Solución de problemas de alta disponibilidad de Firepower Threat Defence
Opciones de descarga
-
ePub (443.3 KB)
Visualice en diferentes aplicaciones en iPhone, iPad, Android, Sony Reader o Windows Phone -
Mobi (Kindle) (506.6 KB)
Visualice en dispositivo Kindle o aplicación Kindle en múltiples dispositivos
Lenguaje no discriminatorio
El conjunto de documentos para este producto aspira al uso de un lenguaje no discriminatorio. A los fines de esta documentación, "no discriminatorio" se refiere al lenguaje que no implica discriminación por motivos de edad, discapacidad, género, identidad de raza, identidad étnica, orientación sexual, nivel socioeconómico e interseccionalidad. Puede haber excepciones en la documentación debido al lenguaje que se encuentra ya en las interfaces de usuario del software del producto, el lenguaje utilizado en función de la documentación de la RFP o el lenguaje utilizado por un producto de terceros al que se hace referencia. Obtenga más información sobre cómo Cisco utiliza el lenguaje inclusivo.
Acerca de esta traducción
Cisco ha traducido este documento combinando la traducción automática y los recursos humanos a fin de ofrecer a nuestros usuarios en todo el mundo contenido en su propio idioma. Tenga en cuenta que incluso la mejor traducción automática podría no ser tan precisa como la proporcionada por un traductor profesional. Cisco Systems, Inc. no asume ninguna responsabilidad por la precisión de estas traducciones y recomienda remitirse siempre al documento original escrito en inglés (insertar vínculo URL).
Contenido
Introducción
Este documento describe el funcionamiento, la verificación y los procedimientos de resolución de problemas para la alta disponibilidad (HA) en Firepower Threat Defence (FTD).
Prerequisites
Requirements
Cisco recomienda conocer estos temas:
- Plataformas FTD y ASA
- Capturas de paquetes en dispositivos FTD
Se recomienda encarecidamente leer la Guía de configuración de Firepower Configurar alta disponibilidad de FTD en appliances Firepower para comprender mejor los conceptos descritos en este documento.
Componentes Utilizados
La información que contiene este documento se basa en las siguientes versiones de software y hardware.
- FTD de Cisco
- Cisco Firepower Management Center (FMC)
La información que contiene este documento se creó a partir de los dispositivos en un ambiente de laboratorio específico. Todos los dispositivos que se utilizan en este documento se pusieron en funcionamiento con una configuración verificada (predeterminada). Si tiene una red en vivo, asegúrese de entender el posible impacto de cualquier comando.
Antecedentes
La información y los ejemplos se basan en FTD, pero la mayoría de los conceptos también son totalmente aplicables a Adaptive Security Appliance (ASA).
Un FTD admite dos modos de gestión principales:
- Off-box a través de FMC, también conocido como gestión remota
- Integrado mediante Firepower Device Manager (FDM), también conocido como gestión local
Nota: El FTD gestionado a través de FDM se puede añadir en alta disponibilidad a partir del código de versión v6.3.0 de Firepower.
Opciones de diseño
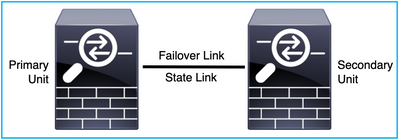
Desde el punto de vista del diseño del FTD, se puede conectar directamente, como se muestra en esta imagen:
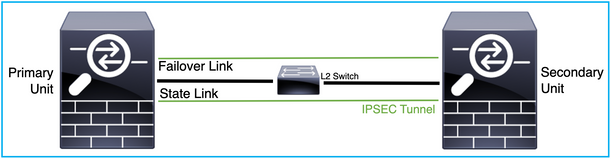
O bien, se puede conectar a través del switch de capa 2 (L2), como se muestra en esta imagen:
Terminología de HA
| Activo |
El ASA activo recibe todos los flujos de tráfico y filtra todo el tráfico de red. Los cambios de configuración se realizan en el ASA activo. |
| Enlace HA |
Las dos unidades en un par de failover se comunican constantemente a través de un link de failover para determinar el estado operativo de cada unidad y para sincronizar los cambios de configuración. La información compartida a través del enlace es:
|
| Principal |
Esta es la unidad que se configura generalmente primero cuando se crea un HA. La importancia de esto radica en que si ambos dispositivos de un ASA HA se unieran en el mismo instante, el principal asumiría la función activa. |
| Secundario |
Esta es la unidad que se configura generalmente en segundo lugar cuando se crea un HA. La importancia de esto radica en que, si ambos dispositivos de un ASA HA se unieran en el mismo instante, el secundario asumiría la función de espera. |
| Standby |
El ASA en espera no maneja ningún tráfico en vivo, sincroniza las conexiones y la configuración del dispositivo activo, y asume el rol activo en caso de una falla. |
| Enlace de estado |
La unidad activa utiliza el link de estado para pasar la información de estado de conexión al dispositivo en espera. Por lo tanto, la unidad standby puede mantener ciertos tipos de conexiones y no le afecta. Esta información ayuda a la unidad standby a mantener las conexiones que existen cuando ocurre un failover. Nota: Cuando utiliza el mismo link para failover y stateful failover, conserva las interfaces mejor. Sin embargo, debe considerar una interfaz dedicada para el link de estado y el link de failover, si tiene una configuración grande y una red de tráfico alto. Recomendamos que el ancho de banda del link de stateful failover coincida con el ancho de banda más grande de las interfaces de datos en el dispositivo. |
Estados HA
| Activo |
El dispositivo gestiona actualmente el tráfico activo en la red y todos los cambios de configuración que deben realizarse deben realizarse en este dispositivo. |
| App Sync |
El dispositivo en este estado sincroniza la configuración desde el dispositivo activo. |
| Sincronización masiva |
El dispositivo en este estado sincroniza la configuración desde el dispositivo activo. |
| Inhabilitado |
La conmutación por fallas en la unidad ha sido deshabilitada (comando: no failover). |
| Negociación |
El dispositivo comprueba la disponibilidad del dispositivo activo y asume la función activa si el dispositivo activo no está preparado para el modo de espera. |
| Preparado para espera |
Actualmente, el dispositivo no gestiona el tráfico, pero asume la función activa si el dispositivo activo muestra algún problema de comprobación de estado. |
| Configuración de sincronización |
La configuración se replica desde el dispositivo activo al dispositivo en espera. |
| En espera en frío |
El dispositivo asume el control como activo en la conmutación por fallas pero no replica los eventos de conexión. |
Diagrama de flujo de estado HA
Principal (sin ningún par conectado):

Secundario (con un peer conectado activo):

Verificación de IU
FTD HA gestionado de FirePOWER Management Center
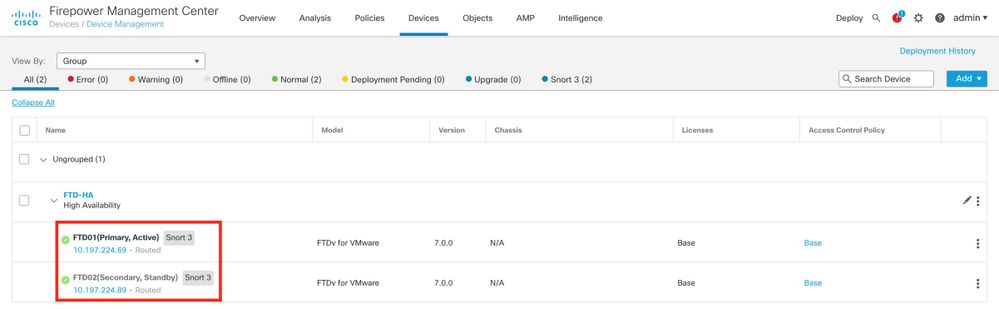
El estado de FTD HA se puede comprobar desde la interfaz de usuario de FMC al navegar hasta Device > Device Management, como se muestra en esta imagen:
FTD HA gestionado de FDM
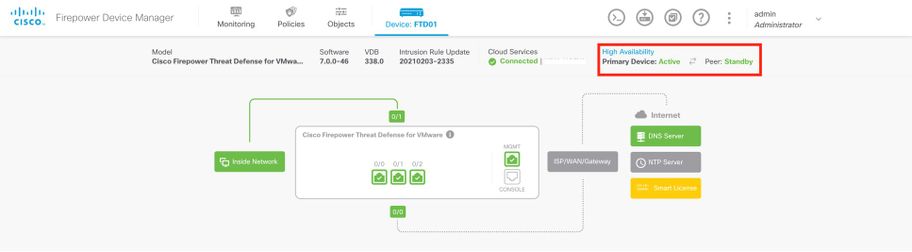
Página principal de descripción general de FDM:
Página de descripción general secundaria de FDM:
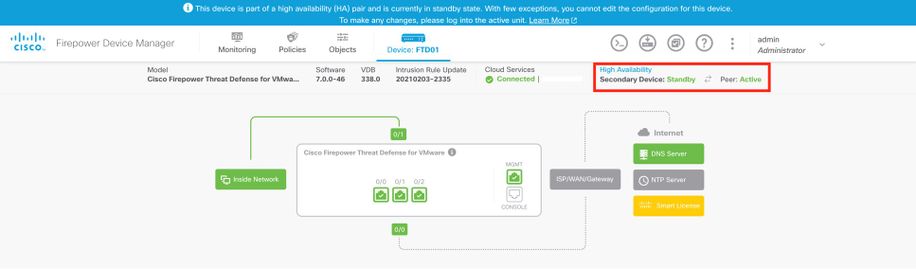
ASA HA gestionado por ASDM
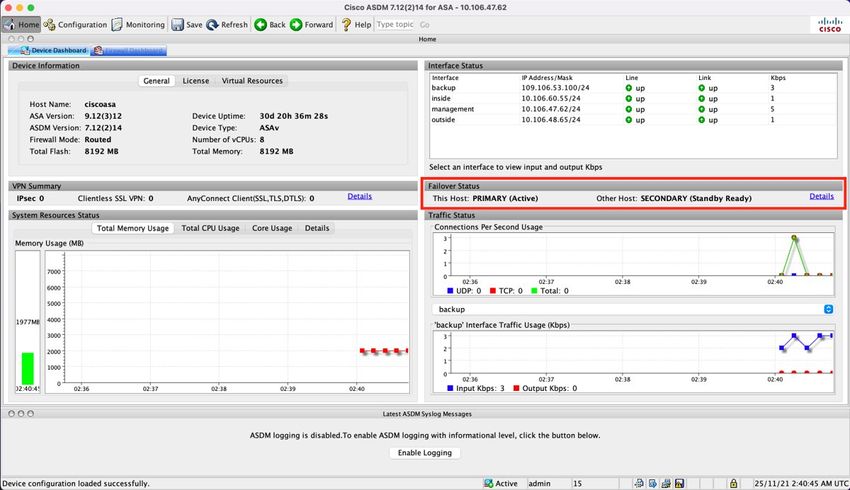
Página de inicio de ASDM para ASA principal:
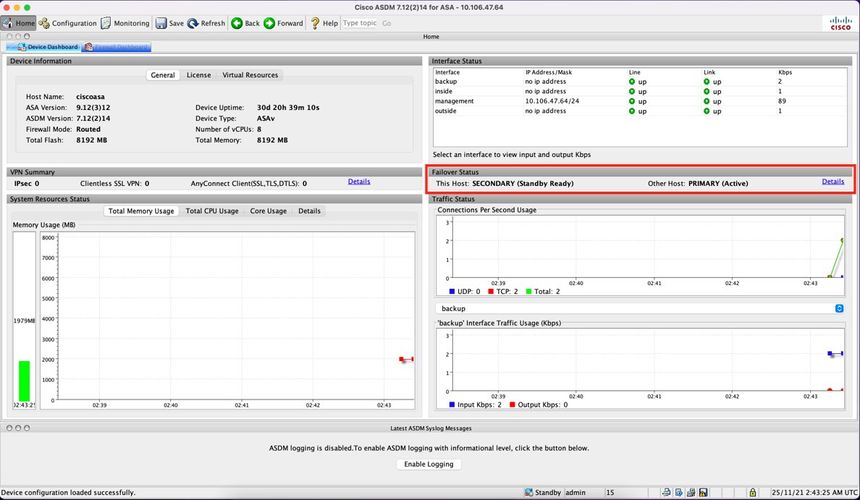
Página de inicio de ASDM para ASA secundario:
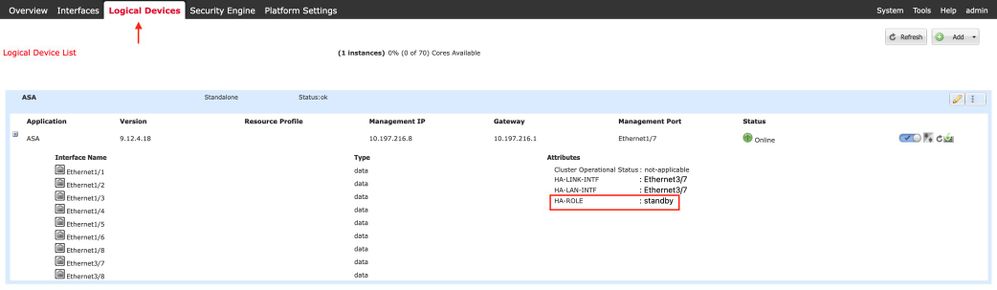
Firepower Chassis Manager para 4100/9300 con FTD/ASA HA
Página Dispositivo lógico de FCM principal:
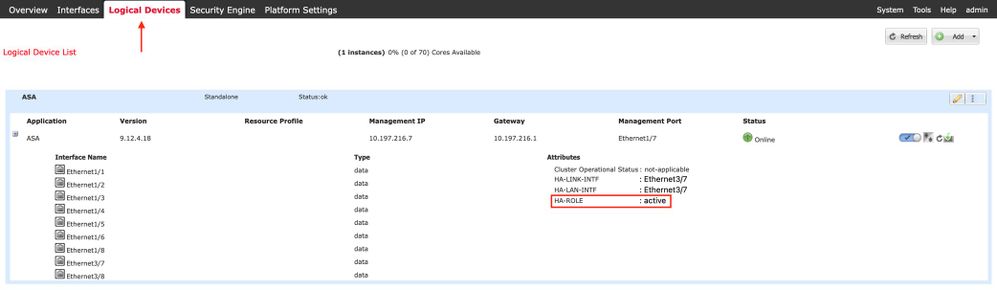
Página Dispositivo lógico FCM secundario:
Verificar CLI
> show running-config failover
failover
failover lan unit secondary
failover lan interface failover-link GigabitEthernet0/2
failover replication http
failover link failover-link GigabitEthernet0/2
failover interface ip failover-link 10.10.69.49 255.255.255.0 standby 10.10.69.89
Los puntos importantes a tener en cuenta en esto son:
- failover
- failover lan unit secondary —> si la unidad es primaria o secundaria
- failover lan interface failover-link GigabitEthernet0/2 —> failover link physical interface on the device
- failover replication http
- failover link failover-link GigabitEthernet0/2
- failover interface ip failover-link 10.10.69.49 255.255.255.0 standby 10.10.69.89 —> primary and the standby device failover link ip addresses.
> show failover
Failover On
Failover unit Secondary
Failover LAN Interface: failover-link GigabitEthernet0/2 (up)
Reconnect timeout 0:00:00
Unit Poll frequency 1 seconds, holdtime 15 seconds
Interface Poll frequency 5 seconds, holdtime 25 seconds
Interface Policy 1
Monitored Interfaces 0 of 311 maximum
MAC Address Move Notification Interval not set
failover replication http
Version: Ours 9.16(0)26, Mate 9.16(0)26
Serial Number: Ours 9A1JSSKW48J, Mate 9ABR3HWFG12
Last Failover at: 01:18:19 UTC Nov 25 2021
This host: Secondary - Standby Ready
Active time: 0 (sec)
slot 0: ASAv hw/sw rev (/9.16(0)26) status (Up Sys)
Interface outside (0.0.0.0): Normal (Not-Monitored)
Interface inside (192.168.45.2): Normal (Not-Monitored)
Interface diagnostic (0.0.0.0): Normal (Not-Monitored)
slot 1: snort rev (1.0) status (up)
slot 2: diskstatus rev (1.0) status (up)
Other host: Primary - Active
Active time: 707216 (sec)
Interface outside (0.0.0.0): Normal (Not-Monitored)
Interface inside (192.168.45.1): Normal (Not-Monitored)
Interface diagnostic (0.0.0.0): Normal (Not-Monitored)
slot 1: snort rev (1.0) status (up)
slot 2: diskstatus rev (1.0) status (up)
Stateful Failover Logical Update Statistics
Link : failover-link GigabitEthernet0/2 (up)
Stateful Obj xmit xerr rcv rerr
General 95752 0 115789 0
sys cmd 95752 0 95752 0
up time 0 0 0 0
RPC services 0 0 0 0
TCP conn 0 0 0 0
UDP conn 0 0 0 0
ARP tbl 0 0 20036 0
Xlate_Timeout 0 0 0 0
IPv6 ND tbl 0 0 0 0
VPN IKEv1 SA 0 0 0 0
VPN IKEv1 P2 0 0 0 0
VPN IKEv2 SA 0 0 0 0
VPN IKEv2 P2 0 0 0 0
VPN CTCP upd 0 0 0 0
VPN SDI upd 0 0 0 0
VPN DHCP upd 0 0 0 0
SIP Session 0 0 0 0
SIP Tx 0 0 0 0
SIP Pinhole 0 0 0 0
Route Session 0 0 0 0
Router ID 0 0 0 0
User-Identity 0 0 1 0
CTS SGTNAME 0 0 0 0
CTS PAC 0 0 0 0
TrustSec-SXP 0 0 0 0
IPv6 Route 0 0 0 0
STS Table 0 0 0 0
Rule DB B-Sync 0 0 0 0
Rule DB P-Sync 0 0 0 0
Rule DB Delete 0 0 0 0
Logical Update Queue Information
Cur Max Total
Recv Q: 0 5 504656
Xmit Q: 0 1 95752
Failover activado: La conmutación por fallas está habilitada o inhabilitada.
Este host: Secundario: Preparado para la espera. La función de este dispositivo y los estados de las interfaces.
Otros hosts: Primario - Activo. El otro dispositivo está en estado Activo y se comunica con el dispositivo actual.
> show failover history
==========================================================================
From State To State Reason
==========================================================================
01:18:14 UTC Nov 25 2021
Not Detected Negotiation No Error
01:18:27 UTC Nov 25 2021
Negotiation Just Active No Active unit found
01:18:27 UTC Nov 25 2021
Just Active Active Drain No Active unit found
01:18:27 UTC Nov 25 2021
Active Drain Active Applying Config No Active unit found
01:18:27 UTC Nov 25 2021
Active Applying Config Active Config Applied No Active unit found
01:18:27 UTC Nov 25 2021
Active Config Applied Active No Active unit found
==========================================================================
Utilice esta opción para comprobar los estados históricos de los dispositivos y los motivos de dichos cambios de estado:
> show failover state
State Last Failure Reason Date/Time
This host - Secondary
Standby Ready None
Other host - Primary
Active None
====Configuration State===
Sync Done - STANDBY
====Communication State===
Mac set
Verifique el estado actual de los dispositivos y el motivo de la última conmutación por error:
| Campo |
Descripción |
|---|---|
| Estado de configuración |
Muestra el estado de la sincronización de la configuración. Posibles estados de configuración para la unidad en espera:
Posibles estados de configuración para la unidad activa:
|
| Estado de comunicación |
Muestra el estado de la sincronización de la dirección MAC.
|
| Fecha/hora |
Muestra una fecha y una marca de hora para la falla. |
| Motivo del último error |
Muestra el motivo del último error notificado. Esta información no se borra, incluso si se borra la condición de falla. Esta información sólo cambia cuando se produce una conmutación por error. Posibles razones de falla:
|
| Estado |
Muestra el estado Primario/Secundario y Activo/En espera de la unidad. |
| Este host/Otros hosts |
Este host indica la información del dispositivo en el que se ejecutó el comando. Otro host indica información para el otro dispositivo en el par de failover. |
> show failover descriptor
outside send: 00020000ffff0000 receive: 00020000ffff0000
inside send: 00020100ffff0000 receive: 00020100ffff0000
diagnostic send: 01020000ffff0000 receive: 01020000ffff0000
Troubleshoot
Depuraciones
> debug fover ?
cable Failover LAN status
cmd-exec Failover EXEC command execution
fail Failover internal exception
fmsg Failover message
ifc Network interface status trace
open Failover device open
rx Failover Message receive
rxdmp Failover recv message dump (serial console only)
rxip IP network failover packet recv
snort Failover NGFW mode snort processing
switch Failover Switching status
sync Failover config/command replication
tx Failover Message xmit
txdmp Failover xmit message dump (serial console only)
txip IP network failover packet xmit
verify Failover message verify
Capturas y capturas de interfaz de failover:
Puede consultar esta captura para determinar si los paquetes hello de failover se envían en el link de failover a la velocidad a la que se envían.
> show capture
capture capfail type raw-data interface Failover [Capturing - 452080 bytes]
match ip host 10.197.200.69 host 10.197.200.89
> show capture capfail
15 packets captured
1: 09:53:18.506611 10.197.200.69 > 10.197.200.89 ip-proto-105, length 54
2: 09:53:18.506687 10.197.200.89 > 10.197.200.69 ip-proto-105, length 54
3: 09:53:18.813800 10.197.200.89 > 10.197.200.69 ip-proto-105, length 46
4: 09:53:18.814121 10.197.200.69 > 10.197.200.89 ip-proto-105, length 50
5: 09:53:18.814151 10.197.200.69 > 10.197.200.89 ip-proto-105, length 62
6: 09:53:18.815143 10.197.200.89 > 10.197.200.69 ip-proto-105, length 62
7: 09:53:18.815158 10.197.200.89 > 10.197.200.69 ip-proto-105, length 50
8: 09:53:18.815372 10.197.200.69 > 10.197.200.89 ip-proto-105, length 50
9: 09:53:19.514530 10.197.200.89 > 10.197.200.69 ip-proto-105, length 54
10: 09:53:19.514972 10.197.200.69 > 10.197.200.89 ip-proto-105, length 54
11: 09:53:19.718041 10.197.200.69 > 10.197.200.89 ip-proto-9, length 70
12: 09:53:20.533084 10.197.200.69 > 10.197.200.89 ip-proto-105, length 54
13: 09:53:20.533999 10.197.200.89 > 10.197.200.69 ip-proto-105, length 54
14: 09:53:20.686625 10.197.200.89 > 10.197.200.69 ip-proto-9, length 74
15: 09:53:20.686732 10.197.200.69 > 10.197.200.89 ip-proto-9, length 74
15 packets shown
Captura ARP en el link de failover:
Puede tomar esta captura para ver si los peers tienen entradas Mac en la tabla ARP.
> show capture
capture caparp type raw-data ethernet-type arp interface Failover [Capturing - 1492 bytes]
> show capture caparp
22 packets captured
1: 11:02:38.235873 arp who-has 10.197.200.69 tell 10.197.200.89
2: 11:02:38.235934 arp reply 10.197.200.69 is-at 0:50:56:a0:85:6c
3: 11:03:47.228793 arp who-has 10.197.200.69 tell 10.197.200.89
4: 11:03:47.228870 arp reply 10.197.200.69 is-at 0:50:56:a0:85:6c
5: 11:08:52.231296 arp who-has 10.197.200.69 tell 10.197.200.89
6: 11:08:52.231387 arp reply 10.197.200.69 is-at 0:50:56:a0:85:6c
7: 11:32:49.134163 arp who-has 0.0.0.0 (ff:ff:ff:ff:ff:ff) tell 0.0.0.0 (0:0:0:0:0:0)
8: 11:32:50.226443 arp who-has 10.197.200.1 tell 10.197.200.28
9: 11:42:17.220081 arp who-has 10.197.200.89 tell 10.197.200.69
10: 11:42:17.221652 arp reply 10.197.200.89 is-at 0:50:56:a0:72:4d
11: 11:42:20.224124 arp who-has 10.197.200.89 tell 10.197.200.69
12: 11:42:20.225726 arp reply 10.197.200.89 is-at 0:50:56:a0:72:4d
13: 11:42:25.288849 arp who-has 10.197.200.69 tell 10.197.200.89
14: 11:42:25.288956 arp reply 10.197.200.69 is-at 0:50:56:a0:85:6c
15: 11:46:17.219638 arp who-has 10.197.200.89 tell 10.197.200.69
16: 11:46:17.220295 arp reply 10.197.200.89 is-at 0:50:56:a0:72:4d
17: 11:47:08.135857 arp who-has 10.197.200.69 tell 10.197.200.89
18: 11:47:08.135994 arp reply 10.197.200.69 is-at 0:50:56:a0:85:6c
19: 11:47:11.142418 arp who-has 10.197.200.89 tell 10.197.200.69
20: 11:47:11.143150 arp reply 10.197.200.89 is-at 0:50:56:a0:72:4d
21: 11:47:18.213993 arp who-has 10.197.200.69 tell 10.197.200.89
22: 11:47:18.214084 arp reply 10.197.200.69 is-at 0:50:56:a0:85:6c
22 packets shown
>
Escenarios
Si la unidad de peer no puede unirse al grupo HA o falla mientras implementa los cambios de la unidad activa, inicie sesión en la unidad fallada, navegue a la página Alta Disponibilidad y haga clic en el enlace Historial de Failover.
Error de APP-SYNC
Si el resultado de show failover history indica una falla de App Sync, entonces hubo un problema en el momento de la fase de validación de HA, donde el sistema verifica que las unidades pueden funcionar correctamente como un grupo de alta disponibilidad.
Aparece el mensaje "Toda la validación superada" cuando el estado De es App Sync y el nodo pasa al estado Preparado en espera.
Cualquier error de validación pasa el par al estado Deshabilitado (Error). Resuelva los problemas para que los pares funcionen como un grupo de alta disponibilidad nuevamente.
Tenga en cuenta que si corrige un error de App Sync y realiza cambios en la unidad activa, debe implementarlos y luego reanudar HA para que el nodo par se una.
Los mensajes indican errores, con una explicación de cómo puede resolver los problemas. Estos errores pueden ocurrir en la unión de nodos y en cada implementación subsiguiente.
En el momento de la unión de un nodo, el sistema realiza una comprobación de la última configuración implementada en la unidad activa.
El nodo en espera no puede unirse a HA con "Error de sincronización de la aplicación de CD: Error de aplicación de configuración de aplicación"
En la línea de comandos Standby FTD, /ngfw/var/log/action_queue.log debe tener la razón de la falla de configuración.
Solución: Una vez identificado el error de configuración y realizados los cambios necesarios, se puede reanudar el HA.
Consulte Cisco bug IDCSCvu15611.
==========================================================================
From State To State Reason
==========================================================================
15:10:16 CDT Sep 28 2021
Not Detected Disabled No Error
15:10:18 CDT Sep 28 2021
Disabled Negotiation Set by the config command
15:10:24 CDT Sep 28 2021
Negotiation Cold Standby Detected an Active mate
15:10:25 CDT Sep 28 2021
Cold Standby App Sync Detected an Active mate
15:10:55 CDT Sep 28 2021
App Sync Disabled CD App Sync error is App Config Apply Failed
==========================================================================
El nodo en espera no puede unirse a HA con "La progresión del estado de HA ha fallado debido al tiempo de espera de SINCRONIZACIÓN de APP"
En la línea de comandos Standby FTD, /ngfw/var/log/ngfwmanager.log debe tener la razón del tiempo de espera de sincronización de la aplicación.
En esta etapa, las implementaciones de políticas también fallan porque la unidad activa piensa que la sincronización de la aplicación aún está en curso.
La implementación de la política produce el error: "dado que el proceso de newNode join/AppSync está en curso, no se permiten los cambios de configuración y, por lo tanto, rechaza la solicitud de implementación. Vuelva a intentar la implementación más tarde."
Solución: A veces, cuando reanuda la alta disponibilidad en el nodo En espera, puede resolver el problema.
Consulte Cisco bug ID CSCvt48941.
Consulte Cisco bug ID CSCvx11636.
==========================================================================
From State To State Reason
==========================================================================
19:07:01 EST MAY 31 2021
Not Detected Disabled No Error
19:07:04 EST MAY 31 2021
Disabled Negotiation Set by the config command
19:07:06 EST MAY 31 2021
Negotiation Cold Standby Detected an Active mate
19:07:07 EST MAY 31 2021
Cold Standby App Sync Detected an Active mate
21:11:18 EST Jun 30 2021
App Sync Disabled HA state progression failed due to APP SYNC timeout
==========================================================================
El nodo en espera no puede unirse al HA con "Error de sincronización de la aplicación de CD al no aplicar la configuración del SSP en espera"
En la línea de comandos Standby FTD, /ngfw/var/log/ngfwmanager.log debe tener la razón exacta de la falla.
Solución: A veces, cuando reanuda la alta disponibilidad en el nodo En espera, puede resolver el problema.
Consulte ID de bug de Cisco CSCvy04965.
==========================================================================
From State To State Reason
==========================================================================
04:15:15 UTC Apr 17 2021
Not Detected Disabled No Error
04:15:24 UTC Apr 17 2021
Disabled Negotiation Set by the config command
04:16:12 UTC Apr 17 2021
Negotiation Cold Standby Detected an Active mate
04:16:13 UTC Apr 17 2021
Cold Standby App Sync Detected an Active mate
04:17:44 UTC Apr 17 2021
App Sync Disabled CD App Sync error is Failed to apply SSP config on standby
==========================================================================
Error de comprobación de estado
"HELLO not heard from mate" significa que el compañero está fuera de línea o que el link de failover no comunica los mensajes de keepalive HELLO.
Intente iniciar sesión en el otro dispositivo; si SSH no funciona, obtenga acceso a la consola y verifique si el dispositivo está operativo o desconectado.
Si está operativo, identifique la causa de la falla con el comando show failover state.
Si no está operativo, intente un reinicio sin errores y verifique si ve algún registro de inicio en la consola; de lo contrario, el dispositivo puede considerarse defectuoso de hardware.
==========================================================================
From State To State Reason
==========================================================================
04:53:36 UTC Feb 6 2021
Failed Standby Ready Interface check
02:12:46 UTC Jul 11 2021
Standby Ready Just Active HELLO not heard from mate
02:12:46 UTC Jul 11 2021
Active Config Applied Active HELLO not heard from mate
==========================================================================
Falla de disco o de Snort Down
Si el FTD da este error, "Detectar falla del motor de inspección debido a falla del disco", hay 2 posibilidades.
El motor de detección (instancia de SNORT) está inactivo
Esto se puede validar con el comando en el lado de Linux, pmtool status | grep -i de,
Solución: Si alguna de las instancias está inactiva, verifique si hay /ngfw/var/log/messages e identifique la causa.
El Dispositivo Muestra Una Utilización De Disco Elevada
Esto se puede validar con el comando en el lado de Linux, df -Th.
Solución: Identifique el directorio que consume la mayor parte del disco y póngase en contacto con el TAC para eliminar los archivos no deseados.
==========================================================================
From State To State Reason
==========================================================================
Active Config Applied Active No Active unit found
16:07:18 UTC Dec 5 2020
Active Standby Ready Other unit wants me Standby
16:07:20 UTC Dec 5 2020
Standby Ready Failed Detect Inspection engine failure due to disk failure
16:07:29 UTC Dec 5 2020
Failed Standby Ready My Inspection engine is as good as peer due to disk recovery
==========================================================================
Fallo de tarjeta de servicio
Por lo general, estos problemas se notifican debido a un fallo del módulo Firepower en los dispositivos ASA 5500-X. Verifique la integridad del módulo mediante show module sfr details.
Solución: Recopile el registro del sistema ASA en el momento de la falla y estos pueden contener detalles como la falla del plano de datos o de control.
Esto puede deberse a varias razones en el módulo SFR. Se recomienda abrir el TAC para encontrar la causa raíz de este problema en el IPS.
==========================================================================
From State To State Reason
==========================================================================
21:48:19 CDT Aug 1 2021
Active Standby Ready Set by the config command
21:48:19 CDT Aug 1 2021
Standby Ready Just Active Service card in other unit has failed
21:48:19 CDT Aug 1 2021
Active Config Applied Active Service card in other unit has failed
==========================================================================
Falla de latido MIO
Firepower Threat Defence/ASA informa de un fallo debido a un "fallo de latido del blade MIO" en FPR1K, 2K, 4K y 9K.
Consulte ID de bug de Cisco CSCvy14484.
Consulte ID de bug de Cisco CSCvh26447.
==========================================================================
From State To State Reason
==========================================================================
20:14:45 EDT Apr 14 2021
Active Config Applied Active No Active unit found
20:15:18 EDT Apr 14 2021
Active Failed MIO-blade heartbeat failure
20:15:19 EDT Apr 14 2021
Failed Negotiation MIO-blade heartbeat recovered
==========================================================================
Información Relacionada
Historial de revisiones
| Revisión | Fecha de publicación | Comentarios |
|---|---|---|
3.0 |
27-Nov-2024 |
Recertificación |
1.0 |
06-Apr-2022 |
Versión inicial |
Con la colaboración de ingenieros de Cisco
- Manav BansalCisco TAC Engineer
- Abhay BhaskarCisco TAC Engineer
 Comentarios
ComentariosContacte a Cisco
- Abrir un caso de soporte

- (Requiere un Cisco Service Contract)