Introducción
Este documento describe el proceso para volver a implementar un nodo sin conexión en clústeres de Cisco Hyperflex.
Prerequisites
Requirements
Esto sólo es compatible con clústeres Hyperflex implementados desde Intersight y a partir de la versión 5.0(2b). Los clústeres implementados a través del instalador de Hyperflex e importados a Intersight no se admiten para esta función todavía.
Tipo de escenarios admitidos para esta característica de Intersight:
- Clúster FI/estándar, clúster Strech, clúster perimetral y clúster DC-No-FI
- Clústeres con SED (unidades autocifradas)
- Clústeres implementados sólo desde Intersight
- Reimplementación de ESXi y SCVM
- Solo reimplementación de SCVM
Escenarios no admitidos
- Clústeres 1 GbE HyperFlex Edge y Stretch.
- Clústeres importados a Intersight
Licencias
Se requiere una licencia Intersight Essentials o superior para la reimplementación de nodos de HyperFlex. Todos los servidores del clúster de HyperFlex deben reclamarse y configurarse con Intersight Essentials o una licencia superior.
Componentes Utilizados
- Cisco Intersight
- Cisco UCSM (opcional)
- Servidores Cisco UCS
- Cisco Hyperflex Cluster versión 5.0(2c)
- VMWare ESXi
- VMware vCenter
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
Mantener un clúster en buen estado se convierte en una prioridad por varias razones, pero la más importante es la redundancia en aras de la integridad de los datos en la solución de almacenamiento Hypercoverge. Existen varios escenarios que requieren la reimplementación simultánea de ESXi y SCVM (máquina virtual de controlador de almacenamiento), como la sustitución de la unidad de arranque en los nodos convergentes.
En el caso de los clústeres implementados desde Intersight, puede volver a implementar SCVM para volver a agregarlo al clúster Hyperflex. Esta actividad se puede ejecutar ahora sin la asistencia del TAC a través de Intersight.
Advertencia: es importante destacar que si no se realiza este proceso correctamente, pueden producirse varios problemas inesperados en los clústeres, como fallos futuros en las actualizaciones de los clústeres o fallos en las expansiones de los clústeres.
Configuración
Para este ejemplo, utilizamos un clúster de Borde de 3 nodos denominado Medellín que ha dañado el nodo 3 debido a una falla del disco M.2
Desde Intersight nuestro punto de partida asume que ya se cubren un par de aspectos:
- El almacenamiento M.2 ya se ha sustituido
- El clúster de Hyperflex sigue en mal estado porque tiene ese nodo sin conexión
Validación sin conexión del nodo de clúster
Puede ver que el clúster no está en buen estado como se explicó y necesita recuperar el nodo que está desconectado ahora que el problema M.2 se ha corregido
En Intersight, vaya a Infrastructure Service > Hyperflex Cluster > Overview > Events. Podrá ver el estado de resistencia
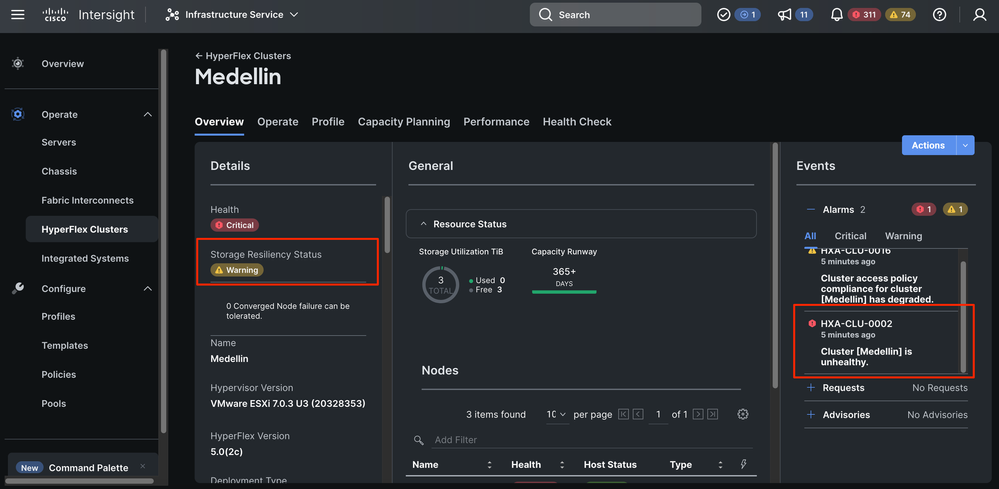
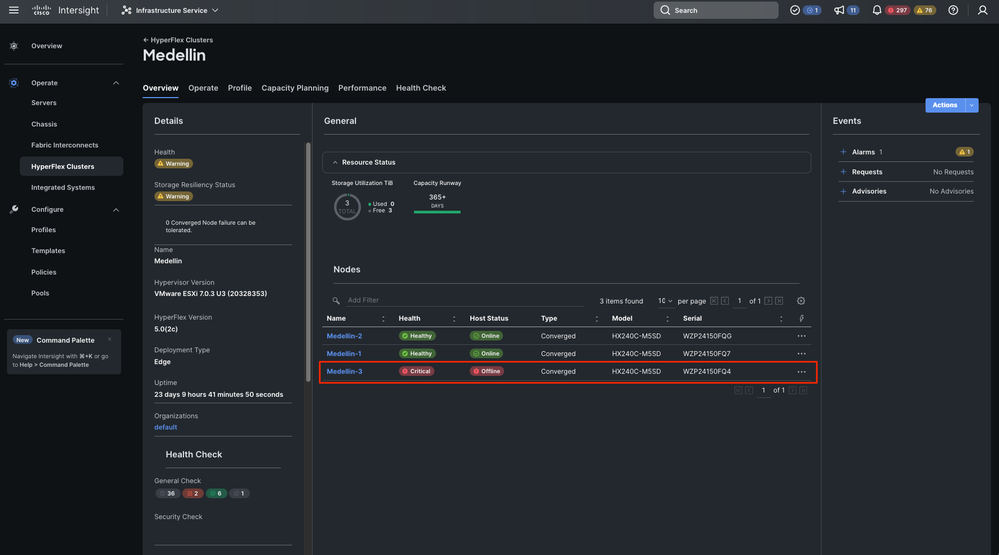
En la misma ficha Descripción general puede ver también qué nodo específico está sin conexión
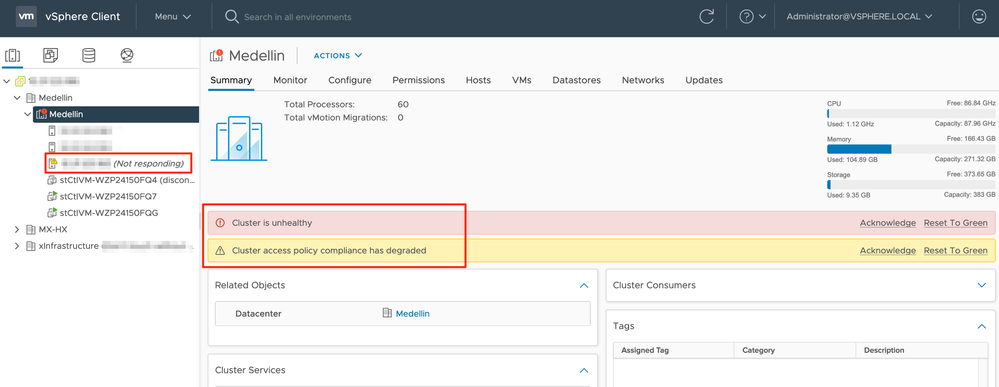
Desde vCenter también recibimos una alerta sobre el estado incorrecto del clúster
Por último, desde CLI también puede evaluar el estado del clúster:
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : WARNING
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 0
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 30.4 GiB
Free Capacity : 3.0 TiB
Compression Savings : 62.06%
Deduplication Savings : 0.00%
Total Savings : 62.06%
# of Nodes Configured : 3
# of Nodes Online : 2
Data IP Address : 169.254.218.1
Resiliency Health : WARNING
Policy Compliance : NON_COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 0
# of persistent device failures tolerable : 1
# of cache device failures tolerable : 1
Zone Type : Unknown
All Flash : No
Pasos de reimplementación
Paso 1. Reinstale el sistema operativo ESXi. Para ello, puede ir a Servidores > Seleccione el Servidor > Opciones (tres puntos) > Seleccione Iniciar el KVM.
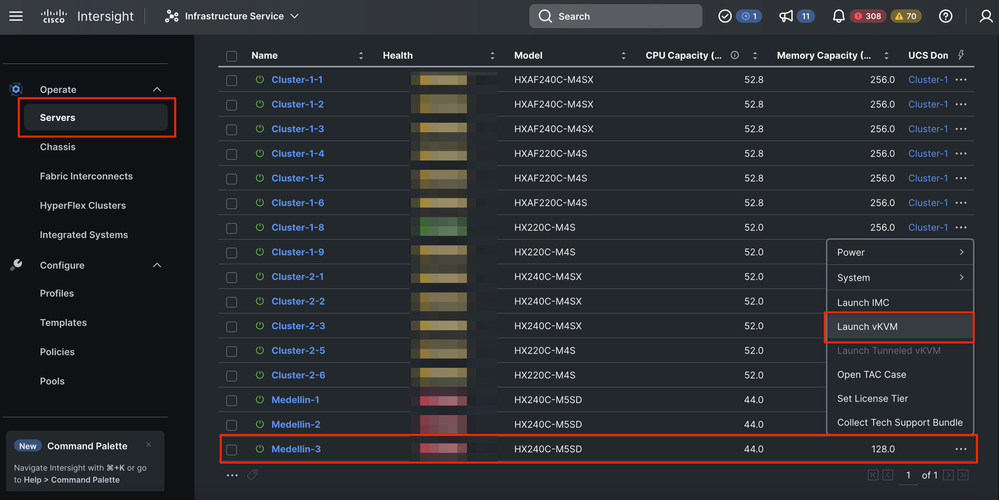
Precaución: debe descargar una imagen personalizada de Cisco Hyperflex para la misma versión exacta de ESXi que otros nodos estén ejecutando en el clúster. Puede descargarlo desde aquí
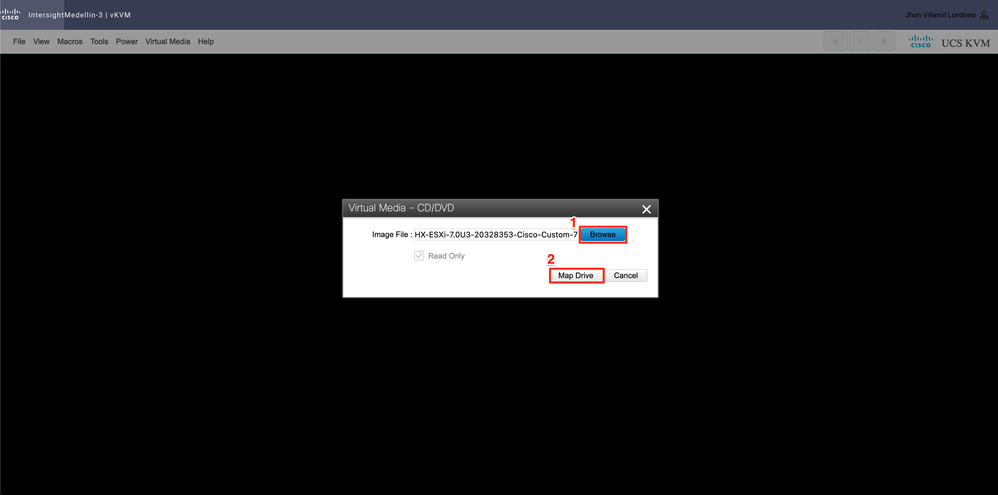
Una vez que se inicie KVM, vaya a Virtual Media > Seleccione Activate Virtual Devices .

A continuación, seleccione Browse > Select the Hyperflex ESXi iso image from your local computer > Select Map Drive
Navegue hasta Power > en función del estado del servidor, seleccione Power on System o Reset System o Power Cycle System 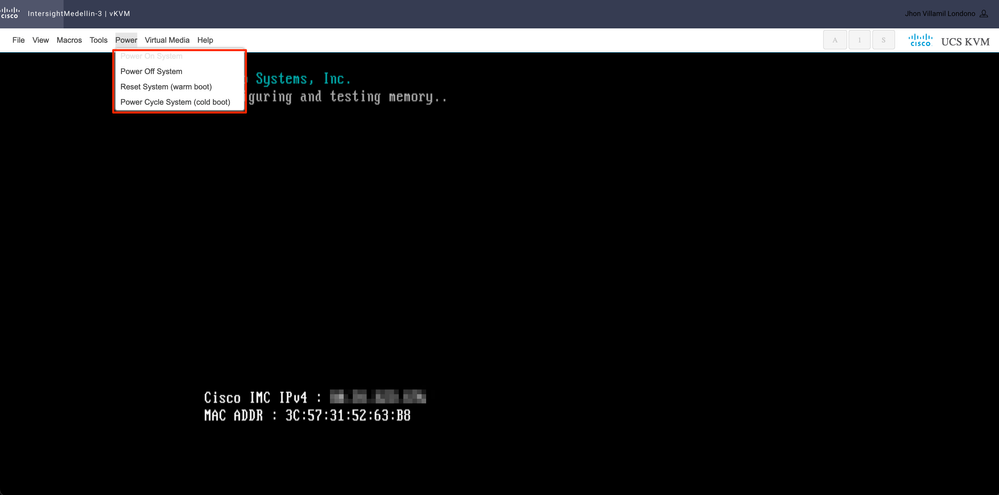
Sugerencia: Reset System (warm boot) reinicia el sistema sin apagarlo, mientras que Power Cycle System (cold boot)apaga el sistema y lo vuelve a encender. En esta situación, con SCVM dañado y ESXi reinstalado, ambas opciones cumplen el mismo propósito
Debe iniciar el dispositivo virtual de CD/DVD. Vaya a Herramientas > Seleccionar teclado > Cuando vea el mensaje del menú de inicio, presione F6
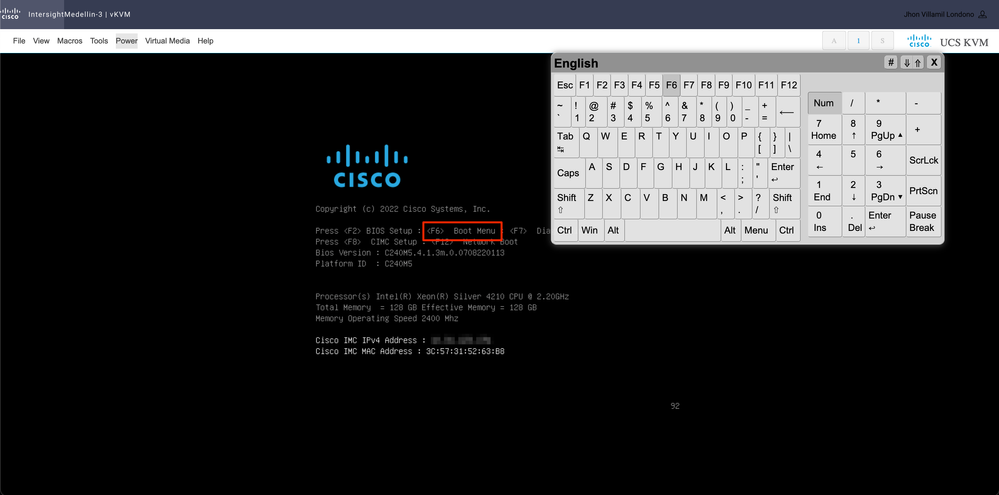
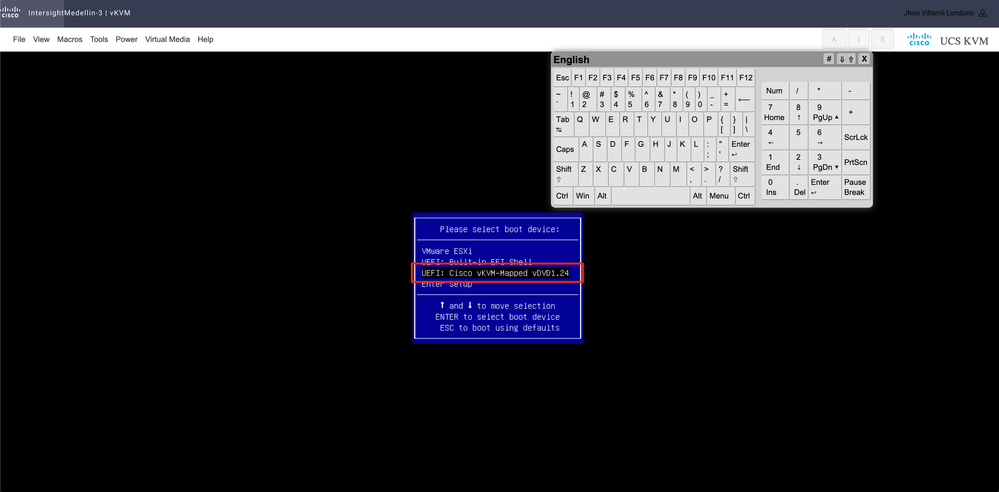
Accederá al menú de arranque y, una vez allí, seleccionará Cisco vKVM-Mapped vDVD1.24 y pulse Intro
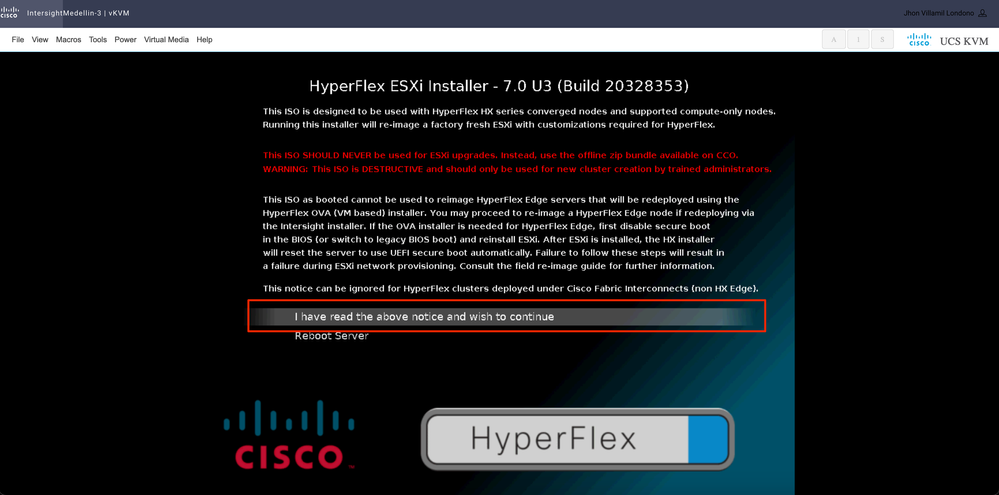
Seleccione He leído el aviso anterior y deseo continuar y pulsar Intro
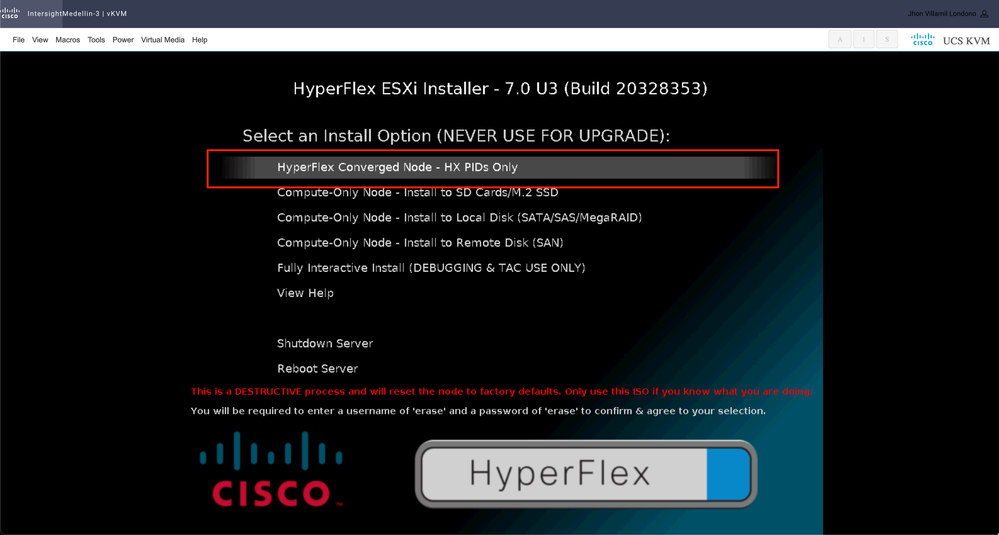
Regularmente se ven diferentes opciones para los nodos informáticos dependiendo del dispositivo de arranque específico que se utilice y otra opción para los nodos convergentes que es la que debe seleccionar aquí
Después se le pedirá que introduzca el nombre de usuario y la contraseña. Escriba username erase > hit Enter > Type password erase > hit ingrese
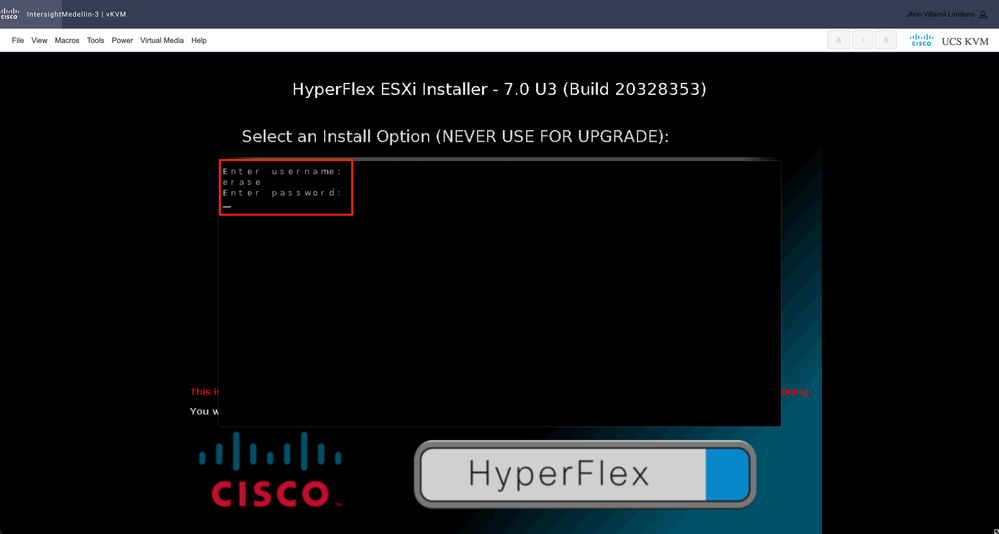
Nota: si se introduce una contraseña o nombre de usuario incorrecto, se le devuelve un paso y puede volver a intentarlo
La instalación comienza en este punto y puede supervisarla a través de vKVM
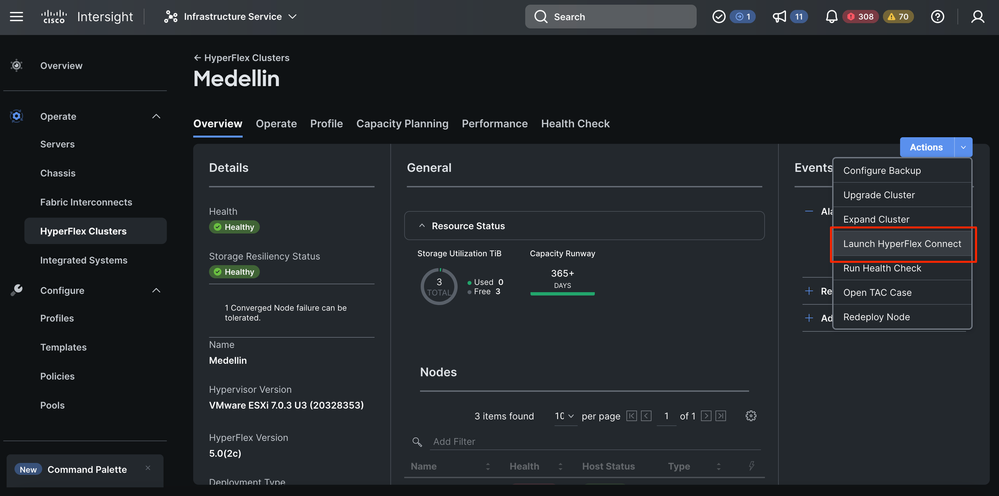
Paso 2. Vaya a Infrastructure Service > Hypeflex Clusters > Seleccione su clúster Hyperflex > Select Actions >Select Redeploy Node
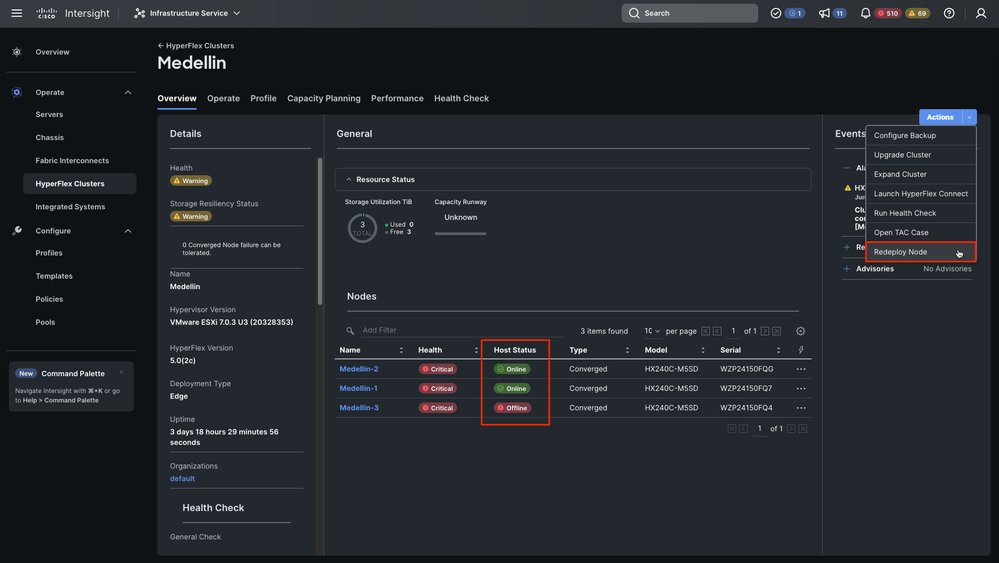

Sugerencia: si sólo SCVM está dañado y necesita volver a instalarse, debe apagar el servidor antes de seleccionar Volver a implementar si no se produce el error "No se puede activar Volver a implementar el nodo porque no hay hosts sin conexión en este clúster".
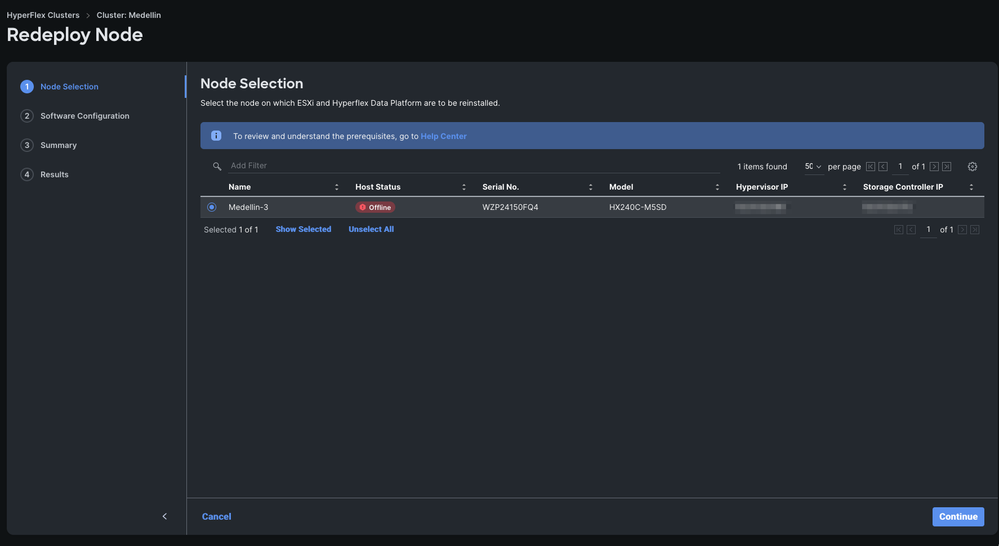
Paso 3. Seleccione el nodo sin conexión > Seleccione Continuar
Paso 4. Compruebe que las directivas de seguridad, vCenter y configuración de proxy se corresponden con el mismo clúster y seleccione Siguiente
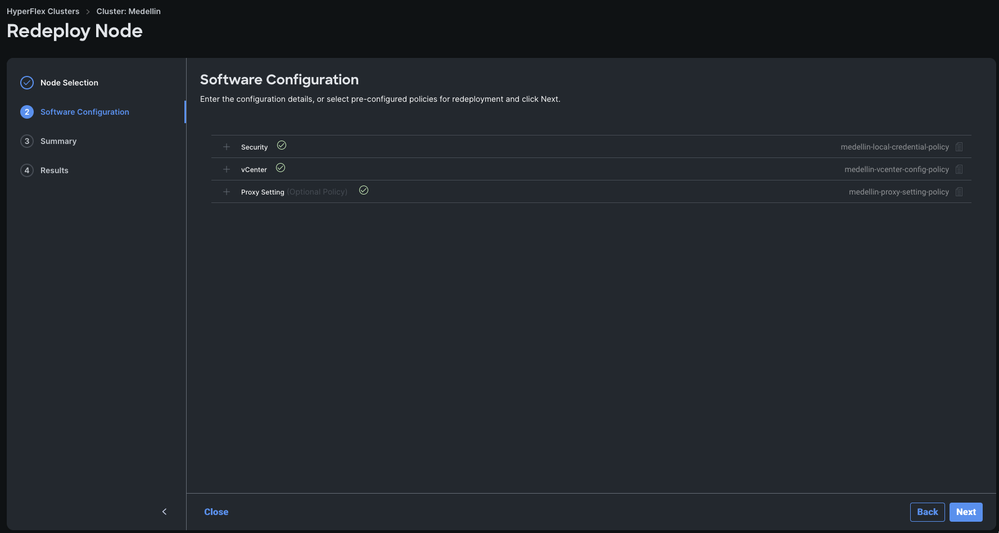
Sin embargo, si sólo se está volviendo a implementar SCVM y ESXi está intacto, en la política de seguridad debe anular la selección de la opción "El hipervisor de este nodo utiliza la contraseña predeterminada de fábrica" y asegurarse de que la contraseña actual de ESXi se actualiza allí antes de seleccionar Siguiente
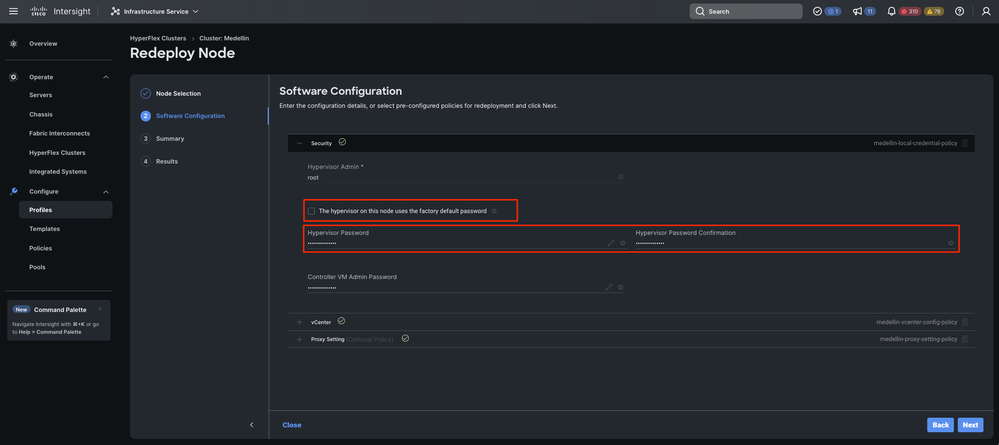
Paso 5. Seleccione Validar y volver a implementar
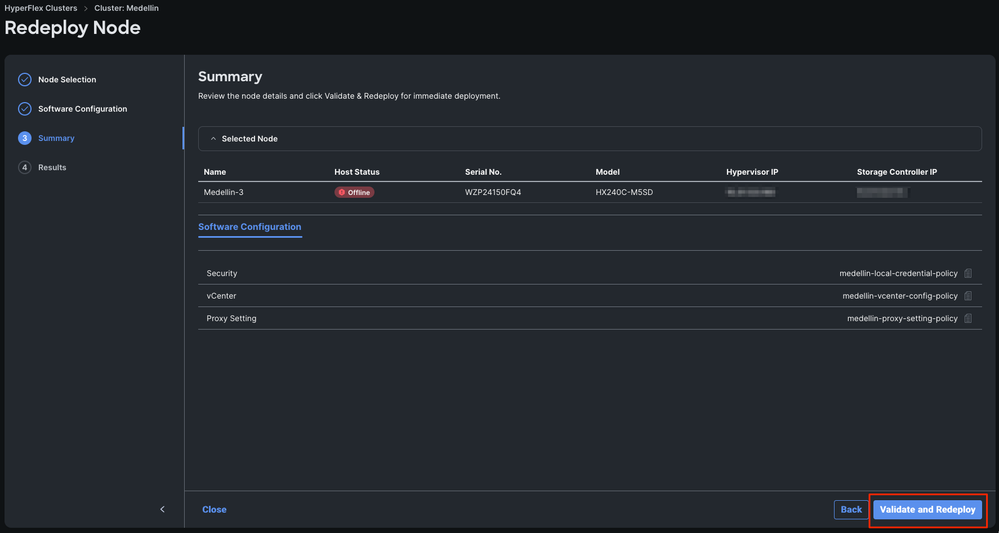
Paso 6. Espere a que se complete el flujo de trabajo
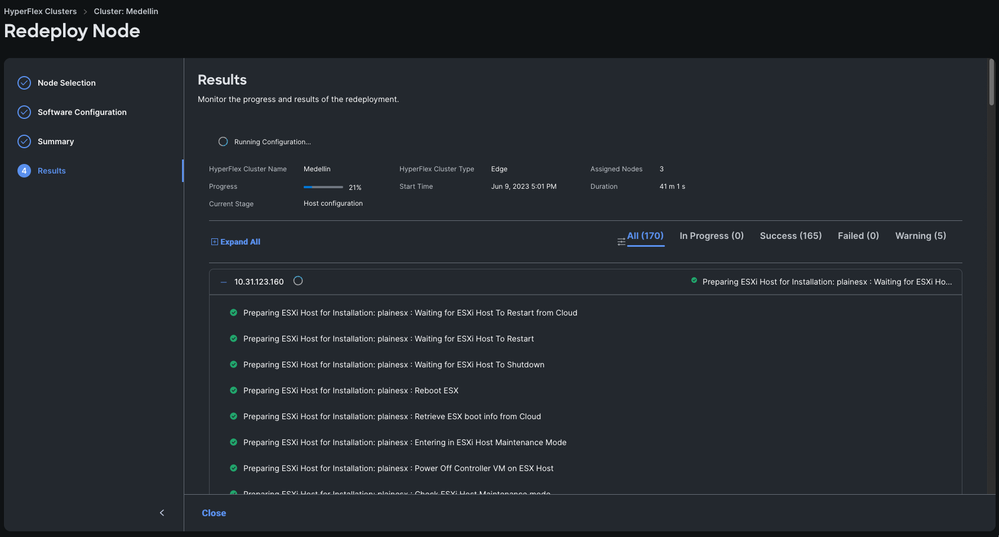
Nota: Puede supervisar el progreso, pero normalmente tarda unas horas
Por último, redespliegue completado y clúster de Medellín está de nuevo en buen estado
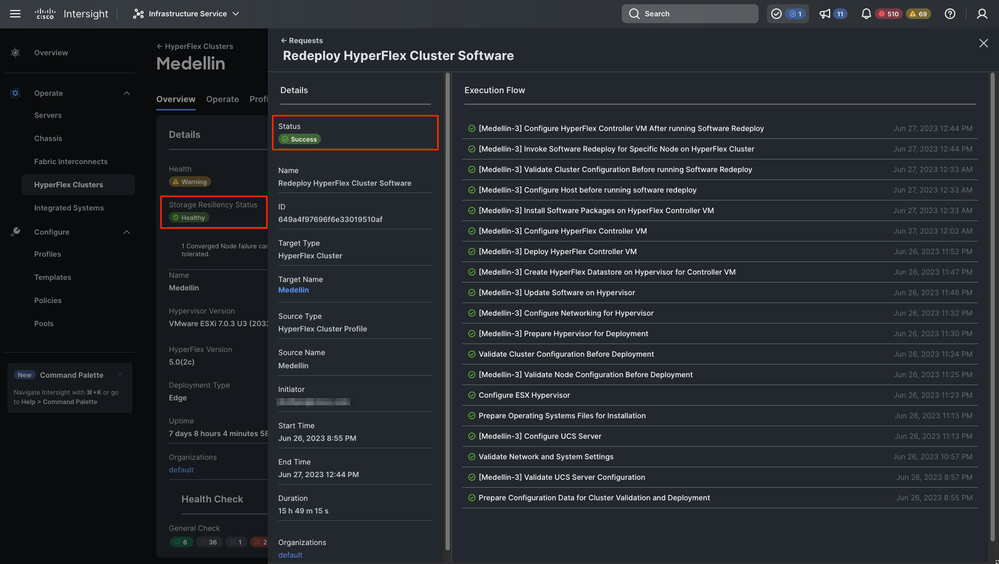
Validación de estado saludable del clúster
Validación de Intersight
Vaya a Clústeres de hiperflexión > Seleccione el clúster > Seleccione la pestaña Descripción general
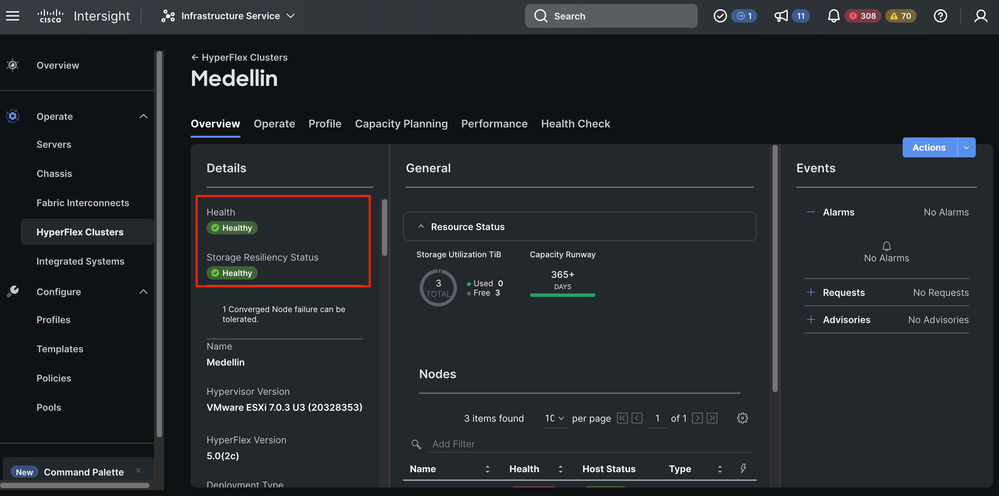
Validación desde Hyperflex Connect
Almuerzo HXDP de Intersight para validar el estado desde allí
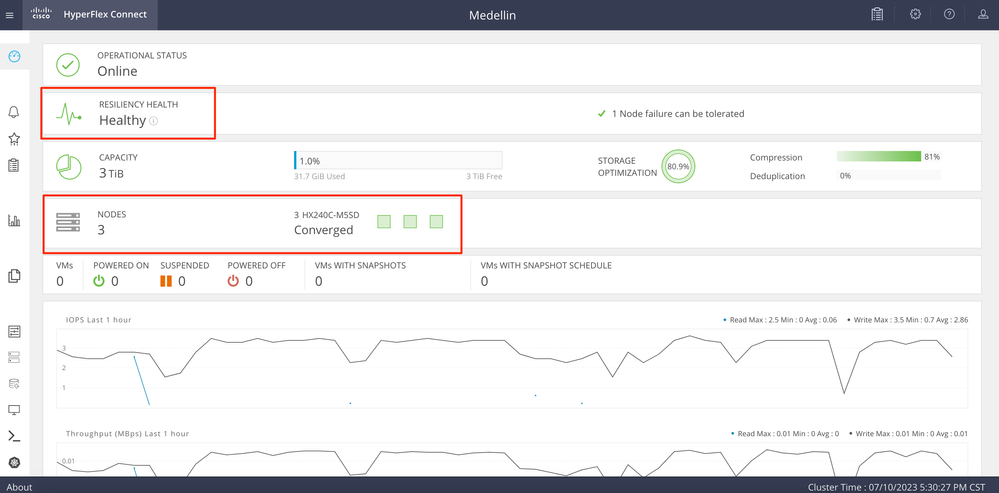
Validación desde CLI
Desde CLI puede utilizar comandos como: hxcli cluster status , hxcli cluster info, hxcli cluster health, hxcli node list
hxshell:~$ hxcli cluster status
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster Ready : Yes
Resiliency Health : HEALTHY
Operational Status : ONLINE
ZK Quorum Status : ONLINE
ZK Node Failures Tolerable : 1
hxshell:~$ hxcli cluster info
Cluster Name : Medellin
Cluster UUID : 6104001978967674717:7117835385033814973
Cluster State : ONLINE
Cluster Access Policy : Lenient
Space Status : NORMAL
Raw Capacity : 9.8 TiB
Total Capacity : 3.0 TiB
Used Capacity : 31.7 GiB
Free Capacity : 3.0 TiB
Compression Savings : 80.90%
Deduplication Savings : 0.00%
Total Savings : 80.90%
# of Nodes Configured : 3
# of Nodes Online : 3
Data IP Address : 169.254.218.1
Resiliency Health : HEALTHY
Policy Compliance : COMPLIANT
Data Replication Factor : 3 Copies
# of node failures tolerable : 1
# of persistent device failures tolerable : 2
# of cache device failures tolerable : 2
Zone Type : Unknown
All Flash : No
Información Relacionada
Flujo de trabajo de reimplementación de nodos HyperFlex
 Comentarios
Comentarios