Introduction
This document describes what a Fibre Channel Network Interface Card (FNIC) Abort is and provides answers to Frequently Asked Questions (FAQ).
What is an Abort?
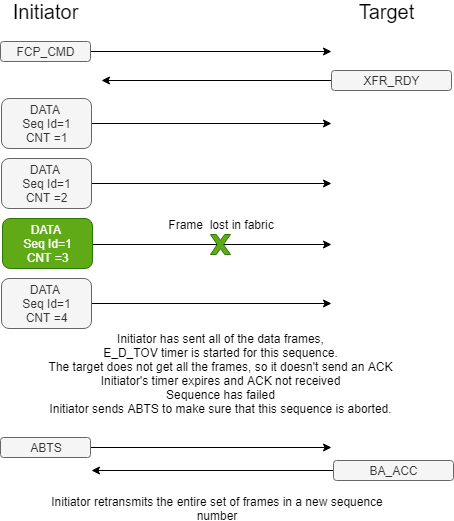
Fibre Channel (FC) has no means of recovery for drops or corrupt frames. Abort (ABTS) message is sent when there are issues with an exchange. An abort is a link level service that can be issued by either the initiator or target. The recovery is handled by the Small Compute System Interface (SCSI) layer with timeouts of 60-120 seconds which depend on the operating system configuration.
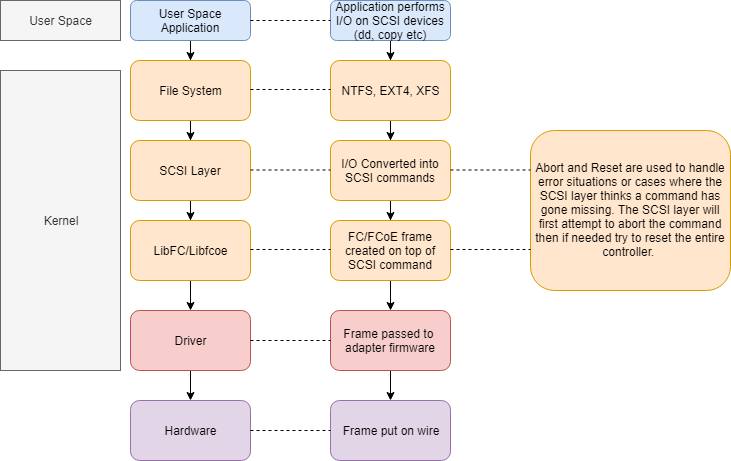
Where does the FNIC fit into the stack?
In the case of Linux/ESXi, the FNIC driver sits between the libfc libraries provided by the Operating System (OS) vendor and the actual hardware. The SCSI layer sends request to fnic driver, fnic driver sends the scsi request to firmware. The firmware generates Fibre Channel over Ethernet (FCoE) frames, and sends on the wire.
Is the FNIC aborts caused by FNIC driver?
No, FNIC aborts are not necessarily a driver issue but rather are a generic message that the initiatior (or target) did not receive a frame within the timeout period and the SCSI layer terminates the exchange and retry.
What can cause FC aborts?
FC aborts can be caused due to various reasons like congestion, low performance devices (hard disk, storage processor, low speed links), firmware issues, driver issues, OS issues, link loss, link down/up, and so on.
As aborts are generic messages, the first step is to narrow down the scope of the issue with questions such as:
- Does it occur on one side of the storage fabric only or both?
- Does it occur on a single host or multiple hosts?
- If multiple hosts, what is common between the hosts that have an issue and what is different from the hosts that do not experience an issue?
- Does it occur when it communicates with a specific Storage Attached Network (SAN) target or specific Logical Unit Number (LUN) on the SAN target?
- Are there other SAN targets or LUNs which do not experience an issue and if so what are the differences with these working LUNs/targets versus the non-working target?
- Is there a pattern to when the issue occurs such as during weekly backup jobs?
The answers to these questions help you isolate where the issue might reside and where to start your focus.
The most common cause of aborts is due to layer 1 issues and it is recommended to check the entire path from initiatior to target for any interface errors such as Cyclic Redundancy Check (CRC) errors or flapping interfaces.
The next common reason for aborts is due to oversubscription of links between the initiatior/target or oversubscription of components on the target such as CPU and the disk. This is where a good performance baseline comes in handy.
What does this abort message indicate found in the log?
VMWare vmkernel log:
2017-07-27T14:54:10.590Z cpu6:33351)<7>fnic : 2 :: Abort Cmd called FCID 0x50a00, LUN 0xa TAG c8 flags 3
In this example, on 2017-07-27T14:54:10 UTC time an abort was called on vmhba2 for FCID 0x50a00 on LUN 0xa with host OS SCSI tag 0xc8.
The LUN ID 0xA is converted to decimal to determine that LUN ID 10 was the LUN the OS attempted to communicate with on the array.
The tag 0xc8 is the host scsi layer's IO tag for the request which can be used to match up with log entries on the VIC adapter.
The device instance 2can be matched up to the vmware vmhba number with fnic-tracetool -i
/tmp # ./fnic-tracetool -i
HBA Device
--- ------
vmhba1 fnic1
vmhba2 fnic2
The FCID 0x50c00can be matched up to a specifc target in the fcns database on the northbound fabric switches if the fabric interconnect runs in end-host mode.
switch-A(nxos)# show fcns database fcid 0x50c00 detail vsan 1
------------------------
VSAN:1 FCID:0x50c00
------------------------
port-wwn (vendor) :50:00:00:00:ff:ff:ff:01 (EMC)
node-wwn :50:00:00:00:ff:ff:ff:00
class :3
node-ip-addr :0.0.0.0
ipa :ff ff ff ff ff ff ff ff
fc4-types:fc4_features :scsi-fcp:both 253
symbolic-port-name :SYMMETRIX::SAF- 3fB::FC::5876_272+::EMUL B80F0000 41234F44 94F360 07.27.15 11:14
symbolic-node-name :SYMMETRIX::FC::5876_272+
port-type :N
port-ip-addr :0.0.0.0
fabric-port-wwn :20:1e:00:2a:6a:ea:00:00
hard-addr :0x000000
permanent-port-wwn (vendor) :50:00:00:00:ff:ff:ff:01 (EMC)
connected interface :fc1/30
VIC Adapter logs
170727-14:54:10.590661 ecom.ecom_main ecom(4:0): abort called for exch abort called for exch 431b, status 3 rx_id 0s_stat 0x0xmit_recvd 0x0burst_offset 0x0sgl_err 0x0 last_param 0x0 last_seq_cnt 0x0tot_bytes_exp 0xa00h_seq_cnt 0x0exch_type 0x1s_id 0x36010fd_id 0x50c00 host_tag 0xc8
- s_stat 0x0 => No frames are received
- exch_type 0x1 => Exchange is Ingress and is active
- Total bytes expected is => tot_bytes_exp 0xa00
- Received is => 0x0
- burst_offset is set => 0x0
- Host scsi layer's IO tag for this request is => 0xc8
- Source ID => 0x36010f
- Dest Target ID => 0x50c00
- Seq ID => 0x0
- rx_id => 0
Status
-
Status 3 = write command
-
Status 1 = read command
Exchange Type(exch_type):
========================
EXCH_NOT_IN_USE = 0,
EXCH_INITIATOR_INGRESS_ACTIVE = 1
EXCH_TARGET_INGRESS_ACTIVE = 2
EXCH_EGRESS_ACTIVE = 3
EXCH_ABORTED = 4
EXCH_DEBUG = 5
Exchange Status values(s_stat
================================
0x00 No frames are received
0x01 At least one frame recvd
0x02 Sequence is still active
0x04 sequence is complete
0x08 transfer sequence init
0x10 egress sequence is active
0x20 rsp fr and host entry sent
0x40 exch data sequence pending
What is the difference between an abort and FCPIO mismatch message?
FCPIO mismatch can occur when not all of the expected data is received.
Total bytes xmit < expecte ddata length
160621-04:26:51.733255 ecom.ecom_main ecom(8:3): ox_id 41d4 rx_id 44b seq_cnt 7 seq_id 1 160621-04:26:52.066235 ecom.ecom_main ecom(8:1): fcpio_data_cnt_mismatch for exch 4202 status 1 rx_id5f7 s_stat 0x3 xmit_recvd 0x3000 burst_offset 0x3000 sgl_err 0x0 last_param 0x2800 last_seq_cnt 0x0 tot_bytes_exp 0x8000 h_seq_cnt 0x5 exch_type 0x0 s_id 0xab800 d_id 0xab800 host_tag 0x377
Related Information
 Feedback
Feedback