimiento.
A partir de HX 5.0(2a), Hyperflex introduce una cuenta de usuario diag con privilegios escalados para la resolución de problemas en la línea de comandos de Hyperflex. Conéctese a la IP de administración de clústeres de hiperflex (CMIP) utilizando SSH como usuario administrativo y luego cambie a diag user.
HyperFlex StorageController 5.0(2d)
admin@192.168.202.30's password:
This is a Restricted shell.
Type '?' or 'help' to get the list of allowed commands.
hxshell:~$ su diag
Password:
____ __ _____ _ _ _ _____
| ___| / /_ _ | ____(_) __ _| |__ | |_ |_ _|_ _____
|___ \ _____ | '_ \ _| |_ | _| | |/ _` | '_ \| __| _____ | | \ \ /\ / / _ \
___) | |_____| | (_) | |_ _| | |___| | (_| | | | | |_ |_____| | | \ V V / (_) |
|____/ \___/ |_| |_____|_|\__, |_| |_|\__| |_| \_/\_/ \___/
|___/
Enter the output of above expression: 5
Valid captcha
diag#Troubleshoot
Corregir la comprobación de ESXi VIB "Algunos de los VIB instalados utilizan VmkAPI obsoletas"
Al actualizar a ESXi 7.0 y versiones posteriores, Intersight garantiza que los hosts ESXi de un clúster Hyperflex no tengan controladores creados con dependencias de versiones antiguas de vmkapi. VMware proporciona una lista de los paquetes de instalación de vSphere (VIB) afectados y describe este problema en este artículo: KB 78389
Inicie sesión en la interfaz de usuario (IU) web de Hyperflex Connect y navegue hasta Información del sistema. Haga clic en Nodes y seleccione el nodo Hyperflex (HX). A continuación, haga clic en Introducir modo de mantenimiento HX.
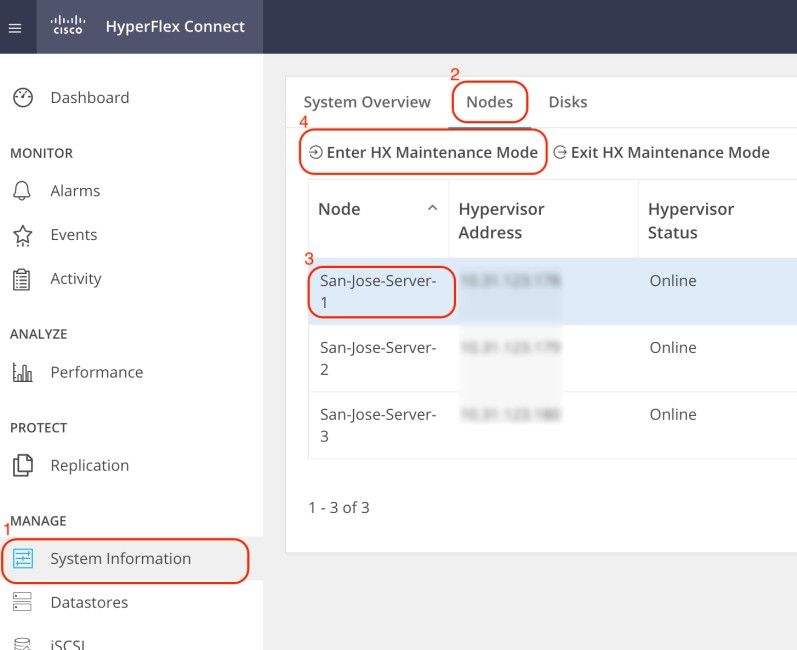
Utilice un cliente SSH para conectarse a la dirección IP de gestión del host ESXi. A continuación, confirme los VIB en el host de ESXi con este comando:
esxcli software vib listRetire el VIB con este comando:
esxcli software vib remove -n driver_VIB_nameReinicie el host de ESXi. Cuando vuelva a estar en línea, en HX Connect, seleccione el nodo HX y haga clic en Exit HX Maintenance Mode.
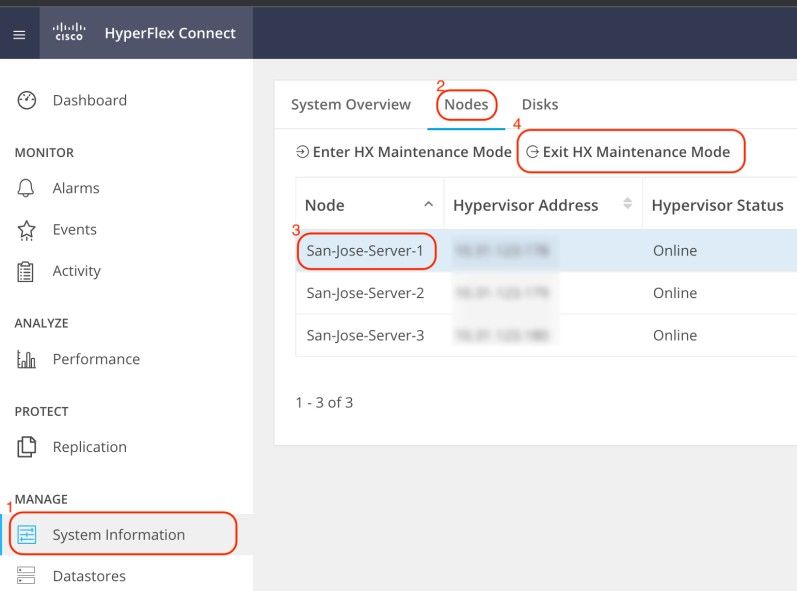
Espere a que el clúster HX se vuelva saludable. A continuación, realice los mismos pasos para los otros nodos del clúster.
Reparar vMotion habilitado "VMotion está deshabilitado en el host de ESXi"
Esta comprobación garantiza que vMotion está habilitado en todos los hosts ESXi del clúster HX. Desde vCenter, cada host de ESXi debe tener un switch virtual (vSwitch), así como una interfaz vmkernel para vMotion.
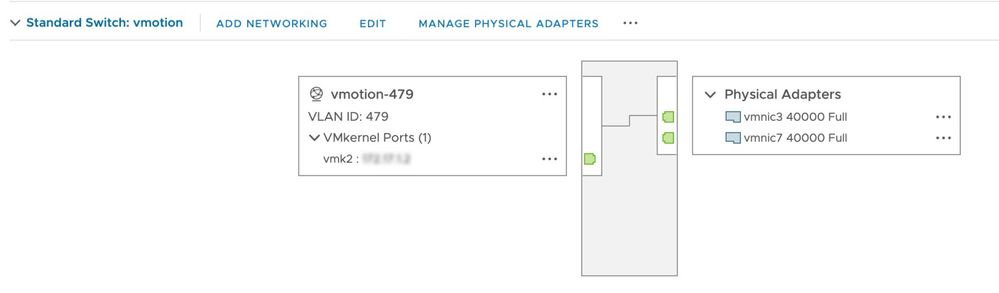
Conéctese a la IP de administración de clústeres Hyperflex (CMIP) usando SSH como usuario administrativo y luego ejecute este comando:
hx_post_installSeleccione la opción 1 para configurar vMotion:
admin@SpringpathController:~$ hx_post_install
Select hx_post_install workflow-
1. New/Existing Cluster
2. Expanded Cluster (for non-edge clusters)
3. Generate Certificate
Note: Workflow No.3 is mandatory to have unique SSL certificate in the cluster. By Generating this certificate, it will replace your current certificate. If you're performing cluster expansion, then this option is not required.
Selection: 1
Logging in to controller HX-01-cmip.example.com
HX CVM admin password:
Getting ESX hosts from HX cluster...
vCenter URL: 192.168.202.35
Enter vCenter username (user@domain): administrator@vsphere.local
vCenter Password:
Found datacenter HX-Clusters
Found cluster HX-01
post_install to be run for the following hosts:
HX-01-esxi-01.example.com
HX-01-esxi-02.example.com
HX-01-esxi-03.example.com
Enter ESX root password:
Enter vSphere license key? (y/n) n
Enable HA/DRS on cluster? (y/n) y
Successfully completed configuring cluster HA.
Disable SSH warning? (y/n) y
Add vmotion interfaces? (y/n) y
Netmask for vMotion: 255.255.254.0
VLAN ID: (0-4096) 208
vMotion MTU is set to use jumbo frames (9000 bytes). Do you want to change to 1500 bytes? (y/n) y
vMotion IP for HX-01-esxi-01.example.com: 192.168.208.17
Adding vmotion-208 to HX-01-esxi-01.example.com
Adding vmkernel to HX-01-esxi-01.example.com
vMotion IP for HX-01-esxi-02.example.com: 192.168.208.18
Adding vmotion-208 to HX-01-esxi-02.example.com
Adding vmkernel to HX-01-esxi-02.example.com
vMotion IP for HX-01-esxi-03.example.com: 192.168.208.19
Adding vmotion-208 to HX-01-esxi-03.example.com
Adding vmkernel to HX-01-esxi-03.example.com
Nota: Para los clústeres perimetrales implementados con HX Installer, la secuencia de comandos hx_post_install debe ejecutarse desde la CLI de HX Installer.
Corregir comprobación de conectividad de vCenter "Error en comprobación de conectividad de vCenter"
Conéctese a la IP de administración de clústeres Hyperflex (CMIP) utilizando SSH como usuario administrativo y switch para diagnosticar al usuario. Asegúrese de que el clúster HX esté registrado en vCenter con este comando:
diag# hxcli vcenter info
Cluster Name : San_Jose
vCenter Datacenter Name : MX-HX
vCenter Datacenter ID : datacenter-3
vCenter Cluster Name : San_Jose
vCenter Cluster ID : domain-c8140
vCenter URL : 10.31.123.186La URL del vCenter debe mostrar la dirección IP o el nombre de dominio completo (FQDN) del servidor del vCenter. Si no muestra la información correcta, vuelva a registrar el clúster HX con vCenter con este comando:
diag# stcli cluster reregister --vcenter-datacenter MX-HX --vcenter-cluster San_Jose --vcenter-url 10.31.123.186 --vcenter-user administrator@vsphere.local
Reregister StorFS cluster with a new vCenter ...
Enter NEW vCenter Administrator password:
Cluster reregistration with new vCenter succeededAsegúrese de que haya conectividad entre HX CMIP y vCenter con estos comandos:
diag# nc -uvz 10.31.123.186 80
Connection to 10.31.123.186 80 port [udp/http] succeeded!
diag# nc -uvz 10.31.123.186 443
Connection to 10.31.123.186 443 port [udp/https] succeeded!Corregir comprobación de estado del limpiador "Error de comprobación del limpiador"
Conéctese a Hyperflex CMIP usando SSH como usuario administrativo y luego cambie a diag user. Ejecute este comando para identificar el nodo en el que no se está ejecutando el servicio de limpieza:
diag# stcli cleaner info
{ 'type': 'node', 'id': '7e83a6b2-a227-844b-87fb-f6e78e6a59be', 'name': '172.16.1.6' }: ONLINE
{ 'type': 'node', 'id': '8c83099e-b1e0-6549-a279-33da70d09343', 'name': '172.16.1.8' }: ONLINE
{ 'type': 'node', 'id': 'a697a21f-9311-3745-95b4-5d418bdc4ae0', 'name': '172.16.1.7' }: OFFLINEEn este caso, 172.16.1.7 es la dirección IP de la máquina virtual del controlador de almacenamiento (SCVM) en la que el limpiador no se está ejecutando. Conéctese a la dirección IP de administración de cada SCVM en el clúster mediante SSH y luego busque la dirección IP de eth1 con este comando:
diag# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 00:0c:29:38:2c:a7
inet addr:172.16.1.7 Bcast:172.16.255.255 Mask:255.255.0.0
UP BROADCAST RUNNING MULTICAST MTU:9000 Metric:1
RX packets:1036633674 errors:0 dropped:1881 overruns:0 frame:0
TX packets:983950879 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:723797691421 (723.7 GB) TX bytes:698522491473 (698.5 GB)Inicie el servicio de limpieza en el nodo afectado con este comando:
diag# sysmtool --ns cleaner --cmd startCorregir estado del servicio NTP "El estado del servicio NTPD es INACTIVO"
Conéctese a HX CMIP usando SSH como usuario administrativo y luego cambie a diag user. Ejecute este comando para confirmar que el servicio NTP está detenido.
diag# service ntp status
* NTP server is not runningSi el servicio NTP no se está ejecutando, ejecute este comando para iniciar el servicio NTP.
diag# priv service ntp start
* Starting NTP server
...done.Corregir disponibilidad del servidor NTP "Error de comprobación de disponibilidad de servidores NTP"
Conéctese a HX CMIP usando SSH como usuario administrativo y luego cambie a diag user. Asegúrese de que el clúster HX tiene configurados servidores NTP accesibles. Ejecute este comando para mostrar la configuración NTP en el clúster.
diag# stcli services ntp show
10.31.123.226Asegúrese de que haya conectividad de red entre cada SCVM del clúster HX y el servidor NTP del puerto 123.
diag# nc -uvz 10.31.123.226 123
Connection to 10.31.123.226 123 port [udp/ntp] succeeded!En caso de que el servidor NTP configurado en el clúster ya no esté en uso, puede configurar un servidor NTP diferente en el clúster.
stcli services ntp set NTP-IP-Address
Advertencia: stcli services ntp set sobrescribe la configuración actual de NTP en el clúster.
Corregir disponibilidad del servidor DNS "Error en la comprobación de disponibilidad de DNS"
Conéctese a HX CMIP usando SSH como usuario administrativo y luego cambie a diag user. Asegúrese de que el clúster HX tiene configurados servidores DNS accesibles. Ejecute este comando para mostrar la configuración DNS en el clúster.
diag# stcli services dns show
10.31.123.226Asegúrese de que haya conectividad de red entre cada SCVM del clúster HX y el servidor DNS del puerto 53.
diag# nc -uvz 10.31.123.226 53
Connection to 10.31.123.226 53 port [udp/domain] succeeded!En caso de que el servidor DNS configurado en el clúster ya no esté en uso, puede configurar un servidor DNS diferente en el clúster.
stcli services dns set DNS-IP-AdrressAdvertencia: stcli services dns set sobrescribe la configuración de DNS actual en el clúster.
Corregir versión de VM del controlador "Falta el valor de versión de VM del controlador en el archivo de configuración del host de ESXi"
Esta comprobación garantiza que cada SCVM incluya guestinfo.stctlvm.version = "3.0.6-3" en el archivo de configuración.
Inicie sesión en HX Connect y asegúrese de que el clúster funciona correctamente.
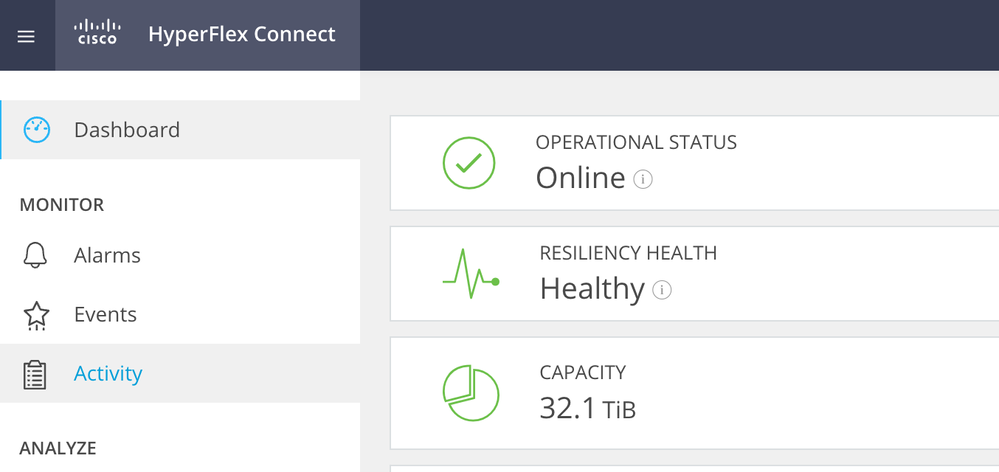
Conéctese a cada host ESXi del clúster mediante SSH con la cuenta raíz. A continuación, ejecute este comando
[root@San-Jose-Server-1:~] grep guestinfo /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx
guestinfo.stctlvm.version = "3.0.6-3"
guestinfo.stctlvm.configrdm = "False"
guestinfo.stctlvm.hardware.model = "HXAF240C-M4SX"
guestinfo.stctlvm.role = "storage"
Precaución: el nombre del almacén de datos y el nombre SCVM pueden ser diferentes en el cluster. Puede escribir Spring y, a continuación, presionar la tecla Tab para completar automáticamente el nombre del almacén de datos. Para el nombre SCVM, puede escribir stCtl y, a continuación, pulsar la tecla Tab para completar automáticamente el nombre SCVM.
Si el archivo de configuración del SCVM no incluye guestinfo.stctlvm.version = "3.0.6-3", inicie sesión en vCenter y seleccione el SCVM. Haga clic en Acciones, diríjase a Encender y seleccione Apagar el SO invitado para apagar el SCVM correctamente.
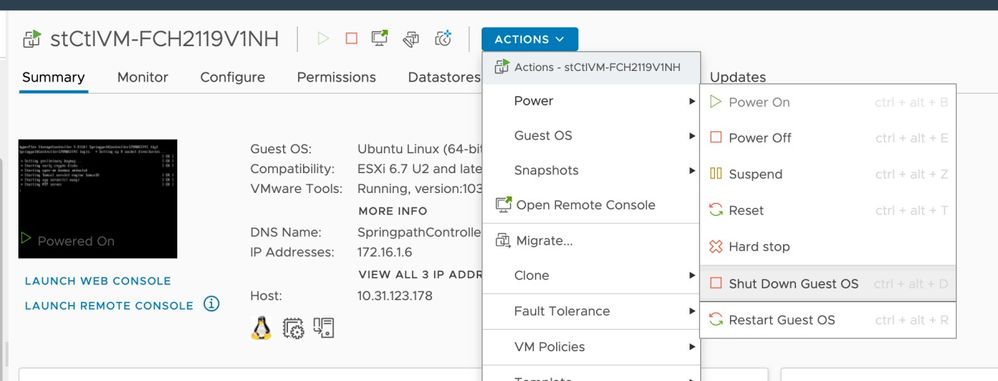
Desde la interfaz de línea de comandos (CLI) de ESXi, cree una copia de seguridad del archivo de configuración de SCVM con este comando:
cp /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx.bakA continuación, ejecute este comando para abrir el archivo de configuración de SCVM:
[root@San-Jose-Server-1:~] vi /vmfs/volumes/SpringpathDS-FCH2119V1NH/stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmxPresione la tecla I para editar el archivo, luego navegue hasta el final del archivo y agregue esta línea:
guestinfo.stctlvm.version = "3.0.6-3"Presione la tecla ESC y escriba :wq para guardar los cambios.
Identifique el ID de máquina virtual (VMID) del SCVM con el comando vim-cmd vmsvc/getallvms y recargue el archivo de configuración del SCVM:
[root@San-Jose-Server-1:~] vim-cmd vmsvc/getallvms
Vmid Name File Guest OS Version Annotation
1 stCtlVM-FCH2119V1NH [SpringpathDS-FCH2119V1NH] stCtlVM-FCH2119V1NH/stCtlVM-FCH2119V1NH.vmx ubuntu64Guest vmx-15
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1Recargue y encienda el SCVM con estos comandos:
[root@San-Jose-Server-1:~] vim-cmd vmsvc/reload 1
[root@San-Jose-Server-1:~] vim-cmd vmsvc/power.on 1Advertencia: en este ejemplo, el VMID es 1.
Debe esperar a que el clúster HX vuelva a funcionar correctamente antes de pasar al siguiente SCVM.
Repita el mismo procedimiento en los SCVM afectados de uno en uno.
Por último, inicie sesión en cada SCVM mediante SSH y cambie para acceder a la cuenta de usuario. Reinicie stMgr nodo a nodo con este comando:
diag# priv restart stMgr
stMgr start/running, process 22030Antes de pasar al siguiente SCVM, asegúrese de que stMgr esté completamente operativo con este comando:
diag# stcli about
Waiting for stmgr management server on port 9333 to get ready . .
productVersion: 5.0.2d-42558
instanceUuid: EXAMPLE
serialNumber: EXAMPLE,EXAMPLE,EXAMPLE
locale: English (United States)
apiVersion: 0.1
name: HyperFlex StorageController
fullName: HyperFlex StorageController 5.0.2d
serviceType: stMgr
build: 5.0.2d-42558 (internal)
modelNumber: HXAF240C-M4SX
displayVersion: 5.0(2d)Información Relacionada
Precaución: en este ejemplo, el VMID es 1.
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
2.0 |
06-Nov-2023 |
Versión inicial |
1.0 |
11-Oct-2023 |
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Carlos RazoCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)