Sustitución del servidor informático UCS C240 M4 - CPAR
Opciones de descarga
-
ePub (2.1 MB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (1.7 MB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe los pasos necesarios para reemplazar un servidor informático defectuoso en una configuración Ultra-M.
Este procedimiento se aplica a un entorno Openstack que utiliza la versión NEWTON en el que Elastic Serives Controller (ESC) no administra Cisco Prime Access Registrar (CPAR) y CPAR se instala directamente en la VM implementada en Openstack.
Antecedentes
Ultra-M es una solución de núcleo de paquetes móviles virtualizada validada y empaquetada previamente diseñada para simplificar la implementación de VNF. OpenStack es el Virtualized Infrastructure Manager (VIM) para Ultra-M y consta de estos tipos de nodos:
- Informática
- Disco de almacenamiento de objetos - Compute (OSD - Compute)
- Controlador
- Plataforma OpenStack: Director (OSPD)
La arquitectura de alto nivel de Ultra-M y los componentes involucrados se ilustran en esta imagen:
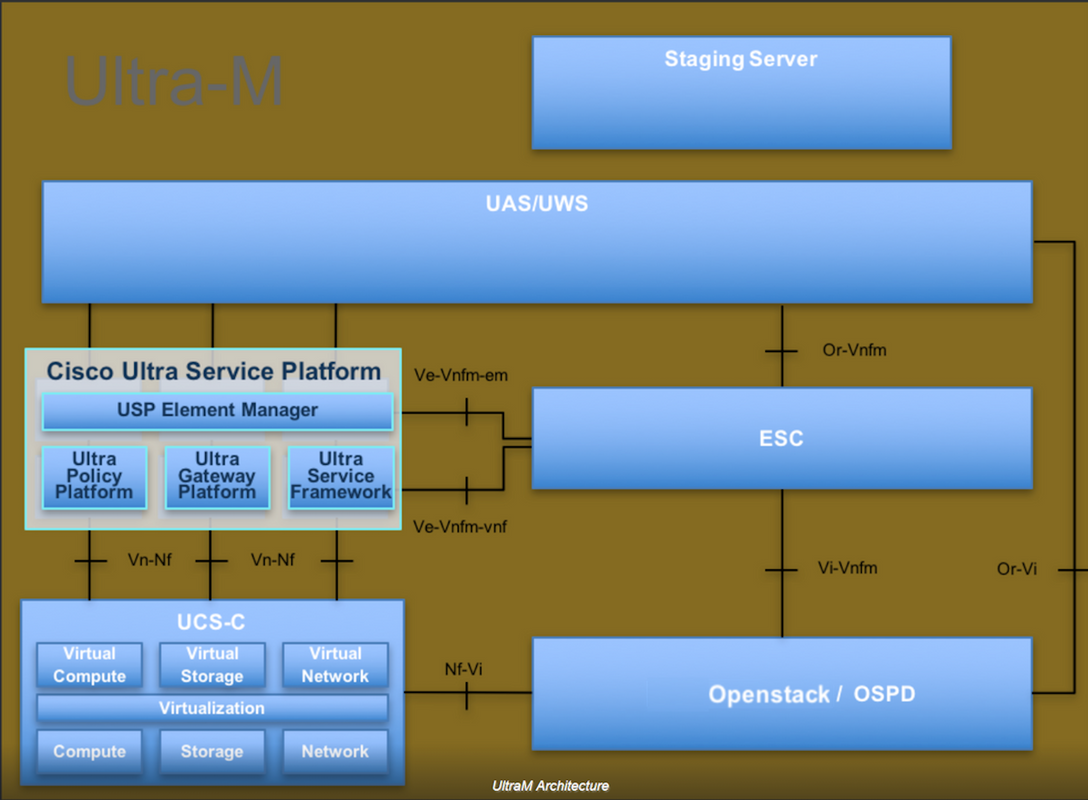
Este documento está dirigido al personal de Cisco que está familiarizado con la plataforma Cisco Ultra-M y detalla los pasos necesarios para llevarse a cabo en OpenStack y Redhat OS.
Nota: Se considera la versión Ultra M 5.1.x para definir los procedimientos en este documento.
Abreviaturas
| MOP | Método de procedimiento |
| OSD | Discos de almacenamiento de objetos |
| OSPD | Director de plataforma OpenStack |
| HDD | Unidad de disco duro |
| SSD | Unidad de estado sólido |
| VIM | Administrador de infraestructura virtual |
| VM | Máquina virtual |
| EM | Administrador de elementos |
| UAS | Servicios de ultra automatización |
| UUID | Identificador único universal |
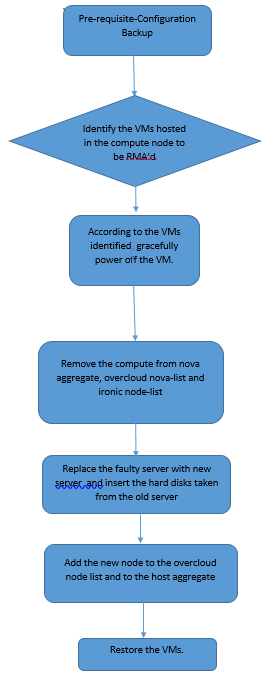
Flujo de trabajo del MoP
Prerequisites
Copia de seguridad
Antes de reemplazar un nodo Compute, es importante verificar el estado actual de su entorno Red Hat OpenStack Platform. Se recomienda que verifique el estado actual para evitar complicaciones cuando el proceso Compute de reemplazo está activado. Se puede lograr con este flujo de reemplazo.
En caso de recuperación, Cisco recomienda realizar una copia de seguridad de la base de datos OSPD con estos pasos:
[root@ al03-pod2-ospd ~]# mysqldump --opt --all-databases > /root/undercloud-all-databases.sql [root@ al03-pod2-ospd ~]# tar --xattrs -czf undercloud-backup-`date +%F`.tar.gz /root/undercloud-all-databases.sql /etc/my.cnf.d/server.cnf /var/lib/glance/images /srv/node /home/stack tar: Removing leading `/' from member names
Este proceso asegura que un nodo se pueda reemplazar sin afectar la disponibilidad de ninguna instancia.
Nota: Asegúrese de tener la instantánea de la instancia para poder restaurar la VM cuando sea necesario. Siga el siguiente procedimiento para tomar una instantánea de la VM.
Identificación de las VM alojadas en el nodo de informática
Identifique las VM alojadas en el servidor informático.
[stack@al03-pod2-ospd ~]$ nova list --field name,host +--------------------------------------+---------------------------+----------------------------------+ | ID | Name | Host | +--------------------------------------+---------------------------+----------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | pod2-stack-compute-4.localdomain | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | pod2-stack-compute-3.localdomain | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | pod2-stack-compute-3.localdomain | +--------------------------------------+---------------------------+----------------------------------+
Nota: En el resultado que se muestra aquí, la primera columna corresponde al identificador único universal (UUID), la segunda columna es el nombre de la máquina virtual y la tercera es el nombre de host donde está presente la máquina virtual. Los parámetros de este resultado se utilizarán en secciones posteriores.
Proceso de instantánea
Cierre de la aplicación CPAR
Paso 1. Abra cualquier cliente SSH conectado a la red y conéctese a la instancia CPAR.
Es importante no cerrar las 4 instancias AAA dentro de un sitio al mismo tiempo, hacerlo de una manera a una.
Paso 2. Cierre la aplicación CPAR con este comando:
/opt/CSCOar/bin/arserver stop
Un mensaje indica "Cisco Prime Access Registrar Server Agent shutdown complete". debería aparecer.
Nota: Si un usuario dejó abierta una sesión CLI, el comando arserver stop no funcionará y se mostrará el siguiente mensaje:
ERROR: You can not shut down Cisco Prime Access Registrar while the
CLI is being used. Current list of running
CLI with process id is:
2903 /opt/CSCOar/bin/aregcmd –s
En este ejemplo, la ID de proceso resaltada 2903 debe terminar antes de que el CPAR pueda ser detenido. Si este es el caso, termine el proceso con este comando:
kill -9 *process_id*
A continuación, repita el paso 1.
Paso 3. Verifique que la aplicación CPAR se haya apagado de hecho con este comando:
/opt/CSCOar/bin/arstatus
Estos mensajes deben aparecer:
Cisco Prime Access Registrar Server Agent not running Cisco Prime Access Registrar GUI not running
Tarea de instantánea de VM
Paso 1. Introduzca el sitio web de la interfaz gráfica de usuario de Horizonte correspondiente al sitio (ciudad) en el que se está trabajando. Cuando se accede al Horizonte, se observa la pantalla que se muestra en la imagen:
Paso 2. Como se muestra en la imagen, navegue hasta Project > Instancias.
Si el usuario utilizado era cpar, sólo aparecerán las 4 instancias AAA en este menú.
Paso 3. Cierre sólo una instancia a la vez, repita todo el proceso en este documento. Para apagar la máquina virtual, navegue hasta Acciones > Apagar instancia y confirme su selección.

Paso 4 Valide que la instancia se haya cerrado realmente a través de Status = Shutoff y Power State = shut Down.
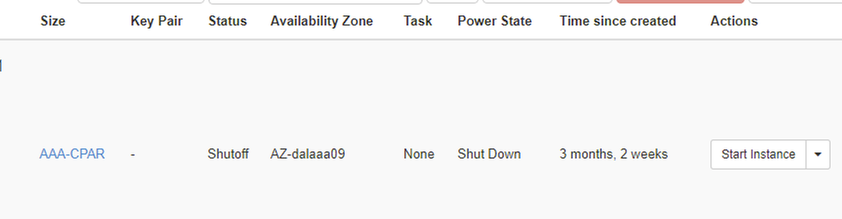
Este paso finaliza el proceso de cierre del CPAR.
Instantánea de VM
Una vez que las máquinas virtuales CPAR están inactivas, las instantáneas pueden tomarse en paralelo, ya que pertenecen a equipos independientes.
Los cuatro archivos QCOW2 se crean en paralelo.
Tome una instantánea de cada instancia de AAA (25 minutos -1 hora) (25 minutos para las instancias que usaron una imagen de cola como origen y 1 hora para las instancias que usaron una imagen sin procesar como origen).
Paso 1. Inicie sesión en la GUI Horizonte de Openstack de POD.
Paso 2. Una vez que haya iniciado sesión, vaya a la sección Proyecto > Informática > Instancias, en el menú superior y busque las instancias AAA.
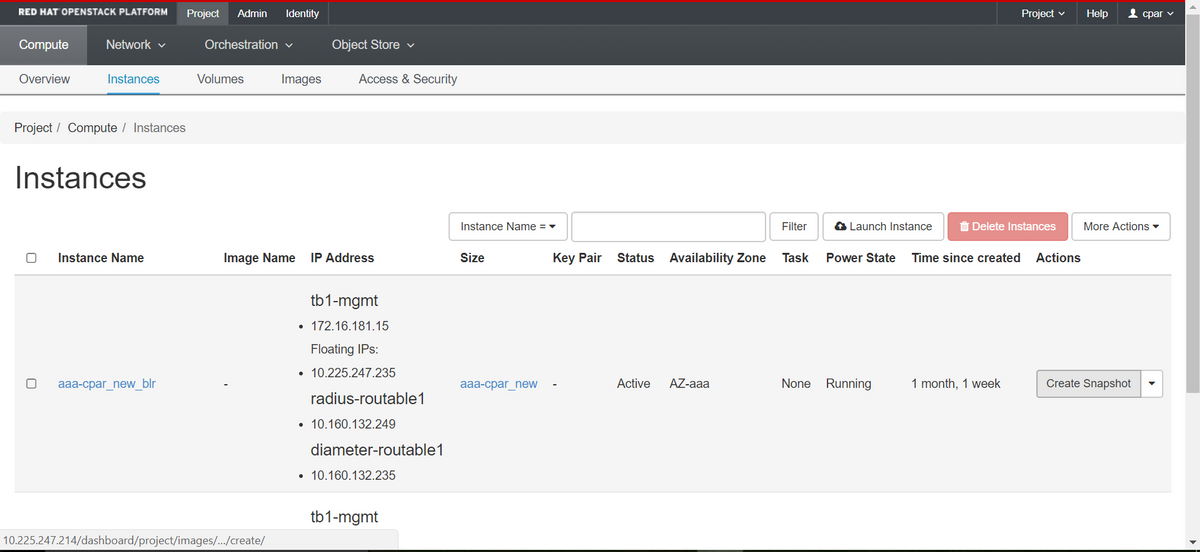
Paso 3. Haga clic en Crear instantánea para continuar con la creación de la instantánea (esto debe ejecutarse en la instancia AAA correspondiente).
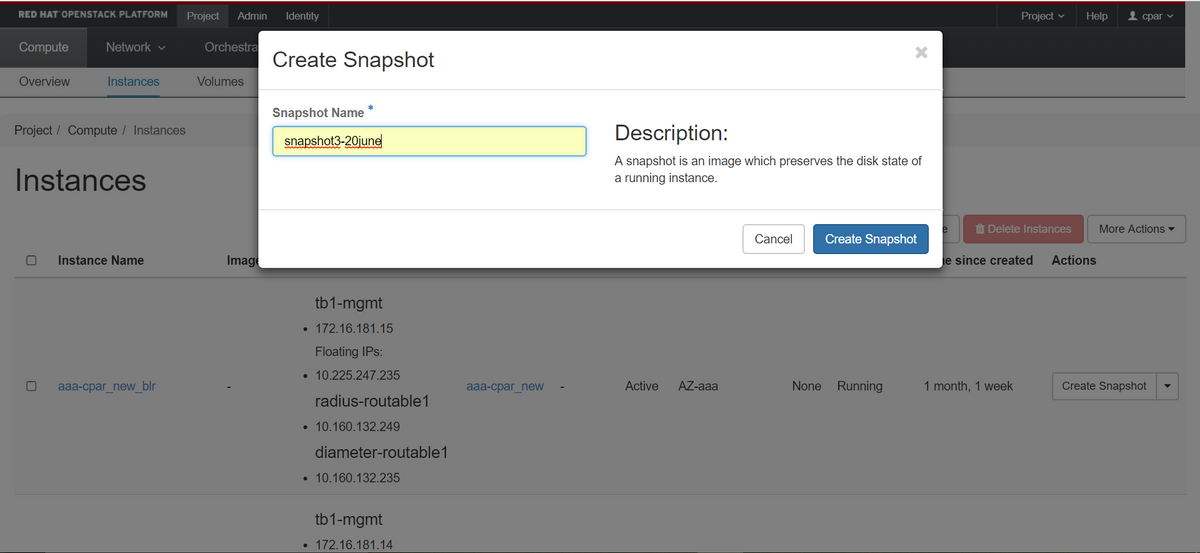
Paso 4. Una vez ejecutada la instantánea, navegue hasta el menú Images y verifique que finaliza y no informa ningún problema.
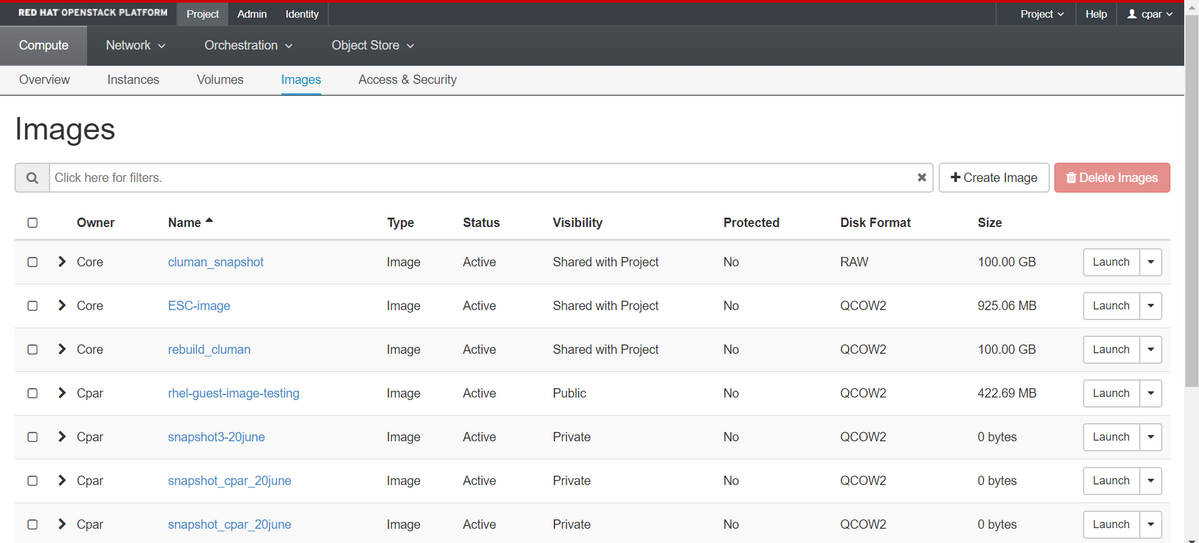
Paso 5. El siguiente paso es descargar la instantánea en un formato QCOW2 y transferirla a una entidad remota en caso de que la OSPD se pierda durante este proceso. Para lograr esto, identifique la instantánea con este comando glance image-list en el nivel OSPD
[root@elospd01 stack]# glance image-list +--------------------------------------+---------------------------+ | ID | Name | +--------------------------------------+---------------------------+ | 80f083cb-66f9-4fcf-8b8a-7d8965e47b1d | AAA-Temporary | | 22f8536b-3f3c-4bcc-ae1a-8f2ab0d8b950 | ELP1 cluman 10_09_2017 | | 70ef5911-208e-4cac-93e2-6fe9033db560 | ELP2 cluman 10_09_2017 | | e0b57fc9-e5c3-4b51-8b94-56cbccdf5401 | ESC-image | | 92dfe18c-df35-4aa9-8c52-9c663d3f839b | lgnaaa01-sept102017 | | 1461226b-4362-428b-bc90-0a98cbf33500 | tmobile-pcrf-13.1.1.iso | | 98275e15-37cf-4681-9bcc-d6ba18947d7b | tmobile-pcrf-13.1.1.qcow2 | +--------------------------------------+---------------------------+
Paso 6. Una vez identificada la instantánea que se descargará (en este caso será la marcada arriba en verde), se descarga en formato QCOW2 a través de este comando glance image-download como se muestra aquí.
[root@elospd01 stack]# glance image-download 92dfe18c-df35-4aa9-8c52-9c663d3f839b --file /tmp/AAA-CPAR-LGNoct192017.qcow2 &
- El "&" envía el proceso a segundo plano. Se tarda algún tiempo en completar esta acción, una vez que se realiza, la imagen se puede encontrar en el directorio /tmp.
- Cuando se envía el proceso al fondo, si se pierde la conectividad, también se detiene el proceso.
- Ejecute el comando disown -h para que, en caso de que se pierda la conexión de Secure Shell (SSH), el proceso siga ejecutándose y finalice en el OSPD.
Paso 7. Una vez finalizado el proceso de descarga, es necesario ejecutar un proceso de compresión, ya que esa instantánea puede llenarse con ZEROES debido a procesos, tareas y archivos temporales manejados por el sistema operativo. El comando que se utilizará para la compresión de archivos es virt-sparsify.
[root@elospd01 stack]# virt-sparsify AAA-CPAR-LGNoct192017.qcow2 AAA-CPAR-LGNoct192017_compressed.qcow2
Este proceso lleva algún tiempo (unos 10-15 minutos). Una vez terminado, el archivo resultante es el que debe transferirse a una entidad externa como se especifica en el paso siguiente.
Para lograr esto, se requiere la verificación de la integridad del archivo, ejecute el siguiente comando y busque el atributo corrupto al final de su salida.
[root@wsospd01 tmp]# qemu-img info AAA-CPAR-LGNoct192017_compressed.qcow2 image: AAA-CPAR-LGNoct192017_compressed.qcow2 file format: qcow2 virtual size: 150G (161061273600 bytes) disk size: 18G cluster_size: 65536 Format specific information: compat: 1.1 lazy refcounts: false refcount bits: 16 corrupt: false
Para evitar un problema donde se pierde la OSPD, la instantánea creada recientemente en formato QCOW2 debe transferirse a una entidad externa. Antes de iniciar la transferencia de archivos tenemos que verificar si el destino tiene suficiente espacio disponible en disco, utilice el comando df -kh, para verificar el espacio de memoria. Se recomienda transferirlo temporalmente a otro OSPD de sitio a través de SFTP sftp root@x.x.x.x donde x.x.x.x es la IP de un OSPD remoto. Para acelerar la transferencia, el destino se puede enviar a varios OSPD. De la misma manera, este comando se puede utilizar scp *name_of_the_file*.qcow2 root@ x.x.x.x:/tmp (donde x.x.x.x es la IP de un OSPD remoto) para transferir el archivo a otro OSPD.
Apagado Graceful
Apagar el nodo
- Para apagar la instancia: nova stop <INSTANCE_NAME>
- Ahora verá el nombre de la instancia con el estado apagado.
[stack@director ~]$ nova stop aaa2-21 Request to stop server aaa2-21 has been accepted. [stack@director ~]$ nova list +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | ID | Name | Status | Task State | Power State | Networks | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+ | 46b4b9eb-a1a6-425d-b886-a0ba760e6114 | AAA-CPAR-testing-instance | ACTIVE | - | Running | tb1-mgmt=172.16.181.14, 10.225.247.233; radius-routable1=10.160.132.245; diameter-routable1=10.160.132.231 | | 3bc14173-876b-4d56-88e7-b890d67a4122 | aaa2-21 | SHUTOFF | - | Shutdown | diameter-routable1=10.160.132.230; radius-routable1=10.160.132.248; tb1-mgmt=172.16.181.7, 10.225.247.234 | | f404f6ad-34c8-4a5f-a757-14c8ed7fa30e | aaa21june | ACTIVE | - | Running | diameter-routable1=10.160.132.233; radius-routable1=10.160.132.244; tb1-mgmt=172.16.181.10 | +--------------------------------------+---------------------------+---------+------------+-------------+------------------------------------------------------------------------------------------------------------+
Eliminación del nodo de cálculo
Los pasos mencionados en esta sección son comunes independientemente de las VM alojadas en el nodo informático.
Eliminar nodo de cálculo de la lista de servicios
Elimine el servicio informático de la lista de servicios:
[stack@director ~]$ openstack compute service list |grep compute-3 | 138 | nova-compute | pod2-stack-compute-3.localdomain | AZ-aaa | enabled | up | 2018-06-21T15:05:37.000000 |
openstack cómputo service delete <ID>
[stack@director ~]$ openstack compute service delete 138
Eliminar agentes neutrales
Elimine el agente neutrón asociado antiguo y abra el agente vswitch para el servidor informático:
[stack@director ~]$ openstack network agent list | grep compute-3 | 3b37fa1d-01d4-404a-886f-ff68cec1ccb9 | Open vSwitch agent | pod2-stack-compute-3.localdomain | None | True | UP | neutron-openvswitch-agent |
openstack network agent delete <ID>
[stack@director ~]$ openstack network agent delete 3b37fa1d-01d4-404a-886f-ff68cec1ccb9
Eliminar de la base de datos irónica
Elimine un nodo de la base de datos irónica y verifíquelo:
nova show <cómputo-node> | hipervisor grep
[root@director ~]# source stackrc [root@director ~]# nova show pod2-stack-compute-4 | grep hypervisor | OS-EXT-SRV-ATTR:hypervisor_hostname | 7439ea6c-3a88-47c2-9ff5-0a4f24647444
ironic node-delete <ID>
[stack@director ~]$ ironic node-delete 7439ea6c-3a88-47c2-9ff5-0a4f24647444 [stack@director ~]$ ironic node-list
El nodo eliminado no debe aparecer ahora en la lista de nodos irónica.
Eliminar de Overcloud
Paso 1. Cree un archivo de script denominado delete_node.sh con el contenido como se muestra. Asegúrese de que las plantillas mencionadas sean las mismas que las utilizadas en el script Deploy.sh utilizado para la implementación de la pila:
delete_node.sh
openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack <stack-name> <UUID>
[stack@director ~]$ source stackrc [stack@director ~]$ /bin/sh delete_node.sh + openstack overcloud node delete --templates -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml -e /home/stack/custom-templates/layout.yaml --stack pod2-stack 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Deleting the following nodes from stack pod2-stack: - 7439ea6c-3a88-47c2-9ff5-0a4f24647444 Started Mistral Workflow. Execution ID: 4ab4508a-c1d5-4e48-9b95-ad9a5baa20ae real 0m52.078s user 0m0.383s sys 0m0.086s
Paso 2. Espere a que la operación de pila OpenStack pase al estado COMPLETE:
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | pod2-stack | UPDATE_COMPLETE | 2018-05-08T21:30:06Z | 2018-05-08T20:42:48Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
Instalación del nuevo nodo informático
Los pasos para instalar un nuevo servidor UCS C240 M4 y los pasos iniciales de configuración se pueden consultar en la Guía de Instalación y Servicio del Servidor Cisco UCS C240 M4
Paso 1. Después de la instalación del servidor, inserte los discos duros en las ranuras respectivas como el servidor antiguo.
Paso 2. Inicie sesión en el servidor con la IP de CIMC.
Paso 3. Realice la actualización del BIOS si el firmware no se ajusta a la versión recomendada utilizada anteriormente. Los pasos para la actualización del BIOS se indican a continuación: Guía de actualización del BIOS del servidor de montaje en bastidor Cisco UCS C-Series
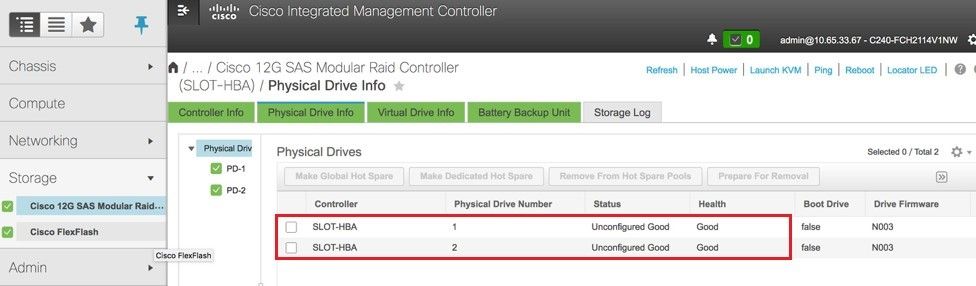
Paso 4. Para verificar el estado de las unidades físicas, que es Unconfigured Good, navegue hasta Storage > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Physical Drive Info.
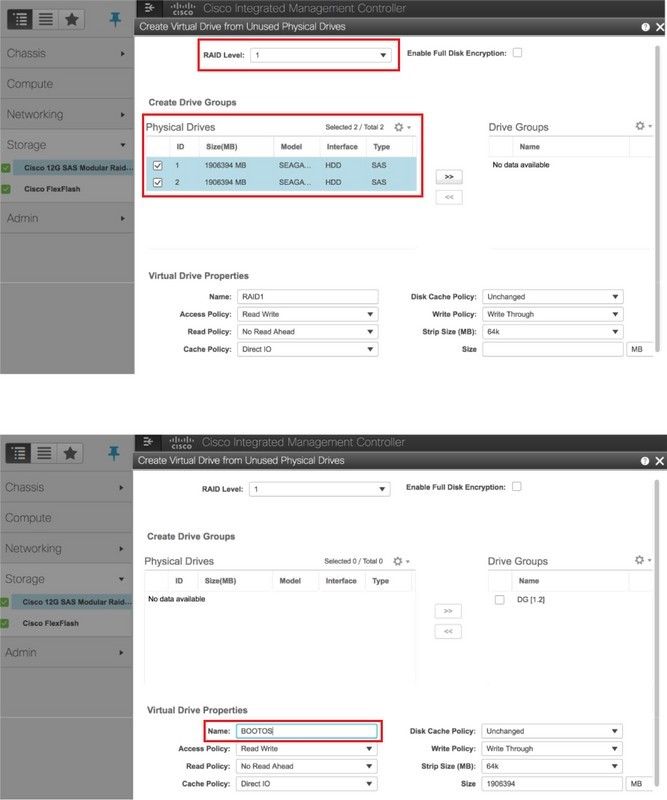
Paso 5. Para crear una unidad virtual desde las unidades físicas con RAID Nivel 1, navegue hasta Almacenamiento > Cisco 12G SAS Modular Raid Controller (SLOT-HBA) > Información del controlador > Crear unidad virtual desde unidades físicas no usadas.
Paso 6. Seleccione el VD y configure Set as Boot Drive, como se muestra en la imagen.

Paso 7. Para habilitar IPMI sobre LAN, navegue a Admin > Communication Services > Communication Services, como se muestra en la imagen.

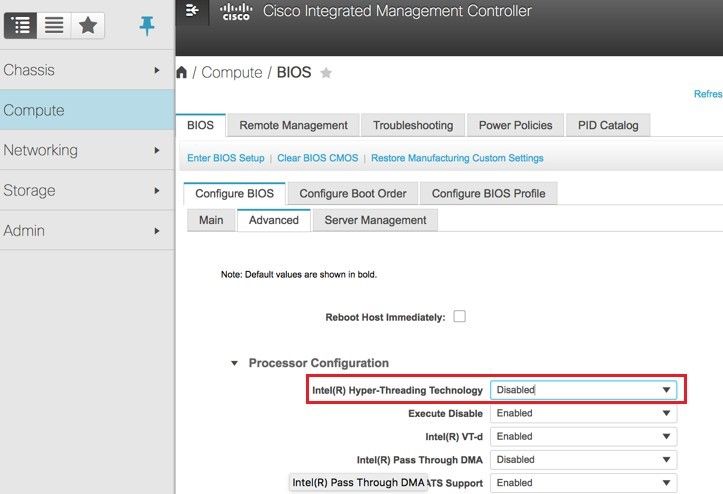
Paso 8. Para inhabilitar el hiperprocesamiento, navegue hasta Compute > BIOS > Configure BIOS > Advanced > Processor Configuration.
Nota: La imagen que se muestra aquí y los pasos de configuración mencionados en esta sección se refieren a la versión de firmware 3.0(3e) y puede haber ligeras variaciones si trabaja en otras versiones.
Agregar el nuevo nodo informático a la nube
Los pasos mencionados en esta sección son comunes independientemente de la VM alojada por el nodo informático.
Paso 1. Agregar servidor informático con un índice diferente
Cree un archivo add_node.json con sólo los detalles del nuevo servidor informático que se agregará. Asegúrese de que el número de índice del nuevo servidor informático no se haya utilizado antes. Normalmente, aumente el siguiente valor de cálculo más alto.
Ejemplo: El más alto anterior fue compute-17, por lo tanto, creado compute-18 en el caso de un sistema 2-vnf.
Nota: Tenga en cuenta el formato json.
[stack@director ~]$ cat add_node.json
{
"nodes":[
{
"mac":[
"<MAC_ADDRESS>"
],
"capabilities": "node:compute-18,boot_option:local",
"cpu":"24",
"memory":"256000",
"disk":"3000",
"arch":"x86_64",
"pm_type":"pxe_ipmitool",
"pm_user":"admin",
"pm_password":"<PASSWORD>",
"pm_addr":"192.100.0.5"
}
]
}
Paso 2. Importe el archivo json.
[stack@director ~]$ openstack baremetal import --json add_node.json Started Mistral Workflow. Execution ID: 78f3b22c-5c11-4d08-a00f-8553b09f497d Successfully registered node UUID 7eddfa87-6ae6-4308-b1d2-78c98689a56e Started Mistral Workflow. Execution ID: 33a68c16-c6fd-4f2a-9df9-926545f2127e Successfully set all nodes to available.
Paso 3. Ejecute la introspección del nodo con el uso del UUID observado desde el paso anterior.
[stack@director ~]$ openstack baremetal node manage 7eddfa87-6ae6-4308-b1d2-78c98689a56e [stack@director ~]$ ironic node-list |grep 7eddfa87 | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | manageable | False | [stack@director ~]$ openstack overcloud node introspect 7eddfa87-6ae6-4308-b1d2-78c98689a56e --provide Started Mistral Workflow. Execution ID: e320298a-6562-42e3-8ba6-5ce6d8524e5c Waiting for introspection to finish... Successfully introspected all nodes. Introspection completed. Started Mistral Workflow. Execution ID: c4a90d7b-ebf2-4fcb-96bf-e3168aa69dc9 Successfully set all nodes to available. [stack@director ~]$ ironic node-list |grep available | 7eddfa87-6ae6-4308-b1d2-78c98689a56e | None | None | power off | available | False |
Paso 4. Ejecute el script Deploy.sh que se utilizó anteriormente para implementar la pila, para agregar el nuevo computenode a la pila de nube excesiva:
[stack@director ~]$ ./deploy.sh ++ openstack overcloud deploy --templates -r /home/stack/custom-templates/custom-roles.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/puppet-pacemaker.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/network-isolation.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/storage-environment.yaml -e /usr/share/openstack-tripleo-heat-templates/environments/neutron-sriov.yaml -e /home/stack/custom-templates/network.yaml -e /home/stack/custom-templates/ceph.yaml -e /home/stack/custom-templates/compute.yaml -e /home/stack/custom-templates/layout.yaml --stack ADN-ultram --debug --log-file overcloudDeploy_11_06_17__16_39_26.log --ntp-server 172.24.167.109 --neutron-flat-networks phys_pcie1_0,phys_pcie1_1,phys_pcie4_0,phys_pcie4_1 --neutron-network-vlan-ranges datacentre:1001:1050 --neutron-disable-tunneling --verbose --timeout 180 … Starting new HTTP connection (1): 192.200.0.1 "POST /v2/action_executions HTTP/1.1" 201 1695 HTTP POST http://192.200.0.1:8989/v2/action_executions 201 Overcloud Endpoint: http://10.1.2.5:5000/v2.0 Overcloud Deployed clean_up DeployOvercloud: END return value: 0 real 38m38.971s user 0m3.605s sys 0m0.466s
Paso 5. Espere a que se complete el estado de pila de openstack.
[stack@director ~]$ openstack stack list +--------------------------------------+------------+-----------------+----------------------+----------------------+ | ID | Stack Name | Stack Status | Creation Time | Updated Time | +--------------------------------------+------------+-----------------+----------------------+----------------------+ | 5df68458-095d-43bd-a8c4-033e68ba79a0 | ADN-ultram | UPDATE_COMPLETE | 2017-11-02T21:30:06Z | 2017-11-06T21:40:58Z | +--------------------------------------+------------+-----------------+----------------------+----------------------+
Paso 6. Verifique que el nuevo nodo de cálculo se encuentre en estado Activo.
[root@director ~]# nova list | grep pod2-stack-compute-4 | 5dbac94d-19b9-493e-a366-1e2e2e5e34c5 | pod2-stack-compute-4 | ACTIVE | - | Running | ctlplane=192.200.0.116 |
Restauración de las VM
Recuperación de una Instancia mediante Snapshot
Proceso de recuperación:
Es posible volver a implementar la instancia anterior con la instantánea tomada en pasos anteriores.
Paso 1 [OPCIONAL]. Si no hay ninguna VMSnapshots anterior, conéctese al nodo OSPD donde se envió la copia de seguridad y devuelva la copia de seguridad a su nodo OSPD original. A través de sftp root@x.x.x.x donde x.x.x.x es la IP del OSPD original. Guarde el archivo de instantánea en el directorio /tmp.
Paso 2. Conéctese al nodo OSPD donde se reimplementa la instancia.

Cree las variables de entorno con el siguiente comando:
# source /home/stack/pod1-stackrc-Core-CPAR
Paso 3. Para utilizar la instantánea como una imagen es necesario cargarla en el horizonte como tal. Utilice el siguiente comando para hacerlo.
#glance image-create -- AAA-CPAR-Date-snapshot.qcow2 --container-format bare --disk-format qcow2 --name AAA-CPAR-Date-snapshot
El proceso puede verse en el horizonte.

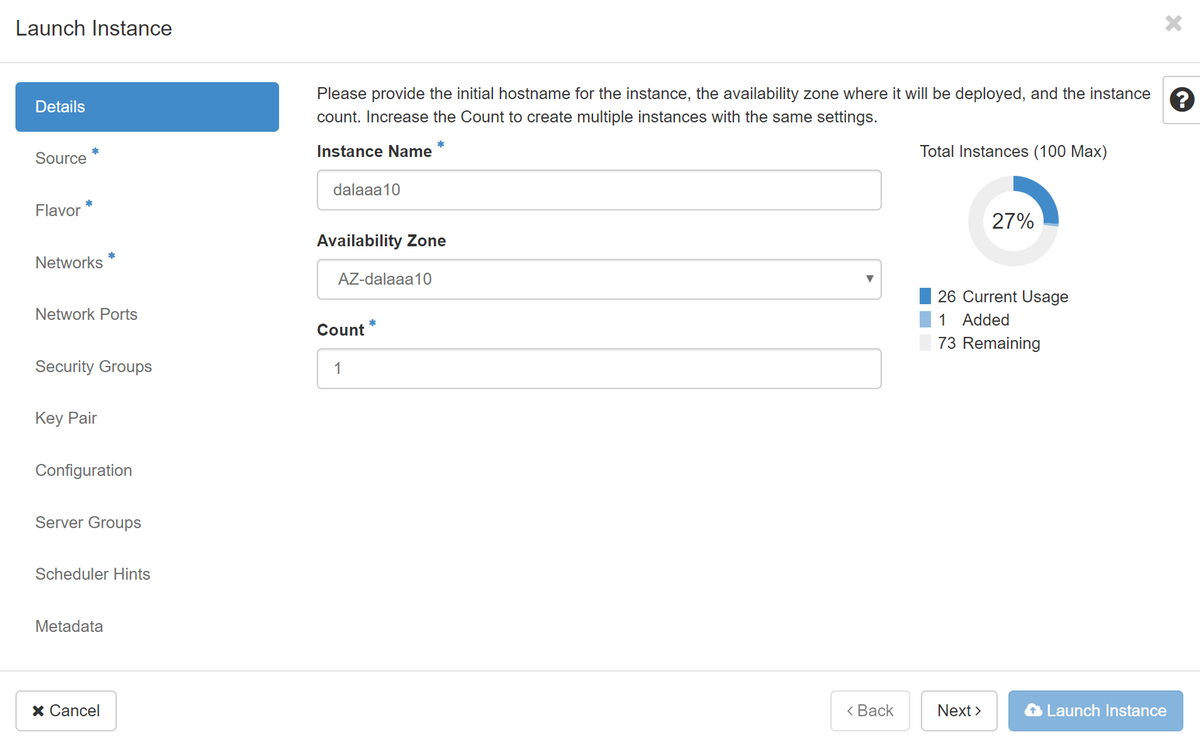
Paso 4. En el Horizonte, navegue hasta Proyecto > Instancias y haga clic en Iniciar instancia, como se muestra en la imagen.

Paso 5. Ingrese el nombre de la instancia y elija la zona de disponibilidad, como se muestra en la imagen.
Paso 6. En la ficha Source, elija la imagen para crear la instancia. En el menú Select Boot Source (Seleccionar origen de arranque) seleccione imagen, se muestra una lista de imágenes aquí, elija la que se cargó anteriormente al hacer clic en el símbolo +.
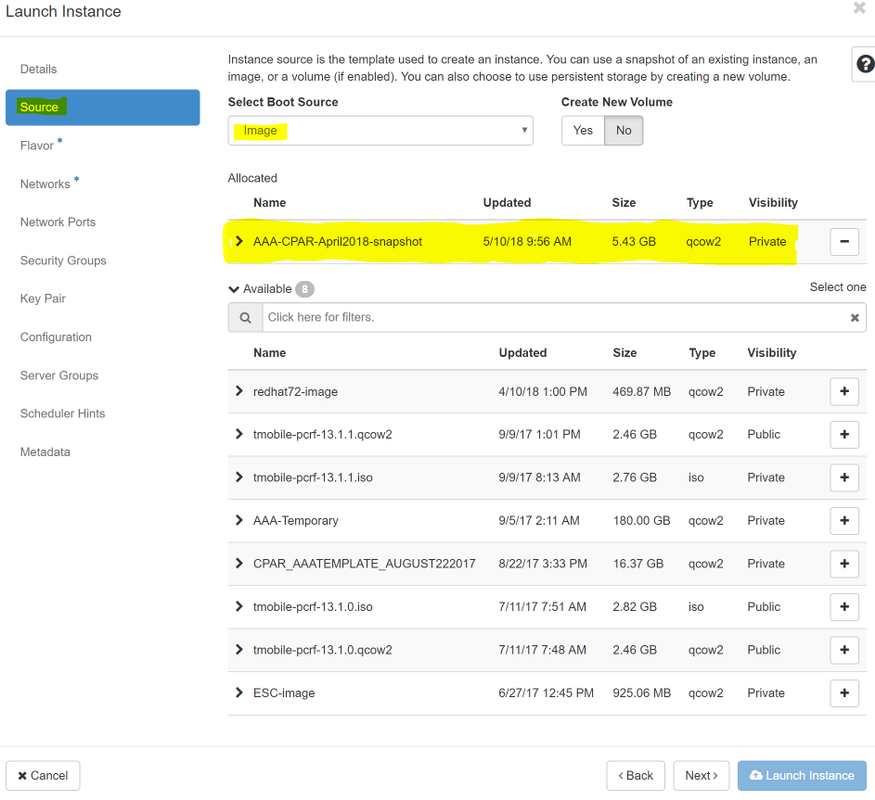
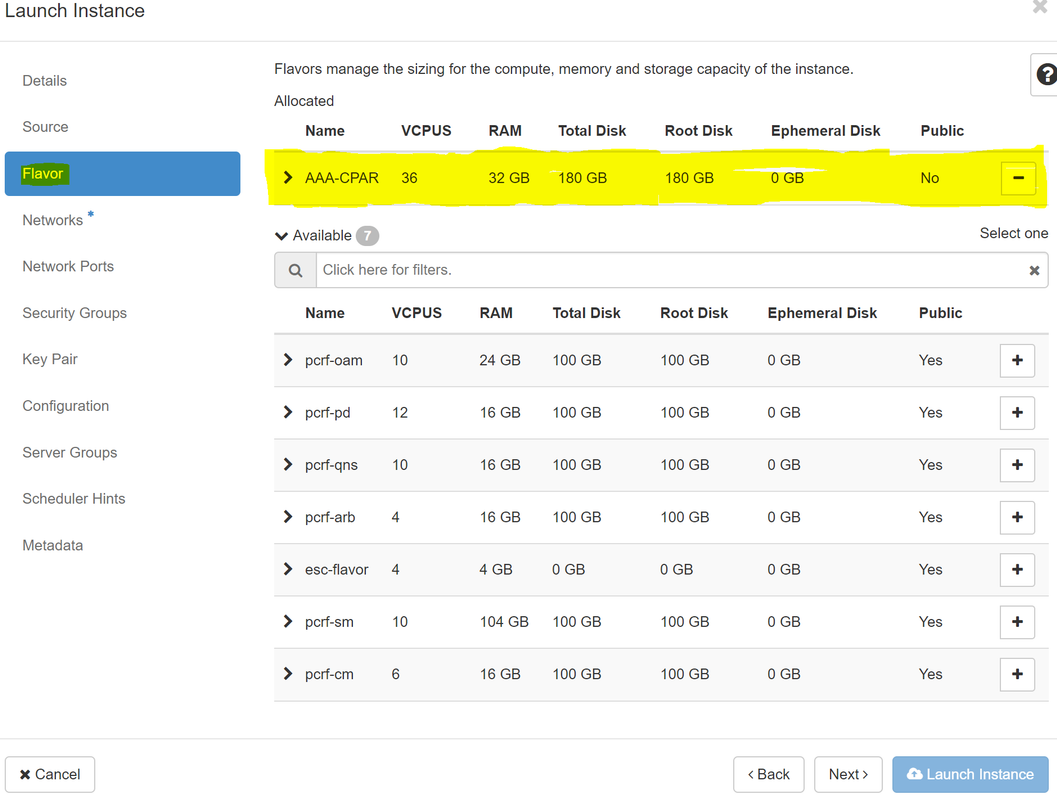
Paso 7. En la pestaña Sabor, elija el sabor AAA mientras hace clic en el +, como se muestra en la imagen.
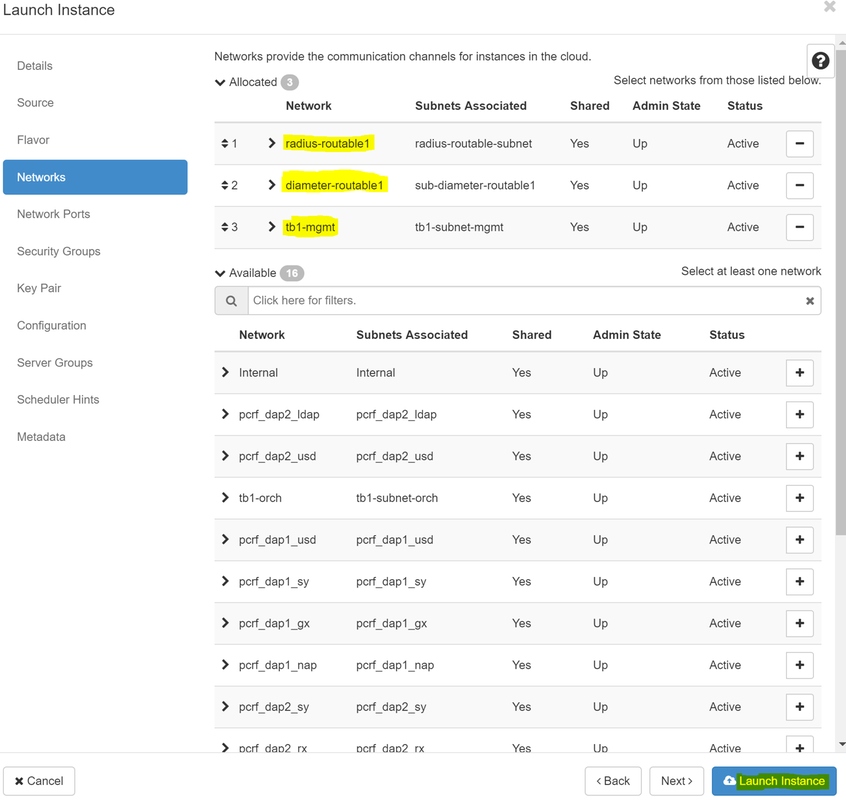
Paso 8. Ahora navegue a la pestaña Redes y elija las redes que necesita la instancia a medida que hace clic en el signo +. En este caso, seleccione diámetro-soutable1, radius-routable1 y tb1-mgmt, como se muestra en la imagen.
Paso 9. Haga clic en Iniciar instancia para crearla. El progreso se puede supervisar en Horizonte:
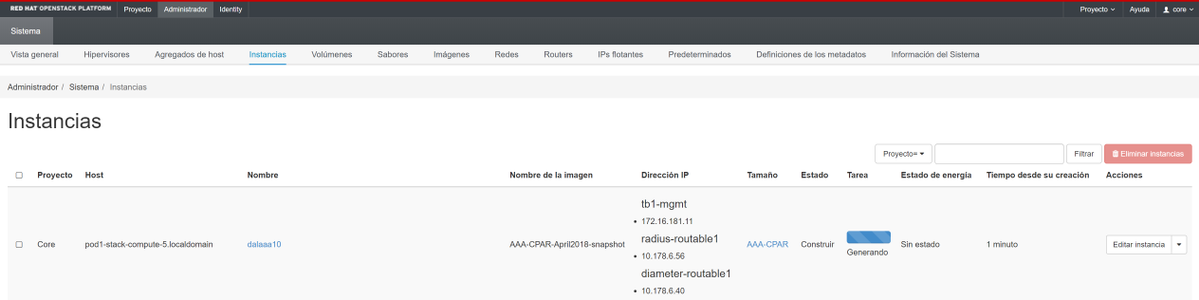
Después de unos minutos, la instancia se implementará completamente y estará lista para su uso.

Creación y asignación de una dirección IP flotante
Una dirección IP flotante es una dirección enrutable, lo que significa que se puede alcanzar desde el exterior de la arquitectura Ultra M/Openstack, y es capaz de comunicarse con otros nodos desde la red.
Paso 1. En el menú superior Horizonte, navegue hasta Admin > Floating IPs.
Paso 2. Haga clic en el botón Asignar IP al proyecto.
Paso 3. En la ventana Asignar IP Flotante seleccione el Pool del que pertenece la nueva IP flotante, el Proyecto donde se va a asignar y la nueva Dirección IP Flotante misma.
Por ejemplo:
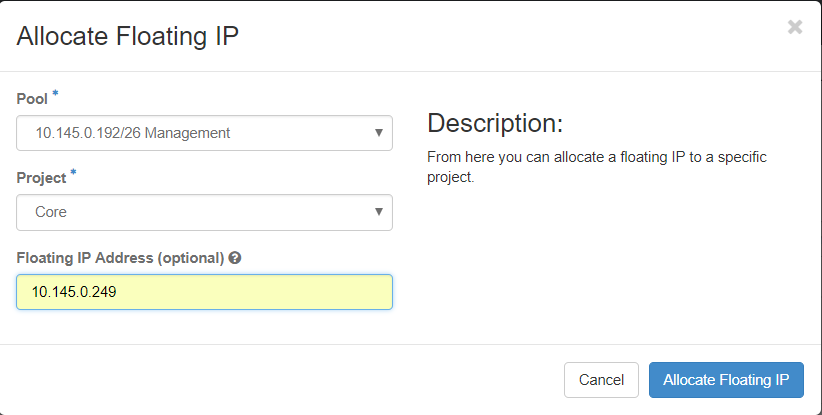
Paso 4. Haga clic en el botón Asignar IP flotante.
Paso 5. En el menú superior Horizonte, vaya a Proyecto > Instancias.
Paso 6. En la columna Acción, haga clic en la flecha que apunta hacia abajo en el botón Crear instantánea, se debe mostrar un menú. Seleccione la opción Asociar IP flotante.
Paso 7. Seleccione la dirección IP flotante correspondiente que se utilizará en el campo IP Address, y elija la interfaz de administración correspondiente (eth0) de la nueva instancia donde se va a asignar esta IP flotante en el puerto que se va a asociar. Consulte la siguiente imagen como ejemplo de este procedimiento.
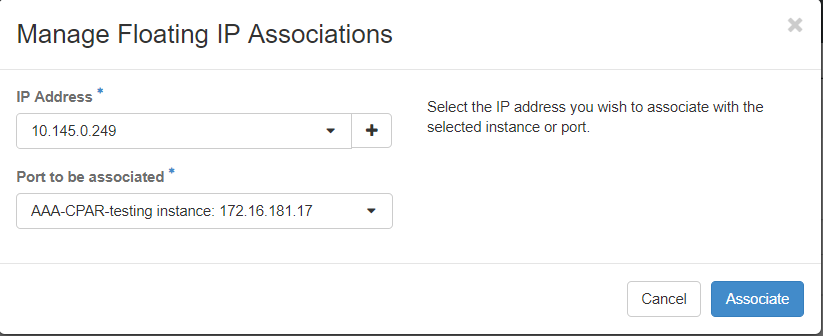
Paso 8. Haga clic en Asociar.
Habilitar SSH
Paso 1. En el menú superior Horizonte, vaya a Proyecto > Instancias.
Paso 2. Haga clic en el nombre de la instancia/VM que se creó en la sección Almorzar una nueva instancia.
Paso 3. Haga clic en la pestaña Consola. Muestra la CLI de la máquina virtual.
Paso 4. Una vez que se muestre la CLI, introduzca las credenciales de inicio de sesión correctas:
Nombre de usuario: raíz
Contraseña cisco123
Paso 5. En la CLI, ingrese el comando vi /etc/ssh/sshd_config para editar la configuración ssh.
Paso 6. Una vez abierto el archivo de configuración ssh, presione I para editar el archivo. A continuación, busque la sección que se muestra a continuación y cambie la primera línea de PasswordAuthentication no a PasswordAuthentication yes.

Paso 7. Presione ESC e ingrese :wq! para guardar los cambios del archivo sshd_config.
Paso 8. Ejecute el comando service sshd restart.
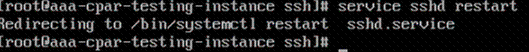
Paso 9. Para probar que los cambios de configuración de SSH se han aplicado correctamente, abra cualquier cliente SSH e intente establecer una conexión segura remota usando la IP flotante asignada a la instancia (es decir, 10.145.0.249) y la raíz del usuario.
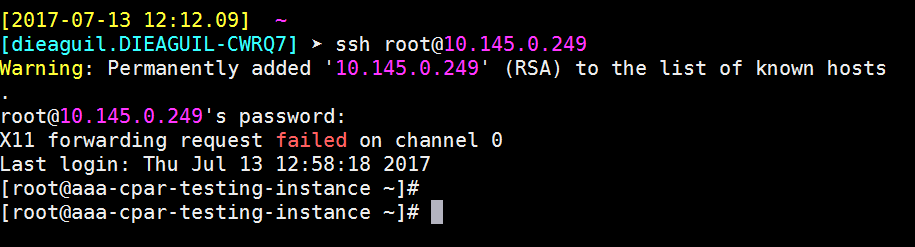
Establecer una Sesión SSH
Abra una sesión SSH con la dirección IP de la máquina virtual/servidor correspondiente donde está instalada la aplicación.

Inicio de instancia de CPAR
Siga estos pasos, una vez que se haya completado la actividad y los servicios CPAR puedan restablecerse en el Sitio que se cerró.
- Para volver a iniciar sesión en Horizon, navegue hasta Project > Instance > Start Instance.
- Verifique que el estado de la instancia esté activo y que el estado de energía esté en ejecución:
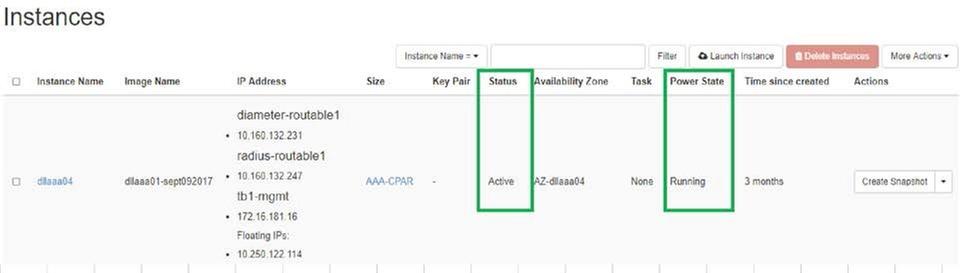
Comprobación de estado posterior a la actividad
Paso 1. Ejecute el comando /opt/CSCOar/bin/arstatus a nivel del sistema operativo.
[root@wscaaa04 ~]# /opt/CSCOar/bin/arstatus Cisco Prime AR RADIUS server running (pid: 24834) Cisco Prime AR Server Agent running (pid: 24821) Cisco Prime AR MCD lock manager running (pid: 24824) Cisco Prime AR MCD server running (pid: 24833) Cisco Prime AR GUI running (pid: 24836) SNMP Master Agent running (pid: 24835) [root@wscaaa04 ~]#
Paso 2. Ejecute el comando /opt/CSCOar/bin/aregcmd a nivel del sistema operativo e ingrese las credenciales de administración. Verifique que CPAR Health sea 10 de 10 y que salga de CPAR CLI.
[root@aaa02 logs]# /opt/CSCOar/bin/aregcmd
Cisco Prime Access Registrar 7.3.0.1 Configuration Utility
Copyright (C) 1995-2017 by Cisco Systems, Inc. All rights reserved.
Cluster:
User: admin
Passphrase:
Logging in to localhost
[ //localhost ]
LicenseInfo = PAR-NG-TPS 7.2(100TPS:)
PAR-ADD-TPS 7.2(2000TPS:)
PAR-RDDR-TRX 7.2()
PAR-HSS 7.2()
Radius/
Administrators/
Server 'Radius' is Running, its health is 10 out of 10
--> exit
Paso 3.Ejecute el comando netstat | diámetro grep y verifique que se hayan establecido todas las conexiones DRA.
El resultado mencionado a continuación es para un entorno en el que se esperan enlaces Diámetro. Si se muestran menos enlaces, esto representa una desconexión del DRA que se debe analizar.
[root@aa02 logs]# netstat | grep diameter tcp 0 0 aaa02.aaa.epc.:77 mp1.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:36 tsa6.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:47 mp2.dra01.d:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:07 tsa5.dra01:diameter ESTABLISHED tcp 0 0 aaa02.aaa.epc.:08 np2.dra01.d:diameter ESTABLISHED
Paso 4. Compruebe que el registro de TPS muestra las solicitudes que está procesando el CPAR. Los valores resaltados representan el TPS y esos son a los que debemos prestar atención.
El valor de TPS no debe exceder de 1500.
[root@wscaaa04 ~]# tail -f /opt/CSCOar/logs/tps-11-21-2017.csv 11-21-2017,23:57:35,263,0 11-21-2017,23:57:50,237,0 11-21-2017,23:58:05,237,0 11-21-2017,23:58:20,257,0 11-21-2017,23:58:35,254,0 11-21-2017,23:58:50,248,0 11-21-2017,23:59:05,272,0 11-21-2017,23:59:20,243,0 11-21-2017,23:59:35,244,0 11-21-2017,23:59:50,233,0
Paso 5. Busque cualquier mensaje de "error" o "alarma" en name_radius_1_log
[root@aaa02 logs]# grep -E "error|alarm" name_radius_1_log
Paso 6.Verifique la cantidad de memoria que es el proceso CPAR, con este comando:
arriba | grep radius
[root@sfraaa02 ~]# top | grep radius 27008 root 20 0 20.228g 2.413g 11408 S 128.3 7.7 1165:41 radius
Este valor resaltado debe ser menor que: 7 Gb, que es el máximo permitido en un nivel de aplicación.
Con la colaboración de ingenieros de Cisco
- Karthikeyan DachanamoorthyCisco Advance Services
- Harshita BhardwajCisco Advance Services
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)