CPAR: Cálculo del Cierre y Reinicio Graceful del Nodo
Opciones de descarga
-
ePub (644.5 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (282.1 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe el procedimiento que se debe seguir para el apagado y reinicio de nodos informáticos.
Este procedimiento se aplica a un entorno Openstack que utiliza la versión NEWTON en el que ESC no administra Cisco Prime Access Registrar (CPAR) y CPAR se instala directamente en la VM implementada en Openstack. CPAR se instala como máquina virtual.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizada validada y empaquetada previamente diseñada para simplificar la implementación de VNF. OpenStack es el Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de estos tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Compute (OSD - Compute)
- Controlador
- Plataforma OpenStack: Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes involucrados se muestran en esta imagen:
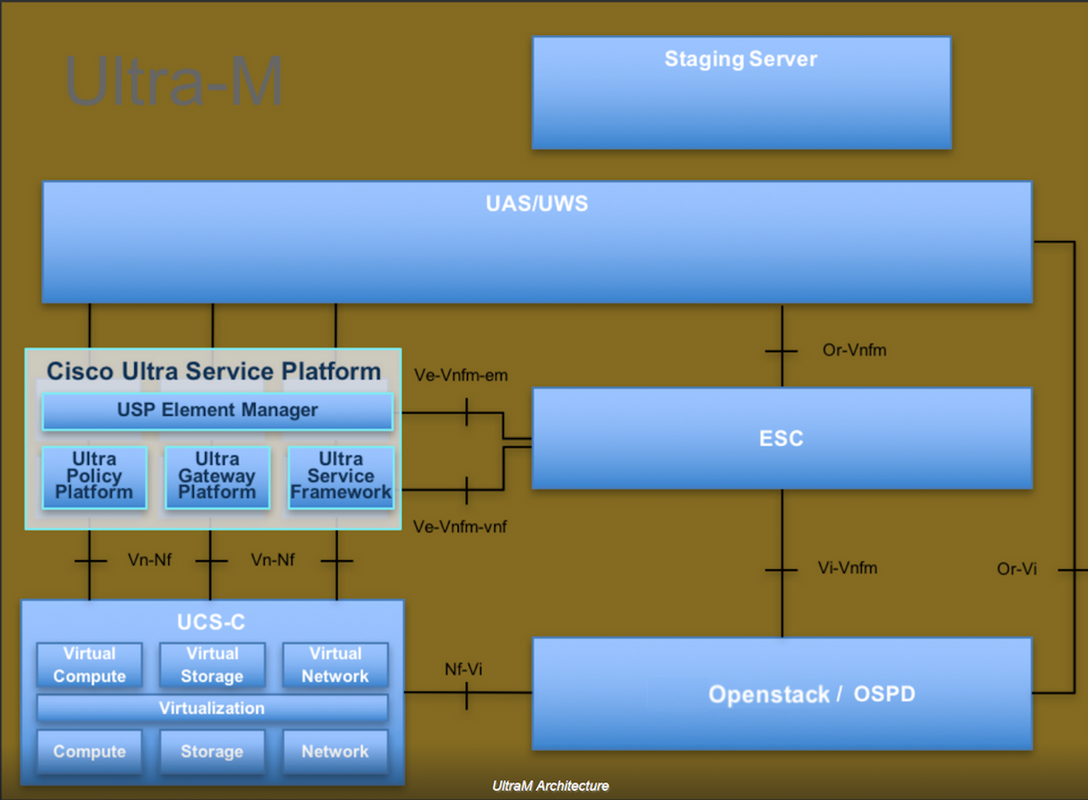
Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Cisco Ultra-M y detalla los pasos necesarios para llevarse a cabo en OpenStack y Redhat OS.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
CPAR Instance Shutdown
Es importante no cerrar las 4 instancias AAA dentro de un sitio (ciudad) al mismo tiempo. Cada instancia de AAA tendrá que apagarse una por una.
Paso 1. Cierre la aplicación CPAR con este comando:
/opt/CSCOar/bin/arserver stop
Mensaje que indica "Cisco Prime Access Registrar Server Agent shutdown complete". Debería aparecer
Nota: Si un usuario dejó abierta una sesión CLI, el comando arserver stop no funcionará y se mostrará este mensaje:
"ERROR: No puede cerrar Cisco Prime Access Registrar mientras el
Se está utilizando CLI. Lista actual de ejecución
CLI con ID de proceso es: 2903 /opt/CSCOar/bin/aregcmd -s"
En este ejemplo, el ID de proceso 2903 debe terminar antes de que el CPAR pueda detenerse. Si este es el caso, complete este proceso a través de este comando:
kill -9 *process_id*
A continuación, repita el paso 1.
Paso 2. Verifique que la aplicación CPAR se cierre realmente con este comando:
/opt/CSCOar/bin/arstatus
Estos mensajes deben aparecer:
El agente del servidor de Cisco Prime Access Registrar no se está ejecutando
La GUI de Cisco Prime Access Registrar no se está ejecutando
Paso 3. Ingrese el sitio web de la GUI de Horizonte que corresponde al Sitio (Ciudad) en el que se está trabajando actualmente, consulte esto para ver los detalles de la IP. Introduzca las credenciales de cpar para la vista personalizada:
Paso 4. Vaya a Proyecto > Instancias, como se muestra en la imagen.
Si el usuario utilizado era cpar, entonces sólo aparecen las 4 instancias AAA en este menú.
Paso 5. Cierre sólo una instancia a la vez. Por favor, repita todo el proceso en este documento.
Para apagar la máquina virtual, navegue hasta Acciones > Apagar instancia:

y confirme su selección.
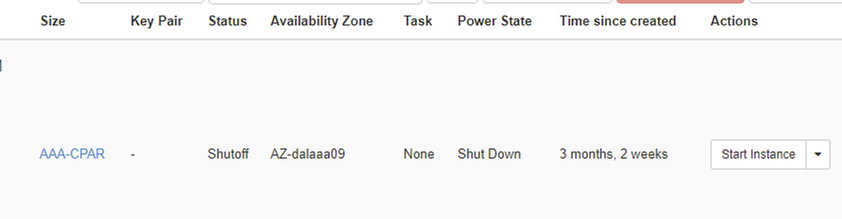
Paso 6. Valide que la instancia se haya cerrado realmente al proteger el estado = Apagar y estado de energía = Apagar
Este paso finaliza el proceso de cierre del CPAR.
Reinicio de CPAR Application Compute y comprobación de estado
Inicio de instancia de CPAR
Siga este procedimiento, una vez que la actividad de RMA haya finalizado y los servicios CPAR puedan restablecerse en el Sitio que se cerró.
Paso 1. Vuelva a iniciar sesión en Horizon, navegue hasta Project > Instance > Start Instance.
Paso 2. Verifique que el estado de la instancia esté activo y que el estado de energía esté en ejecución, como se muestra en la imagen.
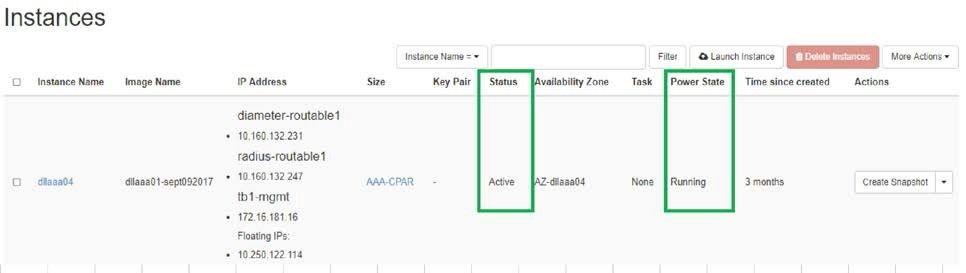
Comprobación del estado posterior al inicio de la instancia CPAR
Paso 1. Inicie sesión mediante Secure Shell (SSH) en la instancia CPAR.
Ejecute el comando /opt/CSCOar/bin/arstatus a nivel del SO
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 4834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Paso 2. Ejecute el comando /opt/CSCOar/bin/aregcmd a nivel del sistema operativo e ingrese las credenciales de administración. Verifique que CPAR Health sea 10 de 10 y que salga de CPAR CLI.
[root@rvraaa02 logs]# /opt/CSCOar/bin/aregcmd Cisco Prime Access Registrar 7.3.0.1 Configuration Utility Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved. Cluster: User: admin Passphrase: Logging in to localhost [ //localhost ] LicenseInfo = PAR-NG-TPS 7.2(100TPS:) PAR-ADD-TPS 7.2(2000TPS:) PAR-RDDR-TRX 7.2() PAR-HSS 7.2() Radius/ Administrators/ Server 'Radius' is running, its health is 10 out of 10 --> exit
Paso 3. Ejecute el comando netstat | diámetro grep y verifique que se hayan establecido todas las conexiones DRA.
El resultado mencionado aquí es para un entorno en el que se esperan links Diámetro. Si se muestran menos enlaces, esto representa una desconexión del DRA que se debe analizar.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Paso 4. Compruebe que el registro de TPS muestra las solicitudes que está procesando el CPAR. Los valores resaltados representan el TPS y los que necesitan atención. El valor de TPS no debe exceder de 1500.
[root@aaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Paso 5 Busque cualquier mensaje de "error" o "alarma" en name_radius_1_log.
[root@aaa02 logs]# grep -E "error|alarma" name_radius_1_log
Con la colaboración de ingenieros de Cisco
- Karthikeyan DachanamoorthyCisco Advance Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)