Introduction
This document describes the Redundancy Configuration Manager (RCM) and User Plane Function (UPF) issues causing sessmgr server state.
Prerequisites
Requirements
Cisco recommends that you have knowledge of these topics:
Components Used
The information in this document is based on these software and hardware versions:
- RCM-checkpointmgr
- UPF-sessmgr
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, ensure that you understand the potential impact of any command.
Background Information
It also provides a detailed troubleshooting guide for sessmgr server state issues, hindering traffic and call processing. Plus, a lab testing section for recovery.
Basics Overview
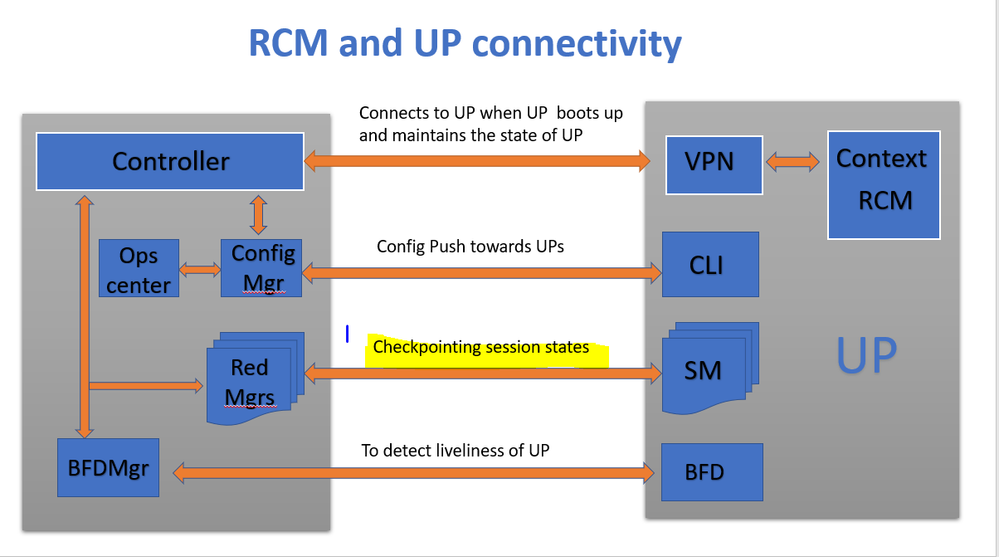
As shown in the image, you can observe the direct connections between redundancy managers (referred to as checkpointmgrs) in RCM and sessmgrs in UPFs for checkpoint tracking.
Redmgrs and Sessmgrs Mapping
1. Every UP has an "N" number of sessmgr.
2. RCM has an "M" number of redmgrs depending on the number of sessmgrs in UPF.
3. Both redmgrs and sessmgrs have 1:1 mapping based on their IDs where there are separate redmgrs for each sessmgr.
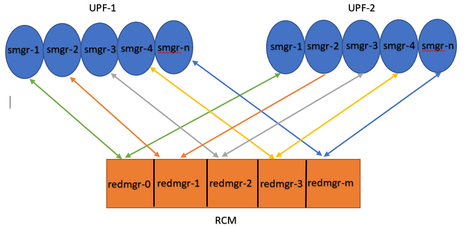
Note :: Redmgr IDs (m) = sessmgr instance ID (n-1)
For example :: smgr-1 is mapped with redmgr 0;smgr-2 is mapped with redmgr-1,
smgr-n is mapped with redmgr(m) = (n-1)
This is important to understand proper IDs of redmgr because we need to have proper logs to be checked
Logs Required
RCM Logs - Command outputs:
rcm show-statistics checkpointmgr-endpointstats
RCM controller and checkpointmgr logs (refer this link)
Log collection
UPF:
Command outputs (hidden mode)
show rcm checkpoint statistics verbose
show session subsystem facility sessmgr all debug-info | grep Mode
If you see any sessmgr in server state check the sessmgr instance IDs and no of sessmgr
show task resources facility sessmgr all
Troubleshoot
Typically, there are 21 sessmgr instances in UPF, consisting of 20 active sessmgrs and 1 standby instance (although this count might vary based on the specific design).
Example:
- To identify inactive active sessmgrs, you can use this command:
show task resources facility sessmgr all
-
In this scenario, attempting to resolve the issue by restarting the problematic sessmgrs and even restarting sessctrl does not lead to the restoration of the affected sessmgrs.
-
Additionally, it is observed that the affected sessmgrs are stuck in server mode rather than the expected client mode, a condition that can be verified using the provided commands.
show rcm checkpoint statistics verbose
show rcm checkpoint statistics verbose
Tuesday August 29 16:27:53 IST 2023
smgr state peer recovery pre-alloc chk-point rcvd chk-point sent
inst conn records calls full micro full micro
---- ------- ----- ------- -------- ----- ----- ----- ----
1 Actv Ready 0 0 0 0 61784891 1041542505
2 Actv Ready 0 0 0 0 61593942 1047914230
3 Actv Ready 0 0 0 0 61471304 1031512458
4 Actv Ready 0 0 0 0 57745529 343772730
5 Actv Ready 0 0 0 0 57665041 356249384
6 Actv Ready 0 0 0 0 57722829 353213059
7 Actv Ready 0 0 0 0 61992022 1044821794
8 Actv Ready 0 0 0 0 61463665 1043128178
Here in above command all the connection can be seen as Actv Ready state which is required
show session subsystem facility sessmgr all debug-info | grep Mode
[local]<Nodename># show session subsystem facility sessmgr all debug-info | grep Mode
Tuesday August 29 16:28:56 IST 2023
Mode: UNKNOWN State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Mode: CLIENT State: SRP_SESS_STATE_SOCK_ACTIVE
Here, all the sessmgrs should ideally be in client mode. However, in this issue, they are in server mode, which prevents them from handling traffic.
Sessmgr Going into Server Mode
-
In order to facilitate communication and transfer of checkpoints, each session manager (sessmgr) establishes a TCP peer connection with the corresponding redundancy manager (redmgr).
-
Once the TCP peer connection is established, the redmgr can checkpoint all subscriber contexts from the sessmgr and save them. This allows for seamless switchover, as the checkpoints can be transferred to other User Plane Functions (UPF) with their respective sessmgr instances.
-
It is crucial for the sessmgr to always be in CLIENT mode. If, for any reason, the sessmgr is detected in server mode, it indicates a broken TCP peer connection with the associated redmgr. In this scenario, checkpointing will not occur.
-
When sessmgrs are stuck in this state within the UPF, performing an unplanned switchover to another UPF without considering the state of the sessmgr results in the same problem. The sessmgr is not able to handle traffic in this situation.

Note: There are certain issues where checkpointmgr itself is waiting for checkpointing where RCM has initiated checkpointing and waiting for the response back from UPF. But when there is no response checkpointmgr itself is not able to communicate which leads to a delay in the completion of the switchover procedure crossing the switchover timer value. So in such cases UP even gets stuck into the PendActive state.
This can be checked in RCM statistics and redmgr logs. Also, with this command, you can get to know which checkpointmgr is has a problem with which UPF.
rcm show-statistics checkpointmgr-endpointstats
4. There can be multiple reasons for sessmgr going into server mode locally but one of the major reasons for this is as explained here.
Reason for Sessmgr Going into Server Mode
1. Based on the number of session managers in the User Plane Function (UPF), replicas are created for the Redundancy Manager (redmgr) and configured in the Resource Control Manager (RCM). This configuration ensures that each redmgr is connected with a session manager instance.
2. If there is a 1:1 mapping between redmgr and sessmgr, what occurs when the session manager instance ID surpasses a value higher than the number of session managers?
For example :::
Sessmgr instance ID :: 1 to 20
Redmgr IDs :: 0 to 19
In this example somehow if my sessmgr instance ID goes beyond the mentioned limit i.e say 21/22/23/24/25 so in this case redmgr is already mapped with instance IDs 0 to 19 and would be unaware about this new sessmgr instance ID created by UPF from 21 to 25 and in such a case sessmgr with this instance IDs :: 21/22/23/24/25 will not be able to form any TCP peer connection with RCM redmgr leading to no checkpoint sync and since there won’t be any checkpoint sync sessmgr will get stuck into server mode and won’t take any traffic.
Refer this diagram
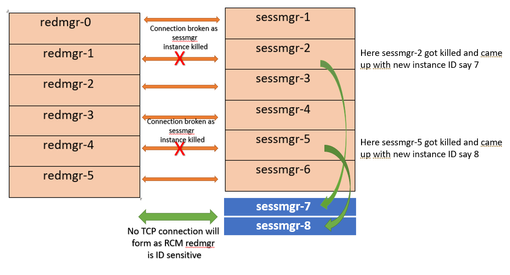
Both this sessmgr instance-7/8 have no TCP peer connection since for RCM redmgr-1 was
connected with instance-2 and redmgr-2 was connected to instance-5 so even though sessmgr
came up with new instance ID value which is beyond defined limit it wont have connection
back with redmgrs which is still just pointing to previous instance but connection is broken
Workaround
The solution to this problem is to limit the number of sessmgr instance IDs to match the number of sessmgrs in UPF and the number of redmgrs in RCM, as specified by the mentioned command.
Max value of sessmgr instance ID = no of checkpointmgr – 1
According to this logic, the number of sessmgrs needs to be defined including standby sessmgrs.
task facility sessmgr max <no of max sessmgrs>
Note :: Implementation of this command needs node reload to enable full functionality of this command
By executing this command, regardless of how many times sessmgr is getting killed, it always comes up with an instance ID value equal to or less than the maximum count of sessmgr. This helps prevent checkpointing issues with RCM and prevents sessmgr from entering server mode for this reason.
 Feedback
Feedback